第二次线上面试总结(2022.9.14)
文章目录
- 2022年9月14号 第二次线上面试(一面)
-
- 面试题总结
-
- 1.MySQL的int类型占多少个字节?
- 2.Java里的int类型最大能存的数字是多少?
- 3.Http请求是无状态的?
- 4.简单描述一下什么是三次握手?
- 5.MySQL索引结构是怎么样的?
- 6.B+树与B树有什么区别和优势吗?
- 7.MySQL怎么实现主从复制?
- 8.简单描述一下动态规划的思路和原理
- 9.通俗的讲一下什么是IOC依赖注入?
- 10.MySQL的String类型占多少个字节?
2022年9月14号 第二次线上面试(一面)
面试题总结
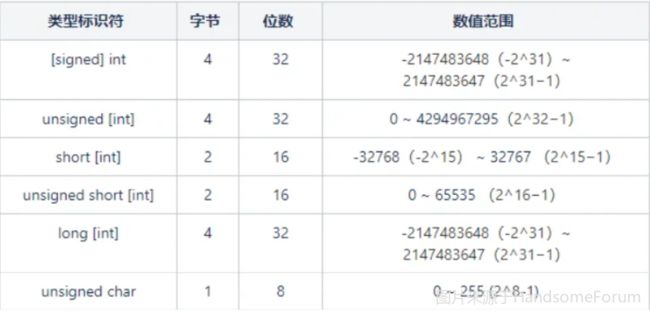
1.MySQL的int类型占多少个字节?
MySQL中,int类型在存储时需要4 个字节。int代表标准整数,可表示普通大小的整数;int类型可以是有符号或无符号的,无符号范围是“0 ~ 4294967295”,有符号范围是“-2147483648~2147483647”。因为整数类型表示确切数字,所以通常将int列用作表的主键,且设置AUTO_INCREMENT属性,每增加一条记录,int列数据会自动以相同步长进行增长。
2.Java里的int类型最大能存的数字是多少?
为什么 int 型数据类型的取值范围不对称呢?
为什么最大值是 2^31 - 1呢?
为什么最小值是 -2^ 31,而不是 -2^31 + 1呢?
我们知道,计算机能够认识的只有二进制(也就是 0 和 1),而我们所认识的字符和数字都要转换成二进制才能让计算机识别并执行。
这里以java的int型为例说明,
我们首先要明白的是,
java的 int 型是32位的,
因为一个 int 值占 4 个字节 byte ,一个字节是 8 位 bit(即8个二进制位),所以 int型 占 32 位,
其中第32位,也就是最高位是符号位,正数为 0,负数为 1,
剩下的31位是用来表示数字部分。
正数在计算机中表示为 原码,
比如:
1 的原码是 :0000 0000 0000 0000 0000 0000 0000 0001
1 的补码是:0000 0000 0000 0000 0000 0000 0000 0001
1 的反码是:0000 0000 0000 0000 0000 0000 0000 0001
没错,正数的 原码 、补码 、 反码 都相同,
那么最大是多少呢?
当然是除了符号位,其他位置上都为 1 的时候,
0111 1111 1111 1111 1111 1111 1111 1111
这个数就是 2147483647,它是 32 位中所能表示的最大正数。
负数在计算机中表示为 补码,
比如:
-1 的原码是:1000 0000 0000 0000 0000 0000 0000 0001
-1 的反码是:1111 1111 1111 1111 1111 1111 1111 1110
-1 的补码是:1111 1111 1111 1111 1111 1111 1111 1111
很明显,负数的 原码 、补码 、 反码 并不相同,而且,
负数的原码 是在 正数的原码 上 将符号位取反 取反,
负数的反码 是在 负数的原码 上 除符号位后 取反,
负数的补码 是在 负数的反码 上 加一。
负数的补码 也可以说是在 负数的原码 上 取反加一。
所以我们再来看看 -2147483647 的表示,
-2147483647 的原码是:1111 1111 1111 1111 1111 1111 1111 1111
-2147483647 的反码是:1000 0000 0000 0000 0000 0000 0000 0000
-2147483647 的补码是:1000 0000 0000 0000 0000 0000 0000 0001
那它是最小值吗?
不是,还有一个很奇怪的东西。
0 在计算机中的表示
在二进制中,0 有两种表示方法,
+0 的原码:0000 0000 0000 0000 0000 0000 0000 0000
-0 的原码:1000 0000 0000 0000 0000 0000 0000 0000
因为 0 只需要一个,所以就把 -0 当成了最小的数 -2147483648
可以这么理解,正因为 0 有两种表示方式,所以会多了一个负数出来,
-2147483648 的补码就是:1000 0000 0000 0000 0000 0000 0000 0000,它在 32位里面是没有原码的。
但需要注意的是,这个补码并不是真正的补码,
真正的补码应该是 1100 0000 0000 0000 0000 0000 0000 0000,但在 java 中溢出了,
所以,就是1000 0000 0000 0000 0000 0000 0000 0000
8位的范围则是[-128, 127]
3.Http请求是无状态的?
无状态含义:
无状态是指协议对于事务处理没有记忆功能。缺少状态意味着,假如后面的处理需要前面的信息,则前面的信息必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要前面信息时,应答就较快。直观地说,就是每个请求都是独立的,与前面的请求和后面的请求都是没有直接联系的。
实际中的使用情况:
在web应用中,我们使用http协议,但是我们需要的web是有状态的,因此加入了cookie、session等机制实现有状态的的web。
web=http协议+状态机制+其他机制
为什么不改进http协议使之有状态:
最初的http协议只是用来浏览静态文件的,无状态协议已经足够,这样实现的负担也很轻(相对来说,实现有状态的代价是很高的,要维护状态,根据状态来操作。)。随着web的发展,它需要变得有状态,但是不是就要修改http协议使之有状态呢?是不需要的。因为我们经常长时间逗留在某一个网页,然后才进入到另一个网页,如果在这两个页面之间维持状态,代价是很高的。其次,历史让http无状态,但是现在对http提出了新的要求,按照软件领域的通常做法是,保留历史经验,在http协议上再加上一层实现我们的目的(“再加上一层,你可以做任何事”)。所以引入了其他机制来实现这种有状态的连接。
哪些方法可以实现有状态连接:
Cookies,Session,Token,JWT
4.简单描述一下什么是三次握手?
三次握手的具体点的描述如下:
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。完成三次握手,客户端与服务器开始传送数据;
5.MySQL索引结构是怎么样的?
索引结构类型有:二叉树,红黑树(平衡二叉树),哈希,B树,B+树,MySQL最终选择的索引结构为B+树
二叉树:左小右大,极端情况下,数据递增插入,会一直向右插入,形成链表,查询效率低
平衡二叉树:任何节点的两个子树,高度就差1
哈希:不能进行范围查询
B树:
1.每个节点放1页数据,一页为16KB
2.每个键值下,存放该键值所在记录的所有数据
3.叶子节点与叶子节点没有指针相互指向,不利于范围查询
4.相对于二叉树,索引深度减少了
B+树:
1.每个节点放1页数据,一页为16KB
2.数据都存在叶子节点,增加了中间节点的存储量
3.叶子节点与叶子节点有指针相互指向
6.B+树与B树有什么区别和优势吗?
1.数据都存储在叶子节点,这样中间节点存放的索引值就越多,在数据量比较大的情况下,降低了树的深度
2.由于数据只存在叶子节点,每次查询的路径深度相同,提高了查询稳定性
3.叶子节点有两个指针,分别指向相邻的节点,便于范围查询
7.MySQL怎么实现主从复制?
MySQL主从复制介绍:
1.MySQL数据库默认是支持主从复制的,不需要借助于其他的技术,我们只需要在数据库中简单的配置即可。
2.MySQL主从复制是一个异步的复制过程,底层是基于Mysql数据库自带的 二进制日志 功能。就是一台或多台MySQL数据库 从另一台MySQL数据库进行日志的复制,然后再解析日志并应用到自身,最终实现 从库 的数据和 主库 的数据保持一致。MySQL主从复制是MySQL数据库自带功能,无需借助第三方工具。
3.二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但是不包括数据查询语句。此日志对于灾难时的数据恢复起着极其重要的作用,MySQL的主从复制, 就是通过该binlog实现的。默认MySQL是未开启该日志的。
4.简单来说就是一台服务器中的MySQL数据库根据另一台服务器中的MySQL数据库的日志文件进行分析然后执行sql语句进行数据复制。
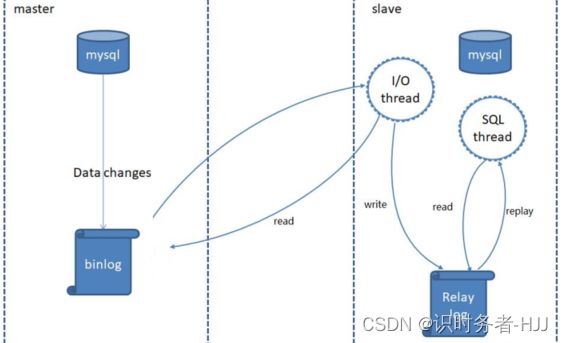
MySQL复制过程分成三步:
1.MySQL master 将数据变更写入二进制日志( binary log)
2.slave将master的binary log拷贝到它的中继日志(relay log)
3.slave重做中继日志中的事件,将数据变更反映它自己的数据
8.简单描述一下动态规划的思路和原理
动态规划遵循一套固定的流程:递归的暴力解法 -> 带备忘录的递归解法 -> 非递归的动态规划解法
适用范围:
每种方法都有自身的局限性,动态规划法也不是万能的。动态规划适合求解多阶段(状态转换)决策问题的最优解,也可用于含有线性或非线性递推关系的最优解问题,但是这些问题都必须满足最优化原理和子问题的“无后向性”。
基本思想:
和分治法一样,动态规划解决复杂问题的思路也是对问题进行分解,通过求解小规模的子问题再反推出原问题的结果。但是动态规划分解子问题不是简单地按照“大事化小”的方式进行的,而是沿着决策的阶段划分子问题,决策的阶段可以随时间划分,也可以随着问题的演化状态划分。分治法要求子问题是互相独立的,以便分别求解并最终合并出原始问题的解,但是动态规划法的子问题不是互相独立的,子问题之间通常有包含关系,甚至两个子问题可以包含相同的子子问题。比如,子问题A的解可能由子问题C的解递推得到,同时,子问题B的解也可能由子问题C的解递推得到。对于这种情况,动态规划法对子问题C只求解一次,然后将其结果保存在一张表中(此表也称为备忘录),避免每次遇到这种情况都重复计算子问题C的解。除此之外,动态规划法的子问题还要满足“无后向性”要求。动态规划法不像贪婪法或分治法那样有固定的算法实现模式,作为解决多阶段决策最优化问题的一种思想,它没有具体的实现模式,可以用带备忘录的递归方法实现,也可以根据堆叠子问题之间的递推公式用递推的方法实现。但是从算法设计的角度分析,使用动态规划法一般需要四个步骤,分别是定义最优子问题、定义状态、定义决策和状态转换方程以及确定边界条件,这四个问题解决了,算法也就确定了。
通用步骤:
1.定义最优子问题
2.定义状态
3.定义决策和状态转换方程
4.确定边界条件
9.通俗的讲一下什么是IOC依赖注入?
IOC:控制反转,把创建对象过程交给Spring进行管理。
IOC全称Inversion of Control,被译为控制反转,是一个重要的面向对象编程的法则,可以用来削减计算机程序的耦合问题,也是轻量级的Spring框架的核心,在Java开发中,IOC意味着将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制。
AOP:面向切面编程,不修改源代码的情况下进行功能增强。
10.MySQL的String类型占多少个字节?
varchar(M):
用于存储可变长度的字符串。 字符串占用空间随字符串实际长度占用空间变化。 实际长度 <= 设置长度M。 M范围:1~255。 需要1到2个字节来保存一个字符。
char(M):
用于存储定长的字符串。 字符串占用空间不随字符串实际长度占用空间变化。 实际长度 = 设置长度M。 M范围:1~255。 适用于较短的常改变的字符串以及较短的长度固定不变的字符串。
tinytext:
用于储存较短字符串类型。 最大长度255个字节。
text:
用于储存一般字符串类型。 最大长度65535个字节。
mediumtext:
用于储存较长字符串类型。 最大长度16777215个字节。
longtext:
用于储存较长字符串类型。 最大长度4294967295个字节。
binary:
用于保存固定长度的二进制字符串。 保存的是字节而不是字符,没有字符集限制。(普通开发过程使用率不高)
varbinary:
用于保存可变长度的二进制字符串。 保存的十字街而不是字符,没有字符集限制。(普通开发过程使用率不高)
tinyblob:
用于存储较小的二进制数据。 最大长度255个字节。
blob:
用于存储一般的二进制数据。 最大长度65535个字节。
mediumblob:
用于存储较大的二进制数据。 最大长度16777215个字节。
longblob:
用于存储较大的二进制数据。 最大长度4294967295个字节。
enum和set:
枚举类型和集合类型
当String为常量时,String常量会放入字符串常量池,字符串常量池对字符串的长度做了限制,最大值为216-1=65535
当String为变量时,则长度限制为2^31-1= 2147483647个字符