数据库基础(MySQL+Oracle)
数据库基础(MySQL+Oracle)
文章目录
- 数据库基础(MySQL+Oracle)
- 数据库概念
-
- 1 .什么是数据库?
- 2 .为什么要存储数据?
- 为什么要用数据库
- 数据库类型
- OLTP&OLAP
- NewSQL
- 云数据库
- 阿里云RDS
- 国产数据库
- 数据库演进
- MySQL
- MariaDB and Percona
- 备份还原
-
- Oracle备份
- MySQL备份
- 远程访问
- 数据库对象
- Oracle
-
- 配置监听
- 进入数据库
- 体系结构
- 逻辑存储结构
- 物理存储结构
- 用户权限
- 创建账号+授权(删除+回收)
- 表空间操作
- MySQL
-
- 基本命令
-
- 设置密码:
- 修改远程登录密码:
- 创建账号:
- 授权:
- 体系结构
- 执行过程
- InnoDB存储引擎
-
- InnoDB缓冲池
- InnoDB后台进程
- InnoDB文件体系
- InnoDB日志体系
- InnoDB存储结构
- 初始数据库
- 用户权限
- 创建账号+授权(回收+删除)
- 数据库操作
- SQL语言
-
- 定义
- 字符编码
- 常用数据类型
- 数据类型
-
- Oracle数据类型
- MySQL数据类型
- 表操作
- 列操作
- 约束
-
- 主键
- 外键(性能差,基本不用)
- 非空约束
- 唯一约束
- 默认约束
- 索引
- 事务
-
- 概念
- 事务控制命令
- 查询
-
- 数据表简介
- 简单查询&高级查询
-
- 去重distinct
- 排序order by(默认升序)
- where等值查询
- null值
- 分页查询
-
- MySQL
- oracle
- IN、NOT操作符
- Like模糊查询
- 计算字段
-
- 拼接字段
- 别名
- 聚合函数
- 分组排序group by
- 分组过滤Having
- 分组排序+语句顺序
- 子查询
- 关联查询
-
- inner join
- left outer join
- right outer join
- full outer join
- 笛卡尔积
- 表起别名
- SQL JOINS
- Union组合查询
- 插入
- 更新
- 删除
-
- Drop & Truncate & Delete
- 注意点
- 视图
- 触发器
-
- 触发器用途
- 触发器语法
-
- MySQL下
- 注意点
- 序列
-
- MySQL自增
- Oracle序列
- 常用命令
-
- MySQL
- Oralcle
- 系统函数
-
- 1.数学函数
-
- MySQL
- 2.聚合函数
- 3.字符串函数
-
- MySQL
- 4.时间日期函数
-
- MySQL
- 5.流程函数
-
- MySQL
- if流程控制:
- case流程控制:
- while流程控制:
- Oracle和MySQL的函数差异
- 自定函数
-
- MySQL
-
- 语法
- Oracle
- 区别
- 存储过程
-
- 语法
- 游标
- 小结
数据库概念
1 .什么是数据库?
将信息(数据)按照计算机可识别的方式规则存放在磁盘库中,并提供一系列可供读写的方式。相比较于磁盘,数据库最大
的特点是提供了非常灵活的接口,可以获取完整数据或者特定部分数据的方式(SQL) , 并提供一套完整管理数据的方法 (存储
结构,备份恢复等)。
2 .为什么要存储数据?
第一:数据要被随时随地反复使用,不是一次性消耗品。
第二:数据要被记录,防止遗忘。
为什么要用数据库

数据库类型

OLTP&OLAP

NewSQL

云数据库

阿里云RDS
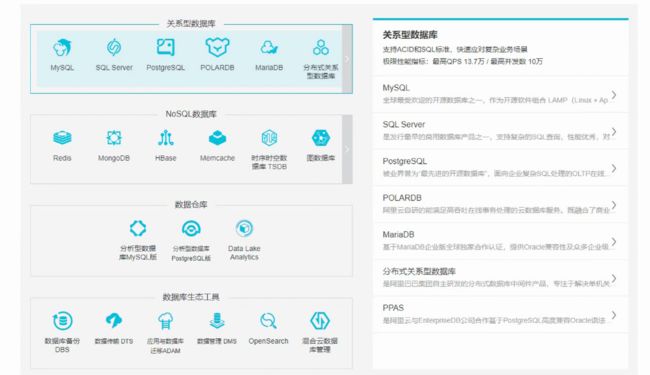
国产数据库

数据库演进

MySQL


MariaDB and Percona

备份还原

Oracle备份

查看帮助
expdp -help
备份
expdp epoint/Gepoint directory=dump dumpfile=epoint.dmp schemas=epoint logfile=epoint_expdp.log
还原
impdp epoint/Gepoint directory=dump dumpfile=EPOINT.DMP remap_schema=epoint:epoint remap_tablespace=epoint:epoint logfile=epoint_impdp.log
MySQL备份

备份(导出)
mysqldump -uroot -pGepoint --single-transaction -ER --master-data=2 --set-gtid-purged=off epoint >e:/backup/epoint.sql
还原(导入)
>mysql -uroot -pGepoint epoint < e:/backup/epoint.sql
远程访问
 ’
’
数据库对象






Oracle
dbca–创建数据库
创建表空间:
CREATE tablespace epoint datafile 'E:\app\Soul\oradata\orcl\epoint.dbf' SIZE 100M autoextend ON NEXT 50m;
创建账号:
CREATE USER epoint IDENTIFIED BY Gepoint DEFAULT tablespace epoint ;
授权:
GRANT dba TO epoint;
配置监听
sqlplus / as sysdba–登录数据库(或者sqlplus system/密码 来登录)
数据库实例:建议手动启动

netca–配置监听(可以远程登录)
![]()
lsnrctl status–查看监听程序的状态

进入数据库
alter system register;–注册一下远程登录
select status from v$instance;–查看实例状态
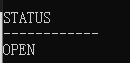
select * from v$database;

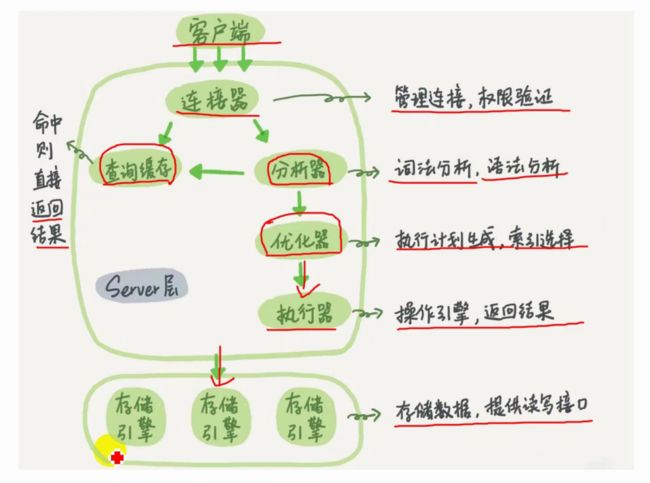
体系结构
数据库实例是数据库启动时初始化的一组后台进程和内存结构,我们的数据库就是依赖于实例完成各项工作。
而数据库文件包括了-系列参数文件、日志文件、数据文件等物理文件,通常存放在磁盘中。
理解了以上概念,我们再来看下数据库的完整定义:
数据库实例+数据库文件=一个完整的数据库




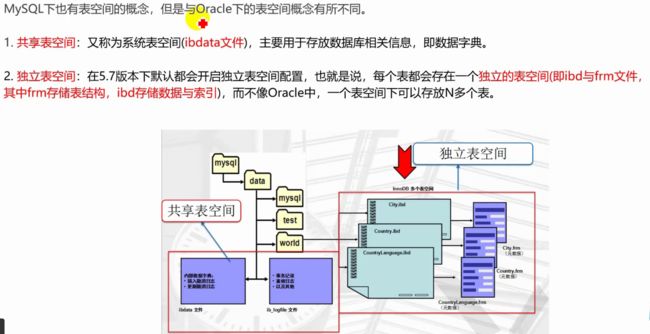
文件体系

逻辑存储结构

物理存储结构
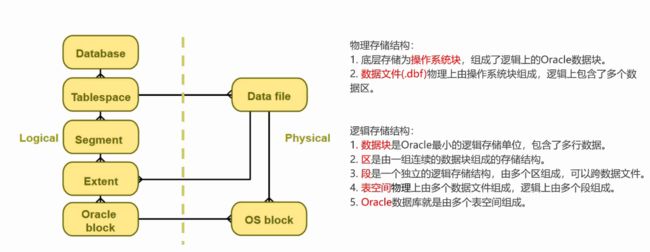
数据文件

输入命令:
select tablespace_name from dba_tablespaces;
可以查看oracle的表空间


注意:一般项目都是一个新的用户对应一个新的表空间
创建表空间:
CREATE tablespace epoint datafile 'E:\app\Soul\oradata\orcl\epoint.dbf' SIZE 100M autoextend ON NEXT 50m;
删除表空间:
drop tablespace epoint including contents and datafiles
用户权限

以sqlplus / as sysdba登录是以sys账号登录
关闭数据库实例:shutdown immediate;
开启数据库实例:startup;
创建账号+授权(删除+回收)

--创建test账号
CREATE USER test IDENTIFIED BY Gepoint DEFAULT tablespace epoint;
--赋予dba权限
GRANT dba TO test;
--移除dba权限
REVOKE dba FROM test;
--删除text账号
DROP USER test CASCADE;
--查询用户权限(dba账号查所有,普通用户查自己)
SELECT * FROM dba_role_privs;
SELECT * FROM user_role_privs;
--查看所有用户信息
SELECT * FROM dba_users;
表空间操作


--查看所有表空间
SELECT * FROM DBA_TABLESPACES;
--创建表空间test,初始大小为10m,开启自动扩展,每次扩展10m,最大10G
CREATE tablespace test datafile 'E:\app\Soul\oradata\orcl\test_01.dbf' SIZE 10M autoextend ON NEXT 10m maxsize 10G;
--修改表空间,初始大小为20m,不开启自动扩展。
ALTER tablespace test ADD datafile 'E:\app\Soul\oradata\orcl\test_02.dbf' SIZE 20M autoextend off;
--初始大小为30m,开启自动扩展,每次扩展10m,不限制大小
ALTER tablespace test ADD datafile 'E:\app\Soul\oradata\orcl\test_03.dbf' SIZE 30M autoextend ON maxsize unlimited;
--删除表空间test
DROP tablespace test INCLUDING contents AND datafiles;
--查看数据文件
select * from dba_data_files;
自动扩展的是oracle块,每个块的大小是8k
MySQL
基本命令
设置密码:
set password for root@localhost = ‘Gepoint’;
修改远程登录密码:
set password for root@'%' = ‘Gepoint’;
创建账号:
create user 'epoint'@'host' IDENTIFIED BY 'Gepoint';
授权:
GRANT ALL ON *.* TO 'epoint'@'host';
体系结构
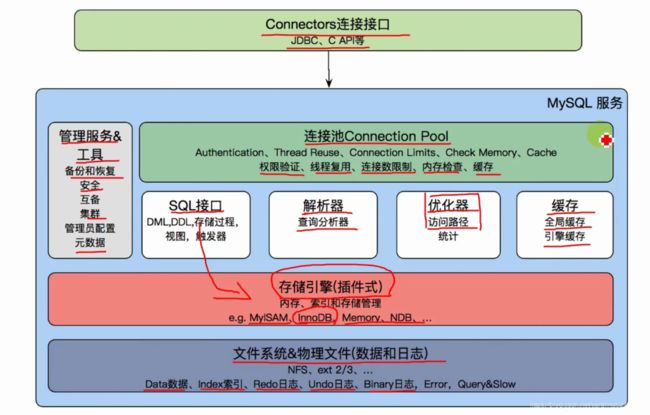
执行过程
InnoDB存储引擎
MySQL是多进程的
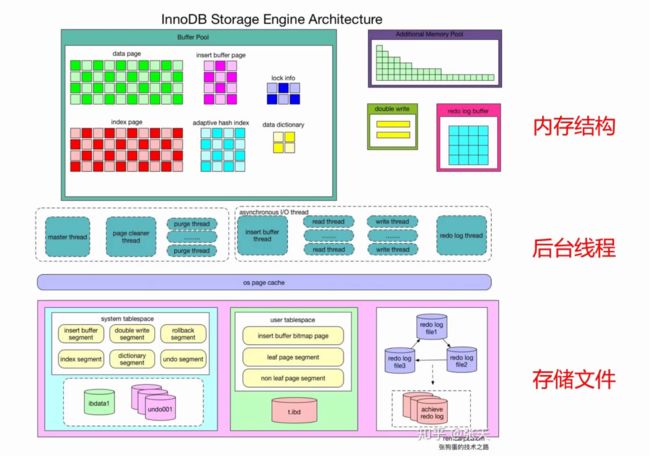
InnoDB缓冲池

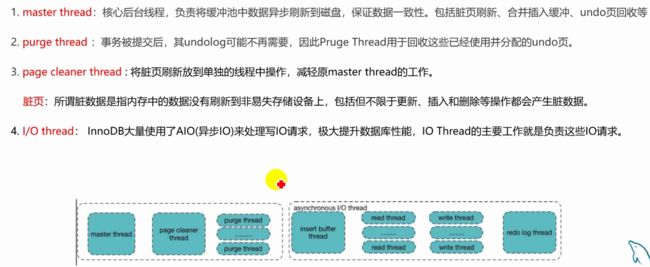
InnoDB后台进程
InnoDB文件体系
InnoDB日志体系
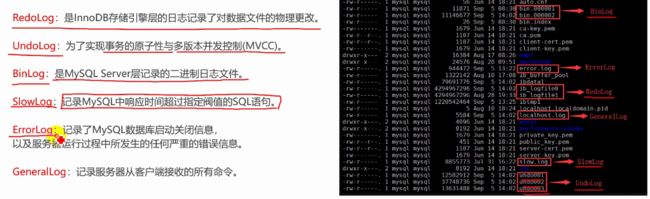
GeneralLog开销很大,在排查某些问题的时候暂时开启
SlowLog为了优化某些SQL暂时开启
InnoDB存储结构

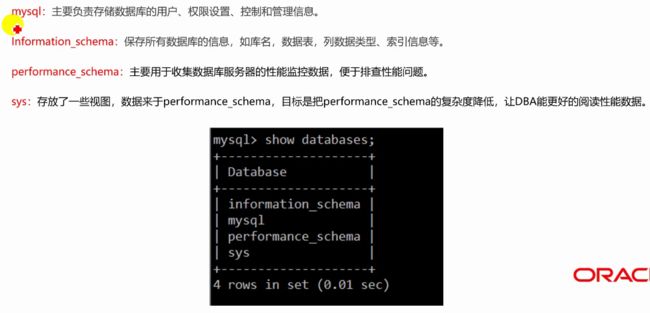
初始数据库
用户权限
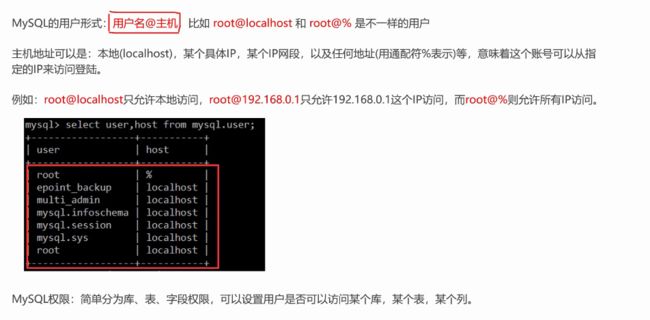
创建账号+授权(回收+删除)

-- 创建账号test
create user test@'%' identified by 'Gepoint';
-- 授权test
grant all privileges on *.* to test@'%';
-- 刷新到内存
flush privileges;
-- 查看账号权限
show grants for test@'%';
-- 回收权限
revoke all privileges on *.* from test@'%';
-- 删除账号
drop user test@'%';
数据库操作

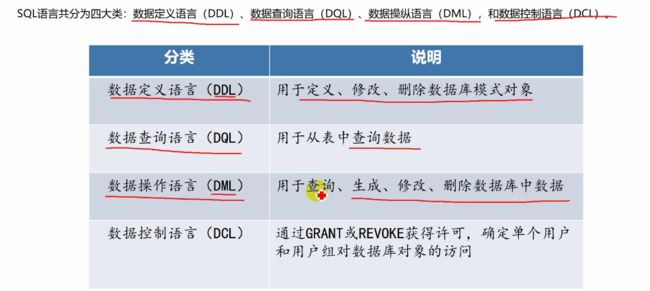
SQL语言
定义

分类
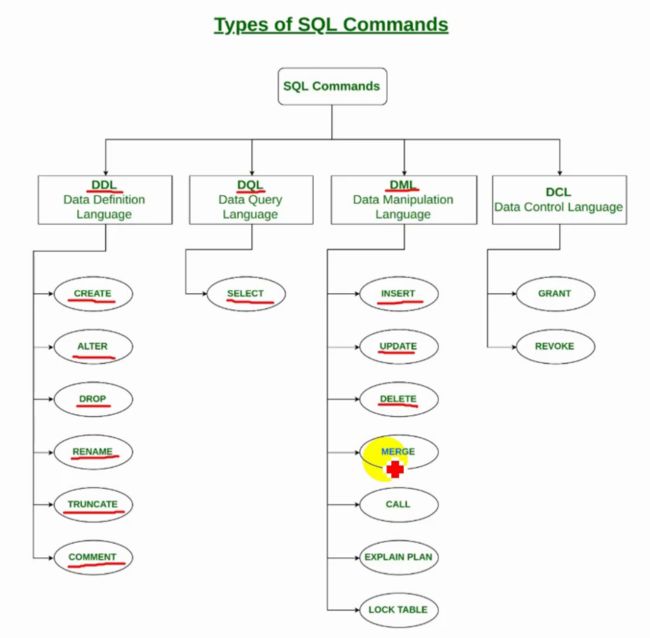
字符编码

定长与变长

常用数据类型
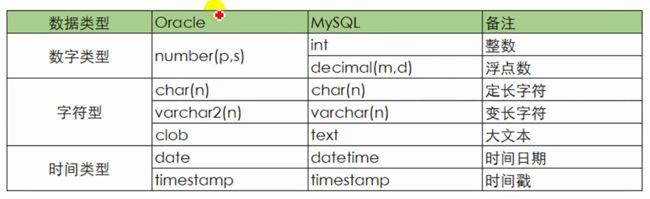
数据类型
Oracle数据类型
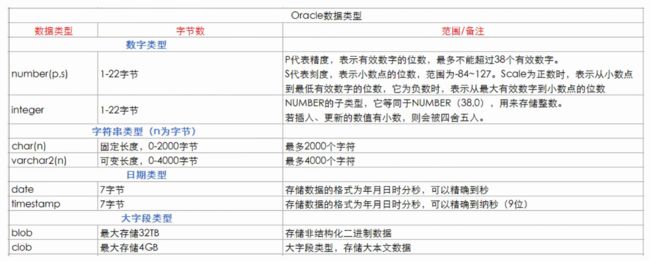

MySQL数据类型

浮点型说明

字符串常见问题

表操作

MySQL
drop table a;
create table a(
`id` int(11),
`name` varchar(255)
)
insert into a values(1,'tom')
select * from a;
-- 截断表,删除表中所有数据
truncate table a;
-- 重命名表
rename table a to aa;
select * from aa;
drop table aa;
列操作
MySQL
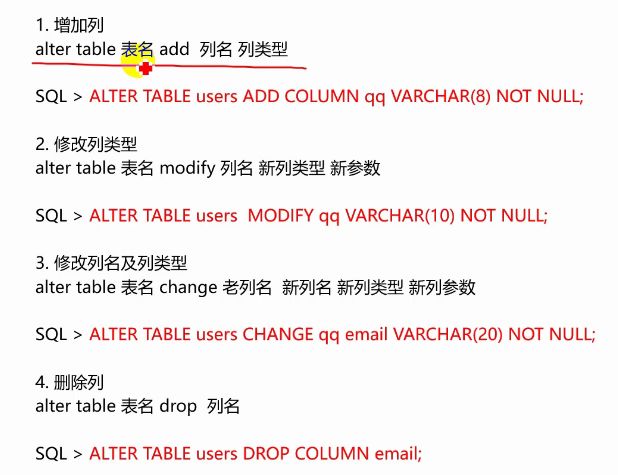
select * from b;
-- 增加列
alter table b add column qq varchar(8) not null;
-- 修改列类型
alter table b modify qq varchar(20) not null;
-- 修改列名
alter table b change qq email varchar(30) not null;
-- 删除列
alter table b drop column email;
约束

主键

外键(性能差,基本不用)
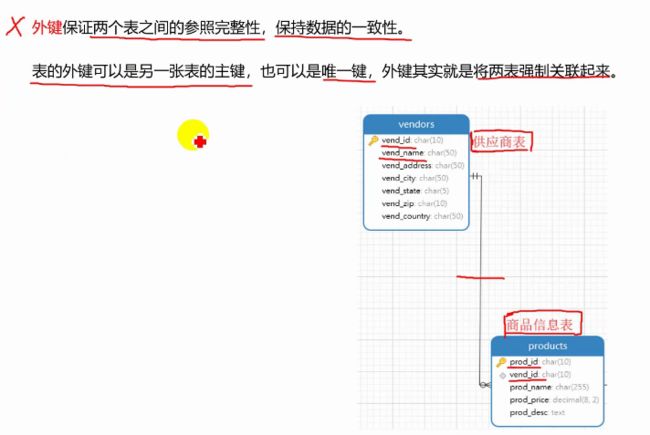
非空约束

唯一约束

默认约束

索引

CREATE INDEX test_id_IDX USING BTREE ON epoint.test (id,address);
事务
概念

举例

事务控制命令
数据没有提交之前,其他人看不见
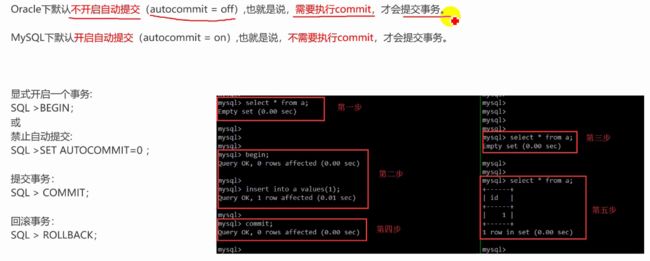

查询
数据表简介



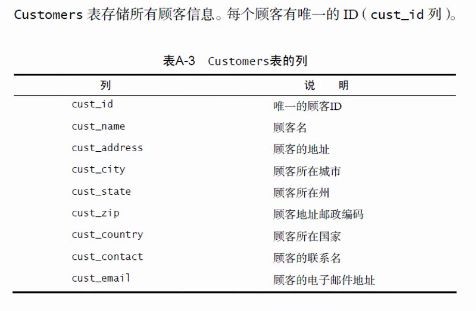



简单查询&高级查询

去重distinct
单列:select distinct vend_id from products p2 ;
多列:select distinct vend_id,prod_price from products p2 ;
注意:不能部分使用DISTINCT
DISTINCT关键字作用于所有的列,不仅仅是跟在其后的那一列。例如,你指定SELECT DISTINCT vend_ id, prod_ price, 除非指定的两列完全相同,否则所有的行都会被检索出来。
排序order by(默认升序)
select prod_name from products p order by prod_name ;
降序desc 升序(默认,可以不写)asc
多列排序

where等值查询
where:条件筛选,多表连接,组合查询and,or(SQL在处理OR操作符前,优先处理AND操作符)
连接符:
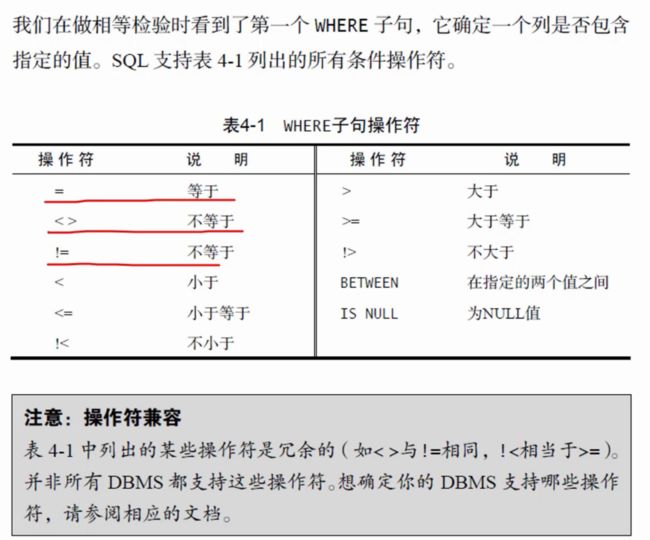
null值

分页查询
MySQL
limit 起始条数,每页条数:
公式:limit (page-1)*n,n
第二页,每页5条:select * from products p limit 5,5;
排序+查询
select * from products p order by p.prod_price desc limit 3,3;
oracle
分步:
- 先对表进行排序,保留需要字段
- 在为排过序的数据添加上ROWNUM字段
rownum--每一张表都有的字段,平时不展示,存储每一条记录的行号
-
最后一次select为ROWNUM指定范围
p a g e s i z e ∗ ( p a g e n u m − 1 ) p a g e n u m ∗ p a g e s i z e pagesize*(pagenum-1)~pagenum*pagesize pagesize∗(pagenum−1) pagenum∗pagesize
取出前5条数据:
SELECT * FROM PRODUCTS p WHERE rownum<=5;
排序+查询
公式:
1.排序
2.标rownum,起别名
3.根据别名筛选
自己定:每页条数pagesize
第几页:请求页数,pagenum使用者传递过来
select * from(select a.*,rownum rn
from
(select 语句 order by 排序字段)a)b
where b.rn>pagesize*(pagenum-1) and
b.rn<=pagenum*pagesize
举例:查询4~6的数据
SELECT * FROM (SELECT a.*,rownum rn FROM (SELECT * FROM PRODUCTS p ORDER BY PROD_PRICE DESC)a)b WHERE b.rn>3 AND b.rn<=6;
IN、NOT操作符


Like模糊查询

计算字段

拼接字段

别名
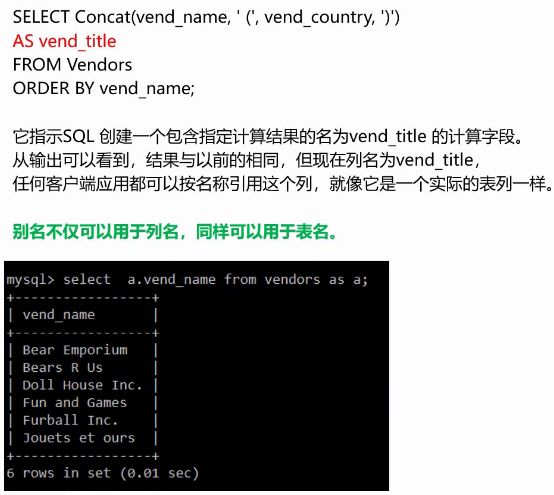
聚合函数

分组排序group by

分组过滤Having

分组排序+语句顺序

子查询

过滤

输出

关联查询

inner join

left outer join

right outer join

full outer join

笛卡尔积
没有筛选条件或者连接条件会出现笛卡尔积

表起别名

SQL JOINS
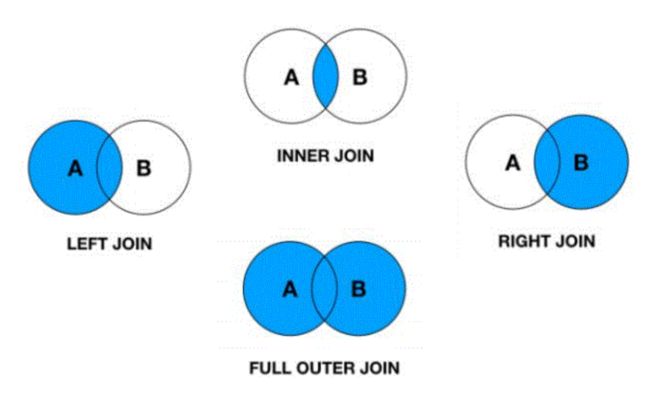
Union组合查询
UNION会去重

UNION ALL不会去重

插入
插入有几种方式:
- 插入完整的行;
- 插入行的一-部分;
- 插入某些查询的结果。
--新增1行顾客信息:
INSERT INTO Customers VALUES('1000000006', 'Toy Land','123 Any Street', 'New York','NY', '11111','USA', NULL,NULL);
--新增一行顾客信息(部分列):
INSERT INTO Customers(cust_id,cust_name, cust_address,cust_city,cust_state,cust_zip, cust_country) VALUES('1000000006', 'Toy Land','123 Any Street', 'New York','NY','11111','USA');
--一次性插入多行数据,用扩好括起来,然后逗号隔开每条记录:(只在MySQL中实验成功)
INSERT INTO CUSTOMERS(cust_id,cust_name,cust_address,cust_city,cust_state,cust_zip,cust_country,cust_contact,cust_email)
VALUES('1000000007','Toy Land','123 Any Street','New York','NY','11111','USA',NULL,NULL),
('100000008','Toy Land','123 Any Street','New York','NY','11111','USA',NULL,NULL),
('100000009','Toy Land','123 Any Street','New York','NY','11111','USA',NULL,NULL),
('1000000010','Toy Land','123 Any Street','New York','NY,11111','USA',NULL,NULL);
--复制顾客信息表:
--MySQL下:
create table customers_new like customers;
insert into customers_new select * from customers;
--Oracle下:
CREATE TABLE customers_new AS SELECT * FROM Customers;
更新
更新(修改)表中的数据,可以使用UPDATE语句。有两种使用UPDATE的方式:
- 更新表中的特定行;
- 更新表中的所有行。
注意:不要省略WHERE子句
在使用UPDATE时一定要细心。因为稍不注意,就会更新表中的所有
行。使用这条语句前,请完整地阅读本节
提示: UPDATE与安全
在客户端/服务器的DBMS中,使用UPDATE语句可能需要特殊的安全
权限。在你使用UPDATE前,应该保证自己有足够的安全权限。
--客户1000000005现在有了电子邮件地址,因此他的记录需要更新:
UPDATE Customers
SET cust_email = '[email protected]'
WHERE cust_id = '1000000005' ;
UPDATE Customers
SET cust_contact = 'Sam Roberts',
cust_email = '[email protected]'
WHERE cust_id = '1000000006';
UPDATE Customers
SET cust_contact = 'Sam Roberts',
cust_email = '[email protected]'
WHERE cust_id in ('1000000005','1000000006');
--更新所有客户的信息:
UPDATE Customers
SET cust_contact = 'Sam Roberts',
cust_email = '[email protected]';
删除
从一个表中删除(去掉)数据,使用DELETE语句。有两种使用DELETE
的方式:
- 从表中删除特定的行;
- 从表中删除所有行。
注意:不要省略WHERE子句
在使用DELETE时一定要细心。因为稍不注意,就会错误地删除表中
所有行。在使用这条语句前,请完整地阅读本节。
--删除1000000006的顾客信息:
DELETE FROM Customers
WHERE cust_id = '1000000006';
--删除所有顾客信息:
DELETE FROM Customers;
Drop & Truncate & Delete
Drop & Truncate & Delete三者都可以用于删除全表,具体有什么不同呢?
drop table tb_ name; truncate table tb_ name; delete from tb name;
Drop:直接将表删除,删除完成后,这张表就找不到了,是一个DDL操作,无法回滚,速度很快。
Truncate:截断表,将表数据全部删除,保留表结构,同样是DDL操作,无法回滚,速度很快。
Delete:清空表数据,保留表结构,是DML操作,可以回滚,会将删除的数据记录到日志中,因此速度较慢,特别是数据量很大时。
注意点
我们在使用UPDATE或DELETE时所遵循的重要原则:
- 除非确实打算更新和删除每行,否则绝对不要使用不带WHERE子句的UPDATE或DELETE语句。
- 保证每个表都有主键,尽可能像WHERE子句那样使用它(可以指定各主键、多个值或值的范围) .
- 在UPDATE或DELETE语句使用WHERE子句前,应该先用SELECT进行测试,保证它过滤的是正确的记录,
以防编写的WHERE子句不正确。 - 使用强制实施引用完整性的数据库,这样DBMS将不允许删除其数据与其他表相关联的行。
- 有的DBMS允许数据库管理员施加约束,防止执行不带WHERE子句的UPDATE或DELETE语句。如果所采用的DBMS支持这个特性,
应该使用它。
总之就是,update与delete之前再三确认,防止误操作,造成数据丢失。
视图
视图是虚拟的表。与包含数据的表不一样,视图只包含使用时动态检索数据的查询。
创建视图:
Oracle:
--创建ProductCustomers视图:
CREATE VIEW ProductCustomers AS
SELECT cust_name, cust_contact, prod_id
FROM Customers C
join Orders o on C.cust_id = o.cust_id
join orderitems o1 on o1.order_num = o.order_num;
MySQL:
CREATE VIEW ProductCustomers AS
SELECT cust_name, cust_contact, prod_id
FROM Customers AS C
join Orders AS o on C.cust_id = o.cust_id
join orderitems AS o1 on o1.order_num = o.order_num;
说明:视图重命名
删除視图,可以使用DROP语句,其语法为DROP VIEW viewname ;
覆盖(或更新) 视图,必须先删除它, 然后再重新创建。
注意:性能问题
因为视图不包含数据,所以每次使用视图时,都必须处理查询执行时
需要的所有检索。 如果你用多个联结和过滤创建了 复杂的视图或者嵌
套了视图,性能可能会下降得很厉害。因此,在部署使用了大量视图
的应用前,应该进行测试。
视图作用
下面是视图的一-些常见应用。
1.重用SQL语句。
2.简化复杂的SQL操作。在编写查询后,可以方便地重用它而不必知道其基本查询细节。
3.使用表的一部分而不是整个表。
4.保护数据。可以授予用户访问表的特定部分的权限,而不是整个表的访问权限。
5.更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
创建视图之后,可以用与表基本相同的方式使用它们。可以对视图执行SELECT 操作,过滤和排序数据,将视图联结到其他视图或表,甚
至添加和更新数据。
重要的是,要知道视图仅仅是用来查看存储在别处数据的一种设施。视图本身不包含数据,因此返回的数据是从其他表中检索出来的。在
添加或更改这些表中的数据时,视图将返回改变过的数据。
视图限制
下面是关于视图创建和使用的一-些最常见的规则和限制。
1.与表- 样,视图必须唯一命名(不能给视图取与别的视图或表相同的名字) .
2.创建视图,必须具有足够的访问权限。这些权限通常由数据库管理人员授予。
3.视图可以嵌套,即可以利用从其他视图中检索数据的查询来构造视图。所允许的嵌套层数在不同的DBMS中有所不同(嵌套视图可能会
严重降低查询的性能,因此在产品环境中使用之前,应该对其进行全面测试)。
4.有些DBMS要求对返回的所有列进行命名,如果列是计算字段,则需要使用别名。
5.许多DBMS禁止在视图查询中使用ORDER BY子句。
6.有些DBMS把视图作为只读的查询,这表示可以从视图检索数据,但不能将数据写回底层表。详情请参阅具体的DBMS文档。
7.有些DBMS视图会导致查询无法走索引,引起性能问题,特别是MySQL下,对视图的优化作的不是很好,所以尽量就不要使用视图。
触发器
触发器是特殊的存储过程,它在特定的数据库活动发生时自动执行。触发器可以与特定表上的INSERT. UPDATE 和DELETE操作(或
组合)相关联。
触发器通常与单个表相关联,如与Orders 表上的INSERT操作相关联的触发器只在Orders表中插入行时执行。
类似地,Customers 表上的INSERT和UPDATE操作的触发器只在该表上出现这些操作时才执行。
触发器包含三个要素,分别为:
- 事件类型:增删改,即insert. delete和update
- 触发事件:事件类型前和后,即before 和after
- 触发对象:表中的每一条记录(行) ,即整张表。
触发器用途
下面是触发器的一-些常见用途。
1.保证数据一致。例如,在INSERT或UPDATE操作中将所有州名转换为大写。
2.基于某个表的变动在其他表上执行活动。例如,每当更新或删除一行时将审计跟踪记录写入某个日志表。
3.进行额外的验证并根据需要回退数据。例如,保证某个顾客的可用资金不超限定,如果已经超出,则阻塞插入。
4.计算计算列的值或更新时间戳。
不同DBMS的触发器创建语法差异很大,更详细的信息请参阅相应DBMS的文档。
触发器语法
MySQL下

触发器名称–触发器名字,最多64个字符,其命令规则和MySQL 中其他对象的命名方式类似
{ BEFORE | AFTER } --触发器执行时间:可以设置为事件发生前或后
{ INSERT | UPDATE | DELETE }–触发事件:可以设置为在执行INSERT、UPDATE、 DELETE操作时触发
表名称–触发器所属表:触发器属于某一个表, 当在这个表上执行INSERT、UPDATE、 DELETE操作的时就会使触发器触发。
FOR EACH ROW --触发器的执行间隔: FOR EACH ROW子句通知触发器,每行执行一次动作
触发的SQL语句–事件触发时所要执行的SQL语句
NEW和OLD
MySQL中定义了NEW和OLD,用来表示触发器的所在表中,触发了触发器的那一-行数据,来引用触发器中发生变化的记录内容,
具体地:
①在INSERT型触发器中,NEW用来表示将要(BEFORE) 或已经(AFTER) 插入的新数据;
②在UPDATE型触发器中,OLD用来表示将要或已经被修改的原数据,NEW用来表示将要或已经修改为的新数据;
③在DELETE型触发器中,OLD用来表示将要或已经被删除的原数据;
使用方法:
NEW.columnName或OLD.columnName
另外, OLD是只读的,而NEW则可以在触发器中使用SET赋值,这样不会再次触发触发器,造成循环调用。
-- 对于Customers的INSERT,将cust_state列转换为大写:
CREATE TRIGGER tri_customer_state
Before INSERT
ON customers
FOR EACH ROW
begin
SET new.cust_state = Upper(new.cust_state);
end
-- 对Customers表上cust_ name列的更新,用日志表记录下来:
-- 创建备份表
CREATE TABLE cust_log (
old_name CHAR(50),
new_name CHAR(50),
date datetime
);
-- 创建触发器
CREATE TRIGGER tri_custname_update
AFTER update
ON customers
FOR EACH ROW
begin
if new.cust_name != old.cust_name then
insert into cust_log values(old.cust_name, new.cust_name, now());
end if;
end
注意点
尽量少使用触发器,不建议使用! ! !
触发器尽量少使用,因为不管如何,它还是很消耗资源。
如果使用的话要谨慎的使用,确定它是非常高效的:
触发器是针对每一-行的;对增删改非常频繁的表上切记不要使用触发器,因为它会非常消耗资源。
序列
MySQL自增
MySQL的AUTO_INCREMENT属性可以用于在插入新的记录的时候,进行主键自增。
CREATE TABLE animals (
id int NOT NULL AUTO_INCREMENT,
name CHAR(30) NOT NULL,
PRIMARY KEY (id)
);
Oracle序列
Oracle提供了sequence对象,由系统提供自增长的序列号,用于生成数据库数据记录的自增长主键或序号。
语法
CREATE SEQUENCE序列名
[INCREMENT BY n]
[START WITH n]
[{MAXVALUE/ MINVALUE n| NOMAXVALUE}]
[{CYCLE|NOCYCLE}]
[{CACHE n| NOCACHE}];
- INCREMENT BY:用于定义序列的步长,如果省略,则默认为1,如果出现负值,则代表Oracle序列的值是按照此步长递减的。
- START WITH:定义序列的初始值(即产生的第一个值), 默认为1.
- MAXVALUE:定义序列生成器能产生的最大值。选项NOMAXVALUE是默认选项,代表没有最大值定义。
- MINVALUE:定义序列生成器能产生的最小值。选项NOMAXVALUE是默认选项,代表没有最小值定义。
- CYCLE和NOCYCLE:表示当序列生成器的值达到限制值后是否循环。CYCLE代表循环,NOCYCLE代表不循环。 如果循环,则当递增序列达到最大
值时,循环到最小值; - CACHE(缓冲):定义存放序列的内存块的大小,默认为20。NOCACHE表示不对序列进行内存缓冲。对序列进行内存缓冲,可以改善序列的性能。
序列使用
--创建序列seq_ test:
create sequence seq_test
minvalue 1
maxvalue 9999999
start with 1
increment by 1
cache 50;
--获取序列的当前值:
select seq_test.currval from dual;
--获取序列的下一个值:
select seq_test.nextval from dual;
Oracle实现自增方式一:序列+触发器(常用):
--创建序列
CREATE SEQUENCE Tab_Userlnfo_Sequence
START WITH 1
MINVALUE 1
MAXVALUE 999999999
INCREMENT BY 1
CACHE 20;
--创建用户表
CREATE TABLE UserInfo(
id NUMBER(10) NOT NULL,
username VARCHAR2(15) NOT NULL,
password VARCHAR2(15) NOT NULL,
CONSTRAINTS PF_UserInfo PRIMARY KEY(id)
);
--创建触发器
CREATE TRIGGER Tig_UserInfo_Insert
BEFORE INSERT
ON UserInfo
FOR EACH ROW WHEN(new.id IS NULL)
BEGIN
--将取到的值放入id中
select Tab_Userlnfo_Sequence.nextval into :new.id from dual;
END;
SELECT * FROM UserInfo;
INSERT INTO UserInfo VALUES (NULL,'tom','123');
Oracle实现自增方式二:显示调用序列的下一个值进行插入
CREATE SEQUENCE Tab_UserInfo_Sequence
START WITH 1
MINVALUE 1
MAXVALUE 999999999
INCREMENT BY 1
CACHE 20;
CREATE TABLE Userlnfo
id NUMBER(10) NOT NULL,
username VARCHAR2(15) NOT NULL,
password VARCHAR2(15) NOT NULL,
CONSTRAINTS PF_Userlnfo PRIMARY KEY(id)
);
insert into Userlnfo values(Tab_UserInfo_Sequence.nextval,'aaa', '111');
insert into Userlnfo values(Tab_UserInfo_Sequence.nextval,'bbb', '222');
insert into Userlnfo values(Tab_UserInfo_Sequence.nextval,'ccc', '333');
常用命令
MySQL
mysql -uroot -p -h 127.0.0.1 -P3306远程连接show databases; use db_ name; show full tables;库表视图展示select version();版本查询desc tb_name;列信息show create table tb_name; 表定义,可以生成建表语句show create view view_name;视图定义show processlist;查看连接进程select host,user from mysql.user;查看所有用户
Oralcle
sqlplus username/password@ip:port/service_name客户端连接数据库select * from v$version查看版本select * from v$database查看数据库信息select * from v$instance查看实例信息select ownere,table_name,tablespace_name from dba_tables;所有用户表
select table_name,tablespace_name from user_tables;当前用户表select * from dba_tablespaces;查看表空间select * from dba_data_files;查看数据文件
系统函数
常用的系统函数分为以下几类:
1.数学函数
MySQL

-- 数学函数
select abs(id) from a;
select ceil(3.15) from dual;
select floor(3.15) from dual;
select mod(11,3) from dual;
select rand() from dual;
select round(3.1415,2) from dual;
select truncate(3.149995,2) from dual;
2.聚合函数

-- 聚合函数,配合分组使用
select round(avg(p.prod_price),2) from products p ;
select count(*) from products p2 ;
select max(prod_price) from products p2 ;
select min(prod_price) from products p2 ;
select sum(prod_price) from products p2 ;
3.字符串函数
MySQL

-- 字符串函数
select concat('hello','world') from dual;-- helloworld
select insert('123456',1,3,'777') from dual;-- 777456
select lower('ANS') from dual; -- ans
select upper('abs') from dual;-- ABS
select left('123456',3) from dual;-- 123
select right('123456',3) from dual;-- 456
select lpad('123',6,'000') from dual; -- 000123
select rpad('123',6,'000') from dual; -- 123000
select length(ltrim(' 123')) from dual; -- 3
select length(rtrim('123 ')) from dual; -- 3
select length(trim(' 123 ')) from dual; -- 3
select repeat('0',10) from dual;-- 0000000000
select strcmp('123','123') from dual;-- 0
select strcmp('123','321') from dual;-- -1
select replace ('123456123','123','aaa') from dual;-- aaa456aaa
select substr('123456',2,3) from dual;-- 234
select initcap('xin dian ruan jian') from dual;-- 首字母大写
-字符-数字转换:
select chr(65),chr(97) from dual;
4.时间日期函数
MySQL

-- 时间函数
select curdate() from dual;-- 2021-10-31
select curtime() from dual;-- 22:41:54
select now() from dual;-- 2021-10-31 22:41:58.0
select unix_timestamp(now()) from dual;-- 日期-时间戳
select from_unixtime(unix_timestamp(now())) from dual;-- 时间戳-日期
select from_unixtime(0) from dual;-- 时间戳-日期1970-01-01 08:00:00.0
select week(now()) from dual;-- 返回一年中的第几周
select year (now()) from dual;-- 返回年份
select minute(now()) from dual;-- 返回分钟
select second(now()) from dual;-- 返回秒
select monthname(now()) from dual;-- 返回月份的单词 如:October
select date_format(now(),'%d-%m-%Y') from dual; -- 31-10-2021
select date_add(now(),interval 1 day) from dual; -- 在当前日期+1天 day month year minute hour
select datediff('2021-10-30','2021-10-20') from dual; -- 相差的天数
时间日期格式

MySQL: select date_format(now(), '%Y-%m-%d %H:%i:%s') from dual;
Oracle: select to_char(sysdate,'YYYY-MM-DD HH24:Mi:SS") from dual;
5.流程函数
MySQL
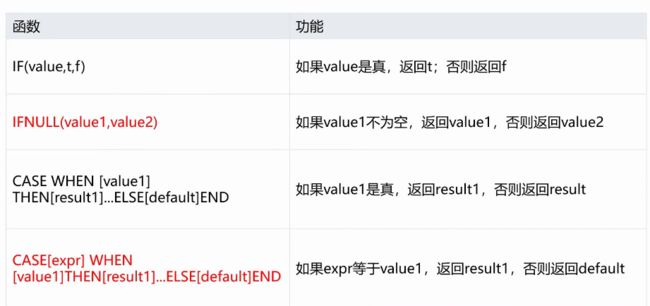
-- 流程函数
select * from a;
insert into a values(5);
select if(id=1,'true','false') from a;-- 非1值为false,1为true
select ifnull(id,'false') from a;-- null值为false,非null为true
select * from student;
create table student(name varchar(10),sex varchar(5),score int);
insert into student values('tom','男',90);
insert into student values('jack','女',80);
insert into student values('mary','男',70);
insert into student values('lily','女',50);
-- 男的话输出1,女的话输出2(判断可以例举的值)
select name,sex,
case sex
when '男' then 1
when '女' then 2
end
from
student ;
-- 判断成绩(判断一个范围的值)
select name,sex,
case
when score >= 60 then '及格'
when score<60 then '不及格'
end
from
student ;
if流程控制:

case流程控制:

while流程控制:

Oracle和MySQL的函数差异

CAST()参数
- 二进制,同带binary前缀的效果 : BINARY
- 字符型,可带参数 : CHAR()
- 日期 : DATE
- 时间: TIME
- 日期时间型 : DATETIME
- 浮点数 : DECIMAL
- 整数 : SIGNED
- 无符号整数 : UNSIGNED
Oracle加减时间
select to_date( '2004-05-07 13:23:44', 'yyyy-mm-dd hh24:mi:ss') + interval '7' MINUTE from dual;
select sysdate - interval '7' hour from dual;
select sysdate - interval '7' day from dual;
select sysdate - interval '7' month from dual;
Oracle时间和字符串转换
SELECT to_char(SYSDATE,'HH24:MI:SS YYYY-MM-DD') FROM dual ;
select to_date( '2004-05-07 13:23:44', 'yyyy-mm-dd hh24:mi:ss') from dual;
Oracle判断空值
SELECT NVL(NULL,'false') FROM dual;
自定函数
MySQL
在使用数据库的过程中,系统函数可能完成不了我们的业务需求,这时候就需要自定义函数。
自定义函数是一种与存储过程十分相似的过程式数据库对象。它与存储过程一样, 都是由SQL语句和过程式语句组成的代码
片段,并且可以被应用程序和其他SQL语句调用。
自定义函数与存储过程之间存在几点区别:
-
自定义函数不能拥有输出参数,这是因为自定义函数自身就是输出参数;而存储过程可以拥有输出参数。
-
自定义函数中必须包含一条RETURN语句,而这条特殊的SQL语句不允许包含于存储过程中。
-
可以直接对自定义函数进行调用而不需要使用CALL语句,而对存储过程的调用需要使用CALL语句。
语法


-- 示例1
DROP FUNCTION IF EXISTS HELLO;
CREATE FUNCTION HELLO(NAME varchar(10))
returns VARCHAR(30)
begin
-- 定义变量
declare result VARCHAR(30);
set result=concat('HELLO,',NAME);
return result;
end;
select HELLO('TOM') from dual;
-- 示例2
DROP FUNCTION IF EXISTS max_number;
create function max_number(var1 int,var2 int)
returns int
begin
if var1>var2 then
return var1;
else
return var2;
end if;
end;
select max_number(15,50) from dual;
-- 示例3
-- 根据需求判断输入时间属于前一天或当天,例如小于10点为前一天,超过10点即为当天。
DROP FUNCTION IF EXISTS get_date;
create function get_date(v_datetime datetime,v_time varchar(50))
returns varchar(50)
begin
declare v_date varchar(50);
declare cDate varchar(50);
declare beginDate varchar(50);
set cDate=date_format(v_datetime,'%Y-%m-%d %H:%i:%s');
set beginDate=concat(date_format(v_datetime,'%Y-%m-%d '),v_time);
if cDate < beginDate then
set v_date = date_format(date_add(v_datetime,interval -1 day),'%Y-%m-%d');
else
set v_date = date_format(v_datetime,'%Y-%m-%d');
end if;
return v_date;
end;
select get_date(now(),'12:00:00') from dual;
Oracle
--实例1
CREATE OR REPLACE FUNCTION HELLO(NAME VARCHAR2)
RETURN VARCHAR2
AS
-- 定义变量
RESULT VARCHAR2(30);
BEGIN
RESULT:='HELLO,'||NAME;
RETURN RESULT;
END;
--调用函数
SELECT HELLO('JACK') FROM DUAL;
-- 示例2
CREATE OR REPLACE FUNCTION max_number(var1 NUMBER,var2 NUMBER)
RETURN NUMBER
AS
BEGIN
IF var1>var2 THEN
RETURN var1;
ELSE
RETURN var2;
END IF ;
END;
SELECT max_number(75,9) FROM dual;
--示例3
CREATE OR replace function get_date(v_datetime date,v_time varchar2)
return varchar2
AS
v_date varchar2(50);
cDate varchar2(50);
beginDate varchar2(50);
begin
cDate:=TO_CHAR(v_datetime,'YYYY-MM-DD hh24:mi:ss');
beginDate:=concat(TO_CHAR(v_datetime,'YYYY-MM-DD '),v_time);
if cDate < beginDate then
v_date := TO_CHAR (v_datetime - 1,'YYYY-MM-DD');
else
v_date := TO_CHAR(v_datetime,'YYYY-MM-DD');
end if;
return v_date;
end;
select get_date(SYSDATE ,'12:00:00') from dual;
区别
| MySQL | Oracle |
|---|---|
| returns | return |
| 定义用declare 变量名 类型 | 定义写在AS下面 变量名 类型 |
| 赋值用SET 变量名=值 | 赋值用 := |
| 字符串连接concat,任意个 | concat只能连接2个,||可以多个 |
| 形参和返回值要写数据长度 | 形参和返回值可以不写长度 |
存储过程
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。
存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数来调用执行。
存储过程思想上很简单,就是数据库SQL语言层面的代码封装与重用。
1.通过把处理封装在一个易用的单元中, 可以简化复杂的操作。
2.不要求反复建立一系列处理步骤, 因而保证了数据的一致性。
3.简化对变动的管理。如果表名、列名或业务逻辑(或别的内容)有变化,那么只需要更改存储过程的代码。
4.因为存储过程通常以编译过的形式存储,所以DBMS处理命令所需的工作量少,提高了性能。
换句话说,使用存储过程有三个主要的好处,即简单、安全、高性能。
不同DBMS中的存储过程语法有所不同,事实上,编写真正的可移植存储过程几乎是不可能的。
语法


示例一:
MySQL:
-- 示例1
drop procedure if exists delete_orders;
create procedure delete_orders(ordernum int)
begin
delete from orderitems where order_num =ordernum;
delete from orders where order_num =ordernum;
end;
select * from orders o ;
select * from orderitems o ;
-- 调用存储过程
call delete_orders(20005);
Oracle:
CREATE OR REPLACE PROCEDURE delete_orders(ordernum number)
AS
BEGIN
delete from orderitems where order_num =ordernum;
delete from orders where order_num =ordernum;
COMMIT;
END;
SELECT * FROM ORDERS o ;
SELECT * FROM ORDERITEMS o ;
-- 调用存储过程
CALL delete_orders(20005);
示例二:
MySQL:
-- 示例2 获取对应的版本号
create procedure GetCurrentNumber(nname varchar(100),nflag varchar(100),out cnumber varchar(100))
begin
declare mvalue int;
select max(cast(CurrentValue as SIGNED)) into mvalue
from code_maxnumber where NumberName=nname and NumberFlag=nflag;
if mvalue is null then
insert into code_maxnumber(NumberName,NumberFlag,Currentvalue) values(nname,nflag,1);
else
update code_maxnumber set currentvalue=currentvalue+1 where NumberName=nname and NumberFlag=nflag;
end if;
if(ifnull(mvalue,0)=0) then
set cnumber='1';
else
set mvalue=mvalue+1;
set cnumber=cast(mvalue as char);
end if;
end;
create table code_maxnumber ( numbername varchar(100) , numberflag varchar(100) , currentvalue int );
select * from code_maxnumber;
call GetCurrentNumber('案卷编号','02',@c);
select @c;
Oracle:
create table code_maxnumber ( numbername varchar2(100) , numberflag varchar2(100) , currentvalue number);
SELECT * FROM code_maxnumber;
CREATE OR replace procedure GetCurrentNumber(nname varchar2,nflag varchar2,cnumber out varchar2)
AS
mvalue number;
begin
select max(cast(CurrentValue as number)) into mvalue
from code_maxnumber where NumberName=nname and NumberFlag=nflag;
if (mvalue is NULL) then
insert into code_maxnumber(NumberName,NumberFlag,Currentvalue) values(nname,nflag,1);
else
update code_maxnumber set currentvalue=currentvalue+1 where NumberName=nname and NumberFlag=nflag;
end if;
if(nvl(mvalue,0)=0) then
cnumber:='1';
else
mvalue:=mvalue+1;
cnumber:=cast(mvalue as char);
end if;
end;
-- 调用
DECLARE
cnumber NUMBER;
BEGIN
GetCurrentNumber('案卷编号','02',cnumber);
END;
游标
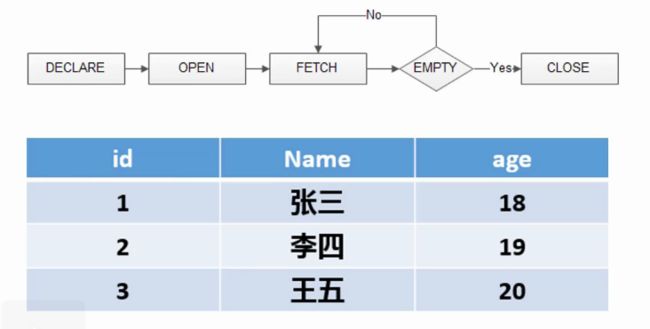
游标实际上是一种能从包括多条数据记录的结果集中每次提取一条记录的机制。
游标充当指针的作用,尽管游标能遍历结果中的所有行,但他一次只指向一行。
游标的作用就是用于对查询数据库所返回的记录进行遍历,以便针对特定的数据进行操作。
生命周期:
示例三:数据迁移(较难了解即可)
mysql

oracle

分别在Oracle与MySQL下创建存储过程pro_delete_all_order,用游标的方式从orders表中获取所有订单号,然后将每个订单号的记录删除,包括orders和orderitems的相关记录。
MySQL:
SELECT * FROM ORDERS o ;
SELECT * FROM ORDERITEMS o ;
DROP PROCEDURE IF EXISTS pro_delete_all_order;
CREATE PROCEDURE pro_delete_all_order()
begin
declare c int(11);
declare total int default 0;
declare done int default false;
declare all_order CURSOR for SELECT o.order_num FROM ORDERS o;
declare continue HANDLER for not found set done = true;
set total = 0;
open all_order;
fetch all_order into c;
while(not done) do
delete from orderitems where order_num = c;
delete from orders where order_num = c;
set total = total + 1;
fetch all_order into c;
end while;
close all_order;
select total;
END;
call pro_delete_all_order();
oracle:
Oracle:
SELECT * FROM ORDERS o ;
SELECT * FROM ORDERITEMS o ;
CREATE OR REPLACE PROCEDURE pro_delete_all_order
as
CURSOR all_order IS SELECT * FROM ORDERS o;
BEGIN
FOR temp IN all_order LOOP
DELETE FROM ORDERITEMS o WHERE o.ORDER_NUM = temp.ORDER_NUM;
DELETE FROM ORDERS o WHERE o.ORDER_NUM = temp.ORDER_NUM;
COMMIT;
END LOOP;
END;
BEGIN
pro_delete_all_order;
END;
小结
