Pytorch实现图像风格迁移(一)
图像风格迁移是图像纹理迁移研究的进一步拓展,可以理解为针对一张风格图像和一张内容图像,通过将风格图像的风格添加到内容图像上,从而对内容图像进行进一步创作,获得具有不同风格的目标图像。基于深度学习网络的图像风格迁移主要有三种类型,分别为固定风格固定内容的风格迁移、固定风格任意内容的快速风格迁移和任意风格任意内容的极速风格迁移。
图像风格迁移主要任务是将图像的风格迁移到内容图像上,使得内容图像也具有一定的风格。其中风格图像通常可以是艺术家的一些作品,如画家梵高的《向日葵》《星月夜》,日本浮世绘的《神奈川冲浪里》等经典的画作,这些图像通常包含一些经典的艺术家风格。风格图像也可以是经典的具有特色的照片,如夕阳下的照片、城市的夜景等,图像具有鲜明色彩图像。而内容图像则通常来自现实世界,可以是自拍照、户外摄影等。利用图像风格迁移则可以将内容图像处理为想要的风格。
1.固定风格固定内容的普通风格迁移
固定风格固定内容的风格迁移方法,也可以称为普通图像风格迁移方法,也是最早的基于深度卷积神经网络的图像风格迁移方法。针对每张固定内容图像和风格图像,普通图像风格迁移方法都需要重新经过长时间的训练,这是最慢的方法,也是最经典的方法。固定风格固定内容的风格迁移方法思路很简单,就是把图片当作可以训练的变量,通过不断优化图片的像素值,降低其与内容图片的内容差异,并降低其与风格图片的风格差异,通过对卷积网络的多次迭代训练,能够生成一幅具有特定风格的图像,并且内容与内容图片的内容一致,生成图片风格与风格图片的风格一致。
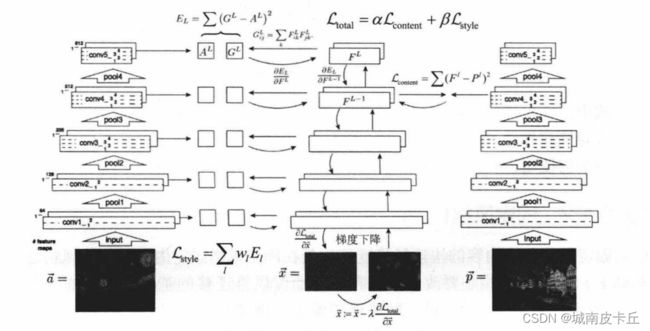
上图是论文《Image Style Transfer Using Convolutional Neural Networks》中,提到的基于VGG16网络中卷积层的图像风格迁移流程。在图中左边的图像 ![]() 为输入的风格图像,右边的图像
为输入的风格图像,右边的图像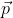 为输入的内容图像。中间的图像
为输入的内容图像。中间的图像 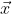 则是表示由随机噪声生成的图像风格迁移后的图像。
则是表示由随机噪声生成的图像风格迁移后的图像。![]() 表示图像的内容损失,
表示图像的内容损失,![]() 表示图像的风格损失,
表示图像的风格损失, 和
和  分别表示内容损失权重和风格损失权重。
分别表示内容损失权重和风格损失权重。
针对深度卷积神经网络的研究发现,使用较深层次的卷积计算得到的特征映射能够较好地表示图像的内容,而较浅层次的卷积计算得到的特征映射能够较好地表示图像的风格。基于这样的思想就可以通过不同卷积层的特征映射来度量目标图像在风格上和风格图像的差异,以及在内容上和内容图像的差异。
两个图像的内容相似性度量主要是通过度量两张图像在通过VGG16的卷积计算后,在conv4_2层上特征映射的相似性,作为图像的内容损失,内容损失函数如下所示:
![]()
式中,l 表示特征映射的层数; F 和 P 分别是目标图像和内容图像在对应卷积层输出的特征映射。
图像风格的损失并不是直接通过特征映射进行比较的,而是通过计算Gram矩阵先计算出图像的风格,再进行比较图像的风格损失。计算特征映射的Gram矩阵则是先将其特征映射变换为一个列向量,而Gram矩阵则使用这个列向量乘以其转置获得,Gram矩阵可以更好地表示图像的风格。所以输入风格图像 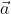 和目标图像 ,使用
和目标图像 ,使用 ![]() 和
和 ![]() 分别表示它们在 l 层特征映射的风格表示(计算得到的Gram矩阵),那么图像的风格损失可以通过下面的方式进行计算:
分别表示它们在 l 层特征映射的风格表示(计算得到的Gram矩阵),那么图像的风格损失可以通过下面的方式进行计算:
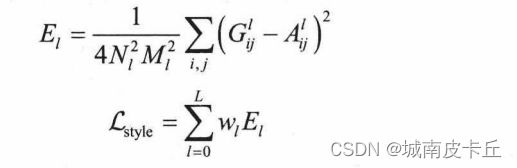
式中,![]() 是每个层的风格损失的权重;
是每个层的风格损失的权重;  和
和 ![]() 对应着特征映射的高和宽。针对固定图像固定风格的图像风格迁移,使用PyTorch很容易实现。后续小节将介绍如何使用PyTorch进行固定图像固定风格的图像风格迁移。
对应着特征映射的高和宽。针对固定图像固定风格的图像风格迁移,使用PyTorch很容易实现。后续小节将介绍如何使用PyTorch进行固定图像固定风格的图像风格迁移。
2.固定风格任意内容的快速风格迁移
固定风格任意内容的快速风格迁移,是在固定风格固定内容的图像风格迁移的基础上,做出的一些必要改进,即在普通图像风格迁移的基础上,添加一个可供训练的图像转换网络。针对一种风格图像进行训练后,可以将任意输入图像非常迅速地进行图像迁移学习,让该图像具有学习好的图像风格。其深度网络的框架如下:
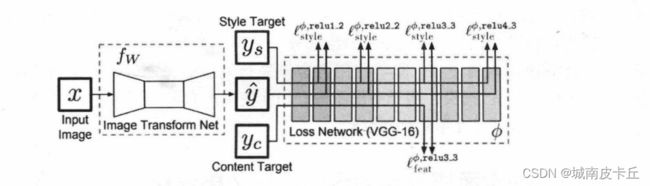
上图来自论文《Perceptual Losses for Real-Time Style Transfer and Super-Resolution》图示可以看作两个部分,一部分是通过输入图像 x 经过图像转换网络 ![]() ,得到网络的输出
,得到网络的输出  ,这部分是普通风格迁移图像框架中没有的部分,普通图像风格迁移的输入图像是随机噪声,而快速风格迁移的输入是一张图像经过转换网络
,这部分是普通风格迁移图像框架中没有的部分,普通图像风格迁移的输入图像是随机噪声,而快速风格迁移的输入是一张图像经过转换网络 ![]() 的输出;另一部分是使用VGG16网络中的相关卷积层去度量一张图像的内容损失和风格损失。
的输出;另一部分是使用VGG16网络中的相关卷积层去度量一张图像的内容损失和风格损失。
在图像转换网络( Image Transform Net)部分,可以分为3个阶段,分别是图像降维部分、残差连接部分和图像升维部分。
(1)图像降维部分:主要通过3个卷积层来完成,将图像的尺寸从256×256逐渐缩小到原来的1/4,即64×64,并且将通道数逐渐从3个增加到128个特征映射。
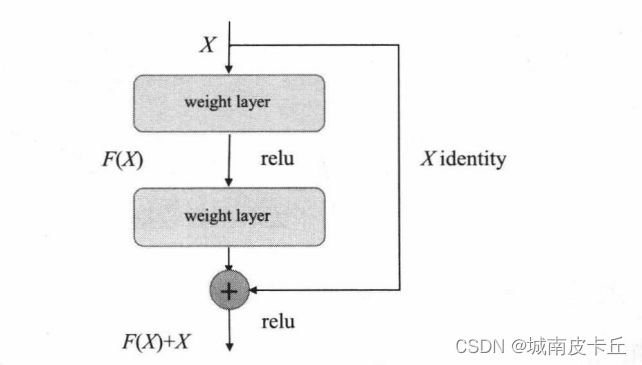
(2)残差连接部分:该部分是通过连接5个残差块,对图像进行学习,该结构用于学习如何在原图上添加少量内容,改变原图的风格。其中每个残差连接的结构如图所示:
(3)图像升维部分:该部分主要输出5个残差单元,通过3个卷积层的操作,逐渐将其通道数从128缩小到3,每个特征映射的尺寸从64×64放大到256 ×256,也可以使用转置卷积来完成网络的升维部分。
1.准备VGG19网络
从torchvision的models模块中导入预训练好的VGG19网络,预训练好的网络是在ImageNet数据集上进行训练的,所以使用时会非常方便。因为VGG19网络的作用是计算对应图像在网络中一些层输出的特征映射,在计算过程中,不需要更新VGG19的参数权重,所以导入VGG19网络后,需要将其中的权重冻结,程序如下所示:
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import torch
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
import requests
from torchvision import models
from torchvision import transforms
import time
import hiddenlayer as hl
from skimage.io import imread
vgg19=models.vgg19(pretrained=True)
vgg=vgg19.features
for param in vgg.parameters():
param.requires_grad_(False)在上面的程序中,使用models.vgg19(pretrained=True)读取已经预训练的VGG19网络,参数pretrained=True表示读取的网络是已经预训练过的。预训练过的网络可以直接进行相关的应用。因不需要网络中的分类器相关的层,所以使用vgg19.features即可获取网络中由卷积和池化组成的特征提取层。在冻结网络的权重时,通过一个循环来遍历网络中所有可以训练的权重,然后通过requires_grad_(False)方法,设置权重在接下来的计算中不更新梯度,即权重不更新。
准备好VGG19网络之后,还需要对输入的图像进行相关的处理,因为网络可以接受任意尺寸的输入图像(图像的尺寸不宜过小,预防深层的卷积操作后没有特征映射输出,或特征映射尺寸太小),但是图像的尺寸越大,在进行风格迁移时,需要进行的计算量就会越多,速度就会越慢,所以需要保持图像有合适的尺寸。虽然图像风格迁移时可以使用任意尺寸的图像,而且输入的风格图像的尺寸和内容图像的尺寸大小也可以不相同(在实际应用中为了方便,通常会将风格图像的尺寸和内容图像的尺寸设置为相同),但目标图像尺寸和内容图像的尺寸需要相同,这样才能计算和比较内容损失的大小。下面定义load_image()函数用于读取图像,在读取图像的同时,控制图像的尺寸大小,程序如下所示:
def load_image(img_path,max_size=400,shape=None):
image=Image.open(img_path).convert('RGB')
#如果图片尺寸过大,就对图像进行尺寸变换
if max(image.size) > max_size:
size=max_size
else:
size=max(image.size)
#如果指定了图像的尺寸,就像图像转化为shape指定的尺寸
if shape is not None:
size=shape
#使用transform将图像转化为张量,并进行标准化
in_transform=transforms.Compose([
transforms.Resize(size),#图像尺寸变换,图像的短边匹配size
transforms.ToTensor(),#数组转化为张量
#图像进行标准化
transforms.Normalize((0.485,0.456,0.406),(0.229,0.224,0.225))
])
image=in_transform(image)[:3,:,:].unsqueeze(dim=0)
return image
load_image()函数有三个参数,第一个参数是输入需要读取图像的路径img_path,第二个参数和第三个参数用于控制图像的大小。如果指定了max_size参数,在读取图像时,若图像的尺寸过大,图像会进行相应的缩小,如果指定了图像的尺寸( shape参数),则将图像转化为shape指定的大小。读取图像后,为了方便通过卷积网络计算相关的特征输出,使用transforms的相关转换操作,对图像进行预处理,最后将输出一个可以使用的四维张量image。上述读取后的图像并不能通过matplotlib库直接进行可视化,需要定义一个im_convert()函数,该函数可以将一张图像的四维张量转化为一个可以使用matplotlib库可视化的三维数组,程序如下所示:
def im_convert(tensor):
"""
将[1,c,h,w]维度的张量转化为[h,w,c]的数组
因为张量进行了标准化,所以要进行标准化逆变换
:param tensor:
:return:
"""
image=tensor.data.numpy().squeeze()#去除batch维度数据
image=image.transpose(1,2,0)#置换数组的维度[c,h,w]->[h,w,c]
#进行标准化的逆操作
image=image * np.array((0.229,0.224,0.225))+ np.array((0.485,0.456,0.406))
image=image.clip(0,1)#将图像的取值剪切到0-1
return image
下面的程序将读取需要使用的风格图像和内容图像,并将它们可视化。
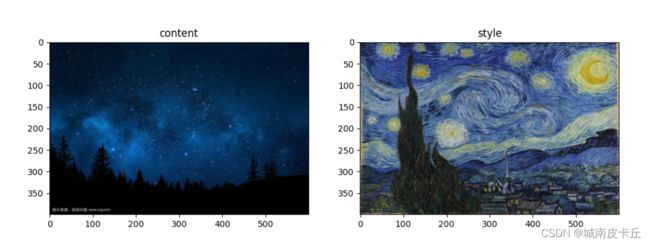
content=load_image(r"C:\Users\zex\Desktop\sky.jpg",max_size=400)
print("content shape:",content.shape)
#根据内容图像的宽高来设置风格图像的宽高
style=load_image(r"C:\Users\zex\Desktop\fangao.png",shape=content.shape[-2:])
print("style shape:",style.shape)
#可视化图像,可视化内容图像和风格图像
fig,(ax1,ax2)=plt.subplots(1,2,figsize=(12,5))
ax1.imshow(im_convert(content))
ax1.set_title("content")
ax2.imshow(im_convert(style))
ax2.set_title("style")
plt.show()
运行上述程序得到如下所示的输出和如下图所示的图像。为了保证两张图像具有相同的大小,在程序中通过内容图像的尺寸来定义风格图像的尺寸。
2.图像的输出特征和Gram矩阵的计算
为了更方便获取图像在VGG19网络指定层上的特征映射输出,定义一个get_features()函数,程序如下所示:
def get_features(image,model,layer=None):
"""
将一张图像image在一个网络model中进行前向传播计算,并获取指定层layer中特征映射输出
:param image:
:param model:
:param layer:
:return:
"""
#将PyTorch的VGGNet的完整映射层名称与论文中的名称相对应
#layers参数指定:需要用于图像的内容和样式表示的图层
##如果layers没有指定、就使用默认的层
if layer is None:
layers={
'0':'conv1_1',
'5':'conv2_1',
'10':'conv3_1',
'19':'conv4_1',
'21':'conv4_2',
'28':'conv5_1'
}
features={}#获取的每层特征保存到字典中
x=image#需要获取的特征图像
#model._modules是一个字典,保存着网络model每层信息
for name,layer in model._modules.items():
#从第一层开始获取图像的特征
x=layer(x)
#如果是layers参数指定的特征,那就保存到features中
if name in layers:
features[layers[name]]=x
return features
get_features()函数通过输人参数图像(image),使用网络(model)和指定的层参数( layers),输出图像在指定网络层上的特征映射,并将输出的结果保存在一个字典中,如指定VGG19网络,但不指定layers参数,默认情况下会输出VGG19网络的conv1_1、conv2_1、conv3_1、conv4_1、conv4_2、conv5_1层的特征映射。比较两个图像是否具有相同的风格时,可以使用Gram矩阵来评价。我们定义函数gram_matrix()对一张图像的特征映射输出计算Gram矩阵。
def gram_matrix(tensor):
"""
计算指定向量的Gram matrix,该矩阵表示图像的风格特征
格拉姆矩阵最终能够在保证内容的情况下,进行风格传输
tensor:是一张图像前向计算后的一层特征映射
:param tensor:
:return:
"""
#获得tensor的batch_size,depth,height,width
_,d,w,h=tensor.size()
#改变矩阵的维度为(深度,高*宽)
tensor=tensor.view(d,h*w)
#计算gram matrix
gram=torch.mm(tensor,tensor.t())
return gram
在上面定义的gram_matrix()函数是计算一张图像Gram矩阵,针对输入的四维特征映射,将其每一个特征映射设置为一个向量,得到一个行为d(特征映射数量),列为h* w(每个特征映射的像素数量)的矩阵,该矩阵乘以其转置即可得到需要的Gram矩阵。
在定义好两个辅助函数后,下面针对内容图像和风格图像计算特征输出,并且计算风格图像在每个特征输出上的Gram矩阵,程序如下所示:
#计算在第一次训练之前内容特征和风格特征,使用get_features函数
content_features=get_features(content,vgg)
#计算风格图像的风格表示
style_features=get_features(style,vgg)
#为风格图像的风格表示计算每层的格拉姆矩阵,使用字典保存
style_grams={layer: gram_matrix(style_features[layer]) for layer in style_features}
#使用内容图像的副本创建一个目标图像,训练时对目标图像进行调整
target=content.clone().requires_grad_(True)
3.进行图像风格迁移
在相关准备工作做好之后,下面就可以使用相关图像和网络进行图像风格迁移的学习,为了训练效果,在计算风格时,针对不同层的风格特征映射Gram矩阵,定义不同大小的权重,此处使用style_weights字典法完成,并且针对最终的损失,内容损失权重α和风格损失权重β分别定义为1和1× ,程序如下所示:
,程序如下所示:
style_weights={'conv1_1':1.,
'conv2_1':0.75,
'conv3_1':0.2,
'conv4_1':0.2,
'conv5_2':0.2}
alpha=1
beta=1e6
content_weight=alpha
style_weight=beta需要注意的是,在style_weights中没有定义conv4_2层的Gram权重,这是因为该层的特征映射用于度量图像内容的相似性。
定义好权重参数后,下面使用Adam优化器进行训练,其中学习率为0.0003,并且为了监督网络在训练过程中的结果,每间隔1000次迭代输出目标图像的可视化情况,用于观察,并将迭代过程中每次相关损失值保存在列表中。用于优化目标图像的程序如下所示:
show_every=1000#每迭代1000次输出一个中间结果
#将损失保存
total_loss_all=[]
content_loss_all=[]
style_loss_all=[]
#使用Adam优化器
optimizer=optim.Adam([target],lr=0.0003)
steps=5000#优化时迭代的次数
t0=time.time()#记录需要的时间
for i in range(steps):
#获取目标图像的特征
target_features=get_features(target,vgg)
#计算内容损失
content_loss=torch.mean((target_features["conv4_2"] - content_features["conv4_2"])**2)
#计算风格损失,并且初始化为0
style_loss=0
#将每层的gram_matrix损失相加
for layer in style_weights:
#计算要生成的图像风格表示
target_feature = target_features[layer]
target_gram=gram_matrix(target_feature)
_,d,h,w=target_feature.shape
#获取风格图像在每层的风格的gram_matrix
style_gram=style_grams[layer]
#计算要生成图像的风格和风格图像的风格之间的差距,每层都有一个权重
layer_style_loss=style_weights[layer] * torch.mean((target_gram-style_gram)**2)
#累加计算风格差异损失
style_loss +=layer_style_loss/(d*h*w)
#计算一次迭代的总的损失,即内容损失和风格损失的加权和
total_loss=content_weight * content_loss + style_weight * style_loss
#保留三种损失大小
content_loss_all.append(content_loss.item())
style_loss_all.append(style_loss.item())
total_loss_all.append(total_loss.item())
#更新需要生成的目标图像
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
#输出每show_every次迭代后的生成图像
if i % show_every==0:
print('Total loss:',total_loss.item())
print('Use time:',(time.time()-t0)/3600,'hour')
newIm=im_convert(target)
plt.imshow(newIm)
plt.title("Iteration:"+str(i)+'times')
plt.show()
result=Image.fromarray((newIm * 255).astype(np.uint8))
result.save('C:\\Users\\zex\\Desktop\\' +str(i)+'.bmp')在上面的程序中还需要注意以下几点:
(1)优化器的使用方式为optim.Adam([target], lr=0.0003),表明在优化器中,最终要优化的参数是目标图像的像素值,不会优化VGG网络中的权重等参数。
(2)获取目标图像在相关层的特征输出时使用get_features(target, vgg)函数,并且因为内容图像的特征映射在conv4_2层,所以内容损失计算时,需提取指定层的输出,即使用target_features['conv4_2']获得目标图像的内容表示,以及使用content__features['conv4_2']获得内容图像的内容表示。
(3)由于图像的风格表示的损失是通过多个层来表示,所以需要通过for循环来逐层计算相关的Gram矩阵和风格损失。
(4)最终的损失是风格损失和内容损失的加权和。
(5)为了观察和保留图像风格在迁移过程中的结果,将图像每间隔1000次迭代计算后的结果进行可视化并保存到指定的文件中。
由于以上程序训练时间十分漫长,这也是普通图像风格迁移方法的最大缺点,因此最终结果这里就不展示了。下一节课介绍快速图像风格迁移方法。