【CityPersons】《CityPersons:A Diverse Dataset for Pedestrian Detection》

CVPR-2017
文章目录
- 1 Background and Motivation
- 2 Related Work
- 3 Advantages / Contributions
- 4 A convnet for pedestrian detection
- 5 CityPersons dataset
-
- 5.1 Bounding box annotations
- 5.2 Statistics
- 5.3 Benchmarking
- 5.4 Baseline experiments
- 6 Improve quality using CityPersons
-
- 6.1 Generalization across datasets
- 6.2 Better pre-training improves quality
- 6.3 Exploiting Cityscapes semantic labels
- 7 Conclusion(own) / Future work
1 Background and Motivation
行人检测是计算机视觉社区的一个流行的研究主题之一,general object detector 未必对行人检测是最优,作者改进 faster RCNN 以更适配行人检测任务,与此同时基于 Cityscapses 分割数据集提出 CityPersons
2 Related Work
- Convnets for pedestrian detection.
- Pedestrian datasets
- Semantic labels for pedestrian detection
3 Advantages / Contributions
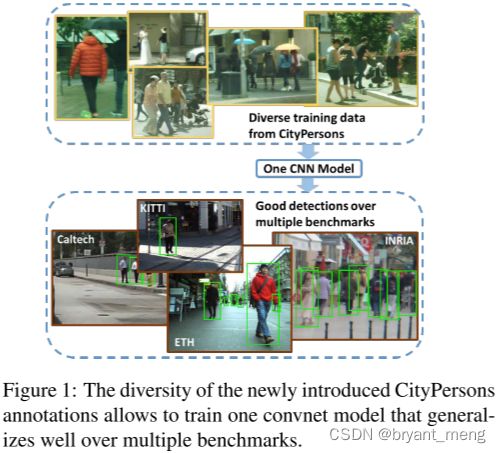
- 基于 Cityscapses 分割数据集 introduce CityPersons 行人检测数据集
- 改进 Faster RCNN,report new state-of-art results on Caltech and KITTI dataset
- 用 CityPersons 数据集训练出来的模型作为预训练模型有很好的泛化性能
- 结合 Cityscapses 的分割标签,检测性能会进一步提升
4 A convnet for pedestrian detection
1)Training, testing ( M R O MR^O MRO, M R N MR^N MRN)
log miss-rate (MR) is averaged over the FPPI (false positives per image) range of [ 1 0 − 2 , 1 0 0 ] [10^{−2}, 10^{0}] [10−2,100] FPPI.
M R O MR^O MRO 表示 original annotation
M R N MR^N MRN 表示 new annotation
2)FasterRCNN
5 个改进
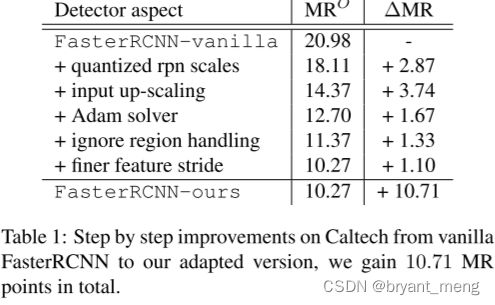
- Quantized RPN scales:split the full scale range in 10 quantile bins (equal amount of samples per bin),增加了 anchor 的 scales 个数——配合 spatial ratio,候选区域变多了
- Input up-scaling,2x
- Finer feature stride,removing the fourth max-pooling layer from VGG16 reduces the stride to 8 pixels
- Ignore region handling,training the RPN proposals avoid sampling the ignore regions
- Solver,SGD->Adam
5 CityPersons dataset
5.1 Bounding box annotations
克服分割标签转检测框时产生的问题(作者说的第二点,分割标签最小外切矩阵应该比较准吧?哈哈,也没有说矩形框的中心就是目标中心啊,水平方向何来 segment centre rather the object centre),看齐 Existing datasets (INRIA, Caltech, KITTI) 的标注格式
CityPersons 采用了 amodal bounding box 打标形式
《Amodal Instance Segmentation》2016
也即,被遮挡的区域也给你打出来

1)Fine-grained categories
4 种类型
- pedestrian (walking, running or standing up)
- rider (riding bicycles or motorbikes),
- sitting person,
- other person (with unusual postures, e.g. stretching).
2)Annotation protocol
如图 2 所示,pedestrian 和 reider 两类 amodal 模式,上顶中下两个点,宽长比 0.41,形成框,sitting person 和 other person 两类 only provide the segment bounding box
fake human 区域(people on posters, statue, mannequin, people’s reflection in mirror or window, etc.)mark them as ignore regions.
遮挡率计算如下
B B − v i s B B − f u l l \frac{BB-vis}{BB-full} BB−fullBB−vis
3)Annotation tool
pops out one person segment at a time
首先,标注 the fine-grained category
然后,do the full body annotation for pedestrians and riders
But the ignore region annotations have to be done by searching over the whole images
5.2 Statistics
1)Volume
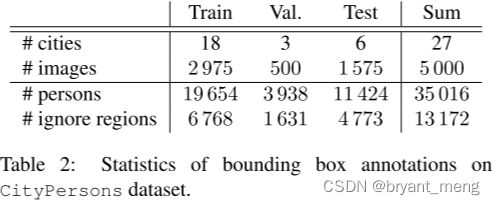
2)Diversity
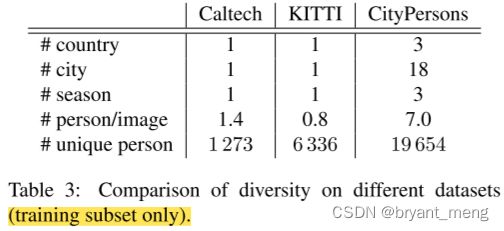
作者的数据集中 identical persons 也即 ID 也很多
provides fine-grained labels
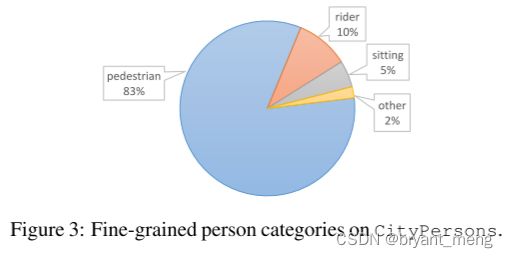
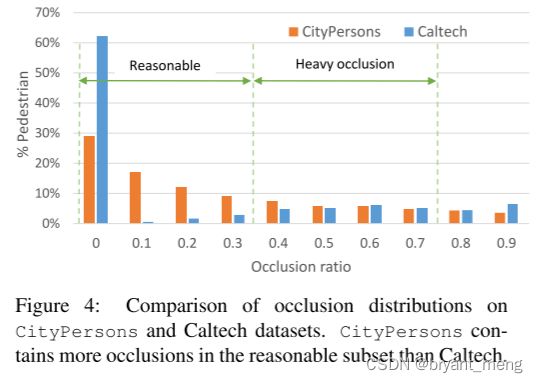
3)Occlusion
Reasonable 表示遮挡小于 35% 的样本
CityPersons has more occlusion cases
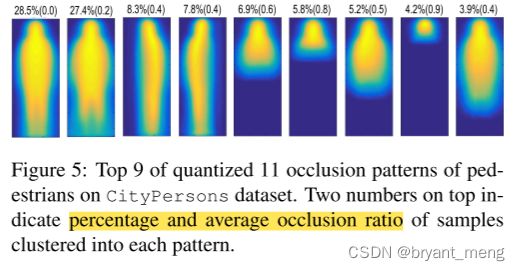
最常见的 9 种遮挡类型如下:
5.3 Benchmarking
MR stands for log-average miss rate on the “reasonable” setup (scale [50, ∞], occlusion ratio [0, 0.35]) unless otherwise specified.
cyclists/sitting persons/other persons/ignore regions are not considered
其他类都是来作秀的对吧,哈哈
5.4 Baseline experiments
only use the reasonable subset of pedestrians for training
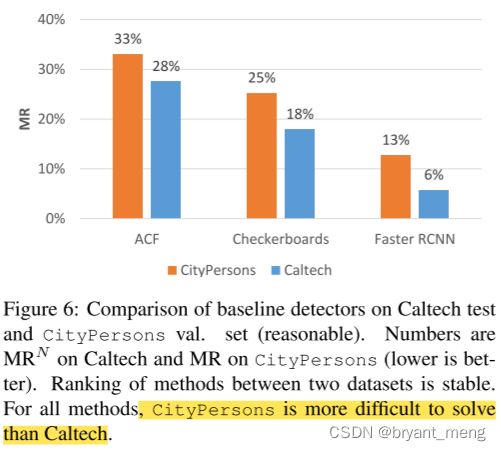
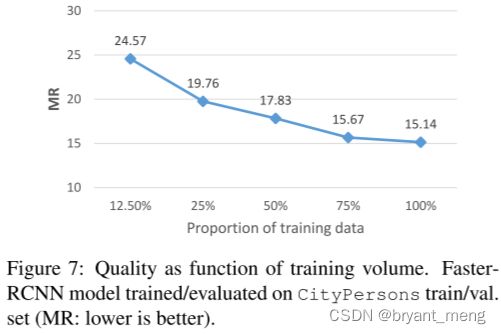
数量级和效果呈对数关系
6 Improve quality using CityPersons
6.1 Generalization across datasets

CityPersons generalizes better than Caltech and KITTI.
attribute to
-
the size and diversity of the Cityscapes data
-
the quality of the bounding boxes annotations
6.2 Better pre-training improves quality
看看 Caltech 上的效果
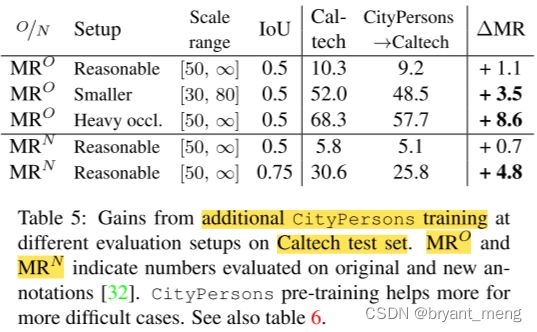
improves more for harder cases
better-aligned detections,IoU 0.5->0.75 反而 Δ M R \Delta MR ΔMR 更多
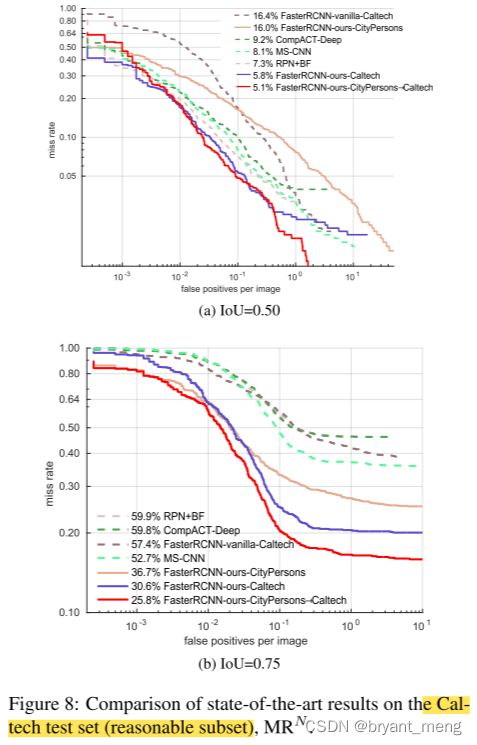
领先一手预训练,哈哈哈哈
再看看 KITTI 上的效果

6.3 Exploiting Cityscapes semantic labels

FCN-8s 训练 Cityscapes coarse annotations,用来 predict semantic map
concatenate semantic channels with RGB channels and feed them altogether into convnets
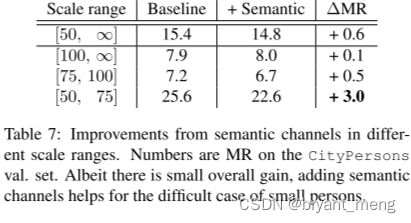
7 Conclusion(own) / Future work
- 《Pedestrian Detection: An Evaluation of the State of the Art》


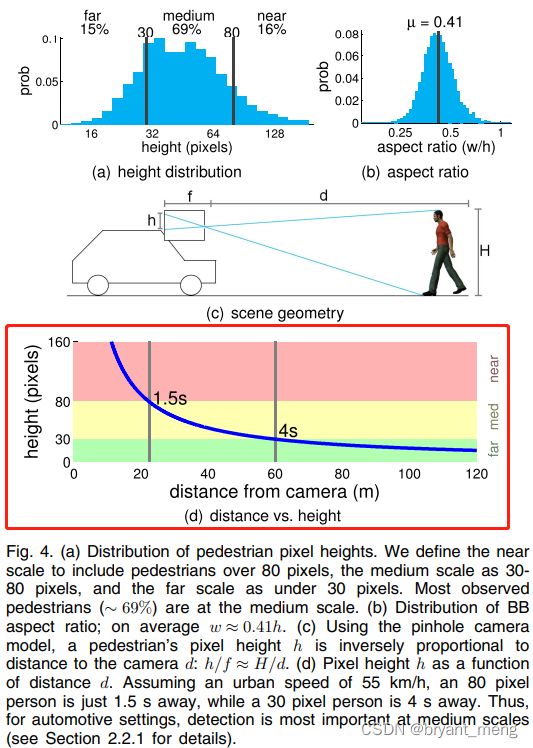
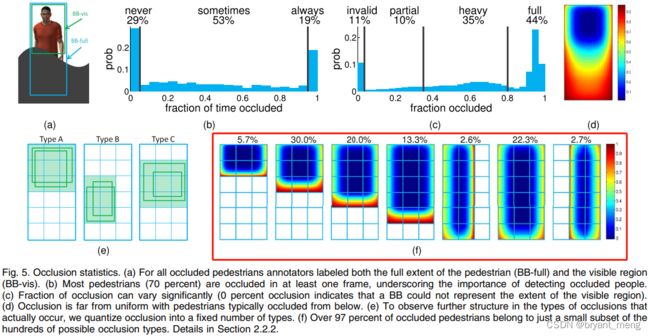
- 《Multispectral Pedestrian Detection: Benchmark Dataset and Baseline》(CVPR-2015)

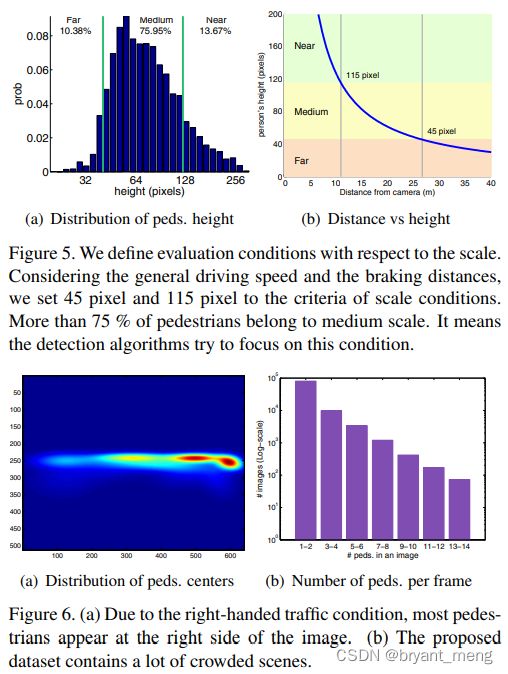
- 《Amodal Instance Segmentation》2016


