Java专项练习题错题汇总
题目目录
- 1. GC垃圾回收机制
- 2. 多线程的start() 、run()
- 3. null是关键字,NULL不是关键字,NULL可以作标识符
- 4. list.remove()
- 5. JVM 内存五大区域
- 6. 关于byte变量运算
- 7. 关于interface主体内的属性
- 8. & 与 &&
- 9. `System.out.println(true ? false : true == true ? false : true);`
- 10. 建包
- 11. 字面量 和 变量
- 12. main
- 13. 数组下标
- 14. 异常
- 15. javac.exe等
- 16. 关于异常
- 17.ArrayList 的扩容问题
- 18. 关于try-catch-finally
- 19. File类
- 20.Java有5种方式来创建对象:
- 21. 代码块
-
- 22. try-catch 中的return
- 23. String final 相关
- 24. ASCII
- 25. 子类必须显示调用父类构造函数
- 26. 静态方法 & static
- 27. 实现线程间通知和唤醒
- 28. 实现GBK编码字节流到UTF-8编码字节流的转换:
- 29. 静态域
- 30. 数组复制相关
- 31.可以把任何一种数据类型的变量赋给Object类型的变量。
- 32. 继承
- 33. import java.util.*
- 34. 三元操作符类型的转换规则
- 35. 自己领悟
- 36. switch
- 37. HashMap与HashTable 、Map
- 38. 流
- 39.序列化
- 40. 事务的并发一致性问题
- 41. 锁
1. GC垃圾回收机制
错误:在Java中,对于不再使用的内存资源,如调用完成的方法,“垃圾回收器”会自动将其释放。( )
方法调用时,会创建栈帧在栈中,调用完是程序自动出栈释放,而不是gc释放。
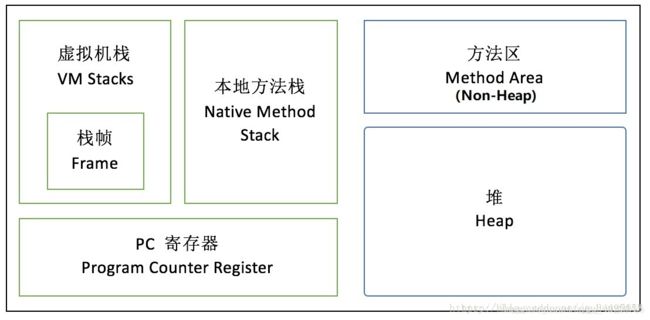
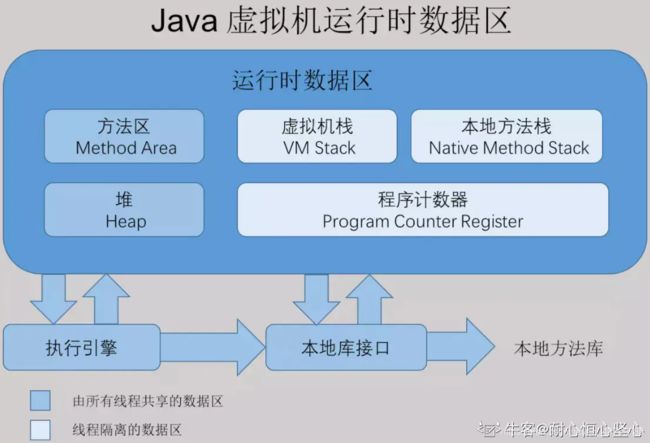
JVM 内存可简单分为三个区:
1、堆区(heap):用于存放所有对象,是线程共享的(注:数组也属于对象)
2、栈区(stack):用于存放基本数据类型的数据和对象的引用,是线程私有的(分为:虚拟机栈和本地方法栈)
3、方法区(method):用于存放类信息、常量、静态变量、编译后的字节码等,是线程共享的(也被称为非堆,即 None-Heap)
Java 的垃圾回收器(GC)主要针对堆区

1,新生代:(1)所有对象创建在新生代的Eden区,当Eden区满后触发新生代的Minor GC,将Eden区和非空闲Survivor区存活的对象复制到另外一个空闲的Survivor区中。(2)保证一个Survivor区是空的,新生代Minor GC就是在两个Survivor区之间相互复制存活对象,直到Survivor区满为止。
2,老年代:当Survivor区也满了之后就通过Minor GC将对象复制到老年代。老年代也满了的话,就将触发Full GC,针对整个堆(包括新生代、老年代、持久代)进行垃圾回收。
3,持久代:持久代如果满了,将触发Full GC。
2. 多线程的start() 、run()
public static void main(String args[]) {
Thread t = new Thread() {
public void run() {
pong();
}
};
t.run();
System.out.print("ping");
}
static void pong() {
System.out.print("pong");
}
输出 pongping
在第7行的时候,调用的是t.run();方法,之间调用run方法就是普通的方法调用而已,所以肯定是先执行pong()再执行System.out.print(“ping”);
如果第7行换成t.start()方法,答案就应该选择c,因为t.start()后,线程变为就绪状态,什么时候开始执行时不确定的,可能是主程序先继续执行,也可能是新线程先执行。
3. null是关键字,NULL不是关键字,NULL可以作标识符
4. list.remove()
如果一个list初始化为{5,3,1},执行以下代码后,其结果为()?[4, 3, 1, 6]
nums.add(6);
nums.add(0,4);
nums.remove(1);
nums.remove(1);删除索引为1 处的元素。
list有两个形式的remove(),一个是根据索引删除 list.remove(index),一个是根据存储对象的匹配度删除 list.remove(obj)。
假设num已经被创建为一个ArrayList对象,并且最初包含以下整数值:[0,0,4,2,5,0,3,0]。 执行下面的方法numQuest(),最终的输出结果是什么?
private List<Integer> nums;
//precondition: nums.size() > 0
//nums contains Integer objects
public void numQuest() {
int k = 0;
Integer zero = new Integer(0);
while (k < nums.size()) {
if (nums.get(k).equals(zero))
nums.remove(k);
k++;
}
}
[0, 4, 2, 5, 3]
注意这种方法的删除元素会导致下标变化,删除一个元素后,后面元素会调整位置。
5. JVM 内存五大区域
6. 关于byte变量运算
1. byte a1 = 2, a2 = 4, a3;
2. short s = 16;
3. a2 = s;
4. a3 = a1 * a2;
java中如果碰到char、byte和short参与运算时,会自动将这些值转换为int类型然后再进行运算。这里a1和a2就自动转为int类型了,结果也为Int类型。把一个int类型赋值给byte需要转型。
7. 关于interface主体内的属性
下面字段声明中哪一个在interface主体内是合法的? ()
private final static int answer = 42;
public static int answer = 42;
final static answer = 42;
int answer;
在接口中,属性都是默认public static final修饰的,所以:
A(错误):不能用private修饰;
B(正确):在接口中,属性默认public static final,这三个关键字可以省略;
C(错误):没写属性的类型;
D(错误):final修饰的属性必须赋值;
接口中属性不属于对象,属于类(接口),因为默认使用static修饰。
8. & 与 &&
&在逻辑运算中是非短路逻辑与,在位运算中是按位与
&& 逻辑运算:逻辑与
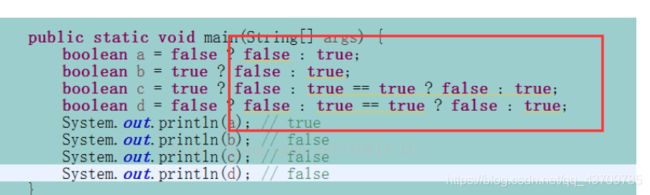
9. System.out.println(true ? false : true == true ? false : true);
输出false。
true == true ? false : true 为死代码(Dead Code)
我已经知道答案了,何必往后执行呢?
10. 建包
如果要建立一个java.scut.computer的包
只需在代码中加入“package java.scut.computer;”一个语句,并且必须放在代码的第一行
11. 字面量 和 变量
int i = -5;
i = ++(i++);
答案是 编译错误。
这题编译错误在于这一句: i = ++(i++);
++( ) 括号里面必须是一个变量,而 i ++ 是一个字面量。
12. main
JAVA程序中可以有多个名字为main方法。 正确。
java中可以有多个重载的main方法,只有public static void main(String[] args){}是函数入口
13. 数组下标
java语言中的数组元素下标总是从0开始,下标可以是整数或整型表达式,正确。
for(int i=0;i<10;i++){
a[i+1]=a[i]
}
这个i+1就是整数型表达式 。
14. 异常
捕获到的异常不仅可以在当前方法中处理,还可以将异常抛给调用它的上一级方法来处理。
编译时异常必须显示处理,运行时异常交给虚拟机。
运行时异常可以不处理。当出现这样的异常时,总是由虚拟机接管。比如我们从来没有人去处理过Null Pointer Exception异常,它就是运行时异常,并且这种异常还是最常见的异常之一。出现运行时异常后,系统会把异常一直往上层抛,一直遇到处理代码。如果没有处理块,到最上层,如果是多线程就由Thread.run()抛出,如果是单线程就被main()抛出。抛出之后,如果是线程,这个线程也就退出了。如果是主程序抛出的异常,整个程序也就退出了。运行时异常是Exception的子类,也有一般异常的特点,是可以被Catch块处理的。只不过往往不对它处理罢了。也就是说,如果不对运行时异常进行处理,那么出现运行时异常之后,要么是线程中止,要么是主程序终止。
15. javac.exe等
javac.exe是编译.java文件
java.exe是执行编译好的.class文件
javadoc.exe是生成Java说明文档
jdb.exe是Java调试器
javaprof.exe是剖析工具
16. 关于异常
checked exception:指的是编译时异常,该类异常需要本函数必须处理的,用try和catch处理,或者用throws抛出异常,然后交给调用者去处理异常。
runtime exception:指的是运行时异常,该类异常不必须本函数必须处理,当然也可以处理。
Thread.sleep() 和 Object.wait(),都可以抛出 InterruptedException。这个异常是不能忽略的,因为它是一个检查异常(checked exception)
17.ArrayList 的扩容问题
Arraylist默认数组大小是10,扩容后的大小是扩容前的1.5倍,
如果新创建的集合有带初始值,默认就是传入的大小,也就不会扩容
18. 关于try-catch-finally
- 只有try,报错。
- try-catch,正确。
- try-finally,正确。
- try-catch-finally,正确。
public void test() {
try {
throw new NullPointerException();
}finally {
}
}
19. File类
File类是对文件整体或者文件属性操作的类,例如创建文件、删除文件、查看文件是否存在等功能,不能操作文件内容;文件内容是用IO流操作的。
20.Java有5种方式来创建对象:
使用 new 关键字(最常用): ObjectName obj = new ObjectName();
使用反射的Class类的newInstance()方法: ObjectName obj = ObjectName.class.newInstance();
使用反射的Constructor类的newInstance()方法: ObjectName obj = ObjectName.class.getConstructor.newInstance();
使用对象克隆clone()方法: ObjectName obj = obj.clone();
使用反序列化(ObjectInputStream)的readObject()方法: try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(FILE_NAME))) { ObjectName obj = ois.readObject(); }
21. 代码块
public class B
{
public static B t1 = new B();
public static B t2 = new B();
{
System.out.println("构造块");
}
static
{
System.out.println("静态块");
}
public static void main(String[] args)
{
B t = new B();
}
}
构造块 构造块 静态块 构造块
22. try-catch 中的return
public boolean returnTest()
{
try
{
return true;
}
catch (Exception e)
{
}
finally
{
return false;
}
}
输出false
23. String final 相关
String StringBuffer 都是由final修饰。意味着不能继承。二者都是由字符数组实现,其中字符数组由final修饰,意味着不能修改。
String s = "asdf";
s = "qaz";
不能修改不意味着不能重新赋值。
24. ASCII
空格 32
字符 0 48
字母 a 97
字母 A 65
25. 子类必须显示调用父类构造函数
class Base{
public Base(String s){
System.out.print("B");
}
}
public class Derived extends Base{
public Derived (String s) {
System.out.print("D");
}
public static void main(String[] args){
new Derived("C");
}
}
26. 静态方法 & static
public class Test
{
public int x;
public static void main(String []args)
{
System. out. println("Value is" + x);
}
}
非静态变量不能够被静态方法引用
public class Test {
public int aMethod(){
static int i = 0;
i++;
return i;
}
public static void main(String args[]){
Test test = new Test();
test.aMethod();
int j = test.aMethod();
System.out.println(j);
}
}
编译错误,Java中静态变量只能在类主体中定义,不能在方法中定义。 静态变量属于类所有而不属于方法。
27. 实现线程间通知和唤醒
Object.wait/notify/notifyAll是 Object类 中的方法
Condition.await/signal/signalAll ;Condition是在java 1.5中才出现的,它用来替代传统的Object的wait()、notify()实现线程间的协作,相比使用Object的wait()、notify(),使用Condition的await()、signal()这种方式实现线程间协作更加安全和高效。
28. 实现GBK编码字节流到UTF-8编码字节流的转换:
操作步骤就是先解码再编码
用new String(src,“GBK”)解码得到字符串
用getBytes(“UTF-8”)得到UTF8编码字节数组
byte[] src,dst;
dst=new String(src,“GBK”).getBytes(“UTF-8”)
29. 静态域
public class B
{
public static B t1 = new B();
public static B t2 = new B();
{
System.out.println("构造块");
}
static
{
System.out.println("静态块");
}
public static void main(String[] args)
{
B t = new B();
}
}
输出:构造块 构造块 静态块 构造块
并不是静态块最先初始化,而是静态域.(BM:啊!多么痛的领悟!)
而静态域中包含静态变量、静态块和静态方法,其中需要初始化的是静态变量和静态块.而他们两个的初始化顺序是靠他们俩的位置决定的!
So!
初始化顺序是 t1 t2 静态块
30. 数组复制相关
java语言的下面几种数组复制方法中,哪个效率最高?
总结:
(1)从速度上看:System.arraycopy > clone > Arrays.copyOf > for
(2)for的速度之所以最慢是因为下标表示法每次都从起点开始寻位到指定下标处(现代编译器应该对其有进行优化,改为指针),另外就是它每一次循环都要判断一次是否达到数组最大长度和进行一次额外的记录下标值的加法运算。
(3)查看Arrays.copyOf的源码可以发现,它其实本质上是调用了System.arraycopy。之所以时间差距比较大,是因为很大一部分开销全花在了Math.min函数上了。
简略说说吧:
System.arraycopy():native方法+JVM手写函数,在JVM里预写好速度最快
clone():native方法,但并未手写,需要JNI转换,速度其次
Arrays.copyof():本质是调用1的方法
for():全是深复制,并且不是封装方法,最慢情有可原
31.可以把任何一种数据类型的变量赋给Object类型的变量。
还是老话,Java中一切都是对象,Object是所有类的根类!
32. 继承
public class Demo {
class Super {
int flag = 1;
Super() {
test();
}
void test() {
System.out.println("Super.test() flag=" + flag);
}
}
class Sub extends Super {
Sub(int i) {
flag = i;
System.out.println("Sub.Sub()flag=" + flag);
}
void test() {
System.out.println("Sub.test()flag=" + flag);
}
}
public static void main(String[] args) {
new Demo().new Sub(5);
}
}
输出:
Sub.test() flag=1
Sub.Sub() flag=5
33. import java.util.*
能访问java/util目录下的所有类,不能访问java/util子目录下的所有类
34. 三元操作符类型的转换规则
1.若两个操作数不可转换,则不做转换,返回值为Object类型
2.若两个操作数是明确类型的表达式(比如变量),则按照正常的二进制数字来转换,int类型转换为long类型,long类型转换为float类型等。
3.若两个操作数中有一个是数字S,另外一个是表达式,且其类型标示为T,那么,若数字S在T的范围内,则转换为T类型;若S超出了T类型的范围,则T转换为S类型。
4.若两个操作数都是直接量数字,则返回值类型为范围较大者
Object a = true ? new Boolean(false) : new Character('1').getClass(); // java.lang.Boolean
Object b = true ? new Byte((byte) 1) : new Character('1'); // java.lang.Integer
Object c = true ? new Byte((byte) 1) : new Short((short) 1); // java.lang.Short
byte b = 1;
char c = 1;
short s = 1;
int i = 1;
// 三目,一边为byte另一边为char,结果为int
// 其它情况结果为两边中范围大的。适用包装类型
i = true ? b : c; // int
b = true ? b : b; // byte
s = true ? b : s; // short
// 表达式,两边为byte,short,char,结果为int型
// 其它情况结果为两边中范围大的。适用包装类型
i = b + c; // int
i = b + b; // int
i = b + s; // int
// 当 a 为基本数据类型时,a += b,相当于 a = (a) (a + b)
// 当 a 为包装类型时, a += b 就是 a = a + b
b += s; // 没问题
c += i; // 没问题
// 常量任君搞,long以上不能越
b = (char) 1 + (short) 1 + (int) 1; // 没问题
// i = (long) 1 // 错误
35. 自己领悟

36. switch
switch语句后的控制表达式只能是short、char、int整数类型和枚举类型,不能是long、float,double和boolean类型。String类型是java7开始支持。
a、基本类型byte char short 原因:这些基本数字类型可自动向上转为int, 实际还是用的int。
b、基本类型包装类Byte,Short,Character,Integer 原因:java的自动拆箱机制 可看这些对象自动转为基本类型
c、String 类型 原因:实际switch比较的string.hashCode值,它是一个int类型
d、enum类型 原因 :实际比较的是enum的ordinal值(表示枚举值的顺序),它也是一个int类型 所以也可以说 switch语句只支持int类型
37. HashMap与HashTable 、Map
HashMap实现Map接口,它允许任何类型的键和值对象,并允许将NULL用作键或值。
Hashtable中,Key和Value都不能是null。
Hashtable:
(1)Hashtable 是一个哈希表,它存储的内容是键值对(key-value)映射。
(2)Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。
(3)HashTable直接使用对象的hashCode。
HashMap:
(1)由数组+链表组成的,基于哈希表的Map实现,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的。
(2)不是线程安全的,HashMap可以接受为null的键(key)和值(value)。 null 可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为 null
(3)HashMap重新计算hash值
(4)HashMap的实例有俩个参数影响其性能: “初始容量” 和 装填因子
(5)HashMap中的key-value都是存储在Entry中的
(6)HashMap是采用拉链法解决哈希冲突的
HashTable中hash数组默认大小是11,增加的方式是old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数
Hashtable,HashMap,Properties继承关系如下:
public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable
public class HashMap<K,V>extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
Properties 类 继承了 Hashtable 类,而 Hashtable 类则继承Dictionary 类
TreeMap通过红黑树实现Map接口的类,key不可以为null,会报NullPointerException异常,value可以为null。


38. 流
按照流是否直接与特定的地方(如磁盘、内存、设备等)相连,分为节点流和处理流两类。
节点流:可以从或向一个特定的地方(节点)读写数据。如FileReader.
处理流:是对一个已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写。如BufferedReader.处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接。
JAVA常用的节点流:
文 件 FileInputStream FileOutputStrean FileReader FileWriter 文件进行处理的节点流。
字符串 StringReader StringWriter 对字符串进行处理的节点流。
数 组 ByteArrayInputStream ByteArrayOutputStreamCharArrayReader CharArrayWriter 对数组进行处理的节点流(对应的不再是文件,而是内存中的一个数组)。
管 道 PipedInputStream PipedOutputStream PipedReaderPipedWriter对管道进行处理的节点流。
常用处理流(关闭处理流使用关闭里面的节点流)
缓冲流:BufferedInputStrean BufferedOutputStream BufferedReader BufferedWriter 增加缓冲功能,避免频繁读写硬盘。
转换流:InputStreamReader OutputStreamReader 实现字节流和字符流之间的转换。
数据流 DataInputStream DataOutputStream 等-提供将基础数据类型写入到文件中,或者读取出来.
流的关闭顺序
一般情况下是:先打开的后关闭,后打开的先关闭
另一种情况:看依赖关系,如果流a依赖流b,应该先关闭流a,再关闭流b。例如,处理流a依赖节点流b,应该先关闭处理流a,再关闭节点流b
可以只关闭处理流,不用关闭节点流。处理流关闭的时候,会调用其处理的节点流的关闭方法。
39.序列化
public class DataObject implements Serializable{
private static int i=0;
private String word=" ";
public void setWord(String word){
this.word=word;
}
public void setI(int i){
Data0bject. i=I;
}
}
DataObject object=new Data0bject ( );
object. setWord(“123”);
object. setI(2);
将此对象序列化为文件,并在另外一个JVM中读取文件,进行反序列化,请问此时读出的Data0bject对象中的word和i的值分别为:
“123”, 0
序列化保存的是对象的状态,静态变量属于类的状态,因此,序列化并不保存静态变量。所以i是没有改变的。
Java在序列化时不会实例化static变量和transient修饰的变量,因为static代表类的成员,transient代表对象的临时数据,被声明这两种类型的数据成员不能被序列化
40. 事务的并发一致性问题
不可重复读、脏读、幻读、丢失修改
LeetBook
41. 锁
上面链接也有