计网第四章.网络层—路由选择协议和IP数据报的首部格式
以下来自湖科大
计算机网络公开课笔记
一、路由选择协议
路由选择分为静态和动态。
静态路由选择:人工配置
动态路由选择:通过路由选择协议自动获取路由信息。
1.1 路由选择协议分类
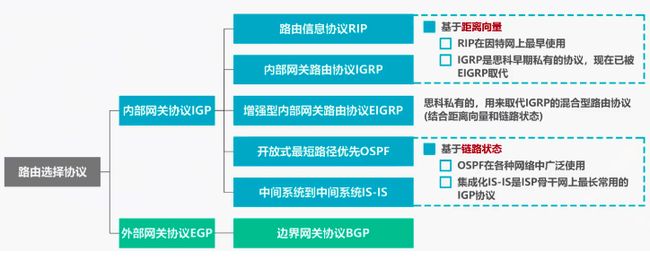
上图中叫网关协议,是之前的叫法,后来就叫路由协议。
本文只讲RIP协议、OSPF协议、BGP协议三个。
1.2 路由器基本结构
注意转发表是由路由表得出的,但是后续课程中为了容易理解而没有严格区分,都叫路由表
整个路由器结构可划分为两大部分,一个是路由选择部分(包含路由选择处理机),另一个是分组转发部分:
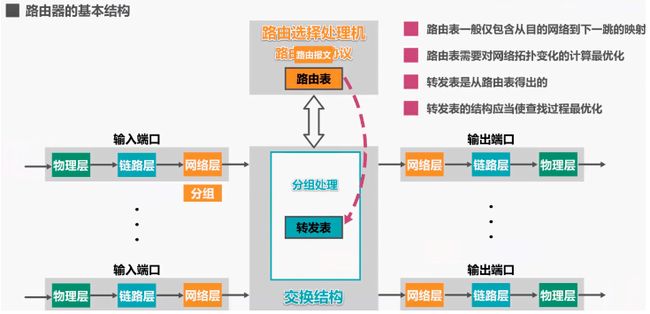
路由器对数据报的处理过程:
(一)输入路由器
电信号从某个输入端口进入路由器,物理层将信号转换成比特流,送交数据链路层处理,数据链入层从比特流中识别出帧,去掉帧头和帧尾后,送交网络层处理。如果送交网络层的分组是普通代转发的数据分组,则根据分组首部中的目的地址进行查表转发,若找不到匹配的转发条目,则丢弃分组(并通告源主机),否则按照匹配条目中所指示的端口进行转发。
如果送交网络层的分组,是路由器之间交换路由信息的路由报文则把这种分组送交路由选择处理机,路由选择处理机根据分组的内容来更新自己的路由表。路由表一般仅包含从目的网络到下一跳的映射
(二)从路由器输出
网络层更新数据分组首部中某些字段的值,例如将数据分组的生存时间减一(防止路由环路问题即死循环),然后送交数据链路层进行封装,数据链路层将数据分组封装成帧,送交物理层处理,物理层将帧看作是比特流,将其变换成相应的电信号进行发送。
(三)路由器的输入、输出缓冲区
路由器的各端口还应具有输入缓冲区和输出缓冲区,输入缓冲区用来暂存,新进入路由器,但还来不及处理的分组;输出缓冲区用来暂存,已经处理完毕,但还来不及发送的分组
三种路由选择协议:RIP协议、OSPF协议、BGP协议
1.3 路由信息协议RIP——适用小型互联网
Routing Information Protocal
RIP要求自治系统内的每一个路由器都要维护从他自己到自治系统内其他每一个网络的距离记录,这是一组距离,称为距离向量D-V(Distance-Vector)
自治系统AS可以理解为就是子网,因特网是分层次的,会把一些网络和路由器划分成不同的自治系统,比如不同国家之间就是不同的自治系统
RIP使用跳数作为度量来衡量到达目的网络的距离。将路由器到直连网络的距离定义为1,例如下图中的路由器R1到其直连网络N1的距离为1。将路由器到非直连网络的距离,定义为所经过的路由器数+1

R3到N1是经过2个路由器,所以距离为3
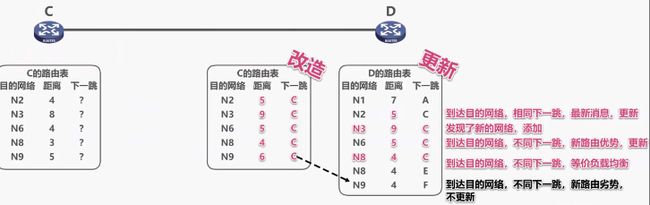
RIP的三个要点:

路由器收到隔壁路由器发来的路由表,会根据这个路由表来更新自己的路由表,先是新增目的网络,而且因为新目的网络的出现,路由距离也变化了,如果有更短的方式,改路由器就会更新距离和下一跳的路由器
缺点1:
RIP允许一条路径最多只能包含15个路由器,距离等于16时,相当于不可达。因此RIP只适用于小型互联网
缺点2:
RIP认为距离短的路由是好的路由,也就是所通过路由器数量最少的路由,即使那条路上的带宽很小!!如下图,RIP认为R1—R4—R5是最好的路由:
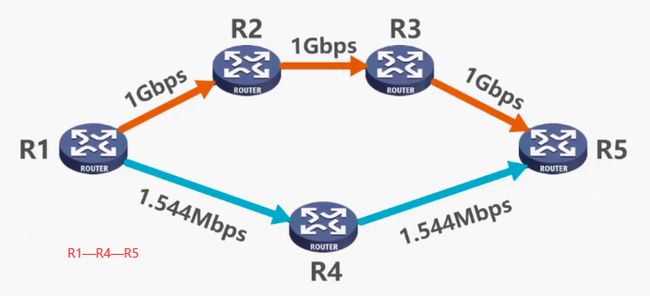
当几条路由距离相等时,就将通信量均匀地分布到这些等价的路由上——等价负载均衡
缺点3:
“坏消息传的慢”问题。就是某个节点故障了,相邻的路由器(如A)知道不可到达,但是有些路由器(如B)先发了路由表过来,A就以为能通过B到达该节点,因为路由表记录的就是距离和下一跳,然后A的又发给B,B又以为下一跳是A,两者互相跳,形成路由环路
坏消息传的慢,又称为 路由环路 或 距离无穷技术问题,这是距离向量算法的一个固有问题
解决:
-
当路由表发生变化时,就要立即发送更新报文及触发更新,而不仅是周期性发送;
-
让路由器记录收到某特定路由信息的接口,而不让同一路由信息再通过此接口向反方向传送,即水平分割。
请注意使用上述措施后,也不能彻底避免路由环路问题,这是距离向量算法的本质所决定的
1.4 开放最短路径优先OSPF——解决了RIP的问题
Open Shortest Path First,开放最短路径优先。克服了上述RIP的缺点:
- 1.不限制网络规模
- 2.会考虑链路的代价
- 3.保证不会产生路由环路
原因:
2和3都是因为采用了最短路径算法,会根据链路的代价(而不是单纯的距离)来计算最优路径。
1是,为了使OSPF能用于规模很大的网络,OSPF把一个自洽系统再划分为若干个更小的范围,叫区域;
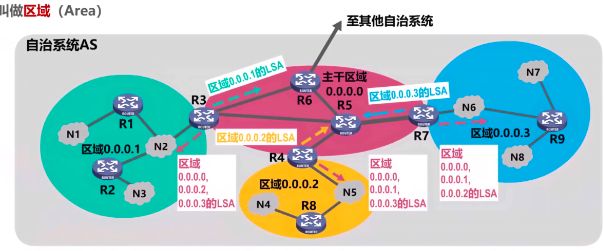
划分区域的好处就是把利用洪范法交换链路状态信息的范围局限于每一个区域,而不是整个自治系统,这样就减少了整个网络上的通信量——有利于扩大网络规模
洪泛法就是路由器把接收到的包往所有连接的路径上去转发。
OSPF具体特性如下:

思科路由器中,OSPF计算代价的方法是用100兆比特每秒除以链路带宽。不同网络自治系统对代价的度量不一样。

基于Dijkstra的最短路径算法在OSPF中的应用:
每个路由器有一个LSDB,即链路状态数据库(LS是Link state),上面存的是每个路由器的链路状态通告,这里面就有去相邻路由器的距离等信息,然后根据LSDB就能构建出一个以路由器为节点含权重的有向图,然后用Dijkstra算法进行最短路径优先计算。

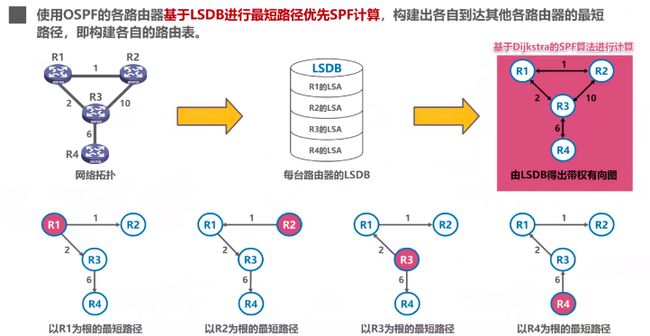
Dijkstra算法详解
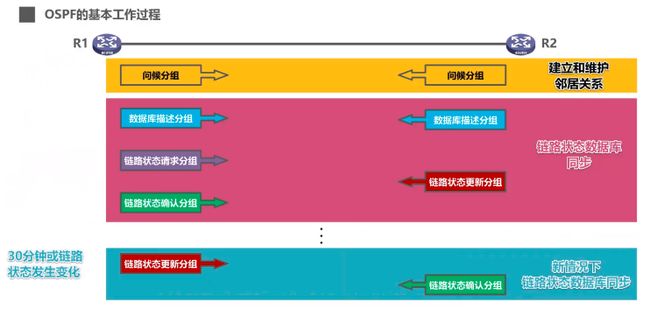
两个路由器之间需要发送分组来更新链路状态数据库(就像RIP互发路由表)
1.5 边界网关协议BGP
前两个协议RIP和OSPF都是内部网关协议,BGP是外部网关协议。
内部网关协议适用于自治系统内,外部网关协议适用于自治系统之间
由于不同自治系统对路由“代价"的度量是不同的(比如不同国家之间),由于没有统一的路由度量,因此在跨自治系统时,寻找最佳路由是无意义的
此外还需要考虑安全,比如不能经过有些国家和地区。
因此,边界网关协议BGP只能是力求寻找一条能够到达目的网络且比较好的路由,也就是不能兜圈子,而并非要寻找一条最佳路由。
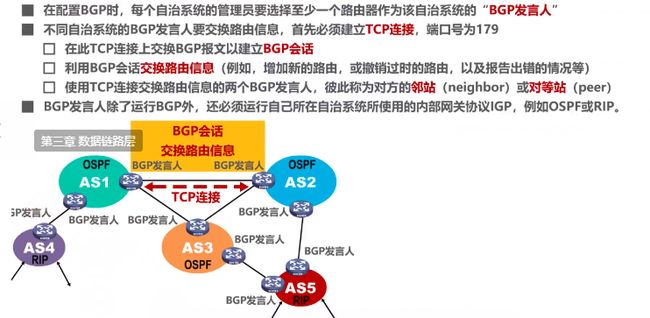
注意,不同自治系统之间的BGP发言人需要先建立TCP连接,才能交换路由信息。
而TCP相比下层的IP层协议,它是面向连接的,可靠的。
二、IPv4数据报的首部格式
每1行是32比特,即4字节,固定部分5行,所以固定部分占用20字节。
IP数据报的首部长度为20 ~ 60字节,是4字节的整数倍。(TCP报文首部是固定为20字节的,而IP报文首部长度不是固定的)
下面介绍各个字段的含义:
版本: 表明是IPv4还是IPv6,可变部分的可选字段很少被使用,填充部分存在是当可选字段用上时,可选字段长度为1~40字节不等,需要填充部分将其填为4字节的整数倍。如下所述:
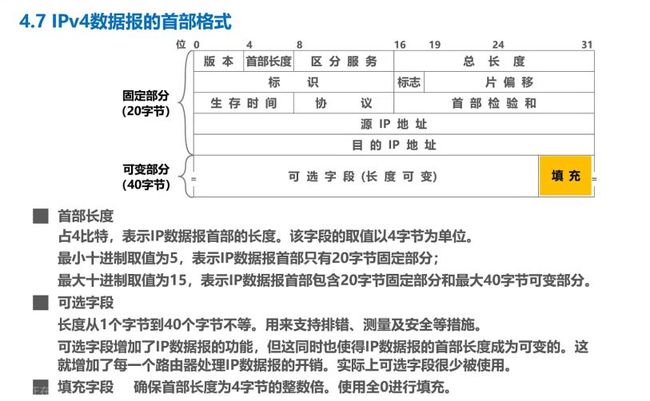
区分服务:只有在使用区分服务时,该字段才起作用,一般情况下都不使用该字段
总长度:该字段占16比特,用来表示IP数据报的总长度(首部 + 数据载荷),最大取值为十进制的65535字节,需要注意的是在实际应用中很少传输这么长的IP数据报

每一种数据链路层协议都会规定每一帧最大的数据载荷MTU,以太网的为1500字节,所以当IP数据报超过这个时,就会被==分片==。(注意不是只有超过1500字节会被分片)
标识IP数据报分片的三个字段:标识 、标志 、片偏移

举例说明IP数据报的分片过程:
每个分片都要加上原来的首部,20字节! 但里面的字段不一定一样,比如片偏移。

假如分片2经过某个网络又需要继续分片:

生存时间TTL:
该字段占8个比特,最初以秒为单位,最大生存周期为255秒,路由器转发IP数据报时,将IP数据报首部中的该字段的值,减去IP数据报在本路由器上所耗费的时间,若不为零就要转发,否则就丢弃。
现在TTL 以跳数为单位 ,路由器转发IP数据报时,将IP数据报首部中的该字段的值减一,若不为0就转发,为0就要丢弃,还会给源点发送ICMP报文,告知时间超过了。
作用:出现路由环路时,IP数据报不会在路由器环路中永久兜圈!
协议:
占8个比特,用来指明IP数据报的数据部分是何种协议数据单元
协议字段不同值对应不同协议,常用的如下:
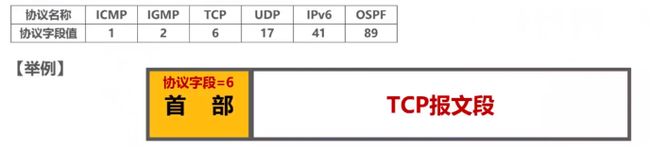
如上,如果IP数据报首部的协议字段的值为6,说明IP数据报的数据部分搭载的是TCP报文
首部校验和:——IPv6不计算
该字段占16比特,用来检测IP数据报首部,在传输过程中是否出现差错,所采用的检错码比循环冗余检错码简单,称为因特网检验和。
IP数据报每经过一个路由器,路由器都要重新计算首部检验和。因为某些字段,例如生存时间,标志,片偏移等的取值可能会发生变化。由于IP层本身并不提供可靠传输的服务,并且计算首部检验和是一项耗时的操作,因此在IPV6中,路由器不再计算首部检验和,从而更快转发IP数据报
源地址和目的地址:
各占32比特,填写发送该IP数据报的源主机的IP地址和接收该数据报的目的主机的IP地址
路由器读取目的IP知道下一跳是哪。
最后,路由器对IP报文首部的修改:
IP分组经过路由器R时生存时间字段的值被减1,首部检验和会被重新计算,若IP分组总长度大于最大传送单元MTU的值,则需要进行分片。此时总长度字段、标志字段、片偏移字段都需要修改。