一个pandas和excel、csv高效IO增强库—pandasrw
目录
- 安装与代码
- 一、常用API
-
- 1、加载表
- 2、写入表
- 3、流式加载表
- 4、将csv转化为utf8编码
- 5、将xlsx转换为csv
- 二、功能特点
-
- 1、性能提升
- 2、易用性提升
- 3、大内存表的流式加载和计算
- 三、pickle支持和使用
这个库是本人发布在github的一个项目,欢迎大家交流,方便的时候的给个star。pandasrw的名称是pandas read和write的缩写,目前支持excel、csv和pickle文件的读写。
pandas的读写excel和csv一直偏慢且存在易用性问题,特别是对于大文件的读写,瓶颈非常明显。pandasrw 库通过将各类库进一步封装,提高了pandas 读写excel、csv等文件的性能和易用性。
安装与代码
安装
通过pip进行安装
pip install pandasrw
代码
这个库是本人在github写的一个项目,欢迎大家交流。请各位方便的时候的给个star。
https://github.com/stormtozero/pandasrw
一、常用API
1、加载表
df=load(file_path, col_name=None,sheetname='Sheet1',engine="polars")
示例:输入路径读取Sheet1表的全部列,生产pandas的DataFrame 默认使用polars引擎。该表可以是xlsx、xlsx、csv和pkl格式
df=load(file_path)
2、写入表
dump(df,file_path,sheetname='Sheet1',engine="polars")
示例:输入路径,将pandas的DataFrame写入Sheet1表,默认使用polars引擎。该表可以是xlsx、xlsx、csv和pkl格式
dump(df,file_path)
3、流式加载表
file_path是路径, row_count是没错读取的行
load_stream_row(file_path, row_count,col_name=None)
生成一个pandas.io.parsers.readers.TextFileReader对象
对于该迭代器对象,通过遍历迭代器分块运算
3.1、遍历迭代器
3.2、对于迭代器中的每个DataFrame进行运算
3.3、采用追加写(功能mode="a"或者mode=“a+”)的方式写入csv。
注意:file_result_csv和上文函数中的file_path_csv绝对不能相同,即读取的csv和存入的csv不能同路径。否则会不停的迭代下去,不能退出循环。
原因:使用chunksize分块读取后,pandas并没有真正的将csv的内容加载入内存,只是解析了csv的内容和建立了连接(类似浅拷贝),在调用迭代器时再从csv中加载。所以再使用追加写的时候,会一边写入csv,一边再从csv中读取,形成死循环。
for df in df_iter:
df=运算结果
df.to_csv(file_result_csv,mode="a", index=False,encoding='UTF-8',header=False)
示例3:输入路径读取Sheet1表的全部列,生产pandas的DataFrame 默认使用polars引擎。该表可以是xlsx、xlsx、csv和pkl格式
df_iter=load_stream_row(file_path, row_count)
4、将csv转化为utf8编码
encode_to_utf8(filename, des_encode):
5、将xlsx转换为csv
会在file_path文件夹下生成一个同名csv文件。
xlsxtocsv(file_path)
二、功能特点
1、性能提升
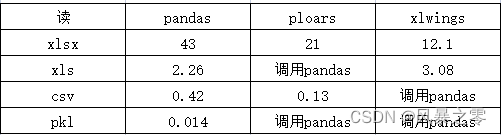
通过封装polars、pandas、xlwings库实现性能的提升和保证兼容性。通过参数engine来选择采用的读写引擎,默认采用polars库。对于polars和xlwings不支持的格式后端自动选择pandas进行兼容。各类引擎的特点如下。
polars库:
一个rust写的高性能库。读写快,支持xlsx和csv文件类型,其中xlsx为通过xlsx2csv库转换为csv来实现。兼容性较好,但是不如pandas。xlsx可以比pandas快2倍,csv可以快3倍.
建议:推荐使用。截至2023年3月该库的star已经超过1.3k,性能和质量已经经过检验。
pandas库:
支持xlsx、xls、csv、pkl四种文件类型,读写较慢,但是兼容性最好。
建议:备选。
xlwings库:
支持xlsx和xls两种文件类型,该库本身支持csv,但是在测试时性能较差未采用。
读写xlsx文件速度最快,可以达到pandas的3倍,但是在数据类型推断上较为粗糙,数据类型只能区分为object和float64两种类型,不能进一步区分int64等类型。本库通过调用 win32实现对excel的操作,需要使用windows操作协同且安装了excel软件。
建议:在excel数据较大一般超过100M时使用,且对细分数据类型不敏感或者采用手动修改数据类型的场景。

2、易用性提升
易用性方面主要做了以下二个方面的提升
2.1、对csv格式的编码自动修改为utf-8解决了 “‘utf-8’ codec can’t decode”等编码类报错。
2.2、对各类后缀进行了自适应,无需在手动指定excel、csv、pickle等
3、大内存表的流式加载和计算
为了API的简洁暂时只实现了一个sheet的表格的流式加载和计算
三、pickle支持和使用
如果一个较大的表会多次使用,请转pickle存储,后续读写pickle文件会大大加快读写性能。