大数据之Hive
文章目录
- Hive的基本了解
-
- 1.什么是Hive
- 2.为什么要使用Hive
- 3.Hive的特点
- 4.Hive架构图
- 5.Hive与Hadoop的关系
- Hive的安装部署
-
- 1.derby版hive直接使用
- 2.基于mysql管理元数据版hive
- 外部表
-
-
-
-
- 操作案例
-
-
-
Hive的基本了解
1.什么是Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能(HQL)。
2.为什么要使用Hive
-
操作接口采用类SQL语法,提供快速开发的能力。
-
避免了去写MapReduce,减少开发人员的学习成本。
-
功能扩展很方便。
3.Hive的特点
-
可扩展
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
-
延展性
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
-
容错
良好的容错性,节点出现问题SQL仍可完成执行。
4.Hive架构图
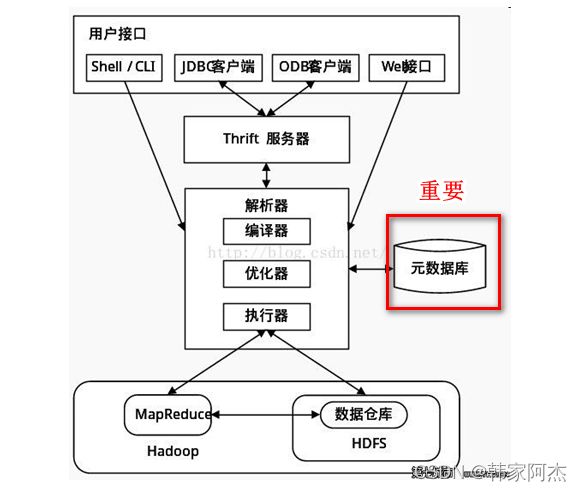
5.Hive与Hadoop的关系
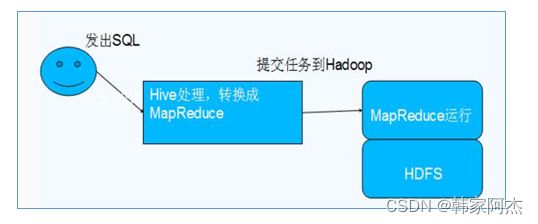
Hive利用HDFS存储数据,利用MapReduce查询分析数据
Hive的安装部署
1.derby版hive直接使用
前提:Hive安装非常简单,解压之后即可直接运行,不需要太多配置,前提是要配置JAVA_HOME和HADOOP_HOME。并且Hadoop要全量启动(五个进程)
- 解压hive
cd /opt/softwares
tar -xvzf apache-hive-2.3.6-bin.tar.gz -C ../servers/
- 修改目录名称
cd ../servers/
mv apache-hive-2.3.6-bin hive-2.3.6
- 初始化元数据库
cd hive-2.3.6
bin/schematool -dbType derby -initSchema
- 启动
在hive-2.3.6目录下执行
bin/hive
- 创建数据库
create database jtdb;
- 创建表
use jtdb;
create table tb_user(id int,name string);
- 插入数据
insert into table tb_user values(1,"zhangfei");
2.基于mysql管理元数据版hive
- 解压hive
cd /opt/softwares
tar -xvzf apache-hive-2.3.6-bin.tar.gz -C ../servers/
- 修改目录名称
cd ../servers/
mv apache-hive-2.3.6-bin hive-2.3.6
- 检测服务器mysql数据库
mysql
show databases;
- 配置mysql允许外网访问
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
flush privileges;
- 修改配置文件hive-site.xml
创建hive-site.xml
vim hive-site.xml
在hive-site.xml这个文件中添加
<configuration>
<property>
<name>hive.default.fileformatname>
<value>TextFilevalue>
property>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=truevalue>
<description>JDBC connect string for a JDBC metastoredescription>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
<description>Driver class name for a JDBC metastoredescription>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
<description>username to use against metastore databasedescription>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>rootvalue>
<description>password to use against metastore databasedescription>
property>
configuration>
- 上传mysql驱动
将资料中mysql-connector-java-5.1.38-bin.jar上传到hive的lib目录中。 - 初始化
bin/schematool -dbType mysql -initSchema
- 创建表并指定字段之间的分隔符
create table if not exists stu(id int ,name string) row format delimited fields terminated by '\t' stored as textfile location '/user/stu';
外部表
外部表因为是指定其他的hdfs路径的数据加载到表当中来,所以hive表会认为自己不完全独占这份数据,所以删除hive表的时候,数据仍然存放在hdfs当中,不会删掉。
内部表:当删除表的时候,表结构和表数据全部都会删除掉。
外部表:当删除表的时候,认为表的数据会被其他人使用,自己没有独享数据的权利,所以只会删除掉表的结构(元数据),不会删除表的数据。
操作案例
分别创建老师与学生表外部表,并向表中加载数据
创建老师表:
create external table teacher (t_id string,t_name string) row format delimited fields terminated by '\t';
创建学生表:
create external table student (s_id string,s_name string,s_birth string , s_sex string ) row format delimited fields terminated by '\t';
从本地文件系统向表中加载数据:
load data local inpath '/opt/data/hivedatas/student.csv' into table student;