这20个Pandas函数一定要牢记,建议收藏!!
来自:Deephub IMBA
Pandas 是数据科学社区中使用最广泛的库之一,它是一个强大的工具,可以进行数据操作、清理和分析。本文将提供最常用的 Pandas 函数以及如何实际使用它们的样例。我们将涵盖从基本数据操作到高级数据分析技术的所有内容,到本文结束时,你会深入了解如何使用 Pandas 并使数据科学工作流程更高效。

1、pd.read_csv ()
read_csv用于读取CSV(逗号分隔值)文件并将其转换为pandas DataFrame。
import pandas as pd
df = pd.read_csv('Popular_Baby_Names.csv')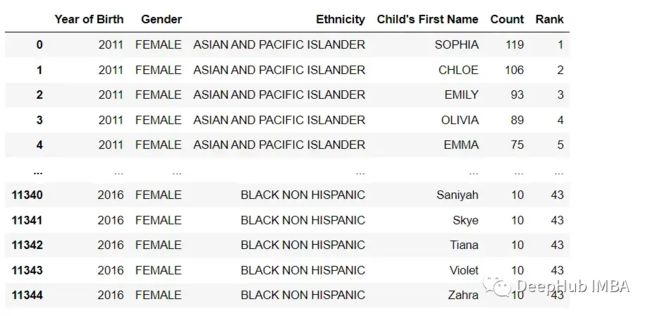
在这个例子中,pd.read_csv函数读取文件' data.csv '并将其转换为一个DataFrame,它有许多选项,如sep, header, index_col, skiprows, na_values等。
df = pd.read_csv('Popular_Baby_Names.csv', sep=';', header=0, index_col=0, skiprows=5, na_values='N/A')这个例子读取CSV文件data.csv,使用;作为分隔符,第一行作为标题,第一列作为索引,跳过前5行,将N/ a替换为NaN。
2、df.describe ()
df.describe()方法用于生成DataFrame的各种特征的汇总统计信息。它返回一个新的DataFrame,其中包含原始DataFrame中每个数值列的计数、平均值、标准差、最小值、第25百分位、中位数、第75百分位和最大值。
print(df.describe())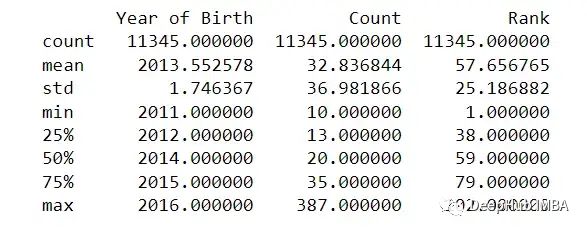
通过向方法传递适当的参数,还可以包括或排除某些列,比如排除非数值列。
df.describe(include='all') # include all columns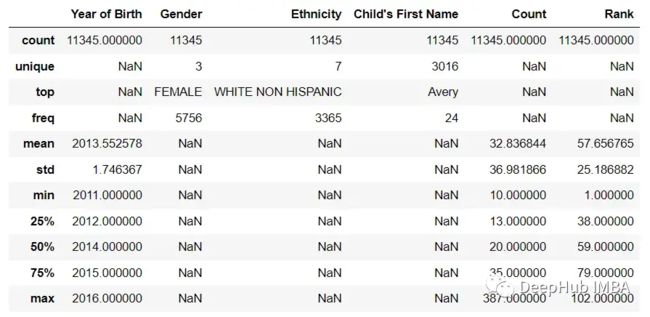
df.describe(exclude='number') # exclude numerical columns
3、df.info ()
df.info()可以获得DataFrame的简明摘要,包括每列中非空值的数量、每列的数据类型以及DataFrame的内存使用情况。
print(df.info())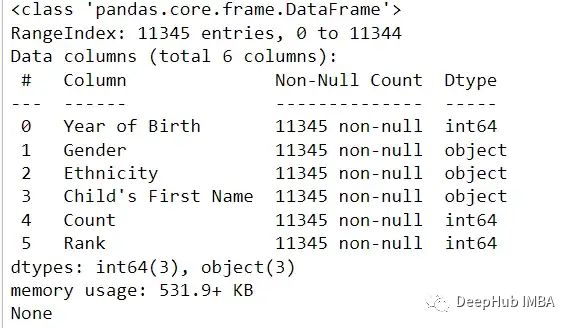
4、df.plot ()
df.plot()可以从DataFrame创建各种类型的图。默认情况下,它在DataFrame中创建所有数值列的线状图。但是你也可以通过参数kind来指定你想要创建的图形类型。可选选项有line、bar、barh、hist、box、kde、density、area、pie、scatter和hexbin。
在下面的例子中,将使用.plot()方法绘制数值变量和分类变量。对于分类变量,将绘制条形图和饼状图,对于数值变量,将绘制箱形图。
df['Gender'].value_counts().plot(kind='bar')
df['Gender'].value_counts().plot(kind='pie')
df['Count'].plot(kind='box')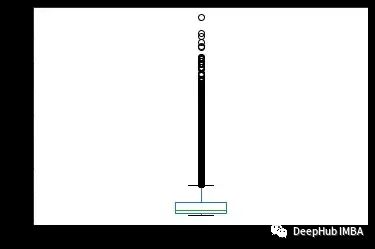
它还支持许多其他选项,如title,xlabel,ylabel,legend,grid,xlim,ylim,xticks,yticks等,df.plot()只是matplotlib的一个方便包装。所以matplotlib的参数都可以在df.plot中使用
5、df.iloc ()
.iloc()函数用于根据索引选择行和列
print(df.iloc[0])
print(df.iloc[:2])
print(df.iloc[:, 0])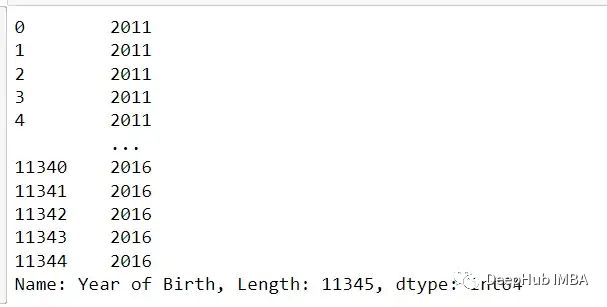
print(df.iloc[:, :2])
print(df.iloc[1, 1])![]()
在上面的例子中,df.Iloc[0]选择第一行,Iloc[:2]选择前两行,Iloc[:, 0]选择第一列,Iloc[:,:2]选择前两列,Iloc[1,1]选择位于(第二行,第二列)(1,1)位置的元素。
.iloc()只根据它们基于整数的索引选择行和列,所以如果您想根据它们的标签选择行和列,应该使用.loc()方法,如下所示。
6、df.loc ()
.loc()函数用于根据DataFrame中基于标签的索引选择行和列。它用于根据基于标签的位置选择行和列。
print(df.loc[:, ['Year of Birth', 'Gender']])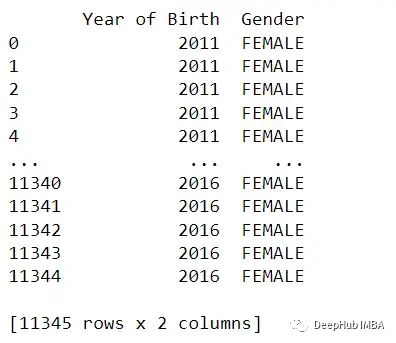
在上面的例子中,df.loc[:, ['Year of Birth', 'Gender']]选择名为'出生年份'和'性别'的列。
7、df.assign ()
.assign()函数用于根据现有列的计算向DataFrame添加新列。它允许您在不修改原始数据的情况下添加新列。该函数会返回一个添加了列的新DataFrame。
df_new = df.assign(count_plus_5=df['Count'] + 5)
df_new.head()
在上面的例子中,df.assign()第一次被用来创建一个名为'count_plus_5'的,值为count + 5的新列。
原始的df保持不变,返回新的df_new,并添加了新的列。.assign()方法可以在一个链中多次使用,可以在一行代码中添加多个新列。
8、df.query ()
.query()函数可以根据布尔表达式过滤数据。可以使用类似于SQL的查询字符串从DataFrame中选择行。该函数返回一个新的DataFrame,其中只包含满足布尔表达式的行。
df_query = df.query('Count > 30 and Rank < 20')
df_query.head()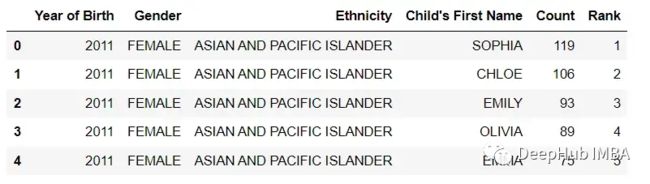
df_query = df.query("Gender == 'MALE'")
df_query.head()
在上面的例子中,使用df.query()来选择Count大于30且Rank小于30的行,第二次使用df.query()来选择Gender为'MALE'的行。
原始的DataFrame df保持不变,df_query返回过滤后新的DataFrame。
.query()方法可以与任何有效的布尔表达式一起使用,当你希望基于多个条件筛选DataFrame,或者当条件复杂且难以使用标准索引操作符表示时,它非常有用。
另外请记住.query()方法很慢,所以如果性能很关键,应该尽量避免使用。
9、df.sort_values ()
.sort_values()函数可以按一列或多列对数据进行排序。它根据一个或多个列的值按升序或降序对DataFrame进行排序。该函数返回一个按指定列排序的新DataFrame。
df_sorted = df.sort_values(by='Count')
df_sorted.head()
df_sorted = df.sort_values(by='Rank', ascending=False)
df_sorted.head()
df_sorted = df.sort_values(by=['Count', 'Rank'])
df_sorted.head()
在上面的例子中,第一次使用df.sort_values()按“Count”升序对DataFrame排序,第二次使用按“Rank”降序排序,最后一次使用按多个列“Count”和“Rank”排序。
.sort_values()方法可用于DataFrame的任何列,当希望基于多个列对DataFrame进行排序时,或者当希望按列降序对DataFrame进行排序时,它非常有用。
10、df.sample ()
.sample()函数可以从数据帧中随机选择行。它返回一个包含随机选择的行的新DataFrame。该函数采用几个参数,可以控制采样过程。
df_sample = df.sample(n=2, replace=False, random_state=1)
df_sample
df_sample = df.sample(n=3, replace=True, random_state=1)
df_sample
df_sample = df.sample(n=2, replace=False, random_state=1, axis=1)
df_sample
在上面的例子中,第一次使用df.sample()随机选择2行,第二次使用df.sample()随机选择3行,最后一次使用df.sample()随机选择2列。
当希望随机选择数据子集进行测试或验证时,或者当希望随机选择行样本进行进一步分析时,.sample()方法非常有用。random_state参数对于再现性很有用,使用axis=1参数可以选择列。
11、df.isnull ()
isnull()方法返回一个与原始DataFrame形状相同的DataFrame,通过True或False值,指示原始DataFrame中的每个值是否缺失。缺失的值NaN或None,在结果的DataFrame中将为True,而非缺失的值将为False。
df.isnull()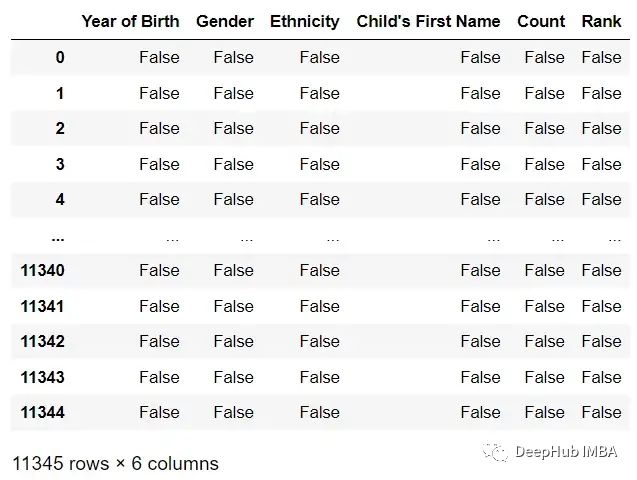
12、df.fillna ()
fillna()方法用于用指定的值或方法填充DataFrame中的缺失值。默认情况下,它用NaN替换缺失的值,也可以指定一个不同的值来代替,一般情况下可以使用以下的参数:
value:指定用来填充缺失值的值。可以是标量值,也可以是不同列的值的字典。
method:指定用于填充缺失值的方法。可以是'ffill'(向前填充)或'bfill'(向后填充)或'interpolate'(插值值)或'pad'或'backfill'
axis:指定填充缺失值的轴。它可以是0(行)或1(列)。
inplace:是将缺失的值填充到位(修改原始的DataFrame),还是返回一个新的DataFrame。
limit:指定要填充的连续缺失值的最大数量。
downcast:指定一个值字典,用于向下转换列的数据类型。
df.fillna(0)
df.fillna(method='ffill')
df.fillna(method='bfill')
df.interpolate()需要注意的是,fillna()方法返回一个新的DataFrame,并不修改原始的DataFrame。如果想修改原始的DataFrame,可以使用inplace参数并将其设置为True。
df.fillna(0, inplace=True)13、df.dropna ()
df.dropna()可以从DataFrame中删除缺失值或空值。它从DataFrame中删除至少缺失一个元素的行或列。可以通过调用df.dropna()删除包含至少一个缺失值的所有行。
df = df.dropna()如果只想删除包含至少一个缺失值的列,可以使用df.dropna(axis=1)
df = df.dropna(axis=1)你还可以设置thresh参数,只保留至少具有阈值非na /null值的行/列。
df = df.dropna(thresh=2)14、df.drop ()
df.drop()可以通过指定的标签从DataFrame中删除行或列。它可以用于删除一个或多个基于标签的行或列。
你可以通过调用df.drop()来删除特定的行,并传递想要删除的行的索引标签,并将axis参数设置为0(默认为0)。
df_drop = df.drop(0)这将删除DataFrame的第一行。
也可以通过传递一个索引标签列表来删除多行:
df_drop = df.drop([0,1])这将删除DataFrame的第一行和第二行。可以通过传递想要删除的列的标签并将axis参数设置为1来删除列:
df_drop = df.drop(['Count', 'Rank'], axis=1)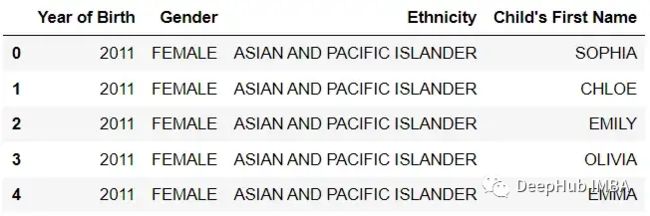
15、pd.pivot_table ()
pd.pivot_table()可以从DataFrame创建数据透视表。透视表是一种以更有意义和更有组织的方式总结和聚合数据的表。在下面的例子中,将创建一个以Ethnicity为索引的透视表,并汇总计数的总和。这用于了解数据集中每个Ethnicity的计数。
pivot_table = pd.pivot_table(df, index='Ethnicity', values='Count', aggfunc='sum')
pivot_table.head()
通过指定多个索引和值参数,可以在透视表中包含更多列,还可以包括多个aggfunc函数。
pivot_table = pd.pivot_table(df, index=['Ethnicity','Gender'], values= 'Count' , aggfunc=['sum','count'])
pivot_table.head(20)
16、df.groupby ()
df.groupby()用于根据一个或多个列对DataFrame的行进行分组。并且可以对组执行聚合操作,例如计算每个组中值的平均值、和或计数。
df.groupby()返回一个GroupBy对象,然后可以使用该对象对组执行各种操作,例如计算每个组中值的和、平均值或计数。
grouped = df.groupby('Gender')
print(grouped.mean())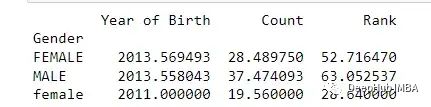
grouped = df.groupby(['Gender', 'Ethnicity'])
print(grouped.sum())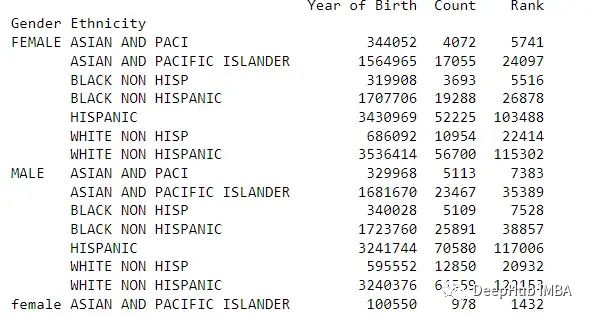
17、df.transpose ()
df.transpose()用于转置DataFrame的行和列,这意味着行变成列,列变成行。
df_transposed = df.transpose()
df_transposed.head()
也可以使用df上的T属性来实现。df.T和df.transpose()是一样的。
18、df.merge ()
df.merge()可以根据一个或多个公共列组合两个dataframe。它类似于SQL join。该函数返回一个新的DataFrame,其中只包含两个DataFrame中指定列中的值匹配的行。
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],
'value': [5, 6, 7, 8]})
merged_df = df1.merge(df2, on='key')
print(merged_df)
两个df通过key列进行了合并,相同的列名会被添加x和y。
你也可以通过分别传递how = ' left '、how = ' right '或how = ' outer '来使用左连接、右连接和外连接。
还可以通过将列列表传递给on参数来合并多个列。
merged_df = df1.merge(df2, on=['key1','key2'])还可以使用left_on和right_on参数指定要合并的不同列名。
merged_df = df1.merge(df2, left_on='key1', right_on='key3')merge()函数有许多选项和参数,可以控制合并的行为,例如处理缺失的值,保留所有行还是只保留匹配的行,合并哪些列等等。
19、df.rename ()
df.rename()可以更改DataFrame中一个或多个列或行的名称。可以使用columns参数更改列名,使用index参数更改行名。
df_rename = df.rename(columns={'Count': 'count'})
df_rename.head()
也可以使用字典一次重命名多个列:
df_rename = df.rename(columns={'Count': 'count', 'Rank':'rank'})
df_rename.head()
重命名索引:
df_rename = df.rename(index={0:'first',1:'second',2:'third'})
df_rename.head()
20、df.to_csv ()
df.to_csv()可以将DataFrame导出到CSV文件。与上面的Read_csv作为对应。调用df.to_csv()将DataFrame导出到CSV文件:
df.to_csv('data.csv')可以通过传递sep参数来指定CSV文件中使用的分隔符。默认情况下,它被设置为“,”。
df.to_csv('path/to/data.csv', sep='\t')也可以通过将列名列表传递给columns参数来只保存DataFrame的特定列,通过将布尔掩码传递给索引参数来只保存特定的行。
df.to_csv('path/to/data.csv', columns=['Rank','Count'])还可以使用index参数指定在导出的CSV文件中包含或不包含dataframe的索引。
df.to_csv('path/to/data.csv', index=False)使用na_rep参数将导出的CSV文件中缺失的值替换为指定的值。
df.to_csv('path/to/data.csv', na_rep='NULL')总结
以上这20个pandas函数,绝对可以帮助我们完成80%以上的任务,我们这里只是简单的总结,想group,merge等参数比较多并且常用的函数可以通过pandas的文档进一步熟悉,这将对我们的工作有很大的帮助。
作者:Youssef Hosni
NO.1
往期推荐
Historical articles
用Python写了一个网易云音乐(附源码、视频教程)
用Python制作进度条,真的太方便了!!
13 个可能未使用过的 Python 特性
Python+ChatGPT制作了一个AI百宝箱,太实用了!!
分享、收藏、点赞、在看安排一下?



