Redis进阶教程
Redis进阶
目标
Redis持久化【掌握】
Redis消息发布定阅【了解】
Redis集群配置【掌握】
SpringBoot整合Redis【重点】
讨论问题:
数据存放的位置有哪些(磁盘,内存,数据库)
为什么做缓存?
速度:内存 >10 倍固态硬盘 > 10 倍机械硬盘
一、SpringBoot操作Redis
1、 添加redis依赖
spring Boot 提供了对 Redis 集成的组件包:spring-boot-starter-data-redis,它依赖于 spring-data-redis 和 lettuce 。
另外,这里还有两个小细节:
- Spring Boot 1.x 时代,spring-data-redis 底层使用的是 Jedis;2.x 时代换成了 Lettuce 。
- Lettuce依赖于 commons-pool2
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
dependency>
2、配置文件
## Redis 服务器地址
spring.redis.host=localhost
## Redis 服务器连接端口
spring.redis.port=6379
## Redis 数据库索引(默认为 0)
spring.redis.database=0
## 以下非必须,有默认值
## Redis 服务器连接密码(默认为空)
spring.redis.password=
## 连接池最大连接数(使用负值表示没有限制)默认 8
spring.redis.lettuce.pool.max-active=8
## 连接池最大阻塞等待时间(使用负值表示没有限制)默认 -1
spring.redis.lettuce.pool.max-wait=-1
## 连接池中的最大空闲连接 默认 8
spring.redis.lett uce.pool.max-idle=8
## 连接池中的最小空闲连接 默认 0
spring.redis.lettuce.pool.min-idle=0
3、操作redis API
在这个单元测试中,我们使用 redisTemplate 存储了一个字符串 "Hello Redis" 。
Spring Data Redis 针对 api 进行了重新归类与封装,将同一类型的操作封装为 Operation 接口:
| 专有操作 | 说明 |
|---|---|
| ValueOperations | string 类型的数据操作 |
| ListOperations | list 类型的数据操作 |
| SetOperations | set 类型数据操作 |
| ZSetOperations | zset 类型数据操作 |
| HashOperations | map 类型的数据操作 |
//解决中文乱码问题
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate redisTemplateInit(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
//设置序列化Key的实例化对象
redisTemplate.setKeySerializer(new StringRedisSerializer());
//设置序列化Value的实例化对象
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
/**
*
* 设置Hash类型存储时,对象序列化报错解决
*/
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
return redisTemplate;
}
}
4、RedisTemplate 和 StringRedisTemplate
RedisTemplate
但是很显然,这和 Redis 的实际情况是相违背的:在最小的存储单元层面,Redis 本质上只能存字符串,不可能存其它的类型。这么看来,StringRedisTemplate 更贴合 Redis 的存储本质。那么 RedisTemplate 是如何实现以任何类型(通过对value 值的序列化完成的)。
而使用RedisTemplate 存储对象时会把对象的地址保存起来,以便反序列化,这样就大大浪费存储空间,解决这个问题使用StringRedisTemplate ,认为手动对对想序列化与反序化
Users users = new Users();
users.setId(2);
users.setUsername("李四2");
redisTemplate.opsForValue().set("user:2", JSON.toJSONString(users)); //存的时候序列化对象
String u = redisTemplate.opsForValue().get("user:2"); //redis 只能返回字符串
System.out.println("u="+ JSON.parseObject(u,Users.class)); //使用JSON工具反序化成对象
若springboot中没有引入spring-boot-starter-web依赖,需要加jackson 的依赖。
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-databindartifactId>
dependency>
5、SpringBoot操作String字符串
a、键过期
key的自动过期问题,Redis 在存入每一个数据的时候都可以设置一个超时间,过了这个时间就会自动删除数据。
常用的redis时间单位
MINUTES:分钟
SECONDS:秒
DAYS: 天
//给user对象设置10分钟过期时间
redisTemplate.opsForValue().set("user:1", JSON.toJSONString(users),10,TimeUnit.MINUTES );
b、删除数据
//删除键
redisTemplate.delete(key);
//判断键是否存在
boolean exists = redisTemplate.hasKey(key);
6、SpringBoot操作Hash(哈希)
一般我们存储一个键,很自然的就会使用 get/set 去存储,实际上这并不是很好的做法。Redis 存储一个 key 会有一个最小内存,不管你存的这个键多小,都不会低于这个内存,因此合理的使用 Hash 可以帮我们节省很多内存。
@Test
public void testHash() {
String key = "tom";
HashOperations<String, Object, Object> operations = redisTemplate.opsForHash();
operations.put(key, "name", "tom");
operations.put(key, "age", "20");
String value= (String) operations.get(key,"name");
System.out.println(value);
}
根据上面测试用例发现,Hash set 的时候需要传入三个参数,第一个为 key,第二个为 field,第三个为存储的值。一般情况下 Key 代表一组数据,field 为 key 相关的属性,而 value 就是属性对应的值。
7、SpringBoot操作List集合类型
Redis List 的应用场景非常多,也是 Redis 最重要的数据结构之一。 使用 List 可以轻松的实现一个队列, List 典型的应用场景就是消息队列,可以利用 List 的 Push 操作,将任务存在 List 中,然后工作线程再用 POP 操作将任务取出进行执行。
/**
* 测试List
* leftPush 将数据添加到key对应的现有数据的左边,也就是头部
* leftPop 取队列最左边数据(从数据库移除)
* rightPush 将数据添加到key对应的现有数据的右边,也就是尾部
*/
@Test
public void testList() {
final String key = "list";
ListOperations<String,Object> list = redisTemplate.opsForList();
list.leftPush(key, "hello");
list.leftPush(key, "world");
list.leftPush(key, "goodbye");
Object mete = list.leftPop("list");
System.out.println("删除的元素是:"+mete); //删除 goodbye
String value = (String) list.leftPop(key);
System.out.println(value.toString());
// range(key, 0, 2) 从下标0开始找,找到2下标
List<Object> values = list.range(key, 0, 2);
for (Object v : values) {
System.out.println("list range :" + v);
}
}
}
Redis List 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis 内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
8、SpringBoot操作Set集合类型
Redis Set 对外提供的功能与 List 类似,是一个列表的功能,特殊之处在于 Set 是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,Set 是一个很好的选择,并且 Set 提供了判断某个成员是否在一个 Set 集合内的重要接口,这个也是 List 所不能提供的。
/**
* 测试Set
*/
@Test
public void testSet() {
final String key = "set";
SetOperations<String,Object> set = redisTemplate.opsForSet();
set.add(key, "hello");
set.add(key, "world");
set.add(key, "world");
set.add(key, "goodbye");
Set<Object> values = set.members(key);
for (Object v : values) {
System.out.println("set value :" + v);
}
Boolean exist = set.isMember(key,"hello") //判断是否存在某个元素
operations.move("set", "hello", "setcopy"); //把set集合中的hello元素放到setcopy 中
}
}
9、SpringBoot操作ZSet集合类型
Redis ZSet 的使用场景与 Set 类似,区别是 Set 不是自动有序的,而 ZSet 可以通过用户额外提供一个优先级(Score)的参数来为成员排序,并且是插入有序,即自动排序。
/**
* 测试ZSet
* range(key, 0, 3) 从开始下标到结束下标,score从小到大排序
* reverseRange score从大到小排序
* rangeByScore(key, 0, 3); 返回Score在0至3之间的数据
*/
@Test
public void testZset() {
final String key = "lz";
ZSetOperations<String,Object> zset = redisTemplate.opsForZSet();
zset.add(key, "hello", 1);
zset.add(key, "world", 6);
zset.add(key, "good", 4);
zset.add(key, "bye", 3);
Set<Object> zsets = zset.range(key, 0, 3);
for (Object v : zsets) {
System.out.println("zset-A value :"+v);
}
System.out.println("=======");
Set<Object> zsetB = zset.rangeByScore(key, 0, 3);
for (Object v : zsetB) {
System.out.println("zset-B value :"+v);
}
}
}
二、RedisTemplate操作redis
1、数据一致性问题
当数据库数据发生变化时三个问题
1:删除缓存还是更新缓存?
更新缓存:每次更新数据库都要更新缓存,无效操作多
删除缓存:更新数据库是让缓存失效也就是删除redis对应的数据, 查询时候在更新redis缓存
2:先操作缓存还是先操作数据库(并发问题)
先删除缓存,在操作数据库
一个线程删除缓存,在操作数据库时比如(update set age = 20 原值等于10)另外一个线程进来
查缓存没有(被第一个线程删了)查数据库放入缓存放的还是10,这时候线程一修改数据库完成。结果导致缓存为10,数据库为 20,数据不一致性问题。
先操作数据库,在删除缓存(选中方案)
缓存数据突然失效,线程一查询没有缓存,去查数据库(age = 10)然后写入缓存中间,线程2执行修改数据库操作(set age = 20)
删除缓存,这是线程一开始写缓存(age = 10)造成了数据不一致问题
2、缓存穿透
指客户端请求的数据在缓存数据库中都没有,这样缓存永远不会生效,这些请求都会打到数据库
解决方案:
1:缓存空对象给过期时间,优点,实现简单,缺点额外内存消耗
2:布隆过滤器 有点内存占用少,实现复杂,存在误判情况
3、缓存雪崩
指同一时间段内大量的缓存key失效,或者redis宕机,导致大量的请求到达数据库
解决方案:
1:给不同key添加不同过期时间
2:利用redis集群提高服务可有性
3:给业务添加多级缓存
4、缓存击穿
指热点key 问题,就是一个高并发访问的key突然失效,无数的请求访问都会瞬间给数据库带来巨大压力
解决方案:
1:查询缓存未命中是,去查数据库的代码前加互斥锁,从数据库查到数据并且写入缓存完毕后在释放锁
三、安装Linux版redis
1、安装及测试
1:安装wget 环境
yum -y install wget
2:上传redis 压缩包
3:执行命令(安装c语言环境)
yum install gcc
4: 解压后进入redis 根目录执行make编译
make
4: 编译成功后 输入:make install
make install
5: 启动redis(进入redis 目录里的src 中执行下面命令) 使用redis.conf 文件启动
./redis-server ../redis.conf
四、Redis持久化
redis是一个内存数据库,当redis服务器重启,获取电脑重启,数据会丢失,我们可以将redis内存中的数据持久化保存到硬盘的文件中。
redis提供两种持久化方式:
RDB:快照,通过从服务器保存和持久化
AOF:日志,操作生成相关日志,并通过日志来恢复数据。couchDB对于数据内容,不修改,只追加,则文件本身就是日志,不会丢失数据.
1、RDB全称redis database backup file(redis 数据备份文件)持久化
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里,Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
注:fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程,在每次redis服务器启动的时候,会自动把dump.rdb这个文件的键值对 全部读取到内存

编辑redis.conf配置文件
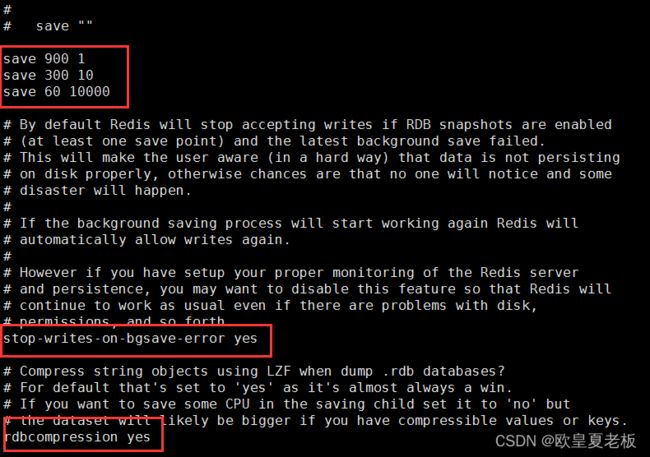
RDB快照相关参数:
save 900 1 #刷新快照到硬盘中,必须满足两者要求才会触发,即900秒之后至少1个关键字发生变化。
save 300 10 #必须是300秒之后至少10个关键字发生变化。
save 60 10000 #必须是60秒之后至少10000个关键字发生变化。
上面三个参数屏闭后,rdb方式就关闭了
stop-writes-on-bgsave-error yes #后台存储错误停止写。
rdbcompression yes #使用LZF压缩rdb文件。
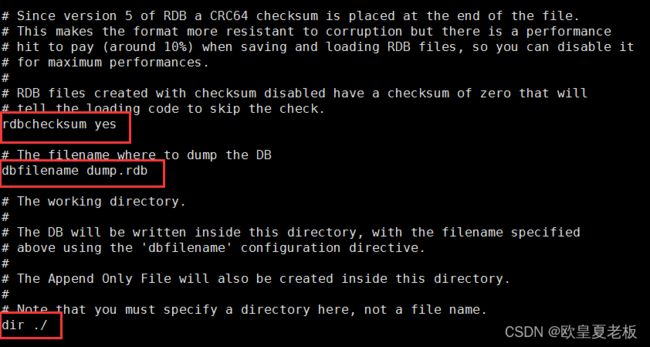
rdbchecksum yes #存储和加载rdb文件时校验。
dbfilename dump.rdb #设置rdb文件名。
dir ./ #设置工作目录,rdb文件会写入该目录。
2、AOF日志持久化
config set appendonly yes
或者进入redis.conf 修改 appendonly = yes 默认是no
AOF日志原理

思想:内存每写一条,就备份一条,时间间隔是1秒钟,缺点:文件大,写操作频繁。
-
以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录),
-
只许追加文件但不可以改写文件,redis启动之初会读取该文件(aof文件)重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
-
aof保存的是appendonly.aof文件
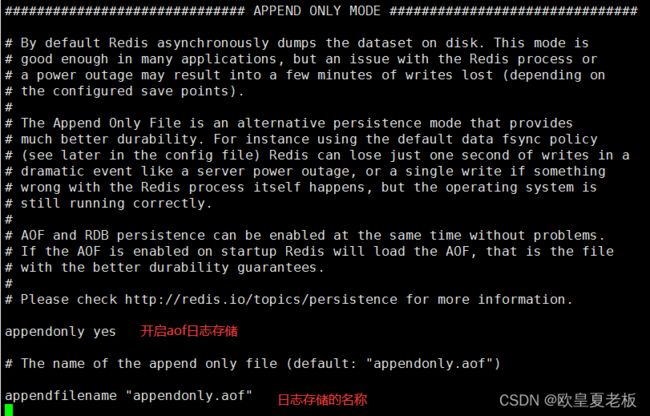
AOF日志相关参数:
appendonly no # 是否打开aof日志功能 no:不开启 yes:开启日志
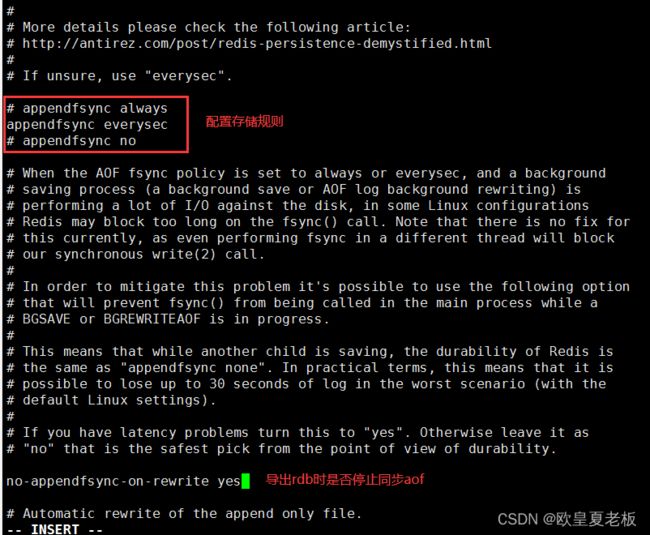
appendfsync always # 每1个命令,都立即同步到aof. 安全,速度慢
everysec # 折衷方案,每秒写1次
no # 写入工作交给操作系统,由操作系统判断缓冲区大小,统一写入到aof. 同步频率低,速度快
no-appendfsync-on-rewrite no # 正在导出rdb快照的过程中,要不要停止同步aof
配置开启AOF日志
配置存储方案
3、AOF重写
思考:如果对同一个key进行多次操作,在aof日志中怎样表现操作记录,一条还是n条?
案例 :创建age并改变五次值


日志会将每一步操作都记录,如果要对一个key操作多次,在数据上的表现只有一个但在日志中会有n条记录。当数据丢失需要找回数据的时候怎样找到正确的值?
aof重写是将内存中的key和value逆化为redis命令重新保存到日志中,就好像是将所执行的操作做的总结。
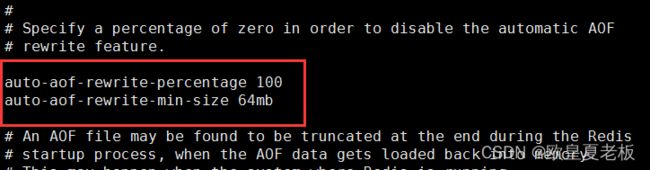
aof重写相关参数:
no-appendfsync-on-rewrite no # 正在导出rdb快照的过程中,要不要停止同步aof
auto-aof-rewrite-percentage 100 #aof文件大小比起上次重写时的大小,增长率100%时,重写
auto-aof-rewrite-min-size 64mb #aof文件,至少超过64M时,重写
问: 在dump rdb过程中,aof如果停止同步,会不会丢失?
答: 不会,所有的操作缓存在内存的队列里, dump完成后,统一操作.
问: aof重写是指什么?
答: aof重写是指把内存中的数据,逆化成命令,写入到.aof日志里.以解决 aof日志过大的问题.
问: 如果rdb文件,和aof文件都存在,优先用谁来恢复数据?
答: aof
问: 2种是否可以同时用?
答: 可以,而且推荐这么做
问: 恢复时rdb和aof哪个恢复的快
答: rdb快,因为其是数据的内存映射,直接载入到内存,而aof是命令,需要逐条执行
问题思考:在使用rdb做持久化时,我们关掉了redis服务,然后重新打开,保存的数据还在。但在做aof的时候我们将redis服务关闭后再打开数据就没有了。在上面不是配置过rdb持久化吗,为什么没起作用?
答:当rdb中有数据,并开启了AOF选项,重启redis服务后会产生一个空的aof文件,当rdb和aof文件都存在,会以aof文件来恢复数据。
五、Redis消息发布定阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
Redis 客户端可以订阅任意数量的频道。
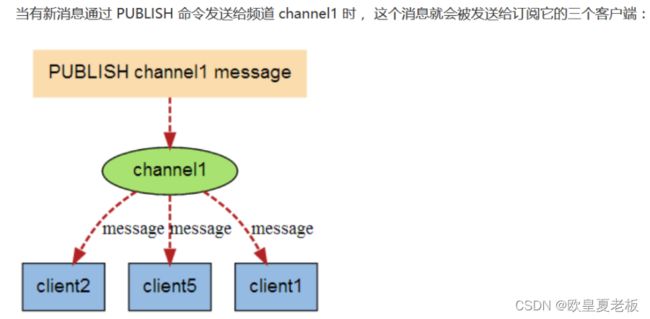
案例:创建消息定阅端
./redis-cli --raw --打开redis客户端
SUBSCRIBE woniu --订阅蜗牛频道信息
案例:创建消息发布端
PUBLISH woniu '你好' --发布 ”你好“ 信息
六、redis分布式锁
对于一个单体项目我们使用jvm锁(synchronized或RentranLock)可以做到数据安全性的,但是对于多实例的系统而言jvm锁就没用了,比如:一个系统发布在不同的tomcat上,jvm锁就没用了
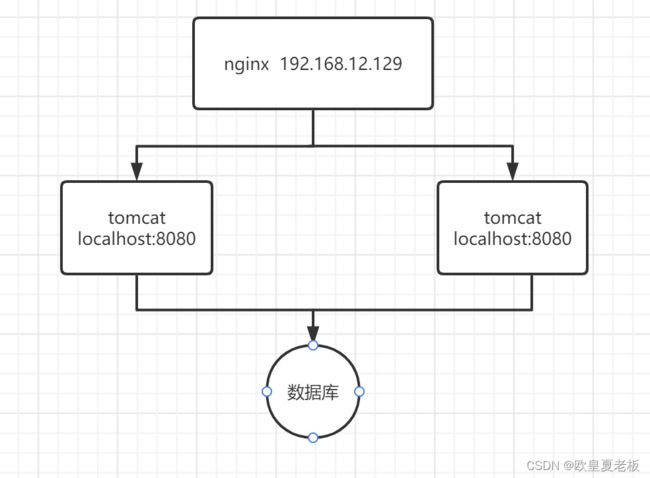
分布式锁:所有服务中所有进程同时竞争一把锁,只有一个线程可以成功获取锁,没有获得锁的线程就等待,直到拿到锁为止。
通过setIfAbsent() 方法实现
String redis_lock = "REDISLOCK";
String vaule = UUID.randomUUID().toString().replace("-","");
Boolean flag = redisTemplate.opsForValue.setIfAbsent(redis_lock,vaule,10L, TimeUnit.SECONDS);
if (!flag){
System.out.println("抢锁失败");
return;
}
System.out.println("抢锁成功");
try {
//...........逻辑代码
//'''''''''''逻辑代码
}catch (Exception e){
}finally { //线程只删除自己生成的uuid
if ( redisTemplate.opsForValue.get(redis_lock).equals(vaule)){
redisTemplate.delete(redis_lock);
}
}
七、redis 集群配置
1、redis主从复制(Master/Slave)
a、集群结构

三个节点:一个主节点,二个从节点
b、准备实例和配置
在虚拟机开启3个redis 实例,来模拟主从集群模式,信息如下:
| ip | post | 角色 |
|---|---|---|
| 127.0.0.1 | 7001 | master |
| 127.0.0.1 | 7002 | slave |
| 127.0.0.1 | 7003 | slave |
1,在redis 目录下建三个文件夹:
2,把redis.conf 分别复制到三个文件夹中:
cp /redis/redis-6.0.6/redis.conf /redis/7001
cp /redis/redis-6.0.6/redis.conf /redis/7002
cp /redis/redis-6.0.6/redis.conf /redis/7003
3,修改文件中端口,RDB文件存放位子,redis实例声明的IP
例如7001实例:
dir ../../7001
port 7001
4,启动三个服务进入src 目录下
例如启动7001实例:
./redis-server ../../7001/redis.conf
5,连接redis客户端
例如连接7001实例:
./redis-cli -p 7001
c、开启主从关系
通过命令建立主从关系:
例如连接7002客户端,执行命令,7002 就成了7001的从节点
redis-cli -p 7002 快速的打开某个端口的客户端
SLAVEOF 127.0.0.1 7001
d、验证主从关系
进入7001 的客户端输入命令
info replication
主从同步原理
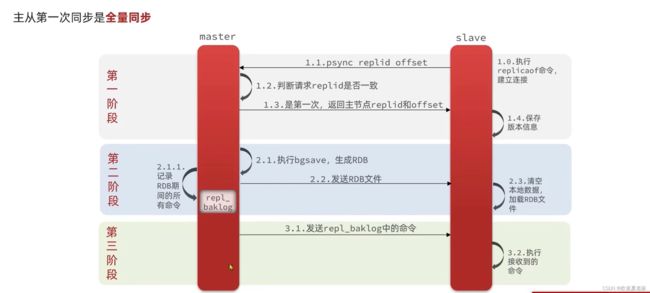
原理:从节点第一次发送请求带上自己的replid 和offset ,主节点判断和自己的replid 是否一致,传给从节点replid 和offset,从节点保存版本信息,主节点执行bgsave 生成RDB 文件,并同步给从节点,从节点加载RDB文件实现数据同步,这时如果主节点发生修改操作,会生成一个repl-baklog 日志。
2、哨兵模式(sentinel)
万一主节点宕机了怎么办?
监控:sentinel不断的检查您的master和slave 是否按预期执行
自动故障恢复:如果master故障,sentinel会将一个slave提升为master,当故障实例恢复后也以新的master为主
通知:sentinel充当redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给redis客户端
sentinel服务状态检测,每隔一秒向集群每个实例发送ping 命令
主观下线:如果某个sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线
客观下线:若超过执行数量(quornum)的sentinel都认为该实例下线,则该实例客观下线,(quornum数最好超过实例总数一半)
| ip | post | 角色 |
|---|---|---|
| 127.0.0.1 | 27001 | master |
| 127.0.0.1 | 27002 | slave |
| 127.0.0.1 | 27003 | slave |
1,在redis 目录下建三个文件夹:

2,新建文件sentinel.conf
以27001为例:
port 27001
sentinel monitor mymaster 127.0.0.1 7001 2
sentinel down-after-milliseconds mymaster 50000
sentinel failover-timeout mymaster 180000
dir "/ding/s1"
3,启动,进入src 目录
redis-sentinel ../../s1/sentinel.conf