【技术分享】Go 工程化-前端性能监控接入层 Layout 设计实践
作者:黎志航&张翔,腾讯监控高级工程师
前言
本文主要介绍 腾讯云前端性能监控(RUM)在全新接入层上的 Go 工程化实践,介绍 Go 项目布局(下文称 Project Layout)的设计理念、设计规范、项目上的思考与实践,以及如何在多人协作开发下高效完成项目。
腾讯云前端性能监控介绍
前端性能监控(Real User Monitoring,RUM)是一站式前端监控解决方案,专注于 Web、小程序等场景监控。前端性能监控聚焦用户页面性能(页面测速,接口测速,CDN 测速等)和质量(JS 错误,Ajax 错误等),并且联动腾讯云应用性能观测实现前后端一体化监控。用户只需要安装 SDK 到自己的项目中,通过简单配置化,即可实现对用户页面质量的全方位守护,真正做到低成本使用和无侵入监控。点击文末「阅读原文」了解腾讯云前端性能监控。
目前前端性能监控平台每天处理超过上百亿的页面数据上报,日均 QPS 也超过百万。
如何理解项目的 Project Layout?
谈起这个,我想起一个特别有意思的聊天。
问:“我想做一个 go 的项目,用什么框架好?”
答:“你可能难以置信,原生最好!”
这个看法,对于一个项目的项目布局同样适用。如果你现在正在创建一个学习的项目,或者是一个很小的项目,没有必要纠结于如何创建 layout?怎么分层?因为绝大部分情况下,这个项目就是一个 main.go 可以搞定!“一把梭哈“把 datasource、业务逻辑、配置、路由全写到一个地方。
但是随着这样“一把梭哈”的方式生产出的项目不断扩大,不断有新成员加入你的项目,这个时候少了设计理念、规范、约束的项目就会变成杂乱、难以继续扩展,甚至不可维。
这时候就要做更多架构相关的事情了,而一个好的 Project Layout 来管理包/库/项目是非常重要的。而 Go 又恰好是一个面向包名设计的语言,可以通过各个包名进行组织 Go 的项目布局。
倘若研发团队的成员都遵循一个的 Layout 规范,可以很好地降低团队成员之间的合作成本,可以很好做好代码的防腐,减少代码的“坏味道”。
Standard Go Project Layout:
https://github.com/golang-standards/project-layout
该 git 库里面提到了很多 Golang 的规范,例如 /cmd , /internal ,/pkg, 其中 /cmd 会放置项目启动、停止的逻辑, /internal 放置项目内部使用的文件,/pkg 放置可复用的文件、库,例如 commons、utils、logger的封装等,更多更详细的说明,可以查阅 Standard Go Project Layout:https://github.com/golang-standards/project-layout。
既然 Go 社区已经规定了一些 Project Layout 的标准模版,为什么我们还需要一个自己的 Layout 规范呢?但是发生在 standard 和 reald world 的问题往往让人觉得很意外,下列我们将会一一揭晓。
RUM Project Layout 的思考
相信大家在写后台的时候第一种接触的目录结构,也就是三层架构或者 MVC 架构。
传统 Project Layout——三层架构
相信大家已经耳熟能详了,我再简单复习一下:
-
Controller 负载处理用户的请求,面向用户暴露的接口逻辑写在这里
-
Service 负责编写业务层的逻辑
-
DAO 负责处理数据层的逻辑,针对数据的增添、删除、修改、查找等
-
(View 层一般是端侧的面向用户的界面,与后台无关,不展开说明)
某头部互联网公司规约也对三层架构有过比较清晰的定义:
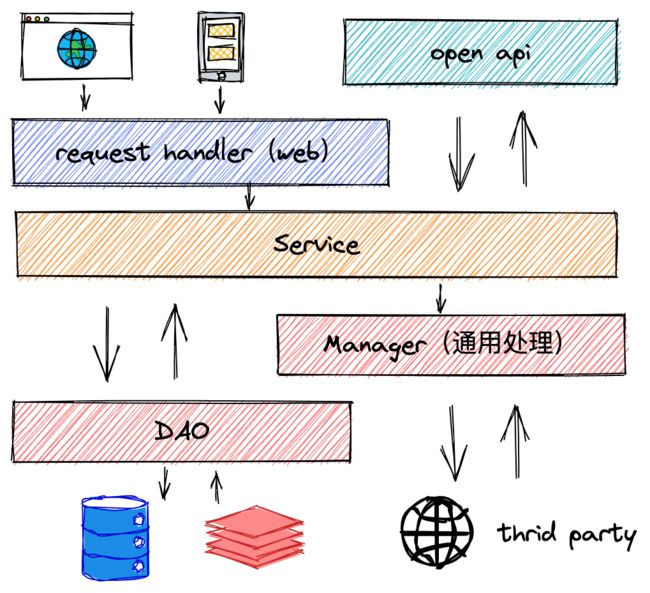
这里小编专门用中文标注了一个层级—manager 层,manager 层是常规规定 Controller、Service、DAO 之外的一个规范。
Manager 层的作用:1. 对第三方平台封装的层,预处理返回结果及转 化异常信息;2. 对 Service 层通用能力的下沉,如缓存方案、中间件通用处理;3. 与 DAO 层交互,对多个 DAO 的组合复用。
《Java 开发手册》
Manager 层也简单可以理解为是对于上层 service 的一些通用逻辑的封装,从而达到共享这部分逻辑的功能。以上看来三层架构是无懈可击的,普遍适用了绝大部分的场景,而且最重要的是容易理解,初学者都能很好上手。
但是从 PHP 一直到 Golang,写三层架构的时候都给我带来了一些困惑,我先来简化一下这个请求的逻辑:
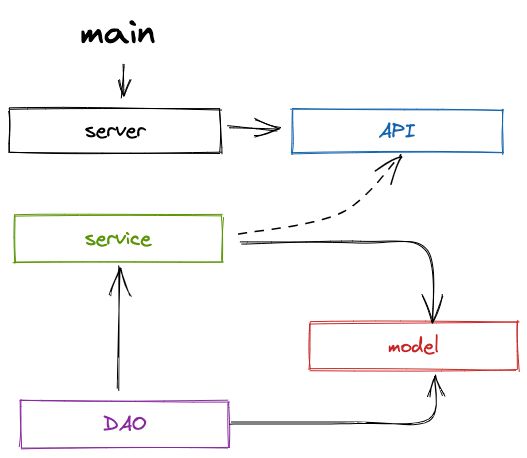
1. 实践中存在的问题:职责不清
传统的 Controller 层即接口处理层与 Service 业务逻辑层,会出现一些职责不清的问题,可能会写着写着出现一些越界逻辑。
来看这样一段代码:
// /controller/project/create_project.go...// 权限校验if _, err := service.GetGroupRole(gourpID, operator); err != nil {
// 权限不足,没有加入该 group
utils.ParamsErr(ctx, "Permission Denied")}
这是一段在 controller 的代码,client 传递过来的 groupID 和 operator 我们可能只能在 validate 层做一些类型的判断,例如是不是都是数字?
那进入到业务逻辑里面的时候,我们需要判断这个 operator 是不是有操作这个 group 的权限时,请问这一段逻辑是放到 service 层还是放在controller ?
假设放在 controller,是不是每个 controller 都容易堆积这样的一段代码呢?(刚好这里不适应使用 middleware 校验),怎么共享呢?如果放在 service 层,那就更加奇怪了,不是说好了在 controller 处理用户请求吗?怎么校验参数了(是不是显然越界了?)。
不仅如此, service 层和 manager 层同样有这样的问题,manager 是通用逻辑层是为了复用 service 层的逻辑,但是发现没有,其实 manager 和 service 其实是没有什么本质上的区别的,除非技术高超,否则在多人协作的场景下,manager 层,很容易就充当了 service 的层级,service 慢慢的也就变成另一个 controller 罢了。
在许多组织中重复使用的尝试解决方案是在架构中创建一个新层,并承诺这一次,真实而真实地,没有业务逻辑将被放入新层。但是,由于没有机制来检测违反该承诺的时间,组织几年后发现新层混乱了业务逻辑并且旧问题再次出现。
很显然这是职责不清。
2. 缺乏定义领域对象的概念。
很多领域中有重要防腐作用的概念,都没有在三层架构中体现。例如 VO、DTO、DO、PO 等都是没有在项目中体现的。
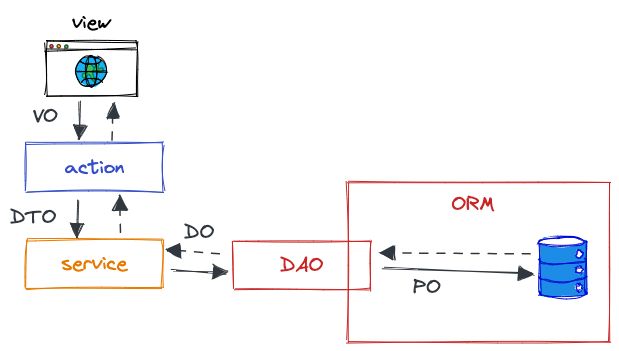
当我们不用定义领域对象,这些概念有什么问题?
没有这些概念对对象进行划分时,我们将会遇到:导致各个实体对象直接偷传到各个层级。透传的问题就是会导致客户端可能需要的数据字段,会污染整个业务对象,例如小程序客户端需要一个头像、性别,或者字段组成的字段时候,有可能这个对象就会贯穿整个服务,甚至到数据库表都是这样的对象。
举个例子:
type User struct {
ID Int
Sex String
Name String
Password String}
例如我们定义了这样的一个用户的对象,如果我们从 DAO一直到接口到客户端都使用这样的一个结构定义,后续客户端更新,需要增加更多的字段(甚至有一些接口是 DAO 层不需要的),那在修改数据库字段时,还要考虑会不会影响展示层,这样就污染了 DAO 层,本来 DAO 层数据的修改不应该影响接口层的展现。
另外,我们在用户对象还定义了一个用户的密码的字段,这个字段必然不能通过接口传递出去。所以透传问题就严峻了,需要有逻辑去过滤掉这个密码。
如果我们把数据层和逻辑层的数据结构都用同一个,并且是透传,业务层的字段慢慢渗透到储存的持久层,如果哪天 User 增加一个字段只是业务需要的,持久层是不需要的,那么也会逼迫着存储层增加同样的一个字段,面向数据表的设计造成的结果。所以说,如果不引入领域概念来引导改进项目结构,业务逻辑很容易就演变成编写数据库逻辑。
总而言之, DAO 被业务逻辑绑架了,业务和持久层混合,使到业务维护越来越困难,代码“越来越腐败”,慢慢的就会成了面向数据库写逻辑。
三层结构总体上,还是非常浅显易懂的,对于一个 CRUD 的项目,就用这样的设计,完全没问题,也没必要做什么改动,就是这样 MVC 架构挺好的也非常合适。但是如果项目本身逻辑足够复杂,我们还是需要更多的指导思想,来设计我们的 layout。
领域驱动设计 Domain-driven design
DDD( Domain-driven design) 相信很多同学都学习过,也就是领域驱动开发,它是一套指导开发和设计复杂软件的方法论。
腾讯云前端性能监控 (RUM )引入 DDD 是为了改善项目存在的一些问题,并且增加项目的可维护性。
这里稍微简单看一下 DDD 的一些相关概念,来看下面的图:
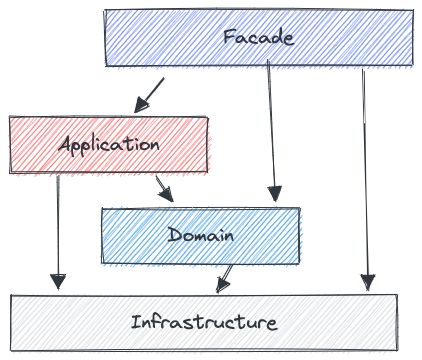
这里的 DDD 的架构图,绝对不是简单的 MVC 偷换概念,他每一个分层里面都有精心设计的一些非常好的指导思想。
-
接口层(Facade)一般包含用户界面、 web服务(restful、ws 等)可能还有其他服务。
-
应用层( Application)一般包含应用的服务,包括 DTO(Data transfer object)、service 等。
-
领域层(Domain)实现领域的核心业务逻辑,例如 model 、service、repo、module 等。
-
基础层(Infrastructure)基础层是贯穿所有层的,它的作用就是为其它各层提供通用的技术和基础服务,包括第三方工具、驱动、消息中间件、网关、文件、缓存以及数据库等。比较常见的功能还是提供数据库持久化。
分层的职责非常明确,每一层都能做到各司其职。数据库的存储和业务逻辑实现的对象也可以是不一样的,这里有一个 DTO 到 DO 的转换,使得不需要面向表来设计、不需要面向数据库编程。这就是 DDD 所提倡的边界各司其职的思想。这在整洁架构(The Clean Architecture)上体现得淋漓尽致:
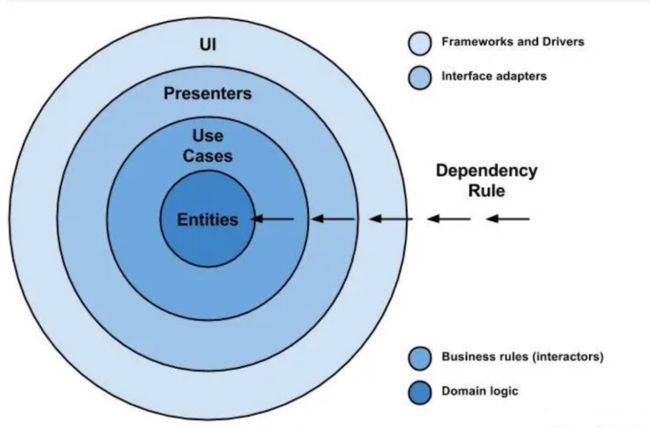
图片来源:https://sohu.com/a/157301348_468635
这种设计,在 trpc-go 目录规范上也有相关的实践:
-
gateway:代码入口网关层;
-
logic:与对外接口和外部依赖解耦的纯业务逻辑层;
-
repository:外部 rpc/store/remotecfg 等网络依赖层。
-
entity: 实体结构层
-
gateway 依赖 logic,logic 依赖 repository,且必须
单向依赖,上下层之间通过 interface wrapper 联通,各层内部变动不能影响外层,结合Dependency Inversion Principle保证可测试性。
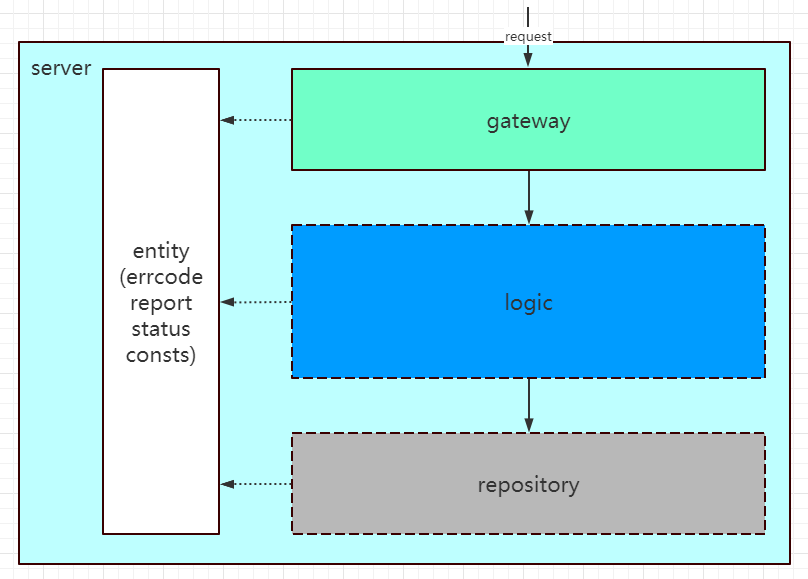
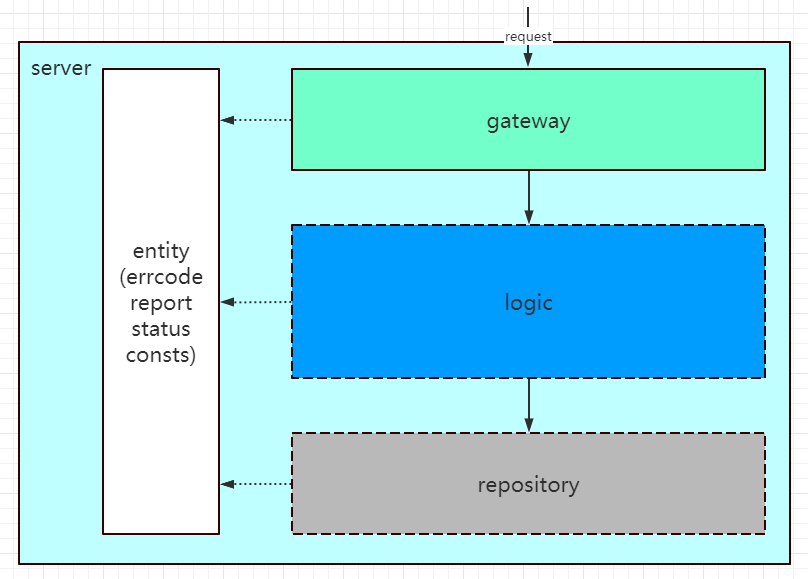
我们重新回到 DDD 的话题上,既然业界上也有这么多 DDD 的实践,怎么不可直接用呢?
实际上,DDD 规定了分层,告诉了我们怎么分层比较好,但是没有告诉我们怎么做。
在各大语言框架里面实现 DDD 分层,都是非常脆弱的。实现 DDD 项目分层非常复杂,不是一个程序员能一上来就能写好的,更别说一开始能根据概念分清楚自己的代码应该写在哪里。再加上 DDD 的概念众多(比如 聚合根,值对象,六边形架构,CQRS(命令和查询职责分离),事件驱动等等概念,让人望而却步。很多层级目录未必也就能套进去,所以在DDD 在落地上存在着非常大的困难。
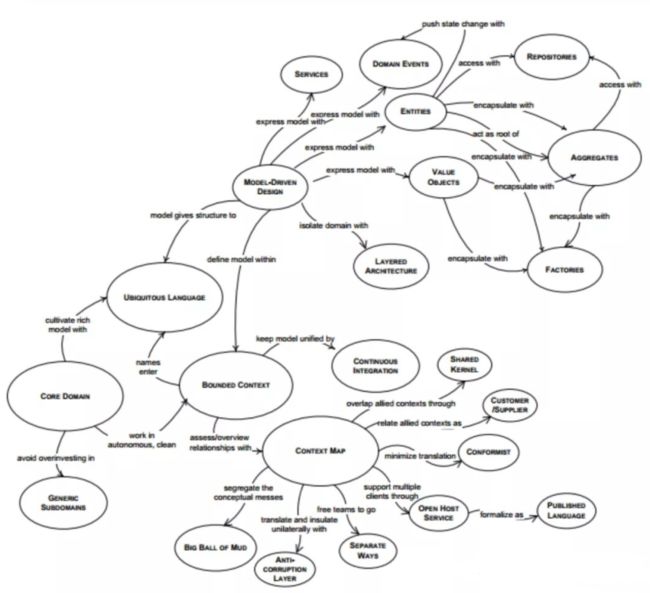
[复杂的 DDD]
RUM Project Layout****工程化设计基本理念
我们是需要一个新的 Project Layout,既用上 DDD 的优点,又可以让层级更加简单一些,可维护性更强一些。
但是这不意味我们就要生搬硬套 DDD 的过来,这样容易从一个极端走进另一个极端,让开发难度指数上升,对于一个新入职的开发而言:什么实体、值对象、各种事件、模型、聚合根,还没开始写代码就被撒腿跑了,何来共建呢?
DDD 的工程目录对于开发人员来说门槛过高且过于理想化,开发人员水平参差不齐也容易导致 DDD 目录被破坏掉。所以我决定另辟蹊径。
设计理念
RUM 基于 tRPC-Go 搭建, 参考了 kratos http://go-kratos.dev推荐的 layout 方式,但是没有直接使用,并在这个的基础上做了很多裁剪,这种方式更适合协作开发。新 Layout 融合 DDD的四层设计与 MVC 三层项目结构,可以避免 DDD 过于复杂的概念与目录层级,同时也避免 MVC 三层架构 Service 代码堆积问题。
**新 Layout与DDD 、三层架构的映射关系
**
既然是融合了 DDD 与 MVC 的结构,不妨来看下映射关系是怎么样的,方便熟悉 DDD 或者 MVC 的加深理解。
1. 新 Layout 与 DDD 的映射关系
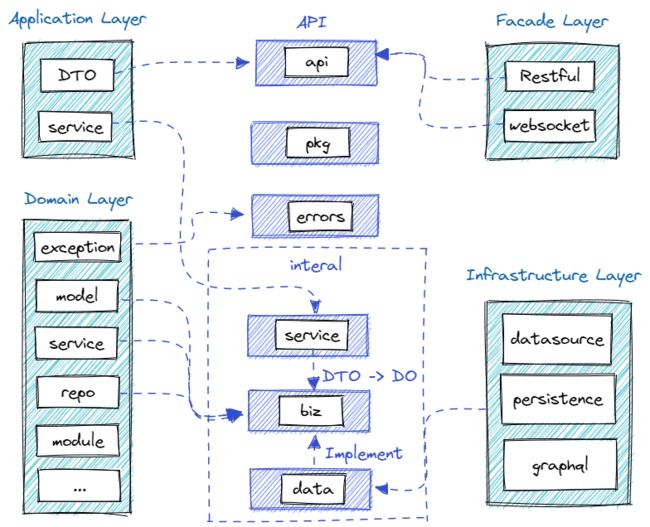
DDD 一般分成四层:接口层、应用层、领域层和基础层。
-
其中接口层(Facade layer)一般包含用户界面、 web服务(restful、ws 等)可能还有其他服务,他对应过来我们的 layout 就是 api 层文件夹,包含了提供web、rpc 等服务的 pb 文件以及 api 的定义
-
应用层( Application layer)一般包含应用的服务,包括 DTO(Data transfer object)、service 等,对应我们 layout 的 internal/service 的服务应用层,是用来实现 api 的逻辑,主要任务是把 DTO 转换到 DO( DTO 就是 Data Transform Object,专门用于数据传输的,比如说 ProtoBuf 定义的数据就是 DTO )。
-
领域层(Domain layer)实现领域的核心业务逻辑,例如 model 、service、repo、module 等。对应我们的 biz 层,主要负责组装业务逻辑,定义 repo等
-
基础层(Infrastructure layer)基础层是贯穿所有层的,它的作用就是为其它各层提供通用的技术和基础服务,包括第三方工具、驱动、消息中间件、网关、文件、缓存以及数据库等。比较常见的功能还是提供数据库持久化。对应我们的 layout 的 data 层,主要是封装一些业务数据的访问,例如 kafka、redis、db 等,他是对于 biz 定义的 repo 接口的实现。
2、新 Layout 与三层架构的映射关系
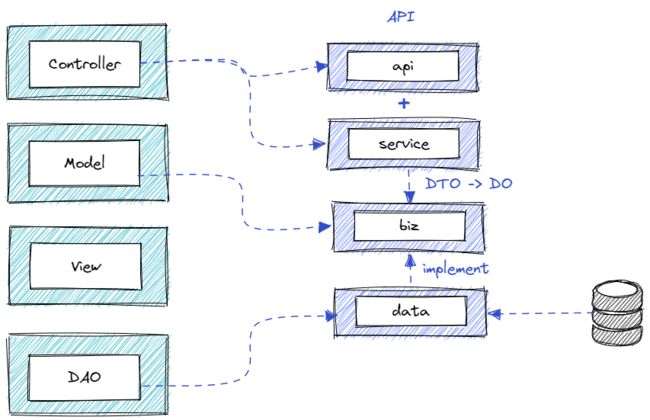
与 MVC 的对照关系就稍微简单一些。
-
Controller 就对应 api + service 负责处理请求
-
Mode 就是 biz 层,类似的作用是描述应用逻辑层(也叫领域层)的对象,这些对象是你开发的应用程序中的一些核心对象。
-
View 无
-
DAO :DAO 就对应我们 layout 的 data 层,但是与之不同的是,DAO一般只描述和存取数据,而 data 更偏向于是将领域对象从持久层取出来。
**Project Layout 介绍
**
1. 我们首先来看一下 RUM 文件树:
// project layout├── api
│ └── rum_collect_svr
│ └── stub
│ └── git.code.oa.com
│ ├── trpc
│ │ └── common
│ │ └── validate.proto
│ └── trpcprotocol
│ └── rum
│ └── collect_rum_collect_svr
│ ├── go.mod
│ ├── go.sum
│ ├── rum_collect_svr_mock.go
│ ├── rum_collect_svr.pb.go
│ ├── rum_collect_svr.pb.validate.go
│ ├── rum_collect_svr.proto
│ └── rum_collect_svr.trpc.go
├── cmd
│ └── interface
│ └── main.go
├── configs
│ ├── Development
│ │ ├── app.yaml
│ │ └── trpc_go.yaml
│ └── Production
├── docs
│ └── architecture.md
├── errors
│ ├── errors.go
│ └── errors_test.go
├── go.mod
├── go.sum
├── internal
│ ├── biz
│ │ ├── domain
│ │ │ ├── project.go
│ │ │ └── project_test.go
│ │ ├── repo
│ │ └── usecase
│ ├── data
│ │ ├── do│ │ │ └── project.go
│ │ ├── project_repo.go
│ │ └── project_repo_test.go
│ ├── pkg
│ │ ├── chain
│ │ ├── datasource
│ │ ├── monitor
│ │ └── pipeline
│ ├── server
│ │ └── trpc.go
│ └── service
│ ├── collect.go
│ └── healthcheck.go
├── main.go
├── makefile
├── pkg
│ ├── filter
│ └── utils
├── scripts
│ ├── monitor.sh
│ ├── README.md
│ ├── start.sh
│ └── stop.sh
├── test
├── transport
│ └── rum
├── trpc_go.yaml
└── trpc.log
2. 那下面我就顺着 layout 的各个功能模块和层级,分别给大家介绍一下。
Go 目录
首先介绍几个和 go standard layout 配合并额目录
-
/cmd
cmd 目录主要是负责项目的初始化,包括读取配置等,以及控制项目的启动、关闭、配置初始化。每个应用程序的目录名应该与你想要的可执行文件的名称相匹配(例如 /cmd/interface ),但是这里存放的并不是整个 Golang 项目的启动文件(main.go),这样 go build 后是一个名为 cmd 的二进制文件,无人知晓是项目的启动文件。
-
/internal
这个目录是由 go 编译器本身强制执行的一个规定,私有应用程序和库代码,这里的代码将会拒绝他人 import 。 /internal 4 个重要的文件夹 biz、data、service、service 将会在通用应用目录详细介绍。
-
/pkg
放置一些可以被外部 import 的代码,在这里放了一些 trpc-go 的 filter 、logger 插件 和一些可以共享的 utils。其他的项目会 import 这些库、所以这里放入的包,不能依赖于本项目的一些配置,如果不希望你的库、代码被其他项目引用,建议还是放入 /internal 目录下 。
服务应用程序目录
-
/api
约定 API 协议的目录,我们在这里放置了 trpc 的 proto 文件,以及 trpc-go 生成的文件也放在这里。
-
/transport
我们在这里放置了一些协议层的插件,得益于 tRPC 以插件机制,我们将协议层抽象成一个个可插拔的插件,这样我们只需要配置就可以暴露各种不同的协议实现服务。例如我们这里有个 RUM 的文件夹,里面是用于规整和转换各个 SDK 上报的数据的一个协议层插件,使接口可以同时兼容 rpc、HTTP 等方式调用。
-
/errors
服务自定义的错误定义在这里。
通用应用目录
-
/configs
配置文件文件夹,这里会放入一些项目启动时候会读取的一些配置,其他的配置我们会放到 rainbow 中。configs 下面还会区分 Development 和 Production 的文件夹
-
/scripts
各种执行操作的脚本会放在这里,例如启动、停止服务、构建、监控的脚本等。这些脚本也会被跟目录的 makefile 所调用。
应用内部目录 /internal/*
-
/internal/server
创建 trpc 、http 服务,并且注入配置、service。
-
/internal/service
类似于 DDD 的 application 层,处理用户的请求,并且实现 DTO 到 DO 的转换。
-
/internal/biz
领域定义模型层,将 model,service,dao 相关的 interface 设计放在这里,并实现业务逻辑。
类似于 DDD 的 domain 层,其中 repo 的接口也定义在这里。
同时 DDD 的 usecase 也放这里,它包含了应用特有的业务规则。封装和实现了系统的所有用例,可以理解为能够复用的逻辑。我们会在应用初始化的时候带在 provider 上。
-
/internal/data
也就是 DAO 里面的 interface 的实现,我们通过 data 去掉了 DDD 基础层
主要是封装一些业务数据的访问,例如 Kafka、Redis、DB 等,同时在 data 这里实现 biz 定义的 repo 接口。
-
/internal/pkg
项目内部共享,不希望被外部项目引用的可以复用的代码。
其他目录
-
/docs
项目的介绍、设计、开发文档。除了根目录的 README.md 外关于项目需要记录的 text 内容可以放到这里。
-
/test
不是放置测试用例,测试用例直接写在被测试的代码隔壁即可。
这里更多的是放测试数据、方便测试的一些脚本或者程序。例如我们有 /test/http/data 。
-
makefile
makefile 非常强大,我们会在这放置一些相关的命令,例如 build tool cli、 stub、test 、golang lint 、docker compose 启动命令等。
**总结
**
引入 DDD( Domain-driven design) 概念会让代码变得需要理解更多的概念,但是换来的是可维护性更强。
软件工程设计“没有银弹”,每个项目的情况不一样,适合项目的才是最好的。
参考文献:
-
Standard Go Project Layout
-
https://www.infoq.cn/article/mee5qutrtjvgwzpp57y6