【c++】——海量数据处理各种面试题(位图的实现和应用,布隆过滤器的应用,哈希切分)
目录
一. 位图
1.1 位图的概念
1.2 位图的使用场景
题目一
题目二
题目三
题目四
二. 布隆过滤器
2.1 布隆过滤器的概念
2.2 布隆过滤器优点
2.3 布隆过滤器缺点
2.4 布隆过滤器使用场景
问题五
问题六
问题七
一. 位图
1.1 位图的概念
位图是内存中连续二进制bit,然后对海量整数的去重和查询。 在位图中,位图的下标是整数,所以整数映射到位图是位图的下标,位图存储的内容是0和1,0代表这个下标这个数是不存在的,1代表下标这个整数是存在的。我举个例子,给定长度为8bit大小的位图,将3,5,7这几个整数映射到该位图中,应该怎样做呢?
ps(蓝色代表的是0,橙色代表的是1)

将3映射到位图中,找到位图的3下标,然后将3位置的bit位设置为1.
 将5映射到位图中,找到位图的中5的下标,然后将5位置的bit位设置为1.
将5映射到位图中,找到位图的中5的下标,然后将5位置的bit位设置为1.

将7映射到位图中,找到位图中7的下标,然后将7位置的bit位设置为1.

位图的实现:
位图的映射
一个char是8个bit位,如果整数10要映射到位图中,就需要找到第二个char数据,然后在找到第二个char的第二个bit位,并将其改变为1即可。任何数 | 1都为1,| 0为原来的数。
namespace sjp
{
//定义一个非类型模板参数
template
class SetBit
{
private:
vector v;//一个char为8个bit位
public:
SetBit()
{
v.resize(N / 8 + 1);//开辟N个bit位
}
void Set(size_t x)//将x映射到位图中
{
//找相对应的位图下标
int index = x / 8 + 1;//x在位图中的第几个char中
int place = x % 8;//在这个数的第几个bit位
v[index] |=(1 << place);
}
//删除x在位图中的映射
void ReSet(size_t x)
{
//找相对应的位图下标
int index = x / 8 + 1;//x在位图中的第几个char中
int place = x % 8;//在这个数的第几个bit位
v[index] &=(~(1 << place));
}
//判断一个数据是否在位图中
bool Test(size_t x)
{
//找相对应的位图下标
int index = x / 8 + 1;//x在位图中的第几个char中
int place = x % 8;//在这个数的第几个bit位
return v[index] &(1 << place);
}
};
//} 1.2 位图的使用场景
题目一
磁盘中有40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。
思路一:将所有的数据都加载到内存中,然后对其遍历。时间复杂度为O(N)。
思路二:将所有的数据都加载到内存中,并存储在under_set中,然后通过映射关系找到它,时间复杂度为O(1).
然而这上面两种情况,在正常计算机是不可能实现的,因为计算机中的内存一般为4g或者8g,而
40亿个整数大概是16g,所以是不可能同时将40亿个无符号整数加载到内存中。

因此所以我们是不可能将40亿个无符号整数同时加载到内存。但我们可以在内存中定义一个位图,将磁盘上的无符号整数数都映射到位图中,然后通过位图去判断无符号整数是否存在,因为是无符号整数范围是0~4294967295,所以需要定义一个4294967295bit大小的位图来映射这40亿个整数。
4294967295在32位下的计算机大概为500mb。相比于16G来说,位图的大小会小很多。


程序运行起来后所占用的内存空间:

题目二
1. 给定100亿个整数,设计算法找到只出现一次的整数?
在这100亿个整数中,我们可以将这些整数出现的次数可以分成3类。
- 一次都没有出现的整数
- 只出现一次的整数
- 出现过两次及以上的整数
所以我们可以定义位图一和位图二对这三种情况进行标记,数的大小代表两个位图的下标。
- 如果一次都没有出现的整数,那么它在两个位图中的都表示为1.
- 如果只出现一次的整数,那么它在位图一标记为1,在位图二上标记为0.
- 如果出现过两次及以上的整数,那么在位图一上标记为0,在位图二上标记为1.
代码实现
class DoubleBM
{
private:
SetBit<-1> s1;
SetBit<-1> s2;
vector v;
public:
DoubleBM()
{
}
void SetDB(size_t x)//将所有的数都映射到位图上
{
if (!s1.Test(x) && !s2.Test(x))
{
s1.Set(x);
}
else if (s1.Test(x) && !s2.Test(x))
{
s1.ReSet(x);
s2.Set(x);
}
}
bool Test(size_t x)//判断一个整数是否只出现一次
{
if (s1.Test(x) && !s2.Test(x))
{
return true;
}
return false;
}
};
} 题目三
给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
方案一:
如果是32位整数,那么可以在内存中创建一个位图,大概是500mb,然后将第一文件中的所有数据映射位图中,如果存在则为1,不存在则为0,然后再将第二个文件中的所有数据与位图进行对比,如果对比到的位置是1,说明该数是两个整数的交集,然后将交集的数据放在第三个文件中。
方案二:哈希切分
将文件1中所有数据通过哈希函数分成1000个小文件,每个文件大约有1000万个整数,大约为40mb,小文件a0,a1,a2...a999,数据通过哈希函数得到的结果就是文件的下标,例如文件a1代表的是整数余数为1的文件,a999代表的是余数为999的文件。然后将文件2中所有数据也通过哈希函数分成1000个小文件,小文件b0,b1,b2...b999,数据通过哈希函数得到的结果就是文件的下标,文件b1代表的是整数余数为1的文件,b999代表的是余数为999的文件,因为两个文件都使用相同的哈希函数,所以两个文件中相同的整数会被分配到下标一致的小文件中,然后将a1和b1就交集,a2和b2求交集,ai和bi求交集。求交集的方法,可以在内存中创建一个under_set数据结构,通过映射的关系求出交集,将交集的数据放在一个新的文件中。
题目四
1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数?
方案一:位图
使用两个位图,分别是位图1和位图2,一个为位图大概为500mb,来记录所有整数出现的次数,在这100亿个数据当中,数据出现的可能次数有:
- 0次,两个位图都记录为0;
- 1次,位图1中记录1,位图2记录为0;
- 2次,位图1中记录为0,位图2记录为1;
- 3次及3次及三次以上,位图1和位图2都记录为1;
将文件中的所有值映射到位图后,然后再找出位图1和位图2中都不全为1就是不超过2次的整数。

方案二:哈希切分法
100亿个整数大小大约为40g,创建80个小文件,分别标记为a0,a1,a2...a79,然后对大文件中每个整数都%80,得出的结果就放到相对应的小文件中,如得81%80=1,则81放在a1中,所有相同的整数都会放在一个小文件中,然后将一个一个的小文件加载到内存中,统计每个小文件中不出现2次的整数,然后将这些统计出来的整数统一放在一个文件中。
二. 布隆过滤器
2.1 布隆过滤器的概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。这种方式不仅可以提升查询效率,也可以节省大量的空间。
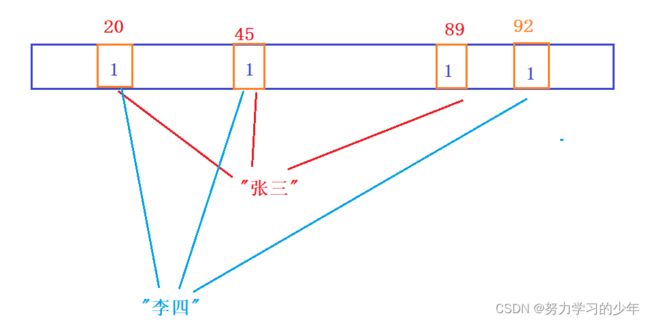
布隆过滤器主要是将字符串等其他数据映射到位图中,但是位图只能映射整数,所以我们需要通过哈希函数将字符串变量转换为整数映射到位图中(ps:哈希函数是将字符串类型转换为整数的函数),但不同的字符串利用哈希函数转换为整数有可能冲突的,导致不同字符串映射到位图中相同的位置上,为了减少这种冲突,我们可以利用不同的哈希函数将字符串转换为不同的整数,再将转换的整数都映射到位图中,最后一个字符串在位图中对应的多个整数。如下:假设“张三“这个字符串通过哈希函数1转换为20,通过哈希函数2转换为45,
通过哈希函数3转换为89,然后将这转换的3个整数都映射到位图中,当要判断”张三“这个字符串是否存在时,需要判断这3个整数是否都存在,如果其中一个整数不存在,则该字符串就不存在。

也就是说,在布隆过滤器中,每个字符串都会转换成多个不同的整数,目的是减少映射冲突。当然冲突的概率是一定会存在,这是不可避免的。如下:
例如:要判断"王五"是否存在,王五通过哈希函数转换成整数有:20,89,92,发现位图的对应的位置都已经被”张三"和"李四"给占用了,此时就会判断王五已经存在了。因此布隆过滤器判断某个字符串"存在",代表的是不一定真正的存在。但是如果布隆过滤器判断某个字符串不存在,那么它一定是不存在的,因为字符串转换的整数映射到位图中只要一个不存在,那么该字符串是一定不存在的。例如:假设”田七"通过哈希函数转换为整数位20,92,98,其中98中那个位置为0,则说明田七这个字符串一定不存在。
各种字符哈希函数的冲突率博客介绍:
各种字符串Hash函数 - clq - 博客园
其中BKDRHash,APHash,DJBHash冲突率是比较低,因此我们选择这三个哈希函数来实现我们的布隆过滤器。
布隆过滤器的实现:
下面使用三种哈希函数将字符串转换为整数的布隆过滤器。(可以使用多个哈希函数)
#include"Setbit.hpp"
struct BKDRHash
{
BKDRHash()//字符串哈希函数1
{
}
size_t operator()(const string& str)
{
size_t hash = 0;
for(auto ch:str)
{
hash = hash * 131 + ch; // 也可以乘以31、131、1313、13131、131313..
}
return hash;
}
};
struct APHash
{
APHash()//字符串哈希函数2
{}
size_t operator()(const string str)
{
register size_t hash = 0;
size_t ch;
for (long i = 0; i> 3));
}
else
{
hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
}
return hash;
}
};
struct DJBHash
{
DJBHash()//字符串哈希函数3
{
}
size_t operator()(const string& str)
{
size_t hash = 5381;
for (auto ch : str)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
template
class BloomFilter
{
private:
sjp:: SetBit _bitset;
public:
void Set(const K& s)//对字符串建立映射
{
//将字符串转换为3个整数
size_t i1 = Hash1()(s)%N;
size_t i2 = Hash2()(s)%N;
size_t i3 = Hash3()(s)%N;
//将3个整数映射到位图中
_bitset.Set(i1);
_bitset.Set(i2);
_bitset.Set(i3);
}
bool Test(const K& s)
{
size_t i1 = Hash1()(s)%N;
size_t i2 = Hash2()(s)%N;
size_t i3 = Hash3()(s)%N;
//如果有一个数据在位图是不存在的,则说明该数据不存在
if (!_bitset.Test(i1))
{
return false;
}
if (!_bitset.Test(i2))
{
return false;
}
if(!_bitset.Test(i3))
{
return false;
}
//如果所有数据在位图中都存在,则说明该字符串存在。
return true;
}
}; 测试代码:
将100个字符映射到位图中,然后再检查不同的10000个字符串是否与位图中的字符串发生冲突。
int main()
{
BloomFilter<500> bf;
vector v1;
//将100个字符串映射到布隆过滤器中
for (int i = 0; i < 100; i++)
{
string s = "shen jia peng";
s +=to_string(1234+i);
v1.push_back(s);
}
for (auto& str : v1)
{
bf.Set(str);
}
//测试10000个字符串是否与位图中的字符串冲突的概率
int N = 10000;
vector v2;
for (int i = 0; i 结果
在开辟2000个bit位,10000个字符串冲突的概率是32个,冲突概率是挺低的,也就是说1个字符串在位图中只需要3个字节就可以进行映射。并且冲突率还是可以接受的。
2.2 布隆过滤器优点
- 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
2.3 布隆过滤器缺点
- 存在误判,判断 “在” 是不准确的,判断“不在”是准确的。
- 不能获取元素本身。
- 一般情况下不能将元素从布隆过滤器中删除元素。
2.4 布隆过滤器使用场景
场景一:运行容忍布隆过滤器的误判。
例如:在游戏中创建创建昵称,为了保证游戏的昵称是具有唯一性的,并且可以快速判断一个游戏昵称是否被创建过,我们可以将之前定义的所有游戏昵称都映射到布隆过滤器中,然后将要创建的游戏昵称与布隆过滤器进行对比,如果存在,此时之前不一定能够创建过,但是我们不能够创建该昵称,如果不存在,那么该昵称之前一定没有创建过,所以就可以创建它,这样就保证了每个角色的游戏昵称的唯一性。
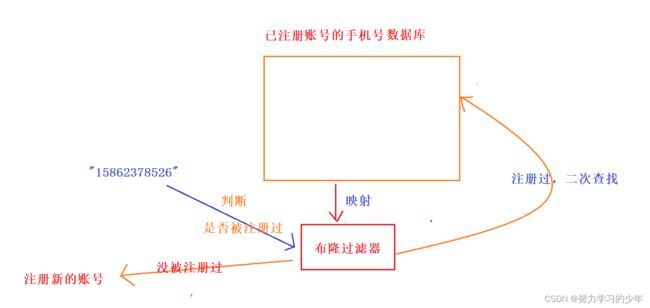
场景二:判断一个手机号是否注册过游戏账号
我们可以将所有创建过账号的手机号放在数据库中,然后将数据库中的映射到一个布隆过滤器中,
我们可以先去布隆过滤器中判断该手机号是否被注册过,如果没有被注册过账号,那么该手机号一定没有被注册过,如果判断是注册过,则该手机不一定被注册过,那么在到数据库中进行判断是否被创建过账号。因为大部分手机号要注册游戏账号都是没有被注册过的,可以排除大部分去数据库中查找的情况。
问题五
1. 给两个文件,文件1和文件2,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法。
query:可能是http网络请求,sql请求,本质都是字符串
近视算法:位图映射
在内存中创建一个1gb的布隆过滤器,然后将文件1中所有的query都映射到布隆过滤器中,然后文件2通过该布隆过滤器去判断是否query是否在布隆过滤器中,如果在布隆过滤器中,那么该query就是交集。
精确算法:哈希切分
假设平均一个query为20个字节,那么一个文件的大小就大约为200G,所以我们可以将一个文件分成为400个小文件,a0,a1,a2,...a399,平均每个文件为500mb,然后对文件1中的query进行BKDRHash()(querty)%400计算,将计算的结果放在对应的小文件中,如果结果为querty计算的结果为32,那么放在a32文件中,同样文件2也分成400个小文件,b0,b1,b2....b399,然后对文件2中的query进行BKDRHash()(querty)%400计算,将计算结果放进相对应的小文件中。因为文件1和文件2使用的相同的哈希函数,所以两个文件相同的query会放在下标一致的文件中,然后求出a0和b0,a1和b1...a399和b399的交集即可。可以先将一个文件加载内存中,利用under_set建立映射,另一个文件在通过映射关系求出交集。
问题六
如何扩展BloomFilter使得它支持删除元素的操作?
采用计数的方式标记每个位置,之前的布隆过滤器是一个映射位置是1个bit位,所以只能表示0和1,那么我们可以8个bit(一个字节)位标记一个映射位置,所以一个映射位置可以表示0~255。所以当有一个字符串映射到某个位置上时,那么该位置就+1,如果删掉某个字符串时,那么该字符串映射的对应的位置就-1。

删除田六,将15和20,25上的位置都减1。

问题七
给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
解决方法:哈希切分
创建1000个小文件,小文件a0,a1,a2...,a999,每个文件大小大约是100mb(每个文件的大小不一定是一样),然后对所有的IP地址利用哈希函数转换为整数,将转换的整数%1000,如:结果=BKDRHash(x)%1000,得到的结果就放在相对应的文件中,结果是1,那么放在小文件a1中,因为是所有的IP地址使用的是相同的哈希函数,那么相同的IP转换成整数是一定相同的,则相同的IP地址一定放在同一小文件中,然后再将一个一个的小文件加载到内存中,统计IP地址的次数,可以使用map进行统计,最后将每个文件中出现最多次数的IP和次数放在一个文件中,最后在将这个文件加载内存中进行对比,通过排序,就可以找到log flie文件中出现最多次数的IP。