【iOS】—— 分类、扩展和关联对象
分类、扩展和关联对象
- 一、分类与扩展的区别
-
-
- 1、`category`类别(分类)
- 2、`extension`(类扩展)
-
- 二、关联对象的实现
-
-
- 1.关联对象的实现步骤:
- 2.关联对象分析:
-
- 三、关联对象-设值流程
-
-
- 1.四个核心对象:
- 2.`objc_setAssociatedObject`解析:
-
-
- 内存策略:
- `_object_set_associative_reference`源码如下:
-
- 3.`AssociationsManager`解析:
-
-
- `AssociationsManager`的源码如下:
-
- 4.`try_emplace`方法探究:
- 5.`LookupBucketFor`方法:
- 6.`InsertIntoBucket`方法:
- 7.InsertIntoBucketImpl方法分析:
- 8.`isFirstAssociation`首次关联对象:
- 9.关联对象的数据结构:
-
- 四、关联对象-取值流程
-
-
- 1.`objc_getAssociatedObject`方法:
- 2.`_object_get_associative_reference`方法:
-
- 五、关联对象-移除流程
-
-
- 1.`objc_removeAssociatedObjects`方法:
- 2.`_object_remove_assocations`源码:
- 3.对象销毁dealloc时,销毁相关的关联对象:
-
- 六、总结
一、分类与扩展的区别
1、category类别(分类)
- 专门用来给类添加新的方法。
- 不能给类添加成员属性,添加了成员属性,也无法取到。
- 【注意】:其实可以通过
runtime给分类添加属性,即属性关联,重写setter、getter方法。 - 分类中用
@property定义的变量,只会生成变量的setter、getter方法的声明,不能生成方法实现和带下划线的成员变量。
2、extension(类扩展)
- 可以说成是特殊的分类,也可称作匿名分类。
- 可以给类添加成员属性,但是是私有变量。
- 可以给类添加方法,也是私有方法。
二、关联对象的实现
关联对象(AssociatedObject)是一种运用runtime在分类中添加"属性"的方法。那么关联是怎样实现添加"属性"的呢?
1.关联对象的实现步骤:
- 创建一个分类,并在其
.h文件中声明一个属性。 - 添加头文件
#import。 - 在
.m中声明该属性为动态加载@dynamic。 - 实现
setter和getter方法。
举例:
UIViewController+Test.h
#import <UIKit/UIKit.h>
@interface UIViewController (Test)
//定义一个属性
@property (nonatomic, strong) NSString *tempString;
@end
UIViewController+Test.m
#import "UIViewController+Test.h"
//一定要记得加头文件
#import <objc/runtime.h>
@implementation UIViewController (Test)
//用@dynamic修饰属性,这样编译器不会自动实现setter和getter方法
@dynamic tempString;
//实现该属性的setter和getter方法
- (void)setTempString:(NSString *)tempString {
objc_setAssociatedObject(self, @"setObj", tempString, OBJC_ASSOCIATION_RETAIN_NONATOMIC);
}
- (NSString *)tempString {
return objc_getAssociatedObject(self, @"setObj");
}
@end
2.关联对象分析:
从代码能看出,实际上关联对象并没有往原有类中添加成员变量。当然了,实际上类的空间编译的时候就已经是确定好的了,分类的属性实际上就是set和get方法的实现。
那么我们只要看懂set和get方法内部的实现就能搞清楚究竟关联对象是怎么做的。
三、关联对象-设值流程
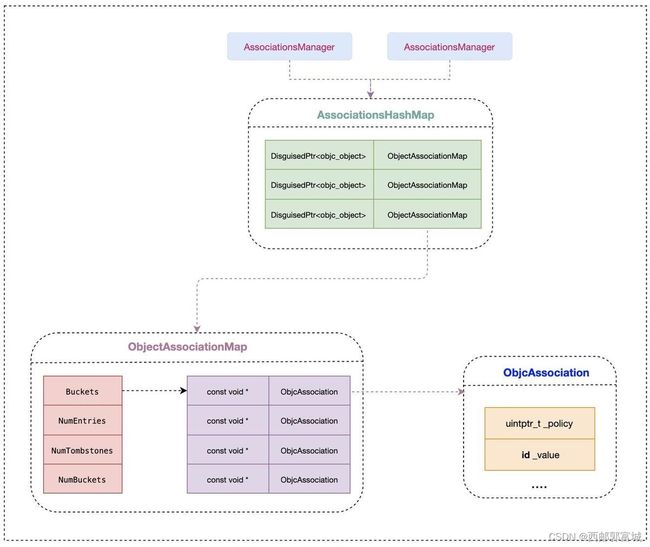
1.四个核心对象:
- AssociationsManager
- AssociationsHashMap
- ObjectAssociationMap
- ObjcAssociation
在源码分析之前,我们需要去苹果官方下载runtime库我们才可以看其源码。
2.objc_setAssociatedObject解析:
我们在源码库中可以看到其实现部分:
void objc_setAssociatedObject(id object, const void *key, id value, objc_AssociationPolicy policy) {
_object_set_associative_reference(object, key, value, policy);
}
我们在调用此方法的时候,一共传递了四个参数:
| 参数名称 | 解释 |
|---|---|
| id object | 需要关联的对象 |
| void *key | 对应的key |
| id value | 对应的值 |
| objc_AssociationPolicy policy | 内存管理策略 |
内存策略:
typedef OBJC_ENUM(uintptr_t, objc_AssociationPolicy) {
//等效于assign
OBJC_ASSOCIATION_ASSIGN = 0, /**< 指定关联对象的弱引用。 */
//等效于nonatomic,retain
OBJC_ASSOCIATION_RETAIN_NONATOMIC = 1, /**< 指定对关联对象的强引用。
* 关联不是以原子方式建立的。 */
//等效于nonatiomic,copy
OBJC_ASSOCIATION_COPY_NONATOMIC = 3, /**< 指定复制关联对象。
* 关联不是以原子方式建立的。 */
//等效于retain
OBJC_ASSOCIATION_RETAIN = 01401, /**< 指定对关联对象的强引用。
* 关联是原子式的。 */
//等效于copy
OBJC_ASSOCIATION_COPY = 01403 /**< 指定复制关联对象。
* 关联是原子式的。 */
};
对于四个参数理解完了之后让我们看看它真正的实现函数_object_set_associative_reference:
_object_set_associative_reference源码如下:
void _object_set_associative_reference(id object, const void *key, id value, uintptr_t policy) {
// This code used to work when nil was passed for object and key. Some code
// probably relies on that to not crash. Check and handle it explicitly.
// rdar://problem/44094390
if (!object && !value) return;
if (object->getIsa()->forbidsAssociatedObjects())
_objc_fatal("objc_setAssociatedObject called on instance (%p) of class %s which does not allow associated objects", object, object_getClassName(object));
// 将 object 封装成 DisguisedPtr 目的是方便底层统一处理
DisguisedPtr<objc_object> disguised{(objc_object *)object};
// 将 policy和value 封装成ObjcAssociation,目的是方便底层统一处理
ObjcAssociation association{policy, value};
// retain the new value (if any) outside the lock.
// 根据policy策略去判断是进去 retain 还是 copy 操作
association.acquireValue();
bool isFirstAssociation = false;//用来判断是否是,第一次关联该对象
{
// 实例化 AssociationsManager 注意这里不是单例
AssociationsManager manager;
// 实例化 全局的关联表 AssociationsHashMap 这里是单例
AssociationsHashMap &associations(manager.get());
//如果传过来的value有值
if (value) {
// AssociationsHashMap:关联表 ObjectAssociationMap:对象关联表
// 首先根据对象封装的disguised去关联表中查找有没有对象关联表
// 如果有直接返回结果,如果没有则根据`disguised`去创建对象关联表
// 创建ObjectAssociationMap时当(对象的个数+1大于等于3/4,进行两倍扩容)
auto refs_result = associations.try_emplace(disguised, ObjectAssociationMap{});
if (refs_result.second) {
/* it's the first association we make */
// 表示第一次关联该对象
isFirstAssociation = true;
}
/* establish or replace the association */
// 获取ObjectAssociationMap中存储值的地址
auto &refs = refs_result.first->second;
// 将需要存储的值存放在关联表中存储值的地址中
// 同时会根据key去查找,如果查找到`result.second` = false ,如果找不到就创建`result.second` = true
// 创建association时,当(association的个数+1)超过3/4,就会进行两倍扩容
auto result = refs.try_emplace(key, std::move(association));
//查找到了
if (!result.second) {
// 交换association和查询到的`association`
// 其实可以理解为更新查询到的`association`数据,新值替换旧值
association.swap(result.first->second);
}
} else { // value没有值走else流程
// 查找disguised 对应的ObjectAssociationMap
auto refs_it = associations.find(disguised);
// 如果找到对应的 ObjectAssociationMap 对象关联表
if (refs_it != associations.end()) {
// 获取 refs_it->second,里面存放了association类型数据
auto &refs = refs_it->second;
// 根据key查询对应的association
auto it = refs.find(key);
if (it != refs.end()) {
// 如果找到,更新旧的association里面的值
association.swap(it->second);
// value = nil时释放关联对象表中存的`association`
refs.erase(it);
if (refs.size() == 0) {
// 如果该对象关联表中所有的关联属性数据被清空,那么该对象关联表会被释放
associations.erase(refs_it);
}
}
}
}
}
// Call setHasAssociatedObjects outside the lock, since this
// will call the object's _noteAssociatedObjects method if it
// has one, and this may trigger +initialize which might do
// arbitrary stuff, including setting more associated objects.
// 首次关联对象调用setHasAssociatedObjects方法
// 通过setHasAssociatedObjects方法`标记对象存在关联对象`设置`isa指针`的`has_assoc`属性为`true`
if (isFirstAssociation)
object->setHasAssociatedObjects();
// release the old value (outside of the lock).
// 释放旧值因为如果有旧值会被交换到`association`中
// 原来`association`的新值会存放到对象关联表中
association.releaseHeldValue();
}
_object_set_associative_reference方法主要有下列两步操作:
- 根据
object在全局关联表(AssociationsHashMap)中查询ObjectAssociationMap,如果没有就去开辟内存创建ObjectAssociationMap,创建的规则就是在3/4时,进行两倍扩容,扩容的规则和cache方法存储的规则是一样的。` - 将根据
key查询到相关的association(即关联的数据 value和policy),如果查询到直接更新里面的数据,如果没有则去获取空的association类型然后将值存放进去,扩容的规则和cache方法存储的规则是一样的。
_object_set_associative_reference函数内部我们可以找到我们上面说过的实现关联对象技术的四个核心对象。接下来我们来一个一个看其内部实现原理探寻他们之间的关系。
3.AssociationsManager解析:
AssociationsManager manager并不是单例,通过AssociationsHashMap &associations(manager.get());获取的关联表是全局唯一的。
AssociationsManager的源码如下:
class AssociationsManager {
using Storage = ExplicitInitDenseMap<DisguisedPtr<objc_object>, ObjectAssociationMap>;
static Storage _mapStorage;
public:
// 构造函数(在作用域内加锁)
AssociationsManager() { AssociationsManagerLock.lock(); }
// 析构函数(离开作用域,解锁)
~AssociationsManager() { AssociationsManagerLock.unlock(); }
// 获取全局的一张AssociationsHashMap表
AssociationsHashMap &get() {
return _mapStorage.get();
}
static void init() {
_mapStorage.init();
}
};
从源码我们可以发现:static Storage _mapStorage;,_mapStorage是全局静态变量,因此获取的AssociationsHashMap关联表也是全局唯一的一份。
AssociationsManager的构造函数AssociationsManager()和析构函数~AssociationsManager()主要是在相应作用域内加锁,为了防止多线程访问出现混乱。
4.try_emplace方法探究:
try_emplace方法的作用就是去表中查找Key相应的数据,不存在就创建:(我的理解就是哈希表,通过key去查找相应桶中的数据)
- 通过
LookupBucketFor方法去表中查找Key对应的TheBucket是否有存在,如果存在对TheBucket进行包装然后返回。 - 如果不存在,通过
InsertIntoBucket方法插入新值,扩容的规则和cache方法存储的规则是一样的。
// Inserts key,value pair into the map if the key isn't already in the map.
// The value is constructed in-place if the key is not in the map, otherwise
// it is not moved.
//如果键不在map中,则将键值对插入到map中。
//如果键不在map中,该值将被就地构造,否则不会移动。
template <typename... Ts>
std::pair<iterator, bool> try_emplace(KeyT &&Key, Ts &&... Args) {
BucketT *TheBucket;
// 根据key去查找对应的TheBucket
if (LookupBucketFor(Key, TheBucket))
// 通过make_pair生成相应的键值对
return std::make_pair(
makeIterator(TheBucket, getBucketsEnd(), true),
false); // Already in map.表示【表中】已经存在bucket
// Otherwise, insert the new element.
// 如果没有查询到 将数据(键值)插入TheBucket中
TheBucket =
InsertIntoBucket(TheBucket, std::move(Key), std::forward<Ts>(Args)...);
// 通过make_pair生成相应的键值对
return std::make_pair(
makeIterator(TheBucket, getBucketsEnd(), true),
true); // true表示第一次往哈希关联表中添加bucket
}
5.LookupBucketFor方法:
这个方法就是 根据Key去表中查找Bucket,如果已经缓存过,返回true,否则返回false。
/// LookupBucketFor - Lookup the appropriate bucket for Val, returning it in
/// FoundBucket. If the bucket contains the key and a value, this returns
/// true, otherwise it returns a bucket with an empty marker or tombstone and
/// returns false.
/// LookupBucketFor - 为Val查找相应的桶,并在FoundBucket中返回。如果桶中包含键和值,则返回true,否则返回带有空标记或空tombstone的桶并返回false。
template<typename LookupKeyT>
bool LookupBucketFor(const LookupKeyT &Val,
const BucketT *&FoundBucket) const {
// 获取buckets的首地址
const BucketT *BucketsPtr = getBuckets();
// 获取可存储的buckets的总数
const unsigned NumBuckets = getNumBuckets();
// 如果NumBuckets = 0 返回 false
if (NumBuckets == 0) {
FoundBucket = nullptr;
return false;
}
// FoundTombstone - 在探查的时候留意我们是否找到了tombstone。
const BucketT *FoundTombstone = nullptr;
const KeyT EmptyKey = getEmptyKey();
const KeyT TombstoneKey = getTombstoneKey();
assert(!KeyInfoT::isEqual(Val, EmptyKey) &&
!KeyInfoT::isEqual(Val, TombstoneKey) &&
"Empty/Tombstone value shouldn't be inserted into map!");
// 计算hash下标
unsigned BucketNo = getHashValue(Val) & (NumBuckets-1);
unsigned ProbeAmt = 1;
while (true) {
// 内存平移:找到hash下标对应的Bucket
const BucketT *ThisBucket = BucketsPtr + BucketNo;
// Found Val's bucket? If so, return it.
if (LLVM_LIKELY(KeyInfoT::isEqual(Val, ThisBucket->getFirst()))) {
// 如果查询到`Bucket`的`key`和`Val`相等 返回当前的Bucket说明查询到了
FoundBucket = ThisBucket;
return true;
}
// If we found an empty bucket, the key doesn't exist in the set.
// Insert it and return the default value.
// 如果bucket为空,说明当前key还不在表中,返回false,后续进行插入操作
if (LLVM_LIKELY(KeyInfoT::isEqual(ThisBucket->getFirst(), EmptyKey))) {
// If we've already seen a tombstone while probing, fill it in instead
// of the empty bucket we eventually probed to.
FoundBucket = FoundTombstone ? FoundTombstone : ThisBucket;
return false;
}
// If this is a tombstone, remember it. If Val ends up not in the map, we
// prefer to return it than something that would require more probing.
// Ditto for zero values.
//如果这是tombstone,记住它。如果Val最终不在地图中,我们宁愿返回它,而不是需要更多探测的东西。对于零值也是如此。
if (KeyInfoT::isEqual(ThisBucket->getFirst(), TombstoneKey) &&
!FoundTombstone)
//记录发现的第一块tombstone
FoundTombstone = ThisBucket; // Remember the first tombstone found.
if (ValueInfoT::isPurgeable(ThisBucket->getSecond()) && !FoundTombstone)
FoundTombstone = ThisBucket;
// Otherwise, it's a hash collision or a tombstone, continue quadratic
// probing.
//否则,它是一个哈希冲突或tombstone,继续二次探索。
if (ProbeAmt > NumBuckets) {
FatalCorruptHashTables(BucketsPtr, NumBuckets);
}
// 重新计算hash下标
BucketNo += ProbeAmt++;
BucketNo &= (NumBuckets-1);
}
}
6.InsertIntoBucket方法:
template <typename KeyArg, typename... ValueArgs>
BucketT *InsertIntoBucket(BucketT *TheBucket, KeyArg &&Key,
ValueArgs &&... Values) {
// 根据Key 找到TheBucket的内存地址
TheBucket = InsertIntoBucketImpl(Key, Key, TheBucket);
// 将 Key 和 Values保存到TheBucket中
TheBucket->getFirst() = std::forward<KeyArg>(Key);
::new (&TheBucket->getSecond()) ValueT(std::forward<ValueArgs>(Values)...);
return TheBucket;
}
7.InsertIntoBucketImpl方法分析:
主要的工作都是在InsertIntoBucketImpl方法中完成的:
- 计算实际占用
buckets的个数,如果超过负载因子(3/4),进行扩容操作this->grow(NumBuckets * 2);。 - 找到
TheBucket的内存地址:LookupBucketFor(Lookup, TheBucket);。 - 更新占用的容量个数:
incrementNumEntries();。
template <typename LookupKeyT>
BucketT *InsertIntoBucketImpl(const KeyT &Key, const LookupKeyT &Lookup,
BucketT *TheBucket) {
// If the load of the hash table is more than 3/4, or if fewer than 1/8 of
// the buckets are empty (meaning that many are filled with tombstones),
// grow the table.
//如果哈希表的加载量大于3/4,或者小于1/8的桶是空的(这意味着很多桶都装满了tombstones),那么就增加哈希表。
//
// The later case is tricky. For example, if we had one empty bucket with
// tons of tombstones, failing lookups (e.g. for insertion) would have to
// probe almost the entire table until it found the empty bucket. If the
// table completely filled with tombstones, no lookup would ever succeed,
// causing infinite loops in lookup.
//后一种情况比较棘手。例如,如果我们有一个空桶,里面有大量的tombstone,那么失败的查找(例如插入)将不得不探测几乎整个表,直到找到空桶。如果表完全被tombstone填满,那么任何查找都无法成功,导致无限循环的查找。
// 计算实际占用buckets的个数,如果超过负载因子(3/4),进行扩容操作
unsigned NewNumEntries = getNumEntries() + 1;
// 获取buckets的总容量
unsigned NumBuckets = getNumBuckets();
if (LLVM_UNLIKELY(NewNumEntries * 4 >= NumBuckets * 3)) {
// 如果哈希表的负载大于等于3/4,进行二倍扩容
this->grow(NumBuckets * 2); // 首次分配 4 的容量
//查找Bucket
LookupBucketFor(Lookup, TheBucket);
NumBuckets = getNumBuckets();
} else if (LLVM_UNLIKELY(NumBuckets-(NewNumEntries+getNumTombstones()) <=
NumBuckets/8)) {
this->grow(NumBuckets);
//查找Bucket
LookupBucketFor(Lookup, TheBucket);
}
ASSERT(TheBucket);
// Only update the state after we've grown our bucket space appropriately
// so that when growing buckets we have self-consistent entry count.
// If we are writing over a tombstone or zero value, remember this.
//只有在适当增加桶空间之后才更新状态,这样当增加桶时,我们就有了自一致的条目计数。如果我们写在tombstone上或者零值上,记住这个。
if (KeyInfoT::isEqual(TheBucket->getFirst(), getEmptyKey())) {
// Replacing an empty bucket.
// 更换空桶。
// 更新占用的容量个数
incrementNumEntries();
} else if (KeyInfoT::isEqual(TheBucket->getFirst(), getTombstoneKey())) {
// Replacing a tombstone.
// 更换tombstone
incrementNumEntries();
decrementNumTombstones();
} else {
// we should be purging a zero. No accounting changes.
// 我们应该清除一个零。没有占用变更。
ASSERT(ValueInfoT::isPurgeable(TheBucket->getSecond()));
TheBucket->getSecond().~ValueT();
}
return TheBucket;
}
8.isFirstAssociation首次关联对象:
首次关联对象,需要更新对象isa的标志位has_assoc,表示是否有关联对象。
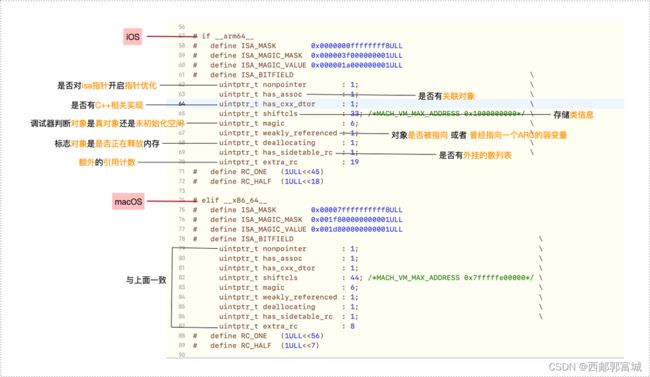
// Call setHasAssociatedObjects outside the lock, since this
// will call the object's _noteAssociatedObjects method if it
// has one, and this may trigger +initialize which might do
// arbitrary stuff, including setting more associated objects.
// 首次关联对象调用setHasAssociatedObjects方法
// 通过setHasAssociatedObjects方法`标记对象存在关联对象`设置`isa指针`的`has_assoc`属性为`true`
if (isFirstAssociation)
object->setHasAssociatedObjects();
查看setHasAssociatedObjects方法:
inline void
objc_object::setHasAssociatedObjects() {
if (isTaggedPointer()) return;
if (slowpath(!hasNonpointerIsa() && ISA()->hasCustomRR()) && !ISA()->isFuture() && !ISA()->isMetaClass()) {
void(*setAssoc)(id, SEL) = (void(*)(id, SEL)) object_getMethodImplementation((id)this, @selector(_noteAssociatedObjects));
if ((IMP)setAssoc != _objc_msgForward) {
(*setAssoc)((id)this, @selector(_noteAssociatedObjects));
}
}
isa_t newisa, oldisa = LoadExclusive(&isa.bits);
do {
newisa = oldisa;
if (!newisa.nonpointer || newisa.has_assoc) {
ClearExclusive(&isa.bits);
return;
}
newisa.has_assoc = true;
} while (slowpath(!StoreExclusive(&isa.bits, &oldisa.bits, newisa.bits)));
}
发现它执行了newisa.has_assoc = true;即标记了这个对象存在关联对象。
通过setHasAssociatedObjects方法设置对象存在关联对象,即isa指针的has_assoc位域设置为true最后通过releaseHeldValue方法释放旧值。
9.关联对象的数据结构:
四、关联对象-取值流程
1.objc_getAssociatedObject方法:
id objc_getAssociatedObject(id object, const void *key) {
return _object_get_associative_reference(object, key);
}
我们可以直观的看到,objc_getAssociatedObject调用了_object_get_associative_reference方法。进入_object_get_associative_reference方法,关联对象取值就是比较简单的了就是查表,源码如下:
2._object_get_associative_reference方法:
id _object_get_associative_reference(id object, const void *key) {
// 创建空的关联对象
ObjcAssociation association{};
{
// 实例化 AssociationsManager 注意这里不是单例
AssociationsManager manager;
// 实例化 全局的关联表 AssociationsHashMap 这里是单例
AssociationsHashMap &associations(manager.get());
// iterator是个迭代器,实际上相当于找到object和对应的ObjectAssociationMap(对象关联表)
AssociationsHashMap::iterator i = associations.find((objc_object *)object);
//找到了object对应的ObjectAssociationMap(对象关联表)
if (i != associations.end()) {
// 获取ObjectAssociationMap(对象关联表)
ObjectAssociationMap &refs = i->second;
// 迭代获取key对应的数据
ObjectAssociationMap::iterator j = refs.find(key);
//找到了key对应的数据
if (j != refs.end()) {
// 获取 association
association = j->second;
// retain 新值
association.retainReturnedValue();
}
}
}
// release旧值,返回新值
return association.autoreleaseReturnedValue();
}
五、关联对象-移除流程
关联对象的移除流程分类两种情况:
- 手动调用
objc_removeAssociatedObjects方法进行移除。 - 对象销毁时,系统会自动移除关联对象。
1.objc_removeAssociatedObjects方法:
void objc_removeAssociatedObjects(id object) {
if (object && object->hasAssociatedObjects()) {
_object_remove_assocations(object, /*deallocating*/false); ///*deallocating*/对象是否正在销毁
}
}
2._object_remove_assocations源码:
// Unlike setting/getting an associated reference,
// this function is performance sensitive because of
// raw isa objects (such as OS Objects) that can't track
// whether they have associated objects.
//与设置/获取关联引用不同,此函数对性能敏感,因为原始isa对象(如OS对象)不能跟踪它们是否有关联对象。
void _object_remove_assocations(id object, bool deallocating) {
ObjectAssociationMap refs{};
{
// 实例化 AssociationsManager 注意这里不是单例
AssociationsManager manager;
// 实例化 全局的关联表 AssociationsHashMap 这里是单例
AssociationsHashMap &associations(manager.get());
// iterator是个迭代器,实际上相当于找到object和对应的ObjectAssociationMap(对象关联表)
AssociationsHashMap::iterator i = associations.find((objc_object *)object);
//找到了object对应的ObjectAssociationMap(对象关联表)
if (i != associations.end()) {
refs.swap(i->second);
// If we are not deallocating, then SYSTEM_OBJECT associations are preserved.
//如果我们没有回收,那么SYSTEM_OBJECT关联会被保留。
bool didReInsert = false;
if (!deallocating) {
for (auto &ref: refs) {
if (ref.second.policy() & OBJC_ASSOCIATION_SYSTEM_OBJECT) {
i->second.insert(ref);
didReInsert = true;
}
}
}
if (!didReInsert)
associations.erase(i);
}
}
// Associations to be released after the normal ones.
//在正常关联之后释放关联。
SmallVector<ObjcAssociation *, 4> laterRefs;
// release everything (outside of the lock).
//释放锁外的所有内容。
for (auto &i: refs) {
if (i.second.policy() & OBJC_ASSOCIATION_SYSTEM_OBJECT) {
// If we are not deallocating, then RELEASE_LATER associations don't get released.
//如果我们没有释放,那么RELEASE_LATER关联不会被释放。
if (deallocating)
laterRefs.append(&i.second);
} else {
i.second.releaseHeldValue();
}
}
for (auto *later: laterRefs) {
later->releaseHeldValue();
}
}
3.对象销毁dealloc时,销毁相关的关联对象:
调用流程:dealloc --> _objc_rootDealloc --> rootDealloc --> object_dispose --> objc_destructInstance --> _object_remove_assocations。
六、总结
总的来说,关联对象主要就是两层哈希map的处理,即存取时都是两层处理,类似于二维数组。
- 关联对象并不存储在被关联对象本身内存中,而是有一个全局统一的
AssociationsManager中 - 一个实例对象就对应一个
ObjectAssociationMap, - 而
ObjectAssociationMap中存储着多个此实例对象的关联对象的key以及ObjcAssociation, ObjcAssociation中存储着关联对象的value和policy策略- 删除的时候接收一个
object对象,然后遍历删除该对象所有的关联对象 - 设置关联对象
_object_set_associative_reference的是时候,如果传入的value为空就删除这个关联对象
文章参考:iOS底层原理20:类扩展与关联对象底层原理探索