Leetcode_part1
Content
- [1. Two Sum](https://leetcode.com/problems/two-sum/)
-
- Solution 1
- Solution 2
- [递归: 17. 电话号码的字母组合](https://leetcode.com/problems/letter-combinations-of-a-phone-number/)
-
- Solution 1 暴力
- Soulution 2 回溯
- Solution 3 队列
- [18. 四数之和](https://leetcode.com/problems/4sum/)
-
- Solution 1 暴力枚举
- Solution 2 双指针法
- [19. 删除链表的倒数第 N 个结点](https://leetcode.com/problems/remove-nth-node-from-end-of-list)
-
- Solution1 计算链表长度
- Solution2 栈
- Solution3 快慢指针
- [20. 有效的括号](https://leetcode.com/problems/valid-parentheses/)
-
- Solution1 栈
- [递归:22. 括号生成](https://leetcode.com/problems/generate-parentheses/)
-
- Solution1 暴力
- Solution2 递归 + 剪枝
- [递归: 24. 两两交换链表中的节点](https://leetcode.com/problems/swap-nodes-in-pairs/)
-
- Solution1 递归
- Solution2 迭代
- [26. 删除有序数组中的重复项](https://leetcode.com/problems/remove-duplicates-from-sorted-array/)
-
- Solution1 暴力
- Solution2 双指针
- Solution3 双指针 优化
- [31. 下一个排列](https://leetcode.com/problems/next-permutation/)
-
- Solution1 暴力
- Solution2
- [二分:33. 搜索旋转排序数组](https://leetcode.com/problems/search-in-rotated-sorted-array/)
-
- Solution1 暴力
- Solution2 二分查找
- [二分:34. 在排序数组中查找元素的第一个和最后一个位置](https://leetcode.com/problems/find-first-and-last-position-of-element-in-sorted-array/)
-
- Solution1 暴力
- Solution2 二分
- [二分: 35. 搜索插入位置](https://leetcode.cn/problems/search-insert-position/)
-
- Solution1 暴力
- Solution2 二分
- [递归: 39. 组合总和](https://leetcode.com/problems/combination-sum/)
-
- Solution1 暴力
- Solution2 回溯
- [递归: 40. 组合总和 II](https://leetcode.com/problems/combination-sum-ii/)
-
- Solution1 回溯
- [递归: 46. 全排列](https://leetcode.com/problems/permutations/)
-
- Solution1 暴力
- Solution2 回溯
- [48. 旋转图像](https://leetcode.com/problems/rotate-image/)
-
- Solution1 原地查找
- Solution2 先转置再竖直对称反转
- [49. 字母异位词分组](https://leetcode.com/problems/group-anagrams/)
-
- Solution1 Map
- [动态规划:53. 最大子数组和](https://leetcode.com/problems/maximum-subarray/)
-
- Solution1 暴力
- Solution2 动态规划
- Solution3 分治
- [54. 螺旋矩阵](https://leetcode.com/problems/spiral-matrix/)
-
- Solution1 原地遍历
- Solution2 按层遍历
- [56. 合并区间](https://leetcode.com/problems/merge-intervals/)
-
- Solution1 排序
- [61. 旋转链表](https://leetcode.com/problems/rotate-list/)
-
- Solution1 暴力
- Soluion2 闭环
- [动态规划:62. 不同路径](https://leetcode.com/problems/unique-paths/)
-
- Solution1 排列组合
- Solution2 动态规划
- [动态规划:64. 最小路径和](https://leetcode.com/problems/minimum-path-sum/)
-
- Solution0 暴力
- Solution1 动态规划
- [66. 加一](https://leetcode.com/problems/plus-one/)
-
- Solution 0 暴力
- Solution 1 逆序遍历 找到9
- [二分:69. x 的平方根 ](https://leetcode.com/problems/sqrtx/)
-
- Solution1 暴力
- Solution2 二分搜索
- [动态规划:70. 爬楼梯](https://leetcode.com/problems/climbing-stairs/)
-
- Solution1 递归
- [75. 颜色分类](https://leetcode.com/problems/sort-colors/)
-
- Solution1 暴力
- Solution2 单指针
- Solution3 双指针
- [递归:78. 子集](https://leetcode.com/problems/subsets/)
-
- Solution1 回溯
- [83. 删除排序链表中的重复元素](https://leetcode.com/problems/remove-duplicates-from-sorted-list/)
-
- Solution1 一次遍历
- [86. 分隔链表](https://leetcode.com/problems/partition-list/)
-
- Solution1 双指针
- [88. 合并两个有序数组](https://leetcode.com/problems/merge-sorted-array/)
-
- Solution1 暴力直接合并后排序
- Solution2 双指针
- Solution3 逆向双指针
- [动态规划 91. 解码方法](https://leetcode.com/problems/decode-ways/)
-
- Solution1 动态规划
- Solution2 动态规划 空间复杂度优化为O(1)
- [92. 反转链表 II](https://leetcode.com/problems/reverse-linked-list-ii/)
-
- Solution1 原地反转
- [树:94. 二叉树的中序遍历](https://leetcode.com/problems/binary-tree-inorder-traversal/)
-
- Solution1 递归
- Solution2 迭代
- [树/动态规划: 96. 不同的二叉搜索树](https://leetcode.com/problems/unique-binary-search-trees/)
-
- Solution1 动态规划
- [树/递归:95. 不同的二叉搜索树 II](https://leetcode.com/problems/unique-binary-search-trees-ii/)
-
- Solution1 回溯
- [树/递归:98. 验证二叉搜索树](https://leetcode.com/problems/validate-binary-search-tree/)
-
- Solution1 递归
- Solution2 中序遍历为升序
- [树/递归:101. 对称二叉树](https://leetcode.com/problems/symmetric-tree/)
-
- Solution1 递归
- Solution2 队列
- [树:102. 二叉树的层序遍历](https://leetcode.com/problems/binary-tree-level-order-traversal/)
-
- Solution1 队列实现
- Solution2 递归实现
- [树:103. 二叉树的锯齿形层序遍历](https://leetcode.com/problems/binary-tree-zigzag-level-order-traversal/)
-
- Solution1 层序遍历
- [树:104. 二叉树的最大深度](https://leetcode.com/problems/maximum-depth-of-binary-tree/)
-
- Solution1 DFS
- Slution2 BFS
- [树:105. 从前序与中序遍历序列构造二叉树](https://leetcode.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal/)
- [118. 杨辉三角](https://leetcode.com/problems/pascals-triangle/)
-
- Solution1 直接求解
- [树:114. 二叉树展开为链表](https://leetcode.com/problems/flatten-binary-tree-to-linked-list/)
-
- Solution1 递归
- Solution2 迭代
- [递归/树:113. 路径总和 II](https://leetcode.com/problems/path-sum-ii/)
-
- Solution1 DFS
- Solution2 BFS
- [递归/树:109. 有序链表转换二叉搜索树](https://leetcode.com/problems/convert-sorted-list-to-binary-search-tree/)
-
- Solution1 先找中点 然后再左右分别构造
- [递归/树:105. 从前序与中序遍历序列构造二叉树](https://leetcode.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal/)
-
- Solution1 递归
- Solution2
- [动态规划:121. 买卖股票的最佳时机](https://leetcode.com/problems/best-time-to-buy-and-sell-stock/)
-
- Solution0 暴力解法
- Solution1 动态规划
- [动态规划:122. 买卖股票的最佳时机 II](https://leetcode.com/problems/best-time-to-buy-and-sell-stock-ii/)
-
- Solution1 贪心算法
- Solution2 动态规划
- [125. 验证回文串](https://leetcode.com/problems/valid-palindrome/)
-
- Solution1 筛选 + 判断
- Solution2 筛选 + 判断 02
- Solution03 在原字符串上直接判断
- [动态规划:139. 单词拆分](https://leetcode.com/problems/word-break/)
-
- Solution1 动态规划
- Solution2 动态规划 优化版
- [141. 环形链表](https://leetcode.com/problems/linked-list-cycle/)
-
- Solution1 哈希表
- Solution2
- [142. 环形链表 II](https://leetcode.com/problems/linked-list-cycle-ii/)
-
- Solution1 哈希表
- Solution2 双指针
- [143. 重排链表](https://leetcode.com/problems/reorder-list/)
-
- Solution0 暴力
- Solution1 双指针
- [树:144. 二叉树的前序遍历](https://leetcode.com/problems/binary-tree-preorder-traversal/)
-
- Solution1 递归
- Solution2 迭代
- [146. LRU 缓存](https://leetcode.com/problems/lru-cache/)
-
- Solution1 哈希表 + 双向链表
- [分治:148. 排序链表](https://leetcode.com/problems/sort-list/)
-
- Solution1 自顶向下归并排序
- Solution2 自底向上归并排序
- [150. 逆波兰表达式求值](https://leetcode.com/problems/evaluate-reverse-polish-notation/)
-
- Solution1 栈
- Solution2 数组模拟栈
- [动态规划:152. 乘积最大子数组](https://leetcode.com/problems/maximum-product-subarray/)
-
- Solution0 暴力
- Solution1 动态规划
- [171. Excel 表列序号](https://leetcode.com/problems/excel-sheet-column-number/)
-
- Solution1 26进制
- [155. 最小栈](https://leetcode.com/problems/min-stack/comments/)
-
- Solution1 辅助栈
- Solution2 不用辅助栈
- [160. 相交链表](https://leetcode.com/problems/intersection-of-two-linked-lists/)
-
- Solution1 哈希集合
- Solution2 双指针
- [162. 寻找峰值](https://leetcode.com/problems/find-peak-element/)
-
- Solution1 暴力
- Solution2 二分法
- [169. 多数元素](https://leetcode.com/problems/majority-element/)
-
- Solution 1 哈希表
- Solution 2 排序
- Solution 3 Boyer-Moore 投票法
- [172. 阶乘后的零](https://leetcode.com/problems/factorial-trailing-zeroes/)
-
- Solution1
- [179. 最大数](https://leetcode.com/problems/largest-number/)
-
- Solution0 暴力
- Solution1 排序
- [187. 重复的DNA序列](https://leetcode.com/problems/repeated-dna-sequences/)
-
- Solution1 哈希表
- Solution2 哈希表 滑动窗口 二进制
- [189. 轮转数组](https://leetcode.com/problems/rotate-array/)
-
- Solution1 使用额外的数组
- Solution2 数组翻转
- [动态规划:198. 打家劫舍](https://leetcode.com/problems/house-robber/)
-
- Solution1 动态规划
- Solution2 动态规划
- [树:199. 二叉树的右视图](https://leetcode.com/problems/binary-tree-right-side-view/)
-
- Solution1 层序遍历
- [递归:200. 岛屿数量](https://leetcode.com/problems/number-of-islands/)
-
- Solution1 DFS
- Solution2 BFS
- [202. 快乐数](https://leetcode.com/problems/happy-number/)
-
- Solution1 快慢指针
- Solution2 暴力
- [203. 移除链表元素](https://leetcode.com/problems/remove-linked-list-elements/)
-
- Solution1 迭代
- Solution2 递归
- [递归:206. 反转链表](https://leetcode.com/problems/reverse-linked-list/)
-
- Solution1 迭代
- Solution2 递归
- [215. 数组中的第K个最大元素](https://leetcode.com/problems/kth-largest-element-in-an-array/)
-
- Solution1 堆排序
- [217. 存在重复元素](https://leetcode.com/problems/contains-duplicate/)
-
- Solution1 排序
- Solution2
- [动态规划:221. 最大正方形](https://leetcode.com/problems/maximal-square/)
-
- Solution0 暴力法
- Solution1 动态规划
- [225. 用队列实现栈](https://leetcode.com/problems/implement-stack-using-queues/)
-
- Solution1 两个队列
- Solution2 单个队列
- [树:226. 翻转二叉树](https://leetcode.com/problems/invert-binary-tree/)
-
- Solution1
- [227. 基本计算器 II](https://leetcode.com/problems/basic-calculator-ii/)
-
- Solution1 栈
- [232. 用栈实现队列](https://leetcode.com/problems/implement-queue-using-stacks/)
-
- Solution1
- [234. 回文链表](https://leetcode.com/problems/palindrome-linked-list/)
-
- Solution0 将链表复制到数组
- Solution1 中点开始比较
- [230. 二叉搜索树中第K小的元素](https://leetcode.com/problems/kth-smallest-element-in-a-bst/)
-
- Solution1 非递归
- Solution2 记录子节点数目
- [树/递归:235. 二叉搜索树的最近公共祖先](https://leetcode.com/problems/lowest-common-ancestor-of-a-binary-search-tree/)
-
- Solution1 非递归
- Solution2 递归
- [树/递归:236. 二叉树的最近公共祖先](https://leetcode.com/problems/lowest-common-ancestor-of-a-binary-tree/)
-
- Solution1 递归
- [237. 删除链表中的节点](https://leetcode.com/problems/delete-node-in-a-linked-list/)
-
- Solution1
- [238. 除自身以外数组的乘积](https://leetcode.com/problems/product-of-array-except-self/)
-
- Solution1 累乘列表
- Solution2 空间复杂度为O(1)的方法
- [240. 搜索二维矩阵 II](https://leetcode.com/problems/search-a-2d-matrix-ii/)
-
- Solution0 暴力
- Solution1 从右上角看是一颗二叉搜索树
- [242. 有效的字母异位词](https://leetcode.com/problems/valid-anagram/)
-
- Solution1 1.直接用sort函数
- Solution2 2.map计数
- Solution3 3.效率最高
- [258. 各位相加](https://leetcode.com/problems/add-digits/)
-
- Solution1 : 找规律
- Solution2 :循环
- [268. 丢失的数字](https://leetcode.com/problems/missing-number/)
-
- Solution1 排序
- Solution2 求和
- Solution3 位运算
- Solution4 哈希
- [动态规划:279. 完全平方数](https://leetcode.com/problems/perfect-squares/)
-
- Solution1 动态规划
- Solution2 数学
- [283. 移动零](https://leetcode.com/problems/move-zeroes/)
-
- Solution1
- [二分:287. 寻找重复数](https://leetcode.com/problems/find-the-duplicate-number/)
-
- Solution1 二分法
- Solution2 二进制
- Solution3 快慢指针
- [292. Nim 游戏](https://leetcode.com/problems/nim-game/)
-
- Solution1 数学推理
- [动态规划:300. 最长递增子序列](https://leetcode.com/problems/longest-increasing-subsequence/)
-
- Solution1 动态规划
- Solution2 贪心
- [动态规划:313. 超级丑数](https://leetcode.com/problems/super-ugly-number/)
-
- Solution1 最小堆
- Solution2 动态规划
- [动态规划/递归:322. 零钱兑换](https://leetcode.com/problems/coin-change/)
-
- Solution1 动态规划
- Solution2 贪心+回溯+剪枝
- 326.3的幂
-
- Solution1 试除法
- Solution2 约数法
- [328. 奇偶链表](https://leetcode.com/problems/odd-even-linked-list/)
-
- Solution1 双链法
- [334. 递增的三元子序列](https://leetcode.com/problems/increasing-triplet-subsequence/)
-
- Solution1 贪心
- Solution2 双向遍历
- [树/动态规划: 337. 打家劫舍 III](https://leetcode.com/problems/house-robber-iii/)
-
- Solution1 动态规划
- [位运算:338. 比特位计数](https://leetcode.com/problems/counting-bits/)\
-
- Solution1
- Solution2
- Solution3
- [344. 反转字符串](https://leetcode.com/problems/reverse-string/)
-
- Solution1 双指针交换
- [堆:347. 前 K 个高频元素](https://leetcode.com/problems/top-k-frequent-elements/)
-
- Solution1 排序法
- Solution2 最小堆法
- [349. 两个数组的交集](https://leetcode.com/problems/intersection-of-two-arrays/)
-
- Solution1
- Solution2
- [371. 两整数之和](https://leetcode.com/problems/sum-of-two-integers/)
-
- Solution1 位运算
- [378. 有序矩阵中第 K 小的元素](https://leetcode.com/problems/kth-smallest-element-in-a-sorted-matrix/)
-
- Solution1 暴力
- Solution2 最小堆
- [394. 字符串解码](https://leetcode.com/problems/decode-string/)
-
- Solution1 两个栈
- [402. 移掉 K 位数字](https://leetcode.com/problems/remove-k-digits/)
-
- Solution1 贪心+单调栈
1. Two Sum
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
提示:
2 <= nums.length <= 104
-109 <= nums[i] <= 109
-109 <= target <= 109
只会存在一个有效答案
进阶:你可以想出一个时间复杂度小于 O(n2) 的算法吗?
Solution 1
双层遍历
Solution 2
哈希表
The basic idea is to maintain a hash table for each element num in nums,
using num as key and its index (0-based) as value. For each num,
search for target - num in the hash table.
If it is found and is not the same element as num, then we are done.
The code is as follows. Note that each time before we add num to mp,
we search for target - num first and so we will not hit the same element.
递归: 17. 电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
示例 1:
输入:digits = “23”
输出:[“ad”,“ae”,“af”,“bd”,“be”,“bf”,“cd”,“ce”,“cf”]
示例 2:
输入:digits = “”
输出:[]
示例 3:
输入:digits = “2”
输出:[“a”,“b”,“c”]
提示:
0 <= digits.length <= 4
digits[i] 是范围 [‘2’, ‘9’] 的一个数字。
Solution 1 暴力
Simple and efficient iterative solution.
Explanation with sample input "123"
Initial state:
result = {""}
Stage 1 for number "1":
result has {""}
candiate is "abc"
generate three strings "" + "a", ""+"b", ""+"c" and put into tmp,
tmp = {"a", "b","c"}
swap result and tmp (swap does not take memory copy)
Now result has {"a", "b", "c"}
Stage 2 for number "2":
result has {"a", "b", "c"}
candidate is "def"
generate nine strings and put into tmp,
"a" + "d", "a"+"e", "a"+"f",
"b" + "d", "b"+"e", "b"+"f",
"c" + "d", "c"+"e", "c"+"f"
so tmp has {"ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf" }
swap result and tmp
Now result has {"ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf" }
Stage 3 for number "3":
result has {"ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf" }
candidate is "ghi"
generate 27 strings and put into tmp,
add "g" for each of "ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"
add "h" for each of "ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"
add "h" for each of "ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"
so, tmp has
{"adg", "aeg", "afg", "bdg", "beg", "bfg", "cdg", "ceg", "cfg"
"adh", "aeh", "afh", "bdh", "beh", "bfh", "cdh", "ceh", "cfh"
"adi", "aei", "afi", "bdi", "bei", "bfi", "cdi", "cei", "cfi" }
swap result and tmp
Now result has
{"adg", "aeg", "afg", "bdg", "beg", "bfg", "cdg", "ceg", "cfg"
"adh", "aeh", "afh", "bdh", "beh", "bfh", "cdh", "ceh", "cfh"
"adi", "aei", "afi", "bdi", "bei", "bfi", "cdi", "cei", "cfi" }
Finally, return result.
Soulution 2 回溯


Solution 3 队列
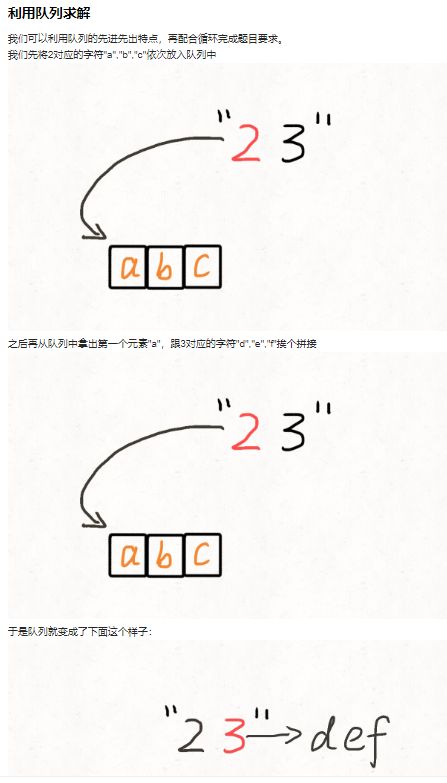


18. 四数之和
给你一个由 n 个整数组成的数组 nums ,和一个目标值 target 。请你找出并返回满足下述全部条件且不重复的四元组 [nums[a], nums[b], nums[c], nums[d]] (若两个四元组元素一一对应,则认为两个四元组重复):
0 <= a, b, c, d < n
a、b、c 和 d 互不相同
nums[a] + nums[b] + nums[c] + nums[d] == target
你可以按 任意顺序 返回答案 。
示例 1:
输入:nums = [1,0,-1,0,-2,2], target = 0
输出:[[-2,-1,1,2],[-2,0,0,2],[-1,0,0,1]]
示例 2:
输入:nums = [2,2,2,2,2], target = 8
输出:[[2,2,2,2]]
提示:
1 <= nums.length <= 200
-109 <= nums[i] <= 109
-109 <= target <= 109
Solution 1 暴力枚举
Solution 2 双指针法
The two pointers pattern requires the array to be sorted, so we do that first. Also, it's easier to deal with duplicates if the array is sorted: repeated values are next to each other and easy to skip.
For 3Sum, we enumerate each value in a single loop, and use the two pointers pattern for the rest of the array. For kSum, we will have k - 2 nested loops to enumerate all combinations of k - 2 values.




19. 删除链表的倒数第 N 个结点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
示例 2:
输入:head = [1], n = 1
输出:[]
示例 3:
输入:head = [1,2], n = 1
输出:[1]
提示:
链表中结点的数目为 sz
1 <= sz <= 30
0 <= Node.val <= 100
1 <= n <= sz

Solution1 计算链表长度

Solution2 栈


Solution3 快慢指针


20. 有效的括号
给定一个只包括 ‘(’,‘)’,‘{’,‘}’,‘[’,‘]’ 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
示例 1:
输入:s = “()”
输出:true
示例 2:
输入:s = “()[]{}”
输出:true
示例 3:
输入:s = “(]”
输出:false
示例 4:
输入:s = “([)]”
输出:false
示例 5:
输入:s = “{[]}”
输出:true
Solution1 栈
class Solution {
public:
bool isValid(string s) {
stack st; //taking stack for keep tracking the order of the brackets..
for(auto i:s) //iterate over each and every elements
{
if(i=='(' or i=='{' or i=='[') st.push(i); //if current element of the string will be opening bracket then we will just simply push it into the stack
else //if control comes to else part, it means that current element is a closing bracket, so check two conditions current element matches with top of the stack and the stack must not be empty...
{
if(st.empty() or (st.top()=='(' and i!=')') or (st.top()=='{' and i!='}') or (st.top()=='[' and i!=']')) return false;
st.pop(); //if control reaches to that line, it means we have got the right pair of brackets, so just pop it.
}
}
return st.empty(); //at last, it may possible that we left something into the stack unpair so return checking stack is empty or not..
}
};

递归:22. 括号生成
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例 1:
输入:n = 3
输出:[“((()))”,“(()())”,“(())()”,“()(())”,“()()()”]
示例 2:
输入:n = 1
输出:[“()”]
提示:
1 <= n <= 8






Solution1 暴力

Solution2 递归 + 剪枝

递归: 24. 两两交换链表中的节点
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例 1:
输入:head = [1,2,3,4]
输出:[2,1,4,3]
示例 2:
输入:head = []
输出:[]
示例 3:
输入:head = [1]
输出:[1]
Solution1 递归



Solution2 迭代


26. 删除有序数组中的重复项
给你一个 升序排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。
由于在某些语言中不能改变数组的长度,所以必须将结果放在数组nums的第一部分。更规范地说,如果在删除重复项之后有 k 个元素,那么 nums 的前 k 个元素应该保存最终结果。
将最终结果插入 nums 的前 k 个位置后返回 k 。
不要使用额外的空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
判题标准:
系统会用下面的代码来测试你的题解:
int[] nums = […]; // 输入数组
int[] expectedNums = […]; // 长度正确的期望答案
int k = removeDuplicates(nums); // 调用
assert k == expectedNums.length;
for (int i = 0; i < k; i++) {
assert nums[i] == expectedNums[i];
}
如果所有断言都通过,那么您的题解将被 通过。
示例 1:
输入:nums = [1,1,2]
输出:2, nums = [1,2,_]
解释:函数应该返回新的长度 2 ,并且原数组 nums 的前两个元素被修改为 1, 2 。不需要考虑数组中超出新长度后面的元素。
示例 2:
输入:nums = [0,0,1,1,1,2,2,3,3,4]
输出:5, nums = [0,1,2,3,4]
解释:函数应该返回新的长度 5 , 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4 。不需要考虑数组中超出新长度后面的元素。
提示:
1 <= nums.length <= 3 * 104
-104 <= nums[i] <= 104
nums 已按 升序 排列
Solution1 暴力
Solution2 双指针


Solution3 双指针 优化
31. 下一个排列
整数数组的一个 排列 就是将其所有成员以序列或线性顺序排列。
例如,arr = [1,2,3] ,以下这些都可以视作 arr 的排列:[1,2,3]、[1,3,2]、[3,1,2]、[2,3,1] 。
整数数组的 下一个排列 是指其整数的下一个字典序更大的排列。更正式地,如果数组的所有排列根据其字典顺序从小到大排列在一个容器中,那么数组的 下一个排列 就是在这个有序容器中排在它后面的那个排列。如果不存在下一个更大的排列,那么这个数组必须重排为字典序最小的排列(即,其元素按升序排列)。
例如,arr = [1,2,3] 的下一个排列是 [1,3,2] 。
类似地,arr = [2,3,1] 的下一个排列是 [3,1,2] 。
而 arr = [3,2,1] 的下一个排列是 [1,2,3] ,因为 [3,2,1] 不存在一个字典序更大的排列。
给你一个整数数组 nums ,找出 nums 的下一个排列。
必须 原地 修改,只允许使用额外常数空间。
示例 1:
输入:nums = [1,2,3]
输出:[1,3,2]
示例 2:
输入:nums = [3,2,1]
输出:[1,2,3]
示例 3:
输入:nums = [1,1,5]
输出:[1,5,1]
提示:
1 <= nums.length <= 100
0 <= nums[i] <= 100
Solution1 暴力

Solution2



二分:33. 搜索旋转排序数组
整数数组 nums 按升序排列,数组中的值 互不相同 。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k+1], …, nums[n-1], nums[0], nums[1], …, nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,5,6,7] 在下标 3 处经旋转后可能变为 [4,5,6,7,0,1,2] 。
给你 旋转后 的数组 nums 和一个整数 target ,如果 nums 中存在这个目标值 target ,则返回它的下标,否则返回 -1 。
你必须设计一个时间复杂度为 O(log n) 的算法解决此问题。
示例 1:
输入:nums = [4,5,6,7,0,1,2], target = 0
输出:4
示例 2:
输入:nums = [4,5,6,7,0,1,2], target = 3
输出:-1
示例 3:
输入:nums = [1], target = 0
输出:-1
提示:
1 <= nums.length <= 5000
-104 <= nums[i] <= 104
nums 中的每个值都 独一无二
题目数据保证 nums 在预先未知的某个下标上进行了旋转
-104 <= target <= 104
Solution1 暴力
Solution2 二分查找


二分:34. 在排序数组中查找元素的第一个和最后一个位置
给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题。
示例 1:
输入:nums = [5,7,7,8,8,10], target = 8
输出:[3,4]
示例 2:
输入:nums = [5,7,7,8,8,10], target = 6
输出:[-1,-1]
示例 3:
输入:nums = [], target = 0
输出:[-1,-1]
提示:
0 <= nums.length <= 105
-109 <= nums[i] <= 109
nums 是一个非递减数组
-109 <= target <= 109
Solution1 暴力
Solution2 二分


二分搜索讲解
https://www.bilibili.com/video/BV1fA4y1o715?spm_id_from=0.0.header_right.history_list.click
寻找target在数组里的左右边界,有如下三种情况:
- 情况一:target 在数组范围的右边或者左边,例如数组{3, 4, 5},target为2或者数组{3, 4, 5},target为6,此时应该返回{-1, -1}
- 情况二:target 在数组范围中,且数组中不存在target,例如数组{3,6,7},target为5,此时应该返回{-1, -1}
- 情况三:target 在数组范围中,且数组中存在target,例如数组{3,6,7},target为6,此时应该返回{1, 1}
class Solution {
public:
vector searchRange(vector& nums, int target) {
int leftBorder = getLeftBorder(nums, target);
int rightBorder = getRightBorder(nums, target);
// 情况一
if (leftBorder == -2 || rightBorder == -2) return {-1, -1};
// 情况三
if (rightBorder - leftBorder > 1) return {leftBorder + 1, rightBorder - 1};
// 情况二
return {-1, -1};
}
private:
int getRightBorder(vector& nums, int target) {
int left = 0;
int right = nums.size() - 1;
int rightBorder = -2; // 记录一下rightBorder没有被赋值的情况
while (left <= right) {
int middle = left + ((right - left) / 2);
if (nums[middle] > target) {
right = middle - 1;
} else { // 寻找右边界,nums[middle] == target的时候更新left
left = middle + 1;
rightBorder = left;
}
}
return rightBorder;
}
int getLeftBorder(vector& nums, int target) {
int left = 0;
int right = nums.size() - 1;
int leftBorder = -2; // 记录一下leftBorder没有被赋值的情况
while (left <= right) {
int middle = left + ((right - left) / 2);
if (nums[middle] >= target) { // 寻找左边界,nums[middle] == target的时候更新right
right = middle - 1;
leftBorder = right;
} else {
left = middle + 1;
}
}
return leftBorder;
}
};
二分: 35. 搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为 O(log n) 的算法。
示例 1:
输入: nums = [1,3,5,6], target = 5
输出: 2
示例 2:
输入: nums = [1,3,5,6], target = 2
输出: 1
示例 3:
输入: nums = [1,3,5,6], target = 7
输出: 4
Solution1 暴力
public int searchInsert(int[] nums, int target) {
for(int i = 0; i < nums.length;i++){
if(nums[i] >= target){
return i;
}
}
return nums.length;
}
Solution2 二分
class Solution {
public:
int searchInsert(vector& nums, int target) {
int n = nums.size();
int left = 0;
int right = n; // 定义target在左闭右开的区间里,[left, right) target
while (left < right) { // 因为left == right的时候,在[left, right)是无效的空间
int middle = left + ((right - left) >> 1);
if (nums[middle] > target) {
right = middle; // target 在左区间,在[left, middle)中
} else if (nums[middle] < target) {
left = middle + 1; // target 在右区间,在 [middle+1, right)中
} else { // nums[middle] == target
return middle; // 数组中找到目标值的情况,直接返回下标
}
}
// 分别处理如下四种情况
// 目标值在数组所有元素之前 [0,0)
// 目标值等于数组中某一个元素 return middle
// 目标值插入数组中的位置 [left, right) ,return right 即可
// 目标值在数组所有元素之后的情况 [left, right),这是右开区间,return right 即可
return right;
}
};
递归: 39. 组合总和
Solution1 暴力
Solution2 回溯
class Solution {
public:
void dfs(vector& candidates, int target, vector>& ans, vector& combine, int idx) {
if (idx == candidates.size()) {
return;
}
if (target == 0) {
ans.emplace_back(combine);
return;
}
// 直接跳过
dfs(candidates, target, ans, combine, idx + 1);
// 选择当前数
if (target - candidates[idx] >= 0) {
combine.emplace_back(candidates[idx]);
dfs(candidates, target - candidates[idx], ans, combine, idx);
combine.pop_back();
}
}
vector> combinationSum(vector& candidates, int target) {
vector> ans;
vector combine;
dfs(candidates, target, ans, combine, 0);
return ans;
}
};


递归: 40. 组合总和 II
Solution1 回溯
方法一:回溯
思路与算法
由于我们需要求出所有和为 \textit{target}target 的组合,并且每个数只能使用一次,因此我们可以使用递归 + 回溯的方法来解决这个问题:
我们用 \textit{dfs}(\textit{pos}, \textit{rest})dfs(pos,rest) 表示递归的函数,其中 \textit{pos}pos 表示我们当前递归到了数组 \textit{candidates}candidates 中的第 \textit{pos}pos 个数,而 \textit{rest}rest 表示我们还需要选择和为 \textit{rest}rest 的数放入列表作为一个组合;
对于当前的第 \textit{pos}pos 个数,我们有两种方法:选或者不选。如果我们选了这个数,那么我们调用 \textit{dfs}(\textit{pos} + 1, \textit{rest} - \textit{candidates}[\textit{pos}])dfs(pos+1,rest−candidates[pos]) 进行递归,注意这里必须满足 \textit{rest} \geq \textit{candidates}[\textit{pos}]rest≥candidates[pos]。如果我们不选这个数,那么我们调用 \textit{dfs}(\textit{pos} + 1, \textit{rest})dfs(pos+1,rest) 进行递归;
在某次递归开始前,如果 \textit{rest}rest 的值为 00,说明我们找到了一个和为 \textit{target}target 的组合,将其放入答案中。每次调用递归函数前,如果我们选了那个数,就需要将其放入列表的末尾,该列表中存储了我们选的所有数。在回溯时,如果我们选了那个数,就要将其从列表的末尾删除。
上述算法就是一个标准的递归 + 回溯算法,但是它并不适用于本题。这是因为题目描述中规定了解集不能包含重复的组合,而上述的算法中并没有去除重复的组合。
例如当 \textit{candidates} = [2, 2]candidates=[2,2],\textit{target} = 2target=2 时,上述算法会将列表 [2][2] 放入答案两次。
因此,我们需要改进上述算法,在求出组合的过程中就进行去重的操作。我们可以考虑将相同的数放在一起进行处理,也就是说,如果数 \textit{x}x 出现了 yy 次,那么在递归时一次性地处理它们,即分别调用选择 0, 1, \cdots, y0,1,⋯,y 次 xx 的递归函数。这样我们就不会得到重复的组合。具体地:
我们使用一个哈希映射(HashMap)统计数组 \textit{candidates}candidates 中每个数出现的次数。在统计完成之后,我们将结果放入一个列表 \textit{freq}freq 中,方便后续的递归使用。
列表 \textit{freq}freq 的长度即为数组 \textit{candidates}candidates 中不同数的个数。其中的每一项对应着哈希映射中的一个键值对,即某个数以及它出现的次数。
在递归时,对于当前的第 \textit{pos}pos 个数,它的值为 \textit{freq}[\textit{pos}][0]freq[pos][0],出现的次数为 \textit{freq}[\textit{pos}][1]freq[pos][1],那么我们可以调用
\textit{dfs}(\textit{pos} + 1, \textit{rest} - i \times \textit{freq}[\textit{pos}][0])
dfs(pos+1,rest−i×freq[pos][0])
即我们选择了这个数 ii 次。这里 ii 不能大于这个数出现的次数,并且 i \times \textit{freq}[\textit{pos}][0]i×freq[pos][0] 也不能大于 \textit{rest}rest。同时,我们需要将 ii 个 \textit{freq}[\textit{pos}][0]freq[pos][0] 放入列表中。
这样一来,我们就可以不重复地枚举所有的组合了。
我们还可以进行什么优化(剪枝)呢?一种比较常用的优化方法是,我们将 \textit{freq}freq 根据数从小到大排序,这样我们在递归时会先选择小的数,再选择大的数。这样做的好处是,当我们递归到 \textit{dfs}(\textit{pos}, \textit{rest})dfs(pos,rest) 时,如果 \textit{freq}[\textit{pos}][0]freq[pos][0] 已经大于 \textit{rest}rest,那么后面还没有递归到的数也都大于 \textit{rest}rest,这就说明不可能再选择若干个和为 \textit{rest}rest 的数放入列表了。此时,我们就可以直接回溯。
class Solution {
private:
vector> freq;
vector> ans;
vector sequence;
public:
void dfs(int pos, int rest) {
if (rest == 0) {
ans.push_back(sequence);
return;
}
if (pos == freq.size() || rest < freq[pos].first) {
return;
}
dfs(pos + 1, rest);
int most = min(rest / freq[pos].first, freq[pos].second);
for (int i = 1; i <= most; ++i) {
sequence.push_back(freq[pos].first);
dfs(pos + 1, rest - i * freq[pos].first);
}
for (int i = 1; i <= most; ++i) {
sequence.pop_back();
}
}
vector> combinationSum2(vector& candidates, int target) {
sort(candidates.begin(), candidates.end());
for (int num: candidates) {
if (freq.empty() || num != freq.back().first) {
freq.emplace_back(num, 1);
} else {
++freq.back().second;
}
}
dfs(0, target);
return ans;
}
};






递归: 46. 全排列
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
示例 2:
输入:nums = [0,1]
输出:[[0,1],[1,0]]
示例 3:
输入:nums = [1]
输出:[[1]]
Solution1 暴力
Solution2 回溯

class Solution {
public:
void backtrack(vector>& res, vector& output, int first, int len){
// 所有数都填完了
if (first == len) {
res.emplace_back(output);
return;
}
for (int i = first; i < len; ++i) {
// 动态维护数组
swap(output[i], output[first]);
// 继续递归填下一个数
backtrack(res, output, first + 1, len);
// 撤销操作
swap(output[i], output[first]);
}
}
vector> permute(vector& nums) {
vector > res;
backtrack(res, nums, 0, (int)nums.size());
return res;
}
};
48. 旋转图像
给定一个 n × n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。
你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。
示例 1:
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[[7,4,1],[8,5,2],[9,6,3]]
示例 2:
输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]]
输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]]
提示:
n == matrix.length == matrix[i].length
1 <= n <= 20
-1000 <= matrix[i][j] <= 1000
Solution1 原地查找

Solution2 先转置再竖直对称反转

class Solution {
public:
void rotate(vector>& matrix) {
//先转置
for(int row=0;row<=matrix.size()-1;row++){
for(int col=row;col<=matrix[0].size()-1;col++){
swap(matrix[row][col],matrix[col][row]);
}
}
//在竖直对称翻转
for(int row=0;row<=matrix.size()-1;row++){
for(int col = 0;col<=(matrix.size()-1)/2;col++){
swap(matrix[row][col],matrix[row][matrix.size()-1-col]);
}
}
}
};
49. 字母异位词分组
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的字母得到的一个新单词,所有源单词中的字母通常恰好只用一次。
示例 1:
输入: strs = [“eat”, “tea”, “tan”, “ate”, “nat”, “bat”]
输出: [[“bat”],[“nat”,“tan”],[“ate”,“eat”,“tea”]]
示例 2:
输入: strs = [“”]
输出: [[“”]]
示例 3:
输入: strs = [“a”]
输出: [[“a”]]
提示:
1 <= strs.length <= 104
0 <= strs[i].length <= 100
strs[i] 仅包含小写字母
Solution1 Map
Use an unordered_map to group the strings by their sorted counterparts. Use the sorted string as the key and all anagram strings as the value.
Moreover, since the string only contains lower-case alphabets, we can sort them using counting sort to improve the time complexity.
class Solution {
public:
vector> groupAnagrams(vector& strs) {
map>res;
//遍历
for(auto val:strs){
string tmp=val;
//以排序后的str作为key vector作为value 放进map
sort(val.begin(),val.end());
if(res.find(val)==res.end()){
vector t={tmp};
res.insert({val,t});
}else{
res[val].push_back(tmp);
}
}
//遍历输出结果
vector> result;
for(auto p:res){
result.push_back(p.second);
}
return result;
}
};
动态规划:53. 最大子数组和
给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
子数组 是数组中的一个连续部分。
示例 1:
输入:nums = [-2,1,-3,4,-1,2,1,-5,4]
输出:6
解释:连续子数组 [4,-1,2,1] 的和最大,为 6 。
示例 2:
输入:nums = [1]
输出:1
示例 3:
输入:nums = [5,4,-1,7,8]
输出:23
提示:
1 <= nums.length <= 105
-104 <= nums[i] <= 104
Solution1 暴力
Solution2 动态规划



Solution3 分治

54. 螺旋矩阵
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
示例 1:
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[1,2,3,6,9,8,7,4,5]
示例 2:
输入:matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
输出:[1,2,3,4,8,12,11,10,9,5,6,7]
提示:
m == matrix.length
n == matrix[i].length
1 <= m, n <= 10
-100 <= matrix[i][j] <= 100
spiral-matrix
Algorithm:
First we will iterate in to first row from left to right push back all the elements into a vector. After iterating, we change the top to second row (top++).
Then we will iterate from new top to bottom and push back only right most elements of each row. After iterating, we change the right to second last column (right--).
Then we will iterate in bottom row from right to left and pushback all the elements from new right to left. After iterating, we change the bottom to second last row (bottom--).
Then we will iterate from new bottom to new top and push back only left most element. After iterating, we change the left to second column (left++).
Repeat all these steps until left = right and top = bottom.
Solution1 原地遍历
class Solution {
public:
vector spiralOrder(vector>& matrix) {
vector res;
if(matrix.empty()){return res;}
int s=0,x=matrix.size()-1,z=0,y=matrix[0].size()-1;
while(true){
//在上边沿
for(int i=s,j=z;j<=y;j++){
res.push_back(matrix[i][j]);
}
if(++s>x) break;
//在右边沿
for(int i=s,j=y;i<=x;i++){
res.push_back(matrix[i][j]);
}
if(--y=z;j--){
res.push_back(matrix[i][j]);
}
if(--x=s;i--){
res.push_back(matrix[i][j]);
}
if(++z>y) break;
}
return res;
}
};
Solution2 按层遍历

class Solution {
public:
vector spiralOrder(vector>& matrix) {
if (matrix.size() == 0 || matrix[0].size() == 0) {
return {};
}
int rows = matrix.size(), columns = matrix[0].size();
vector order;
int left = 0, right = columns - 1, top = 0, bottom = rows - 1;
while (left <= right && top <= bottom) {
for (int column = left; column <= right; column++) {
order.push_back(matrix[top][column]);
}
for (int row = top + 1; row <= bottom; row++) {
order.push_back(matrix[row][right]);
}
if (left < right && top < bottom) {
for (int column = right - 1; column > left; column--) {
order.push_back(matrix[bottom][column]);
}
for (int row = bottom; row > top; row--) {
order.push_back(matrix[row][left]);
}
}
left++;
right--;
top++;
bottom--;
}
return order;
}
};
56. 合并区间
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
示例 1:
输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
输出:[[1,6],[8,10],[15,18]]
解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
输入:intervals = [[1,4],[4,5]]
输出:[[1,5]]
解释:区间 [1,4] 和 [4,5] 可被视为重叠区间。
提示:
1 <= intervals.length <= 104
intervals[i].length == 2
0 <= starti <= endi <= 104
nitially sort the array and then push the first element into the answer for speculation.
We have two condition if the first elements second part of ans array is greater than or equal to the second element first part of the
interval array.
The other condition we have to tackle is what if its not? then we push the particular element into the ans array which will be then be under speculation.
interval: [[1,3],[2,6],[8,10],[15,18]]
i
We initally push the 1st element into the ans array:
ans=[[1,3]]
j j points to the latest pushed element
Then we i is incremented.
[[1,3],[2,6],[8,10],[15,18]]
i
Now the ans[j][1]>interval[i][0] this means there is a possiblity of merging so we merger them
Remember the way we merge is to take the second element as max(ans[j][1],interval[i][1])
cuz imagine we have this
[1,7][2,4] --->merge should be ---->[1,7]
ans=[[1,6]]
then we move i forward
[[1,3],[2,6],[8,10],[15,18]]
i
Since ans[j][1]> merge(vector>& interval) {
vector> ans;
if(interval.size()==0)return ans;
sort(interval.begin(),interval.end());
ans.push_back(interval[0]);
int j=0;
for(int i=1;i=interval[i][0])
ans[j][1]=max(ans[j][1],interval[i][1]);
else
{
j++;
ans.push_back(interval[i]);
}
}
return ans;
}
Solution1 排序

复杂度分析
时间复杂度:O(n\log n)O(nlogn),其中 nn 为区间的数量。除去排序的开销,我们只需要一次线性扫描,所以主要的时间开销是排序的 O(n\log n)O(nlogn)。
空间复杂度:O(\log n)O(logn),其中 nn 为区间的数量。这里计算的是存储答案之外,使用的额外空间。O(\log n)O(logn) 即为排序所需要的空间复杂度。
class Solution {
public:
vector> merge(vector>& intervals) {
if (intervals.size() == 0) {
return {};
}
sort(intervals.begin(), intervals.end());
vector> merged;
for (int i = 0; i < intervals.size(); ++i) {
int L = intervals[i][0], R = intervals[i][1];
if (!merged.size() || merged.back()[1] < L) {
merged.push_back({L, R});
}
else {
merged.back()[1] = max(merged.back()[1], R);
}
}
return merged;
}
};
61. 旋转链表
给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置。
示例 1:
输入:head = [1,2,3,4,5], k = 2
输出:[4,5,1,2,3]
示例 2:
输入:head = [0,1,2], k = 4
输出:[2,0,1]
提示:
链表中节点的数目在范围 [0, 500] 内
-100 <= Node.val <= 100
0 <= k <= 2 * 109
There is no trick for this problem. Some people used slow/fast pointers to find the tail node but I don't see the benefit (in the sense that it doesn't reduce the pointer move op) to do so. So I just used one loop to find the length first.
class Solution {
public:
ListNode* rotateRight(ListNode* head, int k) {
if(!head) return head;
int len=1; // number of nodes
ListNode *newH, *tail;
newH=tail=head;
while(tail->next) // get the number of nodes in the list
{
tail = tail->next;
len++;
}
tail->next = head; // circle the link
if(k %= len)
{
for(auto i=0; inext; // the tail node is the (len-k)-th node (1st node is head)
}
newH = tail->next;
tail->next = NULL;
return newH;
}
};
Solution1 暴力
Soluion2 闭环

动态规划:62. 不同路径
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
示例 1:
输入:m = 3, n = 7
输出:28
示例 2:
输入:m = 3, n = 2
输出:3
解释:
从左上角开始,总共有 3 条路径可以到达右下角。
- 向右 -> 向下 -> 向下
- 向下 -> 向下 -> 向右
- 向下 -> 向右 -> 向下
示例 3:
输入:m = 7, n = 3
输出:28
示例 4:
输入:m = 3, n = 3
输出:6
提示:
1 <= m, n <= 100
题目数据保证答案小于等于 2 * 109
Since the robot can only move right and down, when it arrives at a point, it either arrives from left or above. If we use dp[i][j] for the number of unique paths to arrive at the point (i, j), then the state equation is dp[i][j] = dp[i][j - 1] + dp[i - 1][j]. Moreover, we have the base cases dp[0][j] = dp[i][0] = 1 for all valid i and j.
class Solution {
public:
int uniquePaths(int m, int n) {
vector> dp(m, vector(n, 1));
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m - 1][n - 1];
}
};
The above solution runs in O(m * n) time and costs O(m * n) space. However, you may have noticed that each time when we update dp[i][j], we only need dp[i - 1][j] (at the previous row) and dp[i][j - 1] (at the current row). So we can reduce the memory usage to just two rows (O(n)).
class Solution {
public:
int uniquePaths(int m, int n) {
vector pre(n, 1), cur(n, 1);
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
cur[j] = pre[j] + cur[j - 1];
}
swap(pre, cur);
}
return pre[n - 1];
}
};
Further inspecting the above code, pre[j] is just the cur[j] before the update. So we can further reduce the memory usage to one row.
class Solution {
public:
int uniquePaths(int m, int n) {
vector cur(n, 1);
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
cur[j] += cur[j - 1];
}
}
return cur[n - 1];
}
};
Now, you may wonder whether we can further reduce the memory usage to just O(1) space since the above code seems to use only two variables (cur[j] and cur[j - 1]). However, since the whole row cur needs to be updated for m - 1 times (the outer loop) based on old values, all of its values need to be saved and thus O(1)-space is impossible. However, if you are having a DP problem without the outer loop and just the inner one, then it will be possible.
Solution1 排列组合

Solution2 动态规划
我们令 dp[i][j] 是到达 i, j 最多路径
动态方程:dp[i][j] = dp[i-1][j] + dp[i][j-1]
注意,对于第一行 dp[0][j],或者第一列 dp[i][0],由于都是在边界,所以只能为 1
时间复杂度:O(m*n)O(m∗n)
空间复杂度:O(m * n)O(m∗n)
优化:因为我们每次只需要 dp[i-1][j],dp[i][j-1]
所以我们只要记录这两个数,直接看代码吧!
思路二:
class Solution {
public int uniquePaths(int m, int n) {
int[][] dp = new int[m][n];
for (int i = 0; i < n; i++) dp[0][i] = 1;
for (int i = 0; i < m; i++) dp[i][0] = 1;
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m - 1][n - 1];
}
}
优化1:空间复杂度 O(2n)O(2n)
class Solution {
public int uniquePaths(int m, int n) {
int[] pre = new int[n];
int[] cur = new int[n];
Arrays.fill(pre, 1);
Arrays.fill(cur,1);
for (int i = 1; i < m;i++){
for (int j = 1; j < n; j++){
cur[j] = cur[j-1] + pre[j];
}
pre = cur.clone();
}
return pre[n-1];
}
}
优化2:空间复杂度 O(n)O(n)
class Solution {
public int uniquePaths(int m, int n) {
int[] cur = new int[n];
Arrays.fill(cur,1);
for (int i = 1; i < m;i++){
for (int j = 1; j < n; j++){
cur[j] += cur[j-1] ;
}
}
return cur[n-1];
}
}
动态规划:64. 最小路径和
给定一个包含非负整数的 m x n 网格 grid ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
说明:每次只能向下或者向右移动一步。
示例 1:
输入:grid = [[1,3,1],[1,5,1],[4,2,1]]
输出:7
解释:因为路径 1→3→1→1→1 的总和最小。
示例 2:
输入:grid = [[1,2,3],[4,5,6]]
输出:12
提示:
m == grid.length
n == grid[i].length
1 <= m, n <= 200
0 <= grid[i][j] <= 100
his is a typical DP problem. Suppose the minimum path sum of arriving at point (i, j) is S[i][j], then the state equation is S[i][j] = min(S[i - 1][j], S[i][j - 1]) + grid[i][j].
Well, some boundary conditions need to be handled. The boundary conditions happen on the topmost row (S[i - 1][j] does not exist) and the leftmost column (S[i][j - 1] does not exist). Suppose grid is like [1, 1, 1, 1], then the minimum sum to arrive at each point is simply an accumulation of previous points and the result is [1, 2, 3, 4].
Now we can write down the following (unoptimized) code.
class Solution {
public:
int minPathSum(vector>& grid) {
int m = grid.size();
int n = grid[0].size();
vector > sum(m, vector(n, grid[0][0]));
for (int i = 1; i < m; i++)
sum[i][0] = sum[i - 1][0] + grid[i][0];
for (int j = 1; j < n; j++)
sum[0][j] = sum[0][j - 1] + grid[0][j];
for (int i = 1; i < m; i++)
for (int j = 1; j < n; j++)
sum[i][j] = min(sum[i - 1][j], sum[i][j - 1]) + grid[i][j];
return sum[m - 1][n - 1];
}
};
As can be seen, each time when we update sum[i][j], we only need sum[i - 1][j] (at the current column) and sum[i][j - 1] (at the left column). So we need not maintain the full m*n matrix. Maintaining two columns is enough and now we have the following code.
Solution0 暴力
Solution1 动态规划

class Solution {
public int minPathSum(int[][] grid) {
for(int i = 0; i < grid.length; i++) {
for(int j = 0; j < grid[0].length; j++) {
if(i == 0 && j == 0) continue;
else if(i == 0) grid[i][j] = grid[i][j - 1] + grid[i][j];
else if(j == 0) grid[i][j] = grid[i - 1][j] + grid[i][j];
else grid[i][j] = Math.min(grid[i - 1][j], grid[i][j - 1]) + grid[i][j];
}
}
return grid[grid.length - 1][grid[0].length - 1];
}
}
66. 加一
给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。
最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。
你可以假设除了整数 0 之外,这个整数不会以零开头。
示例 1:
输入:digits = [1,2,3]
输出:[1,2,4]
解释:输入数组表示数字 123。
示例 2:
输入:digits = [4,3,2,1]
输出:[4,3,2,2]
解释:输入数组表示数字 4321。
示例 3:
输入:digits = [0]
输出:[1]
提示:
1 <= digits.length <= 100
0 <= digits[i] <= 9
My solution is nothing special and isn't clever at all. I decided to post it since I thought the "official" solution article from leetcode was very poorly written and confused me more, even after I solved it on my own.
So, I believe my comments below should explain the idea, but I want to add that it helps to test the more obscure test cases for this problem to understand the algorithm. For example:
[9]
[9090]
class Solution {
public:
vector plusOne(vector& digits) {
int n = digits.size() - 1;
for (int i = n; i >= 0; --i) { // traverse digits from the last element (least significant)
// since we begin with the last digit, increasing that digit by one
// results in overflow. Therefore, all elements PRIOR to digits[0]
// need to be considered since there may be additional nines between
// digits[0], ... , digits[n].
if (digits[i] == 9) {
digits[i] = 0;
} else { // current digit is not 9 so we can safely increment by one
digits[i] += 1;
return digits;
}
}
// if the program runs to this point, each 9 is now a 0.
// to get a correct solution, we need to add one more element with
// a value of zero AND set digits[0] to 1 (in the most significant position)
// to account for the carry digit.
digits.push_back(0);
digits[0] = 1;
return digits;
}
};
Solution 0 暴力
Solution 1 逆序遍历 找到9

二分:69. x 的平方根
给你一个非负整数 x ,计算并返回 x 的 算术平方根 。
由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。
注意:不允许使用任何内置指数函数和算符,例如 pow(x, 0.5) 或者 x ** 0.5 。
示例 1:
输入:x = 4
输出:2
示例 2:
输入:x = 8
输出:2
解释:8 的算术平方根是 2.82842…, 由于返回类型是整数,小数部分将被舍去。
提示:
0 <= x <= 231 - 1
Time Complexity: O(logn) | due to binary search using while loop.
Space Complexity: O(1) | as only 4 variables are initialized at the beginning. Which is constant irrespective of given input.
long long s=0, e=x, ans, mid; //long long due to some of test cases overflows integer limit.
while(s<=e){
mid=(s+e)/2;
if(mid*mid==x) return mid; //if the 'mid' value ever gives the result, we simply return it.
else if(mid*midSolution1 暴力
Solution2 二分搜索

动态规划:70. 爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
示例 1:
输入:n = 2
输出:2
解释:有两种方法可以爬到楼顶。
- 1 阶 + 1 阶
- 2 阶
示例 2:
输入:n = 3
输出:3
解释:有三种方法可以爬到楼顶。
- 1 阶 + 1 阶 + 1 阶
- 1 阶 + 2 阶
- 2 阶 + 1 阶
提示:
1 <= n <= 45
The problem seems to be a dynamic programming one. Hint: the tag also suggests that!
Here are the steps to get the solution incrementally.
Base cases:
if n <= 0, then the number of ways should be zero.
if n == 1, then there is only way to climb the stair.
if n == 2, then there are two ways to climb the stairs. One solution is one step by another; the other one is two steps at one time.
The key intuition to solve the problem is that given a number of stairs n, if we know the number ways to get to the points [n-1] and [n-2] respectively, denoted as n1 and n2 , then the total ways to get to the point [n] is n1 + n2. Because from the [n-1] point, we can take one single step to reach [n]. And from the [n-2] point, we could take two steps to get there.
The solutions calculated by the above approach are complete and non-redundant. The two solution sets (n1 and n2) cover all the possible cases on how the final step is taken. And there would be NO overlapping among the final solutions constructed from these two solution sets, because they differ in the final step.
Now given the above intuition, one can construct an array where each node stores the solution for each number n. Or if we look at it closer, it is clear that this is basically a fibonacci number, with the starting numbers as 1 and 2, instead of 1 and 1.
Solution1 递归
class Solution {
public:
int climbStairs(int n) {
int dp0=1;
int dp1=1;
for(int i=2;i<=n;i++){
int tmp=dp0;
dp0=dp1;
dp1=tmp+dp1;
}
return dp1;
}
};
75. 颜色分类
给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums ,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
必须在不使用库的sort函数的情况下解决这个问题。
示例 1:
输入:nums = [2,0,2,1,1,0]
输出:[0,0,1,1,2,2]
示例 2:
输入:nums = [2,0,1]
输出:[0,1,2]
提示:
n == nums.length
1 <= n <= 300
nums[i] 为 0、1 或 2
进阶:
你可以不使用代码库中的排序函数来解决这道题吗?
你能想出一个仅使用常数空间的一趟扫描算法吗?
The solution requires the use of tracking 3 positions, the Low, Mid and High.
We assume that the mid is the "Unknown" area that we must evaluate.
If we encounter a 0, we know that it will be on the low end of the array, and if we encounter a 2, we know it will be on the high end of the array.
To achieve this in one pass without preprocessing (counting), we simply traverse the unknown will generating the low and high ends.
Take this example:
Assume our input is: 1 0 2 2 1 0 (short for simplicity).
Running the algorithm by hand would look something like:
1 0 2 2 1 0
^ ^
L H
M
Mid != 0 || 2
Mid++
1 0 2 2 1 0
^ ^ ^
L M H
Mid == 0
Swap Low and Mid
Mid++
Low++
0 1 2 2 1 0
^ ^ ^
L M H
Mid == 2
Swap High and Mid
High--
0 1 0 2 1 2
^ ^ ^
L M H
Mid == 0
Swap Low and Mid
Mid++
Low++
0 0 1 2 1 2
^ ^ ^
L M H
Mid == 2
Swap High and Mid
High--
0 0 1 1 2 2
^ ^
L M
H
Mid <= High is our exit case
Solution1 暴力
根据题目中的提示,我们可以统计出数组中 0, 1, 20,1,2 的个数,再根据它们的数量,重写整个数组。这种方法较为简单,也很容易想到,而本题解中会介绍两种基于指针进行交换的方法。
Solution2 单指针
我们可以考虑对数组进行两次遍历。在第一次遍历中,我们将数组中所有的 00 交换到数组的头部。在第二次遍历中,我们将数组中所有的 11 交换到头部的 00 之后。此时,所有的 22 都出现在数组的尾部,这样我们就完成了排序。
具体地,我们使用一个指针 \textit{ptr}ptr 表示「头部」的范围,\textit{ptr}ptr 中存储了一个整数,表示数组 \textit{nums}nums 从位置 00 到位置 \textit{ptr}-1ptr−1 都属于「头部」。\textit{ptr}ptr 的初始值为 00,表示还没有数处于「头部」。
在第一次遍历中,我们从左向右遍历整个数组,如果找到了 00,那么就需要将 00 与「头部」位置的元素进行交换,并将「头部」向后扩充一个位置。在遍历结束之后,所有的 00 都被交换到「头部」的范围,并且「头部」只包含 00。
在第二次遍历中,我们从「头部」开始,从左向右遍历整个数组,如果找到了 11,那么就需要将 11 与「头部」位置的元素进行交换,并将「头部」向后扩充一个位置。在遍历结束之后,所有的 11 都被交换到「头部」的范围,并且都在 00 之后,此时 22 只出现在「头部」之外的位置,因此排序完成。
class Solution {
public:
void sortColors(vector& nums) {
int n = nums.size();
int ptr = 0;
for (int i = 0; i < n; ++i) {
if (nums[i] == 0) {
swap(nums[i], nums[ptr]);
++ptr;
}
}
for (int i = ptr; i < n; ++i) {
if (nums[i] == 1) {
swap(nums[i], nums[ptr]);
++ptr;
}
}
}
};
Solution3 双指针

class Solution {
public:
void sortColors(vector& nums) {
int n = nums.size();
int p0 = 0, p2 = n - 1;
for (int i = 0; i <= p2; ++i) {
while (i <= p2 && nums[i] == 2) {
swap(nums[i], nums[p2]);
--p2;
}
if (nums[i] == 0) {
swap(nums[i], nums[p0]);
++p0;
}
}
}
};
递归:78. 子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
提示:
1 <= nums.length <= 10
-10 <= nums[i] <= 10
nums 中的所有元素 互不相同

Solution1 回溯
https://leetcode.com/problems/subsets/comments/1011321
https://leetcode.com/problems/subsets/solution/c-zong-jie-liao-hui-su-wen-ti-lei-xing-dai-ni-gao-/
class Solution {
private:
vector> result;
vector path;
void backtracking(vector& nums, int startIndex) {
result.push_back(path); // 收集子集,要放在终止添加的上面,否则会漏掉自己
if (startIndex >= nums.size()) { // 终止条件可以不加
return;
}
for (int i = startIndex; i < nums.size(); i++) {
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back();
}
}
public:
vector> subsets(vector& nums) {
result.clear();
path.clear();
backtracking(nums, 0);
return result;
}
};
83. 删除排序链表中的重复元素
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
示例 1:
输入:head = [1,1,2]
输出:[1,2]
示例 2:
输入:head = [1,1,2,3,3]
输出:[1,2,3]
提示:
链表中节点数目在范围 [0, 300] 内
-100 <= Node.val <= 100
题目数据保证链表已经按升序 排列
noticed that the solutions posted here are too long and complicated. They use unnecessary variables and/or checks etc.
The solution can be much more concise. Here is my solution:
class Solution {
public:
ListNode *deleteDuplicates(ListNode *head) {
ListNode* cur = head;
while (cur) {
while (cur->next && cur->val == cur->next->val)
cur->next = cur->next->next;
cur = cur->next;
}
return head;
}
};
Note about freeing memory. We need to free memory when we delete a node. But don't use delete node; construct on an interview without discussing it with the interviewer. A list node can be allocated in many different ways and we can use delete node; only if we are sure that the nodes were allocated with new TreeNode(...);.
Solution1 一次遍历
方法一:一次遍历
思路与算法
由于给定的链表是排好序的,因此重复的元素在链表中出现的位置是连续的,因此我们只需要对链表进行一次遍历,就可以删除重复的元素。
具体地,我们从指针 \textit{cur}cur 指向链表的头节点,随后开始对链表进行遍历。如果当前 \textit{cur}cur 与 \textit{cur.next}cur.next 对应的元素相同,那么我们就将 \textit{cur.next}cur.next 从链表中移除;否则说明链表中已经不存在其它与 \textit{cur}cur 对应的元素相同的节点,因此可以将 \textit{cur}cur 指向 \textit{cur.next}cur.next。
当遍历完整个链表之后,我们返回链表的头节点即可。
细节
当我们遍历到链表的最后一个节点时,\textit{cur.next}cur.next 为空节点,如果不加以判断,访问 \textit{cur.next}cur.next 对应的元素会产生运行错误。因此我们只需要遍历到链表的最后一个节点,而不需要遍历完整个链表。
复杂度分析
时间复杂度:O(n)O(n),其中 nn 是链表的长度。
空间复杂度:O(1)O(1)。
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if (!head) {
return head;
}
ListNode* cur = head;
while (cur->next) {
if (cur->val == cur->next->val) {
cur->next = cur->next->next;
}
else {
cur = cur->next;
}
}
return head;
}
};
86. 分隔链表
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
示例 1:
输入:head = [1,4,3,2,5,2], x = 3
输出:[1,2,2,4,3,5]
示例 2:
输入:head = [2,1], x = 2
输出:[1,2]
提示:
链表中节点的数目在范围 [0, 200] 内
-100 <= Node.val <= 100
-200 <= x <= 200
Approach 1: Two Pointer Approach
Intuition
We can take two pointers before and after to keep track of the two linked lists as described above. These two pointers could be used two create two separate lists and then these lists could be combined to form the desired reformed list.
Algorithm
Initialize two pointers before and after. In the implementation we have initialized these two with a dummy ListNode. This helps to reduce the number of conditional checks we would need otherwise. You can try an implementation where you don't initialize with a dummy node and see it yourself!
Dummy Node Initialization
Iterate the original linked list, using the head pointer.
If the node's value pointed by head is lesser than x, the node should be part of the before list. So we move it to before list.
Else, the node should be part of after list. So we move it to after list.
Once we are done with all the nodes in the original linked list, we would have two list before and after. The original list nodes are either part of before list or after list, depending on its value.
Note: Since we traverse the original linked list from left to right, at no point would the order of nodes change relatively in the two lists. Another important thing to note here is that we show the original linked list intact in the above diagrams. However, in the implementation, we remove the nodes from the original linked list and attach them in the before or after list. We don't utilize any additional space. We simply move the nodes from the original list around.
Now, these two lists before and after can be combined to form the reformed list.
We did a dummy node initialization at the start to make implementation easier, you don't want that to be part of the returned list, hence just move ahead one node in both the lists while combining the two list. Since both before and after have an extra node at the front.
Solution1 双指针

88. 合并两个有序数组
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
注意:最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。
示例 1:
输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
输出:[1,2,2,3,5,6]
解释:需要合并 [1,2,3] 和 [2,5,6] 。
合并结果是 [1,2,2,3,5,6] ,其中斜体加粗标注的为 nums1 中的元素。
示例 2:
输入:nums1 = [1], m = 1, nums2 = [], n = 0
输出:[1]
解释:需要合并 [1] 和 [] 。
合并结果是 [1] 。
示例 3:
输入:nums1 = [0], m = 0, nums2 = [1], n = 1
输出:[1]
解释:需要合并的数组是 [] 和 [1] 。
合并结果是 [1] 。
注意,因为 m = 0 ,所以 nums1 中没有元素。nums1 中仅存的 0 仅仅是为了确保合并结果可以顺利存放到 nums1 中。
提示:
nums1.length == m + n
nums2.length == n
0 <= m, n <= 200
1 <= m + n <= 200
-109 <= nums1[i], nums2[j] <= 109
进阶:你可以设计实现一个时间复杂度为 O(m + n) 的算法解决此问题吗?
This code relies on the simple observation that once all of the numbers from nums2 have been merged into nums1, the rest of the numbers in nums1 that were not moved are already in the correct place.
The way to think about the solution is that we will have to do a reverse sorting.
We initialize k=m+n-1 as that will be the last location of nums1.
We will keep checking for the greater element of the two arrays(i=m-1,j=n-1) and insert the values.
nums1 = [1,2,3,0,0,0], m = 3
nums2 = [2,5,6], n = 3
nums1 = [1,2,3,0,0,0]
| |
i k
nums2 = [2,5,6]
|
j
nums2[j]>nums1[i] thus nums1[k]=6
k and j are decremented.
nums1 = [1,2,3,0,0,6]
| |
i k
nums2 = [2,5,6]
|
j
nums2[j]>nums1[i] thus nums1[k]=5
k and j are decremented.
nums1 = [1,2,3,0,5,6]
| |
i k
nums2 = [2,5,6]
|
j
We keep following up this procedure and we get the desired reult.
void merge(vector& nums1, int m, vector& nums2, int n) {
int i=m-1,j=n-1,k=m+n-1;
while(i>=0&&j>=0)
{
if(nums1[i]>nums2[j])
{
nums1[k]=nums1[i];
i--;
k--;
}
else
{
nums1[k]=nums2[j];
j--;
k--;
}
}
while(i>=0)
nums1[k--]=nums1[i--];
while(j>=0)
nums1[k--]=nums2[j--];
}
Solution1 暴力直接合并后排序

Solution2 双指针

class Solution {
public:
void merge(vector& nums1, int m, vector& nums2, int n) {
int p1 = 0, p2 = 0;
int sorted[m + n];
int cur;
while (p1 < m || p2 < n) {
if (p1 == m) {
cur = nums2[p2++];
} else if (p2 == n) {
cur = nums1[p1++];
} else if (nums1[p1] < nums2[p2]) {
cur = nums1[p1++];
} else {
cur = nums2[p2++];
}
sorted[p1 + p2 - 1] = cur;
}
for (int i = 0; i != m + n; ++i) {
nums1[i] = sorted[i];
}
}
};
复杂度分析
时间复杂度:O(m+n)O(m+n)。
指针移动单调递增,最多移动 m+nm+n 次,因此时间复杂度为 O(m+n)O(m+n)。
空间复杂度:O(m+n)O(m+n)。
需要建立长度为 m+nm+n 的中间数组 \textit{sorted}sorted。
Solution3 逆向双指针

class Solution {
public:
void merge(vector& nums1, int m, vector& nums2, int n) {
int p1 = m - 1, p2 = n - 1;
int tail = m + n - 1;
int cur;
while (p1 >= 0 || p2 >= 0) {
if (p1 == -1) {
cur = nums2[p2--];
} else if (p2 == -1) {
cur = nums1[p1--];
} else if (nums1[p1] > nums2[p2]) {
cur = nums1[p1--];
} else {
cur = nums2[p2--];
}
nums1[tail--] = cur;
}
}
};
动态规划 91. 解码方法
一条包含字母 A-Z 的消息通过以下映射进行了 编码 :
‘A’ -> “1”
‘B’ -> “2”
…
‘Z’ -> “26”
要 解码 已编码的消息,所有数字必须基于上述映射的方法,反向映射回字母(可能有多种方法)。例如,“11106” 可以映射为:
“AAJF” ,将消息分组为 (1 1 10 6)
“KJF” ,将消息分组为 (11 10 6)
注意,消息不能分组为 (1 11 06) ,因为 “06” 不能映射为 “F” ,这是由于 “6” 和 “06” 在映射中并不等价。
给你一个只含数字的 非空 字符串 s ,请计算并返回 解码 方法的 总数 。
题目数据保证答案肯定是一个 32 位 的整数。
示例 1:
输入:s = “12”
输出:2
解释:它可以解码为 “AB”(1 2)或者 “L”(12)。
示例 2:
输入:s = “226”
输出:3
解释:它可以解码为 “BZ” (2 26), “VF” (22 6), 或者 “BBF” (2 2 6) 。
示例 3:
输入:s = “0”
输出:0
解释:没有字符映射到以 0 开头的数字。
含有 0 的有效映射是 ‘J’ -> “10” 和 ‘T’-> “20” 。
由于没有字符,因此没有有效的方法对此进行解码,因为所有数字都需要映射。
提示:
1 <= s.length <= 100
s 只包含数字,并且可能包含前导零。
通过次数235,094提交次数721,617


Solution1 动态规划

class Solution {
public:
int numDecodings(string s) {
if (s[0] == '0') return 0;
vector dp(s.size()+1);
dp[0]=1;dp[1]=1;
for (int i =1; i < s.size(); i++) {
if (s[i] == '0')//1.s[i]为0的情况
if (s[i - 1] == '1' || s[i - 1] == '2') //s[i - 1]等于1或2的情况
dp[i+1] = dp[i-1];//由于s[1]指第二个下标,对应为dp[2],所以dp的下标要比s大1,故为dp[i+1]
else
return 0;
else //2.s[i]不为0的情况
if (s[i - 1] == '1' || (s[i - 1] == '2' && s[i] <= '6'))//s[i-1]s[i]两位数要小于26的情况
dp[i+1] = dp[i]+dp[i-1];
else//其他情况
dp[i+1] = dp[i];
}
return dp[s.size()];
}
};
Solution2 动态规划 空间复杂度优化为O(1)

92. 反转链表 II
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left <= right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。
示例 1:
输入:head = [1,2,3,4,5], left = 2, right = 4
输出:[1,4,3,2,5]
示例 2:
输入:head = [5], left = 1, right = 1
输出:[5]
提示:
链表中节点数目为 n
1 <= n <= 500
-500 <= Node.val <= 500
1 <= left <= right <= n
进阶: 你可以使用一趟扫描完成反转吗?
Solution1 原地反转
Algorithm
We define a recursion function that will do the job of reversing a portion of the linked list.
Let's call this function recurse. The function takes in 3 parameters: m being the starting point of the reversal, n being the ending point for the reversal, and a pointer right which will start at the n^{th}n
th
node in the linked list and move backwards with the backtracking of the recursion. If this is not clear at the moment, the diagrams that follow will help.
Additionally, we have a pointer called left which starts from the m^{th}m
th
node in the linked list and moves forward. In Python, we have to take a global variable for this which get's changed with recursion. In other languages, where changes made in function calls persist, we can consider this pointer as an additional variable for the function recurse.
In a recursion call, given m, n, and right, we check if n == 1. If this is the case, we don't need to go any further.
Until we reach n = 1, we keep moving the right pointer one step forward and after doing that, we make a recursive call with the value of n decreased by 1. At the same time, we keep on moving the left pointer forward until m == 1. When we refer to a pointer being moved forward, it essentially means pointer.next.
So we backtrack as soon as n reaches 1. At that point of time, the right pointer is at the last node of the sublist we want to reverse and the left has already reached the first node of this sublist. So, we swap out the data and move the left pointer one step forward using left = left.next. We need this change to persist across the backtracking process.
From there on, every time we backtrack, the right pointer moves one step backwards. This is the simulation we've been mentioning all along. The backward movement is simulated by backtracking.
We stop the swaps when either right == left, which happens if the sublist size is odd, or, right.next == left which happens when during the backtracking process for an even sized sublist, the right pointer crosses left. We use a global boolean flag for stopping the swaps once these conditions are met.
Let's look at a series of diagrams explaining the process on a sample linked list. Hopefully, things would be clearer after this.
This is the first step in the recursion process. We have a list given to us and the left and the right pointers start off from the head of the linked list. The first step makes a recursive call with updated values of m and n i.e. their values each reduced by 1. Also, the left and the right pointers move one step forward in the linked list.
The next two steps show the movement of the left and the right pointers in the list. Notice that after the second step, the left pointer reaches it's designated spot. So, we don't move it any further. Only the right pointer progresses from here on out until it reaches node 6.
As we can see, after the step 5, both the pointers are in their designated spots in the list and we can start the backtracking process. We don't recurse further. The operation performed during the backtracking is swapping of data between the left and right nodes.
The right pointer crosses the left pointer after step 3 (backtracking) as can be seen above and by that point, we have already reversed the required portion of the linked list. We needed the output list to be [7 → 9 → 8 → 1 → 10 → 2 → 6] and that's what we have. So, we don't perform any more swaps and in the code, we can use a global boolean flag to stop the swapping after a point. We can't really break out of recursion per say.

树:94. 二叉树的中序遍历
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:
输入:root = [1,null,2,3]
输出:[1,3,2]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [1]
输出:[1]
提示:
树中节点数目在范围 [0, 100] 内
-100 <= Node.val <= 100
Solution1 递归

Solution2 迭代
class Solution {
public:
vector inorderTraversal(TreeNode* root) {
vector res;
stack stk;
while (root != nullptr || !stk.empty()) {
while (root != nullptr) {
stk.push(root);
root = root->left;
}
root = stk.top();
stk.pop();
res.push_back(root->val);
root = root->right;
}
return res;
}
};
树/动态规划: 96. 不同的二叉搜索树
给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。
示例 1:
输入:n = 3
输出:5
示例 2:
输入:n = 1
输出:1
提示:
1 <= n <= 19



Solution1 动态规划
结题思路:假设n个节点存在二叉排序树的个数是G(n),1为根节点,2为根节点,…,n为根节点,
当1为根节点时,其左子树节点个数为0,右子树节点个数为n-1,
同理当2为根节点时,其左子树节点个数为1,右子树节点为n-2,
所以可得G(n) = G(0)G(n-1)+G(1)(n-2)+…+G(n-1)*G(0)
class Solution {
public:
int numTrees(int n) {
vector dp(n + 1);
dp[0] = 1;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= i; j++) {
dp[i] += dp[j - 1] * dp[i - j];
}
}
return dp[n];
}
};
树/递归:95. 不同的二叉搜索树 II
给你一个整数 n ,请你生成并返回所有由 n 个节点组成且节点值从 1 到 n 互不相同的不同 二叉搜索树 。可以按 任意顺序 返回答案。
示例 1:
输入:n = 3
输出:[[1,null,2,null,3],[1,null,3,2],[2,1,3],[3,1,null,null,2],[3,2,null,1]]
示例 2:
输入:n = 1
输出:[[1]]
提示:
1 <= n <= 8
The basic idea is that we can construct the result of n node tree just from the result of n-1 node tree.
Here's how we do it: only 2 conditions: 1) The nth node is the new root, so newroot->left = oldroot;
2) the nth node is not root, we traverse the old tree, every time the node in the old tree has a right child, we can perform: old node->right = nth node, nth node ->left = right child; and when we reach the end of the tree, don't forget we can also add the nth node here.
One thing to notice is that every time we push a TreeNode in our result, I push the clone version of the root, and I recover what I do to the old node immediately. This is because you may use the old tree for several times.
Solution1 回溯


树/递归:98. 验证二叉搜索树
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
节点的左子树只包含 小于 当前节点的数。
节点的右子树只包含 大于 当前节点的数。
所有左子树和右子树自身必须也是二叉搜索树。
示例 1:
输入:root = [2,1,3]
输出:true
示例 2:
输入:root = [5,1,4,null,null,3,6]
输出:false
解释:根节点的值是 5 ,但是右子节点的值是 4 。
提示:
树中节点数目范围在[1, 104] 内
-231 <= Node.val <= 231 - 1
For the recursive solution, we set a lower bound and a upper bound for the tree. When we recurse on the left subtree, the upper bound becomes the value of its root. When we recurse on the right subtree, the lower bound becomes the value of its root.
Solution1 递归
方法一: 递归
思路和算法
要解决这道题首先我们要了解二叉搜索树有什么性质可以给我们利用,由题目给出的信息我们可以知道:如果该二叉树的左子树不为空,则左子树上所有节点的值均小于它的根节点的值; 若它的右子树不空,则右子树上所有节点的值均大于它的根节点的值;它的左右子树也为二叉搜索树。
这启示我们设计一个递归函数 helper(root, lower, upper) 来递归判断,函数表示考虑以 root 为根的子树,判断子树中所有节点的值是否都在 (l,r)(l,r) 的范围内(注意是开区间)。如果 root 节点的值 val 不在 (l,r)(l,r) 的范围内说明不满足条件直接返回,否则我们要继续递归调用检查它的左右子树是否满足,如果都满足才说明这是一棵二叉搜索树。
那么根据二叉搜索树的性质,在递归调用左子树时,我们需要把上界 upper 改为 root.val,即调用 helper(root.left, lower, root.val),因为左子树里所有节点的值均小于它的根节点的值。同理递归调用右子树时,我们需要把下界 lower 改为 root.val,即调用 helper(root.right, root.val, upper)。
函数递归调用的入口为 helper(root, -inf, +inf), inf 表示一个无穷大的值。
class Solution {
public:
bool helper(TreeNode* root, long long lower, long long upper) {
if (root == nullptr) {
return true;
}
if (root -> val <= lower || root -> val >= upper) {
return false;
}
return helper(root -> left, lower, root -> val) && helper(root -> right, root -> val, upper);
}
bool isValidBST(TreeNode* root) {
return helper(root, LONG_MIN, LONG_MAX);
}
};
复杂度分析
时间复杂度:O(n)O(n),其中 nn 为二叉树的节点个数。在递归调用的时候二叉树的每个节点最多被访问一次,因此时间复杂度为 O(n)O(n)。
空间复杂度:O(n)O(n),其中 nn 为二叉树的节点个数。递归函数在递归过程中需要为每一层递归函数分配栈空间,所以这里需要额外的空间且该空间取决于递归的深度,即二叉树的高度。最坏情况下二叉树为一条链,树的高度为 nn ,递归最深达到 nn 层,故最坏情况下空间复杂度为 O(n)O(n) 。
Solution2 中序遍历为升序
基于方法一中提及的性质,我们可以进一步知道二叉搜索树「中序遍历」得到的值构成的序列一定是升序的,这启示我们在中序遍历的时候实时检查当前节点的值是否大于前一个中序遍历到的节点的值即可。如果均大于说明这个序列是升序的,整棵树是二叉搜索树,否则不是,下面的代码我们使用栈来模拟中序遍历的过程。
可能有读者不知道中序遍历是什么,我们这里简单提及。中序遍历是二叉树的一种遍历方式,它先遍历左子树,再遍历根节点,最后遍历右子树。而我们二叉搜索树保证了左子树的节点的值均小于根节点的值,根节点的值均小于右子树的值,因此中序遍历以后得到的序列一定是升序序列。
class Solution {
public:
bool isValidBST(TreeNode* root) {
stack stack;
long long inorder = (long long)INT_MIN - 1;
while (!stack.empty() || root != nullptr) {
while (root != nullptr) {
stack.push(root);
root = root -> left;
}
root = stack.top();
stack.pop();
// 如果中序遍历得到的节点的值小于等于前一个 inorder,说明不是二叉搜索树
if (root -> val <= inorder) {
return false;
}
inorder = root -> val;
root = root -> right;
}
return true;
}
};
复杂度分析
时间复杂度:O(n)O(n),其中 nn 为二叉树的节点个数。二叉树的每个节点最多被访问一次,因此时间复杂度为 O(n)O(n)。
空间复杂度:O(n)O(n),其中 nn 为二叉树的节点个数。栈最多存储 nn 个节点,因此需要额外的 O(n)O(n) 的空间。
树/递归:101. 对称二叉树
给你一个二叉树的根节点 root , 检查它是否轴对称。
示例 1:
输入:root = [1,2,2,3,4,4,3]
输出:true
示例 2:
输入:root = [1,2,2,null,3,null,3]
输出:false
提示:
树中节点数目在范围 [1, 1000] 内
-100 <= Node.val <= 100
进阶:你可以运用递归和迭代两种方法解决这个问题吗?
Explanation :
class Solution {
public:
bool solve(TreeNode * r1, TreeNode * r2)
{
// See the tree diagram are r1 and r2 null ? No, so this line dont execute
if(r1 == NULL && r2 == NULL)
return true;
// Is any one of r1 or r2 null ? Or are these values different ? No. Both values are
// same so this else if wont execute either
else if(r1 == NULL || r2 == NULL || r1->val != r2->val)
return false;
// Now comes the main part, we are calling 2 seperate function calls
return solve(r1->left, r2->right) && solve(r1->right, r2->left);
// First solve() before && will execute
// r1->left is 3 and r2->right = 3
// Both values are same , they will by pass both if and else if statement
// Now again r1->left is null and r2->right is null
// So they will return true from first if condtion
// Now the scene is : we have executed first solve() before && and it has
// returned us True so expression becomes ' return true && solve() '
// Now solve after && will execute
// Similarly it will check for 4 and 4 , it will by pass if else statements
// next time both will become null, so will return true
// Thus 2nd solve() at the end will also hold true
// and we know 'true && true' is true
// so true will be returned to caller, and thus tree is mirror of itself.
// Similarly you can check for any testcase, flow of execution will remain same.
}
bool isSymmetric(TreeNode* root)
{
// Imagine a tree: 1
// 2 2
// 3 4 4 3
// We are standing on root that is 1, function begins
// and now r1 and r2 points to 2 and 2 respectively.
return solve(root->left, root->right);
}
};
Solution1 递归

class Solution {
public boolean isSymmetric(TreeNode root) {
if(root==null) {
return true;
}
//调用递归函数,比较左节点,右节点
return dfs(root.left,root.right);
}
boolean dfs(TreeNode left, TreeNode right) {
//递归的终止条件是两个节点都为空
//或者两个节点中有一个为空
//或者两个节点的值不相等
if(left==null && right==null) {
return true;
}
if(left==null || right==null) {
return false;
}
if(left.val!=right.val) {
return false;
}
//再递归的比较 左节点的左孩子 和 右节点的右孩子
//以及比较 左节点的右孩子 和 右节点的左孩子
return dfs(left.left,right.right) && dfs(left.right,right.left);
}
}
Solution2 队列
回想下递归的实现:
当两个子树的根节点相等时,就比较:
左子树的 left 和 右子树的 right,这个比较是用递归实现的。
现在我们改用队列来实现,思路如下:
首先从队列中拿出两个节点(left 和 right)比较
将 left 的 left 节点和 right 的 right 节点放入队列
将 left 的 right 节点和 right 的 left 节点放入队列
时间复杂度是 O(n)O(n),空间复杂度是 O(n)O(n)
动画演示如下:
class Solution {
public boolean isSymmetric(TreeNode root) {
if(root==null || (root.left==null && root.right==null)) {
return true;
}
//用队列保存节点
LinkedList queue = new LinkedList();
//将根节点的左右孩子放到队列中
queue.add(root.left);
queue.add(root.right);
while(queue.size()>0) {
//从队列中取出两个节点,再比较这两个节点
TreeNode left = queue.removeFirst();
TreeNode right = queue.removeFirst();
//如果两个节点都为空就继续循环,两者有一个为空就返回false
if(left==null && right==null) {
continue;
}
if(left==null || right==null) {
return false;
}
if(left.val!=right.val) {
return false;
}
//将左节点的左孩子, 右节点的右孩子放入队列
queue.add(left.left);
queue.add(right.right);
//将左节点的右孩子,右节点的左孩子放入队列
queue.add(left.right);
queue.add(right.left);
}
return true;
}
}
树:102. 二叉树的层序遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
示例 1:
输入:root = [3,9,20,null,null,15,7]
输出:[[3],[9,20],[15,7]]
示例 2:
输入:root = [1]
输出:[[1]]
示例 3:
输入:root = []
输出:[]
提示:
树中节点数目在范围 [0, 2000] 内
-1000 <= Node.val <= 1000
What is level in our binary tree? It is set of nodes, for which distance between root and these nodes are constant. And if we talk about distances, it can be a good idea to use bfs.
We put our root into queue, now we have level 0 in our queue.
On each step extract all nodes from queue and put their children to to opposite end of queue. In this way we will have full level in the end of each step and our queue will be filled with nodes from the next level.
In the end we just return result.
Complexity
Time complexity is O(n): we perform one bfs on our tree. Space complexity is also O(n), because we have answer of this size.
Code
Solution1 队列实现


class Solution {
public:
vector> levelOrder(TreeNode* root) {
vector > ret;
if (!root) {
return ret;
}
queue q;
q.push(root);
while (!q.empty()) {
int currentLevelSize = q.size();
ret.push_back(vector ());
for (int i = 1; i <= currentLevelSize; ++i) {
auto node = q.front(); q.pop();
ret.back().push_back(node->val);
if (node->left) q.push(node->left);
if (node->right) q.push(node->right);
}
}
return ret;
}
};
Solution2 递归实现
层序遍历一般来说确实是用队列实现的,但是这里很明显用递归前序遍历就能实现呀,而且复杂度O(n)。。。
要点有几个:
利用depth变量记录当前在第几层(从0开始),进入下层时depth + 1;
如果depth >= vector.size()说明这一层还没来过,这是第一次来,所以得扩容咯;
因为是前序遍历,中-左-右,对于每一层来说,左边的肯定比右边先被遍历到,实际上后序中序都是一样的。。。
代码如下:
class Solution {
public:
vector> levelOrder(TreeNode* root) {
vector> ans;
pre(root, 0, ans);
return ans;
}
void pre(TreeNode *root, int depth, vector> &ans) {
if (!root) return ;
if (depth >= ans.size())
ans.push_back(vector {});
ans[depth].push_back(root->val);
pre(root->left, depth + 1, ans);
pre(root->right, depth + 1, ans);
}
};
树:103. 二叉树的锯齿形层序遍历
给你二叉树的根节点 root ,返回其节点值的 锯齿形层序遍历 。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
示例 1:
输入:root = [3,9,20,null,null,15,7]
输出:[[3],[20,9],[15,7]]
示例 2:
输入:root = [1]
输出:[[1]]
示例 3:
输入:root = []
输出:[]
提示:
树中节点数目在范围 [0, 2000] 内
-100 <= Node.val <= 100
Assuming after traversing the 1st level, nodes in queue are {9, 20, 8}, And we are going to traverse 2nd level, which is even line and should print value from right to left [8, 20, 9].
We know there are 3 nodes in current queue, so the vector for this level in final result should be of size 3.
Then, queue [i] -> goes to -> vector[queue.size() - 1 - i]
i.e. the ith node in current queue should be placed in (queue.size() - 1 - i) position in vector for that line.
For example, for node(9), it's index in queue is 0, so its index in vector should be (3-1-0) = 2.
Solution1 层序遍历
层序遍历,然后在奇数时逆序一下
class Solution {
public:
vector> zigzagLevelOrder(TreeNode* root) {
vector > res;
if(!root) return res;
queue q;
q.push(root);
int flag = 0;
while(!q.empty())
{
vector out;
int size = q.size(); //取得每一层的长度
for(int i = 0; i < size; i++)
{
auto temp = q.front();
q.pop();
out.push_back(temp->val);
if(temp->left)
{
q.push(temp->left);
}
if(temp->right)
{
q.push(temp->right);
}
}
if(flag%2==1)
{
reverse(out.begin(),out.end());
}
res.push_back(out);
flag++;
}
return res;
}
};
树:104. 二叉树的最大深度


Solution1 DFS


Slution2 BFS

树:105. 从前序与中序遍历序列构造二叉树
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
示例 1:
输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
输出: [3,9,20,null,null,15,7]
示例 2:
输入: preorder = [-1], inorder = [-1]
输出: [-1]
提示:
1 <= preorder.length <= 3000
inorder.length == preorder.length
-3000 <= preorder[i], inorder[i] <= 3000
preorder 和 inorder 均 无重复 元素
inorder 均出现在 preorder
preorder 保证 为二叉树的前序遍历序列
inorder 保证 为二叉树的中序遍历序列
olution
You need to understand preorder and postorder traversal first, and then go ahead.
Basic idea is:
preorder[0] is the root node of the tree
preorder[x] is a root node of a sub tree
In in-order traversal
When inorder[index] is an item in the in-order traversal
inorder[0]-inorder[index-1] are on the left branch
inorder[index+1]-inorder[size()-1] are on the right branch
if there is nothing on the left, that means the left child of the node is NULL
if there is nothing on the right, that means the right child of the node is NULL
Algorithm:
Start from rootIdx 0
Find preorder[rootIdx] from inorder, let's call the index pivot
Create a new node with inorder[pivot]
Create its left child recursively
Create its right child recursively
Return the created node.
The implementation is self explanatory. Have a look :)
118. 杨辉三角
给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。
在「杨辉三角」中,每个数是它左上方和右上方的数的和。
示例 1:
输入: numRows = 5
输出: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]]
示例 2:
输入: numRows = 1
输出: [[1]]
The pascal triangle problem has a very simple and intuitive dynamic programming approach. As the definition states, every element of a row is formed by the sum of the two numbers directly above. So, we can just apply DP and use the previously stored rows of trianlge to calculate the new rows.
We can just initialize the start and end elements of each row as 1 and update only the elements between them. This will make the code simpler and avoid the need of having extra checks for edge elements of each row.
Solution1 直接求解
lass Solution {
public:
vector> generate(int numRows) {
vector> yanghui;
for (int i = 0; i < numRows; i++)
{
vector data(i + 1);
yanghui.push_back(data);
for (int j = 0; j < i; ++j)
{
if(j == 0) yanghui[i][j] = 1;
else
{
yanghui[i][j] = yanghui[i - 1][j - 1] + yanghui[i - 1][j];
}
}
yanghui[i][yanghui[i].size() - 1] = 1;
}
return yanghui;
}
};
树:114. 二叉树展开为链表
给你二叉树的根结点 root ,请你将它展开为一个单链表:
展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null 。
展开后的单链表应该与二叉树 先序遍历 顺序相同。
示例 1:
输入:root = [1,2,5,3,4,null,6]
输出:[1,null,2,null,3,null,4,null,5,null,6]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [0]
输出:[0]
提示:
树中结点数在范围 [0, 2000] 内
-100 <= Node.val <= 100

Solution1 递归
TreeNode* last = nullptr;
void flatten(TreeNode* root) {
if (root == nullptr) return;
flatten(root->right);
flatten(root->left);
root->right = last;
root->left = nullptr;
last = root;
}
Solution2 迭代
class Solution {
public:
void flatten(TreeNode* root) {
while(root){
TreeNode* p = root->left;
if(p){
while(p->right) p = p->right;
p->right = root->right;
root->right = root->left;
root->left = nullptr;
}
root = root->right;
}
}
};
递归/树:113. 路径总和 II
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
叶子节点 是指没有子节点的节点。
示例 1:
输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22
输出:[[5,4,11,2],[5,8,4,5]]
示例 2:
输入:root = [1,2,3], targetSum = 5
输出:[]
示例 3:
输入:root = [1,2], targetSum = 0
输出:[]
提示:
树中节点总数在范围 [0, 5000] 内
-1000 <= Node.val <= 1000
-1000 <= targetSum <= 1000
Idea
DFS from the root down to it's descendants:
We need to keep current path (which stores elements in the path) so far.
We need to keep the remain targetSum so far (after minus value of elements in the path).
If we already reach into leaf node
Check if targetSum == 0 then we found a valid path from root to leaf node which sum equal to targetSum, so add current path to the answer.
Else dfs on left node and on the right node.
Complexity
Time: O(N^2), where N <= 5000 is the number of elements in the binary tree.
First, we think the time complexity is O(N) because we only visit each node once.
But we forgot to calculate the cost to copy the current path when we found a valid path, which in the worst case can cost O(N^2), let see the following example for more clear.
Extra Space (without counting output as space): O(H), where H is height of the binary tree. This is the space for stack recursion or keeping path so far.
Solution1 DFS
我们可以采用深度优先搜索的方式,枚举每一条从根节点到叶子节点的路径。当我们遍历到叶子节点,且此时路径和恰为目标和时,我们就找到了一条满足条件的路径。
复杂度分析

class Solution {
public:
vector> ret;
vector path;
void dfs(TreeNode* root, int targetSum) {
if (root == nullptr) {
return;
}
path.emplace_back(root->val);
targetSum -= root->val;
if (root->left == nullptr && root->right == nullptr && targetSum == 0) {
ret.emplace_back(path);
}
dfs(root->left, targetSum);
dfs(root->right, targetSum);
path.pop_back();
}
vector> pathSum(TreeNode* root, int targetSum) {
dfs(root, targetSum);
return ret;
}
};
Solution2 BFS
方法二:广度优先搜索
思路及算法
我们也可以采用广度优先搜索的方式,遍历这棵树。当我们遍历到叶子节点,且此时路径和恰为目标和时,我们就找到了一条满足条件的路径。
为了节省空间,我们使用哈希表记录树中的每一个节点的父节点。每次找到一个满足条件的节点,我们就从该节点出发不断向父节点迭代,即可还原出从根节点到当前节点的路径。
class Solution {
public:
vector> ret;
unordered_map parent;
void getPath(TreeNode* node) {
vector tmp;
while (node != nullptr) {
tmp.emplace_back(node->val);
node = parent[node];
}
reverse(tmp.begin(), tmp.end());
ret.emplace_back(tmp);
}
vector> pathSum(TreeNode* root, int targetSum) {
if (root == nullptr) {
return ret;
}
queue que_node;
queue que_sum;
que_node.emplace(root);
que_sum.emplace(0);
while (!que_node.empty()) {
TreeNode* node = que_node.front();
que_node.pop();
int rec = que_sum.front() + node->val;
que_sum.pop();
if (node->left == nullptr && node->right == nullptr) {
if (rec == targetSum) {
getPath(node);
}
} else {
if (node->left != nullptr) {
parent[node->left] = node;
que_node.emplace(node->left);
que_sum.emplace(rec);
}
if (node->right != nullptr) {
parent[node->right] = node;
que_node.emplace(node->right);
que_sum.emplace(rec);
}
}
}
return ret;
}
};
递归/树:109. 有序链表转换二叉搜索树
给定一个单链表的头节点 head ,其中的元素 按升序排序 ,将其转换为高度平衡的二叉搜索树。
本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差不超过 1。
示例 1:
输入: head = [-10,-3,0,5,9]
输出: [0,-3,9,-10,null,5]
解释: 一个可能的答案是[0,-3,9,-10,null,5],它表示所示的高度平衡的二叉搜索树。
示例 2:
输入: head = []
输出: []
提示:
head 中的节点数在[0, 2 * 104] 范围内
-105 <= Node.val <= 105
Recursively build tree.
find midpoint by fast/slow method, use middle node as root.
build left child by first half of the list
build right child by second half of the list (head is midpoint->next)
Solution1 先找中点 然后再左右分别构造
class Solution {
public TreeNode sortedListToBST(ListNode head) {
if(head == null) return null;
else if(head.next == null) return new TreeNode(head.val);
ListNode pre = head;
ListNode p = pre.next;
ListNode q = p.next;
//找到链表的中点p
while(q!=null && q.next!=null){
pre = pre.next;
p = pre.next;
q = q.next.next;
}
//将中点左边的链表分开
pre.next = null;
TreeNode root = new TreeNode(p.val);
root.left = sortedListToBST(head);
root.right = sortedListToBST(p.next);
return root;
}
}
递归/树:105. 从前序与中序遍历序列构造二叉树
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
示例 1:
输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
输出: [3,9,20,null,null,15,7]
示例 2:
输入: preorder = [-1], inorder = [-1]
输出: [-1]
提示:
1 <= preorder.length <= 3000
inorder.length == preorder.length
-3000 <= preorder[i], inorder[i] <= 3000
preorder 和 inorder 均 无重复 元素
inorder 均出现在 preorder
preorder 保证 为二叉树的前序遍历序列
inorder 保证 为二叉树的中序遍历序列
Solution
You need to understand preorder and postorder traversal first, and then go ahead.
Basic idea is:
preorder[0] is the root node of the tree
preorder[x] is a root node of a sub tree
In in-order traversal
When inorder[index] is an item in the in-order traversal
inorder[0]-inorder[index-1] are on the left branch
inorder[index+1]-inorder[size()-1] are on the right branch
if there is nothing on the left, that means the left child of the node is NULL
if there is nothing on the right, that means the right child of the node is NULL
Algorithm:
Start from rootIdx 0
Find preorder[rootIdx] from inorder, let's call the index pivot
Create a new node with inorder[pivot]
Create its left child recursively
Create its right child recursively
Return the created node.
The implementation is self explanatory. Have a look :)
Solution1 递归
class Solution {
public:
TreeNode* buildTree(vector& preorder, vector& inorder) {
// preorder: [root, [left], [right]]
// inorder: [[left], root, [right]]
return buildTree(preorder, 0, preorder.size() - 1, inorder, 0, inorder.size() - 1);
}
TreeNode* buildTree(vector& preorder, int lo1, int hi1, vector& inorder, int lo2, int hi2) {
if (lo1 > hi1 || lo2 > hi2) return nullptr;
int root = preorder[lo1];
int mid = lo2;
// 在 inorder 中查找 root 位置
for (int i = lo2; i <= hi2; ++i) {
if (inorder[i] == root) {
mid = i;
break;
}
}
auto s = new TreeNode(root);
// 下面的数组表示分割长度
// inorder: [mid-lo2, mid, hi2-mid]
// preorder:[root, mid-lo2, hi2-mid]
s->left = buildTree(preorder, lo1+1, lo1+mid-lo2, inorder, lo2, mid-1);
s->right = buildTree(preorder, lo1+mid-lo2+1, hi1, inorder, mid+1, hi2);
return s;
}
};
Solution2
class Solution {
public:
int getLength(ListNode* head) {
int ret = 0;
for (; head != nullptr; ++ret, head = head->next);
return ret;
}
TreeNode* buildTree(ListNode*& head, int left, int right) {
if (left > right) {
return nullptr;
}
int mid = (left + right + 1) / 2;
TreeNode* root = new TreeNode();
root->left = buildTree(head, left, mid - 1);
root->val = head->val;
head = head->next;
root->right = buildTree(head, mid + 1, right);
return root;
}
TreeNode* sortedListToBST(ListNode* head) {
int length = getLength(head);
return buildTree(head, 0, length - 1);
}
};
动态规划:121. 买卖股票的最佳时机
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:
输入:[7,1,5,3,6,4]
输出:5
解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
示例 2:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 没有交易完成, 所以最大利润为 0。
提示:
1 <= prices.length <= 105
0 <= prices[i] <= 104

I hope now question, approach is absolute clear.
code each line explained : Similar for C++, Java
{
int lsf = Integer.MAX_VALUE; // least so far
int op = 0; // overall profit
int pist = 0; // profit if sold today
for(int i = 0; i < prices.length; i++){
if(prices[i] < lsf){ // if we found new buy value which is more smaller then previous one
lsf = prices[i]; // update our least so far
}
pist = prices[i] - lsf; // calculating profit if sold today by, Buy - sell
if(op < pist){ // if pist is more then our previous overall profit
op = pist; // update overall profit
}
}
return op; // return op
Solution0 暴力解法
class Solution {
public:
int maxProfit(vector& prices) {
int n = (int)prices.size(), ans = 0;
for (int i = 0; i < n; ++i){
for (int j = i + 1; j < n; ++j) {
ans = max(ans, prices[j] - prices[i]);
}
}
return ans;
}
};
Solution1 动态规划
动态规划 前i天的最大收益 = max{前i-1天的最大收益,第i天的价格-前i-1天中的最小价格}
class Solution {
public int maxProfit(int[] prices) {
if(prices.length <= 1)
return 0;
int min = prices[0], max = 0;
for(int i = 1; i < prices.length; i++) {
max = Math.max(max, prices[i] - min);
min = Math.min(min, prices[i]);
}
return max;
}
}
动态规划:122. 买卖股票的最佳时机 II
给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
返回 你能获得的 最大 利润 。
示例 1:
输入:prices = [7,1,5,3,6,4]
输出:7
解释:在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4 。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6 - 3 = 3 。
总利润为 4 + 3 = 7 。
示例 2:
输入:prices = [1,2,3,4,5]
输出:4
解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4 。
总利润为 4 。
示例 3:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 交易无法获得正利润,所以不参与交易可以获得最大利润,最大利润为 0 。
提示:
1 <= prices.length <= 3 * 104
0 <= prices[i] <= 104

Solution1 贪心算法
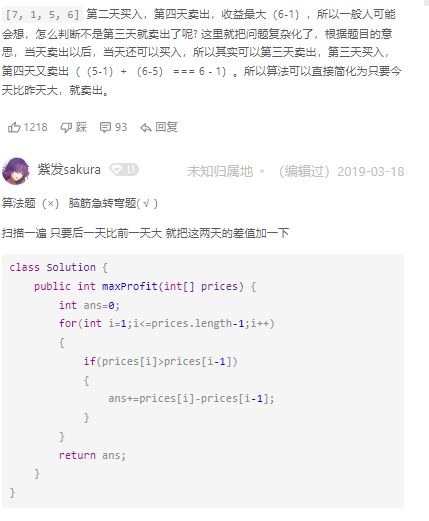
Solution2 动态规划

class Solution {
public int maxProfit(int[] prices) {
int [] dp = new int [prices.length+1];//这里从第0天开始,到底i天
dp[0] = 0;//第0天没有股票,最大利润为0
dp[1] = 0;//第一天只能买,不能买,因此最大利润也是0
for(int i = 1;iB ? A : B;//i从0开始,所以dp[I+1]是当前天数
}
return dp[prices.length];
125. 验证回文串
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个回文串。
字母和数字都属于字母数字字符。
给你一个字符串 s,如果它是回文串,返回 true ;否则,返回 false 。
示例 1:
输入: “A man, a plan, a canal: Panama”
输出:true
解释:“amanaplanacanalpanama” 是回文串。
示例 2:
输入:“race a car”
输出:false
解释:“raceacar” 不是回文串。
示例 3:
输入:s = " "
输出:true
解释:在移除非字母数字字符之后,s 是一个空字符串 “” 。
由于空字符串正着反着读都一样,所以是回文串。
提示:
1 <= s.length <= 2 * 105
s 仅由可打印的 ASCII 字符组成
bool isPalindrome(string s) {
for (int i = 0, j = s.size() - 1; i < j; i++, j--) { // Move 2 pointers from each end until they collide
while (isalnum(s[i]) == false && i < j) i++; // Increment left pointer if not alphanumeric
while (isalnum(s[j]) == false && i < j) j--; // Decrement right pointer if no alphanumeric
if (toupper(s[i]) != toupper(s[j])) return false; // Exit and return error if not match
}
return true;
}
Solution1 筛选 + 判断

Solution2 筛选 + 判断 02

Solution03 在原字符串上直接判断

动态规划:139. 单词拆分
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。
注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
输入: s = “leetcode”, wordDict = [“leet”, “code”]
输出: true
解释: 返回 true 因为 “leetcode” 可以由 “leet” 和 “code” 拼接成。
示例 2:
输入: s = “applepenapple”, wordDict = [“apple”, “pen”]
输出: true
解释: 返回 true 因为 “applepenapple” 可以由 “apple” “pen” “apple” 拼接成。
注意,你可以重复使用字典中的单词。
示例 3:
输入: s = “catsandog”, wordDict = [“cats”, “dog”, “sand”, “and”, “cat”]
输出: false
提示:
1 <= s.length <= 300
1 <= wordDict.length <= 1000
1 <= wordDict[i].length <= 20
s 和 wordDict[i] 仅有小写英文字母组成
wordDict 中的所有字符串 互不相同
We use a boolean vector dp[]. dp[i] is set to true if a valid word (word sequence) ends there. The optimization is to look from current position i back and only substring and do dictionary look up in case the preceding position j with dp[j] == true is found.
Solution1 动态规划
bool wordBreak(string s, vector& wordDict) {
vector dp(s.size()+1, false);
unordered_set m(wordDict.begin(), wordDict.end());
dp[0] = true;
for (int i = 1; i <= s.size(); ++i){
for (int j = 0; j < i; ++j){
if (dp[j] && m.find(s.substr(j, i-j)) != m.end()){
dp[i] = true;
break;
}
}
}
return dp[s.size()];
}
Solution2 动态规划 优化版
【优化】对于以上代码可以优化。每次并不需要从s[0]开始搜索。因为wordDict中的字符串长度是有限的。只需要从i-maxWordLength开始搜索就可以了
bool wordBreak(string s, vector& wordDict) {
vector dp(s.size()+1, false);
unordered_set m(wordDict.begin(), wordDict.end());
dp[0] = true;
//获取最长字符串长度
int maxWordLength = 0;
for (int i = 0; i < wordDict.size(); ++i){
maxWordLength = std::max(maxWordLength, (int)wordDict[i].size());
}
for (int i = 1; i <= s.size(); ++i){
for (int j = std::max(i-maxWordLength, 0); j < i; ++j){
if (dp[j] && m.find(s.substr(j, i-j)) != m.end()){
dp[i] = true;
break;
}
}
}
return dp[s.size()];
}
141. 环形链表
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:false
解释:链表中没有环。
提示:
链表中节点的数目范围是 [0, 104]
-105 <= Node.val <= 105
pos 为 -1 或者链表中的一个 有效索引 。
进阶:你能用 O(1)(即,常量)内存解决此问题吗?
Solution1 哈希表

Solution2



142. 环形链表 II
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:返回索引为 1 的链表节点
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
输入:head = [1,2], pos = 0
输出:返回索引为 0 的链表节点
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:返回 null
解释:链表中没有环。
提示:
链表中节点的数目范围在范围 [0, 104] 内
-105 <= Node.val <= 105
pos 的值为 -1 或者链表中的一个有效索引
Alogrithm Description:
Step 1: Determine whether there is a cycle
1.1) Using a slow pointer that move forward 1 step each time
1.2) Using a fast pointer that move forward 2 steps each time
1.3) If the slow pointer and fast pointer both point to the same location after several moving steps, there is a cycle;
1.4) Otherwise, if (fast->next == NULL || fast->next->next == NULL), there has no cycle.
Step 2: If there is a cycle, return the entry location of the cycle
2.1) L1 is defined as the distance between the head point and entry point
2.2) L2 is defined as the distance between the entry point and the meeting point
2.3) C is defined as the length of the cycle
2.4) n is defined as the travel times of the fast pointer around the cycle When the first encounter of the slow pointer and the fast pointer
According to the definition of L1, L2 and C, we can obtain:
the total distance of the slow pointer traveled when encounter is L1 + L2
the total distance of the fast pointer traveled when encounter is L1 + L2 + n * C
Because the total distance the fast pointer traveled is twice as the slow pointer, Thus:
2 * (L1+L2) = L1 + L2 + n * C => L1 + L2 = n * C => L1 = (n - 1) C + (C - L2)*
It can be concluded that the distance between the head location and entry location is equal to the distance between the meeting location and the entry location along the direction of forward movement.
So, when the slow pointer and the fast pointer encounter in the cycle, we can define a pointer "entry" that point to the head, this "entry" pointer moves one step each time so as the slow pointer. When this "entry" pointer and the slow pointer both point to the same location, this location is the node where the cycle begins.
Solution1 哈希表

Solution2 双指针

class Solution {
public:
ListNode *detectCycle(ListNode *head) {
ListNode *slow = head, *fast = head;
while (fast != nullptr) {
slow = slow->next;
if (fast->next == nullptr) {
return nullptr;
}
fast = fast->next->next;
if (fast == slow) {
ListNode *ptr = head;
while (ptr != slow) {
ptr = ptr->next;
slow = slow->next;
}
return ptr;
}
}
return nullptr;
}
};

143. 重排链表
给定一个单链表 L 的头节点 head ,单链表 L 表示为:
L0 → L1 → … → Ln - 1 → Ln
请将其重新排列后变为:
L0 → Ln → L1 → Ln - 1 → L2 → Ln - 2 → …
不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
示例 1:
输入:head = [1,2,3,4]
输出:[1,4,2,3]
示例 2:
输入:head = [1,2,3,4,5]
输出:[1,5,2,4,3]
提示:
链表的长度范围为 [1, 5 * 104]
1 <= node.val <= 1000
If you never solved singly linked lists problems before, or you do not have a lot of experience, this problem can be quite difficult. However if you already know all the tricks, it is not difficult at all. Let us first try to understand what we need to do. For list [1,2,3,4,5,6,7] we need to return [1,7,2,6,3,5,4]. We can note, that it is actually two lists [1,2,3,4] and [7,6,5], where elements are interchange. So, to succeed we need to do the following steps:
Find the middle of or list - be careful, it needs to work properly both for even and for odd number of nodes. For this we can either just count number of elements and then divide it by to, and do two traversals of list. Or we can use slow/fast iterators trick, where slow moves with speed 1 and fast moves with speed 2. Then when fast reches the end, slow will be in the middle, as we need.
Reverse the second part of linked list. Again, if you never done it before, it can be quite painful, please read oficial solution to problem 206. Reverse Linked List. The idea is to keep three pointers: prev, curr, nextt stand for previous, current and next and change connections in place. Do not forget to use slow.next = None, in opposite case you will have list with loop.
Finally, we need to merge two lists, given its heads. These heads are denoted by head and prev, so for simplisity I created head1 and head2 variables. What we need to do now is to interchange nodes: we put head2 as next element of head1 and then say that head1 is now head2 and head2 is previous head1.next. In this way we do one step for one of the lists and rename lists, so next time we will take element from head2, then rename again and so on.
Complexity: Time complexity is O(n), because we first do O(n) iterations to find middle, then we do O(n) iterations to reverse second half and finally we do O(n) iterations to merge lists. Space complexity is O(1).
Solution0 暴力
Solution1 双指针
1.快慢指针找到中点 2.拆成两个链表 3.遍历两个链表,后面的塞到前面的“缝隙里”
void reorderList(ListNode* head) {
if(head==NULL || head->next == NULL)
return;
//快慢指针分出两段
ListNode *slow = head,*fast = head;
while(fast->next && fast->next->next){
slow = slow->next;
fast = fast->next->next;
}
//后端反转
ListNode *needReverser = slow->next;
slow->next = NULL;
needReverser = reverse(needReverser);
//插入前端缝隙
ListNode *cur = head;
while(cur && needReverser){
ListNode *curSecond = needReverser;
needReverser = needReverser->next;
ListNode *nextCur = cur->next;
curSecond->next = cur->next;
cur->next = curSecond;
cur = nextCur;
}
}
ListNode *reverse(ListNode *head){
ListNode *p1 = NULL;
ListNode *p2 = head;
ListNode *p3 = p2;
while(p2){
p3 = p2->next;
p2->next = p1;
p1 = p2;
p2 = p3;
}
return p1;
}
树:144. 二叉树的前序遍历
给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
示例 1:
输入:root = [1,null,2,3]
输出:[1,2,3]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [1]
输出:[1]
示例 4:
输入:root = [1,2]
输出:[1,2]
示例 5:
输入:root = [1,null,2]
输出:[1,2]
提示:
树中节点数目在范围 [0, 100] 内
-100 <= Node.val <= 100
There are three solutions to this problem.
Iterative solution using stack --- O(n) time and O(n) space;
Recursive solution --- O(n) time and O(n) space (function call stack);
Morris traversal --- O(n) time and O(1) space.
Solution1 递归

Solution2 迭代

class Solution {
public:
vector preorderTraversal(TreeNode* root) {
vector res;
if (root == nullptr) {
return res;
}
stack stk;
TreeNode* node = root;
while (!stk.empty() || node != nullptr) {
while (node != nullptr) {
res.emplace_back(node->val);
stk.emplace(node);
node = node->left;
}
node = stk.top();
stk.pop();
node = node->right;
}
return res;
}
};
复杂度分析
时间复杂度:O(n)O(n),其中 nn 是二叉树的节点数。每一个节点恰好被遍历一次。
空间复杂度:O(n)O(n),为迭代过程中显式栈的开销,平均情况下为 O(\log n)O(logn),最坏情况下树呈现链状,为 O(n)O(n)。
146. LRU 缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存
int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入
[“LRUCache”, “put”, “put”, “get”, “put”, “get”, “put”, “get”, “get”, “get”]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
提示:
1 <= capacity <= 3000
0 <= key <= 10000
0 <= value <= 105
最多调用 2 * 105 次 get 和 put
n this question we have to keep track of the most least recently used item in the cache. I have designed the cache using list and map in C++.
We do it by following the steps below :-
When we access an item in the cache it moves to the front of the list as it is the most recently used item.
When we want to remove an item we remove it from the last of the list as it is the least recently used item in the cache.
When we insert an item we insert it into the front of the list as it is the most recently used item.
The idea is to store the keys in the map and its corrosponding values into the list...
Note : splice() function here takes the element at the m[key] and places it at the beginning of the list...
Solution1 哈希表 + 双向链表
方法一:哈希表 + 双向链表
算法
LRU 缓存机制可以通过哈希表辅以双向链表实现,我们用一个哈希表和一个双向链表维护所有在缓存中的键值对。
双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的。
哈希表即为普通的哈希映射(HashMap),通过缓存数据的键映射到其在双向链表中的位置。
这样以来,我们首先使用哈希表进行定位,找出缓存项在双向链表中的位置,随后将其移动到双向链表的头部,即可在 O(1)O(1) 的时间内完成 get 或者 put 操作。具体的方法如下:
对于 get 操作,首先判断 key 是否存在:
如果 key 不存在,则返回 -1−1;
如果 key 存在,则 key 对应的节点是最近被使用的节点。通过哈希表定位到该节点在双向链表中的位置,并将其移动到双向链表的头部,最后返回该节点的值。
对于 put 操作,首先判断 key 是否存在:
如果 key 不存在,使用 key 和 value 创建一个新的节点,在双向链表的头部添加该节点,并将 key 和该节点添加进哈希表中。然后判断双向链表的节点数是否超出容量,如果超出容量,则删除双向链表的尾部节点,并删除哈希表中对应的项;
如果 key 存在,则与 get 操作类似,先通过哈希表定位,再将对应的节点的值更新为 value,并将该节点移到双向链表的头部。
上述各项操作中,访问哈希表的时间复杂度为 O(1)O(1),在双向链表的头部添加节点、在双向链表的尾部删除节点的复杂度也为 O(1)O(1)。而将一个节点移到双向链表的头部,可以分成「删除该节点」和「在双向链表的头部添加节点」两步操作,都可以在 O(1)O(1) 时间内完成。
struct DLinkedNode {
int key, value;
DLinkedNode* prev;
DLinkedNode* next;
DLinkedNode(): key(0), value(0), prev(nullptr), next(nullptr) {}
DLinkedNode(int _key, int _value): key(_key), value(_value), prev(nullptr), next(nullptr) {}
};
class LRUCache {
private:
unordered_map cache;
DLinkedNode* head;
DLinkedNode* tail;
int size;
int capacity;
public:
LRUCache(int _capacity): capacity(_capacity), size(0) {
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head->next = tail;
tail->prev = head;
}
int get(int key) {
if (!cache.count(key)) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
DLinkedNode* node = cache[key];
moveToHead(node);
return node->value;
}
void put(int key, int value) {
if (!cache.count(key)) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode* node = new DLinkedNode(key, value);
// 添加进哈希表
cache[key] = node;
// 添加至双向链表的头部
addToHead(node);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode* removed = removeTail();
// 删除哈希表中对应的项
cache.erase(removed->key);
// 防止内存泄漏
delete removed;
--size;
}
}
else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
DLinkedNode* node = cache[key];
node->value = value;
moveToHead(node);
}
}
void addToHead(DLinkedNode* node) {
node->prev = head;
node->next = head->next;
head->next->prev = node;
head->next = node;
}
void removeNode(DLinkedNode* node) {
node->prev->next = node->next;
node->next->prev = node->prev;
}
void moveToHead(DLinkedNode* node) {
removeNode(node);
addToHead(node);
}
DLinkedNode* removeTail() {
DLinkedNode* node = tail->prev;
removeNode(node);
return node;
}
};
分治:148. 排序链表
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例 1:
输入:head = [4,2,1,3]
输出:[1,2,3,4]
示例 2:
输入:head = [-1,5,3,4,0]
输出:[-1,0,3,4,5]
示例 3:
输入:head = []
输出:[]
提示:
链表中节点的数目在范围 [0, 5 * 104] 内
-105 <= Node.val <= 105
Brief note about Question-
We have to return the linked list after sorting it in ascending order.
Let's take an example not given in question -
Suppose head of linked list given to us is like, head: [3,-9,8,67,9]
then answer should like [-9,3,8,9,67] after sorting it in ascending order.
Solution - I (Using Merge sort, Accepted)-
We want to sort a linked list, then we may able to use any of the sorting algorithm and then apply on it.
We will use merge sort here, because I find it easy to implement in linked list.
Whole implementation totally based on the merge sort, so i strongly suggest you to read a article on the merge sort.
Some basic thing that we will do in applying merge sort on our linked list are-
We divide our linked liist into two equal parts until when only one element is left.
After that we start merge them on the basis of value.
Now, if we divide them into two equal parts then then how we will find mid in linked list.
We find mid of linked list using tortise and hare method or say using fast and slow pointer.
See commented code for more explanation.
Solution1 自顶向下归并排序

class Solution {
public:
ListNode* sortList(ListNode* head) {
return sortList(head, nullptr);
}
ListNode* sortList(ListNode* head, ListNode* tail) {
if (head == nullptr) {
return head;
}
if (head->next == tail) {
head->next = nullptr;
return head;
}
ListNode* slow = head, *fast = head;
while (fast != tail) {
slow = slow->next;
fast = fast->next;
if (fast != tail) {
fast = fast->next;
}
}
ListNode* mid = slow;
return merge(sortList(head, mid), sortList(mid, tail));
}
ListNode* merge(ListNode* head1, ListNode* head2) {
ListNode* dummyHead = new ListNode(0);
ListNode* temp = dummyHead, *temp1 = head1, *temp2 = head2;
while (temp1 != nullptr && temp2 != nullptr) {
if (temp1->val <= temp2->val) {
temp->next = temp1;
temp1 = temp1->next;
} else {
temp->next = temp2;
temp2 = temp2->next;
}
temp = temp->next;
}
if (temp1 != nullptr) {
temp->next = temp1;
} else if (temp2 != nullptr) {
temp->next = temp2;
}
return dummyHead->next;
}
};
Solution2 自底向上归并排序

class Solution {
public:
ListNode* sortList(ListNode* head) {
if (head == nullptr) {
return head;
}
int length = 0;
ListNode* node = head;
while (node != nullptr) {
length++;
node = node->next;
}
ListNode* dummyHead = new ListNode(0, head);
for (int subLength = 1; subLength < length; subLength <<= 1) {
ListNode* prev = dummyHead, *curr = dummyHead->next;
while (curr != nullptr) {
ListNode* head1 = curr;
for (int i = 1; i < subLength && curr->next != nullptr; i++) {
curr = curr->next;
}
ListNode* head2 = curr->next;
curr->next = nullptr;
curr = head2;
for (int i = 1; i < subLength && curr != nullptr && curr->next != nullptr; i++) {
curr = curr->next;
}
ListNode* next = nullptr;
if (curr != nullptr) {
next = curr->next;
curr->next = nullptr;
}
ListNode* merged = merge(head1, head2);
prev->next = merged;
while (prev->next != nullptr) {
prev = prev->next;
}
curr = next;
}
}
return dummyHead->next;
}
ListNode* merge(ListNode* head1, ListNode* head2) {
ListNode* dummyHead = new ListNode(0);
ListNode* temp = dummyHead, *temp1 = head1, *temp2 = head2;
while (temp1 != nullptr && temp2 != nullptr) {
if (temp1->val <= temp2->val) {
temp->next = temp1;
temp1 = temp1->next;
} else {
temp->next = temp2;
temp2 = temp2->next;
}
temp = temp->next;
}
if (temp1 != nullptr) {
temp->next = temp1;
} else if (temp2 != nullptr) {
temp->next = temp2;
}
return dummyHead->next;
}
};
150. 逆波兰表达式求值
根据 逆波兰表示法,求表达式的值。
有效的算符包括 +、-、*、/ 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
注意 两个整数之间的除法只保留整数部分。
可以保证给定的逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。
示例 1:
输入:tokens = [“2”,“1”,“+”,“3”,“*”]
输出:9
解释:该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9
示例 2:
输入:tokens = [“4”,“13”,“5”,“/”,“+”]
输出:6
解释:该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6
示例 3:
输入:tokens = [“10”,“6”,“9”,“3”,“+”,“-11”,““,”/“,””,“17”,“+”,“5”,“+”]
输出:22
解释:该算式转化为常见的中缀算术表达式为:
((10 * (6 / ((9 + 3) * -11))) + 17) + 5
= ((10 * (6 / (12 * -11))) + 17) + 5
= ((10 * (6 / -132)) + 17) + 5
= ((10 * 0) + 17) + 5
= (0 + 17) + 5
= 17 + 5
= 22
提示:
1 <= tokens.length <= 104
tokens[i] 是一个算符(“+”、“-”、“*” 或 “/”),或是在范围 [-200, 200] 内的一个整数
逆波兰表达式:
逆波兰表达式是一种后缀表达式,所谓后缀就是指算符写在后面。
平常使用的算式则是一种中缀表达式,如 ( 1 + 2 ) * ( 3 + 4 ) 。
该算式的逆波兰表达式写法为 ( ( 1 2 + ) ( 3 4 + ) * ) 。
逆波兰表达式主要有以下两个优点:
去掉括号后表达式无歧义,上式即便写成 1 2 + 3 4 + * 也可以依据次序计算出正确结果。
适合用栈操作运算:遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中
Idea:
Reverse Polish Notation was designed specifically to make computing easier with the more efficient use of a stack. So we can use a stack here to store numbers until they're used, and then each operand will use the top two values of the stack.
Since the order of the numbers is still important for subtraction and division, we'll have to make sure that the two numbers are processed in their original order, which is the opposite order of the stack.
After each successful operation, the result should be pushed back onto the stack until it's used. After iteration is complete, the remaining value in the stack will be our answer, so we should return stack[0].
Time Complexity: O(N) where N is the length of tokens
Space Complexity: O(N) for the length of the stack, up to N / 2 + 1 values
Solution1 栈

class Solution {
public:
int evalRPN(vector& tokens) {
stack stk;
int n = tokens.size();
for (int i = 0; i < n; i++) {
string& token = tokens[i];
if (isNumber(token)) {
stk.push(atoi(token.c_str()));
} else {
int num2 = stk.top();
stk.pop();
int num1 = stk.top();
stk.pop();
switch (token[0]) {
case '+':
stk.push(num1 + num2);
break;
case '-':
stk.push(num1 - num2);
break;
case '*':
stk.push(num1 * num2);
break;
case '/':
stk.push(num1 / num2);
break;
}
}
}
return stk.top();
}
bool isNumber(string& token) {
return !(token == "+" || token == "-" || token == "*" || token == "/");
}
};
复杂度分析
时间复杂度:O(n)O(n),其中 nn 是数组 \textit{tokens}tokens 的长度。需要遍历数组 \textit{tokens}tokens 一次,计算逆波兰表达式的值。
空间复杂度:O(n)O(n),其中 nn 是数组 \textit{tokens}tokens 的长度。使用栈存储计算过程中的数,栈内元素个数不会超过逆波兰表达式的长度。
Solution2 数组模拟栈

class Solution {
public:
int evalRPN(vector& tokens) {
int n = tokens.size();
vector stk((n + 1) / 2);
int index = -1;
for (int i = 0; i < n; i++) {
string& token = tokens[i];
if (token.length() > 1 || isdigit(token[0])) {
index++;
stk[index] = atoi(token.c_str());
} else {
switch (token[0]) {
case '+':
index--;
stk[index] += stk[index + 1];
break;
case '-':
index--;
stk[index] -= stk[index + 1];
break;
case '*':
index--;
stk[index] *= stk[index + 1];
break;
case '/':
index--;
stk[index] /= stk[index + 1];
break;
}
}
}
return stk[index];
}
};
动态规划:152. 乘积最大子数组
给你一个整数数组 nums ,请你找出数组中乘积最大的非空连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。
测试用例的答案是一个 32-位 整数。
子数组 是数组的连续子序列。
示例 1:
输入: nums = [2,3,-2,4]
输出: 6
解释: 子数组 [2,3] 有最大乘积 6。
示例 2:
输入: nums = [-2,0,-1]
输出: 0
解释: 结果不能为 2, 因为 [-2,-1] 不是子数组。
提示:
1 <= nums.length <= 2 * 104
-10 <= nums[i] <= 10
nums 的任何前缀或后缀的乘积都 保证 是一个 32-位 整数
There can be Mutliple ways to frame the solution once we get the intuition right !! So, what should the intuition be ? Let's discuss that out !
Let's consider array to have no 0s (for the moment)......
So, on what factor does the answer depends now ?? It surely depends on the count of negative numbers in the array !!
There are 2 possibilities - either the count of -ve numbers is even or odd.... --->>>
If the count is even, then obviously we would want to include all of them(in fact the whole array) to maximise the product. As multiplying an even number of -ve numbers would make the result +ve.
If the count is odd, then we would want to exclude one -ve number from our product, so that the product gets maximised. So, now the question is, which -ve number to exclude? Example ---> arr={-2,-3,-1,-4,-5} which number should be excluded ? On observing it , we should get one fact clear, that the number which is going to get ignored is either going to be the first one or the last one.
Note that, we cannot exclude a -ve number that is not the first or the last, because, if we do so, we will need to exclude all(because you are breaking the product at this point) other -ve nums following that -ve number and then that needn't result in the maximum product.
Having said all that, now the question is whether to exclude the first -ve num or the last -ve num in the array. We can only know the answer by trying both.
So, firstly we will take the product from the beginning of the array and we will include the first -ve number and will leave out the last one !!
And will do the vice-versa for checking the other scenario !!
So , in that example we would leave the first -ve number... (-2 and then total_product will be product of rest of the numbers in array) or we would leave the last number...(-5) ... And maximum of those 2 cases will be the answer !!
Now, what if array has zeroes? Well, it changes nothing much to be honest, we can consider the part on both the side of 0 as the subarrays and the maximum product that way will be the max(subarray1_ans, subarray2_ans) .... And how to mark the division point ? How do we seperate the subarrays????...
Thats pretty simple and we have done it in kadane's algo, just make the curr_ongoing_prod=1 !! And maintain one maxm_prod variable seperately ....
Example -->>> arr={-2,1,4,5,0,-3,4,6,1,-2} .... so we can consider subarray1={-2,1,4,5} and subarray2={-3,4,6,-2} and then the max_ans(subarray1,subarray2) will be our answer !!
Let's have a look on our code now ....
Solution0 暴力
Solution1 动态规划

class Solution {
public:
int maxProduct(vector& nums) {
int n = nums.size();
if(n == 0){
return 0;
} else if(n == 1) {
return nums[0];
}
int p = nums[0];
int maxP = nums[0];
int minP = nums[0];
for(int i = 1; i < n; i++) {
int t = maxP;
maxP = max(max(maxP * nums[i], nums[i]), minP *nums[i]);
minP = min(min(t * nums[i], nums[i]), minP * nums[i]);
p = max(maxP, p);
}
return p;
}
};
171. Excel 表列序号
给你一个字符串 columnTitle ,表示 Excel 表格中的列名称。返回 该列名称对应的列序号 。
例如:
A -> 1
B -> 2
C -> 3
…
Z -> 26
AA -> 27
AB -> 28
…
示例 1:
输入: columnTitle = “A”
输出: 1
示例 2:
输入: columnTitle = “AB”
输出: 28
示例 3:
输入: columnTitle = “ZY”
输出: 701
提示:
1 <= columnTitle.length <= 7
columnTitle 仅由大写英文组成
columnTitle 在范围 [“A”, “FXSHRXW”] 内
1. There are 26 letters in our alphabet and we start counting from 1, not zero.
So 'Z' is 26.
2. The rest of the combinations start from a base 26
AA --> 26*1+ 1 = 27 (A == 1)
AB --> 26*1+ 2 = 28 (B == 2)
AC -->26*1 + 3 = 29 (C == 3)
.....
So we can write like this:
result = 0
d = s[i](char) - 'A' + 1 (we used s[i] - 'A' to convert the letter to a number like it's going to be C)
result = result* 26 + d
If the given input is only one letter, it will automatically take the value s[i] - 'A' + 1 as the first result is 0.
Some More Explanation
1. For every additional digit of the string, we multiply the value of the digit by 26^n
2. here n is the number of digits it is away from the one's place.
3. This is similar to how the number 254 could be broken down as this:
(2 x 10 x 10) + (5 x 10) + (4).
4. The reason we use 26 instead of 10 is because 26 is our base.
For s = "BCM" the final solution would be (2 x 26 x 26) + (3 x 26) + (13)
We could do this process iteratively. Start at looking at the first digit "B". Add the int equivalent of "B" to the running sum and continue.
Every time we look at the following digit multiply our running sum by 26 before adding the next digit to signify we are changing places. Example below:
"B" = 2
"BC" = (2)26 + 3
"BCM" = (2(26) + 3)26 + 13
Time Complexity : O(n) one scan of string , n is number of characters in the string
CODE WITH EXPLANATION
Solution1 26进制

155. 最小栈
设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。
实现 MinStack 类:
MinStack() 初始化堆栈对象。
void push(int val) 将元素val推入堆栈。
void pop() 删除堆栈顶部的元素。
int top() 获取堆栈顶部的元素。
int getMin() 获取堆栈中的最小元素。
示例 1:
输入:
[“MinStack”,“push”,“push”,“push”,“getMin”,“pop”,“top”,“getMin”]
[[],[-2],[0],[-3],[],[],[],[]]
输出:
[null,null,null,null,-3,null,0,-2]
解释:
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.getMin(); --> 返回 -3.
minStack.pop();
minStack.top(); --> 返回 0.
minStack.getMin(); --> 返回 -2.
提示:
-231 <= val <= 231 - 1
pop、top 和 getMin 操作总是在 非空栈 上调用
push, pop, top, and getMin最多被调用 3 * 104 次
I came up with this simple solution using just a single stack.
Here I am using Stack of Pair of Int. The first value of the pair would store the element of the normal stack and the second value would store the minimum up to that point in the stack.
So even if the minimum element of the stack is removed from the top, we still have a backup of the next minimum element in the pair. So for every element pushed in the stack, it stores its corresponding minimum value.
For example, let's do a Dry Run of an example.
["MinStack","push","push","push","push","push","getMin","pop","pop","top","push","getMin"]
[[],[5],[-2],[3],[-10],[20],[],[],[],[],[30],[]]
We push 5,-2,3,-10,20 in the stack.
If the stack is empty we push {val,val} in the stack
else we push {val,min(s.top().second,val)} which is basically minimum upto that point.
Hence {5,5},{-2,-2},{3,-2},{-10,-10},{20,-10} are pushed in the stack.
To pop simply do stack.pop()
To get the top return stack.top().first;
Now we pop 20 and -10 from the stack
The elements in the stack would be {5,5},{-2,-2},{3,-2}
On pushing 30 to the stack
The elements in the stack would be {5,5},{-2,-2},{3,-2},{30,-2}.
The Output of the code would be:
[null,null,null,null,null,null,-10,null,null,3,null,-2]
All the operations are one liners expect the Push operation which is a 2 liner.
class MinStack {
public:
vector< pair > s;
MinStack() { }
void push(int val) {
if(s.empty())
s.push_back({val,val});
else
s.push_back({val,min(s.back().second,val)});
}
void pop() { s.pop_back(); }
int top() { return s.back().first; }
int getMin() { return s.back().second; }
};
The Time complexity of each operation is O(1)
The Space complexity is O(N)
Solution1 辅助栈


Solution2 不用辅助栈

160. 相交链表
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交:
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
自定义评测:
评测系统 的输入如下(你设计的程序 不适用 此输入):
intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0
listA - 第一个链表
listB - 第二个链表
skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数
skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。
示例 1:
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at ‘8’
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:
输入:intersectVal = 2, listA = [1,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Intersected at ‘2’
解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [1,9,1,2,4],链表 B 为 [3,2,4]。
在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。
由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
这两个链表不相交,因此返回 null 。
提示:
listA 中节点数目为 m
listB 中节点数目为 n
1 <= m, n <= 3 * 104
1 <= Node.val <= 105
0 <= skipA <= m
0 <= skipB <= n
如果 listA 和 listB 没有交点,intersectVal 为 0
如果 listA 和 listB 有交点,intersectVal == listA[skipA] == listB[skipB]
进阶:你能否设计一个时间复杂度 O(m + n) 、仅用 O(1) 内存的解决方案?
O ( 1 ) SPACE SOLUTION
First using constant space check for last element of both lists.
If tails of both lists are different then return NULL
Now we know that intersection length will be same for both lists. So we want to make length prior to the intersection also equal.
Head pointer of the longer list is moved to next till length of both lists become equal
NOW we will have intersetion point at the same distance from head for both the lists.
Now keep comparing heads till match found.
Solution1 哈希集合

Solution2 双指针



class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
if (headA == nullptr || headB == nullptr) {
return nullptr;
}
ListNode *pA = headA, *pB = headB;
while (pA != pB) {
pA = pA == nullptr ? headB : pA->next;
pB = pB == nullptr ? headA : pB->next;
}
return pA;
}
};
162. 寻找峰值
峰值元素是指其值严格大于左右相邻值的元素。
给你一个整数数组 nums,找到峰值元素并返回其索引。数组可能包含多个峰值,在这种情况下,返回 任何一个峰值 所在位置即可。
你可以假设 nums[-1] = nums[n] = -∞ 。
你必须实现时间复杂度为 O(log n) 的算法来解决此问题。
示例 1:
输入:nums = [1,2,3,1]
输出:2
解释:3 是峰值元素,你的函数应该返回其索引 2。
示例 2:
输入:nums = [1,2,1,3,5,6,4]
输出:1 或 5
解释:你的函数可以返回索引 1,其峰值元素为 2;
或者返回索引 5, 其峰值元素为 6。
提示:
1 <= nums.length <= 1000
-231 <= nums[i] <= 231 - 1
对于所有有效的 i 都有 nums[i] != nums[i + 1]

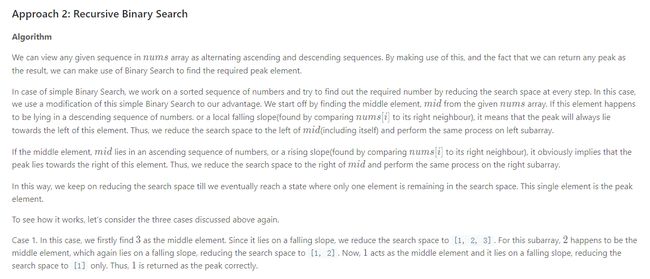
Solution1 暴力

Solution2 二分法

int findPeakElement(vector& nums) {
int left = 0, right = nums.size() - 1;
while (left < right ) {
int mid = left + (right - left) / 2;
if (nums[mid] < nums[mid + 1]) {
left = mid+1;
} else {
right = mid+1;
}
}
return left;
}
169. 多数元素

Approach 1: Brute Force
Intuition
We can exhaust the search space in quadratic time by checking whether each element is the majority element.
Algorithm
The brute force algorithm iterates over the array, and then iterates again for each number to count its occurrences. As soon as a number is found to have appeared more than any other can possibly have appeared, return it.
Complexity Analysis
Time complexity : O(n^2)
The brute force algorithm contains two nested for loops that each run for nn iterations, adding up to quadratic time complexity.
Space complexity : O(1)
The brute force solution does not allocate additional space proportional to the input size.
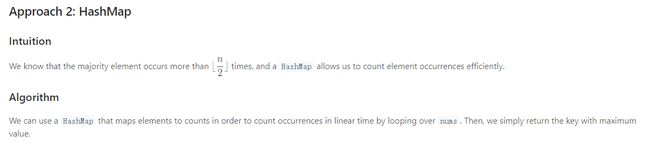
Solution 1 哈希表


Solution 2 排序

Solution 3 Boyer-Moore 投票法

172. 阶乘后的零
给定一个整数 n ,返回 n! 结果中尾随零的数量。
提示 n! = n * (n - 1) * (n - 2) * … * 3 * 2 * 1
示例 1:
输入:n = 3
输出:0
解释:3! = 6 ,不含尾随 0
示例 2:
输入:n = 5
输出:1
解释:5! = 120 ,有一个尾随 0
示例 3:
输入:n = 0
输出:0
提示:
0 <= n <= 104

Solution1
首先题目的意思是末尾有几个0
比如6! = 【1* 2* 3* 4* 5* 6】
其中只有25末尾才有0,所以就可以抛去其他数据 专门看2 5 以及其倍数 毕竟 4 * 25末尾也是0
比如10! = 【2456810】
其中 4能拆成22 10能拆成25
所以10! = 【2*(22)5(23)(222)(2*5)】
一个2和一个5配对 就产生一个0 所以10!末尾2个0
转头一想 2肯定比5多 所以只数5的个数就行了
假若N=31 31里能凑10的5为[5, 2*5, 3*5, 4*5, 25, 6*5]
class Solution {
public:
int trailingZeroes(int n) {
int res=0;
for(int i=n;i>0;i/=5){
res+=i/5;
}
return res;
}
};
179. 最大数
给定一组非负整数 nums,重新排列每个数的顺序(每个数不可拆分)使之组成一个最大的整数。
注意:输出结果可能非常大,所以你需要返回一个字符串而不是整数。
示例 1:
输入:nums = [10,2]
输出:“210”
示例 2:
输入:nums = [3,30,34,5,9]
输出:“9534330”
提示:
1 <= nums.length <= 100
0 <= nums[i] <= 109
Intuition
To construct the largest number, we want to ensure that the most significant digits are occupied by the largest digits.
Algorithm
First, we convert each integer to a string. Then, we sort the array of strings.
While it might be tempting to simply sort the numbers in descending order, this causes problems for sets of numbers with the same leading digit. For example, sorting the problem example in descending order would produce the number 95343039534303, while the correct answer can be achieved by transposing the 33 and the 3030. Therefore, for each pairwise comparison during the sort, we compare the numbers achieved by concatenating the pair in both orders. We can prove that this sorts into the proper order as follows:
Assume that (without loss of generality), for some pair of integers aa and bb, our comparator dictates that aa should precede bb in sorted order. This means that a\frown b > b\frown aa⌢b>b⌢a (where \frown⌢ represents concatenation). For the sort to produce an incorrect ordering, there must be some cc for which bb precedes cc and cc precedes aa. This is a contradiction because a\frown b > b\frown aa⌢b>b⌢a and b\frown c > c\frown bb⌢c>c⌢b implies a\frown c > c\frown aa⌢c>c⌢a. In other words, our custom comparator preserves transitivity, so the sort is correct.
Once the array is sorted, the most "signficant" number will be at the front. There is a minor edge case that comes up when the array consists of only zeroes, so if the most significant number is 00, we can simply return 00. Otherwise, we build a string out of the sorted array and return it.
Solution0 暴力
Solution1 排序
自定义一种排序方式 比较 s1 + s2 和 s2 + s1
class Solution {
public:
static bool cmp(int a,int b){
string sa = to_string(a);
string sb = to_string(b);
return sa+sb>sb+sa;
}
string largestNumber(vector& nums) {
sort(nums.begin(),nums.end(),cmp);
string ret;
for(auto num:nums){
if(!(num==0&&ret[0]=='0')) ret+=to_string(num);
}
return ret;
}
};

187. 重复的DNA序列
DNA序列 由一系列核苷酸组成,缩写为 ‘A’, ‘C’, ‘G’ 和 ‘T’.。
例如,“ACGAATTCCG” 是一个 DNA序列 。
在研究 DNA 时,识别 DNA 中的重复序列非常有用。
给定一个表示 DNA序列 的字符串 s ,返回所有在 DNA 分子中出现不止一次的 长度为 10 的序列(子字符串)。你可以按 任意顺序 返回答案。
示例 1:
输入:s = “AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT”
输出:[“AAAAACCCCC”,“CCCCCAAAAA”]
示例 2:
输入:s = “AAAAAAAAAAAAA”
输出:[“AAAAAAAAAA”]
提示:
0 <= s.length <= 105
s[i]==‘A’、‘C’、‘G’ or ‘T’
Simple sliding window solution.
comments added for better explanation.
class Solution {
public:
vector findRepeatedDnaSequences(string s) {
vector ans;
map mmap;
//storing the first 10 size substring(dna sequence)
//in temp
string temp=s.substr(0,10);
//adding first dna sequence to map
mmap[temp]++;
//now the sliding window.
for(int i=10;i1 and find(ans.begin(),ans.end(),temp)==ans.end())
{
ans.push_back(temp);
}
}
return ans;
}
};
Solution1 哈希表
我们可以用一个哈希表统计 ss 所有长度为 1010 的子串的出现次数,返回所有出现次数超过 1010 的子串。
代码实现时,可以一边遍历子串一边记录答案,为了不重复记录答案,我们只统计当前出现次数为 22 的子串。
class Solution {
const int L = 10;
public:
vector findRepeatedDnaSequences(string s) {
vector ans;
unordered_map cnt;
int n = s.length();
for (int i = 0; i <= n - L; ++i) {
string sub = s.substr(i, L);
if (++cnt[sub] == 2) {
ans.push_back(sub);
}
}
return ans;
}
};
Solution2 哈希表 滑动窗口 二进制

class Solution {
const int L = 10;
unordered_map bin = {{'A', 0}, {'C', 1}, {'G', 2}, {'T', 3}};
public:
vector findRepeatedDnaSequences(string s) {
vector ans;
int n = s.length();
if (n <= L) {
return ans;
}
int x = 0;
for (int i = 0; i < L - 1; ++i) {
x = (x << 2) | bin[s[i]];
}
unordered_map cnt;
for (int i = 0; i <= n - L; ++i) {
x = ((x << 2) | bin[s[i + L - 1]]) & ((1 << (L * 2)) - 1);
if (++cnt[x] == 2) {
ans.push_back(s.substr(i, L));
}
}
return ans;
}
};
189. 轮转数组
给你一个数组,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。
示例 1:
输入: nums = [1,2,3,4,5,6,7], k = 3
输出: [5,6,7,1,2,3,4]
解释:
向右轮转 1 步: [7,1,2,3,4,5,6]
向右轮转 2 步: [6,7,1,2,3,4,5]
向右轮转 3 步: [5,6,7,1,2,3,4]
示例 2:
输入:nums = [-1,-100,3,99], k = 2
输出:[3,99,-1,-100]
解释:
向右轮转 1 步: [99,-1,-100,3]
向右轮转 2 步: [3,99,-1,-100]
提示:
1 <= nums.length <= 105
-231 <= nums[i] <= 231 - 1
0 <= k <= 105
// o(n) This solution is simply reversing the array and the reversing array from 0 to k-1 and then from k to n-1. Do a dry run by taking an example on copy and you will usndersand it.
// o(n) Using extra space approach we simply store the last k elemets in same order from n-k to n-1 in a temp vector and we then pushback the reaining elements in the temp vector from index 0 to n-k-1;
/ o(n*k) we roatate elements of the vector one by one for k times and achieve k roatations.
Solution1 使用额外的数组

Solution2 数组翻转

class Solution {
public:
void reverse(vector& nums, int start, int end) {
while (start < end) {
swap(nums[start], nums[end]);
start += 1;
end -= 1;
}
}
void rotate(vector& nums, int k) {
k %= nums.size();
reverse(nums, 0, nums.size() - 1);
reverse(nums, 0, k - 1);
reverse(nums, k, nums.size() - 1);
}
};
动态规划:198. 打家劫舍
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
示例 1:
输入:[1,2,3,1]
输出:4
解释:偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。
偷窃到的最高金额 = 1 + 3 = 4 。
示例 2:
输入:[2,7,9,3,1]
输出:12
解释:偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。
偷窃到的最高金额 = 2 + 9 + 1 = 12 。
提示:
1 <= nums.length <= 100
0 <= nums[i] <= 400
This is a classic 1D-DP problem where at every step we have a choice to make ...
So the first and foremost thing in any DP problem is to find the reccurence relation !!
At every ith house robber has 2 options: a) rob current house i. b) don't rob current house.
In case he is robbing the (i)th house, the money he can get till the i-th house == money robbed till (i-2)th house + money robbed at (i)th house....let's say total money robbed in this case equals to X.
In case he is not robbing, money robbed till i-th house==money robbed till (i-1)th house...lets say total money robbed in this case equals to Y.
So , the maxm money he gets till i-th house is the max(X,Y).
Example of case (a) --> nums={2,3,2} ... Here, the robber will rob the house at index-2 as nums[index-2] + nums[index-0] > nums[index-1]
Example of case (b)--> nums={2,7,3} ... here maximum money robbed till index-2 will not be equal to nums[index-2] + nums[index-0]... as nums[index-1] is greater than the sum of money at both those houses ...
We can achieve the desired solution to this problem via mutliple ways, let's start with the simpler ones and then will look forward to optimize the Time and Space Complexities
Simple Recursion
Time Complexcity : O ( 2^n ) Gives us TLE
Space Complexcity : O( 1 )
Solution1 动态规划
dp 方程 dp[i] = max(dp[i-2]+nums[i], dp[i-1])
class Solution {
public:
int rob(vector& nums) {
if (nums.empty()) {
return 0;
}
int size = nums.size();
if (size == 1) {
return nums[0];
}
vector dp = vector(size, 0);
dp[0] = nums[0];
dp[1] = max(nums[0], nums[1]);
for (int i = 2; i < size; i++) {
dp[i] = max(dp[i - 2] + nums[i], dp[i - 1]);
}
return dp[size - 1];
}
};
Solution2 动态规划
上述方法使用了数组存储结果。考虑到每间房屋的最高总金额只和该房屋的前两间房屋的最高总金额相关,因此可以使用滚动数组,在每个时刻只需要存储前两间房屋的最高总金额。
class Solution {
public:
int rob(vector& nums) {
if (nums.empty()) {
return 0;
}
int size = nums.size();
if (size == 1) {
return nums[0];
}
int first = nums[0], second = max(nums[0], nums[1]);
for (int i = 2; i < size; i++) {
int temp = second;
second = max(first + nums[i], second);
first = temp;
}
return second;
}
};
复杂度分析
时间复杂度:O(n)O(n),其中 nn 是数组长度。只需要对数组遍历一次。
空间复杂度:O(1)O(1)。使用滚动数组,可以只存储前两间房屋的最高总金额,而不需要存储整个数组的结果,因此空间复杂度是 O(1)O(1)。
树:199. 二叉树的右视图
给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
示例 1:
输入: [1,2,3,null,5,null,4]
输出: [1,3,4]
示例 2:
输入: [1,null,3]
输出: [1,3]
示例 3:
输入: []
输出: []
提示:
二叉树的节点个数的范围是 [0,100]
-100 <= Node.val <= 100
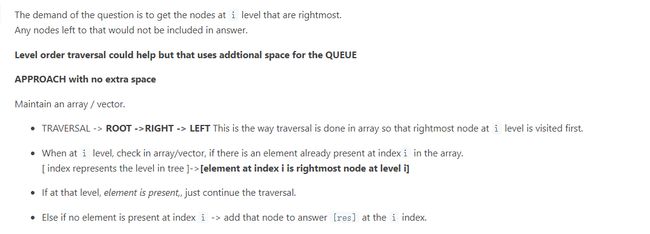
Solution1 层序遍历
使用层序遍历,并只保留每层最后一个节点的值
class Solution {
public:
vector rightSideView(TreeNode* root) {
unordered_map rightmostValueAtDepth;
int max_depth = -1;
queue nodeQueue;
queue depthQueue;
nodeQueue.push(root);
depthQueue.push(0);
while (!nodeQueue.empty()) {
TreeNode* node = nodeQueue.front();nodeQueue.pop();
int depth = depthQueue.front();depthQueue.pop();
if (node != NULL) {
// 维护二叉树的最大深度
max_depth = max(max_depth, depth);
// 由于每一层最后一个访问到的节点才是我们要的答案,因此不断更新对应深度的信息即可
rightmostValueAtDepth[depth] = node -> val;
nodeQueue.push(node -> left);
nodeQueue.push(node -> right);
depthQueue.push(depth + 1);
depthQueue.push(depth + 1);
}
}
vector rightView;
for (int depth = 0; depth <= max_depth; ++depth) {
rightView.push_back(rightmostValueAtDepth[depth]);
}
return rightView;
}
};

这里可以通过维护两个node queue来实现
递归:200. 岛屿数量
给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [
[“1”,“1”,“1”,“1”,“0”],
[“1”,“1”,“0”,“1”,“0”],
[“1”,“1”,“0”,“0”,“0”],
[“0”,“0”,“0”,“0”,“0”]
]
输出:1
示例 2:
输入:grid = [
[“1”,“1”,“0”,“0”,“0”],
[“1”,“1”,“0”,“0”,“0”],
[“0”,“0”,“1”,“0”,“0”],
[“0”,“0”,“0”,“1”,“1”]
]
输出:3
提示:
m == grid.length
n == grid[i].length
1 <= m, n <= 300
grid[i][j] 的值为 ‘0’ 或 ‘1’

Solution1 DFS
思路:遍历岛这个二维数组,如果当前数为1,则进入感染函数并将岛个数+1
感染函数:其实就是一个递归标注的过程,它会将所有相连的1都标注成2。为什么要标注?这样就避免了遍历过程中的重复计数的情况,一个岛所有的1都变成了2后,遍历的时候就不会重复遍历了。建议没想明白的同学画个图看看。
class Solution {
public int numIslands(char[][] grid) {
int islandNum = 0;
for(int i = 0; i < grid.length; i++){
for(int j = 0; j < grid[0].length; j++){
if(grid[i][j] == '1'){
infect(grid, i, j);
islandNum++;
}
}
}
return islandNum;
}
//感染函数
public void infect(char[][] grid, int i, int j){
if(i < 0 || i >= grid.length ||
j < 0 || j >= grid[0].length || grid[i][j] != '1'){
return;
}
grid[i][j] = '2';
infect(grid, i + 1, j);
infect(grid, i - 1, j);
infect(grid, i, j + 1);
infect(grid, i, j - 1);
}
}
Solution2 BFS
主循环和思路一类似,不同点是在于搜索某岛屿边界的方法不同。
bfs 方法:
借用一个队列 queue,判断队列首部节点 (i, j) 是否未越界且为 1:
若是则置零(删除岛屿节点),并将此节点上下左右节点 (i+1,j),(i-1,j),(i,j+1),(i,j-1) 加入队列;
若不是则跳过此节点;
循环 pop 队列首节点,直到整个队列为空,此时已经遍历完此岛屿。
class Solution {
public int numIslands(char[][] grid) {
int count = 0;
for(int i = 0; i < grid.length; i++) {
for(int j = 0; j < grid[0].length; j++) {
if(grid[i][j] == '1'){
bfs(grid, i, j);
count++;
}
}
}
return count;
}
private void bfs(char[][] grid, int i, int j){
Queue list = new LinkedList<>();
list.add(new int[] { i, j });
while(!list.isEmpty()){
int[] cur = list.remove();
i = cur[0]; j = cur[1];
if(0 <= i && i < grid.length && 0 <= j && j < grid[0].length && grid[i][j] == '1') {
grid[i][j] = '0';
list.add(new int[] { i + 1, j });
list.add(new int[] { i - 1, j });
list.add(new int[] { i, j + 1 });
list.add(new int[] { i, j - 1 });
}
}
}
}
202. 快乐数
编写一个算法来判断一个数 n 是不是快乐数。
「快乐数」 定义为:
对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。
然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。
如果这个过程 结果为 1,那么这个数就是快乐数。
如果 n 是 快乐数 就返回 true ;不是,则返回 false 。
示例 1:
输入:n = 19
输出:true
解释:
12 + 92 = 82
82 + 22 = 68
62 + 82 = 100
12 + 02 + 02 = 1
示例 2:
输入:n = 2
输出:false
提示:
1 <= n <= 231 - 1
1.hash-set
The hash-set solution is very straightforward. For every new data, we check whether it is already in the set. If no, we insert it into the set. If yes, we detect the loop. Only when the node in the loop is "1", the number is happy number.
2.hash-map
The idea is similar as hase-set. We check the node value to check whether it is in the loop.
The code is as follow. The time complexity usually is O(1) (the worst may be O(n) due to conflict)
3.Floyd's Cycle detection algorithm
Floyd's cycle detection algorithm is a pointer algorithm that uses only two pointers, which move through the sequence at different speeds. Obviously, if there is a loop, they will meet in the loop. It is also called the "tortoise and the hare algorithm"
4.Brent's Cycle detection algorithm
Brent's algorithm features a moving rabbit and a stationary, then teleporting, turtle. Both turtle and rabbit start at the top of the list. The rabbit takes one step per iteration. Every once in a while, we teleport the turtle to the rabbit's position, and let the rabbit continue moving. We start out waiting just 2 steps before teleportation, and we double that each time we move the turtle. If there is a loop, they will meet in the loop.
The code is as follows. The time complexity is O(λ + μ)*. However you're doing less stepping than with Floyd's (in fact the upper bound for steps is the number you would do with Floyd's algorithm). According to Brent's research, his algorithm is 24-36% faster on average for implicit linked list algorithms.(However, it cost same time as the Floyd's in the OJ ;) )
Solution1 快慢指针
//参考英文网站热评第一。这题可以用快慢指针的思想去做,有点类似于检测是否为环形链表那道题
//如果给定的数字最后会一直循环重复,那么快的指针(值)一定会追上慢的指针(值),也就是
//两者一定会相等。如果没有循环重复,那么最后快慢指针也会相等,且都等于1。
class Solution {
public boolean isHappy(int n) {
int fast=n;
int slow=n;
do{
slow=squareSum(slow);
fast=squareSum(fast);
fast=squareSum(fast);
}while(slow!=fast);
if(fast==1)
return true;
else return false;
}
private int squareSum(int m){
int squaresum=0;
while(m!=0){
squaresum+=(m%10)*(m%10);
m/=10;
}
return squaresum;
}
}
Solution2 暴力
class Solution {
public:
bool isHappy(int n) {
int ans=0;
for(int i = 0 ; i< 100;i++)
{
while(n>0)
{
ans += (n%10)*(n%10);
n = n /10;
}
n = ans;
if(n==1)
return true;
}
return false;
}
};
203. 移除链表元素
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1:
输入:head = [1,2,6,3,4,5,6], val = 6
输出:[1,2,3,4,5]
示例 2:
输入:head = [], val = 1
输出:[]
示例 3:
输入:head = [7,7,7,7], val = 7
输出:[]
提示:
列表中的节点数目在范围 [0, 104] 内
1 <= Node.val <= 50
0 <= val <= 50
✔️ Solution - I (Iterative using Dummy node)
A simple solution to delete the nodes having value T is to traverse over the linked list and just remove the next pointers to the node having value as T. Now, usually in deletion problem of linked list, there can be multiple cases where node to be deleted is either a head node or other node in rest of list. We usually make use of a dummy node at the start or sentinel node to avoid handling multiple edge cases and write a clean uniform solution.
So, the algorithm we are using can be summarised as -
Initialize a dummy/sentinel node having its next pointer pointing to the head of linked list and another node pointer prev pointing to this dummy node.
Start iterating over head of linked list
If current node's value is not equal to T, we can just move to next node without deleting current node. In this case,
We first update prev pointer and point it to current head
Then move head to next node.
Otherwise, if head -> val == T, we know that this node needs to be deleted. In this case,
We can just update the next pointer of previous node to the next pointer of current node. This will basically remove the current node from list.
Then, we update head to its next node just as in previous case.
Finally, ignore the dummy node created at start and return its next node.
Solution1 迭代

Solution2 递归
ListNode *removeElements(ListNode *head, int val)
{
if (!head)
return head;
head->next = removeElements(head->next, val);
return head->val == val ? head->next : head;
}
复杂度分析
时间复杂度:O(n)O(n),其中 nn 是链表的长度。需要遍历链表一次。
空间复杂度:O(1)O(1)。
递归:206. 反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:
输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
示例 2:
输入:head = [1,2]
输出:[2,1]
示例 3:
输入:head = []
输出:[]
提示:
链表中节点的数目范围是 [0, 5000]
-5000 <= Node.val <= 5000
Well, since the head pointer may also be modified, we create a pre that points to it to facilitate the reverse process.
For the example list 1 -> 2 -> 3 -> 4 -> 5 in the problem statement, it will become 0 -> 1 -> 2 -> 3 -> 4 -> 5 (we init pre -> val to be 0). We also set a pointer cur to head. Then we keep inserting cur -> next after pre until cur becomes the last node. This idea uses three pointers (pre, cur and temp). You may implement it as follows.
Solution1 迭代
/迭代法
public ListNode reverseList(ListNode head) {
ListNode pre = null;
ListNode cur = head;
while(cur!=null) {
ListNode next = cur.next;
cur.next = pre;
pre = cur;
cur = next;
}
return pre;
}
Solution2 递归
//尾递归
public ListNode reverseList(ListNode head) {
return reverse(null,head);
}
private static ListNode reverse(ListNode pre,ListNode cur){
if(cur==null) return pre;
ListNode next = cur.next;
cur.next = pre;
return reverse(cur,next);
}
215. 数组中的第K个最大元素
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
输入: [3,2,1,5,6,4], k = 2
输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6], k = 4
输出: 4
提示:
1 <= k <= nums.length <= 105
-104 <= nums[i] <= 104
This problem is well known and quite often can be found in various text books.
You can take a couple of approaches to actually solve it:
O(N lg K) running time + O(K) memory
Other possibility is to use a min oriented priority queue that will store the K-th largest values. The algorithm iterates over the whole input and maintains the size of priority queue.
O(N) best case / O(N^2) worst case running time + O(1) memory
The smart approach for this problem is to use the selection algorithm (based on the partion method - the same one as used in quicksort).
O(N) guaranteed running time + O(1) space
So how can we improve the above solution and make it O(N) guaranteed? The answer is quite simple, we can randomize the input, so that even when the worst case input would be provided the algorithm wouldn't be affected. So all what it is needed to be done is to shuffle the input.
Solution1 堆排序

复杂度分析
时间复杂度:O(n \log n)O(nlogn),建堆的时间代价是 O(n)O(n),删除的总代价是 O(k \log n)O(klogn),因为 k < nk

217. 存在重复元素
给你一个整数数组 nums 。如果任一值在数组中出现 至少两次 ,返回 true ;如果数组中每个元素互不相同,返回 false 。
示例 1:
输入:nums = [1,2,3,1]
输出:true
示例 2:
输入:nums = [1,2,3,4]
输出:false
示例 3:
输入:nums = [1,1,1,3,3,4,3,2,4,2]
输出:true
提示:
1 <= nums.length <= 105
-109 <= nums[i] <= 109
This problem seems trivial, so lets try different approaches to solve it:
Starting from worst time complexity to the best one:
Time complexity: O(N^2), memory: O(1)
The naive approach would be to run a iteration for each element and see whether a duplicate value can be found: this results in O(N^2) time complexity.
Time complexity: O(N lg N), memory: O(1) - not counting the memory used by sort
Since it is trivial task to find duplicates in sorted array, we can sort it as the first step of the algorithm and then search for consecutive duplicates.
Time complexity: O(N), memory: O(N)
Finally we can used a well known data structure hash table that will help us to identify whether an element has been previously encountered in the array.
This is trivial but quite nice example of space-time tradeoff.
Solution1 排序

Solution2
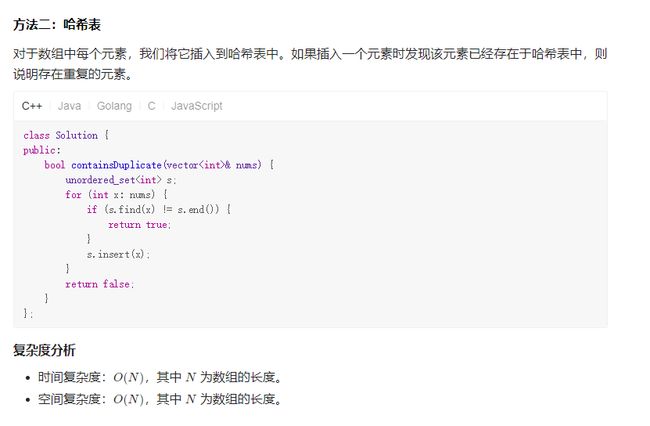
动态规划:221. 最大正方形

Approach 1: Brute Force
The simplest approach consists of trying to find out every possible square of 1’s that can be formed from within the matrix. The question now is – how to go for it?
We use a variable to contain the size of the largest square found so far and another variable to store the size of the current, both initialized to 0. Starting from the left uppermost point in the matrix, we search for a 1. No operation needs to be done for a 0. Whenever a 1 is found, we try to find out the largest square that can be formed including that 1. For this, we move diagonally (right and downwards), i.e. we increment the row index and column index temporarily and then check whether all the elements of that row and column are 1 or not. If all the elements happen to be 1, we move diagonally further as previously. If even one element turns out to be 0, we stop this diagonal movement and update the size of the largest square. Now we, continue the traversal of the matrix from the element next to the initial 1 found, till all the elements of the matrix have been traversed.
Complexity Analysis
Time complexity : O((mn)^2)
In worst case, we need to traverse the complete matrix for every 1.
Space complexity : O(1)O(1). No extra space is used.

Solution0 暴力法

Solution1 动态规划
class Solution {
public int maximalSquare(char[][] matrix) {
/**
dp[i][j]表示以第i行第j列为右下角所能构成的最大正方形边长, 则递推式为:
dp[i][j] = 1 + min(dp[i-1][j-1], dp[i-1][j], dp[i][j-1]);
**/
int m = matrix.length;
if(m < 1) return 0;
int n = matrix[0].length;
int max = 0;
int[][] dp = new int[m+1][n+1];
for(int i = 1; i <= m; ++i) {
for(int j = 1; j <= n; ++j) {
if(matrix[i-1][j-1] == '1') {
dp[i][j] = 1 + Math.min(dp[i-1][j-1], Math.min(dp[i-1][j], dp[i][j-1]));
max = Math.max(max, dp[i][j]);
}
}
}
return max*max;
}
}
225. 用队列实现栈
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。
实现 MyStack 类:
void push(int x) 将元素 x 压入栈顶。
int pop() 移除并返回栈顶元素。
int top() 返回栈顶元素。
boolean empty() 如果栈是空的,返回 true ;否则,返回 false 。
注意:
你只能使用队列的基本操作 —— 也就是 push to back、peek/pop from front、size 和 is empty 这些操作。
你所使用的语言也许不支持队列。 你可以使用 list (列表)或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可。
示例:
输入:
[“MyStack”, “push”, “push”, “top”, “pop”, “empty”]
[[], [1], [2], [], [], []]
输出:
[null, null, null, 2, 2, false]
解释:
MyStack myStack = new MyStack();
myStack.push(1);
myStack.push(2);
myStack.top(); // 返回 2
myStack.pop(); // 返回 2
myStack.empty(); // 返回 False
提示:
1 <= x <= 9
最多调用100 次 push、pop、top 和 empty
每次调用 pop 和 top 都保证栈不为空



Solution1 两个队列

class MyStack {
public:
queue queue1;
queue queue2;
/** Initialize your data structure here. */
MyStack() {
}
/** Push element x onto stack. */
void push(int x) {
queue2.push(x);
while (!queue1.empty()) {
queue2.push(queue1.front());
queue1.pop();
}
swap(queue1, queue2);
}
/** Removes the element on top of the stack and returns that element. */
int pop() {
int r = queue1.front();
queue1.pop();
return r;
}
/** Get the top element. */
int top() {
int r = queue1.front();
return r;
}
/** Returns whether the stack is empty. */
bool empty() {
return queue1.empty();
}
};
Solution2 单个队列

树:226. 翻转二叉树

To invert a binary tree, we swap the left and right subtrees and invert them recursively/iteratively.
Solution1
利用前序遍历
class Solution {
// 先序遍历--从顶向下交换
public TreeNode invertTree(TreeNode root) {
if (root == null) return null;
// 保存右子树
TreeNode rightTree = root.right;
// 交换左右子树的位置
root.right = invertTree(root.left);
root.left = invertTree(rightTree);
return root;
}
}
利用中序遍历
class Solution {
public TreeNode invertTree(TreeNode root) {
if (root == null) return null;
invertTree(root.left); // 递归找到左节点
TreeNode rightNode= root.right; // 保存右节点
root.right = root.left;
root.left = rightNode;
// 递归找到右节点 继续交换 : 因为此时左右节点已经交换了,所以此时的右节点为root.left
invertTree(root.left);
}
}
利用后序遍历
class Solution {
public TreeNode invertTree(TreeNode root) {
// 后序遍历-- 从下向上交换
if (root == null) return null;
TreeNode leftNode = invertTree(root.left);
TreeNode rightNode = invertTree(root.right);
root.right = leftNode;
root.left = rightNode;
return root;
}
}
利用层次遍历
class Solution {
public TreeNode invertTree(TreeNode root) {
// 层次遍历--直接左右交换即可
if (root == null) return null;
Queue queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()){
TreeNode node = queue.poll();
TreeNode rightTree = node.right;
node.right = node.left;
node.left = rightTree;
if (node.left != null){
queue.offer(node.left);
}
if (node.right != null){
queue.offer(node.right);
}
}
return root;
}
}
227. 基本计算器 II
给你一个字符串表达式 s ,请你实现一个基本计算器来计算并返回它的值。
整数除法仅保留整数部分。
你可以假设给定的表达式总是有效的。所有中间结果将在 [-231, 231 - 1] 的范围内。
注意:不允许使用任何将字符串作为数学表达式计算的内置函数,比如 eval() 。
示例 1:
输入:s = “3+2*2”
输出:7
示例 2:
输入:s = " 3/2 "
输出:1
示例 3:
输入:s = " 3+5 / 2 "
输出:5
提示:
1 <= s.length <= 3 * 105
s 由整数和算符 (‘+’, ‘-’, ‘*’, ‘/’) 组成,中间由一些空格隔开
s 表示一个 有效表达式
表达式中的所有整数都是非负整数,且在范围 [0, 231 - 1] 内
题目数据保证答案是一个 32-bit 整数


Solution1 栈
方法一:栈
思路
由于乘除优先于加减计算,因此不妨考虑先进行所有乘除运算,并将这些乘除运算后的整数值放回原表达式的相应位置,则随后整个表达式的值,就等于一系列整数加减后的值。
基于此,我们可以用一个栈,保存这些(进行乘除运算后的)整数的值。对于加减号后的数字,将其直接压入栈中;对于乘除号后的数字,可以直接与栈顶元素计算,并替换栈顶元素为计算后的结果。
具体来说,遍历字符串 ss,并用变量 \textit{preSign}preSign 记录每个数字之前的运算符,对于第一个数字,其之前的运算符视为加号。每次遍历到数字末尾时,根据 \textit{preSign}preSign 来决定计算方式:
加号:将数字压入栈;
减号:将数字的相反数压入栈;
乘除号:计算数字与栈顶元素,并将栈顶元素替换为计算结果。
代码实现中,若读到一个运算符,或者遍历到字符串末尾,即认为是遍历到了数字末尾。处理完该数字后,更新 \textit{preSign}preSign 为当前遍历的字符。
遍历完字符串 ss 后,将栈中元素累加,即为该字符串表达式的值。
class Solution {
public:
int calculate(string s) {
vector stk;
char preSign = '+';
int num = 0;
int n = s.length();
for (int i = 0; i < n; ++i) {
if (isdigit(s[i])) {
num = num * 10 + int(s[i] - '0');
}
if (!isdigit(s[i]) && s[i] != ' ' || i == n - 1) {
switch (preSign) {
case '+':
stk.push_back(num);
break;
case '-':
stk.push_back(-num);
break;
case '*':
stk.back() *= num;
break;
default:
stk.back() /= num;
}
preSign = s[i];
num = 0;
}
}
return accumulate(stk.begin(), stk.end(), 0);
}
};
复杂度分析
时间复杂度:O(n)O(n),其中 nn 为字符串 ss 的长度。需要遍历字符串 ss 一次,计算表达式的值。
空间复杂度:O(n)O(n),其中 nn 为字符串 ss 的长度。空间复杂度主要取决于栈的空间,栈的元素个数不超过 nn。
232. 用栈实现队列
请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty):
实现 MyQueue 类:
void push(int x) 将元素 x 推到队列的末尾
int pop() 从队列的开头移除并返回元素
int peek() 返回队列开头的元素
boolean empty() 如果队列为空,返回 true ;否则,返回 false
说明:
你 只能 使用标准的栈操作 —— 也就是只有 push to top, peek/pop from top, size, 和 is empty 操作是合法的。
你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
示例 1:
输入:
[“MyQueue”, “push”, “push”, “peek”, “pop”, “empty”]
[[], [1], [2], [], [], []]
输出:
[null, null, null, 1, 1, false]
解释:
MyQueue myQueue = new MyQueue();
myQueue.push(1); // queue is: [1]
myQueue.push(2); // queue is: [1, 2] (leftmost is front of the queue)
myQueue.peek(); // return 1
myQueue.pop(); // return 1, queue is [2]
myQueue.empty(); // return false


Solution1

思路
将一个栈当作输入栈,用于压入 \texttt{push}push 传入的数据;另一个栈当作输出栈,用于 \texttt{pop}pop 和 \texttt{peek}peek 操作。
每次 \texttt{pop}pop 或 \texttt{peek}peek 时,若输出栈为空则将输入栈的全部数据依次弹出并压入输出栈,这样输出栈从栈顶往栈底的顺序就是队列从队首往队尾的顺序。
class MyQueue {
private:
stack inStack, outStack;
void in2out() {
while (!inStack.empty()) {
outStack.push(inStack.top());
inStack.pop();
}
}
public:
MyQueue() {}
void push(int x) {
inStack.push(x);
}
int pop() {
if (outStack.empty()) {
in2out();
}
int x = outStack.top();
outStack.pop();
return x;
}
int peek() {
if (outStack.empty()) {
in2out();
}
return outStack.top();
}
bool empty() {
return inStack.empty() && outStack.empty();
}
};

234. 回文链表
给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
示例 1:
输入:head = [1,2,2,1]
输出:true
示例 2:
输入:head = [1,2]
输出:false
提示:
链表中节点数目在范围[1, 105] 内
0 <= Node.val <= 9
进阶:你能否用 O(n) 时间复杂度和 O(1) 空间复杂度解决此题?
Functions used below are HEART n SOUL of linkedlist questions. Usually, any LinkedList question can be broken down to these functions:-
Reverse ===> Used for space optimization
Find Mid ===> Slow-Fast Pointer
Iteration : normal iter, recursive iter, adjacent node 2-vars, slow-fast
Insert : start , mid, last
delete : start, mid, last
THIS QUESTION:
find Mid of linkedlist --------> do see cases of even/odd length on paper
reverse second half from mid pointer ----> see how prev gets changed
Now compare first and second half Easy huh!
EdgeCase:
linkedlist size =0,1
Solution0 将链表复制到数组
class Solution {
public:
bool isPalindrome(ListNode* head) {
vector vals;
while (head != nullptr) {
vals.emplace_back(head->val);
head = head->next;
}
for (int i = 0, j = (int)vals.size() - 1; i < j; ++i, --j) {
if (vals[i] != vals[j]) {
return false;
}
}
return true;
}
};
Solution1 中点开始比较

230. 二叉搜索树中第K小的元素
给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 个最小元素(从 1 开始计数)。

Solution1 非递归
class Solution {
public:
int kthSmallest(TreeNode* root, int k) {
stack s;
int num=0;
TreeNode *cur=root;
while(!s.empty() || cur)
{
if(cur)
{
s.push(cur);
cur=cur->left;
}
else
{
cur=s.top();
s.pop();
num++;
if(num==k)
return cur->val;
cur=cur->right;
}
}
return 0;
}
};
Solution2 记录子节点数目

class MyBst {
public:
MyBst(TreeNode *root) {
this->root = root;
countNodeNum(root);
}
// 返回二叉搜索树中第k小的元素
int kthSmallest(int k) {
TreeNode *node = root;
while (node != nullptr) {
int left = getNodeNum(node->left);
if (left < k - 1) {
node = node->right;
k -= left + 1;
} else if (left == k - 1) {
break;
} else {
node = node->left;
}
}
return node->val;
}
private:
TreeNode *root;
unordered_map nodeNum;
// 统计以node为根结点的子树的结点数
int countNodeNum(TreeNode * node) {
if (node == nullptr) {
return 0;
}
nodeNum[node] = 1 + countNodeNum(node->left) + countNodeNum(node->right);
return nodeNum[node];
}
// 获取以node为根结点的子树的结点数
int getNodeNum(TreeNode * node) {
if (node != nullptr && nodeNum.count(node)) {
return nodeNum[node];
}else{
return 0;
}
}
};
class Solution {
public:
int kthSmallest(TreeNode* root, int k) {
MyBst bst(root);
return bst.kthSmallest(k);
}
};
树/递归:235. 二叉搜索树的最近公共祖先

Well, remember to take advantage of the property of binary search trees, which is, node -> left -> val < node -> val < node -> right -> val. Moreover, both p and q will be the descendants of the root of the subtree that contains both of them. And the root with the largest depth is just the lowest common ancestor. This idea can be turned into the following simple recursive code.
Solution1 非递归
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
//如果根节点和p,q的差相乘是正数,说明这两个差值要么都是正数要么都是负数,也就是说
//他们肯定都位于根节点的同一侧,就继续往下找
while ((root.val - p.val) * (root.val - q.val) > 0)
root = p.val < root.val ? root.left : root.right;
//如果相乘的结果是负数,说明p和q位于根节点的两侧,如果等于0,说明至少有一个就是根节点
return root;
}
Solution2 递归
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
//如果小于等于0,说明p和q位于root的两侧,直接返回即可
if ((root.val - p.val) * (root.val - q.val) <= 0)
return root;
//否则,p和q位于root的同一侧,就继续往下找
return lowestCommonAncestor(p.val < root.val ? root.left : root.right, p, q);
}
树/递归:236. 二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
示例 1:
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。
示例 2:
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。
示例 3:
输入:root = [1,2], p = 1, q = 2
输出:1
提示:
树中节点数目在范围 [2, 105] 内。
-109 <= Node.val <= 109
所有 Node.val 互不相同 。
p != q
p 和 q 均存在于给定的二叉树中。
Approach 1: Recursive Approach
Intuition
The approach is pretty intuitive. Traverse the tree in a depth first manner. The moment you encounter either of the nodes p or q, return some boolean flag. The flag helps to determine if we found the required nodes in any of the paths. The least common ancestor would then be the node for which both the subtree recursions return a True flag. It can also be the node which itself is one of p or q and for which one of the subtree recursions returns a True flag.
Let us look at the formal algorithm based on this idea.
Algorithm
Start traversing the tree from the root node.
If the current node itself is one of p or q, we would mark a variable mid as True and continue the search for the other node in the left and right branches.
If either of the left or the right branch returns True, this means one of the two nodes was found below.
If at any point in the traversal, any two of the three flags left, right or mid become True, this means we have found the lowest common ancestor for the nodes p and q.
Complexity Analysis
Time Complexity: O(N)O(N), where NN is the number of nodes in the binary tree. In the worst case we might be visiting all the nodes of the binary tree.
Space Complexity: O(N)O(N). This is because the maximum amount of space utilized by the recursion stack would be NN since the height of a skewed binary tree could be NN.
Approach 2: Iterative using parent pointers
Intuition
If we have parent pointers for each node we can traverse back from p and q to get their ancestors. The first common node we get during this traversal would be the LCA node. We can save the parent pointers in a dictionary as we traverse the tree.
Algorithm
Start from the root node and traverse the tree.
Until we find p and q both, keep storing the parent pointers in a dictionary.
Once we have found both p and q, we get all the ancestors for p using the parent dictionary and add to a set called ancestors.
Similarly, we traverse through ancestors for node q. If the ancestor is present in the ancestors set for p, this means this is the first ancestor common between p and q (while traversing upwards) and hence this is the LCA node.
Complexity Analysis
Time Complexity : O(N)O(N), where NN is the number of nodes in the binary tree. In the worst case we might be visiting all the nodes of the binary tree.
Space Complexity : O(N)O(N). In the worst case space utilized by the stack, the parent pointer dictionary and the ancestor set, would be NN each, since the height of a skewed binary tree could be NN.
Solution1 递归
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (root == null) return null;
// 如果p,q为根节点,则公共祖先为根节点
if (root.val == p.val || root.val == q.val) return root;
// 如果p,q在左子树,则公共祖先在左子树查找
if (find(root.left, p) && find(root.left, q)) {
return lowestCommonAncestor(root.left, p, q);
}
// 如果p,q在右子树,则公共祖先在右子树查找
if (find(root.right, p) && find(root.right, q)) {
return lowestCommonAncestor(root.right, p, q);
}
// 如果p,q分属两侧,则公共祖先为根节点
return root;
}
private boolean find(TreeNode root, TreeNode c) {
if (root == null) return false;
if (root.val == c.val) {
return true;
}
return find(root.left, c) || find(root.right, c);
}
}
237. 删除链表中的节点
有一个单链表的 head,我们想删除它其中的一个节点 node。
给你一个需要删除的节点 node 。你将 无法访问 第一个节点 head。
链表的所有值都是 唯一的,并且保证给定的节点 node 不是链表中的最后一个节点。
删除给定的节点。注意,删除节点并不是指从内存中删除它。这里的意思是:
给定节点的值不应该存在于链表中。
链表中的节点数应该减少 1。
node 前面的所有值顺序相同。
node 后面的所有值顺序相同。
自定义测试:
对于输入,你应该提供整个链表 head 和要给出的节点 node。node 不应该是链表的最后一个节点,而应该是链表中的一个实际节点。
我们将构建链表,并将节点传递给你的函数。
输出将是调用你函数后的整个链表。
示例 1:
输入:head = [4,5,1,9], node = 5
输出:[4,1,9]
解释:指定链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9
示例 2:
输入:head = [4,5,1,9], node = 1
输出:[4,5,9]
解释:指定链表中值为 1 的第三个节点,那么在调用了你的函数之后,该链表应变为 4 -> 5 -> 9
提示:
链表中节点的数目范围是 [2, 1000]
-1000 <= Node.val <= 1000
链表中每个节点的值都是 唯一 的
需要删除的节点 node 是 链表中的节点 ,且 不是末尾节点
class Solution {
public void deleteNode(ListNode node) {
node.val=node.next.val;
node.next=node.next.next;
}
}
So, this is our code.
We don't have the access to the previous node of the to be deleted node.
But we have the access to the next node, which makes deletion of next node possible.
So, we copy the value of the next node to this node and delete the next node (i.e connecting our current node to the next node's next)
Hopefully you understood, Thank you
Solution1

238. 除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。
题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。
请不要使用除法,且在 O(n) 时间复杂度内完成此题。
示例 1:
输入: nums = [1,2,3,4]
输出: [24,12,8,6]
示例 2:
输入: nums = [-1,1,0,-3,3]
输出: [0,0,9,0,0]
提示:
2 <= nums.length <= 105
-30 <= nums[i] <= 30
保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内
✔️ Solution - I (Calculate product & divide by self)
We can simply calculate product of the whole array and for each element in nums, divide the product by nums[i]. This effectively leaves us with product of whole array except self at each index. We need to take care of zeros that may occur in the array -
1. If there are more than one 0s in nums, the result is an array consisting of all 0.
2. If there is a single 0 in nums, then the result is an array consisting of all 0 except at the index where there was 0 in nums, which will contain product of rest of array.
3. If there's no 0 in nums, then the result is an array ans where ans[i] = prod / nums[i] (prod = product of all elements in nums).
Solution1 累乘列表

class Solution {
public:
vector productExceptSelf(vector& nums) {
int length = nums.size();
// L 和 R 分别表示左右两侧的乘积列表
vector L(length, 0), R(length, 0);
vector answer(length);
// L[i] 为索引 i 左侧所有元素的乘积
// 对于索引为 '0' 的元素,因为左侧没有元素,所以 L[0] = 1
L[0] = 1;
for (int i = 1; i < length; i++) {
L[i] = nums[i - 1] * L[i - 1];
}
// R[i] 为索引 i 右侧所有元素的乘积
// 对于索引为 'length-1' 的元素,因为右侧没有元素,所以 R[length-1] = 1
R[length - 1] = 1;
for (int i = length - 2; i >= 0; i--) {
R[i] = nums[i + 1] * R[i + 1];
}
// 对于索引 i,除 nums[i] 之外其余各元素的乘积就是左侧所有元素的乘积乘以右侧所有元素的乘积
for (int i = 0; i < length; i++) {
answer[i] = L[i] * R[i];
}
return answer;
}
};
Solution2 空间复杂度为O(1)的方法

class Solution {
public:
vector productExceptSelf(vector& nums) {
int length = nums.size();
vector answer(length);
// answer[i] 表示索引 i 左侧所有元素的乘积
// 因为索引为 '0' 的元素左侧没有元素, 所以 answer[0] = 1
answer[0] = 1;
for (int i = 1; i < length; i++) {
answer[i] = nums[i - 1] * answer[i - 1];
}
// R 为右侧所有元素的乘积
// 刚开始右边没有元素,所以 R = 1
int R = 1;
for (int i = length - 1; i >= 0; i--) {
// 对于索引 i,左边的乘积为 answer[i],右边的乘积为 R
answer[i] = answer[i] * R;
// R 需要包含右边所有的乘积,所以计算下一个结果时需要将当前值乘到 R 上
R *= nums[i];
}
return answer;
}
};
240. 搜索二维矩阵 II
编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
每行的元素从左到右升序排列。
每列的元素从上到下升序排列。
示例 1:
输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 5
输出:true
示例 2:
输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 20
输出:false

提示:
m == matrix.length
n == matrix[i].length
1 <= n, m <= 300
-109 <= matrix[i][j] <= 109
每行的所有元素从左到右升序排列
每列的所有元素从上到下升序排列
-109 <= target <= 109

Solution0 暴力
Solution1 从右上角看是一颗二叉搜索树
class Solution {
public:
bool searchMatrix(vector>& matrix, int target) {
if(matrix.size() == 0) {
return false;
}
int i = 0;
int j = matrix[0].size()-1;
while(i < matrix.size() && j >= 0) {
if(matrix[i][j] == target) {
return true;
}
if(matrix[i][j] < target) {
++ i;
}
else {
-- j;
}
}
return false;
}
};
242. 有效的字母异位词
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。
示例 1:
输入: s = “anagram”, t = “nagaram”
输出: true
示例 2:
输入: s = “rat”, t = “car”
输出: false
提示:
1 <= s.length, t.length <= 5 * 104
s 和 t 仅包含小写字母
Hash Table
This idea uses a hash table to record the times of appearances of each letter in the two strings s and t. For each letter in s, it increases the counter by 1 while for each letter in t, it decreases the counter by 1. Finally, all the counters will be 0 if they two are anagrams of each other.
The first implementation uses the built-in unordered_map and takes 36 ms.
class Solution {
public:
bool isAnagram(string s, string t) {
if (s.length() != t.length()) return false;
int n = s.length();
unordered_map counts;
for (int i = 0; i < n; i++) {
counts[s[i]]++;
counts[t[i]]--;
}
for (auto count : counts)
if (count.second) return false;
return true;
}
};
Since the problem statement says that "the string contains only lowercase alphabets", we can simply use an array to simulate the unordered_map and speed up the code. The following implementation takes 12 ms.
class Solution {
public:
bool isAnagram(string s, string t) {
if (s.length() != t.length()) return false;
int n = s.length();
int counts[26] = {0};
for (int i = 0; i < n; i++) {
counts[s[i] - 'a']++;
counts[t[i] - 'a']--;
}
for (int i = 0; i < 26; i++)
if (counts[i]) return false;
return true;
}
};
Sorting
For two anagrams, once they are sorted in a fixed order, they will become the same. This code is much shorter (this idea can be done in just 1 line using Python as here). However, it takes much longer time --- 76 ms in C++.
class Solution {
public:
bool isAnagram(string s, string t) {
sort(s.begin(), s.end());
sort(t.begin(), t.end());
return s == t;
}
};
C++ 三种方法:
Solution1 1.直接用sort函数
class Solution {
public:
bool isAnagram(string s, string t) {
sort(s.begin(),s.end());
sort(t.begin(),t.end());
if(s==t)
return true;
else
return false;
}
};
Solution2 2.map计数
class Solution {
public:
bool isAnagram(string s, string t) {
unordered_map
if (s.size() != t.size())
return false;
for(int i=0;i
–map[t[i]];
}
for(unordered_map
if(it->second!=0)
return false;
}
return true;
}
};
Solution3 3.效率最高
class Solution {
public:
bool isAnagram(string s, string t) {
int num[26]={0};
if(s.length()!=t.length())
return false;
for(int i=0;s[i]!=‘\0’;i++){
num[s[i]-‘a’]++;
num[t[i]-‘a’]–;
}
for(int i=0;i<26;i++)
if(num[i]!=0)
return false;
return true;
}
};
258. 各位相加
给定一个非负整数 num,反复将各个位上的数字相加,直到结果为一位数。返回这个结果。
示例 1:
输入: num = 38
输出: 2
解释: 各位相加的过程为:
38 --> 3 + 8 --> 11
11 --> 1 + 1 --> 2
由于 2 是一位数,所以返回 2。
示例 1:
输入: num = 0
输出: 0
提示:
0 <= num <= 231 - 1
进阶:你可以不使用循环或者递归,在 O(1) 时间复杂度内解决这个问题吗?
Math's Explained :-
Any number where it's digits add to 9 is always divisible by 9. (18, 27, 36, 45, 54, 63, 72, 81, 90, etc.) Therefore the 'digital root' for any number divisible by 9 is always 9. You can see this even in larger numbers like 99 because 9 + 9 = 18, and then 1 + 8 = 9 still, so the root always becomes 9 for any numbers divisible by 9.
Additionally, 0 always has a digital root of 0 obviously.
The only other cases you need to worry about to find the digital root are when it isn't 0 or 9.
So for any number that isn't 0 and isn't divisible by 9, the root will always n % 9 for a given number n. (AKA the difference between given number n and the nearest number that is divisible by 9, since numbers divisible by 9 always have a digital root of 9).
For examples: 100 % 9 = 1 (one greater than 99, which is divisible by 9).
101 % 9 = 2
102 % 9 = 3 and so on.
This explanation/algorithm skips the whole "add digits until there is only 1 remaining", so the description of this problem seems pretty misleading to me since it makes you think the solution will be something unrelated to the optimal one. I guess the point of Leetcode is to learn all of these tricks though.
Solution1 : 找规律
除了传统的单纯循环,还可以找规律。假如一个三位数’abc’,其值大小为s1 = 100 * a + 10 * b + 1 * c,经过一次各位相加后,变为s2 = a + b + c,减小的差值为(s1 -s2) = 99 * a + 9 * b,差值可以被9整除,每一个循环都这样,缩小了9的倍数。当num小于9,即只有一位时,直接返回num,大于9时,如果能被9整除,则返回9(因为不可能返回0也不可能返回两位数及以上的值),如果不能被整除,就返回被9除的余数。
class Solution:
def addDigits(self, num: int) -> int:
if num > 9:
num = num % 9
if num == 0:
return 9
return num
Solution2 :循环

268. 丢失的数字
给定一个包含 [0, n] 中 n 个数的数组 nums ,找出 [0, n] 这个范围内没有出现在数组中的那个数。
示例 1:
输入:nums = [3,0,1]
输出:2
解释:n = 3,因为有 3 个数字,所以所有的数字都在范围 [0,3] 内。2 是丢失的数字,因为它没有出现在 nums 中。
示例 2:
输入:nums = [0,1]
输出:2
解释:n = 2,因为有 2 个数字,所以所有的数字都在范围 [0,2] 内。2 是丢失的数字,因为它没有出现在 nums 中。
示例 3:
输入:nums = [9,6,4,2,3,5,7,0,1]
输出:8
解释:n = 9,因为有 9 个数字,所以所有的数字都在范围 [0,9] 内。8 是丢失的数字,因为它没有出现在 nums 中。
示例 4:
输入:nums = [0]
输出:1
解释:n = 1,因为有 1 个数字,所以所有的数字都在范围 [0,1] 内。1 是丢失的数字,因为它没有出现在 nums 中。
提示:
n == nums.length
1 <= n <= 104
0 <= nums[i] <= n
nums 中的所有数字都 独一无二
The basic idea is to use XOR operation. We all know that a^b^b =a, which means two xor operations with the same number will eliminate the number and reveal the original number.
In this solution, I apply XOR operation to both the index and value of the array. In a complete array with no missing numbers, the index and value should be perfectly corresponding( nums[index] = index), so in a missing array, what left finally is the missing number.
Solution1 排序

Solution2 求和

Solution3 位运算

Solution4 哈希

动态规划:279. 完全平方数
给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。
完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
示例 1:
输入:n = 12
输出:3
解释:12 = 4 + 4 + 4
示例 2:
输入:n = 13
输出:2
解释:13 = 4 + 9
Idea:
This question is very similar to coin change https://leetcode.com/problems/coin-change/discuss/1104203/C%2B%2B-Super-Simple-and-Short-Dynamic-Programming-Solution.
The only difference is that in coin change we get a vector of coins and here we know that the coins are all the perfect squares.
So our first step will be to construct a "coin" vector.
Then, we do it the same way as coin change.
Solution1 动态规划

Solution2 数学

class Solution {
public:
// 判断是否为完全平方数
bool isPerfectSquare(int x) {
int y = sqrt(x);
return y * y == x;
}
// 判断是否能表示为 4^k*(8m+7)
bool checkAnswer4(int x) {
while (x % 4 == 0) {
x /= 4;
}
return x % 8 == 7;
}
int numSquares(int n) {
if (isPerfectSquare(n)) {
return 1;
}
if (checkAnswer4(n)) {
return 4;
}
for (int i = 1; i * i <= n; i++) {
int j = n - i * i;
if (isPerfectSquare(j)) {
return 2;
}
}
return 3;
}
};
283. 移动零
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
请注意 ,必须在不复制数组的情况下原地对数组进行操作。
示例 1:
输入: nums = [0,1,0,3,12]
输出: [1,3,12,0,0]
示例 2:
输入: nums = [0]
输出: [0]
提示:
1 <= nums.length <= 104
-231 <= nums[i] <= 231 - 1
Solution
This question comes under a broad category of "Array Transformation". This category is the meat of tech interviews. Mostly because arrays are such a simple and easy to use data structure. Traversal or representation doesn't require any boilerplate code and most of your code will look like the Pseudocode itself.
The 2 requirements of the question are:
Move all the 0's to the end of array.
All the non-zero elements must retain their original order.
It's good to realize here that both the requirements are mutually exclusive, i.e., you can solve the individual sub-problems and then combine them for the final solution.
Approach #1 (Space Sub-Optimal) [Accepted]
C++
void moveZeroes(vector& nums) {
int n = nums.size();
// Count the zeroes
int numZeroes = 0;
for (int i = 0; i < n; i++) {
numZeroes += (nums[i] == 0);
}
// Make all the non-zero elements retain their original order.
vector ans;
for (int i = 0; i < n; i++) {
if (nums[i] != 0) {
ans.push_back(nums[i]);
}
}
// Move all zeroes to the end
while (numZeroes--) {
ans.push_back(0);
}
// Combine the result
for (int i = 0; i < n; i++) {
nums[i] = ans[i];
}
}
Complexity Analysis
Space Complexity : O(n)O(n). Since we are creating the "ans" array to store results.
Time Complexity: O(n)O(n). However, the total number of operations are sub-optimal. We can achieve the same result in less number of operations.
If asked in an interview, the above solution would be a good start. You can explain the interviewer(not code) the above and build your base for the next Optimal Solution.
Approach #2 (Space Optimal, Operation Sub-Optimal) [Accepted]
This approach works the same way as above, i.e. , first fulfills one requirement and then another. The catch? It does it in a clever way. The above problem can also be stated in alternate way, " Bring all the non 0 elements to the front of array keeping their relative order same".
This is a 2 pointer approach. The fast pointer which is denoted by variable "cur" does the job of processing new elements. If the newly found element is not a 0, we record it just after the last found non-0 element. The position of last found non-0 element is denoted by the slow pointer "lastNonZeroFoundAt" variable. As we keep finding new non-0 elements, we just overwrite them at the "lastNonZeroFoundAt + 1" 'th index. This overwrite will not result in any loss of data because we already processed what was there(if it were non-0,it already is now written at it's corresponding index,or if it were 0 it will be handled later in time).
After the "cur" index reaches the end of array, we now know that all the non-0 elements have been moved to beginning of array in their original order. Now comes the time to fulfil other requirement, "Move all 0's to the end". We now simply need to fill all the indexes after the "lastNonZeroFoundAt" index with 0.
C++
void moveZeroes(vector& nums) {
int lastNonZeroFoundAt = 0;
// If the current element is not 0, then we need to
// append it just in front of last non 0 element we found.
for (int i = 0; i < nums.size(); i++) {
if (nums[i] != 0) {
nums[lastNonZeroFoundAt++] = nums[i];
}
}
// After we have finished processing new elements,
// all the non-zero elements are already at beginning of array.
// We just need to fill remaining array with 0's.
for (int i = lastNonZeroFoundAt; i < nums.size(); i++) {
nums[i] = 0;
}
}
Complexity Analysis
Space Complexity : O(1)O(1). Only constant space is used.
Time Complexity: O(n)O(n). However, the total number of operations are still sub-optimal. The total operations (array writes) that code does is nn (Total number of elements).
Approach #3 (Optimal) [Accepted]
The total number of operations of the previous approach is sub-optimal. For example, the array which has all (except last) leading zeroes: [0, 0, 0, ..., 0, 1].How many write operations to the array? For the previous approach, it writes 0's n-1n−1 times, which is not necessary. We could have instead written just once. How? ..... By only fixing the non-0 element,i.e., 1.
The optimal approach is again a subtle extension of above solution. A simple realization is if the current element is non-0, its' correct position can at best be it's current position or a position earlier. If it's the latter one, the current position will be eventually occupied by a non-0 ,or a 0, which lies at a index greater than 'cur' index. We fill the current position by 0 right away,so that unlike the previous solution, we don't need to come back here in next iteration.
In other words, the code will maintain the following invariant:
All elements before the slow pointer (lastNonZeroFoundAt) are non-zeroes.
All elements between the current and slow pointer are zeroes.
Therefore, when we encounter a non-zero element, we need to swap elements pointed by current and slow pointer, then advance both pointers. If it's zero element, we just advance current pointer.
With this invariant in-place, it's easy to see that the algorithm will work.
C++
void moveZeroes(vector& nums) {
for (int lastNonZeroFoundAt = 0, cur = 0; cur < nums.size(); cur++) {
if (nums[cur] != 0) {
swap(nums[lastNonZeroFoundAt++], nums[cur]);
}
}
}
Complexity Analysis
Space Complexity : O(1)O(1). Only constant space is used.
Time Complexity: O(n)O(n). However, the total number of operations are optimal. The total operations (array writes) that code does is Number of non-0 elements.This gives us a much better best-case (when most of the elements are 0) complexity than last solution. However, the worst-case (when all elements are non-0) complexity for both the algorithms is same.
Solution1
void moveZeroes(int* nums, int numsSize) {
int i = 0,j = 0;
for(i = 0 ; i < numsSize; i++)
{
if(nums[i] != 0)
{
nums[j++] = nums[i];
}
}
while(j < numsSize)
{
nums[j++] = 0;
}
}
二分:287. 寻找重复数
给定一个包含 n + 1 个整数的数组 nums ,其数字都在 [1, n] 范围内(包括 1 和 n),可知至少存在一个重复的整数。
假设 nums 只有 一个重复的整数 ,返回 这个重复的数 。
你设计的解决方案必须 不修改 数组 nums 且只用常量级 O(1) 的额外空间。
示例 1:
输入:nums = [1,3,4,2,2]
输出:2
示例 2:
输入:nums = [3,1,3,4,2]
输出:3
提示:
1 <= n <= 105
nums.length == n + 1
1 <= nums[i] <= n
nums 中 只有一个整数 出现 两次或多次 ,其余整数均只出现 一次
进阶:
如何证明 nums 中至少存在一个重复的数字?
你可以设计一个线性级时间复杂度 O(n) 的解决方案吗?
Overview
Finding the Duplicate Number is a classic problem, and as such there are many different ways to approach it; a total of 7 approaches are presented here. The first 4 approaches involve rearranging or modifying elements of the array, and hence do not meet the constraints specified in the problem statement. However, they are included here since they are more feasible to come up with as the first approach in an interview setting. Since each approach is independent of the other approaches, they can be read in any order.
Proof
Proving that at least one duplicate must exist in numsnums is an application of the pigeonhole principle. Here, each number in numsnums is a "pigeon" and each distinct number that can appear in numsnums is a "pigeonhole." Because there are n+1n+1 numbers and nn distinct possible numbers, the pigeonhole principle implies that if you were to put each of the n + 1n+1 pigeons into nn pigeonholes, at least one of the pigeonholes would have 2 or more pigeons.
Approach 1: Sort
Note: This approach modifies individual elements and does not use constant space, and hence does not meet the problem constraints. However, it utilizes a fundamental concept that can help solve similar problems.
Intuition
In an unsorted array, duplicate elements may be scattered across the array. However, in a sorted array, duplicate numbers will be next to each other.
Algorithm
Sort the input array (numsnums).
Iterate through the array, comparing the current number to the previous number (i.e. compare nums[i]nums[i] to nums[i - 1]nums[i−1] where i > 0i>0).
Return the first number that is equal to its predecessor.
Complexity Analysis
Time Complexity: O(n \log n)O(nlogn)
Sorting takes O(n \log n)O(nlogn) time. This is followed by a linear scan, resulting in a total of O(n \log n)O(nlogn) + O(n)O(n) = O(n \log n)O(nlogn) time.
Space Complexity: O(\log n)O(logn) or O(n)O(n)
The space complexity of the sorting algorithm depends on the implementation of each programming language:
In Java, Arrays.sort() for primitives is implemented using a variant of the Quick Sort algorithm, which has a space complexity of O(\log n)O(logn)
In C++, the sort() function provided by STL uses a hybrid of Quick Sort, Heap Sort and Insertion Sort, with a worst case space complexity of O(\log n)O(logn)
In Python, the sort() function is implemented using the Timsort algorithm, which has a worst-case space complexity of O(n)O(n)
Approach 2: Set
Note: This approach does not use constant space, and hence does not meet the problem constraints. However, it utilizes a fundamental concept that can help solve similar problems.
Intuition
As we traverse the array, we need a way to "remember" values that we've seen. If we come across a number that we've seen before, we've found the duplicate. An efficient way to record the seen values is by adding each number to a set as we iterate over the numsnums array.
Algorithm
In order to achieve linear time complexity, we need to be able to insert elements into a data structure and look them up in constant time. A HashSet/unordered_set is well suited for this purpose. Initialize an empty hashset, seenseen.
Iterate over the array and first check if the current element exists in the hashset (seenseen).
If it does exist in the hashset, that number is the duplicate and can be returned right away.
Otherwise, insert the current element into seenseen, move to the next element in the array and repeat step 2.
Complexity Analysis
Time Complexity: O(n)O(n)
HashSet insertions and lookups have amortized constant time complexities. Hence, this algorithm requires linear time, since it consists of a single for loop that iterates over each element, looking up the element and inserting it into the set at most once.
Space Complexity: O(n)O(n)
We use a set that may need to store at most nn elements, leading to a linear space complexity of O(n)O(n).
Solution1 二分法

class Solution {
public:
int findDuplicate(vector& nums) {
int n = nums.size();
int l = 1, r = n - 1, ans = -1;
while (l <= r) {
int mid = (l + r) >> 1;
int cnt = 0;
for (int i = 0; i < n; ++i) {
cnt += nums[i] <= mid;
}
if (cnt <= mid) {
l = mid + 1;
} else {
r = mid - 1;
ans = mid;
}
}
return ans;
}
};
Solution2 二进制

class Solution {
public:
int findDuplicate(vector& nums) {
int n = nums.size(), ans = 0;
// 确定二进制下最高位是多少
int bit_max = 31;
while (!((n - 1) >> bit_max)) {
bit_max -= 1;
}
for (int bit = 0; bit <= bit_max; ++bit) {
int x = 0, y = 0;
for (int i = 0; i < n; ++i) {
if (nums[i] & (1 << bit)) {
x += 1;
}
if (i >= 1 && (i & (1 << bit))) {
y += 1;
}
}
if (x > y) {
ans |= 1 << bit;
}
}
return ans;
}
};
Solution3 快慢指针


class Solution {
public:
int findDuplicate(vector& nums) {
int slow = 0, fast = 0;
do {
slow = nums[slow];
fast = nums[nums[fast]];
} while (slow != fast);
slow = 0;
while (slow != fast) {
slow = nums[slow];
fast = nums[fast];
}
return slow;
}
};
292. Nim 游戏

Solution
You can always win a Nim game if the number of stones nn in the pile is not divisible by 44.
Reasoning
Let us think of the small cases. It is clear that if there are only one, two, or three stones in the pile, and it is your turn, you can win the game by taking all of them. Like the problem description says, if there are exactly four stones in the pile, you will lose. Because no matter how many you take, you will leave some stones behind for your opponent to take and win the game. So in order to win, you have to ensure that you never reach the situation where there are exactly four stones on the pile on your turn.
Similarly, if there are five, six, or seven stones you can win by taking just enough to leave four stones for your opponent so that they lose. But if there are eight stones on the pile, you will inevitably lose, because regardless whether you pick one, two or three stones from the pile, your opponent can pick three, two or one stone to ensure that, again, four stones will be left to you on your turn.
It is obvious that the same pattern repeats itself for n=4,8,12,16,\dotsn=4,8,12,16,…, basically all multiples of 44.
Complexity Analysis
Time complexity: O(1)O(1)
Only one check is performed.
Space complexity: O(1)O(1)
No additional space is used, so space complexity is also O(1)O(1).
Solution1 数学推理

动态规划:300. 最长递增子序列
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。
示例 1:
输入:nums = [10,9,2,5,3,7,101,18]
输出:4
解释:最长递增子序列是 [2,3,7,101],因此长度为 4 。
示例 2:
输入:nums = [0,1,0,3,2,3]
输出:4
示例 3:
输入:nums = [7,7,7,7,7,7,7]
输出:1
提示:
1 <= nums.length <= 2500
-104 <= nums[i] <= 104
进阶:
你能将算法的时间复杂度降低到 O(n log(n)) 吗?
✔️ Solution 1: Dynamic Programming
This is a classic Dynamic Programming problem.
Let dp[i] is the longest increase subsequence of nums[0..i] which has nums[i] as the end element of the subsequence.
Complexity
Time: O(N^2), where N <= 2500 is the number of elements in array nums.
Space: O(N)
✔️ Solution 2: Greedy with Binary Search
Let's construct the idea from following example.
Consider the example nums = [2, 6, 8, 3, 4, 5, 1], let's try to build the increasing subsequences starting with an empty one: sub1 = [].
Let pick the first element, sub1 = [2].
6 is greater than previous number, sub1 = [2, 6]
8 is greater than previous number, sub1 = [2, 6, 8]
3 is less than previous number, we can't extend the subsequence sub1, but we must keep 3 because in the future there may have the longest subsequence start with [2, 3], sub1 = [2, 6, 8], sub2 = [2, 3].
With 4, we can't extend sub1, but we can extend sub2, so sub1 = [2, 6, 8], sub2 = [2, 3, 4].
With 5, we can't extend sub1, but we can extend sub2, so sub1 = [2, 6, 8], sub2 = [2, 3, 4, 5].
With 1, we can't extend neighter sub1 nor sub2, but we need to keep 1, so sub1 = [2, 6, 8], sub2 = [2, 3, 4, 5], sub3 = [1].
Finally, length of longest increase subsequence = len(sub2) = 4.
In the above steps, we need to keep different sub arrays (sub1, sub2..., subk) which causes poor performance. But we notice that we can just keep one sub array, when new number x is not greater than the last element of the subsequence sub, we do binary search to find the smallest element >= x in sub, and replace with number x.
Let's run that example nums = [2, 6, 8, 3, 4, 5, 1] again:
Let pick the first element, sub = [2].
6 is greater than previous number, sub = [2, 6]
8 is greater than previous number, sub = [2, 6, 8]
3 is less than previous number, so we can't extend the subsequence sub. We need to find the smallest number >= 3 in sub, it's 6. Then we overwrite it, now sub = [2, 3, 8].
4 is less than previous number, so we can't extend the subsequence sub. We overwrite 8 by 4, so sub = [2, 3, 4].
5 is greater than previous number, sub = [2, 3, 4, 5].
1 is less than previous number, so we can't extend the subsequence sub. We overwrite 2 by 1, so sub = [1, 3, 4, 5].
Finally, length of longest increase subsequence = len(sub) = 4.
Complexity
Time: O(N * logN), where N <= 2500 is the number of elements in array nums.
Space: O(N), we can achieve O(1) in space by overwriting values of sub into original nums array.
Complexity:
Time: O(N * logN)
Space: O(N)
Solution1 动态规划

class Solution {
public:
int lengthOfLIS(vector& nums) {
int n = (int)nums.size();
if (n == 0) {
return 0;
}
vector dp(n, 0);
for (int i = 0; i < n; ++i) {
dp[i] = 1;
for (int j = 0; j < i; ++j) {
if (nums[j] < nums[i]) {
dp[i] = max(dp[i], dp[j] + 1);
}
}
}
return *max_element(dp.begin(), dp.end());
}
};

Solution2 贪心

class Solution {
public:
int lengthOfLIS(vector& nums) {
int len = 1, n = (int)nums.size();
if (n == 0) {
return 0;
}
vector d(n + 1, 0);
d[len] = nums[0];
for (int i = 1; i < n; ++i) {
if (nums[i] > d[len]) {
d[++len] = nums[i];
} else {
int l = 1, r = len, pos = 0; // 如果找不到说明所有的数都比 nums[i] 大,此时要更新 d[1],所以这里将 pos 设为 0
while (l <= r) {
int mid = (l + r) >> 1;
if (d[mid] < nums[i]) {
pos = mid;
l = mid + 1;
} else {
r = mid - 1;
}
}
d[pos + 1] = nums[i];
}
}
return len;
}
};
动态规划:313. 超级丑数
超级丑数 是一个正整数,并满足其所有质因数都出现在质数数组 primes 中。
给你一个整数 n 和一个整数数组 primes ,返回第 n 个 超级丑数 。
题目数据保证第 n 个 超级丑数 在 32-bit 带符号整数范围内。
示例 1:
输入:n = 12, primes = [2,7,13,19]
输出:32
解释:给定长度为 4 的质数数组 primes = [2,7,13,19],前 12 个超级丑数序列为:[1,2,4,7,8,13,14,16,19,26,28,32] 。
示例 2:
输入:n = 1, primes = [2,3,5]
输出:1
解释:1 不含质因数,因此它的所有质因数都在质数数组 primes = [2,3,5] 中。
提示:
1 <= n <= 105
1 <= primes.length <= 100
2 <= primes[i] <= 1000
题目数据 保证 primes[i] 是一个质数
primes 中的所有值都 互不相同 ,且按 递增顺序 排列
It is actually like how we merge k sorted list:
ugly number k sorted list
1 2 7 13 19 1 * [2,7,13,19]
| | | | |
2 4 14 26 38 2 * [2,7,13,19]
| | | | |
4 8 28 52 76 4 * [2,7,13,19]
| | | | |
7 14 49 91 133 7 * [2,7,13,19]
| | | | |
8 16 56 ... ... 8 * [2,7,13,19]
| | | | |
. . . . .
. . . . .
. . . . .
We can see that each prime number in primes[] form a sorted list, and now our job is to merge them and find the nth minimum.
Here we don't have the next pointer for each node to trace the next potential candidate. But as we can see in the graph, we can make use of the ugly number we have produced so far!
Solution1 最小堆

class Solution {
public int nthSuperUglyNumber(int n, int[] primes) {
PriorityQueuequeue=new PriorityQueue<>();
long res=1;
for(int i=1;i Solution2 动态规划

class Solution {
public:
int nthSuperUglyNumber(int n, vector& primes) {
vector dp(n + 1); //用来存储丑数序列
dp[1] = 1; //第一个丑数是1
int m = primes.size();
vector nums(m); //记录新丑数序列
vector pointers(m, 1); //记录质数该与哪一位丑数做乘积
for (int i = 2; i <= n; i++) {
int minn = INT_MAX;
for (int j = 0; j < m; j++) {
nums[j] = dp[pointers[j]] * primes[j]; //旧丑数 * 质数序列 = 新丑数序列
minn = min(minn, nums[j]); //寻找所有新丑数中最小的丑数
}
dp[i] = minn;
for (int j = 0; j < m; j++)
if (minn == nums[j]) //如果此位置已经诞生过最小丑数
pointers[j]++; //让此位置所取旧丑数向后推一位
}
return dp[n];
}
};
动态规划/递归:322. 零钱兑换
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
你可以认为每种硬币的数量是无限的。
示例 1:
输入:coins = [1, 2, 5], amount = 11
输出:3
解释:11 = 5 + 5 + 1
示例 2:
输入:coins = [2], amount = 3
输出:-1
示例 3:
输入:coins = [1], amount = 0
输出:0
提示:
1 <= coins.length <= 12
1 <= coins[i] <= 231 - 1
0 <= amount <= 104
If you carefully observe the below 3 codes. You will see that the DP Memoization is dervied from the Recursion code just by changing 3 lines and the DP Tabulation is derived from the DP Memoization.
Recursion
Time: O(2^n)
Space: O(n)
Writing a recursive function is all about find two things:
The base case: Just calculate the output for the smallest possible input
The choice diagram: For any given input, just see what all choices do we have.
DP Memoization
Time: O(n.m)
Space: O(n.m)
In the above recursive case, we were doing repeated work in the form of subproblems. Hence we store the results of those subproblems in a table to reduce the number of recursive calls.
DP Tabulation
Time: O(n.m)
Space: O(n.m)
We have reached the best conceivable run time for this question but since we have recursive calls in the previous algorithm. It might lead to stackoverflow error in the worst case when recursive calls are a lot. Hence we want to totally emit the notion of recursions. To do that, we simply convert the recursion into iterative code.
The below code is bottom up dynamic programming because we are starting from the first element in the 2D array and filling the DP from this first element till the last element. And eventually, the last cell stores our final result.
Solution1 动态规划

class Solution {
public:
int coinChange(vector& coins, int amount) {
int Max = amount + 1;
vector dp(amount + 1, Max);
dp[0] = 0;
for (int i = 1; i <= amount; ++i) {
for (int j = 0; j < (int)coins.size(); ++j) {
if (coins[j] <= i) {
dp[i] = min(dp[i], dp[i - coins[j]] + 1);
}
}
}
return dp[amount] > amount ? -1 : dp[amount];
}
};
Solution2 贪心+回溯+剪枝


void coinChange(vector& coins, int amount, int c_index, int count, int& ans) {
if (amount == 0) {
ans = min(ans, count);
return;
}
if (c_index == coins.size()) return;
for (int k = amount / coins[c_index]; k >= 0 && k + count < ans; k--) {
coinChange(coins, amount - k * coins[c_index], c_index + 1, count + k, ans);
}
}
int coinChange(vector& coins, int amount) {
if (amount == 0) return 0;
sort(coins.rbegin(), coins.rend());
int ans = INT_MAX;
coinChange(coins, amount, 0, 0, ans);
return ans == INT_MAX ? -1 : ans;
}
326.3的幂



Solution1 试除法

Solution2 约数法

328. 奇偶链表


Solution1 双链法
结点1作为奇数链的头 结点2作为偶数链的头
从第3个点开始遍历,依次轮流附在奇、偶链的后面
遍历完后,奇数链的尾连向偶链的头,偶链的尾为空, 返回奇数链的头
class Solution {
public:
ListNode* oddEvenList(ListNode* head) {
if (head == nullptr) {
return head;
}
ListNode* evenHead = head->next;
ListNode* odd = head;
ListNode* even = evenHead;
while (even != nullptr && even->next != nullptr) {
odd->next = even->next;
odd = odd->next;
even->next = odd->next;
even = even->next;
}
odd->next = evenHead;
return head;
}
};
复杂度分析
时间复杂度:O(n)O(n),其中 nn 是链表的节点数。需要遍历链表中的每个节点,并更新指针。
空间复杂度:O(1)O(1)。只需要维护有限的指针。
334. 递增的三元子序列
给你一个整数数组 nums ,判断这个数组中是否存在长度为 3 的递增子序列。
如果存在这样的三元组下标 (i, j, k) 且满足 i < j < k ,使得 nums[i] < nums[j] < nums[k] ,返回 true ;否则,返回 false 。
示例 1:
输入:nums = [1,2,3,4,5]
输出:true
解释:任何 i < j < k 的三元组都满足题意
示例 2:
输入:nums = [5,4,3,2,1]
输出:false
解释:不存在满足题意的三元组
示例 3:
输入:nums = [2,1,5,0,4,6]
输出:true
解释:三元组 (3, 4, 5) 满足题意,因为 nums[3] == 0 < nums[4] == 4 < nums[5] == 6
提示:
1 <= nums.length <= 5 * 105
-231 <= nums[i] <= 231 - 1
bool increasingTriplet(vector& nums) {
int c1 = INT_MAX, c2 = INT_MAX;
for (int x : nums) {
if (x <= c1) {
c1 = x; // c1 is min seen so far (it's a candidate for 1st element)
} else if (x <= c2) { // here when x > c1, i.e. x might be either c2 or c3
c2 = x; // x is better than the current c2, store it
} else { // here when we have/had c1 < c2 already and x > c2
return true; // the increasing subsequence of 3 elements exists
}
}
return false;
}
Solution1 贪心

Solution2 双向遍历

class Solution {
public:
bool increasingTriplet(vector& nums) {
int n = nums.size();
if (n < 3) {
return false;
}
vector leftMin(n);
leftMin[0] = nums[0];
for (int i = 1; i < n; i++) {
leftMin[i] = min(leftMin[i - 1], nums[i]);
}
vector rightMax(n);
rightMax[n - 1] = nums[n - 1];
for (int i = n - 2; i >= 0; i--) {
rightMax[i] = max(rightMax[i + 1], nums[i]);
}
for (int i = 1; i < n - 1; i++) {
if (nums[i] > leftMin[i - 1] && nums[i] < rightMax[i + 1]) {
return true;
}
}
return false;
}
};
复杂度分析
时间复杂度:O(n),其中 nn 是数组 \textit{nums}nums 的长度。需要遍历数组三次。
空间复杂度:O(n),其中 nn 是数组 \textit{nums}nums 的长度。需要创建两个长度为 nn 的数组 \textit{leftMin}leftMin 和 \textit{rightMax}rightMax。
树/动态规划: 337. 打家劫舍 III

Step I -- Think naively
At first glance, the problem exhibits the feature of "optimal substructure": if we want to rob maximum amount of money from current binary tree (rooted at root), we surely hope that we can do the same to its left and right subtrees.
So going along this line, let's define the function rob(root) which will return the maximum amount of money that we can rob for the binary tree rooted at root; the key now is to construct the solution to the original problem from solutions to its subproblems, i.e., how to get rob(root) from rob(root.left), rob(root.right), ... etc.
Apparently the analyses above suggest a recursive solution. And for recursion, it's always worthwhile figuring out the following two properties:
Termination condition: when do we know the answer to rob(root) without any calculation? Of course when the tree is empty ---- we've got nothing to rob so the amount of money is zero.
Recurrence relation: i.e., how to get rob(root) from rob(root.left), rob(root.right), ... etc. From the point of view of the tree root, there are only two scenarios at the end: root is robbed or is not. If it is, due to the constraint that "we cannot rob any two directly-linked houses", the next level of subtrees that are available would be the four "grandchild-subtrees" (root.left.left, root.left.right, root.right.left, root.right.right). However if root is not robbed, the next level of available subtrees would just be the two "child-subtrees" (root.left, root.right). We only need to choose the scenario which yields the larger amount of money.
However the solution runs very slowly (1186 ms) and barely got accepted (the time complexity turns out to be exponential, see my comments below).
Step II -- Think one step further
In step I, we only considered the aspect of "optimal substructure", but think little about the possibilities of overlapping of the subproblems. For example, to obtain rob(root), we need rob(root.left), rob(root.right), rob(root.left.left), rob(root.left.right), rob(root.right.left), rob(root.right.right); but to get rob(root.left), we also need rob(root.left.left), rob(root.left.right), similarly for rob(root.right). The naive solution above computed these subproblems repeatedly, which resulted in bad time performance. Now if you recall the two conditions for dynamic programming (DP): "optimal substructure" + "overlapping of subproblems", we actually have a DP problem. A naive way to implement DP here is to use a hash map to record the results for visited subtrees.
Step III -- Think one step back
In step I, we defined our problem as rob(root), which will yield the maximum amount of money that can be robbed of the binary tree rooted at root. This leads to the DP problem summarized in step II.
Now let's take one step back and ask why we have overlapping subproblems. If you trace all the way back to the beginning, you'll find the answer lies in the way how we have defined rob(root). As I mentioned, for each tree root, there are two scenarios: it is robbed or is not. rob(root) does not distinguish between these two cases, so "information is lost as the recursion goes deeper and deeper", which results in repeated subproblems.
If we were able to maintain the information about the two scenarios for each tree root, let's see how it plays out. Redefine rob(root) as a new function which will return an array of two elements, the first element of which denotes the maximum amount of money that can be robbed if root is not robbed, while the second element signifies the maximum amount of money robbed if it is robbed.
Let's relate rob(root) to rob(root.left) and rob(root.right)..., etc. For the 1st element of rob(root), we only need to sum up the larger elements of rob(root.left) and rob(root.right), respectively, since root is not robbed and we are free to rob its left and right subtrees. For the 2nd element of rob(root), however, we only need to add up the 1st elements of rob(root.left) and rob(root.right), respectively, plus the value robbed from root itself, since in this case it's guaranteed that we cannot rob the nodes of root.left and root.right.
As you can see, by keeping track of the information of both scenarios, we decoupled the subproblems and the solution essentially boiled down to a greedy one. Here is the program:
Solution1 动态规划

class Solution {
public:
unordered_map f, g;
void dfs(TreeNode* node) {
if (!node) {
return;
}
dfs(node->left);
dfs(node->right);
f[node] = node->val + g[node->left] + g[node->right];
g[node] = max(f[node->left], g[node->left]) + max(f[node->right], g[node->right]);
}
int rob(TreeNode* root) {
dfs(root);
return max(f[root], g[root]);
}
};
位运算:338. 比特位计数\
给你一个整数 n ,对于 0 <= i <= n 中的每个 i ,计算其二进制表示中 1 的个数 ,返回一个长度为 n + 1 的数组 ans 作为答案。
示例 1:
输入:n = 2
输出:[0,1,1]
解释:
0 --> 0
1 --> 1
2 --> 10
示例 2:
输入:n = 5
输出:[0,1,1,2,1,2]
解释:
0 --> 0
1 --> 1
2 --> 10
3 --> 11
4 --> 100
5 --> 101
提示:
0 <= n <= 105
进阶:
很容易就能实现时间复杂度为 O(n log n) 的解决方案,你可以在线性时间复杂度 O(n) 内用一趟扫描解决此问题吗?
你能不使用任何内置函数解决此问题吗?(如,C++ 中的 __builtin_popcount )

Solution1
方法一:i & (i - 1)可以去掉i最右边的一个1(如果有),因此 i & (i - 1)是比 i 小的,而且i & (i - 1)的1的个数已经在前面算过了,所以i的1的个数就是 i & (i - 1)的1的个数加上1
public int[] countBits(int num) {
int[] res = new int[num + 1];
for(int i = 1;i<= num;i++){ //注意要从1开始,0不满足
res[i] = res[i & (i - 1)] + 1;
}
return res;
}
Solution2
方法二:i >> 1会把最低位去掉,因此i >> 1 也是比i小的,同样也是在前面的数组里算过。当 i 的最低位是0,则 i 中1的个数和i >> 1中1的个数相同;当i的最低位是1,i 中1的个数是 i >> 1中1的个数再加1
public int[] countBits(int num) {
int[] res = new int[num + 1];
for(int i = 0;i<= num;i++){
res[i] = res[i >> 1] + (i & 1); //注意i&1需要加括号
}
return res;
}
Solution3
分奇数和偶数:
偶数的二进制1个数超级简单,因为偶数是相当于被某个更小的数乘2,乘2怎么来的?在二进制运算中,就是左移一位,也就是在低位多加1个0,那样就说明dp[i] = dp[i / 2]
奇数稍微难想到一点,奇数由不大于该数的偶数+1得到,偶数+1在二进制位上会发生什么?会在低位多加1个1,那样就说明dp[i] = dp[i-1] + 1,当然也可以写成dp[i] = dp[i / 2] + 1
就这么简单!!!
class Solution {
public:
vector countBits(int num) {
int i = 1;
vector ans(num + 1);
for (int i = 0; i <= num; i++) {
if (i % 2 == 0)
ans[i] = ans[i / 2];
else
ans[i] = ans[i / 2] + 1;
}
return ans;
}
};
344. 反转字符串
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
示例 1:
输入:s = [“h”,“e”,“l”,“l”,“o”]
输出:[“o”,“l”,“l”,“e”,“h”]
示例 2:
输入:s = [“H”,“a”,“n”,“n”,“a”,“h”]
输出:[“h”,“a”,“n”,“n”,“a”,“H”]
We use here two pointers that gives us access to characters for swapping in left and right side of the string. For swapping we use a convinient C++ method swap. We just iterate over characters and swap them.
Time: O(n)
Space: O(1)
Solution1 双指针交换
class Solution {
public:
void reverseString(vector& s) {
for (int i = 0, j = s.size() - 1; i < s.size()/2; i++, j--) {
swap(s[i],s[j]);
}
}
};
堆:347. 前 K 个高频元素
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
示例 2:
输入: nums = [1], k = 1
输出: [1]
提示:
1 <= nums.length <= 105
k 的取值范围是 [1, 数组中不相同的元素的个数]
题目数据保证答案唯一,换句话说,数组中前 k 个高频元素的集合是唯一的
进阶:你所设计算法的时间复杂度 必须 优于 O(n log n) ,其中 n 是数组大小。
How's going Ladies - n - Gentlemen, today we are going to solve another coolest problem i.e. Top K Frequent Elements
Okay, so in order to solve this problem, first of all let's understand what the problem statement is:
Given an integer array nums,
and an integer k, return the k most frequent elements. You may return the answer in any order.
Okay, so wait wait listen just looking at this if you know the HashMap, you'll simply gonna say we can solve this problem easily using HashMap. And I'll say yes, exactly we gonna do the exact same thing but we will use Heap as well with HashMap, if you got the idea by listening heap. Then you had just solve the brute force approach
So, let's talk about it's
Brute Force Approach :-
Let's take an example,
Input: nums = [1,1,1,2,2,3], k = 2
Output: [1,2]
So, we have 2 step's to perform in this problem:-
HashMap
Heap
Step -1 :- Make an Frequency map & fill it with the given elements
[1,1,1,2,2,3]
------------------------------------------------
| 1 ---> | 3 |
| | |
| 2 ---> | 2 | HashMap of Integer, Integer
| | |
| 3 ---> | 1 |
------------------------------------------------
Okay, so we just had completed our step no.1 now, it;s time to move to next step
Step -2 :- Make an MaxHeap & fill it with keys & on the peek of our Heap we will be having most frequent elements
HashMap :-
Key Value
1 ----> 3
2 ----> 2
3 ----> 1
Heap :-
| 1 | from the top of the heap we'll pop that no. of element requires in our array of k size
| 2 |
| 3 |
------------
Create result array res & store K frequent elements in it.
Heap :-
| | res : [1]
| 2 |
| 3 |
------------
Heap :-
| | res : [1, 2]
| |
| 3 |
------------
As, our K is 2 we gonna only store Most frequent K elements in our array, therefore in the result we get:- [1, 2]
I hope so, ladies - n - gentlemen, this approach is absolute clear, Let's code it, up
class Solution {
public int[] topKFrequent(int[] nums, int k) {
Map map = new HashMap<>();
for(int i : nums){
map.put(i, map.getOrDefault(i, 0) + 1);
}
PriorityQueue maxHeap = new PriorityQueue<>((a,b) -> map.get(b) - map.get(a));
for(int key : map.keySet()){
maxHeap.add(key);
}
int res[] = new int[k];
for(int i = 0; i < k; i++){
res[i] = maxHeap.poll();
}
return res;
}
}
ANALYSIS :-
Time Complexity :- BigO(K log D) as we are Poll K distinct elements from the Heap & here D is no. of distinct (unique) elements in the input array
Space Complexity :- BigO(D), this is the size of the heap.
Well, this is not a super efficient Approach,
We can solve this more efficiently as well, now some of you'll ask but how!!
Well, for that we have Bucket Sorting
Optimize Approach :-
Let's understand what bucket sort is,
Bucket sort, or bin sort, is a sorting algorithm that works by distributing the elements of an array into a number of buckets. Each bucket is then sorted individually, either using a different sorting algorithm, or by recursively applying the bucket sorting algorithm.
In this process we gonna follow 3 major steps :-
Step - 1 :
Create Frequency map:
1.1 Iterate thru the given nums[] array
1.2. With each iteration - check if map already contains current key
If current key is already in the map just increase the value for this key
Else add key value pair.
Where key is current int and value is 1 (1 -> we encounter given key for the first time)
image
Step - 2 :
Create Bucket List[]:
index of bucket[] arr will represent the value from our map
Why not use int[] arr? Multiple values can have the same frequency that's why we use List[] array of lists instead of regular array
Iterate thrue the map and for each value add key at the index of that value
image
Step - 3 :
If we look at bucket arr we can see that most frequent elements are located at the end of arr
and leat frequent elemnts at the begining
Last step is to iterate from the end to the begining of the arr and add elements to result List
image
I hope so ladies - n - gentlemen Approach is absolute clear, Let's code it up
Solution1 排序法

Solution2 最小堆法

class Solution {
public:
vector topKFrequent(vector& nums, int k) {
vector res;
map freq;
using pii = std::pair;
priority_queue, greater> pq;
for (auto e : nums) ++freq[e];
for (auto& pair : freq) {
pq.emplace(pair.second, pair.first);
if (pq.size() > k) pq.pop();
}
while (!pq.empty()) {
res.emplace_back(pq.top().second);
pq.pop();
}
return res;
}
};
349. 两个数组的交集
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
解释:[4,9] 也是可通过的
Approach 1: Two Sets
Intuition
The naive approach would be to iterate along the first array nums1 and to check for each value if this value in nums2 or not. If yes - add the value to output. Such an approach would result in a pretty bad \mathcal{O}(n \times m)O(n×m) time complexity, where n and m are arrays' lengths.
To solve the problem in linear time, let's use the structure set, which provides in/contains operation in \mathcal{O}(1)O(1) time in average case.
The idea is to convert both arrays into sets, and then iterate over the smallest set checking the presence of each element in the larger set. Time complexity of this approach is \mathcal{O}(n + m)O(n+m) in the average case.
Solution1
class Solution {
public:
vector intersection(vector& nums1, vector& nums2) {
unordered_set result_set; // 存放结果,之所以用set是为了给结果集去重
int hash[1005] = {0}; // 默认数值为0
for (int num : nums1) { // nums1中出现的字母在hash数组中做记录
hash[num] = 1;
}
for (int num : nums2) { // nums2中出现话,result记录
if (hash[num] == 1) {
result_set.insert(num);
}
}
return vector(result_set.begin(), result_set.end());
}
};
Solution2
vector intersection(vector& nums1, vector& nums2) {
unordered_set result_set; // 存放结果
unordered_set nums_set(nums1.begin(), nums1.end());
for (int num : nums2) {
// 发现nums2的元素 在nums_set里又出现过
if (nums_set.find(num) != nums_set.end()) {
result_set.insert(num);
}
}
return vector(result_set.begin(), result_set.end());
}
};
371. 两整数之和
给你两个整数 a 和 b ,不使用 运算符 + 和 - ,计算并返回两整数之和。
示例 1:
输入:a = 1, b = 2
输出:3
示例 2:
输入:a = 2, b = 3
输出:5
提示:
-1000 <= a, b <= 1000
Now we can not use the + operator, which means it is obvious that we have to use some sort of bit manupulation. But the real question is how?
The ans lies within the procedure of the addition, which I am going to show you below.
from binary level, how do we exactly add two numbers, let us see -->
_
a = 2 = 010
b = 3 = 011
------------
c = 5 = 101
In the position, where we have a dash above, there we are generating a carry, which will be carried over to the next bit, and added to that next bit. So, the addition pattern goes like -
0 0 1 1
+ 0 +1 + 0 + 1
---- ---- ---- ----
0 1 1 0 (with a carry 1)
Is this pattern similar to you? Have you seen this in the XOR table? Let's see the XOR table quickly -
a b | XOR
- - | - -
0 0 | 0
0 1 | 1
1 0 | 1
1 1 | 0
These are the exact same, hence for addition, we need to use the XOR operator. But what to do with the carry? Hey, we need to add that carry to the next bit, right? That is what we have seen in the implementation of the addition as well. We will do that only, but we can NOT use addition anyway.
But, before that, let's do the XOR for 2 and 3 example.
-- Doing only XOR --
a = 2 = 010
b = 3 = 011
------------
c = 1 = 001
1 is NOT our answer, and in this procedure, we have left the carry out, which is 100. Now what's the pattern for finding the carry? It is after we AND the two numbers, we will LEFT-SHIFT the result by 1. Didn't get it?
-- Doing only AND --
a = 2 = 010
b = 3 = 011
------------
c = 2 = 010
-----------
Doing Left-Shift by 1 (<<1)
-----------
c = 4 = 100
So, we found out the carry as well, and believe me or not, but it is the entire Algorithm. You have to repeat the steps of 1. XOR and 2. AND with Left-Shift, until the step no 2. becomes 0, and you will have your answer.
Example -
a = 2 = 010
b = 3 = 011
-----------
x = 1 = 001 = a
c = 4 = 100 = b
-----------
x = 5 = 101
c = 0 = 000
x = XOR & c = AND with Left-Shift
Since carry becomes 0, hence our answer is the XOR result = 5.
Below is the working code for the same, and you can run this code to find the desired answer.
class Solution {
public int getSum(int a, int b) {
while(b != 0){
int temp = (a&b)<<1;
a = a ^ b;
b = temp;
}
return a;
}
}
Time Complexity: O(1)
Space Complexity: O(1)
Time is O(1), because the max and min bounds are 1000 and -1000 respectively, which means the input will NOT be arbitrarily large, and it will be in the limits, hence the time will be constant.
The code for c and c++ will be very similar, and python will be a little different. If you like this approach, then please give me a thumbs up.
Thanks & Happy Coding :)
Solution1 位运算
int getSum(int a, int b)
{
int sum, carry;
sum = a ^ b; //异或这里可看做是相加但是不显现进位,比如5 ^ 3
/*0 1 0 1
0 0 1 1
------------
0 1 1 0
上面的如果看成传统的加法,不就是1+1=2,进1得0,但是这里没有显示进位出来,仅是相加,0+1或者是1+0都不用进位*/
carry = (a & b) << 1;
//相与为了让进位显现出来,比如5 & 3
/* 0 1 0 1
0 0 1 1
------------
0 0 0 1
上面的最低位1和1相与得1,而在二进制加法中,这里1+1也应该是要进位的,所以刚好吻合,但是这个进位1应该要再往前一位,所以左移一位*/
if(carry != 0) //经过上面这两步,如果进位不等于0,那么就是说还要把进位给加上去,所以用了尾递归,一直递归到进位是0。
{
return getSum(sum, carry);
}
return sum;
}
378. 有序矩阵中第 K 小的元素
给你一个 n x n 矩阵 matrix ,其中每行和每列元素均按升序排序,找到矩阵中第 k 小的元素。
请注意,它是 排序后 的第 k 小元素,而不是第 k 个 不同 的元素。
你必须找到一个内存复杂度优于 O(n2) 的解决方案。
示例 1:
输入:matrix = [[1,5,9],[10,11,13],[12,13,15]], k = 8
输出:13
解释:矩阵中的元素为 [1,5,9,10,11,12,13,13,15],第 8 小元素是 13
示例 2:
输入:matrix = [[-5]], k = 1
输出:-5
提示:
n == matrix.length
n == matrix[i].length
1 <= n <= 300
-109 <= matrix[i][j] <= 109
题目数据 保证 matrix 中的所有行和列都按 非递减顺序 排列
1 <= k <= n2
进阶:
你能否用一个恒定的内存(即 O(1) 内存复杂度)来解决这个问题?
你能在 O(n) 的时间复杂度下解决这个问题吗?这个方法对于面试来说可能太超前了,但是你会发现阅读这篇文章( this paper )很有趣。
✔️ Solution 1: Max Heap keeps up to k elements
The easy approach is that we iterate all elements in the matrix and and add elements into the maxHeap. The maxHeap will keep up to k smallest elements (because when maxHeap is over size of k, we do remove the top of maxHeap which is the largest one). Finally, the top of the maxHeap is the kth smallest element in the matrix.
This approach leads this problem become the same with 215. Kth Largest Element in an Array, which doesn't take the advantage that the matrix is already sorted by rows and by columns.
Complexity:
Time: O(M * N * logK), where M <= 300 is the number of rows, N <= 300 is the number of columns.
Space: O(K), space for heap which stores up to k elements.
✔️ Solution 2: Min Heap to find kth smallest element from amongst N sorted list
Since each of the rows in matrix are already sorted, we can understand the problem as finding the kth smallest element from amongst M sorted rows.
We start the pointers to point to the beginning of each rows, then we iterate k times, for each time ith, the top of the minHeap is the ith smallest element in the matrix. We pop the top from the minHeap then add the next element which has the same row with that top to the minHeap.
Solution1 暴力
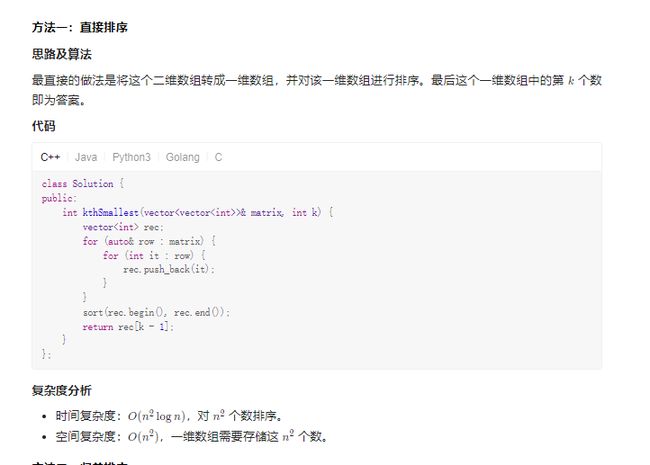
class Solution {
public:
int kthSmallest(vector>& matrix, int k) {
struct point {
int val, x, y;
point(int val, int x, int y) : val(val), x(x), y(y) {}
bool operator> (const point& a) const { return this->val > a.val; }
};
priority_queue, greater> que;
int n = matrix.size();
for (int i = 0; i < n; i++) {
que.emplace(matrix[i][0], i, 0);
}
for (int i = 0; i < k - 1; i++) {
point now = que.top();
que.pop();
if (now.y != n - 1) {
que.emplace(matrix[now.x][now.y + 1], now.x, now.y + 1);
}
}
return que.top().val;
}
};
Solution2 最小堆



394. 字符串解码
给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
示例 1:
输入:s = “3[a]2[bc]”
输出:“aaabcbc”
示例 2:
输入:s = “3[a2[c]]”
输出:“accaccacc”
示例 3:
输入:s = “2[abc]3[cd]ef”
输出:“abcabccdcdcdef”
示例 4:
输入:s = “abc3[cd]xyz”
输出:“abccdcdcdxyz”
提示:
1 <= s.length <= 30
s 由小写英文字母、数字和方括号 ‘[]’ 组成
s 保证是一个 有效 的输入。
s 中所有整数的取值范围为 [1, 300]
This is the standard solution given under the tab 'Solution' of the same problem: https://leetcode.com/problems/decode-string/solution/
We start with the original string s and index = 0. If the index is not ']', meaning its a digit or alphabet (but not '[' -> this is ensured in the later part of the code). Also note that the string won't start with '[' so there is no chance of having it initially.
First lets take the case when the string isdigit. In that case, count the number of times the inner string need to be repeated. For example 26[X], string X will be repeated 26 times and 26 is stored in k. Now increment the index -> this is done as we know that number will be accompanied by [.
Now recurse on the inner string s and also increment index, this time for ]. While recursing for inner string, if the character is not digit, we store that and return it as a string. Now remember this inner string needs to be repeated 'k' times so we add that to current return string 'ret'. Return the ret string.
Solution1 两个栈

402. 移掉 K 位数字
给你一个以字符串表示的非负整数 num 和一个整数 k ,移除这个数中的 k 位数字,使得剩下的数字最小。请你以字符串形式返回这个最小的数字。
示例 1 :
输入:num = “1432219”, k = 3
输出:“1219”
解释:移除掉三个数字 4, 3, 和 2 形成一个新的最小的数字 1219 。
示例 2 :
输入:num = “10200”, k = 1
输出:“200”
解释:移掉首位的 1 剩下的数字为 200. 注意输出不能有任何前导零。
示例 3 :
输入:num = “10”, k = 2
输出:“0”
解释:从原数字移除所有的数字,剩余为空就是 0 。
提示:
1 <= k <= num.length <= 105
num 仅由若干位数字(0 - 9)组成
除了 0 本身之外,num 不含任何前导零
KNOCKCAT
1. Easy C++
2. Line by Line Explanation with Comments.
3. Detailed Explanation ✅
4. Handwritten snap of an TestCase at the end of code given.
5. Please Upvote if it helps⬆️
6. Link to my Github Profile contains a repository of Leetcode with all my Solutions. ⬇️
LeetCode
EXPLANATION
1. Deleting k digits means keeping n - k digits, where n is the total number of digits.
2. Use a stack that you keep sorted ascendingly. You remove elements from it as long as you can still make it to n - k digits,
and your current element is smaller than the top of the stack:
push(2) => 2
push(4) because 2 < 4 => 24
push(6) because 4 < 6 => 246
pop() because 3 < 6 and we can still end up with 2 digits => 24
pop() for the same reason => 2
push(3) => 23
push(5) => 235
Then just take the first k digits => 23. Or you can make sure never to push more than k digits, and then the final stack is your solution.
3. Note that you cannot pop elements if that means you will not be able to build a solution of k digits.
For this, you need to check the current number of elements in the stack and the number of digits to the right of your current position on the input number.
Some More Points
1. Approach is simple. We need a number which is minimum, thus we need to remove the most significant digits first.
For eg. if we have a number having digits 1-4 then 1234 would be the minimum and not 2314 or anything else.
So in case of 2314, we remove 3 first, and then we go for 2 (Because they are more significant than 4). Observing this simple idea,
we need to remove any digit which is greater than its following digit. Thats why we deleted 3 as it,
was greater than 1 and similiarly 2 as it was also greater than 1.
2. In order to accomplish this, we use stack Data Structure where we pop the top if it is greater than current digit.
3. The conditions mentioned in while loop are important to avoid any Runtime Error. For eg. ["10001" 2] the answer is "0" but if we don't
mention the condition !s.empty(), then the while loop will run on empty stack and try to pop the top which doesn't exist thus throwing RE.
Time Complexity :- O(N) // as we only traversing the string for once
Space complexity:- O(N) // as we will store maximum of n digits in our string
Solution1 贪心+单调栈








