NPU架构分析与应用
NPU架构分析与应用
参考文献链接
https://mp.weixin.qq.com/s/62P8zVF7rySLakZJEkd7VA
https://mp.weixin.qq.com/s/hvzwCxzlgfS1yE-PRfs58A
https://mp.weixin.qq.com/s/BKzNwfVe-Bsoh_2090HHcQ
https://mp.weixin.qq.com/s/tEvskB3kIyA0t6a3z3zDhg
https://mp.weixin.qq.com/s/U2TIcwrq75FthslLgNJr2A
https://mp.weixin.qq.com/s/JVXSK_gr49IkRfl0s9UClQ
https://mp.weixin.qq.com/s/u_kBc5yoPJxtiovQD2EbWw
ADS算力芯片NPU的硬件架构
人类自然科学史是一幅幅波澜壮阔的画面:其起源于2500年前古希腊的自然哲学,经过400年前伽利略时期的痛苦孕育,在300年前成功诞生出牛顿力学。其后经历了四次科学革命,同步紧随了四次技术革命和工业革命的大爆发。

当前行业AI化与数字化为核心的智能化时代,云计算与AI等先进生产力开始有机结合与延伸拓展,通过加速提升的算力来逐步呈现数字经济的核心价值。按照《云网融合:算力时代的数字信息基础设施》一书的统计分析,算力的支撑使得数字经济占GDP比重由2015年的14.2%提升至2020年的38.6%。
算力、数据、算法共同构成了计算资源的三要素,而ADS领域正是三要素集大成者。AI算法在ADS领域的行业应用,其当前演进方向主要体现在:
1)能够在统一空间支持多模传感器感知融合与多任务共享;
2)预测与规划联合建模,离线与在线学习相结合,能够自学习处理不确定性下的安全与可解释问题,通过持续学习解决新场景问题。
如图1和图2所示,对应ADS负载的多样化和融合感知决策算法多样化的演进趋势,ADS算力新需求体现在从compute-bound走向memory-bound,NPU的设计需求也从偏计算走向偏存算的混合模式。

图1 NPU设计新需求:从偏计算走向偏存算的混合模式

图2 DNN中不同模块的运行时间剖析图案例(注:引用参考文献1)
当前市场上主流AI算力芯片,都存在几个共性问题,一是低算力问题:多针对3x3卷积优化,算法总体效率低;二是内存墙问题:PE存算分离数据难共享;三是能耗墙问题:数据重复搬移高耗能。
从下一代的工程实践上看,ADS算法需要通过“硬件预埋,算法迭代,算力均衡“ ,提供一个向前兼容的解决方案,以通用大算力来解决未来不确定性的算法演进,具体体现在:
- 底层架构的演进:从存算分离到近内存计算,最终走向内存计算。
- 数据通道与模型:高速数据接口+数据压缩+模型压缩+低精度逼近计算+稀疏计算加速。
- 并行的顶层架构:模型-硬件联合设计,以及硬设计可配置+硬件调度+软运行可编程调度引擎。
对比CPU十百级的并行处理单元和GPU上万级的并行处理单元,NPU会有百万级的并行计算单元,可以采用Spatial加速器架构来实现,即Spatial PE空间单元阵列通过NoC,数据总线,或跨PE的互联来实现数据流交互。粗颗粒度的可配置架构CGRA是Spatial加速器的一种形态,即可配置的PE Array通过纳秒或微秒级别可配置的Interconnect来对接,可以支持配置驱动或者数据流驱动运行。脉动Systolic加速器架构也是Spatial加速器的一类实现方式,其主要计算是通过1D或2D计算单元对数据流进行定向固定流动处理最终输出累加计算结果,存在的问题难以支撑压缩模型的稀疏计算加速处理。NPU的第二类计算单元是Vector加速器架构,其计算可以通过可配置的矢量核来实现。NPU也可以采用多核架构技术,即提供千百级的加速器物理核来组件封装提供更高程度的平行度,尤其是适合大算力下高并行数据负载。NPU另外一个在演进中的是内存处理器PIM架构,即通过将计算靠近存储的方式来降低数据搬移能耗和提升内存带宽。可以分成近内存计算与内存计算两种类型。近内存计算将计算引擎靠近传统的DRAM或者SRAM cell,保持设计特性。内存计算需要对内存cell添加数据计算逻辑,多采用ReRAM或者STT-RAM新型工艺,目前多采用数字类型的设计,技术难题是如何在运行态时进行大模型参数动态刷新,工艺实现也落后于市场预期。
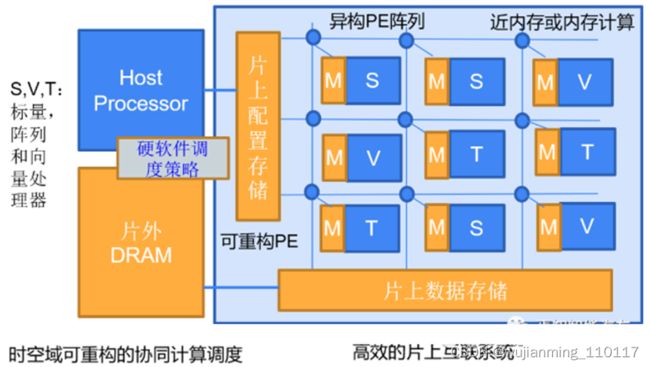
图3 NPU细粒度可重构的硬件架构CGRA案例
如图3所示,总结来说,NPU可配置特性是指NPU可以通过软件定义来修改运行状态下CGRA硬件逻辑单元的运算与互联,可以通过配置数据比特流来修改配置内存。NPU可编程特性是指针对用户自定义的数据流,通过指令集来实现不同类型的计算操作。通常只有FPGA可以针对计算单元和互联提供细颗粒度的可配置特性,大算力NPU能够引进这样的先进设计思路也是势在必然的。
综上所述,NPU硬件架构的演进,其总体特性可以归结如下:
软件定义架构:当前行业云化和数字化推动软件架构从单体应用架构 - 垂直应用架构 - 分布式架构 -SOA 架构 - 微服务架构的演变。对于大算力NPU的硬件架构而言,其演进也不言而喻,同样需要解决高并发、大吞吐等问题,针对算法的多样性需求,同样需要通过软件定义架构,来实现底层微架构硬件的可配置、可调度、可弹性扩展特性,以及顶层架构的微任务与多并行调度,提升底层PE与数据通道的效率均衡,减少数据流的无效搬移与无效计算,提升能耗比和算力效率。
弹性负载均衡:对NPU微架构中的存储与计算PE而言,可配置意味着可以通过片上的控制逻辑来动态配置细颗粒度的PE阵列,通过Array+Vector异构组合的SHAV弹性架构,来适应算法中多形态的算子尺寸和数据流变化需求。对NPU顶层架构而言,微任务与多并行调度意味着,多核的SHAV计算模块,可以通过高带宽的分布式数据总线来搭建实现多核的弹性扩展。
联合优化设计:对NPU中模型-硬件联合设计而言,具体的实现策略体现在:
1)降低计算资源需求的策略,例如3x3卷积Conv可以通过面向通道的Conv3x3 +Conv1x1来实现,Conv5x5以上可以通过Conv3x3 +Conv1x1组合来实现;
2)逼近计算策略,可以通过低比特数据优化表征HFP8/INT8/INT4/IN4+Quantization-aware后训练来实现;
3)压缩与稀疏计算策略,可以通过模型裁剪与优化,参数统计从偏置分布向零分布调整,以及类似参数扰动+列打包的RL压缩编码来实现;
4)模型-硬件联合搜索,可以认为NPU预定义的硬件架构是模板,网络模型ASIC-NAS在有限硬件计算空间内进行DNN的模型搜索和模型小型化,寻求计算单元的最佳组合模型来提升相同计算复杂度下的等效算力效率。
达芬奇架构NPU


ADS-NPU芯片架构
AI算法在自动驾驶ADS领域的行业应用,其当前从感知到认知的演进方向,主要体现在:
1)能够在统一空间支持多模传感器感知融合与多任务共享,在提升有限算力的计算效率的同时,确保算法模型在信息提取中对极端恶劣场景(雨雪雾、低照度、高度遮挡、传感器部分失效、主动或被动场景攻击等)的泛化感知能力,降低对标注数据和高清地图的过度依赖;
2)预测与规划联合建模,离线与在线学习相结合,监督与自监督学习相结合,从而能够处理不确定性下的安全行驶与有效决策,提供认知决策行为的可解释问题,通过持续学习解决新场景问题。
当前,对应于ADS传感器负载多样化和融合感知决策算法多样化的演进趋势,ADS的算力需求和芯片加速能力以(十倍速/每几年)的持续高增长态势呈现。ADS领域大算力NPU芯片的当前发展现状,真可谓是:大算力之时代,以感知策,四两拨千斤者;狂洗牌乎战局,唯快应变,一力降十会也。

图1. DNN任务占比分析: CNN vs Transformer
(图表分析来自文献1)
如图1 所示,ADS算法从Compute-bound向Memory-bound演进。ADS的存算混合需求,可以通过“硬件预埋,算法迭代,算力均衡“ ,来提供一个向前兼容的解决方案,以通用大算力NPU设计来解决算法未来的不确定性,具体体现在:1) 底层架构的演进:从存算分离到近内存计算,最终走向内存计算; 2) 数据通道与模型:高速数据接口+数据压缩+模型压缩+低精度逼近计算+稀疏计算加速; 3) 并行的顶层架构:模型-硬件联合设计,以及硬设计可配置+硬件调度+软运行可编程调度引擎。
老子曾曰“合抱之木,生于毫末;九层之台,起于垒土;千里之行,始于足下。” 老子又曰 ”天下难事,必作于易;天下大事,必作于细。”处理艰难问题从易入手,致力远大目标从微着力。ADS-NPU芯片的架构设计,同样需要用【见微知著】的能力,来解决异构计算、稀疏计算、逼近计算、内存计算等几类常见的难题与挑战。
- 异构计算之设计挑战

图2. 脉动阵列架构(图表分析来自文献1)

图3. 可配置的脉动阵列架构(图表分析来自文献1)
对比CPU十百级的并行处理单元和GPU上万级的并行处理单元,NPU会有百万级的并行计算单元,可以采用Spatial加速器架构来实现,即Spatial PE空间单元阵列通过NoC,数据总线,或跨PE的互联来实现矩阵乘运算(全卷积计算或全连接FC计算)、数据流高速交互、以及运算数据共享。
粗颗粒度的可配置架构CGRA是Spatial加速器的一种形态,即可配置的PE Array通过纳秒或微秒级别可配置的Interconnect来对接,可以支持配置驱动或者数据流驱动运行。
如图2和图3所示,脉动Systolic加速器架构也是Spatial加速器的一类实现方式,其主要计算是通过1D或2D计算单元对数据流进行定向固定流动处理最终输出累加计算结果,对DNN输出对接卷积层或池化层的不同需求,可以动态调整硬件计算逻辑和数据通道,但存在的问题难以支撑压缩模型的稀疏计算加速处理。
NPU的第二类计算单元是Vector矢量加速器架构,面向矢量的Element-wise Sum、Conv1x1卷积、Batch Normalization、激活函数处理等运算操作,其计算可以通过可配置的矢量核来实现,业界常用的设计是标量+矢量+阵列加速器的组合应用来应对ADS多类传感器的不同前处理需求和多样化算法模型流水线并行处理的存算混合需求。
NPU SoC也可以采用多核架构技术,即提供千百级的加速器物理核来组件封装和Chiplet片上互联提供更高程度的平行度,尤其是适合大算力下高并行数据负载,这需要底层硬件调度与上层软件调度相结合,提供一个分布式硬件计算资源的细颗粒度运行态调用。
NPU另外一个在演进中的内存处理器PIM架构,即通过将计算靠近存储的方式来降低数据搬移能耗和提升内存带宽。可以分成近内存计算与内存计算两种类型。近内存计算将计算引擎靠近传统的DRAM或者SRAM cell,保持设计特性。
内存计算需要对内存cell添加数据计算逻辑,多采用ReRAM或者STT-MRAM新型工艺,目前采用模拟或数字类型的设计,可实现>100TOPS/Watt的PPA性能,但技术难题是如何在运行态时进行大模型参数动态刷新,工艺实现可能也落后于市场预期。

图4. AI算法模型负载的算子分布统计(图表分析来自文献2)
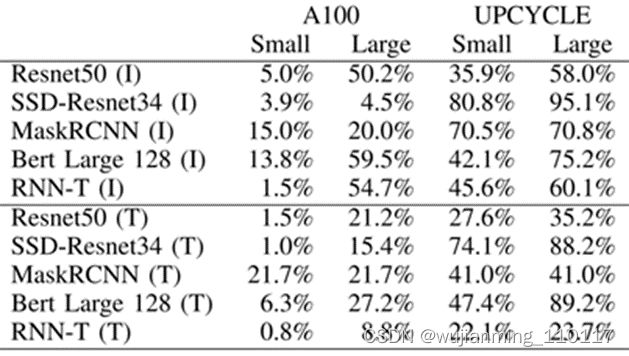
图5. nVidia A100的TensorCore架构与UPCYCLE 融合架构的计算效率对比
(图表分析来自文献2)
当前市场上主流AI芯片,常用的架构有以下几种形态:1) GEMM加速架构(TensorCore from nVidia, Matrix Core from AMD); 2) CGRA (初创公司); 3) Systolic Array (Google TPU); 4) Dataflow (Wave, Graphcore,初创公司); 4) Spatial Dataflow (Samba Nova, Groq); 5) Sparse架构 (Inferentia)。
如图4与图5所示案例可以看出,ADS-NPU设计其中有一个挑战是低计算效率问题。异构计算架构一个主要的目的是希望从设计方法学上找到一个硬设计时优化可配置与软运行时动态可编程的平衡点,从而能够提供一个通用的方案覆盖整个设计空间。
另外值得一提的是,UPCYCLE 的融合架构案例,涉及到SIMD/Short Vector, Matrix Multiply, Caching, Synchronization等多核优化策略,这个案例,说明只是通过短矢量处理+传统的内存缓存+同步策略的传统方法结合,在不使用标量+矢量+阵列的微架构组合条件下,依旧可以从顶层软件架构层面的优化(指令集和工具链优化策略,模型-硬件联合优化)来实现7.7x整体计算性能提升与23x功耗效率提升。
2. 稀疏计算之设计挑战
ADS-NPU低效率计算问题,从微架构设计领域,可以涉及到:1) 稀疏数据(稀疏DNN网络,或者稀疏输入输出数据)导致PE对大量零值数据的无效计算问题;2)PE之间由于软件硬件调度算法的效率低,PE之间互相依赖导致的延迟问题;3)数据通道与计算通道峰值能力不匹配导致的数据等待问题。
上述问题2和问题3可以从顶层架构和存算微架构设计上来有效解决。问题1可以对稀疏数据进行压缩处理来有效提升微架构计算单元PE的效率。如图6和图7所示,稀疏数据图编码的案例,可以有效提升数据存储空间和对数据通道的冲击,计算单元依据非零数据NZVL分布图进行有效甄别计算,以添加简单的逻辑单元为代价就可以将一个72PE的计算效率提升到95%,数据带宽降低40%。

图6. 稀疏计算微架构案例(图表分析来自文献3)

图7. 稀疏数据图编码案例(图表分析来自文献3)
3. 逼近计算之设计挑战

图8. 算法模型与量化表征的关系案例(图表分析来自文献6)
算法模型与量化表征的关系案例如图8所示,逼近计算设计可以通过算法模型的低比特参数表征+量化后训练的方式,在不降低算法模型精度的情况下,通过时间和空间复用的方式,等效增加低比特MAC PE单元。
逼近计算的另外一个优势是可以与稀疏计算相结合。低比特表征会增加数据的稀疏特性,类似ReLU等激活函数和池化计算也会产出大量零值数据。另外浮点数值如果用bit-slices进行表征,也会有大量高位零比特特征。
零值输出数据意味着可以通过预计算可以直接跳过后续大量的卷积计算等。如图9所示的案例,其中简单的bit-slice数据分解表征会产生偏置分布,可以通过Signed Bit-Slice方法来解决,从而将PPA性能有效提升到(x4能耗,x5性能,x4面积)。

图9. Signed Bit-Slice和RLE游程编码案例 (图表分析来自文献4)
4. 内存计算之设计挑战
ADS-NPU设计其中有一个挑战是数据墙问题能耗墙问题,即计算单元PE存算分离设计导致数据重复搬移,数据共享困难,数据通道与计算通道峰值能力不匹配会导致PE的低效率和SRAM/DRAM高能耗。
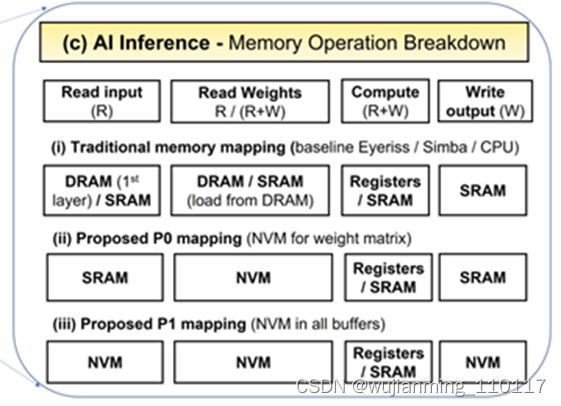
图10. MRAM取代SRAM案例 (图表分析来自文献5)
一个有趣的尝试是用新型工艺MRAM (STT/SOT/VGSOT-MRAM) 来部分或全部取代SRAM, P0方案是只取代算法模型参数缓存和全局参数缓存;P1方案是MRAM全面取代SRAM。对比SRAM-only架构,从图10 的案例可以看出MRAM-P0解决方案可以有>30%能耗提升,MRAM-P1解决方案有>80%能耗提升,芯片面积减少>30%。

图11. Von Neumann与内存计算的架构对比 (图表分析来自文献6)

图12. 内存计算的模拟墙问题 (图表分析来自文献6)
当前初创公司的内存计算架构策略需要对内存cell添加数据计算逻辑,通过采用ReRAM或者STT-MRAM新型工艺,采用模拟或数字类型的设计来实现。模拟内存计算IMC对打破传统的Von Neumann计算机架构内存墙和能耗墙应该更有优势,但需要同时打破设计中的模拟墙问题,这也是当前数字设计IMC-SRAM或者IMC-MRAM占多数的原因。
如图11和图12所示,IMC的主要问题来自于模数转换ADC/DAC接口和激活函数的接口带来的设计冗余。一种新的实验设计是用基于RRAM的RFIMC微架构(RRAM cells + CLAMP circuits + JQNL-ADCs + DTACs)。每个RRAM cell代表2比特内存数据,4个RAM cell来存储8比特的权重,JQNL-ADC采用8比特浮点数。
从图13可以看出RFIMC的微架构能够部分解决模拟墙的问题,可实现>100TOPS/Watt的PPA性能,但存在的问题是,只支持小规模的全矢量矩阵乘,超大尺寸的矩阵乘,需要将模拟数据进行局部搬移,是否有数据墙的问题仍未知。

图13. RFIMC的性能分解图 (图表分析来自文献6)
5. 算法-硬件之共同设计挑战
ADS算法多样化的演进趋势和对NPU大算力存算的混合需求,需要算法-NPU联合设计来实现模型整体效率。
常用的量化与模型裁剪能够解决一部分问题,模型-硬件联合搜索,可以认为NPU预定义的硬件架构是模板,网络模型ASIC-NAS是一个典型的案例,即在有限硬件计算空间内进行DNN的模型搜索和模型小型化,寻求计算单元的最佳组合模型来提升相同计算复杂度下的等效算力效率。
NPU添加了硬件的可配置和细颗粒可调度,但依旧存在很大的性能约束性。如图14 和图15所示,SkyNet算法与硬件共同设计的案例,是将NPU细颗粒度的PE单元进行Bundle优化封装,其价值在于可以降低NAS架构搜索的高维空间,从而减低对硬件底层架构的依赖关系和优化算法的复杂度。

图14. SkyNet算法与硬件共同设计案例 (图表分析来自文献7)

图15. SkyNet-Bundle-NAS示例 (图表分析来自文献7)
自研架构NPU
目前手机市场中,AI已成为标配,但手机里的AI够不够聪明,还得看手机芯片里的NPU是否够强大。那么,NPU到底是什么呢?
NPU:手机AI的核心载体
大家都知道,手机正常运行离不开SoC芯片,SoC只有指甲盖大小,却“五脏俱全”,其集成的各个模块共同支撑手机功能实现,如CPU负责手机应用流畅切换、GPU支持游戏画面快速加载,而NPU(神经网络处理器)就专门负责实现AI运算和AI应用的实现。

在手机SoC中,NPU扮演最聪明的角色,并直接影响手机AI能力的强弱。2017年,华为推出自研架构NPU,相比传统标量、矢量运算模式,华为自研架构NPU采用3D Cube针对矩阵运算做加速,因此,单位时间计算的数据量更大,单位功耗下的AI算力也更强,相对传统的CPU和GPU实现数量级提升,实现更优能效。

AI究竟怎么用?
2017年,Alpha狗打败围棋第一人柯洁,被科技行业认作AI技术的里程碑,与此同时,网络上AI毁灭论甚嚣尘上,阻止AI技术发展的声音不绝于耳,然而,技术是一把双刃剑,只要将AI应用在更多贴近日常生活需求的场景里,AI能够为带来更多便利。
基于端侧AI技术的深厚积累,华为联合开发者及合作伙伴率先落地了不少AI应用。例如,2018年麒麟980实现了AI姿态识别功能,能在人物快速运动的状态下,准确识别人体骨骼线条,为AI应用开发提供更多基础能力。

2019年,麒麟990系列实现AI人像实时分割能力,能精准分割人物和背景,并将背景实时替换,相比其他手机实现的换背景功能,麒麟990系列还能精准识别每一个个体,并将其移除画面,为更多视频类的AI应用提供新的玩法和可能。

除了芯片层面的AI能力外,目前搭载麒麟990系列的华为Mate 30系列已经实现一系列AI应用。其中,AI随心支持手机屏幕实时跟随人脸,无需重力感应,手机界面就能跟随面部方向实时旋转,看视频不用反复开关锁定屏幕。

AI隔空操控可以实现不触屏的滑动、截屏交互动作,有了AI隔空操控,过年也能一边包饺子一边刷抖音,寒冬也能带着手套隔空滑动浏览网页,这个功能可以说是非常实用了。
![]()
Mate 30系列AI应用的背后,是麒麟990系列的AI能力加持。据了解,麒麟990系列采用华为自研达芬奇架构NPU,创新设计NPU双大核+NPU微核架构,其中,NPU大核负责处理大算力场景,如AI姿态识别、AI实时换背景,而轻量级的AI应用如AI随心、AI隔空操控则由NPU微核处理,占用更少的资源,也进一步提升了NPU的性能和能效。


不仅如此,华为在为消费者带来AI智慧应用的同时,也在鼎力推动开放AI生态,基于华为推出的达芬奇架构NPU和HiAI 3.0,麒麟平台为开发者提供更强大完备的工具链和更强大的端侧算力,截止2019年12月,HiAI 3.0日活用户已接近1亿,月调用量超过6000亿。

如今进入2020年,AI也将搭载5G的快车,实现算力和能力的跃迁,真正开启万物互联的智能世界,相信在华为等科技巨头的引领下,手机AI会变得更加智慧,更加实用,为带来更多炫酷的AI功能。通过这幅漫画,读懂NPU了吗?
自研架构昆仑芯XPU-R
01
AI无处不在

AI在最近十年左右蓬勃发展,一开始在学术界、算法上有很多突破,随后在语音、图像、自然语言处理等多个领域的准确率均实现大幅度提升,甚至在一些评价标准上超过了人的能力。这使AI技术得到了很多落地应用机会,同时也有更多更好的AI算法出现,更好地服务这个产业。
可以说AI已经成为一个应用非常广泛的技术,这也是要用AI做一款通用计算架构的原因。
02
AI计算需求驱动架构创新
首先,认为AI算法的应用场景足够广阔,值得为此去设计一款针对AI通用的架构,这是基础。
其次,已有的传统处理器架构解决方案实际上不太能满足AI的计算需求。
这张图(下图右)是近些年来AI算法对算力的一些要求,可以看到增长非常快,基本上是每3.5个月,对AI算法计算量的要求就翻一倍。

这张图(上图左)是传统处理器细分的一些性能指标提升的情况,可以看到很多曲线已经出现了明显的瓶颈。
比较影响处理器性能的几个因素,比如工作频率、单线程的性能以及核心数量的提升速度,其实都没办法做到很高的速率。这是物理上的限制,因为频率没办法无限制地提高。工作频率的提高取决于底层晶体管充放电的速度,这是有一定瓶颈的。工作频率的提升会导致芯片的功耗增大,对散热问题也是一个非常大的挑战。
从技术上来讲,单核性能在技术上的突破也已经到了瓶颈。目前单线程已经做得很好,包括一些分支跳转的推测执行技术,这些技术上来之后,单线程性能还如何继续发展?并没有一个非常明确的答案。
综合来看,传统处理器的架构很难追上AI算法的需求。即使先不考虑这些技术,只看晶体管数量,18到24个月翻一倍的速度也追不上AI算力发展的需求。也就是说,AI算法应用已经足够广阔,需要一个计算架构,但现有的这些计算架构又没办法满足需求。
正是这样一个契机,可以在AI领域做一款全新的、领域专用的计算架构,这也是团队十年来做的一件事。
03
昆仑芯XPU架构——十年磨一剑
2011年开始做AI异构方向的相关工作,是非常早的一个时间点,AI浪潮刚刚起步。在这么一个时间点,就已经开始尝试用异构计算方法做一款自定义的计算架构为AI加速,这是非常领先的。
在这个期间,以FPGA为平台。FPGA究竟是什么?简单来说,是一个可编程的芯片。这个编程编的是电路结构,而不是软件代码。可以依托可编程性实现想要的计算架构。
在技术开始迭代的初期,利用FPGA的可编程性去实现架构是比较好的选择——不涉及流片之类的问题,是一个比较成熟的商业产品,只需要专注于这个架构本身。做的事情主要是专注于怎么把这个电路架构设计好,那段时间迭代了很多个版本。
2013年,有第一代基于28nm的FPGA加速卡,也发现了更好的架构设计,使AI的计算效率能够成倍提升。

首先,肯定是要仔细分析AI算子的计算特点以及访存特点。同时,也发现在AI领域,尤其是推理领域,定点化是一个非常关键的技术,这可以使得核心计算单元从浮点转向定点,由此实现能耗效率的飞跃。
早在2013、2014年,就开始做这种定点化的工作,直到2016年GPU才在Pascal架构上首次引用了定点支持,可见在这一方面是非常领先的。
2015年,推出第二代基于20nm的FPGA板卡,当时这代产品相对于同时代的GPU有2倍以上的性能优势。
经过多年积累,2017年逐个突破了各种各样的AI领域场景——从语音到推荐类、图像类、自动驾驶类的场景,逐渐做到了AI领域内全场景的支持。
也是基于这一点,2017年,整体的FPGA部署超过了一万两千片,是当时国内最大的FPGA集群。2017年,架构已经基本达到在AI领域内通用的水平,可以说这个架构整体的成熟度已经比较高了。
然而,FPGA平台也出现了一些不足之处。作为一个商业产品,制造出来时的规格是确定的,然而想要有更大的空间、更大的自由度,让架构更好地发挥能力。由于在FPGA上已经做了足够多的迭代,所以当时做好准备跳过FPGA完全自主地定义芯片的spec。也就是从那时候,转向了自研芯片。
2018年,昆仑芯项目正式启动。2019年,一次性流片成功,昆仑芯1代AI加速芯片,以及对应的AI加速卡产品也出来了。经过加速卡的调试以及相关软硬件产品和生态的完善,2021年第一代产品取得了非常好的成果,量产超过两万片,也是国内量产落地最大的、规模最大的AI芯片。
这就是十年来在AI加速通用架构领域积累和成长的过程。在这个过程中,总结出了几点经验。从产品定位上讲,如果要使产品或技术架构有长期生命力,有几点非常重要。
04
具有长期竞争力的产品定位
1
通用
足够通用,用户才能更好地利用产品去支持不同种类的work load。不仅仅是从产品角度,从技术角度来说,通用也是非常重要的一点。之前在做这种AI场景的时候发现,如果用非常专用定制的技术去支持不同场景,技术的生命力或者说使用周期是非常短的,会造成研发成本浪费、研发效率低下,技术也没有什么积累,因为基本上换个场景都得重新去做。而且,如果做不到通用就没办法自己做芯片。可能在FPGA时代还勉强可以支撑,但如果真的要实打实做芯片,没有通用的技术能力就无从谈起。
2
易编程
这对芯片的使用者,也就是软件的开发者来讲非常重要。会非常关注究竟有多大的可能性在芯片上做开发。如果算法有迭代升级,是否能够很快支持,所以这一点非常关键。从技术方面来说,只有在芯片的架构有足够的灵活性、足够多的数据通路和计算模式的支持,并且要支持足够多的参数、编程接口的情况下,才能很好地满足用户在不同编程场景下的需求。
3
高性能
高性能其实是一个非常基础的要求。因为毕竟是在做一个全新的AI技术芯片架构,如果没有高性能,用户没办法从现有计算架构上迁移过来。是一个全新的、面向AI的通用架构,高性能是基础能力。
4
TCO
TCO非常重要,关系到用户在产品周期中究竟要付出多大的代价。这对技术提出了很多要求。首先,芯片的资源效率一定要非常高,要在尽可能少的面积下实现非常多、非常高效的算力和功能,这样才能降低芯片整体的生产成本。其次,功耗水平要控制在一个范围之内。比如每瓦的算力要能达到一个比较高的水平,这样才能使芯片所代表的硬件产品部署到用户的实际场景时,功耗所带来的供电成本被控制在一个比较好的水平。
5
自研创新
这是比较核心的一点。芯片的关键IP,即具有核心竞争力的这部分必须是自研的,这样才能有长期技术迭代的可能性。一直在坚持核心的AI通用计算IP,这部分一直是自主迭代、完全自研、完全自主知识产权的状态。
这就是产品的定位,也是已经能做到的产品的特点。从技术本身来说,无论是学界还是产业界,都非常认可技术能力。
05
技术领先学界和产业界


首先,从Hot Chips来看,这是一个非常顶级的芯片界会议,在这个会议上发表了四篇论文,也是国内同一个团队发表次数最多的记录。也是其中几篇论文的作者之一。
从这些论文中就能够看到昆仑芯XPU整个架构迭代的思考和变化。在2014年的这篇文章中,提出了这个架构(图示),从今天的角度来讲,其实是一个比较偏向定制的版本,流水线是一个非常专用的部件,所有的计算顺序一定是按照这个流水线的定义去走,同时设计了很多专用的buffer来支撑计算单元的计算。这个版本也是FPGA时代的一个雏形版本。
后面,在不断迭代的过程中,最终形成了一个更偏向于通用计算处理器的架构。可以看到(图示)这时候没有了特别多定制化的数据通路或定制的ALU组合的顺序,而是多个通用核和多个加速单元的形式,更有利于通用性跟灵活性的发挥。在做到这一点的同时,也保持了非常好的实际性能和效率。
当时在做这方面的工作时,并没有其他资料可供参考。回过头来看,谷歌也是多年之后才发表了之前的一些架构。
2017年谷歌把TPU,也相当于是AI加速芯片TPU的第一代芯片的架构披露了出来。当时内部的思想其实和想法有很多共通之处——有很多定制的流水线通路。后面,在披露第二代TPU时,可以看到转向了一种更加通用的计算模式。虽然没有了解过对方是怎么做的,但是从后面大家发表的论文来看,其实一直是站在国际第一梯队。对技术趋势的判断,对架构迭代的趋势后来也得到了科学验证,是非常符合整个发展趋势和潮流的。
06
AI计算特点和解决思路
接下来说一下是怎么去设计昆仑芯XPU架构的。

首先,从开发者或者说应用上来看,大家更多关心的是多种场景,以及对应的模型。但是在架构设计者眼里,更多关心的是模型背后的算子。在这么多年的迭代过程中,把这些算子分为两大类。
第一类,出现频率非常高的,比如说像全连接、卷积、bn、ln这些,很多的神经网络中都会有,而且不仅是某一类的神经网络,比如语音、图像,都有这种全连接层和激活。这种算子出现频率非常高、计算量大,可能抓取十多个算子,总耗时就能达到某个模型的90%以上,计算量和耗时占比都非常高。一句话来讲,这类算子的数量相对没有那么多,但性能至关重要。对于这部分算子,希望用相对专用定制的加速器的电路形式去实现,来提升整个架构的实现效率,同时还要有一定的可编程性。比如虽然做的是卷积,但是卷积有非常多的规模参数,比如图像的长宽高所需要的参数是非常多的,这就需要参数能够做到全部、全面、灵活的支持,所以说架构本身要有一定的可编程性。虽然可以用这种专用定制电路去提升能耗、效率或者性能,但是仍然要保留一定的可编程性。
第二类算子的特点相对来说不太好把握,数量很多。芯片不仅支持推理还需要支持训练,这里面的算子就非常复杂,而且计算类型很丰富,很难总结出这部分算子的规律、特点。同时在不断变化,每一年都会发现新的算子变种、变形,已有算子很难把这些东西cover掉,或者说很难保证未来几年之内都是这一些东西。同时甚至还有一些算子,干脆就是用户自己发明的,这些自己定制、创造出来的东西很难在芯片设计时把握清楚。
对于这部分算子,处理的思路也是不断迭代的。一开始思考放在CPU上,直接用CPU跟芯片协同解决这个问题。然而,一旦用CPU计算,一方面性能肯定会很差,因为算力不足,同时,会引入很多CPU跟AI芯片之间的通信开销,非常影响整体端到端性能的上限。
接下来想到运用定制电路模块化的思路,比如说搞一个电路库,每个算子有不同的电路实现,对不同的模型可以用不同的电路去组合、完成。这种思路其实在之前做FPGA的时候可能勉强可以,毕竟FPGA有可编程性。
但真的要做高性能自研芯片,这个思路显然是不现实的——不可能所有算子库的对应电路全都放在芯片上,这样的面积根本没法收敛。最终,决定做一个自研的通用处理器,用通用处理器的思路去解决这部分算法。
07
通用AI计算架构的优势
最终实现了通用AI计算处理器的昆仑芯XPU-R架构。相对CPU跟GPU,主要的区别和优势在哪里呢?
从这个图中可以很明显看出来,CPU很强调通用性及单核的性能。用了很大一部分逻辑在控制单元的各种优化上。比如说,对这种分支跳转的优化,有复杂的Cache结构去保证寄存器的读写效率。真正用于计算来讲,这种部件并不多,所以通用性、单核性能会比较好。但是在这种AI场景下,反而总体的性能或者TCO都是比较差的。
GPU相对CPU更加适合AI计算,因为每个核里面没有那么多控制单元,其实是把更多资源放在了计算部件上。同时,近些年来为了进一步提升GPU,也引入了一些定制单元,为了和架构做兼容,这些定制单元用的是小核的思路,就放了很多小的定制的计算单元。
架构相对于其中这个AI计算层面来说,做得更加彻底,效率更高:
1)加速计算单元的计算密度非常高,因此相对于CPU,整体上的性能、能耗效率有非常大的提升。
2)不仅是做计算部分,针对AI算子的特点,在计算单元的周围做了很多非常精细的数据整理和处理,整个数据通路的设计非常贴合AI算子的特点,这使得加速计算单元这部分的整体效率非常高。
3)也有通用计算单元,这部分性能也非常高。通用计算单元内部对于一些复杂算子的处理能力,比GPU相同的计算单元更强。这也是之前的这张PPT上讲的思路,用这种通用加专用的架构去解决AI计算的一些核心挑战,使得在高性能、TCO通用性和易编程这几个维度做到了全面的水平。
08
全面增强的昆仑芯2代
下面主要介绍一下昆仑芯2代相对于昆仑芯1代的一些特色优势。
高性能分布式AI系统
昆仑芯2代能够支持芯片和芯片之间直接的互联和数据传输。这一点对分布式训练非常有帮助。可以直接在多芯片之间交换训练一些中间结果。同时,近两年的趋势是推理模型中其实也有分布式推理的需求,片间通信的能力使得很多模型级并行、数据级并行的通讯需求都能够得到很好的满足。
支持硬件的虚拟化
可以做到从硬件角度使计算单元跟存储单元实现物理隔离,避免多个用户之间相互影响,保证每个用户的延时和吞吐,更好地提升芯片整体的利用率。
增强的通用计算能力
首先从峰值的性能,主要是FP16、INT16性能来讲,从spec上做了一个翻倍提升。同时,对模型中具体计算的瓶颈做了架构优化,使在真正的实际业务模型的处理上,效率相对于第一代有更进一步的提升。可以看到一些模型相对于昆仑芯1代的实际性能的提升倍数会超过spec本身的提升。
看一下主要参数。昆仑芯2代采用7nm先进工艺,也是第一个使用GDDR6显存的AI芯片,同时实现了256 TOPS@INT8的超高算力,把功耗控制在了150W以下,和CPU之间的连接采用的是PCIe4.0的接口。
09
昆仑芯XPU-R架构
这是昆仑芯2代XPU-R架构以及SoC上一些部件的总体框图。
可以看到多个XPU Cluster单元和XPU SDNN单元,这两部分分别对应计算加速单元、通用处理器单元。称SDNN为软件定义的神经网络引擎,这部分是计算加速单元,主要处理比较高频的、计算量大的张量跟向量运算,能灵活实现卷积、矩阵计算,还有激活等操作。Cluster是通用计算核,内部是有一些标量跟向量计算,向量主要是SIMD指令集,同时每个Cluster的内部有很多XPU Core。Cluster具有很高的通用性和可编程性。整体来讲,架构本身的灵活度就可以使对这种XPU Cluster的编程做到非常细粒度。
除了这两大核心的计算IP之外,还有一些其他的SoC上的部件,包括Shared Memory。可以提供一个软件完全显示管理的大容量的Memory,能够大幅提升带宽。还有片间互联,以及跟主机连接的PCIe的接口。同时还引入了Video Codec,这实际上是视频编解码以及图像预处理的功能。这可以使在一些图像的端到端的领域,有全场景的、端到端的计算支持。
同时,还有安全模块,可以提供通信通道和安全服务,实现从主机到昆仑芯芯片整体的安全机制的保护,保证所有的模型数据不被攻击者窃取。
10
丰富的产品线涵盖多种场景
图中是昆仑芯XPU-R架构承载的硬件产品。无论是比较高性能的单机多卡训练场景,还是PCIe加速卡以及一些对加速卡的尺寸跟功耗要求比较严格的场景,都有对应的硬件产品。比如R480-X8,内部有8块昆仑芯2代芯片,可以总体达到2P的INT8的计算能力。
11
性能表现全面优于竞品
从性能上来看,也全面优于竞品。包括GEMM(通用矩阵乘法)、BERT(自然语言处理模型),以及图像检测和分类的两个模型,在这些模型上相对竞品有明显性能优势。

总结来看:昆仑芯架构在技术层面可以做到独立自主,架构是完全自主设计和实现的;同时,灵活易用,软件栈非常完善;最后,规模部署,有多个产品并且实现了两万片以上的落地案例。
ISP+NPU融合架构
麒麟9000作为华为新一代5nm 5G SoC,在影像系统领域实现了跨越式升级,业界首次实现了ISP+NPU融合架构,将超强的细节还原、降噪能力带入视频领域,使暗光环境下拍摄的视频更加清晰、细节更加淋漓尽致。
ISP+NPU融合架构到底是什么?一张图看懂

通用NPU与针对自动驾驶系统NPU的差异点和挑战
未来几十年,自动驾驶技术将重塑整个社会。当车内的乘客可以将手和注意力从驾驶中释放出来,这将颠覆现在大部分的商业模式,例如购物、视频、游戏等。同时,交通运输的效率也将大幅提高, 人类社会将会得到极大的提升。
但现在对于自动驾驶和智能汽车行业来说,还处于非常早期的阶段,只有L2和L3的解决方案部署在高端汽车上,而L4以上目前还没有成熟稳定的解决方案。特斯拉、华为、小鹏、蔚来等厂商推出了L3/L4自动驾驶解决方案,而大众、福特、捷豹、路虎等传统汽车厂商也在部分产品中推出了不低于L2的自动驾驶解决方案。
然而,为了实现这个梦想,需要无限的计算能力、无限的存储空间、超强的可靠性,当然,这些不仅只是针对豪华汽车,而是普惠车型上也能实现让每个人都能负担得起的成本。这与过去十年智能手机市场所发生的情况如出一辙。
相信中国在未来十年可以成为自动驾驶的领先营销之一,因为中国有许多新的电动汽车巨头,如蔚来、小鹏、理想、比亚迪和吉利汽车,另外加上政府正在积极鼓励电动汽车取代传统的汽油动力汽车,以实现产业升级。

预计,到2025年之前超过50%的新车销售将提供L2/L3自动驾驶功能,到2030年这一数字将增加到90%。到2030年,汽车芯片整体市场规模将达到1150亿美元,占整个芯片市场的11%。
阻碍自动驾驶普及的原因有很多,除了在所有复杂的真实环境中仍然没有足够的来自车队的测试和验证数据外,个人认为计算能力是限制L4以上自动驾驶的主要因素。典型的L4自动驾驶系统会有4-6个雷达,1-6个激光雷达,6-12个摄像头和8-16个超声波。传感器将产生共计3Gbit/s (~1.4TB/h)到40gbit /s (~19 TB/h)之间的数据。
例如,Waymo的自动驾驶汽车有8个摄像头、6个雷达和6个激光雷达。为了处理这些数据,对于L4自动驾驶来说,计算能力要求可能在1000TOPS以上,而L5可能是L4的10倍,达到10000TOPS。不过,目前主流的解决方案也只有100TOPS-250TOPS左右。
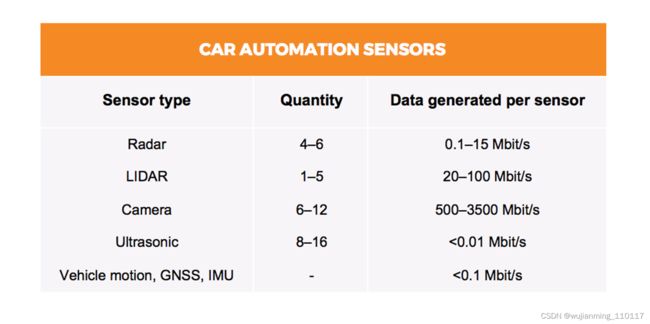
然而,用于自动驾驶系统的NPU并不仅仅是计算能力,可能有其独立于一般NPU的特点。为了设计出具有竞争力的自动驾驶NPU,需要同时理解通用NPU和ADAS NPU所面临的挑战。
通用NPU和超大算力芯片组面临的巨大挑战
随着摩尔定律失效,通用NPU和超大算力芯片面临的主要挑战可以从功耗墙、内存墙和利用墙等方向着手分析问题和挑战;
功耗墙:下图展示了微处理器发展的40年趋势。从20世纪70年代到现在,晶体管的密度以指数级的速度增长,频率和单线程性能也同样增长,直到2000年代中期,登纳德微缩失效。因此,峰值的时钟速率稳定在3-4 GHz左右,功耗峰值在几百瓦的范围内。

通常下一代CMOS工艺比上一代的晶体管电容(以及开关功耗)的下降幅度约为S倍(比例因子,例如32nm工艺对比22nm工艺尺寸下降了1.4倍),同时晶体管开关频率可以提高S倍,而相同尺寸的芯片上的晶体管数量增加了S^2。
在登纳德微缩理论有效的情况下,可以将阈值缩放为1/S,因为不存在短沟道效应,漏电流没有上升,而单个晶体管的电容值也下降了S倍,因此在芯片最高频率可以提升S倍,而晶体管数量增加S2,所以即使性能提升了S3倍,但是功耗却还是保持不变,因此并不会遇到功耗墙的挑战。
但是在登纳德微缩理论受限制的情况下,则阈值电压无法缩放,因为在极小尺寸下产生短沟道效应漏电流会上升到不可接受的水平,而单个晶体管的电容值也下降了S倍,则单个晶体管的开关功耗仅下降为1/S。如果把频率提升S倍,同时晶体管数量也增加了S2倍的话,在最高频率的功耗会上升到S2倍。

如下图所示,当芯片在工艺上65nm制造时,可以实现在1.8GHz频率下跑4个核。而演进至32nm时,则因子S=2,在相同的面积下可以实现2^24=44=16个核。假如由于设备散热的限制芯片的功耗需要保持一致,且登纳德微缩理论受限制,则要么保持频率不变为1.8GHz,则有8个核可以同时运行,其余8个核处于挂起状态;或者提升频率2倍为3.6GHz,则只有4个核可以同时运行,其余的12个核处于挂起状态;或者实现16个核同时运行在0.9GHz频率下。图中黑色区域表示处于挂起状态的核,灰色则表示运行在低频状态的核。

单位面积的产生功耗以及每TOPS消耗的功耗等要比单位面积的性能密度更为重要,因为除了对于少数对于尺寸空间极为受限的设备,大多数场景下芯片面积只是意味着成本,但是芯片的成本可以通过增加发货量摊薄。而能效比太差则会导致芯片发热,降低芯片可靠性,甚至使得整个设备失效。因此,NPU的设计主要需要考虑如果将上图黑色和灰色部分的面积有效地使用以提升芯片的能效比。可以考虑如下的几种方向:
1.利用由于先进工艺带来的多余面积实现针对专有任务的加速器或协处理器实现异构架构,使得在特定任务上比通用处理器快得多或节能得多。例如针对深度神经网络当中不同类型的算子可以通过专用的处理模块,例如卷积和全连接,Pooling和激活函数分别可以用不同的处理模块实现最高效率,而非在同一通用处理模块中实现。
2.通过动态电压和频率调节(DVFS)来实现功耗的调节,针对一些规模较大的深度神经网络,且时延和精度要求比较高的应用,则允许芯片暂时在频率翻倍情况下运行一段时间超过名义热预算,依赖热电容缓冲系统温度的升高,而针对规模较小的模型或者时延不敏感的任务,则配置是的芯片在正常低压低频的状态下实现最佳功耗。例如英特尔的turbo boost,海思的GPU Turbo都是采用类似的方案;

3.用低性能的众核跑在低频和低压上实现的并行计算来代替一个高频高压高性能的大核达到能效比的最大化。
如下图所示,虽然降低频率的同时也会降低处理器的速度,但是功耗效率可以得到提升,这是因为随着频率降低,工作电压也可以降低,从而导致Transistor的开关的动态功耗降低,而静态功耗主要来自漏电流几乎保持不变。
因此,可以看到将工作电压降低在阈值附近(NTV)可以实现最佳的能效比,而工作电压低于该值后漏电流会急剧上升,Transistor无法正常工作,阈值电压是由工艺决定的。另一方面随着DNN网络规模越来越大例如resnet,Inception以及VGG等等,同时并行度也越来越高,这样更易于能够充分利用并行计算在实时性满足的情况下提升能效比,这点对于端侧的AI芯片的尤为重要。

4.基于粗粒度可重构阵列(CGRA)的架构试图通过减少处理器内部的实现复杂数据路径的多路复用,大大简化PE的复杂度,减少流水线级数,则更容易实现之前提到的近阈值NTV运算,提升单个PE的能效比。同时根据PE单元的数据位带宽,设计粗粒度大于4 bits的可重构数据通路,这样即可以满足DNN在不同精度(4 bits,8 bits以及16 bits等等)下可配置的需求以实现推理的最高效率。
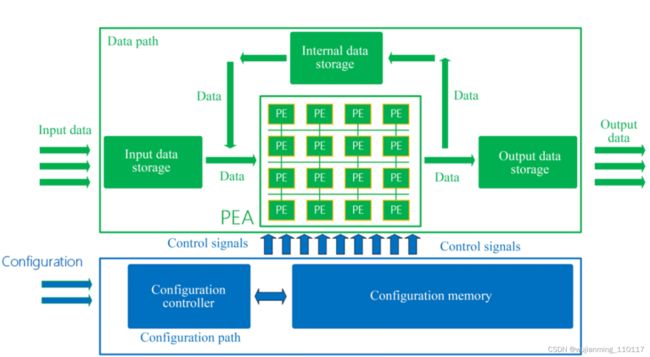
5.将多余的面积用于增加更多Cache或者on-chip SRAM,以减少由于cache miss导致从Off-Chip的数据读取,从而减少功耗的浪费。当然,设计片上Cache和SRAM需要匹配好PE的处理速率和存储带宽,使得三者之间没有相互限制。
内存墙:微处理器性能的提升速度远远超过DRAM存储速度的提升速度,因此处理器和片外DRAM存储访问之间存在着巨大速率差,如果处理器每条指令需要处理数据都从DRAM访问,那么会大大地降低处理器的性能。

因此需要在处理器和片外DRAM之间增加比DRAM访问速率更快的存储单元例如片内寄存器和cache等等,这就使得内存层次结构变得异常复杂。处理器在内存管理和阮存缺失上也会花费了大量的执行时间,这也会导致功耗的增加和性能的下降。

谷歌研究了在TPU中实现的边缘设备的谷歌神经网络模型(CNN, RCNN, LSTM和Transformer)的瓶颈是什么。有两个关键的观察结果:
1、62.7%的系统能耗是花费在数据移动上对于CNN模型,48.1%的静态能量和36.5%的动态能量花费在片上缓冲区的参数访问和存储上。在所有模型中,边缘TPU平均将50.3%的总功耗用于片外内存访问(包括DRAM能量和片外互连能量)。
2、数据移动的很大一部分通常来自内存中的简单函数,如乘累加和移位等等。

基础以上的两点观察,针对深度神经网络处理器的设计,要解决内存墙的问题,则需要从以处理器为中心的计算方式转换为以数据为中心的计算方式,即处理器中的计算函数搬移到数据存储的地方而非把数据搬移到处理器中进行计算。主要有如下两种思路:
解决方案1:内存计算,将应用卸载到PIM (processing in memory)中,降低能耗,提高性能。例如三星电子在2022年在Nature公开了首例基于MRAM的存算一体处理器,用于神经网络加速。该芯片构建了一个64×64的MRAM阵列,该论文中实现了将VGG类的人脸识别算法中的某一层offload到MRAM存算芯片上运行,从测试数据上看,仅用0.56mW就达到了0.63FPS的人脸识别速率,达到了极高的能效比。

解决方案2:将计算移至内存附近,甚至在内存中计算。如下图所示为一种以数据为中心的近内存计算的设计构架,最终该架构主要的思想为将函数(即计算和临时值)移动到需要更新的数据相近的核当中,而不是将存储在不同的内存分区的数据搬移到运行函数的核当中实现计算,主要通过三点设计实现:
(1)通过在逻辑层放置简单的in-order处理核心,有效地利用3D堆栈内存中的可用内存带宽,并使每个核心只能操作在垂直方向上被分配的内存分区上的数据
(2)在三维堆叠内存中不同的in order核心之间的设计一种有效的通信方法,使每个核心能够对由另一个核心控制的内存分区中的数据发起计算请求。
(3)设计一种基于消息传递的编程接口,类似于现代分布式系统的编程方式,允许对驻留在每个内存分区中的数据进行远程函数调用。通过以上几点设计:


利用率墙:
芯片的峰值计算能力是一回事,而AI芯片的利用率是另一回事。从下表中可以看到,对于不同的DNN型号,DNN加速器的利用率大多在50%以下。尤其像英伟达这类通用GPU的架构,实际利用率仅仅在30%以下。
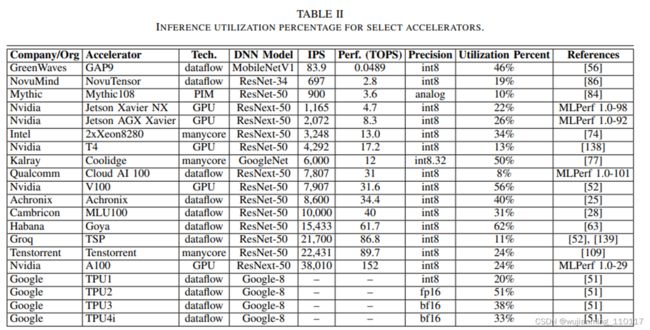
要提高DNN加速器的利用率,有以下几个潜在原因:1.针对特定硬件优化优化模型的结构和编程。例如,谷歌发布了EffecentNet - EdgeTPU,这是一个从EffecentNets衍生而来的图像分类模型,但针对谷歌的边缘TPU进行了定制化优化。原生的EffecentNets主要依赖于深度可分离卷积(depthwise sparable convolution),以减少参数的数量和计算量。
但是google研究团队发现在Edge TPU上较浅深度的输入张量(2242243)与较大的深度的输出张量(11211232)以及较小的卷积核尺寸(23)的组合具有较低的利用率(44.02%),而增加卷积核的大小,其中由于利用率的提高,内核大小的增加对运行时的影响较小。
因此在该情况下Edge TPU上一个常规的3x3卷积(右)比一个深度可分离的卷积(左)有更多的计算(乘法和累积(mac)操作),由于2倍的有效硬件利用率,常规的33卷积在Edge TPU上执行得更快。


2.反过来从硬件微架构角度,也要考虑如何高效地支持灵活的算子以适应不同DNNs实现高利用率。例如,华为Davinci AI核心实现了一个包含标量单元、矢量单元和立方体单元(Cube)的异构架构,提供conv 33、conv 11、Pooling、activation等各种神经网络需要的算子。
例如Cube的大小可定制为444、161616或323232等,可以支持不同精度如INT4、INT8到FP 16、FP32等等。矢量宽度可定制为32字节、128字节或256字节。立方体的大小和向量的宽度越大,那么计算密度就越高。然而,一些神经网络不能充分利用MAC,因此Cube单元可能会因为利用率而失去优势。
3.片外存储带宽,NPU核心计算能力以及片内存储大小的匹配以及合理的data path会影响NPU计算单元的利用率。这和之前提到的内存墙有点类似,一般NPU核心的算力增长要快于DRAM的访问速率,因此需要实现片内内存用作缓存。
一般神经网络的计算是以每一层为单元计算的,例如卷积层,pooling层等等。首先需要将输入以及权重数据从片外DRAM搬运到片内SRAM当中供计算单元PE使用,一旦PE需要处理数据在缓存中未命中,也需要去DRAM中访问,在数据搬运至片内SRAM中之前,PE单元处于饥饿状态,则利用率下降。
因此,需要一次性搬运好网络某一层所需要的所有数据能够快速搬运至SRAM当中,所有的中间结果也都可以再SRAM存储复用,不用写回到片外DRAM中。另外一般神经网络中的以层的输出往往就是下层的输入,因此输出数据也需要存储在SRAM当中复用,避免去片外DRAM读取。
自动驾驶NPU的特点和独特挑战
设计ADS系统中的NPU,不仅需要考虑在上一章提到的常见挑战。ADS系统有自己的特点,在设计NPU时需要考虑。
ADS系统的任务包括感知、感知、定位、规划、控制、驱动等。每个任务可能包含多个子任务,如感知内部的目标检测、识别和分割。而所有这些任务并不是相互独立的,共同的一个最终目标就是确保车辆安全有效地行驶在车内。

系统输入通常涉及多个传感器的数据,比如多个摄像头的图像,雷达和激光雷达的点云,超声波信号,位置、速度和加速度传感器的数据,以及声音和运动信号。在各种天气条件下,不同传感器的影响差异很大,可以下图中看到,不同传感在在某些恶劣天气下会完全失效。因此,需要多模态传感器融合解决方案来保证不同场景下任务的最佳输入质量,根据外部天气环境动态调整不同数据输入的权重和融合方式。

从硬件的角度来看,ADS SoC通常是异构架构。除了NPU,还有cpu、DSP、GPU等图像信号处理器。

所有的任务和子任务都需要在异构中映射到不同的核上。

基于以上对于ADS系统的描述,因此在ADS SoC中设计NPU需要考虑以下几点:
首先,在ADS系统中有一组不同的DNNs,如Resnet, FPN, Transformer,需要并行或级联运行在NPU中以处理ADS系统中不同任务的多模态数据;这些不同任务的深度神经网络可以进行分层的特征共享/融合。NPU不仅仅针对一个特定的深度神经网络中优化硬件的利用率和功耗效率,更要考虑到每个深度神经网络和任务的运行时间比例和哪些DNNs之间需要层间的特征共享/融合,以获得整体最优的利用率和功耗效率。
因此,需要设计一种可重构硬件架构,能够在运行时高效地为不同的dnn和任务配置。并实现硬件感知的神经网络搜索(NAS),不仅可以在一个DNN上搜索特定的任务,还可以进行多通道和多任务架构的搜索。更重要的是,这不是在NAS中分别优化每个单独的任务。对于ADS系统,其目标是优化最终的驱动/控制,而感知、定位等中间任务则协同服务于最终目标,因此需要实现多网络协同优化达到整体最优结果。
其次,ADS系统的决策依赖于多种输入下多个深度神经网络和任务的输出综合全面地做出决策,这些深度神经网络的输入是来自不同传感器的多模态信号,质量会受到外部环境或场景的影响,其输出有效性也会相应地打折扣。因此每单个的神经网络模型推理精度是可以适当调整的。因此,在ADS的DNNs推理中需要可调整的混合多精度,即可以针对同时在运行的不同模型实现不同精度下的推理,甚至同一模型下不同层间的精度也可以不同。
第三,ADS系统强调实时和快速响应。当接收到传感器输入,考虑依赖于这些输入产生的控制输出,那么对传感器数据的处理必须按时完成。因此,需要保证网络的实时性-这对安全性和性能都至关重要,特别是在汽车高速行驶的情况下。
这是ADS DNN推断与主流通用ML非常不同的一个重要例子。而任务的DNN推断的延迟不仅取决于NPU核心内部计算能力和数据流的并行性,还取决于通过SoC系统总线对外部存储的访问。因此,需要在NPU和SoC层面设计QoS机制,能够提供基本的权限管理并避免关键任务处于饥饿状态。
最后,超级可靠性的要求也使得面向ADS的NPU不同于一般的NPU。ADS SoC芯片整体需要通过AEC Q100车用芯片可靠性标准。
基于以上分析,把面向ADS SoC系统的NPU概括为实时可重构的可靠多模态多任务(MMMT) DNN加速器,ADAS NPU面临的挑战来自几个方向,主要包括以下几个关键问题:
1.针对需要支持的自动驾驶系统中所需的不同DNN模型设计layer wised计算模式
a)如何为ADS系统DNN模型设计高效的数据流,以便提高不同层次DNN的输入、权重和输出等数据的可重用性,并减少硬件所需的MAC操作次数?
b)如何设计一种在不同场景(如雨雪等恶劣天气)下,利用混合精度对ADS进行效率和精度量化权衡的方法?通过降低数据的精度,使量化模型在保持与全精度模型(FP32)相似精度(95%)的情况下,可以实现X倍的模型尺寸或X倍的计算成本降低,从而最大限度地减少精度损失,最大限度地提高效率
c)定义ADS系统中用于不同DNN模型的常用基本计算算子。除了基本的CONV 33、CONV 11和Pooling等等之外,针对ADS系统特诊定义特殊算子,例如跨层共享/融合,精度转换等等;
2.根据计算模式设计一个高效的实时可配置硬件架构:
a)如何设计能够通过MAC和SMID实现基本运算符和预取器的异构PE微体系结构,并高效地支持精度和稀疏度混合计算?
b)设计紧密耦合的存储层次和系统,减少数据移动,提高不同深度神经网络层间的可重用性。
c)设计支持数据流或计算模式的片上网络(network-on-chip, NoC),在ADS系统中高效连接PE和内存,并为任务提供QoS机制。
3.设计多通道多任务的硬件-算法协同设计流程,对每个任务进行整体优化而不是分别独立优化
a)根据NPU硬件架构,为DNN搜索空间构建硬件优化的典型DNN模型结构,并通过硬件感知的NAS将其充分映射到硬件配置空间
b)如何保证仿真结果的可信度?不但要包括该算法的输出延迟、精度均小于5%,还要有功耗的估算,且精度要达到20%,且与实际芯片性能呈线性关系,以便觉得最优的硬件配置方案和神经网络结构优化。
参考文献链接
https://mp.weixin.qq.com/s/62P8zVF7rySLakZJEkd7VA
https://mp.weixin.qq.com/s/hvzwCxzlgfS1yE-PRfs58A
https://mp.weixin.qq.com/s/BKzNwfVe-Bsoh_2090HHcQ
https://mp.weixin.qq.com/s/tEvskB3kIyA0t6a3z3zDhg
https://mp.weixin.qq.com/s/U2TIcwrq75FthslLgNJr2A
https://mp.weixin.qq.com/s/JVXSK_gr49IkRfl0s9UClQ
https://mp.weixin.qq.com/s/u_kBc5yoPJxtiovQD2EbWw