Android LowMemoryKiller概述
Agenda
Low memory killer 概述
内核空间LMK
ULMK‐vmpressure
ULMK‐PSI
Low memory killer 概述
lowmemorykiller的作用就是当内存比较紧张的时候去及时杀掉一些对用户来说不那么重要的进程,回收内存,保证手机的正常运行。安卓平台lowmemorykiller机制演进:

内核空间LMK
Kernel LMK相关概念
• /sys/module/lowmemorykiller/parameters/minfree:
18432,23040,27648,32256,55296,80640
数字代表一个内存级别
• /sys/module/lowmemorykiller/parameters/adj:
0,100,200,300,900,906
数字代表一个进程优先级级别
当手机内存低于80640时,就去杀掉优先级906以及以上级别的进程;当内存低于55296时,就去杀掉优先级900以及以上的进程。
• proc/pid/oom_adj:代表当前进程的优先级,这个优先级是kernel中的进程优先级
• /proc/pid/oom_score_adj:上层优先级,跟ProcessList中的优先级对应
Lmkd:在手机中是一个常驻进程,lmkd是在init进程启动的时候启动,根据AMS指示更新进程优先级
内核空间LMK

AMS: ActivityManagerService
Lmkd: userspace lowmemory killer daemon
Lowmemorykiller :The lowmemorykiller driver lets user‐space specify a set of memory thresholds where processes with a range of oom_score_adj values will get killed.

AMS与lmkd的通信
AMS与lmkd通过socket通信
主要分为三种command,每种command代表一种数据控制方式:
LMK_TARGET:更新/sys/module/lowmemorykiller/parameters/中的minfree以及adj
LMK_PROCPRIO:更新指定进程的优先级,也就是oom_score_adj
LMK_PROCREMOVE:移除进程
Lowmemorykiller init
初始化lowmemorykiller,注册shrinker,当空闲内存页面不足时,内核线程kswpd会调用注册的shrink回调函数来回收页面。

lowmem_scan 调用流程
回收内存流程时会被调用,lowmem_scan挂到了register_shrinker里,shrink_slab_node里会scan_objects
调用栈:
• [
(shrink_slab_node+0x204/0x3d0)
• [
(shrink_slab+0x70/0xe4)
• [
(try_to_free_pages+0x3c0/0x74c)
• [
(__alloc_pages_nodemask+0x578/0x92c)
判断是否需要kill进程
- lowmem_scan首先看看能不能找到oom_score_adj,如果找不到就认为内存充足不杀进程。
- 判断内存是否充足的条件就是other_free和other_file两个都必须同时小于lowmem_minfree中的用户设定值,other_free基本上是free pages,other_file基本上是file pages,两者可以分别看成MemFree和Cached大小

查找被杀进程
遍历所有的进程for_each_process,查找 oom_score_adj要比min_score_adj大且rss最大的进程,通过send_sig(SIGKILL, selected, 0)杀掉。

Issues with lowmemorykiller kernel driver
- Relies on hard‐coded free‐memory limits with no scaling based on the memory pressure
- Vendors often heavily customize the driver to work on their devices, which indicates rigidity of the design. Customizations include listening to vmpressure events, adding additional free‐memory watermarks, and other memory‐pressure hints
- Hooks into slab shrinker API that was not designed for this purpose. Shrinkers are supposed to quickly drop unused caches and exit in order to avoid slowing down the vmscan process. Workload that lowmemorykiller performs includes searching for heavy processes and killing them, which are not quick operations
ULMK ‐VMPRESSURE
1.监听kernel的vmpressure events,由lmkd根据进程adj以及内存level来决定杀哪些进程。
2.SM8250 的kernel版本4.19,为了支持ULMK,kernel增加了PSI framework(Pressure stall information),PSI会记录CPU/memory/IO 的压力信息并通知用户空间。ULMK通过读取这些数据来决定杀哪个进程。

1. AMS 与 Lmkd 通过soket通信,与前面介绍相同
2. Lmkd 与 Memcg通信

a. kernel 会向 lmkd 报告memory pressure event
b. Lmkd 会根据kernel报告的critical memory pressure 或medium memorypressure 杀app
c. 根据进程的adj以及minfree来选择app杀掉
Lmkd 监听vmpressure
vmpressure本身就定义了low, medium, critical三类内存压力状态,LMKD 的初始化流程:
Lmkd::init()
‐> init_mp_common(low,medium,critical)
open(MEMCG_SYSFS_PATH "memory.pressure_level", O_RDONLY | O_CLOEXEC);
evctlfd = open(MEMCG_SYSFS_PATH "cgroup.event_control", O_WRONLY | O_CLOEXEC);
write(evctlfd, buf, strlen(buf) + 1)
> memcg_write_event_control
event‐>register_event = vmpressure_register_event;
event‐>register_event(memcg, event‐>eventfd, buf);
Lmkd 如何处理vmpressure
对于 memory pressure 事件,处理函数是 mp_event_common,传递给他的 data 是memory
pressure level
Lmkd::init
‐>init_mp_common
vmpressure_hinfo[level_idx].data = level_idx;
vmpressure_hinfo[level_idx].handler = mp_event_common;
epev.data.ptr = (void *)&vmpressure_hinfo[level_idx];
ret = epoll_ctl(epollfd, EPOLL_CTL_ADD, evfd, &epev);
处理函数入口:mp_event_common
‐>use_minfree_levels
if (other_free < minfree && other_file < minfree)
min_score_adj = lowmem_adj[i];
pages_to_free = lowmem_minfree[lowmem_targets_size ‐ 1] ‐ ((other_free < other_file) ? other_free : other_file);
do_kill:
find_and_kill_processes(min_score_adj, 0);
在未开启use_minfree_levels的情况下,需要结合mp level以及swap 分区空余大小来决定是否
kill app
‐>!use_minfree_levels
if (mi.field.nr_free_pages < low_pressure_mem.max_nr_free_pages) {
pages_to_free = low_pressure_mem.max_nr_free_pages ‐
mi.field.nr_free_pages; }
if (level < VMPRESS_LEVEL_CRITICAL &&
mi.field.free_swap > low_pressure_mem.max_nr_free_pages)
return;
min_score_adj = level_oomadj[level];
find_and_kill_processes(min_score_adj, 0);
Issues with vmpressure for memory pressure detection:
• Reflects current reclaim efficiency rather than memory pressure level
• Difficult to tune because of no direct link between reclaim efficiency
and its effects on user experience
• Tightly coupled with vmscan implementation, changes in vmscan
mechanisms may result in behavior change
• In testing, highly depends on the system memory size and particular
workload
ULMK‐‐PSI
PSI improvements
• More accurate pressure detection compared to vmpressure (2‐10x
fewer false positives)
• Thresholds are configurable making tuning possible
• PSI signals are rate‐limited and userspace can decide how often to
poll after the first signal
• Supports unlimited number of triggers
PSI
PSI将各个任务延迟汇总为资源压力指标,这些指标反映工作负载运行状况和资源利用率方面的问题。
基准productivity:可以在CPU上执行任务的时间。
压力:表示由于资源争用而无法执行任务的时间量。
productivity的概念包括两个部分:workload和CPU。 为了衡量压力对两者的影响,我们定义了两个资源的争用状态:SOME和FULL。
• SOME: Time percentage due to the stalling of a few tasks caused by lack of a specific kind of resource.
• FULL: Time percentage due to the stalling of all tasks caused by lack of a specific kind of resource.

• Psi旨在提供可供用户配置的低延迟的短期压力监测机制。
• 在用户定义的时间窗口内度量延迟高于用户定义的阈值时通知用户。
• 时间窗口和阈值都以usecs表示,可以同时监视具有不同阈值和窗口大小的多个psi资源。
• PSI监测的资源包括:memory,IO以及cpu
PSI如何监控资源压力
• 用户需要注册trigger,当资源压力超过门限值时通过poll()通知
用户。
• Trigger描述的是特定时间窗口内的最大累计停顿时间,例如 任何
500ms窗口内100ms的总停顿时间生成唤醒事件。
• 要注册trigger,用户必须在proc / pressure /下打开psi接口文件,
表示要监视的资源,并写入所需的阈值和时间窗口。例如,将
“some 150000 1000000”写入/ proc / pressure / memory,将为在1
秒时间窗口内测量的部分内存停顿150ms阈值。
• PSI监视器仅在系统进入受监测的psi度量标准的卡顿状态时激活,
并在退出卡顿状态时停用。
注册trigger代码实例
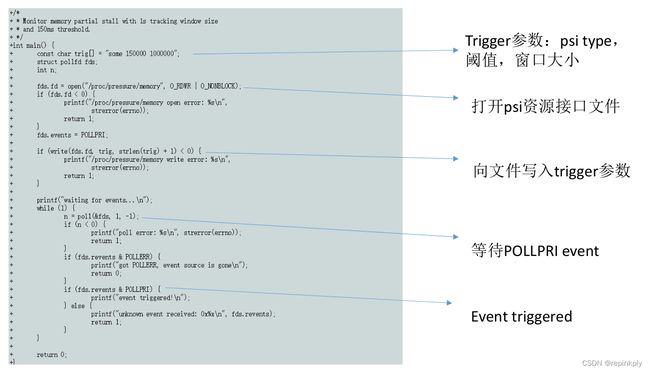
LMKD注册trigger

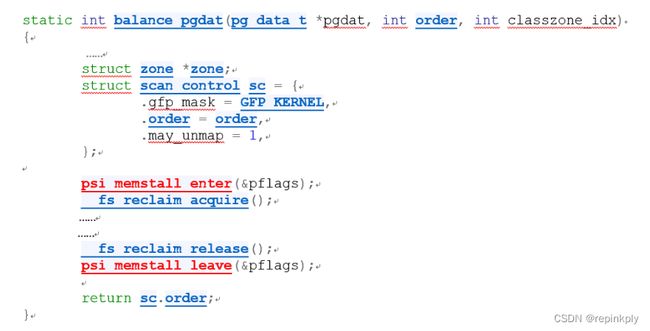
系统记录memory stall状态
系统通过psi_memstall_enter以及psi_memstall_leave记录memory stall 状态,
在下面几个内存相关的文件将对memstall 状态进行记录
mm/compaction.c
mm/filemap.c, mm/page_alloc.c mm/vmscan.c
Psi 更新trigger

通知事件
psi_fop_poll此函数是用户态发起poll()系统调用后,会有psi此函数对接,检查在此poll之前的时间内是否有事件发生,如果有则设置相应事件signal,如果无则通过poll_wait()让其等待。所以用户每次监听io/mem/cpu的任一文件,都会引发此对接函数的调用,根据已有的trigger判断事件监听情况。

Lmkd 处理PSI通知

References
• https://source.android.com/devices/tech/perf/lmkd
• Android Bootcamp 2018 Low Memory Killer changes
• Qcom document: ULMK and Memcg overview on android Go
• https://blog.csdn.net/u011733869/article/details/78820240
• http://tjtech.me/analyze‐lmk‐kernel.html
• https://lkml.org/lkml/2019/1/10/910