服务器监控报警系统软件设计,Monitor监控报警系统
申请指南
每个游戏申请正式上线通过后,都会发放对应的项目代号,如:[sample],这个项目代号就是该网络游戏的唯一标识,每个游戏都会有自己的项目代号。
注意:下文中用到[sample]的地方就代表了需要用项目代号去填,每个游戏请填写自己的项目代号!
拿到项目代号后,会同时拿到该项目在监控系统相关的influxdb,grafana服务的账号和密码。账号就是项目代号[sample],密码是16位随机字符串。
简介
Monitor监控系统是基于第三方开源监控服务Grafana搭建的,详情及教程可以参考Grafana的官方网站,本教程只简要介绍如何在Apollo开服工具中使用Monitor监控系统。
域名和账号
账号:[sample](就是项目代号)
密码:游戏接入的时候会发放,16位随机字符串
入门教程
这里只介绍一些简单的常用方法,更详细的教程请到Grafana的官方网站学习。
初次使用
使用给到的grafana账号密码登录Monitor监控系统

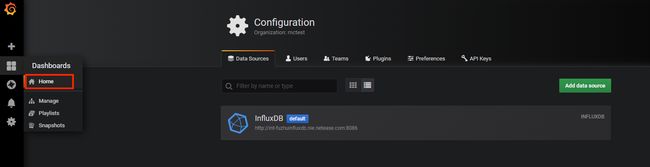
登录成功后进入Home Dashboard,由于还没有创建任何面板,所以这里还是空的,鼠标指向左下角用户图标,发现目前正处于Main org.的组织中,点击它切换到自己项目组织下。
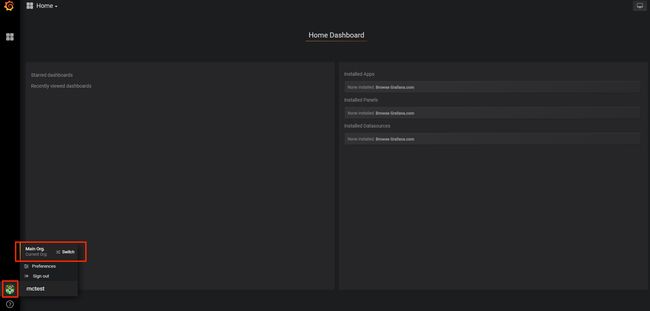
可以发现除了Main org.外还有另一个组织mctest,其实就是跟你的项目代号名称一样的组织,这个就是对应你的游戏的组织,点击Switch
to切换到自己的组织。
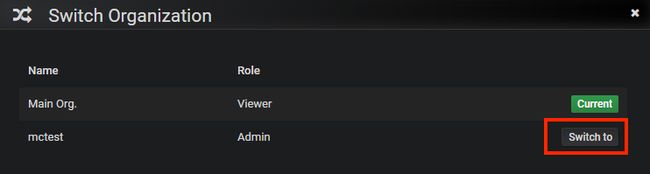
成功切换后,再次来到Home Dashboard面板,这次可以发现它提示你做下一步:添加数据源。
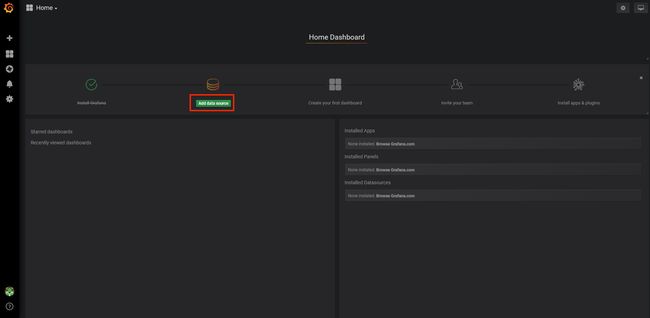
数据源就是存放监控数据的数据库,Apollo开服工具提供的监控数据库是InfluxDB,关于InfluxDB的详细介绍会在后面的章节中给出。这里先选中InfluxDB,创建一个数据源来连接自己的监控数据库。
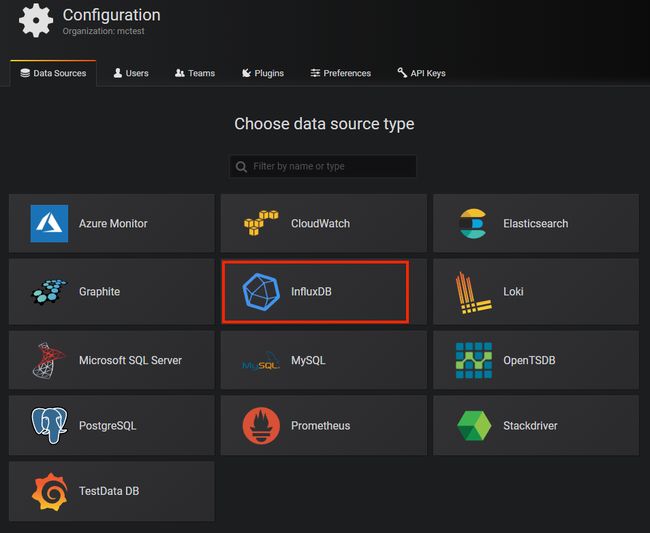
InfluxDB数据源的配置,参考下图所示。
Name 可以自定义,就是你给数据源起个名字,这里直接用默认的 InfluxDB 就行。
HTTP 部分:正式环境的InfluxDB域名是http://influxdb.apollo.netease.com:8086,填写到 HTTP URL 中,其他不用勾选。
Auth 部分:勾选上 Basic Auth,User 填项目代号 [sample],Password 填之前给到的 InfluxDB
密码。
InfluxDB Details 部分:Database 填项目代号 [sample],User 填项目代号 [sample],Password
填之前给到的 InfluxDB 密码。

填好之后,点击下方的Save & Test按钮,如果都填对了,那么会发现提示:Data source is working。

配置完数据源之后,点击Back按钮回到配置页面,接着返回到Home面板继续下一步:创建监控面板。
点击New dashboard按钮创建新的面板。

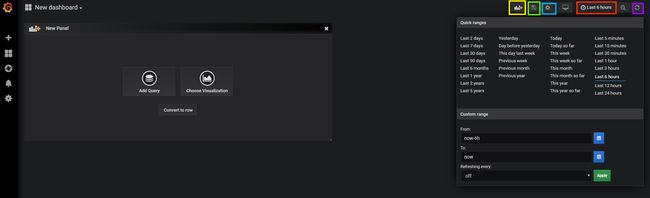
来到面板界面,这里将是你以后经常查看监控图表的地方。首先介绍右上角的操作:
红框点开后,出现时间区间选取页面,详细使用方法可以自行探索,或者参考Grafana的官方网站。
黄框点击后,可以用来新建一张图表,具体图表使用方法后续介绍。
绿框点击后,可以保存你当前对面板所做的改动,记得保存,否则你的修改将不会被保存下来。
蓝框点击后,进入面板设置界面,后续介绍。
紫框点击后,可以刷新当前时间区间。
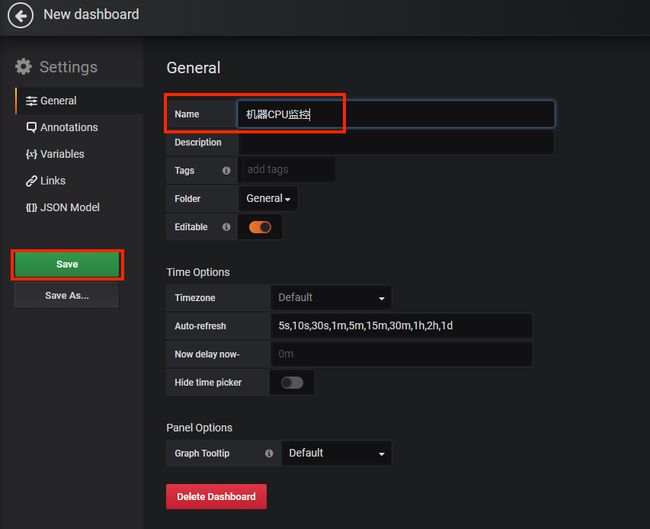
先点击面板设置,给当前面板取一个名字,然后保存。
然后,我们对监控系统的初次使用介绍到此为止。接下来将介绍图表的使用。
使用监控图表
进入监控面板页面后,点击右上角的add panel按钮增加一个图表。再点击Add
Query按钮即可进入到如下页面。
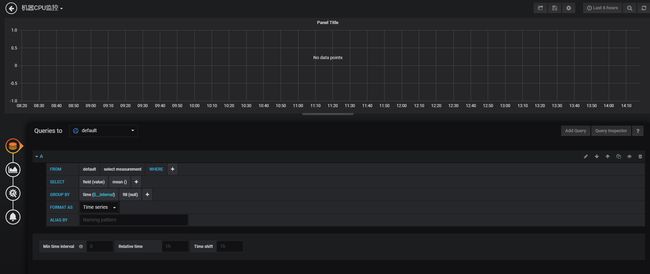
实际上监控图表所作的工作,就是执行用户给定的查询语句,从数据源中查询到数据,然后图形化地显示出来。下图以监控物理机的CPU使用率为例,从procstat表中查询cpu_usage字段,按照
进程名(process_name)来分组,以10s为时间区间组合起来,组合值取平均值显示。
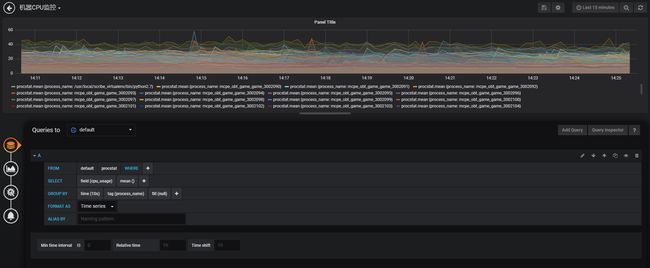
然后点右上角的保存按钮,就可以将图表保存起来。更详细的教程,请直接参考Grafana的官方网站。
使用模板
官方给所有的服主提供了一些通用的面板模板,服主只需要直接导入json文件,再做一些配置,就可以快速搭建好各服务器的基础监控。这些模板文件都放在template/monitor文件夹下,都是JSON文件。下面将以CPU模板为例,介绍如何导入官方提供的面板模板。
首先在左边的快捷栏中,将鼠标指向加号按钮,点击Import按钮。
然后点击右上角的Upload .json File按钮,选择模板-CPU.json文件。

之后在导入选项界面,创建一个文件夹来存放,CPU模板是用来监控物理机的CPU,所以创建一个文件夹叫物理机,然后点击Import按钮导入模板。

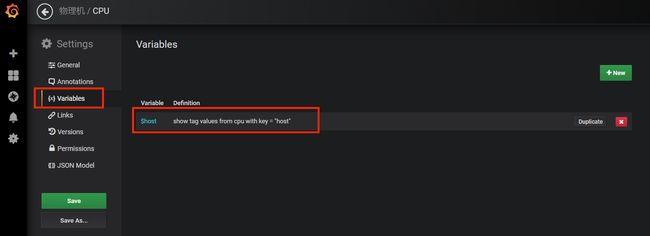
导入成功后进入面板界面,已经可以看到一个图表有数据显示了,但是右上角有错误提示:Datasource named minecraft was not
found。这是因为模板中使用了全局变量的配置,就是图中左上角绿框部分,这个是在面板设置界面中配置的。正是因为这个错误,所以后边的图表没有显示数据。

接下来我们打开面板的设置界面,将这个全局变量host配置好。点击右上角齿轮模样的按钮可以进入面板的设置界面。然后点击Variables进入全局变量设置的标签页,点击全局变量$host。
进入该变量的编辑页面之后可以发现Data source项是空的,点开,选择自己的数据源,一般是自己的项目代号[sample]。
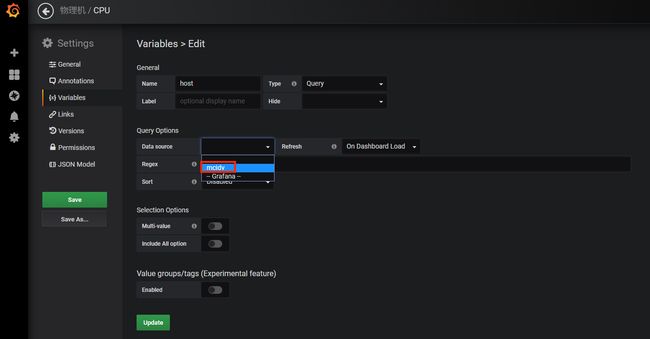
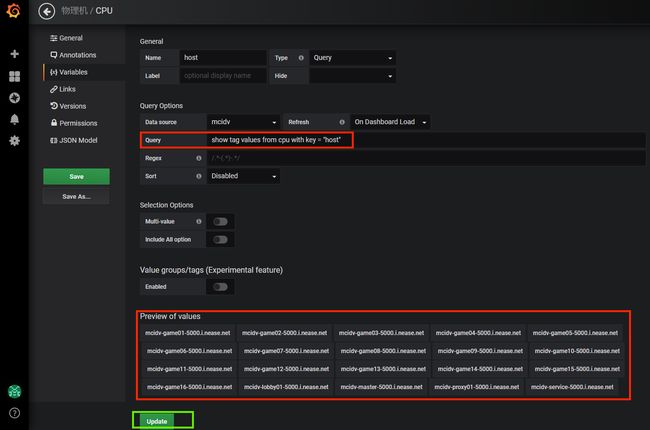
接着在Query栏中输入查询语句:show tag values from cpu with key =
"host",即可在下方预览到查询出来的值,这些值就是该全局变量可选的值。最后点Update按钮更新。
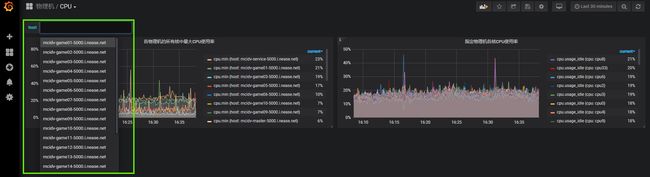
再返回到面板界面,发现第二张图也恢复数据显示了,通过左上角的全局变量选项栏可以选择你想要看的物理机,选择之后第二个图表会显示对应这台物理机上面各个CPU核心的使用率。
监控数据上传
监控系统中的数据都是通过监控Mod上传到监控数据库 (InfluxDB)
的,所以要能看到游戏相关的数据,比如在线人数之类的,就需要先开发和部署监控Mod。官方的监控Mod中已经包含了一些基础信息的收集和上报,所以如果你什么都不改,只用官方监控Mod的话,也可以看到包括各服人数,各服状态等基本信息。官方Mod默认会跟随Apollo开服工具一起部署,所以每个开启的服务都一定会包含官方Mod。
监控Mod配置
要使用监控Mod来上传数据,需要在配置中填写相关配置。在deploy.json文件中,common级别下,跟redis的配置级别同级的地方,加上influxdb配置,如下:
"influxdb": {
"host": "http://influxdb.apollo.netease.com", # 这个是对应正式环境的 influxdb 域名
"port": 8086,
"user": "sample", # 这里填写你的项目代号
"password": "xxxxxxxxxxxxxxxx", # 这里填写分配给你的 influxdb 密码
"database": "sample", # 这里填写你的项目代号
"interval": 60, # 这里填写监控时间间隔
"enabled": true # 这里设置监控系统是否开启
}
然后重新部署服务器,即可开启监控系统数据上传。
官方监控Mod
官方提供的监控Mod一共有两个,分别是neteaseMonitor和neteaseMonitorSample。
neteaseMonitor:这个Mod是monitor监控引擎,服主不能修改这个Mod,由于是官方Mod,每次部署的时候都会放进去的,所以服主自己的开发Mod中也不需要包含这个进来。
neteaseMonitorSample:这个Mod是官方提供的监控Mod示例,里面包含了官方写好的基础监控信息,可以用来作为学习使用,不要修改。如果需要开发自己的监控Mod,可以新建一个Mod。下文会介绍如何开发自己的监控Mod。
跟其他的Apollo开服工具Mod 类似,每个Mod都需要区分是跑在
master/service/lobby/game,监控Mod也一样,下午将以 master 中的监控Mod为例,其他角色中的监控Mod也是类似的,可以自行根据示例代码学习。
如何开发自己的监控Mod
开发自己的监控Mod参考官方范例neteaseMonitorSample即可,首先新建一个Mod,目录如下图所示:

在modMain.py中实现一个基础的Mod框架
x
# -*- coding: utf-8 -*-
import logout
from common.mod import Mod
'''
自定义的监控Mod
'''
@Mod.Binding(name="selfMonitor",version="1.0")
class SelfMonitorMod(object):
def __init__(self):
pass
@Mod.InitMaster()
def initMaster(self):
logout.info('----- SelfMonitorMod init')
@Mod.DestroyMaster()
def destroyMaster(self):
logout.info('----- SelfMonitorMod destroy')
然后引入monitor引擎,在初始化中注册自己的监控函数获取器。这个获取器实际上就是为了定义开发者自己的监控函数列表,在这个函数中需要返回你想在每次监控系统采数据的时候执行的函数列表。
xxxxxxxxxx
# -*- coding: utf-8 -*-
import logout
from common.mod import Mod
import neteaseMonitor.monitor as monitor # 引入monitor引擎
'''
自定义的监控Mod
'''
@Mod.Binding(name="selfMonitor",version="1.0")
class SelfMonitorMod(object):
def __init__(self):
pass
@Mod.InitMaster()
def initMaster(self):
logout.info('----- SelfMonitorMod init')
# 注册监控函数获取器
monitor.RegisterTaskGetter('SelfMonitorGetter', self.SelfMonitorGetter)
@Mod.DestroyMaster()
def destroyMaster(self):
logout.info('----- SelfMonitorMod destroy')
# 注销监控函数获取器
monitor.UnregisterTaskGetter('SelfMonitorGetter')
def SelfMonitorGetter(self):
'''
自定义监控函数
'''
# 这里可以添加自己的监控函数列表,之所以这么设计是因为
# 方便这个mod热更,可以通过热更的方式增加或者删除监控
tsks = []
return tsks
然后这里列举一个例子,监控当前服务器的TPS,即Tick Per
Second。
xxxxxxxxxx
# -*- coding: utf-8 -*-
import logout
import time # 引入 time 来获取当前时间戳
from common.mod import Mod
import neteaseMonitor.monitor as monitor
import master.masterConf as masterConf # 引入 masterConf 是为了从中获取 master 当前配置
'''
自定义的监控Mod
'''
@Mod.Binding(name="selfMonitor",version="1.0")
class SelfMonitorMod(object):
def __init__(self):
self.lastGatherTime = int(round(time.time())) # 记录上次监控的时间戳,用于计算两次统计的时间间隔
self.lastTick = 0 # 记录上次的tick值,用于计算两次统计的tick差值
@Mod.InitMaster()
def initMaster(self):
logout.info('----- SelfMonitorMod init')
monitor.RegisterTaskGetter('SelfMonitorGetter', self.SelfMonitorGetter)
@Mod.DestroyMaster()
def destroyMaster(self):
logout.info('----- SelfMonitorMod destroy')
monitor.UnregisterTaskGetter('SelfMonitorGetter')
def SelfMonitorGetter(self):
'''
自定义监控函数
'''
tsks = []
tsks.append(self.GatherTps) # 加上自己的监控TPS的函数
return tsks
# 脚本执行tps
# 传入参数是当前Monitor引擎从启动至今的tick值,每次tick都会加一,每隔一段时间间隔才会触发监控系统进行数据收集
def GatherTps(self, totalTick):
ps = []
now = int(round(time.time()))
if now - self.lastGatherTime == 0:
tps = 0
else:
tps = (totalTick - self.lastTick) / (now - self.lastGatherTime)
self.lastGatherTime = now
self.lastTick = totalTick
# 0表示master
appversion = masterConf.masterConf.get('app_version', '')
mytype = masterConf.masterConf.get('type', '')
host = masterConf.masterConf.get('ip', '')
port = masterConf.masterConf.get('port', 0)
myid = 0
ps.append(monitor.Point().measurement('server_tps').tag('app_version', appversion).tag('type', mytype).tag('serverid', myid).tag('host', host).field('port', port).field('num', tps))
return ps
将上述Mod放入Apollo开服工具中部署,生效后即可在Monitor监控系统中查看。从数据源中,server_tps 表里面读取你上传上去的数据。
报警系统
报警系统是基于Grafana搭建的,在Grafana的图表中设置好报警条件及阈值后,一旦符合报警的要求,就会自动触发报警。触发报警后Grafana将会发送一条报警消息到官方的报警服务器,然后由报警服务器决定该如何进行通知。目前通知方式需要联系官方管理员进行配置,暂不提供自定义配置。下面将对如何使用报警系统进行介绍:
设置报警通道
登录Monitor监控网站,鼠标指向左边选项栏中铃铛模样的标签,点击Notification channels。

点击中间的Add channel按钮创建第一个报警通道。
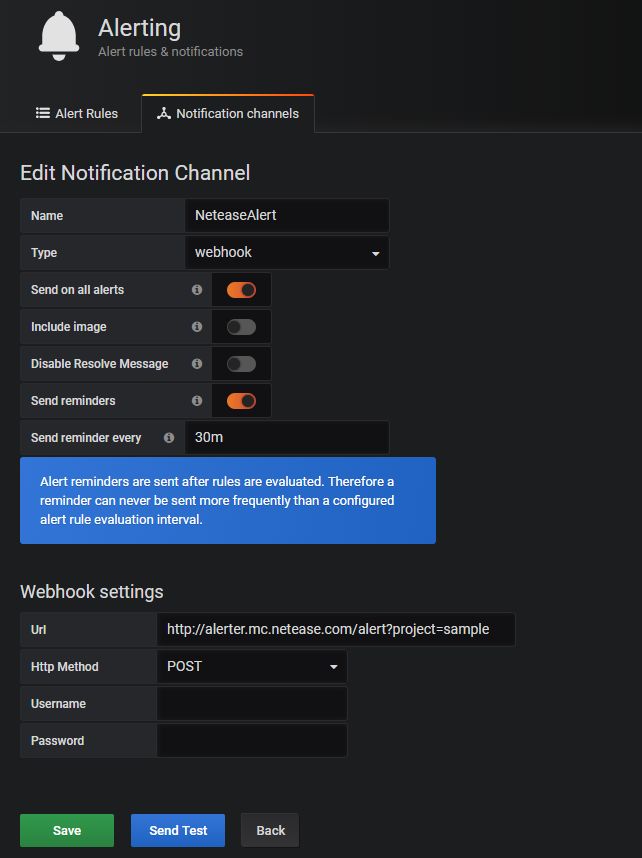
在报警通道设置界面:
Name 部分:填一个名字,这里填NeteaseAlert
Type 部分:选择webhook方式
Send on all alerts:勾选后表示默认所有的报警都会通过这个通道发
Include image:勾选后表示在报警的时候同时截图发送,因为目前的报警通知不支持图片,所以这里不用勾选
Disable Resolve Message:勾选后表示当状态从报警中恢复到正常时,不再发送信息,即不告知恢复正常,这里不用勾选
Send reminders:勾选后表示除了状态刚变成报警中时会发报警消息,过后每隔一段时间,如果依然处于报警中的状态,那么还会发一次重复报警
Send reminder every:表示每隔多长时间发送重复报警,这里填默认30分钟
Http Method:选择 POST
之后点Send Test按钮检查是否配置正确,如果没问题,就点Save按钮保存。
完成以上配置后,Grafana 的报警消息到官方报警服务器就打通了。接着请联系管理员为你的游戏项目设置好对应的通知方式,期间可以通过上文描述的Send
Test来测试。
为图表设置报警
在图表的设置界面,同样有一个铃铛模样的标签页,在这里选择Create Alert。

具体的报警设置,按照如下说明来:
Name:就是这个报警的名字
Evaluate every:表示每隔多长时间检查下面的条件是否成立
For:这个选项可不设置,不设置表示每次检查一旦发现条件成立就会发通知。如果设置,则表示条件成立后,并不会将状态直接从 OK 改为 Alert,而是先变为 Pending
状态,这时候不会立即发通知,等这个条件一直满足超过设定的 For 的时间,才会将状态改为 Alert,并发送通知
Conditions:条件组中可以设置多个条件,只有判断成立才触发状态变更
avg():用来控制如何将搜索出来的数据集计算得出一个可以跟阈值进行比较的值,可以换成 max(), min() 等等
query(A, 5m, now):第一个参数指定了是用哪个语句来执行,就是代表了图表的查询语句标签页定义的语句。后面的两个参数5m,
now则表示了时间区间,5分钟之前到现在。如果填成10m, now-2m则表示10分钟之前到2分钟之前的这段时间。
IS ABOVE 200:表示算出来的结果是否超过200,这种跟阈值对比的算法可以自行修改。
No Data & Error Handling:表示没有收到数据,或者执行出错的情况下,将状态设置成什么。
Send to:NeteaseAlert,因为之前我们将这个设置为所有报警都要发的通道。
Message:这里表示发出的报警的文字内容是什么。

以上设置完毕后,报警即开始生效。可以在Alerting管理界面管理定制好的各项报警规则,可以暂停或启动。
