Seata分布式事务模式详解
目录
一、基本介绍
Seata支持的事务模型
Seata特性
Seata框架
组成模块
全局事务
定义
事务流程模型
Seata中的事务模式能力边界
二、4种模式介绍
1、AT模式
2、TCC 模式
3、Saga 模式
4、XA 模式
一、基本介绍
Seata支持的事务模型
- AT模式
- TCC模式
- Saga模式
- XA模式
Seata特性
- 支持多个微服务框架 :dubbo、spring cloud、sofa - rpc、motan和gRPC
- 高可用:支持基于数据库存储的集群模式,可水平扩展。
- 高可扩展:支持配置中心、注册中心、spi扩展
Seata框架
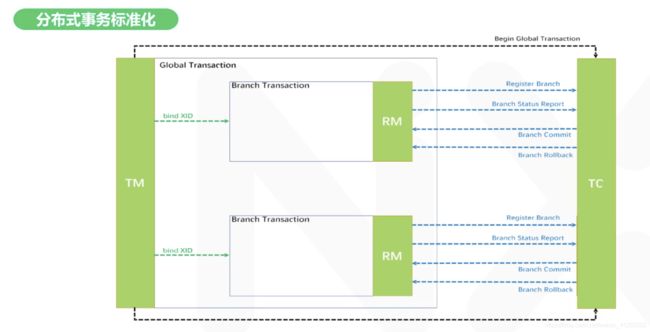
组成模块
Transaction Manager(TM)
- 事务管理器 - 这是一个产品经理
- 全局事务的发起员,能够根据全局事务的成功与否来对全局提交或回滚进行决策。
- 产品经理决定一个需求,是涉及哪些团队(她会去和各团队leader进行沟通),并且她会对需求做出决策,做,还是不做。
Transaction Coordinator(TC)
- 事务协调器 - 技术团队的leader
- 维护全局事务的运行状态,负责协调并驱动全局事务的提交或者回滚
- 技术团队的leader不会决定哪些需求做或者不做,如果做,那么leader会在各团队之间进行协调。
Resource Manager(RM)
- 资源管理器 - 各团队的码农们
- 负责对分支事务进行控制,包括分支注册、状态汇报,接收协调器发来的指令,以及对本地事务的开启、提交或回滚。
- 各个团队的coder们,真正完成本项目代码并使之落地的工程建造者,他们会和leader把需求转化成实际代码,也会在leader说不行做不了的时候接收指令回滚掉代码(别吧!)
全局事务
定义
若干分支事务的整体协调
事务流程模型
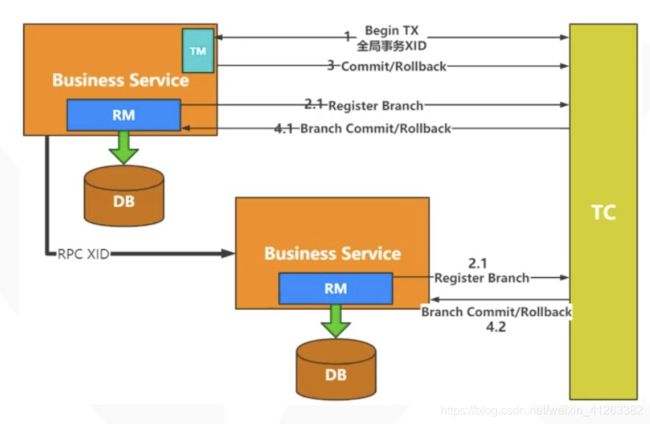
- TM向TC申请开启一个全局事务,TC创建后,返回全局唯一XID,XID会在全局上下文中传播。
- RM向TC注册分支事务,该分支事务归属于拥有相同XID的全局事务。
- TM想TC发起全局提交或回滚
- TC调度XID的分支事务完成提交或者回滚。
理解:一个全局事务只有一个TM,但是每一个需要调用别的服务的服务也就是全局事务的发起者都应该持有或者说是具备成为一个TM的能力。
从这里我们可以看到,全局事务的发起者通过rpc调用开启远程的分支事务,并且将全局事务id通过调用链传播下去,很明显,这一条调用链只有起点能够对整条调用链的成功与否进行感知,rpc调用链让起点天然具备了决定全局提交或是回滚的能力。
Seata中的事务模式能力边界
条件:
数据库一定要支持本地事务——几乎是所有事务模式的基础
数据表一定要定义主键——考虑到事务的隔离性,AT里面很有用。
限制:
- 难以实现更高的隔离级别

二、4种模式介绍
1、AT模式
前提
- 基于支持本地 ACID 事务的关系型数据库。
- Java 应用,通过 JDBC 访问数据库。
整体机制
两阶段提交协议的演变:
一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
二阶段:
- 提交异步化,非常快速地完成。
- 回滚通过一阶段的回滚日志进行反向补偿。
写隔离
- 一阶段本地事务提交前,需要确保先拿到 全局锁 。
- 拿不到 全局锁 ,不能提交本地事务。
- 拿 全局锁 的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁。
以一个示例来说明:
两个全局事务 tx1 和 tx2,分别对 a 表的 m 字段进行更新操作,m 的初始值 1000。
tx1 先开始,开启本地事务,拿到本地锁,更新操作 m = 1000 - 100 = 900。本地事务提交前,先拿到该记录的 全局锁 ,本地提交释放本地锁。 tx2 后开始,开启本地事务,拿到本地锁,更新操作 m = 900 - 100 = 800。本地事务提交前,尝试拿该记录的 全局锁 ,tx1 全局提交前,该记录的全局锁被 tx1 持有,tx2 需要重试等待 全局锁 。
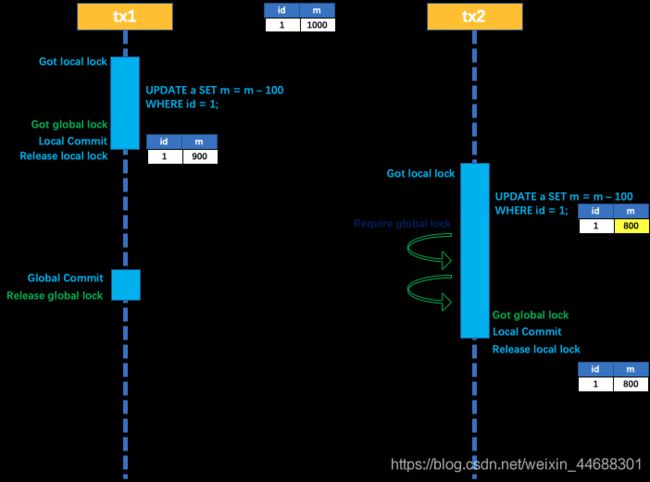
tx1 二阶段全局提交,释放 全局锁 。tx2 拿到 全局锁 提交本地事务。

如果 tx1 的二阶段全局回滚,则 tx1 需要重新获取该数据的本地锁,进行反向补偿的更新操作,实现分支的回滚。
此时,如果 tx2 仍在等待该数据的 全局锁,同时持有本地锁,则 tx1 的分支回滚会失败。分支的回滚会一直重试,直到 tx2 的 全局锁 等锁超时,放弃 全局锁 并回滚本地事务释放本地锁,tx1 的分支回滚最终成功。
因为整个过程 全局锁 在 tx1 结束前一直是被 tx1 持有的,所以不会发生 脏写 的问题。
读隔离
在数据库本地事务隔离级别 读已提交(Read Committed) 或以上的基础上,Seata(AT 模式)的默认全局隔离级别是 读未提交(Read Uncommitted) 。
如果应用在特定场景下,必需要求全局的 读已提交 ,目前 Seata 的方式是通过 SELECT FOR UPDATE 语句的代理。

SELECT FOR UPDATE 语句的执行会申请 全局锁 ,如果 全局锁 被其他事务持有,则释放本地锁(回滚 SELECT FOR UPDATE 语句的本地执行)并重试。这个过程中,查询是被 block 住的,直到 全局锁 拿到,即读取的相关数据是 已提交 的,才返回。
出于总体性能上的考虑,Seata 目前的方案并没有对所有 SELECT 语句都进行代理,仅针对 FOR UPDATE 的 SELECT 语句。
工作机制
以一个示例来说明整个 AT 分支的工作过程。
业务表:product
| Field | Type | Key |
|---|---|---|
| id | bigint(20) | PRI |
| name | varchar(100) | |
| since | varchar(100) |
AT 分支事务的业务逻辑:
update product set name = 'GTS' where name = 'TXC';一阶段
过程:
1.解析 SQL:得到 SQL 的类型(UPDATE),表(product),条件(where name = 'TXC')等相关的信息。
2.查询前镜像:根据解析得到的条件信息,生成查询语句,定位数据。
select id, name, since from product where name = 'TXC';
得到前镜像:
| id | name | since |
|---|---|---|
| 1 | TXC | 2014 |
3.执行业务 SQL:更新这条记录的 name 为 'GTS'。
4.查询后镜像:根据前镜像的结果,通过 主键 定位数据。
select id, name, since from product where id = 1`;
得到后镜像:
| id | name | since |
|---|---|---|
| 1 | GTS | 2014 |
5.插入回滚日志:把前后镜像数据以及业务 SQL 相关的信息组成一条回滚日志记录,插入到 UNDO_LOG 表中。
{
"branchId": 641789253,
"undoItems": [{
"afterImage": {
"rows": [{
"fields": [{
"name": "id",
"type": 4,
"value": 1
}, {
"name": "name",
"type": 12,
"value": "GTS"
}, {
"name": "since",
"type": 12,
"value": "2014"
}]
}],
"tableName": "product"
},
"beforeImage": {
"rows": [{
"fields": [{
"name": "id",
"type": 4,
"value": 1
}, {
"name": "name",
"type": 12,
"value": "TXC"
}, {
"name": "since",
"type": 12,
"value": "2014"
}]
}],
"tableName": "product"
},
"sqlType": "UPDATE"
}],
"xid": "xid:xxx"
}6.提交前,向 TC 注册分支:申请 product 表中,主键值等于 1 的记录的 全局锁 。
7.本地事务提交:业务数据的更新和前面步骤中生成的 UNDO LOG 一并提交。
8.将本地事务提交的结果上报给 TC。
二阶段-回滚
- 收到 TC 的分支回滚请求,开启一个本地事务,执行如下操作。
1.收到 TC 的分支回滚请求,开启一个本地事务,执行如下操作。
2.通过 XID 和 Branch ID 查找到相应的 UNDO LOG 记录。
3.数据校验:拿 UNDO LOG 中的后镜与当前数据进行比较,如果有不同,说明数据被当前全局事务之外的动作做了修改。这种情况,需要根据配置策略来做处理,详细的说明在另外的文档中介绍。
4.根据 UNDO LOG 中的前镜像和业务 SQL 的相关信息生成并执行回滚的语句:
update product set name = 'TXC' where id = 1;
5.提交本地事务。并把本地事务的执行结果(即分支事务回滚的结果)上报给 TC。
二阶段-提交
- 收到 TC 的分支提交请求,把请求放入一个异步任务的队列中,马上返回提交成功的结果给 TC。
- 异步任务阶段的分支提交请求将异步和批量地删除相应 UNDO LOG 记录。
附录-回滚日志表
UNDO_LOG Table:不同数据库在类型上会略有差别。
以 MySQL 为例:
| Field | Type |
|---|---|
| branch_id | bigint PK |
| xid | varchar(100) |
| context | varchar(128) |
| rollback_info | longblob |
| log_status | tinyint |
| log_created | datetime |
| log_modified | datetime |
-- 注意此处0.7.0+ 增加字段 context
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;2、TCC 模式
一个分布式的全局事务,整体是 两阶段提交 的模型。全局事务是由若干分支事务组成的,分支事务要满足 两阶段提交 的模型要求,即需要每个分支事务都具备自己的:
- 一阶段 prepare 行为
- 二阶段 commit 或 rollback 行为
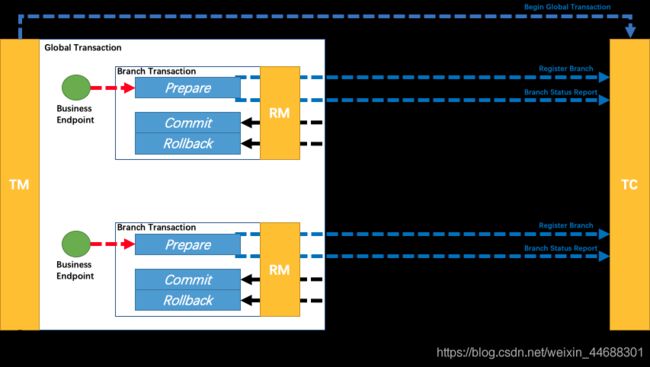
根据两阶段行为模式的不同,我们将分支事务划分为 Automatic (Branch) Transaction Mode 和 TCC (Branch) Transaction Mode.
AT 模式基于支持本地 ACID 事务 的 关系型数据库:
- 一阶段 prepare 行为:在本地事务中,一并提交业务数据更新和相应回滚日志记录。
- 二阶段 commit 行为:马上成功结束,自动 异步批量清理回滚日志。
- 二阶段 rollback 行为:通过回滚日志,自动 生成补偿操作,完成数据回滚。
相应的,TCC 模式,不依赖于底层数据资源的事务支持:
- 一阶段 prepare 行为:调用 自定义 的 prepare 逻辑。
- 二阶段 commit 行为:调用 自定义 的 commit 逻辑。
- 二阶段 rollback 行为:调用 自定义 的 rollback 逻辑。
所谓 TCC 模式,是指支持把 自定义 的分支事务纳入到全局事务的管理中。
3、Saga 模式
Saga模式是SEATA提供的长事务解决方案,在Saga模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务都由业务开发实现。

适用场景:
- 业务流程长、业务流程多
- 参与者包含其它公司或遗留系统服务,无法提供 TCC 模式要求的三个接口
优势:
- 一阶段提交本地事务,无锁,高性能
- 事件驱动架构,参与者可异步执行,高吞吐
- 补偿服务易于实现
缺点:
- 不保证隔离性(应对方案见后面文档)
Saga的实现:
基于状态机引擎的 Saga 实现:
目前SEATA提供的Saga模式是基于状态机引擎来实现的,机制是:
- 通过状态图来定义服务调用的流程并生成 json 状态语言定义文件
- 状态图中一个节点可以是调用一个服务,节点可以配置它的补偿节点
- 状态图 json 由状态机引擎驱动执行,当出现异常时状态引擎反向执行已成功节点对应的补偿节点将事务回滚
- 可以实现服务编排需求,支持单项选择、并发、子流程、参数转换、参数映射、服务执行状态判断、异常捕获等功能
注意: 异常发生时是否进行补偿也可由用户自定义决定

4、XA 模式
前提
- 支持XA 事务的数据库。
- Java 应用,通过 JDBC 访问数据库。
整体机制
在 Seata 定义的分布式事务框架内,利用事务资源(数据库、消息服务等)对 XA 协议的支持,以 XA 协议的机制来管理分支事务的一种 事务模式。
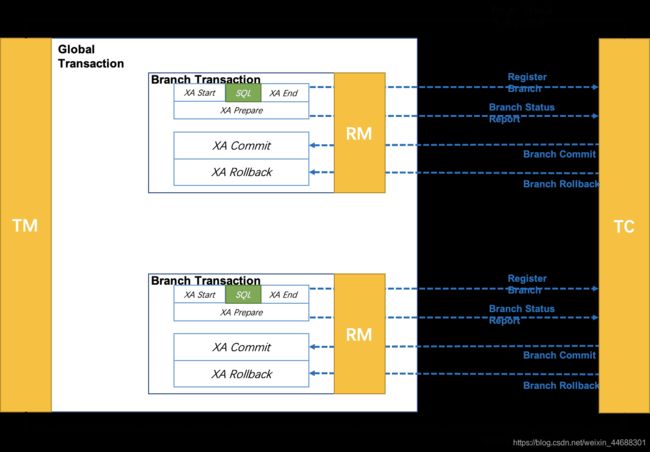
执行阶段:
- 可回滚:业务 SQL 操作放在 XA 分支中进行,由资源对 XA 协议的支持来保证 可回滚
- 持久化:XA 分支完成后,执行 XA prepare,同样,由资源对 XA 协议的支持来保证 持久化(即,之后任何意外都不会造成无法回滚的情况)
完成阶段:
- 分支提交:执行 XA 分支的 commit
- 分支回滚:执行 XA 分支的 rollback
工作机制
1. 整体运行机制
XA 模式 运行在 Seata 定义的事务框架内:
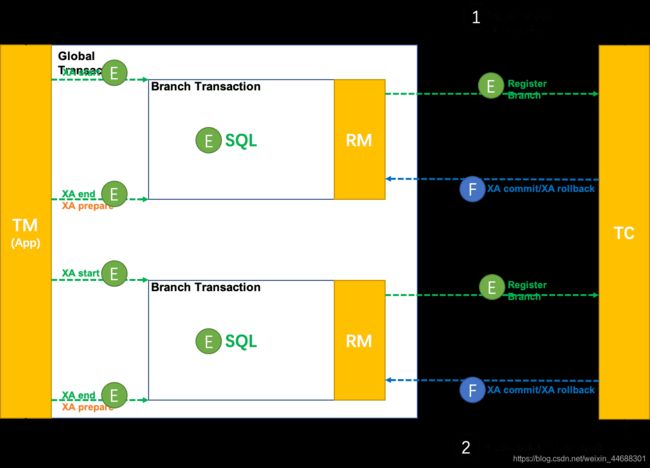
执行阶段(E xecute):
- XA start/XA end/XA prepare + SQL + 注册分支
完成阶段(F inish):
- XA commit/XA rollback
2. 数据源代理
XA 模式需要 XAConnection。
获取 XAConnection 两种方式:
- 方式一:要求开发者配置 XADataSource
- 方式二:根据开发者的普通 DataSource 来创建
第一种方式,给开发者增加了认知负担,需要为 XA 模式专门去学习和使用 XA 数据源,与 透明化 XA 编程模型的设计目标相违背。
第二种方式,对开发者比较友好,和 AT 模式使用一样,开发者完全不必关心 XA 层面的任何问题,保持本地编程模型即可。
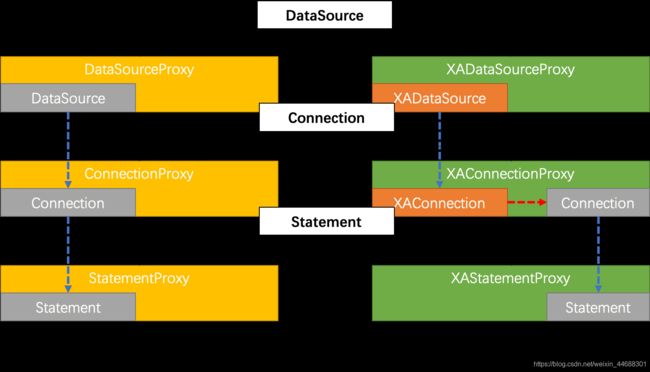
我们优先设计实现第二种方式:数据源代理根据普通数据源中获取的普通 JDBC 连接创建出相应的 XAConnection。
类比 AT 模式的数据源代理机制,如下:

但是,第二种方法有局限:无法保证兼容的正确性。
实际上,这种方法是在做数据库驱动程序要做的事情。不同的厂商、不同版本的数据库驱动实现机制是厂商私有的,我们只能保证在充分测试过的驱动程序上是正确的,开发者使用的驱动程序版本差异很可能造成机制的失效。
这点在 Oracle 上体现非常明显。参见 Druid issue:https://github.com/alibaba/druid/issues/3707
综合考虑,XA 模式的数据源代理设计需要同时支持第一种方式:基于 XA 数据源进行代理。
类比 AT 模式的数据源代理机制,如下:
3. 分支注册
XA start 需要 Xid 参数。
这个 Xid 需要和 Seata 全局事务的 XID 和 BranchId 关联起来,以便由 TC 驱动 XA 分支的提交或回滚。
目前 Seata 的 BranchId 是在分支注册过程,由 TC 统一生成的,所以 XA 模式分支注册的时机需要在 XA start 之前。
将来一个可能的优化方向:
把分支注册尽量延后。类似 AT 模式在本地事务提交之前才注册分支,避免分支执行失败情况下,没有意义的分支注册。
这个优化方向需要 BranchId 生成机制的变化来配合。BranchId 不通过分支注册过程生成,而是生成后再带着 BranchId 去注册分支。
XA 模式的使用
从编程模型上,XA 模式与 AT 模式保持完全一致。
可以参考 Seata 官网的样例:seata-xa
样例场景是 Seata 经典的,涉及库存、订单、账户 3 个微服务的商品订购业务。
在样例中,上层编程模型与 AT 模式完全相同。只需要修改数据源代理,即可实现 XA 模式与 AT 模式之间的切换。
@Bean("dataSource")
public DataSource dataSource(DruidDataSource druidDataSource) {
// DataSourceProxy for AT mode
// return new DataSourceProxy(druidDataSource);
// DataSourceProxyXA for XA mode
return new DataSourceProxyXA(druidDataSource);
}