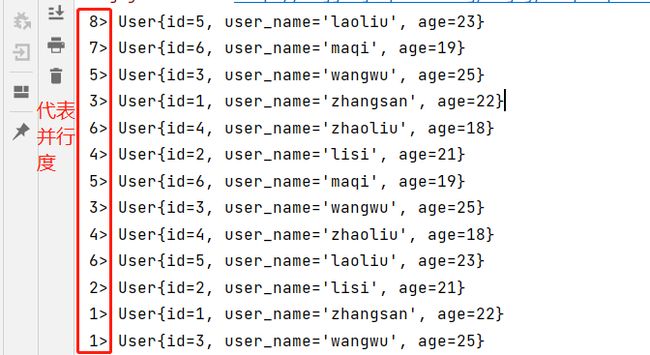
Flink设置Source数据源使用kafka获取数据
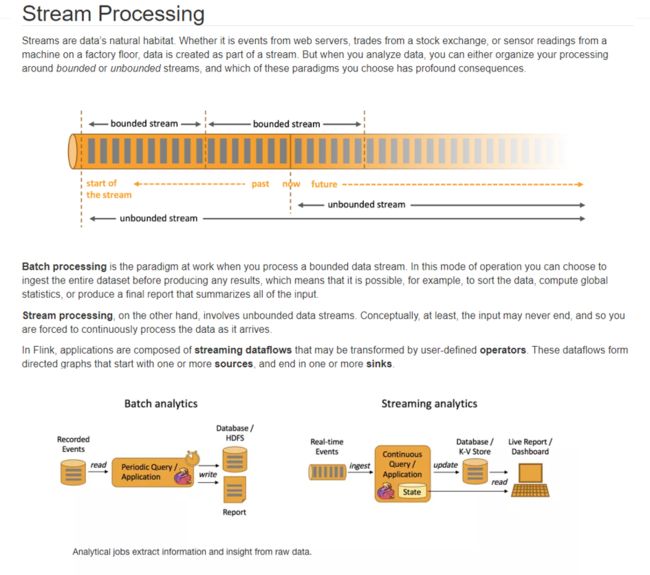
流处理说明
有边界的流bounded stream:批数据
无边界的流unbounded stream:真正的流数据


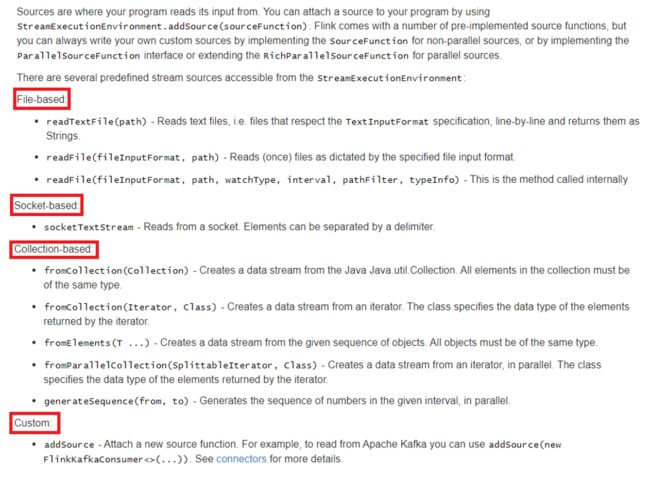
Source
基于集合

package com.pzb.source;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* Desc 演示DataStream-Source-基于集合
*/
public class SourceDemo01_Collection {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置自动处理,不设置默认流处理
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream ds1 = env.fromElements("hadoop spark flink", "hadoop spark flink");
DataStream ds2 = env.fromCollection(Arrays.asList("hadoop spark flink", "hadoop spark flink"));
DataStream ds3 = env.generateSequence(1, 100);//产生一个从1-100的有序数据 官方认为此方法已过时,建议使用下方的方法
DataStream ds4 = env.fromSequence(1, 100);//产生一个从1-100的有序数据
//TODO 2.transformation
//TODO 3.sink
ds1.print();
ds2.print();
ds3.print();
ds4.print();
//TODO 4.execute
env.execute();
}
}
基于文件

package com.pzb.source;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* Desc 演示DataStream-Source-基于本地/HDFS的文件/文件夹/压缩文件
*/
public class SourceDemo02_File {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream ds1 = env.readTextFile("data/input/words.txt");
DataStream ds2 = env.readTextFile("data/input/dir");// 读取该目录下的所有文件
DataStream ds3 = env.readTextFile("data/input/wordcount.txt.gz"); // 读取压缩包文件
DataStream ds4 = env.readTextFile("hdfs://hadoop111:8020/data/input/words.txt");// 读hdfs文件
//TODO 2.transformation
//TODO 3.sink
ds1.print();
ds2.print();
ds3.print();
//TODO 4.execute
env.execute();
}
}
基于Socket

package com.pzb.source;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* Desc 演示DataStream-Source-基于Socket
*/
public class SourceDemo03_Socket {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream lines = env.socketTextStream("node1", 9999);// 不管怎么设置socketTextStream并行度,其并行度都为1
//TODO 2.transformation
/*SingleOutputStreamOperator words = lines.flatMap(new FlatMapFunction() {
@Override
public void flatMap(String value, Collector out) throws Exception {
String[] arr = value.split(" ");
for (String word : arr) {
out.collect(word);
}
}
});
words.map(new MapFunction>() {
@Override
public Tuple2 map(String value) throws Exception {
return Tuple2.of(value,1);
}
});*/
//注意:下面的操作将上面的2步合成了1步,直接切割单词并记为1返回
SingleOutputStreamOperator> wordAndOne = lines.flatMap(new FlatMapFunction>() {
@Override
public void flatMap(String value, Collector> out) throws Exception {
String[] arr = value.split(" ");
for (String word : arr) {
out.collect(Tuple2.of(word, 1));
}
}
});
SingleOutputStreamOperator> result = wordAndOne.keyBy(t -> t.f0).sum(1);
//TODO 3.sink
result.print();
//TODO 4.execute
env.execute();
}
}
基于Kafka
addSource
首先添加相关依赖
org.apache.flink
flink-connector-kafka_2.11
1.13.6
package com.peng.kafka_;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
/**
* @author 海绵先生
* @Description TODO Source对接Kafka
* @date 2022/10/11-17:07
*/
public class KafkaComsumerDemo {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
//准备kafka连接参数
Properties props = new Properties();
props.setProperty("bootstrap.servers", "hadoop111:9092");//集群地址
props.setProperty("group.id", "flink");//消费者组id
props.setProperty("auto.offset.reset","latest");//latest有offset记录从记录位置开始消费,没有记录从最新的/最后的消息开始消费 /earliest有offset记录从记录位置开始消费,没有记录从最早的/最开始的消息开始消费
props.setProperty("flink.partition-discovery.interval-millis","5000");//会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测
props.setProperty("enable.auto.commit", "true");//自动提交,设置offset
props.setProperty("auto.commit.interval.ms", "2000");//自动提交的时间间隔
//使用连接参数创建FlinkKafkaConsumer/kafkaSource
FlinkKafkaConsumer kafkaSource = new FlinkKafkaConsumer("flink_kafka", new SimpleStringSchema(), props);// String泛型为当前存储数据的数据类型
/*
SimpleStringSchema接口:官方注释说 Very simple serialization schema for strings :非常简单的字符串序列化架构。将数据序列化和反序列化成String类型,默认编码格式为UTF-8。
*/
//使用kafkaSource
DataStream kafkaDS = env.addSource(kafkaSource);
//TODO 2.transformation
//TODO 3.sink
kafkaDS.print();
//TODO 4.execute
env.execute();
}
}
Kafka存储的数据类型是字节数据类型,要想把字节数据类型转换成Java中对应的基本数据类型/类数据类型,需要进行反序列化操作。
自定义反序列化:
package com.peng.kafka_;
import com.alibaba.fastjson.JSON;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import cn.hutool.json.JSONUtil;
import java.io.IOException;
import java.util.Properties;
/**
* @author 海绵先生
* @Description TODO 实现将Kafka里的Json数据消息转换成所对应的类
* @date 2022/11/6-11:28
*/
public class Kafka_Sink_Source {
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class People{
private int id;
private String name;
private int age;
}
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// TODO sink 自定义生产数据,将数据传送到Kafka
DataStreamSource peopleDataStreamSource = env.fromElements(new People(1, "zhangsan", 18),
new People(2, "lisi", 20),
new People(3, "wangwu", 22));
Properties sinkProperties = new Properties();
sinkProperties.setProperty("bootstrap.servers","hadoop111:9092");
SingleOutputStreamOperator map = peopleDataStreamSource.map(new MapFunction() {
@Override
public String map(People value) throws Exception {//因为Kafka是识别不了Java里的数据类型的,因此要将其转换成String类型
// 直接.toString也行,但是为了后面更好的反序列化,所以就转换成了JSONString
return JSON.toJSONString(value);
}
});
FlinkKafkaProducer sinkKafka = new FlinkKafkaProducer<>("flink_kafka", new SimpleStringSchema(), sinkProperties);
map.addSink(sinkKafka);
// TODO source 对接上一步,接收kafka数据
Properties sourceProperties = new Properties();
sourceProperties.setProperty("bootstrap.servers","hadoop111:9092");
sourceProperties.setProperty("group.id", "flink");//消费者组id
sourceProperties.setProperty("auto.offset.reset","latest");
sourceProperties.setProperty("flink.partition-discovery.interval-millis","5000");
sourceProperties.setProperty("enable.auto.commit", "false");//自动提交,设置offset
sourceProperties.setProperty("auto.commit.interval.ms", "2000");//自动提交的时间间隔
FlinkKafkaConsumer flink = new FlinkKafkaConsumer("flink_kafka", new DeserializationSchema() {
@Override
public TypeInformation getProducedType() {
// 定义返回的类型
return TypeInformation.of(People.class);
}
@Override
public People deserialize(byte[] message) throws IOException {
// 引入import cn.hutool.json.JSONUtil;
// 将String类型的数据,通过key值转换成对用的class
return JSONUtil.toBean(new String(message),People.class);
}
@Override
public boolean isEndOfStream(People nextElement) {
return false;
}
},sourceProperties);
DataStreamSource peopleDataStreamSource1 = env.addSource(flink);
peopleDataStreamSource1.print("反序列化结果:");// 反序列化结果::2> Kafka_Sink_Source.People(id=1, name=zhangsan, age=18)
env.execute();
}
}
这样数据就具有类的操作了
自定义Source-随机订单数据
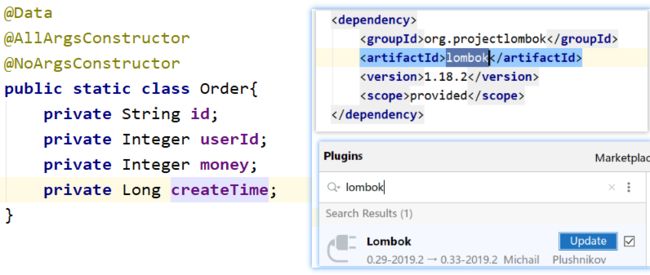
注意: lombok的使用

Rich代表“富”,它可以获得运行环境的上下文,并拥有一些生命周期的方法
- open是 Rich Function 的初始化方法,也就是会开启一个算子的生命周期。当一个算子的实际工作方法例如 map()或者 filter()方法被调用之前,open()会首先被调用。所以像文件 IO 的创建,数据库连接的创建,配置文件的读取等等这样一次性的工作,都适合在 open()方法中完成。
- close()方法,是生命周期中的最后一个调用的方法,类似于解构方法。一般用来做一些清理工作。
- run()
- cancel()
- 并且,每个transform方法都有对应的Rich抽象类

package com.pzb.source;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import java.util.Random;
import java.util.UUID;
/**
* Desc 演示DataStream-Source-自定义数据源
* 需求:
*/
public class SourceDemo04_Customer {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream orderDS = env.addSource(new MyOrderSource()).setParallelism(2);
//TODO 2.transformation
//TODO 3.sink
orderDS.print();
//TODO 4.execute
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Order{
private String id;
private Integer userId;
private Integer money;
private Long createTime;
}
public static class MyOrderSource extends RichParallelSourceFunction{//Order为输出的数据类型
private Boolean flag = true;
//执行并生成数据
@Override
public void run(SourceContext ctx) throws Exception {//当线程启动时,会自动启动run方法
Random random = new Random();
while (flag) {
//UUID是java.util包里的类,具有自定生成订单的功能
String oid = UUID.randomUUID().toString();
int userId = random.nextInt(3);
int money = random.nextInt(101);
long createTime = System.currentTimeMillis();
ctx.collect(new Order(oid,userId,money,createTime));
Thread.sleep(1000);
}
}
//执行cancel命令的时候执行
@Override
public void cancel() {
flag = false;
}
}
}
自定义Source-MySQL

package com.pzb.source;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
/**
* Desc 演示DataStream-Source-自定义数据源-MySQL
* 需求:
*/
public class SourceDemo05_Customer_MySQL {
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source
DataStream studentDS = env.addSource(new MySQLSource()).setParallelism(1);
//TODO 2.transformation
//TODO 3.sink
studentDS.print();
//TODO 4.execute
env.execute();
}
/*
CREATE TABLE `t_student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
INSERT INTO `t_student` VALUES ('1', 'jack', '18');
INSERT INTO `t_student` VALUES ('2', 'tom', '19');
INSERT INTO `t_student` VALUES ('3', 'rose', '20');
INSERT INTO `t_student` VALUES ('4', 'tom', '19');
INSERT INTO `t_student` VALUES ('5', 'jack', '18');
INSERT INTO `t_student` VALUES ('6', 'rose', '20');
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class Student {
private Integer id;
private String name;
private Integer age;
}
// 貌似这些方法都会自动调用???是线程?
public static class MySQLSource extends RichParallelSourceFunction {
private boolean flag = true;
// 数据库的连接对象
private Connection conn = null;
private PreparedStatement ps =null;
private ResultSet rs = null;
//open只执行一次,适合开启资源
@Override
public void open(Configuration parameters) throws Exception {
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata", "root", "root");
String sql = "select id,name,age from t_student";
ps = conn.prepareStatement(sql);// 执行SQL语句
}
//open后会启动run方法
@Override
public void run(SourceContext ctx) throws Exception {
while (flag) {// 先设置死循环,让程序持续读取数据,调用cancel时,破除死循环
rs = ps.executeQuery();//executeQuery会把数据库响应的查询结果存放在ResultSet类对象中供我们使用。
while (rs.next()) {// 遍历Set里的值
int id = rs.getInt("id");//根据列标签获取对应的值
String name = rs.getString("name");
int age = rs.getInt("age");
ctx.collect(new Student(id,name,age));
}
Thread.sleep(5000);
}
}
//接收到cancel命令时取消数据生成
@Override
public void cancel() {
flag = false;
}
//close里面关闭资源
@Override
public void close() throws Exception {
if(conn != null) conn.close();
if(ps != null) ps.close();
if(rs != null) rs.close();
}
}
}