盘点分布式文件存储系统____分布式文件存储系统简介
盘点分布式文件存储系统
在项目的数据存储中,结构化数据通常采用关系型数据库,非结构化数据(文件)的存储就有很多种方式,服务器本地存储、Nas挂载、ftp等等,今天就来盘点一下,分布式文件存储系统。
一、分布式存储简介
1、什么是分布式存储
在开始介绍分布式存储之前,先了解一下,非分布式的存储方案。
在单机时代,将文件直接存储在服务部署的服务器上——
- 直连存储(DAS):存储和数据直连,拓展性、灵活性差。
为了扩展,将文件和服务分离,通过网络连接——
- 中心化存储(NAS、SAN):设备类型丰富,通过网络互连,具有一定的拓展性,但是受到控制器能力限制,拓展能力有限。同时,设备到了生命周期要进行更换,数据迁移需要耗费大量的时间和精力。

**分布式存储:**通过网络使用企业中的每台机器上的磁盘空间,并将这些分散的存储资源构成一个虚拟的存储设备,数据分散的存储在企业的各个角落。

2、分布式存储的优势
可扩展:分布式存储系统可以扩展到数百甚至数千个这样的集群大小,并且系统的整体性能可以线性增长。
高可用性:在分布式文件系统中,高可用性包含两层,一是整个文件系统的可用性,二是数据的完整和一致性
低成本:分布式存储系统的自动容错和自动负载平衡允许在成本较低服务器上构建分布式存储系统。此外,线性可扩展性还能够增加和降低服务器的成本。
弹性存储: 可以根据业务需要灵活地增加或缩减数据存储以及增删存储池中的资源,而不需要中断系统运行
二、主流分布式文件存储系统
目前主流的分布式文件系统有:GFS、HDFS、Ceph、Lustre、MogileFS、MooseFS、FastDFS、TFS、GridFS等。
1、GFS(Google File System)
? Google公司为了满足本公司需求而开发的基于Linux的专有分布式文件系统。尽管Google公布了该系统的一些技术细节,但Google并没有将该系统的软件部分作为开源软件发布。
2、HDFS(Hadoop Distributed File System)
? HDFS(Hadoop Distributed File System)是 Hadoop 项目的一个子项目。是 Hadoop 的核心组件之一, Hadoop 非常适于存储大型数据 (比如 TB 和 PB),其就是使用 HDFS 作为存储系统. HDFS 使用多台计算机存储文件,并且提供统一的访问接口,像是访问一个普通文件系统一样使用分布式文件系统。

3、TFS(Taobao FileSystem)
? TFS是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器 集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化 了文件的访问流程,一定程度上为TFS提供了良好的读写性能。
4、Lustre
Lustre是一个大规模的、安全可靠的,具备高可用性的集群文件系统,它是由SUN公司开发和维护的。该项目主要的目的就是开发下一代的集群文件系统,可以支持超过10000个节点,数以PB的数据量存储系统。目前Lustre已经运用在一些领域,例如HP SFS产品等。
5、 MooseFS
MooseFS是一款相对小众的分布式文件系统,不需要修改上层应用接口即可直接使用,支持FUSE的操作方式,部署简单并提供Web界面的方式进行管理与监控,同其他分布式操作系统一样,支持在线扩容,并进行横向扩展。MooseFS还具有可找回误操作删除的文件,相当于一个回收站,方便业务进行定制;同时MooseFS对于海量小文件的读写要比大文件读写的效率高的多。
但MooseFS的缺点同样明显,MFS的主备架构情况类似于MySQL的主从复制,从可以扩展,主却不容易扩展。短期的对策就是按照业务来做切分,随着MFS体系架构中存储文件的总数上升,Master Server对内存的需求量会不断增大。并且对于其单点问题官方自带的是把数据信息从Master Server同步到Metalogger Server上,Master Server一旦出问题Metalogger Server可以恢复升级为Master Server,但是需要恢复时间。目前,也可以通过第三方的高可用方案(heartbeat+drbd+moosefs)来解决 Master Server 的单点问题。
6、MogileFS
由memcahed的开发公司danga一款perl开发的产品,目前国内使用mogielFS的有图片托管网站yupoo等。MogileFS是一套高效的文件自动备份组件,由Six Apart开发,广泛应用在包括LiveJournal等web2.0站点上。
7. FastDFS
是一款类似Google FS的开源分布式文件系统,是纯C语言开发的。FastDFS是一个开源的轻量级分布式文件系统,它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
8、GlusterFS
开源分布式横向扩展文件系统,可以根据存储需求快速调配存储,内含丰富的自动故障转移功能,且摈弃集中元数据服务器的思想。适用于数据密集型任务的可扩展网络文件系统,具有可扩展性、高性能、高可用性等特点。gluster于2011年10月7日被Red Hat收购。
9、 GridFS
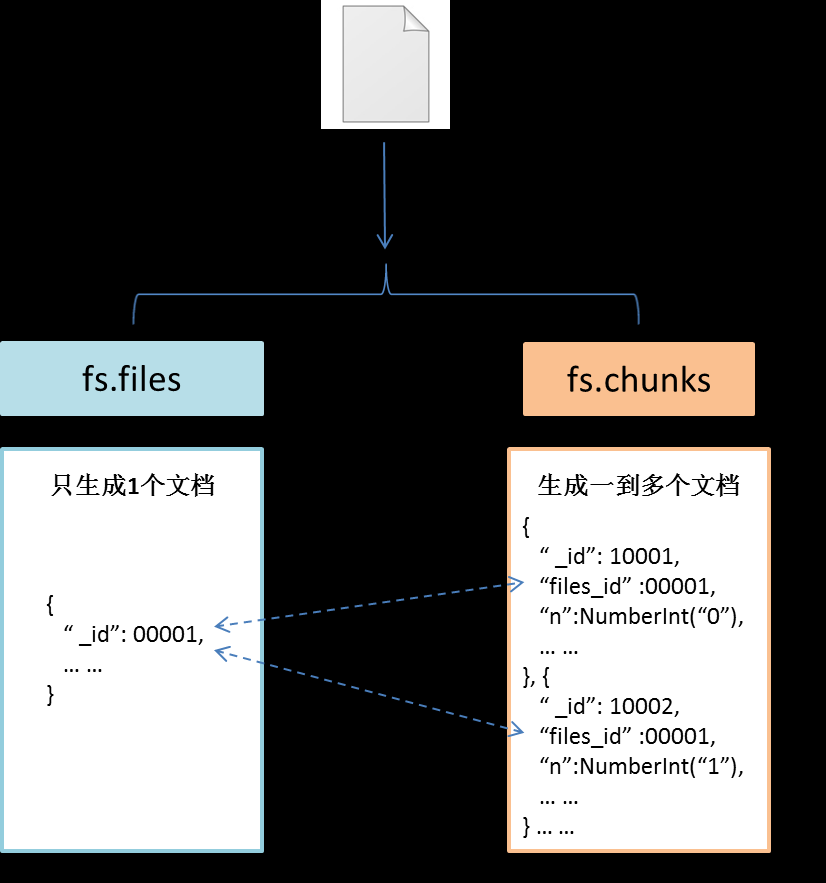
MongoDB是知名的NoSQL数据库,GridFS是MongoDB的一个内置功能,它提供一组文件操作的API以利用MongoDB存储文件,GridFS的基本原理是将文件保存在两个Collection中,一个保存文件索引,一个保存文件内容,文件内容按一定大小分成若干块,每一块存在一个Document中,这种方法不仅提供了文件存储,还提供了对文件相关的一些附加属性(比如MD5值,文件名等等)的存储。文件在GridFS中会按4MB为单位进行分块存储。
三、分布式文件系统的对比
1、整体对比
| 文件系统 | 开发者 | 开发语言 | 开源协议 | 易用性 | 适用场景 | 特性 | 缺点 |
|---|---|---|---|---|---|---|---|
| GFS | 不开源 | ||||||
| HDFS | Apache | Java | Apache | 安装简单,官方文档专业化 | 存储非常大的文件 | 大数据批量读写,吞吐量高;一次写入,多次读取,顺序读写 | 难以满足毫秒级别的低延时数据访问;不支持多用户并发写相同文件;不适用于大量小文件 |
| Ceph | 加州大学圣克鲁兹分校Sage Weil | C++ | LGPL | 安装简单,官方文档专业化 | 单集群的大中小文件 | 分布式,没有单点依赖,用C编写,性能较好 | 基于不成熟的btrfs,自身也不够成熟稳定,不推荐在生产环境使用 |
| TFS | Alibaba | C++ | GPL V2 | 安装复杂,官方文档少 | 跨集群的小文件 | 针对小文件量身定做,随机IO性能比较高;实现了软RAID,增强系统的并发处理能力及数据容错恢复能力;支持主备热倒换,提升系统的可用性;支持主从集群部署,从集群主要提供读/备功能 | 不适合大文件的存储;不支持POSIX,通用性较低;不支持自定义目录结构与文件权限控制;通过API下载,存在单点的性能瓶颈;官方文档少,学习成本高 |
| Lustre | SUN | C | GPL | 复杂,而且严重依赖内核,需要重新编译内核 | 大文件读写 | 企业级产品,非常庞大,对内核和ext3深度依赖 | |
| MooseFS | Core Sp. z o.o. | C | GPL V3 | 安装简单,官方文档多,且提供Web界面的方式进行管理与监控 | 大量小文件读写 | 比较轻量级,用perl编写,国内用的人比较多 | 对master服务器有单点依赖,性能相对较差 |
| MogileFS | Danga Interactive | Perl | GPL | 主要用在web领域处理海量小图片 | key-value型元文件系统;效率相比mooseFS高很多 | 不支持FUSE | |
| FastDFS | 国内开发者余庆 | C | GPL V3 | 安装简单,社区相对活跃 | 单集群的中小文件 | 系统无需支持POSIX,降低了系统的复杂度,处理效率更高;实现了软RAID,增强系统的并发处理能力及数据容错恢复能力;支持主从文件,支持自定义扩展名;主备Tracker服务,增强系统的可用性 | 不支持断点续传,不适合大文件存储;不支持POSIX,通用性较低;对跨公网的文件同步,存在较大延迟,需要应用做相应的容错策略;同步机制不支持文件正确性校验;通过API下载,存在单点的性能瓶颈 |
| GlusterFS | Z RESEARCH | C | GPL V3 | 安装简单,官方文档专业化 | 适合大文件,小文件性能还存在很大优化空间 | 无元数据服务器,堆栈式架构(基本功能模块可以进行堆栈式组合,实现强大功能),具有线性横向扩展能力;比mooseFS庞大 | 由于没有元数据服务器,因此增加了客户端的负载,占用相当的CPU和内存;但遍历文件目录时,则实现较为复杂和低效,需要搜索所有的存储节点,不建议使用较深的路径 |
| GridFS | MongoDB | C++ | 安装简单 | 通常用来处理大文件(超过16M) | 可以访问部分文件,而不用向内存中加载全部文件,从而保持高性能;文件和元数据自动同步 |
2、 特性对比
| 文件系统 | 数据存储方式 | 集群节点通讯协议 | 专用元数据存储点 | 在线扩容 | 冗余备份 | 单点故障 | 跨集群同步 | FUSE挂载 | 访问接口 |
|---|---|---|---|---|---|---|---|---|---|
| HDFS | 文件 | 私有协议(TCP) | 占用MDS | 支持 | 存在 | 不支持 | 支持 | 不支持POSIX | |
| Ceph | 对象/文件/块 | 私有协议(TCP) | 占用MDS | 支持 | 支持 | 存在 | 不支持 | 支持 | POSIX |
| Lustre | 对象 | 私有协议(TCP)/ RDAM(远程直接访问内存) | 双MDS | 支持 | 不支持 | 存在 | 未知 | 支持 | POSIX/MPI |
| MooseFS | 块 | 私有协议(TCP) | 占用MFS | 支持 | 支持 | 存在 | 不支持 | 支持 | POSIX |
| MogileFS | 文件 | HTTP | 占用DB | 支持 | 不支持 | 存在 | 不支持 | 不支持 | 不支持POSIX |
| FastDFS | 文件/块 | 私有协议(TCP) | 无 | 支持 | 支持 | 不存在 | 部分支持 | 不支持 | 不支持POSIX |
| GlusterFS | 文件/块 | 私有协议(TCP)/RDAM(远程直接访问内存) | 无 | 支持 | 支持 | 不存在 | 支持 | 支持 | POSIX |
| TFS | 文件 | 私有协议(TCP) | 占用NS | 支持 | 支持 | 存在 | 支持 | 未知 | 不支持POSIX |
什么是POSIX?
POSIX表示可移植操作系统接口(Portable Operating System Interface of UNIX,缩写为 POSIX ),也就是Unix下应用程序共同遵循的一种规范。支持POSIX的应用程序意味着在各个Unix系统间提供了跨平台运行的支持。
四、选型参考
- 适合做通用文件系统的有:Ceph,Lustre,MooseFS,GlusterFS;
- 适合做小文件存储的文件系统有:Ceph,MooseFS,MogileFS,FastDFS,TFS;
- 适合做大文件存储的文件系统有:HDFS,Ceph,Lustre,GlusterFS,GridFS;
- 轻量级文件系统有:MooseFS,FastDFS;
- 简单易用,用户数量活跃的文件系统有:MooseFS,MogileFS,FastDFS,GlusterFS;
- 支持FUSE挂载的文件系统有:HDFS,Ceph,Lustre,MooseFS,GlusterFS。
分布式文件存储系统简介
在分布式存储技术体系当中,分布式文件存储是其中的分类之一,也是大数据架构当中常常用到的。得益于Hadoop的高人气,Hadoop原生的HDFS分布式文件系统,也广泛为人所知。但是分布式文件存储系统,并非只有HDFS。今天的大数据开发分享,我们就主要来讲讲常见的分布式文件存储系统。
分布式文件系统,可以说是分布式系统下的一个子集,这里我们选取市场应用比较广泛的几款产品,HDFS、Ceph、FastDFS以及MooseFS来做简单的分析——

HDFS
如上所说,HDFS是分布式文件系统当中人气非常高的一个。基于Hadoop基础架构,HDFS天然就有很好的优势,尤其是面对大规模离线批处理任务,地位难以撼动。
HDFS,可以为各类分布式计算框架如Spark、MapReduce等提供海量数据存储服务,同时HBase、Hive底层存储也依赖于HDFS。与Hadoop生态的紧密联系,也使其稳稳占据市场主流地位。
优点:
高容错性:数据自动保存多个副本,副本丢失后,自动恢复
适合批处理:移动计算而非数据。数据位置暴露给计算框架
适合大数据处理:GB,TB,甚至PB级数据。百万规模以上文件数量。10K+节点规模。
流式文件访问:一次性写入,多次读取。保证数据一致性。
可构建在廉价机器上:通过多副本提高可靠性。提供容错和恢复机制。
缺点:
不适合低延迟数据访问场景:比如毫秒级,低延迟与高吞吐率
不适合小文件存取场景:占用NameNode大量内存。寻道时间超过读取时间。
不适合并发写入,文件随机修改场景:一个文件只能有一个写者。仅支持append
不符合posix语义,需要通过SDK来读写操作。对java支持良好,其他语言一般
Ceph
企业级的存储需求,通常分为块存储、文件存储和对象存储,而Ceph能够同时满足这三种需求。Ceph提供三大存储接口,能够将企业中的三种存储需求统一汇总到一个存储系统中,并提供分布式、横向扩展,高度可靠性的存储,具备高可用性、高性能及可扩展等特点。
优点:
支持对象存储(OSD)集群,通过CRUSH算法,完成文件动态定位,处理效率更高
符合posix语义,支持通过FUSE方式挂载,降低客户端的开发成本,通用性高
支持分布式的MDS/MON,无单点故障
强大的容错处理和自愈能力
支持在线扩容和冗余备份,增强系统的可靠性
缺点:
目前处于试验阶段,系统稳定性有待考究
部署和运维较复杂,集群管理工具较少
FastDFS
FastDFS是以C语言开发的一项开源轻量级分布式文件系统,提供文件存储、文件同步、文件访问(文件上传/下载)等通用文件管理操作,尤其适合以文件为载体的在线服务,如图片网站,视频网站等。追求高性能和高扩展性FastDFS,可以看做是基于文件的key value pair存储系统,称作分布式文件存储服务更为合适。
优点:
支持在线扩容机制,增强系统的可扩展性
实现了软RAID,增强系统的并发处理能力及数据容错恢复能力
支持主从文件,支持自定义扩展名
主备Tracker服务,增强系统的可用性
缺点:
不支持POSIX通用接口访问,通用性较低
对跨公网的文件同步,存在较大延迟,需要应用做相应的容错策略
同步机制不支持文件正确性校验,降低了系统的可用性
通过API下载,存在单点的性能瓶颈
MooseFS
MooseFS是在HDFS之后出现的,它也是类似的MDS+OSS架构,区别于HDFS的是,MooseFS没有对运行其上的业务做假设,它没有假设业务是大文件或海量小文件,也就是说,MooseFS的定位是像ext4、xfs、NTFS等单机文件系统一样的通用型文件存储。
优点:
扩容成本低、支持在线扩容,不影响业务,体系架构可伸缩性极强
支持POSIX通用接口访问,支持通过FUSE方式挂载,降低客户端的开发成本,通用性高
文件对象高可用,可设置任意的文件冗余程度(提供比Raid 10更高的冗余级别)
提供系统负载,将数据读写分配到所有的服务器上,加速读写性能
实现了软RAID,增强系统的并发处理能力及数据容错恢复能力
数据恢复比较容易,增强系统的可用性。有回收站功能,方便业务定制
缺点:
Master Server的单点解决方案的健壮性。Master Server一旦出问题Metalogger Server可以恢复升级为Master Server,但是需要恢复时间
Master Server本身的性能瓶颈。MFS的主备架构情况类似于MySQL的主从复制,从可以扩展,主却不容易扩展
随着MFS体系架构中存储文件的总数上升,Master Server对内存的需求量会不断增大
MinIO
什么是MinIO ?
根据官方定义:
- MinIO 是在 Apache License v2.0 下发布的对象存储服务器。 它与 Amazon S3 云存储服务兼容。 它最适合存储非结构化数据,如照片,视频,日志文件,备份和容器/ VM 映像。 对象的大小可以从几 KB 到最大 5TB。
- MinIO 服务器足够轻,可以与应用程序堆栈捆绑在一起,类似于 NodeJS,Redis 和 MySQL。
- 一种高性能的分布式对象存储服务器,用于大型数据基础设施。它是机器学习和其他大数
据工作负载下 Hadoop HDFS 的理想 s3 兼容替代品。
为什么需要MinIO?
- Minio 有良好的存储机制
- Minio 有很好纠删码的算法与擦除编码算法
- 拥有RS code 编码数据恢复原理
- 公司做强做大时,数据的拥有重要性,对数据治理与大数据分析做准备。
- 搭建自己的一套文件系统服务,对文件数据进行安全保护。
- 拥有自己的平台,不限于其他方限制。
MinIO 和其他OSS存储解决方案各有什么优缺点?
这里主要针对Ceph、Minio、FastDFS 热门的存储解决方案进行比较。
Ceph
优点
- 成熟
- 红帽继子,ceph创始人已经加入红帽
- 国内有所谓的ceph中国社区,私人机构,不活跃,文档有滞后,而且没有更新的迹象。
- 从git上提交者来看,中国有几家公司的程序员在提交代码,星辰天合,easystack, 腾讯、阿里基于ceph在做云存储,但是在开源社区中不活跃,阿里一位叫liupan的有参与
- 功能强大
- 支持数千节点
- 支持动态增加节点,自动平衡数据分布。(TODO,需要多长时间,add node时是否可以不间断运行)
- 可配置性强,可针对不同场景进行调优
缺点
学习成本高,安装运维复杂。
Minio
优点
- 学习成本低,安装运维简单,开箱即用
- 目前minio论坛推广给力,有问必答
- 有java客户端、js客户端
- 数据保护:分布式Minio采用 纠删码来防范多个节点宕机和位衰减bit rot。分布式Minio至少需要4个硬盘,使用分布式Minio自动引入了纠删码功能。
- 一致性:Minio在分布式和单机模式下,所有读写操作都严格遵守read-after-write一致性模型。
缺点
- 社区不够成熟,业界参考资料较少
- 不支持动态增加节点,minio创始人的设计理念就是动态增加节点太复杂,后续会采用其它方案来支持扩容。
FastDFS
fastdfs是阿里余庆做的一个个人项目,在一些互联网创业公司中有应用,没有官网,不活跃,6个contributors。
让我放弃FastDFS拥抱MinIO的8个瞬间
https://blog.csdn.net/qq_43842093/article/details/121867111