腾讯会议10秒编译百万代码|鹅厂编译加速标杆案例公开

腾小云导读
作为一个天然跨平台的产品,腾讯会议从第一行代码开始,团队就坚持同源同构的思想,即同一套架构,同一套代码,服务所有场景。过去一年,腾讯会议,迭代优化了 20000 个功能,稳定支持了数亿用户,其客户端仅上层业务逻辑代码就超 100 万行,经过优化,目前在 Windows 平台上的编译时间最快缩短到 10秒,成为行业 C++ 跨平台项目的标杆。本文将详细介绍背后的优化逻辑,希望给业界同行提供参考。
看目录,点收藏
1 编译加速有哪些方向?
2 如何优雅的预编译 Module 产物?
2.1 构建在哪执行
2.2 如何增量发布产物
2.3 预编译产物上传到何处
2.4 如何使用预编译产物
3 发布 Module 产物
4 使用Module产物
4.1 匹配产物
4.2 CMake产物替换源码编译
4.3 自动Generate
4.4 半自动Generate
4.5 IDE显示源码
5 断点调试
5.1 Android产物替换
5.2 成也Maven,败也Maven
5.3 Android Studio显示产物源码
6 万物皆可增量
7 构建参数
8 总结
01
编译加速有哪些方向?
大家知道,编译是将源代码经过编译器的预处理、编译、汇编等步骤,生成能够被计算机直接执行的机器码的过程,而这个过程是十分耗时的。
常规的开发工具如 xcode、gradle 为了提高效率都会自带编译缓存的功能,即将上一次编译的结果缓存起来,对于没有修改的代码再次编译就直接使用缓存。
但此这些缓存文件一般存在于本地,更新代码后难免需要一次重编,生成新的编译缓存。在会议这样一个上百人的团队里,修改提交十分频繁,更新一次代码所需要重编的代码量往往是十分巨大的。特别是一些被深度依赖的头文件被修改,往往等价于需要全量编译了。
虽说也有一些工具能够支持云端共享编译缓存,如 gradle 的 remote build cache,但是对 C++ 部分并没有 cache,而且方案也不能跨平台通用。
腾讯会议经历了框架 3.0 的模块化改造后,原本一整块代码按照业务拆分出了若干个小模块,开发需求修改代码逐渐集中在模块内部。这为我们的编译加速提供了新思路:每个业务模块之间是不存在依赖关系的,那么开发没有修改的模块是否可以免编译呢?

那么想要模块免编译,可行的方案有两种:
|
从长远来看,如果 Module 独立运行肯定是最优的,但是现阶段比较难实现,虽然会议的模块代码没有相互依赖,但业务功能间的相互依赖还是较高,模块要独立运行很难跑通完整功能;而 Module 预编译方案在会议项目中的可行性更高,不需要改动业务逻辑。
02
如何优雅的预编译 Module 产物?
那么既然要预编译所有的 module,就需要有一个机器自动构建 module 产物,并上传构建产物到云端。本地编译时从云端拉取预先编译好的产物来加速APP 编译。
那么,这里有几个问题需要确定:
1.构建在哪里执行;
2.如何增量发布产物;
3.预编译产物上传到何处;
4.如何使用预编译产物
2.1 构建在哪执行
首先,产物构建需要一台机器自动触发,很自然会想到持续集成(Continuous Integration,简称 CI)机器,这里我们选择了 Coding CI 来自动触发构建。首先来看看会议的开发模式:

会议的开发模式是从主分支拉子分支开发新需求,开发完成后再合入主干。那么 CI 应该在哪条流水线构建 module 产物呢?需要为每条流水线都构建吗?
如果在 master 流水线构建:那么开发分支一旦 module 代码有修改,module 缓存就失效了。只改动一两个 module 还好,但如果是 module 全部失效(比如 module 依赖的公共接口有变更),那增量构建的逻辑就形同虚设了。
如果在 feature/bugfix 流水线构建:开发分支那么多,每个分支流水线都跑一次 module 构建,时间、仓库的存储成本都激增。而且,每个分支的构建产物相互独立,本地如果想要用产物加速编译,就必须得先启动流水线跑一次,等预编译产物构建完成了才可以使用。这对于拉一个 bugfix 分支修改两行代码就修复一个 bug 的场景来说是不可接受的。
2.1.1 有没有更加优雅的方式呢?
这里首先分析一下 module 之间的的关系,我们的module 相互之间代码是没有依赖的,module 共同依赖一些基础代码,我们称之为 module API。其实,大多数情况下,module 构建出来的产物,对于其他分支来说,只要module API 没有变更就是可以复用的。那怎么最大化的利用上这些产物呢?这取决于如何管理 module 产物的版本号,只要分支代码有可用的版本号就可以复用产物。
比如,从 master 拉一个 bugfix 分支,只需要改几行代码,就可以直接用master 的版本号就行了。如果是 feature 分支,一开始也是从 master 继承module 的版本号,随着功能开发的进行,当我们修改了 module A 的代码,再手动更新一下 module A 的版本号,最后随着 feature 一起合入 master。
这样一套流程似乎可行,只是实际操作起来会给开发者带来一定的使用成本,因为需要开发者手动管理 module 的版本号。
试想一下,如果有两个 feature 分支都同时修改了同一个 module 的代码,那他们都会去更新这个 module 的版本号,MR 的时候就会发生版本冲突:

这时就必须是 feature A merge feature B 的代码,然后重新更新 Module B的版本号再构建。可能一个 module 代码冲突还好,但如果是 module API 的修改了呢?那就是所有 module 都需要更新了,这是非常机械且令人头疼的!
某著名大佬曾说过:“但凡重复的工作,我都希望交给机器来做”,这种明显重复的机械的工作,能否直接交给机器完成呢?
通过分析不难发现,在构建参数一致的情况下,module 产物的版本号和我们的代码是一一对应的,即只要 module 代码有修改那我们就应该更新这个module 的版本号。那我们有没有什么已有的东西符合这个属性来当作版本号呢?有!Git commit ID 不就是吗?
在我们的认知里,commit ID 似乎是反映整个项目所有代码的版本,但需要给每个 module 建立各自的版本记录,commit ID 能满足吗?熟悉 git 的人应该知道,git 可以通过指定

这样,只需要输入 module 的代码目录,就可以推算出这个 module 代码对应的预编译产物版本号,那我们就无需自己来管理版本号了,交给 git 管理:
|
如此,就省掉了繁琐的版本号维护流程。也正因为 module 版本号是 commit ID,不同分支只要 module 的代码没有变,那 commit ID 也就不会变,不同分支间的 module 产物也就可以复用。
因此,我们可以只要在 master 或者 master&feature 分支触发产物的构建,就能覆盖绝大多数分支。
2.2 如何增量发布产物
确定了使用 CI 来构建产物后,然后可以通过代码提交来自动触发 CI 启动。但为了避免浪费构建机资源,并不需要每次都构建发布所有模块,仅增量的发布修改过的模块即可。
那如何判断模块是否修改过呢?与获取 module 版本号的方式类似,我们可以使用命令:git diff --
2.3 预编译产物上传到何处
CI 构建出来的产物,需要一个仓库来保存,“善解人意”的腾讯软件镜像源为我们提供了各种仓库:Maven、Generic、CocoaPods。Android 有 Maven,上传、下载、管理版本十分方便,可惜其他平台并不支持。按照腾讯会议的一贯思路,就得考虑跨平台的方式来上传、下载产物。
最终我们选择了原始的腾讯云 Generic 仓库。相较于其他镜像仓库,Generic 仓库具有以下优势:
|
于是,我们自定义了一套产物打包、存储的规范,将各端构建好的产物,自己造轮子实现上传、下载、校验、解压安装等功能。正所谓:“造轮子一时爽,一直造轮子一直爽”。
2.4 如何使用预编译产物
为了让开发者无学习成本的使用预编译产物,产物的匹配和编译切换最好是无感的。即开发者并不需要主动配置,编译时脚本会自动匹配可用的预编译产物来构建 APP。
以 module A 为例,自动匹配产物的大致流程如下:
1.通过 git diff 查询当前的 changes list
2.有修改到 module A 的代码,脚本就自动切换到 module A 的源码编译;
3.没有修改 module A 的代码,则自动选择 module A 的产物构建。
大致方向确定了,接下来就是具体的实施细节了。
03
发布 Module 产物
首先,发布产物需要确认的是预编译产物结构是怎样的。为了脚本逻辑能够跨平台,我们将每个模块输出的产物统一命名规范为:xx_module_output.zip,也就是各平台将自己每个 module 的产物打包到一个 zip 包中。但是 zip 包并不能反映产物的具体信息,比如对应的版本号、时间等,因此还需要一个 manifest 文件来汇总所有产物的相关信息。那么一个版本的代码对应的产物有:
xx_module_output.zip:xx_module的编译产物,总共会有n个xx_module_output.zip(n为模块个数);
base_manifest.json:当前版本的所有 module 产物信息,包括 module 名字、版本号等。
而 base_manifest.json 里保存的信息结构如下:
{
"modules": [
{
"name": "account", // 模块名称
"version": "7b2331b7e9", // 模块版本号,即模块commit ID
"time": "1632624109" // 模块版本时间,即模块commit时间戳
},
{
"name": "audio",
"version": "7b2331b7e9",
"time": "1632624109"
},
… ],
"appVersion": "7b2331b7e9", // 代码库git commit ID
"appVersionTime": "1632624109"// 代码库commit时间戳}然后,在有代码提交时,自动触发 CI 启动 Module 发布脚本,通过 git diff 找到提交的 change list,然后从 changes list 来判断哪些 module 有变更,对变更的 module 重编发布:

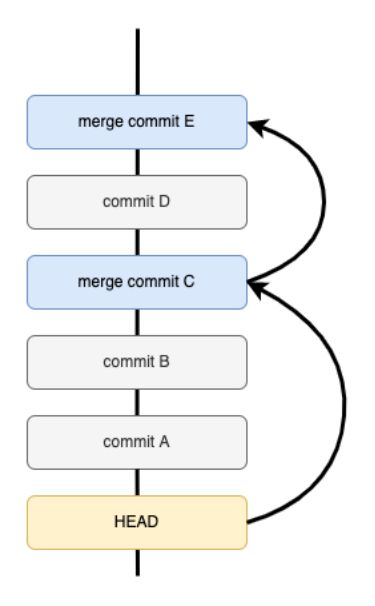
流程看起来并不复杂,但实际操作上确有很多问题值得推敲。比如:我们知道git diff 是一个对比命令,既然是对比就会有一个基准 commit ID 和目标commit ID,目标 commit 就取当前最新的 commit 就好了。但基准 commit应该取哪个呢?是上一个提交吗?来看下面这个开发流程:

开发者从 master 拉取了一个分支修复 bug,本地产生了两次 commit但没有 push,最后走 MR 流程合入主干。整个过程产生了三个 commit,如果直接使用最近一次的 commit 来 diff 产生结果,那么 diff 的 commit 是最后的那次 merge commit,结果正好是这次 bugfix 的所有改动记录。也就不用管前面的 commit a、commit b 了,这样看起来使用最近一次 commit diff 似乎没有问题。
但如果这次编译被跳过或者失败了,那么下一次的 MR 还只关注本次 MR 的提交内容,中间跳过的代码提交就很可能一直没有对应构建产物了。
因此,我们是通过查找最近一次有 base_manifest.json 文件与之对应的merge commit 来作为基准 commit。即从当前 commit 开始,回溯之前所有的merge commit,如果能够找到merge commit对应的base_manifest.json,那就说明这次 merge commit 是有发布 module 的,那么就以它为基准计算 diff。当然,我们并不会无限制的往前回溯,在尝试回溯了 n 次后仍然没有找到,则认为没有发布。
其次,要如何 diff 特定 module 代码呢?
前面提到 git diff 可以通过
git diff targetCommitId baseCommitId -- path/to/module/xxx_module #获取module的diff(v1)那么,只需包含这个 module 自身的代码目录路径就可以了吗?
答案是不够的。因为 module 还会依赖其他的接口代码,如 module API 的,接口的改动也会影响到 module 的编译结果,因此还需要包含 module API 的目录才行。于是获取 module diff 就变成下面这样:
git diff targetCommitId baseCommitId -- path/to/module/xxx_module path/to/module-api #获取module的diff (v2)另外,在 module 目录中,有些无关的文件并不影响编译结果(比如其他端的UI代码),在计算 diff 时我们需要将其排除,如何做到呢?也是通过
git diff targetCommitId baseCommitId --name-only -- path/to/module/xxx_module path/to/module-api :!path/to/module/xxx_module/ui/Windows :!path/to/module/xxx_module/ui/Mac :!path/to/module/xxx_module/ui/iOS #获取module的diff (final)同样的,在发布 module 时,需要提供一个版本号,前面已经提到,可以使用module 的 commit ID 作为版本号。那么要如何获取 module 的 commit ID呢?git 命令都支持传入
不难发现,git log 命令的
git diff targetCommitId baseCommitId --name-only -- path/to/module/xxx_module path/to/module-api :!path/to/module/xxx_module/ui/Windows :!path/to/module/xxx_module/ui/Mac :!path/to/module/xxx_module/ui/iOS #获取module的diff (final)确定了 diff 与获取 module 版本号的算法,发布流程基本就可以走通了,接下来就是如何使用产物。
04
使用Module产物
首先需要确认的是,当前的代码要如何判断 CI 是否有发布与之匹配的 module产物。
4.1 匹配产物
前面我们提到在发布产物时,是通过回溯查找每个commit对应的base_manifest.json 来确定最近一次发布的 commit。那么匹配当前可用的产物也是类似的逻辑,通过回溯来找到最近有发布的 commit,整个 module 增量构建的流程如下:
|

这里判断 module 是否修改的 diff 算法与发布产物时类似,以产物的版本号为base commit、设置 module 的
产物匹配下载成功后,就是使用预编译产物来替换源码编译了。本着无使用成本的原则,我们希望替换过程能够脚本自动化完成,不需要开发者关心和介入就能无缝切换。
4.2 CMake产物替换源码编译
会议的跨平台层代码使用 C++ 实现,并采用 CMake 来组织工程结构的,所以C++ 代码的产物替换,需要从 CMake 文件入手。
首先,C++ 预编译的产物是动态/静态库,这些对于 CMake 来讲就是library,可以通过 add_library() 或者 link_directories() 函数将其作为预编译库添加进来,以动态库 xx_plugins 为例,增量脚本会根据匹配的产物,会生成一个use_library_flag.cmake 文件,用来标记命中增量的库:
# use_library_flag.cmake
set(lib_wemeet_plugins_bin "/Users/jay/Dev/Workspaces/wemeet/app/app/.productions/Android/libraries/wemeet_plugins")
set(lib_wemeet_sdk_bin "/Users/jay/Dev/Workspaces/wemeet/app/app/.productions/Android/libraries/wemeet_sdk")
...
set(lib_xxx patch/to/lib_xxx)我们在使用 xx_plugins 的方式上做了改变:
|
那么,增量产物命中后要实现产物/源码的切换,是不是只需要重新生成use_library_flag.cmake 这个文件就可以了呢?
先来看看 CMake 的使用流程,主要分为 generate 和 build 这两个步骤:
|
对于 Android 来说,cmake 是属于 gradle 管理的一个子编译系统,在构建Android 的时候 gradle 会执行 cmake generate 和 build。
但对于 Xcode和 Visual Studio,cmake 修改之后是需要手动执行 generate的,原因是因为点击 IDE 的 build 按钮后仅仅是执行 build 命令,IDE 不会自动执行 cmake generate。
那么,增量命中的产物列表有更新时,需要开发者手动执行 generate 一次才能更新工程结构,切换到我们预期的编译路径。但这样开发者就需要关心增量产物匹配情况是否有变更,增加了使用成本。
有没有办法将这个过程自动化呢?
4.3 自动Generate
技术前提:
https://cliutils.gitlab.io/modern-cmake/chapters/basics/programs.html
cmake 提供了运行其他程序的能力,既包含配置时,也包含构建时。对于Windows端我们可以插入一段脚本,在编译前做自动 generate 检测:
if(WIN32)
# https://cliutils.gitlab.io/modern-cmake/chapters/basics/programs.html
add_custom_command(OUTPUT "${CMAKE_CURRENT_BINARY_DIR}/running_command_at_build_time_generated.trickier"
COMMAND node ${CMAKE_CURRENT_SOURCE_DIR}/build_project/auto_generate_proj.js
${LIB_OS_TYPE}
${windows_output_bin_dir}
...
)
add_custom_target(auto_generate_project ALL
DEPENDS "${CMAKE_CURRENT_BINARY_DIR}/running_command_at_build_time_generated.trickier")
endif()脚本会对比上一次构建的产物命中模块,当命中模块的列表有变更时,则启动子进程调用cmd窗口执行 Windows 的 generate:
const cmd = `start cmd.exe /K call ${path.join(winGeneratePath, generateStr)}`;
child_process.exec(cmd, {cwd: winGeneratePath, stdio: 'inherit'});
process.exit(0);注意: 使用 node 触发 cmd 执行 generate 脚本时,需要使用 detached 进程的方式,并使需要进程 sleep 足够时间以等待脚本执行结束。
4.4 半自动Generate
对于 iOS 和 OS X 平台,也可以 在 xcode 的 Pre-actions 环节插入一段脚本,来检测模块的命中列表是否有变更:

但由于 xcode 本身检测到工程结构改变会自动停止编译,因此我们通过弹窗提示开发者,当检测到命中产物的模块已经更改时,需要手动 generate 更新工程结构。

4.5 IDE显示源码
产物/源码切换编译的问题解决了之后,我们也发现了了新的问题:在xx_plugins 命中增量产物时,发现 IDE 找不到 xx_plugins 的源码了!
这是因为前面改造 CMakeLists.txt 脚本时,命中增量的情况下,并不会去执行 add_subdirectory(xx_plugins),那 IDE 自然不会索引 xx_plugins 的源码了,这显然是十分影响开发体验的。要解决这个问题就必须命中增量时也执行 add_subdirectory(xx_plugins) 添加源码目录,可添加了源码目录就会去编译它,那么可以让它不编译吗?
答案是肯定的!我们来看看 cmake --build 的文档:
Usage: cmake --build [options] [-- [native-options]]
Options:
= Project binary directory to be built.
--parallel [], -j []
= Build in parallel using the given number of jobs.
If is omitted the native build tool's
default number is used.
The CMAKE_BUILD_PARALLEL_LEVEL environment variable
specifies a default parallel level when this option
is not given.
--target ..., -t ...
= Build instead of default targets.
--config = For multi-configuration tools, choose .
--clean-first = Build target 'clean' first, then build.
(To clean only, use --target 'clean'.)
--verbose, -v = Enable verbose output - if supported - including
the build commands to be executed.
-- = Pass remaining options to the native tool. 文档中提到 cmake build 命令是可以通过–target 参数来设置需要编译的target,而 target 则是通过 add_library 定义的代码库,默认情况下 cmake会 build 所有的 target。但如果我们指定了 target 后,那么 cmake 就只会编译该 target 及 target 依赖的库。
在会议项目中 lib_app 依赖了其他所有的增量库,属于依赖关系中的顶层library,因此我们的 build 命令可以加上参数--target lib_app,那么:
|
因此,我们可以进一步改造CMakeLists.txt,让add_subdirectory(xx_plugins)始终执行:
# CMakeLists.txt
include(use_library_flag.cmake)
...
# 引入wemeet_plugins源码目录
add_subdirectory(wemeet_plugins)
if(lib_wemeet_plugins_bin) # 命中增量
# 则导入该lib
add_library(prebuilt_wemeet_plugins SHARED IMPORTED)
set_target_properties(${prebuilt_wemeet_plugins}
PROPERTIES IMPORTED_LOCATION
${lib_wemeet_plugins_bin}/${LIB_PREFIX}wemeet_plugins.${DYNAMIC_POSFIX}) # DYNAMIC_POSFIX: so、dll、dylib
set(shared_wemeet_plugins prebuilt_wemeet_plugins) # 设置为预编译库
else() # 未命中增量
set(shared_wemeet_plugins wemeet_plugins) # 设置为源码库
endif()
...
# 引用wemeet_plugins
target_link_libraries(wemeet_app_sdk PRIVATE ${shared_wemeet_plugins})这样在 xx_plugins 命中增量的情况下,开发者也可以继续用 IDE 愉快的阅读、修改源码了。
05
断点调试
使用增量产物代替源码编译同时会带来的另一个问题:lldb 的断点调试失效了!
要解决这个问题,首先要知道 lldb 二进制匹配源码断点的规则:lldb 断点匹配的是源码文件在机器上的绝对路径!(win 端没有用 lldb 调试器没有这个问题,只要 pdb 文件和二进制放在同级目录就能够自动匹配)
那么,在机器 A 上编译的二进制产物 bin_A 由于源码文件路径和本地机器B上的不一样,在机器 B 上设置的断点,lldb 就无法在二进制 bin_A 中找到与之对应位置。
那有办法可以解决这个问题吗?在 lldb 内容有限的文档我们发现这样一个命令:
settings set target.source-map /buildbot/path /my/path其作用就是将本地源码路径与二进制中的代码路径做一个映射,这样lldb就可以正确找到代码对应的断点位置了。那么“药”找到了,如何“服用”呢?
首先,我们会有多个库分别编译成二进制发布,并且由于是增量发布,各个库的构建机器的路径可能都不一样,因此需要为每个库都设置一组映射关系。好在source-map是可以支持设置多组映射的,因此我们的映射命令演变成了:
settings set target.source-map /qci/workspace_A/path_to_lib1 /my_local/path_to_lib1
/qci/workspace_B/path_to_lib2 /my_local/path_to_lib2
/qci/workspace_C/path_to_lib3 /my_local/path_to_lib3
...
/qci/workspace_X/path_to_libn /my_local/path_to_libn命令有了,何时执行呢?需要手动执行吗?依然还是无使用成本的原则,我们希望脚本能自动化完成这些繁琐的事情。
了解 lldb 的开发者想必都知道“~/.lldbinit"这个配置文件,我们可以在执行增量脚本的时候,把 source-map 配置添加到“~/.lldbinit"中,这样 lldb 启动的时候就会自动加载,但是这里的配置是在用户目录下,会对所有 lldb 进程生效。为了避免对其他仓库/项目代码调试造成影响,我们应该缩小配置的作用范围,xcode 是支持项目级别的 .lldbinit 配置,也就是可以将配置放到 xcode 的项目根目录:
# Mac端的.lldbinit放到Mac的xcode项目根目录:
app/Mac/Src/App/Application/WeMeetApp/.lldbinit
# iOS端的.lldbinit放到iOS的xcode项目根目录:
app/iOS/Src/App/Application/WeMeetApp/.lldbinitAndroid Studio(简称 AS)就没有这么人性化了,并不能自动读取项目根目录的 .lldbinit 配置,但可以在 AS 中手动配置一下 LLDB Startup Commands:
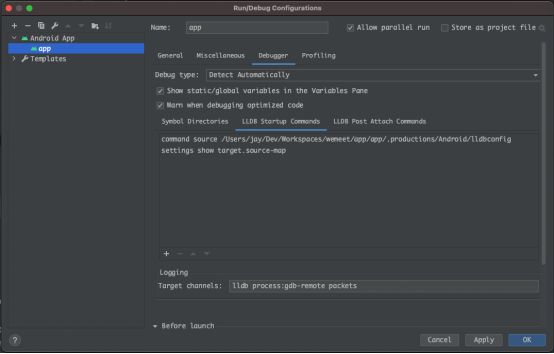
手动配置虽然造成了一定使用成本,但还好只需要配置一次。
5.1 Android产物替换
Android 中的子模块由于包含了 Java 代码和资源文件,预编译的产物就不是动态库/静态库了,产物替换得从 gradle 入手。
前面文章有提到,为了更好的跨平台,我们选择了 Generic 仓库来存储增量构建的产物。 熟悉Android 的开发者都知道,Android 平台集成预编译产物的方式有两种:
|
如果选择本地文件集成,那么我们就需要将模块源码打包成 aar 文件,但会遇到一个问题:若模块采用 maven 集成的方式依赖了三方库,是不会包含在最终打包的 aar 文件中的,这就会导致产物集成该模块时丢失了一部分代码。而Google 推荐的集成方式都是 maven 集成,因为 maven 产物中的 pom.xml文件会记录模块依赖的三方库,方便管理版本冲突以及重复引入等问题。
那么如何在 Generic 仓库中使用 maven 集成呢?Generic 仓库其实就是一个只提供上传、下载的文件存储服务器,文件上传、下载均需自行实现,因此,每一个模块产物的文件内容各端可以自行定义,最终打包成一个压缩包上传到仓库即可。那么对于 Android 端我们可以将每个模块产物按照本地maven仓库的文件格式进行打包发布:
app/.productions/Android/repo/com/tencent/wemeet/module/chat/ ├── f4d57a067d │ ├── chat-f4d57a067d-prebuilt-info.json │ ├── chat-f4d57a067d.aar │ ├── chat-f4d57a067d.aar.md5 │ ├── chat-f4d57a067d.aar.sha1 │ ├── chat-f4d57a067d.aar.sha256 │ ├── … │ ├── chat-f4d57a067d.pom │ ├── chat-f4d57a067d.pom.md5 │ ├── chat-f4d57a067d.pom.sha1 │ ├── chat-f4d57a067d.pom.sha256 │ └── chat-f4d57a067d.pom.sha512 ├── maven-metadata.xml ├── maven-metadata.xml.md5 ├── maven-metadata.xml.sha1 ├── maven-metadata.xml.sha256 └── maven-metadata.xml.sha512 |
以上就是模块 chat 以 maven 格式进行发布产物的文件列表,可以看到该仓库中只有一个版本(版本号:f4d57a067d)的产物,也就是说每个版本的增量产物其实就是一个 maven 仓库,我们将产物下载下来解压后,通过引入本地maven仓库的方式添加到项目中来:
// build.gradle
repositories {
maven { url "file://path/to/local/maven" }
}
dependencies {
implementation 'com.tencent.wemeet.module:chat:f4d57a067d'
}集成方式敲定了,那要如何自动切换呢?gradle 本身就是脚本,那么我们可以在增量脚本执行后,根据脚本的执行结果,命中产物的模块则以 maven 方式依赖,未命中的则以源码依赖。为了简化使用方法,我们定义了一个 projectWm函数:
// common.gradle
gradle.ext.prebuilts = [:]
// setup prebuilt result
...
ext.projectWm = { String name ->
String projectName = name.substring(1) // remove ":"
if (gradle.ext.prebuilts.containsKey(projectName)) { // 命中增量产物
def prebuilt = gradle.ext.prebuilts[projectName]
return "com.tencent.wemeet.module:${projectName}:${prebuilt.version}"
} else { // 未命中增量产物
return project(name)
}
}
// build.gradle
apply from: 'common.gradle' // 引入通用配置
...
dependencies {
implementation projectWm(':chat')
...
}projectWm 里面封装了替换源码编译的逻辑,这样我们只需要将所有的project(":xxx")改成projectWm(":xxx") 即可,使用方便简单。
解决完替换的问题,就可以愉快的使用增量产物了?
5.2 成也Maven,败也Maven
虽然 maven 的依赖管理给我们带来了便利,但对于产物替换源码编译的场景,也带了新的问题。看这样一个 case,有 A、B、C 三个模块,他们的依赖关系如下:
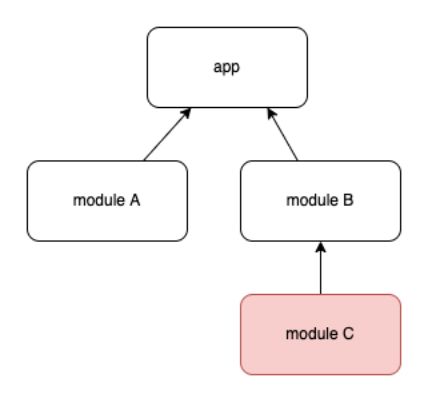
前面的 projectWm 方案,对于模块A这种单一模块可以很好的解决问题,但对于模块 B 依赖模块 C 这种复杂的依赖关系却不适用。比如模块 B 命中增量、模块 C 未命中时,由于 B 使用 projectWm 替换成了 maven 依赖,而模块 C 会因为模块的 maven 产物中 pom.mxl 定义的依赖关系给带过来,也就是模块 C也会是 maven 依赖,而无法变成源码依赖。我们必须将模块 B 附带的 maven依赖中的模块 C 再替换源码!通过查阅 gradle 文档,我们发现 gralde 提供了dependencySubstitution 功能可以将 maven 依赖替换成源码,用法也十分简单:

于是我们可以将为命中的 module C 再替换成源码编译:
configurations.all {
resolutionStrategy.dependencySubstitution.all { DependencySubstitution dependency ->
if (dependency.requested instanceof ModuleComponentSelector) {
def group = dependency.requested.group
def moduleName = dependency.requested.module
if (group == 'com.tencent.wemeet'|| (group.startsWith('application') && dependency.requested.version == 'unspecified')) {
def prebuilt = gradle.ext.prebuilts[moduleName]
if (prebuilt == null) { // module未命中
def targetProject = findProject(":${moduleName}")
if (targetProject != null) {
dependency.useTarget targetProject
}
}
}
}
}
}替换好了本以为万事大吉了,但实际编译运行时,随着命中情况的变化,经常偶发的失败:Could not resolve module_xx:

究其原因,还是上面的替换没有起作用,替换的源码模块找不到,难道 gradle提供的API有问题?通过仔细阅读文档,发现这样一段话:

意思就是Dependency Substitution 只是帮你把依赖关系转变过来了,但实际上并不会将这个 project 添加到构建流程中。所以我们还得将源码编译的 project 手动添加到构建中:
// build.gradle
dependencies { implementation project(":xxx") }那接下来的问题就是如何找到编译 app 最终需要源码编译的 module,然后添加到 app 的 dependencies{}依 赖中。这就要求得拿到所有 module 的依赖关系图,这个并不困难,在gradle configure之后就可以通过解析configurations 获取。但问题是我们必须得在 gradle configure 之前获取依赖关系,因为在 dependencies{} 中添加依赖是在 gradle configure 阶段生效的。
问题进入了陷入死循环,这样一来,我们并不能通过 gradle的configure 结果获取依赖关系,得另辟蹊径。
前面提到过,maven 会将模块产物依赖的子模块写到 pom.xml 文件中,虽然pom.xml 里记录的依赖并不全,但是我们可以将这些依赖关系拼凑起来:
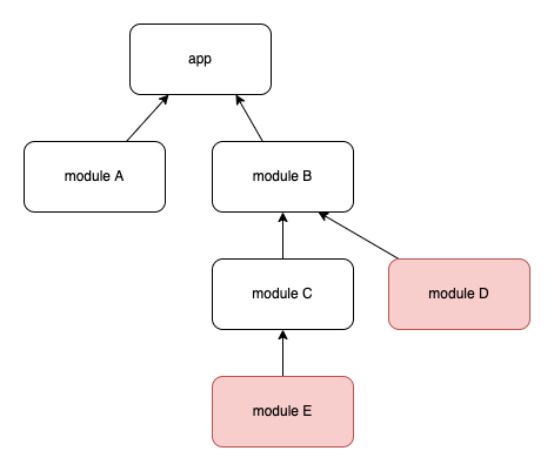
假设我们有上图的一个依赖关系,module A、B、C 都命中了增量,D、E 未命中,为了避免“Could not resolve module_xx”的编译错误,我们需要将module D、E 添加到 app 的 dependencies{} 中,那么脚本中如何确定呢:
|
源码替换的流程,到这里大致就走通了,不过除此之外还有其他替换相关的细节问题(如版本号统一、本地 aar 文件的依赖替换等),这里就不继续展开讲了。
5.3 Android Studio显示产物源码
与 cmake 类似,命中产物的模块由于变成了 Maven 依赖,也会遇到 AS 无法正确索引源码的问题。
首先,AS 中加载的源码是在 Gradle sync 阶段索引出来的,而我们用产物替换源码编译仅需要在 build 的时候生效。那是否可以在 sync 阶段让 AS 认为所有模块都未命中,去索引模块的源码,仅在真正 build才 做实际的替换呢?
答案是肯定的,但问题是如何判断 AS 是在 sync 或 build 呢?gradle 并没有提供 API,但通过分析 gradle.startParameter 参数可以发现,AS sync 其实是启动了一个不带任何 task参数的gradle命令,并且将systemPropertiesArgs中的“idea.sync.active“参数设置为了 true,于是我们可以以此为依据来区分 gradle 是否在 sync:
// settings.gradle
gradle.ext.isGradleSync = gradle.startParameter.systemPropertiesArgs['idea.sync.active'] == 'true'
ext.projectWm = { String name ->
String projectName = name.substring(1) // remove ":"
if (gradle.ext.isGradleSync) { // Gradle Sync
return project(name)
}
// 增量替换源码...
}06
万物皆可增量
以上讲的是业务 module 的增量流程,会议的业务 module 之间是没有依赖关系的,结构比较清晰。那其他依赖关系更复杂的子工程呢?
通过总结 module 的增量规律我们发现,一个子工程要实现增量化编译,需要解决的一个核心问题是判断这个是否需要重编。而 module 是通过 git diff –
|
因此,这里可以延伸一下,即确定了子工程的源码及其依赖的接口路径后,都可以通过这套流程来发布、匹配增量产物,完成增量化的接入。
07
构建参数
前面有说到,当构建参数一致的情况下,产物版本和代码版本是一一对应的。但实际情况是,我们经常也需要修改构建参数,比如编译 release、debug 版本编译的结果往往会有很大差异。
那么对于构建参数不一致的场景,增量构建的产物要如何匹配呢?
这里引入 variant(变体)的概念,即编译的产物会因构建参数不同有多种组合,每一种参数组合构建出来的产物我们称之为其中一种变体。虽然参数组合可能有n种,但是常用的组合可能就只有几种。每一种组合都需要重新构建和存储对应产物,成本成倍增加,要覆盖所有的组合显然不太现实。
既然常用的组合就那么几种,那么只覆盖这几种组合命中率就基本达标了。不同构建参数组合的产物之间是不通用的,所以存储路径上也应该是相互隔离的:

上图示例中,兼容了 package type(debug、release 等)和publish channel(app、private、oversea s等)两种参数组合,实际场景可能更多,我们可以根据需要进行定制。
08
总结
到这里,已经讲述了腾讯会议使用增量编译加速编译的大致原理,其核心思想就是尽量少编译、按需编译。在本地能够匹配到远端预先编译好的产物时,就取代本地的源码编译以节省时间。

接下来看下整体优化效果:
在全部命中增量产物的情况下,由于省去了大量的代码编译,全量编译效率也大幅提升:
平台 |
优化前 |
优化后 |
效率提升 |
Android |
17min |
3min |
82% |
| Windows | 20min | 10s | 99% |
iOS |
12min |
3min |
75% |
OSX |
16min |
4min |
75% |
注:以上数据为2022年3月本地实测数据,实际耗时可能因机器配置不同而不一致。
截止到现在,会议代码全量编译耗时已超30min+,但由于采用模块化增量编译,在命中增量的情况下效果是稳定的,即编译耗时不会随着代码量的增长而持续增加。
增量编译带来的效率提升是显著的,但现阶段也有一些不足之处:
1.产物命中率优化:现阶段产物命中率还不够高,当修改了公共头文件时容易导致命中率下降,但这种修改可以进一步细分,如当新增接口时,其实并不影响依赖它的模块命中。
2.自动获取依赖:目前工程依赖的关系是用配置文件人工维护的,因此会出现依赖关系更新滞后的情况。后续可以尝试从cmake、gradle等工具中获取依赖,自动更新配置。
以上是本次分享全部内容,欢迎大家在评论区分享交流。如果觉得内容有用,欢迎转发~
-End-
原创作者|何杰、郭浩伟、吴超、杜美依、田林江
技术责编|何杰、郭浩伟、吴超、杜美依、田林江





随着产品得到市场初步认可,业务开始规模化扩张。提速的压力从业务传导到研发团队,后者开始快速加人,期望效率能跟上业务的脚步,乃至带动业务发展。但不如人意的是,实际的研发效能反而可能与期望背道而驰——业务越发展,研发越跑不动。其实影响开发效率的因素远远不止代码编译耗时过长!
你在开发过程中会经常遇到哪些复杂耗时的头痛问题呢?
欢迎在评论区聊一聊你的问题。在4月13日前将你的评论记录截图,发送给腾讯云开发者公众号后台,可领取腾讯云「开发者春季限定红包封面」一个,数量有限先到先得。我们还将选取点赞量最高的1位朋友,送出腾讯QQ公仔1个。4月13日中午12点开奖。快邀请你的开发者朋友们一起来参与吧!
下方关注腾讯云开发者并点亮星标
第一时间看腾讯方案和学习资源