入坑kaggle第三天- Titanic - Machine Learning from Disaster模型优化
直觉可靠吗?
在数据分析时, 直接往往是不可靠的, 因为数据是真实的, 没有经过任何人为处理, 而且并非二维的线性模型。
而且, 数据的复杂程度, 是难以用直觉处理的, 必须用科学的工具。
当前模型的分数为:
Score: 0.77511
还有很多的提升空间。根据以往写深度学习模型的经验, 一般是2/8法则, 20%的时间写一个能用的模型, 剩下80%的时间优化模型。
1 数据分析
https://www.youtube.com/watch?v=fS70iptz-XU
这个视频提供了很好的数据模型方法与解题思路。
train.csv文件, 就是一个数据表格, 用pandas和matplotlib.pyplot可以大大提高分析效率。

import pandas as pd
df = pd.read_csv('titanic/train.csv')
print(df.shape)
print(df.count())
(891, 12)
PassengerId 891
Survived 891
Pclass 891
Name 891
Sex 891
Age 714
SibSp 891
Parch 891
Ticket 891
Fare 891
Cabin 204
Embarked 889
dtype: int64
可以看到, 表格为891行, 12列, 部分数据没有填写, 需要做数据清洗。
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('titanic/train.csv')
fig = plt.figure(figsize=(8, 4)) # fig size = 8 * 4
df.Survived.value_counts().plot(kind='bar', alpha=0.5)
plt.show()
用value_counts()可以作图分析:
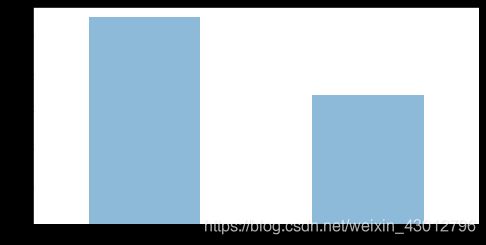
可见, 891名乘客中, 大约550人死亡, 350人存活。
也可用百分数:只需加入:normalize=True
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('titanic/train.csv')
fig = plt.figure(figsize=(8, 4)) # fig size = 8 * 4
df.Survived.value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.show()

可见60%的死亡, 40%的存活。
记得电影中说道, 妇女和儿童优先上救生艇, 先看年龄
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('titanic/train.csv')
fig = plt.figure(figsize=(8, 4)) # fig size = 8 * 4
plt.subplot2grid((2,3), (0,0)) # sub1
df.Survived.value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Survived")
plt.subplot2grid((2,3), (0,1)) # sub2
plt.scatter(df.Survived, df.Age, alpha=0.1)
plt.title("Age wrt Survived")
plt.show()

可以看出, 电影是真实的, 死亡的大多为老年人, 存活的大多为年轻人。中年人的存活死亡几乎相同。
如果加入头等舱,2, 3等, 结果如下:
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('titanic/train.csv')
fig = plt.figure(figsize=(8, 4)) # fig size = 8 * 4
plt.subplot2grid((2,3), (0,0)) # sub1
df.Survived.value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Survived")
plt.subplot2grid((2,3), (0,1)) # sub2
plt.scatter(df.Survived, df.Age, alpha=0.1)
plt.title("Age wrt Survived")
plt.subplot2grid((2,3), (0,2)) # sub3
df.Pclass.value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Class")
plt.show()
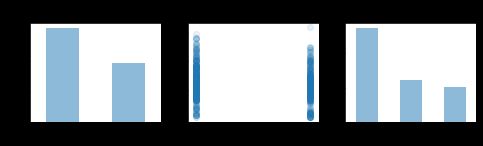
可以看到, 富人和穷人的比例
如果加入曲线, 可以看到穷人和富人的分布
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('titanic/train.csv')
fig = plt.figure(figsize=(8, 4)) # fig size = 8 * 4
plt.subplot2grid((2,3), (0,0)) # sub1
df.Survived.value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Survived")
plt.subplot2grid((2,3), (0,1)) # sub2
plt.scatter(df.Survived, df.Age, alpha=0.1)
plt.title("Age wrt Survived")
plt.subplot2grid((2,3), (0,2)) # sub3
df.Pclass.value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Class")
plt.subplot2grid((2,3), (1,0), colspan=2)
for x in [1, 2, 3]:
df.Age[df.Pclass == x].plot(kind='kde') # kind density estimation
plt.title('Class wrt Age')# with regard to
plt.legend(("1st", "2nd", "3rd"))
plt.show()

群人几乎都是20岁左右, 富人大多为30-40岁。
昨天, 本以为死亡与乘客无关, 但通过作图发现, 多数为英国人, 少数为法国和爱尔兰人。
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('titanic/train.csv')
fig = plt.figure(figsize=(8, 4)) # fig size = 8 * 4
plt.subplot2grid((2,3), (0,0)) # sub1
df.Survived.value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Survived")
plt.subplot2grid((2,3), (0,1)) # sub2
plt.scatter(df.Survived, df.Age, alpha=0.1)
plt.title("Age wrt Survived")
plt.subplot2grid((2,3), (0,2)) # sub3
df.Pclass.value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Class")
plt.subplot2grid((2,3), (1,0), colspan=2)
for x in [1, 2, 3]:
df.Age[df.Pclass == x].plot(kind='kde') # kind density estimation
plt.title('Class wrt Age')# with regard to
plt.legend(("1st", "2nd", "3rd"))
plt.subplot2grid((2,3), (1,2)) # sub3
df.Embarked.value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Embarked")
plt.show()

然后是性别, 这才是影响最大的。
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('titanic/train.csv')
fig = plt.figure(figsize=(18, 6)) # fig size = 8 * 4
plt.subplot2grid((3,4), (0,0)) # sub0
df.Survived.value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Survived")
plt.subplot2grid((3,4), (0,1)) # sub1
df.Survived[df.Sex == 'male'].value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Men Survived")
plt.subplot2grid((3,4), (0,2)) # sub3
df.Survived[df.Sex == 'female'].value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Women Survived")
plt.show()

可见男人大多挂了。Women, children first.
import pandas as pd
import matplotlib.pyplot as plt
female_color = '#FA0000'
df = pd.read_csv('titanic/train.csv')
fig = plt.figure(figsize=(18, 6)) # fig size = 8 * 4
plt.subplot2grid((3,4), (0,0)) # sub1
df.Survived.value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Survived")
plt.subplot2grid((3,4), (0,1)) # sub2
df.Survived[df.Sex == 'male'].value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Men Survived")
plt.subplot2grid((3,4), (0,2)) # sub3
df.Survived[df.Sex == 'female'].value_counts(normalize=True).plot(kind='bar', alpha=0.5, color=female_color)
plt.title("Women Survived")
plt.subplot2grid((3,4), (0,3)) # sub4
df.Sex[df.Survived == 1].value_counts(normalize=True).plot(kind='bar', alpha=0.5, color=[female_color, 'b'])
plt.title("Sex of Survived")
plt.show()

还有一点是:三等舱的人大多死亡:
import pandas as pd
import matplotlib.pyplot as plt
female_color = '#FA0000'
df = pd.read_csv('titanic/train.csv')
fig = plt.figure(figsize=(18, 6)) # fig size = 8 * 4
plt.subplot2grid((3,4), (0,0)) # sub1
df.Survived.value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Survived")
plt.subplot2grid((3,4), (0,1)) # sub2
df.Survived[df.Sex == 'male'].value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Men Survived")
plt.subplot2grid((3,4), (0,2)) # sub3
df.Survived[df.Sex == 'female'].value_counts(normalize=True).plot(kind='bar', alpha=0.5, color=female_color)
plt.title("Women Survived")
plt.subplot2grid((3,4), (0,3)) # sub4
df.Sex[df.Survived == 1].value_counts(normalize=True).plot(kind='bar', alpha=0.5, color=[female_color, 'b'])
plt.title("Sex of Survived")
plt.subplot2grid((3,4), (1,0), colspan=4)
for x in [1, 2, 3]:
df.Survived[df.Pclass == x].plot(kind='kde') # kind density estimation
plt.title('Class wrt Survived')# with regard to
plt.legend(("1st", "2nd", "3rd"))
plt.show()

最后一张真相:
import pandas as pd
import matplotlib.pyplot as plt
female_color = '#FA0000'
df = pd.read_csv('titanic/train.csv')
fig = plt.figure(figsize=(18, 6)) # fig size = 8 * 4
plt.subplot2grid((3,4), (0,0)) # sub1
df.Survived.value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Survived")
plt.subplot2grid((3,4), (0,1)) # sub2
df.Survived[df.Sex == 'male'].value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Men Survived")
plt.subplot2grid((3,4), (0,2)) # sub3
df.Survived[df.Sex == 'female'].value_counts(normalize=True).plot(kind='bar', alpha=0.5, color=female_color)
plt.title("Women Survived")
plt.subplot2grid((3,4), (0,3)) # sub4
df.Sex[df.Survived == 1].value_counts(normalize=True).plot(kind='bar', alpha=0.5, color=[female_color, 'b'])
plt.title("Sex of Survived")
plt.subplot2grid((3,4), (1,0), colspan=4)
for x in [1, 2, 3]:
df.Survived[df.Pclass == x].plot(kind='kde') # kind density estimation
plt.title('Class wrt Survived')# with regard to
plt.legend(("1st", "2nd", "3rd"))
plt.subplot2grid((3,4), (2,0)) # sub2
df.Survived[(df.Sex == 'male') & (df.Pclass == 1)].value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Rich Men Survived")
plt.subplot2grid((3,4), (2,1)) # sub2
df.Survived[(df.Sex == 'male') & (df.Pclass == 3)].value_counts(normalize=True).plot(kind='bar', alpha=0.5)
plt.title("Poor Men Survived")
plt.subplot2grid((3,4), (2,2)) # sub2
df.Survived[(df.Sex == 'female') & (df.Pclass == 1)].value_counts(normalize=True).plot(kind='bar', alpha=0.5, color=female_color)
plt.title("Rich Women Survived")
plt.subplot2grid((3,4), (2,3)) # sub2
df.Survived[(df.Sex == 'female') & (df.Pclass == 3)].value_counts(normalize=True).plot(kind='bar', alpha=0.5, color=female_color)
plt.title("Poor Women Survived")
plt.show()
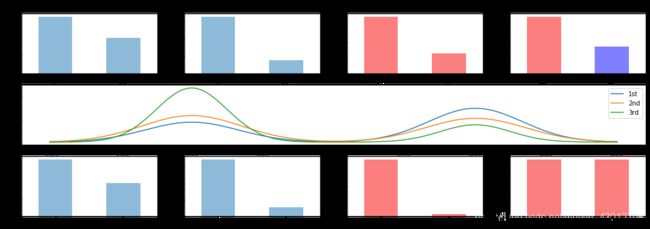
有钱的女人几乎都活着, 那就是Rose一类人, 没钱的男人几乎都死了, Jack一类人, 有钱的男人Karl一类人, 存活率高于没钱的女人。可能现实中比电影更加残酷。
所以说性别和票价或Pclass这些参数是相当重要的。
2 模型的选择
2.1 假设女生男死
import pandas as pd
train = pd.read_csv('titanic/train.csv')
train["Hyp"] = 0 # hypothesis filled first with 0
train.loc[train.Sex == "female", "Hyp"] = 1
train['Result'] = 0
train.loc[train.Survived == train['Hyp']] = 1
print(train['Result'].value_counts())
1 701
0 190
Name: Result, dtype: int64
可见假设可靠, 也不全对
用百分数:
import pandas as pd
train = pd.read_csv('titanic/train.csv')
train["Hyp"] = 0 # hypothesis filled first with 0
train.loc[train.Sex == "female", "Hyp"] = 1
train['Result'] = 0
train.loc[train.Survived == train['Hyp']] = 1
print(train['Result'].value_counts(normalize=True))
1 0.786756
0 0.213244
Name: Result, dtype: float64
train.csv中: accuracy 78.6%
model 1: 什么也不做, 也不用写代码, 因为submission.csv, 就是按照这样假设的, 为了学习, 重新写入如下代码, 不用机器学习模型结果如下。
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
test_data["Hyp"] = 0 # hypothesis filled first with 0
test_data.loc[test_data.Sex == "female", "Hyp"] = 1
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': test_data.Hyp})
output.to_csv('my_submission.csv', index=False)
print("Your submission was successfully saved!")
public score: 0.76555
这也不比昨天的模型差。
昨天模型:public score: 0.77511
2.2 使用机器学习模型
2.2.1 random forest model
features: 选取[‘Pclass’, ‘Age’, ‘Sex’, ‘SibSp’, ‘Parch’]
train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
from sklearn.ensemble import RandomForestClassifier
def clean_data(data): # transform text to number for machine leaarning
data['Fare'] = data['Fare'].fillna(data['Fare'].dropna().median())
data['Age'] = data['Age'].fillna(data['Age'].dropna().median())
data.loc[data['Sex'] == 'male', 'Sex'] = 0
data.loc[data['Sex'] == 'female', 'Sex'] = 1
data['Embarked'] = data['Embarked'].fillna('S') # if no data, fill with S
data.loc[data['Embarked'] == 'S', 'Embarked'] = 0
data.loc[data['Embarked'] == 'C', 'Embarked'] = 1
data.loc[data['Embarked'] == 'Q', 'Embarked'] = 2
# clean data
clean_data(train_data)
clean_data(test_data)
# label
y = train_data["Survived"]
# features choose 5
features = train_data[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch']].values
test_features = test_data[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch']].values
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(features, y)
predictions = model.predict(test_features)
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('my_submission.csv', index=False)
print("Your submission was successfully saved!")
print(model.score(features, y))
训练数据集的精度提高到了: 0.8417508417508418
测试结果为: 0.76794, 并不理想
增加features后: [‘Pclass’, ‘Age’, ‘Sex’, ‘SibSp’, ‘Parch’, “Fare”, “Embarked”]
训练数据集的精度提高到了: 0.8540965207631874
测试结果为: 0.76794, 没有增加
修改:n_estimators=200, max_depth=25
训练数据集的精度提高到了: 0.9797979797979798
测试结果为: 0.75837, 反而下降, 肯定是overfitting
通过调整模型参数, 避免overfiitting, model = RandomForestClassifier(n_estimators=50, max_depth=6, random_state=1)
分数有20000多名, 提高到3923名
0.78468
Your submission scored 0.78468, which is an improvement of your previous score of 0.77990. Great job!
感觉修改模型提高不大, 如何进入2000名, 尝试修改模型。
2.2.2 logistic regression model
from sklearn import linear_model
def clean_data(data): # transform text to number for machine leaarning
data['Fare'] = data['Fare'].fillna(data['Fare'].dropna().median())
data['Age'] = data['Age'].fillna(data['Age'].dropna().median())
data.loc[data['Sex'] == 'male', 'Sex'] = 0
data.loc[data['Sex'] == 'female', 'Sex'] = 1
data['Embarked'] = data['Embarked'].fillna('S') # if no data, fill with S
data.loc[data['Embarked'] == 'S', 'Embarked'] = 0
data.loc[data['Embarked'] == 'C', 'Embarked'] = 1
data.loc[data['Embarked'] == 'Q', 'Embarked'] = 2
# clean data
clean_data(train_data)
clean_data(test_data)
# label
y = train_data["Survived"]
# features choose 5
features = train_data[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch', "Fare", "Embarked"]].values
test_features = test_data[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch', "Fare", "Embarked"]].values
model = linear_model.LogisticRegression()
model.fit(features, y)
predictions = model.predict(test_features)
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('my_submission.csv', index=False)
print("Your submission was successfully saved!")
print(model.score(features, y))
不理想:test score of 0.76315
2.2.3 logistic regression polynomial model
from sklearn import linear_model, preprocessing
def clean_data(data): # transform text to number for machine leaarning
data['Fare'] = data['Fare'].fillna(data['Fare'].dropna().median())
data['Age'] = data['Age'].fillna(data['Age'].dropna().median())
data.loc[data['Sex'] == 'male', 'Sex'] = 0
data.loc[data['Sex'] == 'female', 'Sex'] = 1
data['Embarked'] = data['Embarked'].fillna('S') # if no data, fill with S
data.loc[data['Embarked'] == 'S', 'Embarked'] = 0
data.loc[data['Embarked'] == 'C', 'Embarked'] = 1
data.loc[data['Embarked'] == 'Q', 'Embarked'] = 2
# clean data
clean_data(train_data)
clean_data(test_data)
# label
y = train_data["Survived"]
# features choose 5
features = train_data[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch', "Fare", "Embarked"]].values
test_features = test_data[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch', "Fare", "Embarked"]].values
model = linear_model.LogisticRegression()
model_ = model.fit(features, y)
print(model_.score(features, y))
poly = preprocessing.PolynomialFeatures(degree=2)
poly_features = poly.fit_transform(features)
poly_test_features = poly.fit_transform(test_features)
model_ = model.fit(poly_features, y)
print(model_.score(poly_features, y))
predictions = model.predict(poly_test_features)
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('my_submission.csv', index=False)
print("Your submission was successfully saved!")
没有提高, 几乎一样
2.2.4 decision tree
from sklearn import tree
def clean_data(data): # transform text to number for machine leaarning
data['Fare'] = data['Fare'].fillna(data['Fare'].dropna().median())
data['Age'] = data['Age'].fillna(data['Age'].dropna().median())
data.loc[data['Sex'] == 'male', 'Sex'] = 0
data.loc[data['Sex'] == 'female', 'Sex'] = 1
data['Embarked'] = data['Embarked'].fillna('S') # if no data, fill with S
data.loc[data['Embarked'] == 'S', 'Embarked'] = 0
data.loc[data['Embarked'] == 'C', 'Embarked'] = 1
data.loc[data['Embarked'] == 'Q', 'Embarked'] = 2
# clean data
clean_data(train_data)
clean_data(test_data)
# label
y = train_data["Survived"]
# features choose 5
features = train_data[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch', "Fare", "Embarked"]].values
test_features = test_data[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch', "Fare", "Embarked"]].values
decision_tree = tree.DecisionTreeClassifier(random_state = 1)
decision_tree_ = decision_tree.fit(features, y)
print(decision_tree_.score(features, y))
predictions = decision_tree.predict(test_features)
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('my_submission.csv', index=False)
print("Your submission was successfully saved!")
overfitting, 显著下降
修改模型, 避免overfitting, 由于kaggle今天的测试次数用完, 明天测试。
2.2.5 dicision tree增加深度
from sklearn import tree, model_selection
def clean_data(data): # transform text to number for machine leaarning
data['Fare'] = data['Fare'].fillna(data['Fare'].dropna().median())
data['Age'] = data['Age'].fillna(data['Age'].dropna().median())
data.loc[data['Sex'] == 'male', 'Sex'] = 0
data.loc[data['Sex'] == 'female', 'Sex'] = 1
data['Embarked'] = data['Embarked'].fillna('S') # if no data, fill with S
data.loc[data['Embarked'] == 'S', 'Embarked'] = 0
data.loc[data['Embarked'] == 'C', 'Embarked'] = 1
data.loc[data['Embarked'] == 'Q', 'Embarked'] = 2
# clean data
clean_data(train_data)
clean_data(test_data)
# label
y = train_data["Survived"]
# features choose 5
features = train_data[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch', "Fare", "Embarked"]].values
test_features = test_data[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch', "Fare", "Embarked"]].values
decision_tree = tree.DecisionTreeClassifier(random_state = 1, max_depth = 7, min_samples_split = 2)
decision_tree_ = decision_tree.fit(features, y)
print(decision_tree_.score(features, y))
predictions = decision_tree.predict(test_features)
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('my_submission.csv', index=False)
print("Your submission was successfully saved!")