【note】Transformer
Attention(注意力机制)
Attention(注意力机制)是一种信息处理机制,目标是从众多信息中选择出对当前任务目标更关键的信息。
假设有 N N N 个输入向量 [ x 1 , x 2 , . . . , x N ] ∈ R D × N [x_1,x_2,...,x_N]\in \R^{D\times N} [x1,x2,...,xN]∈RD×N ,询问向量为 q ∈ R D q\in \R^D q∈RD 。我们需要一个打分函数来计算每个输入向量和查询向量之间的相关性。
注意力打分函数 s ( x , q ) s(x,q) s(x,q) 常用的模型有
- 缩放点积模型 s ( x , q ) = x T q D s(x,q)=\frac{x^Tq}{\sqrt{D}} s(x,q)=DxTq ,其中 D D D 为向量维度。
- 加性模型 s ( x , q ) = v T tanh ( W x + U q ) s(x,q)=v^T\tanh(Wx+Uq) s(x,q)=vTtanh(Wx+Uq) ,其中 W , U , v W,U,v W,U,v 为可学习的参数
选择向量 x n x_n xn 的概率为 α n = S o f t m a x ( s ( x n , q ) ) = exp ( s ( x n , q ) ) ∑ i = 1 N exp ( s ( x i , q ) ) \alpha_n=Softmax(s(x_n,q))=\frac{\exp (s(x_n,q))}{\sum_{i=1}^N\exp (s(x_i,q))} αn=Softmax(s(xn,q))=∑i=1Nexp(s(xi,q))exp(s(xn,q))
注意力函数将输入信息汇总:
a t t ( X , q ) = ∑ n = 1 N α n x n = E z ∼ p ( z ∣ X , q ) [ x z ] att(X,q)=\sum_{n=1}^N\alpha_nx_n=E_{z\sim p(z|X,q)}[x_z] att(X,q)=∑n=1Nαnxn=Ez∼p(z∣X,q)[xz]
键值对注意力
改用 ( K , V ) (K,V) (K,V) 表示 N N N 组输入信息,将注意力函数修改为:
a t t ( ( K , V ) , q ) = ∑ n = 1 N α n v n = 1 ∑ i = 1 N exp ( s ( k i , q ) ) ∑ n = 1 N exp ( s ( k n , q ) ) v n att((K,V),q)=\sum_{n=1}^N\alpha_nv_n=\frac{1}{\sum_{i=1}^N\exp (s(k_i,q))}\sum_{n=1}^N\exp (s(k_n,q))v_n att((K,V),q)=∑n=1Nαnvn=∑i=1Nexp(s(ki,q))1∑n=1Nexp(s(kn,q))vn
当 K = V K=V K=V 时即为普通的注意力机制
多头注意力
若有 M M M 组询问 Q = [ q 1 , q 2 , . . . , q M ] Q=[q_1,q_2,...,q_M] Q=[q1,q2,...,qM] ,每个询问关注输入信息的不同部分,将注意力函数推广为:
a t t ( ( K , V ) , Q ) = ⊕ i = 1 M a t t ( ( K , V ) , q i ) att((K,V),Q)=\oplus_{i=1}^Matt((K,V),q_i) att((K,V),Q)=⊕i=1Matt((K,V),qi)
自注意力模型
自注意力模型可以自动获取模型的长距离依赖关系,提高并行计算效率。
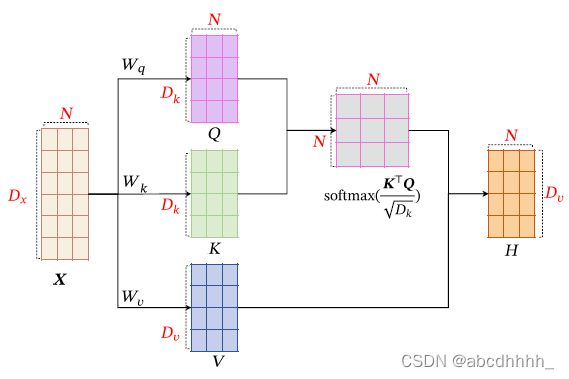
若输入序列为 X = [ x 1 , x 2 , . . . , x N ] ∈ R D x × N X=[x_1,x_2,...,x_N]\in \R^{D_x\times N} X=[x1,x2,...,xN]∈RDx×N ,输出序列为 H = [ h 1 , h 2 , . . . , h N ] ∈ R D v × N H=[h_1,h_2,...,h_N]\in \R^{D_v\times N} H=[h1,h2,...,hN]∈RDv×N ,则自注意力模型的计算过程如下:
- 将 X X X 线性映射到三个不同的空间,得到 Q = W q X , K = W k X , V = W v X Q=W_qX, K=W_kX,V=W_vX Q=WqX,K=WkX,V=WvX (其中 W q , W j ∈ R D k × D x , W v ∈ R D v × D x W_q,W_j\in \R^{D_k\times D_x}, W_v\in \R^{D_v\times D_x} Wq,Wj∈RDk×Dx,Wv∈RDv×Dx 为投影矩阵)
- 利用键值对注意力机制,得到输出向量 h n = a t t ( ( K , V ) , q n ) h_n=att((K,V),q_n) hn=att((K,V),qn)
若采用缩放点积模型( s ( x , q ) = x T q D s(x,q)=\frac{x^Tq}{\sqrt{D}} s(x,q)=DxTq),则 H = V ⋅ S o f t m a x ( K T Q D k ) H=V\cdot Softmax(\frac{K^TQ}{\sqrt{D_k}}) H=V⋅Softmax(DkKTQ) ,其中 Softmax 按列进行归一化
多头自注意力
在 M M M 个投影空间中分别应用自注意力模型,捕获不同的交互信息:
h e a d m = a t t ( ( K m , V m ) , Q m ) head_m=att((K_m,V_m),Q_m) headm=att((Km,Vm),Qm)
M u l t i h e a d ( X ) = W 0 [ h e a d 1 ; h e a d 2 ; . . . ; h e a d M ] ∈ R D x × N Multihead(X)=W_0[head_1;head_2;...;head_M]\in \R^{D_x\times N} Multihead(X)=W0[head1;head2;...;headM]∈RDx×N
其中 W 0 ∈ R D x × M D v W_0\in \R^{D_x\times MD_v} W0∈RDx×MDv 为输出投影矩阵
Transformer
Transformer 是一个基于注意力机制的 Seq2Seq 模型,其网络结构包括编码器和解码器。
Transformer 的完整结构图如下:
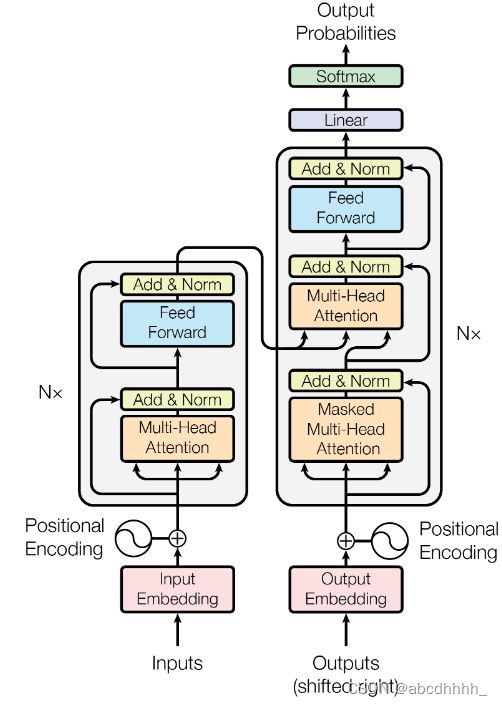
Encoder 部分主要由一层多头自注意力和一层前馈网络构成,而 Decoder 部分中间多插入了一层与 Encoder 之间的多头注意力。
各模块主要功能如下:
- Positional Encoding:位置编码,表示各个单词的相对位置关系。
- Multi-head Attention:多头注意力模型。
- Encoder 部分的是多头自注意力模型,获取每个词元和整句话的注意力关系
- Decoder 部分第一层是 Masked Multi-Head Attention ,查询每个词元和其位置之前所有词的 key 的注意力关系(后文信息遮盖 Mask )。
- Decoder 部分第二层,将前一层得到的注意力关系作为 query ,查询它们与 Encoder 句子中每个 key 的注意力关系
- Add & Norm: 利用 ResNet 和 Layer Norm 对数据进行处理,便于构建深层网络
- Feed Forward: 一个逐位置的前馈神经网络