并行与分布式复习笔记
mulu
- 链表操作与分析
- MPI常用的API与应用
- Pthreads常用的API及其应用、互斥锁、忙等待(自旋锁)的实现与应用
- OpenMP常用的编译指令及其子句应用
- 课本典型案例:矩阵向量乘、曲边梯形面积计算、通过数学求和公式计算π、蒙特卡洛方法计算π、奇偶交换排序。
- 第一章 为什么要并行计算 2
-
- 1.1 为什么需要不断提升性能
- 1.2 为什么要构建并行系统
- 1.4 怎么编写并行程序
-
- 任务并行和数据并行 占6分
-
- 2021考题
- 1.5 并发并行分布式
- 第二章 并行硬件和并行软件 4
-
- 2.1 冯诺依曼体系结构的特点及其瓶颈
- 2.2 冯·诺伊曼模型的改进
-
- 2.2.1 缓存
- 2.2.2 虚拟存储器
- 2.2.3 低层次并行
-
- 指令级并行
- 流水线多发射问题
- 2.3 并行硬件
-
- 2.3.1 Flynn分类法 占6分
- 2021考题
- 2.3.2 Cache的特点、缺失、命中、一致性与解决办法及伪共享问题
- 2.4 共享内存
-
- 动态线程和静态线程
- 2.5 加速比、效率、阿姆达尔定律
- 2.6 可扩展性
- 2.7 并行程序设计
- 第三章 用MPI进行分布式内存编程 8
-
- 3.1 常用API及其应用
-
- 初始化
- 获取进程数量
- 通信
- 2021考题
- 3.2 用MPI实现梯形积分法
- 3.3 集合通信
- 3.4 MPI派生数据类型及MPI程序性能评估
- 3.5 用MPI实现并行排序算法
- 第四章 用Pthread进行共享内存编程 8
-
- 4.1 进程、线程和Pthreads
- 4.2 矩阵-向量乘法
- 4.3 临界区 忙等待 互斥
- 4.4 生产者-消费者同步和信号量
- 4.5 读写锁及缓存一致性 线程安全
- 第五章 openMP共享内存编程 8
- 第六章 分布式系统概述 2
链表操作与分析
MPI常用的API与应用
MPI:一种基于信息传递的并行编程技术(接口标准)。
Pthreads常用的API及其应用、互斥锁、忙等待(自旋锁)的实现与应用
Pthreads标准定义了创建和操纵线程的一整套API。
OpenMP常用的编译指令及其子句应用
用于共享内存并行系统的多处理器程序设计的一套指导性编译处理方案。OpenMp提供了对并行算法的高层的抽象描述,程序员通过在中加入专用的pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。
- parallel指令
- 用在一个代码段之前,表示这段代码将被多个线程并行执行

- 用在一个代码段之前,表示这段代码将被多个线程并行执行
- for指令
- 用于for循环之前,将循环分配到多个线程中并行执行,必须保证每次循环之间无相关性。单独使用不会实现并发执行,也不会加快运行速度,需配合parallel,表示for循环的代码将被多个线程并行执行。

- 用于for循环之前,将循环分配到多个线程中并行执行,必须保证每次循环之间无相关性。单独使用不会实现并发执行,也不会加快运行速度,需配合parallel,表示for循环的代码将被多个线程并行执行。
课本典型案例:矩阵向量乘、曲边梯形面积计算、通过数学求和公式计算π、蒙特卡洛方法计算π、奇偶交换排序。
第一章 为什么要并行计算 2
重点:并行程序设计的重要性
我们需要让程序能够更快地运行,有更加逼真的图像。为了达到这一目的,就需要将串行程序改写为并行程序
1.1 为什么需要不断提升性能
计算问题和需求在增加, 更复杂的问题有待解决
1.2 为什么要构建并行系统
因为我们想要提高计算机的性能,而性能的提高则需要提高晶体管密度
更小的晶体管 = 更快的处理器
更快的处理器 = 更高的能耗
功率消耗增加 = 热量增加
增加的热量 = 不可靠的处理器.
从单核系统转向多核处理器,也就是说我们要引入并行性。
1.4 怎么编写并行程序
任务并行和数据并行 占6分
任务并行
将任务划分为不同的子任务,由不同的核来完成,多个核协同完成总任务
数据并行
是指将待解决问题所需要处理的数据分配给各个核,每个核在分配到的数据集上执行大致相似的操作
2021考题
二.1 简答题
(1)在并行计算任务处理过程中,广泛采用哪两种方法?
答: 任务并行和数据并行 (2 分)
(2)假如 P 教授进行“英国文学调查”的授课,她有 100 个学生,还有 4 个助教。
学期结束的时候,要进行一次期末测试,试卷包括 5 道题,为了给学生打分,P 教
授和他的助教进行试卷批改,可以采用什么方法,并对方法进行阐述。
答:
第一种方案:按照每人批改 100 份试卷中的一道题 任务并行 (2 分)
第二种方案:按照每人批改 20 份试卷 数据并行 (2 分)
核与核之间通常需要进行协同它们的任务.
通信( Communication ):一个或多个核将其当前的部分总和发送给另一个核.
负载平衡( Load balancing ):在内核之间均匀地分配工作,这样一个内核就不会负载过重。
同步(Synchronization):因为每个核都有自己的工作节奏,所以要确保核不会比其他核走得太远
1.5 并发并行分布式
并发计算:多个任务可以在任何时刻进行。
并行计算:多个任务紧密合作来解决一个问题。
分布式计算:可能需要与其他程序合作来解决问题。
第二章 并行硬件和并行软件 4
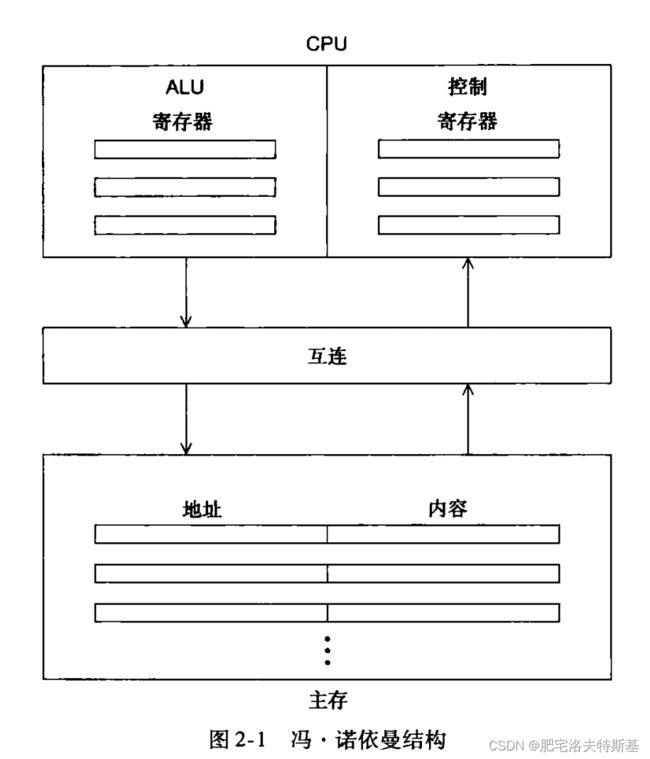
重点:理解什么是并行计算以及并行体系结构、 Flynn 分类法、性能分析、并行加速比与效率;并行程序性能优化2.1 冯诺依曼体系结构的特点及其瓶颈
瓶颈:主存与CPU之间分离
我们需要知道:
- 数据和指令是存在主存中的
- 数据和指令是通过互连结构传输到CPU的,这个互连结构通常是总线。
- 因为互连结构限定了指令和数据访问的速率,所以程序运行所需要的大部分数据和指令被有效地与CPU隔离开。
2.2 冯·诺伊曼模型的改进
三种改进措施:缓存(caching),虚拟存储器(或虚拟内存)、低层次并行
2.2.1 缓存
缓存将互连通路加宽,使得一次内存访问能存取一整块代码和数据,而不只是单条指令和单条数据。这些块称为高速缓存块或者高速缓存行。
而且不再是将所有数据和指令存储在主存中,可以将部分数据块或者代码存储在一个靠近cpu寄存器的特殊存储器里。
高速缓冲存储器-cahe-缓存
程序访问完一个存储区域往往会访问接下来的区域,这个原理称为局部性。在访问完一个内存区域(指令或者数据),程序会在不久的将来(时间局部性)访问邻近的区域(空间局部性)。
2.2.2 虚拟存储器
如果我们运行一个非常大的程序或者一个访问非常大数据集的程序,所有的指令和数据可能都不能放进主存中。利用虚拟存储器(或虚拟内存),使得主存可以作为辅存的缓存。它通过在主存中只存放当前执行程序所需要用到的部分,来利用时间和空间局部性;那些暂时用不到的部分存储在辅存的块中,称为交换空间(swap space)中。
2.2.3 低层次并行
指令级并行
指令级并行(Instruction-Level parallelism, ILP)通过让多个处理器部件或者功能单元同时执行指令来提高处理器的性能。有两种主要方法来实现指令级并行:流水线和多发射。流水线是指将功能单元分阶段安排;多发射是指让多条指令同时启动。
流水线多发射问题
- 流水线
- 一条指令完整的执行步骤包括取指令、指令译码、执行指令三个步骤。流水线方法就是将指令的执行分成若干个小步骤,分别交由不同的线程处理,每个线程只完成自己负责的那一部分。
- 多发射
- 通过增加硬件的方式,将取指令和指令译码实现并行,一次性取出多条指令,然后分发给多个并行的指令译码器,进行译码,然后对应交给不同的功能单元去处理。这样,在一个时钟周期里,能够完成的指令就不只一条了。这种 CPU 设计,叫作多发射
2.3 并行硬件
2.3.1 Flynn分类法 占6分
Flynn分类法,是基于指令流和数据流的数量对计算机进行分类的方法。
一系列修改那些流经数据处理单元的数据(数据流)的命令,可以被认为是一个指令流。
以下是四种不同的情况:
单指令流单数据流(SISD)——冯诺依曼系统,传统的386串行计算器,包含单个CPU,它从存储在内存中的程序那里获得指令,并作用于单一的数据流。
单指令流多数据流(SIMD)——单个的指令流作用于多于一个的数据流上。例如有数据4、5和3、2,一个单指令执行两个独立的加法运算:4+5和3+2,就被称为单指令流多数据流。SIMD的一个例子就是一个数组或向量处理系统,它可以对不同的数据并行执行相同的操作。(并行架构,比如向量机,所有核心指令唯一,但是数据不同,现在 CPU 基本都有这类的向量指令)
多指令流单数据流(MISD)——用多个指令作用于单个数据流的情况实际上很少见。这种冗余多用于容错系统。 (少见,多个指令围殴一个数据)
多指令流多数据流(MIMD)——这种系统类似于多个SISD系统。实际上,MIMD系统的一个常见例子是多处理器计算机,如Sun的企业级服务器。 (并行架构,多核心,多指令,异步处理多个数据流,从而实现空间上的并行,MIMD 多数情况下包含 SIMD,就是 MIMD 有很多计算核,计算核支持 SIMD)
注:GPU 属于 SPMD,但是其可以使用 SIMD 并行
2021考题
二.2 简答题
在冯·诺依曼系统中加入缓存的虚拟内存改变了它作为 SISD 系统的类型吗?如果加入流水线呢?多发射或硬件多线程呢?
答:
(1)缓存和虚拟内存的最基本实现都不会改变每次可以执行的指令数,也不会改变一次可以操作的数据量。然而,更复杂的系统可以提供一些并发性:当出现缓存缺失或页缺失时,CPU 可能会尝试执行不涉及缺失数据或指令的其他指令。这样的系统可能被描述为具有有限的 MIMD 能力:加载/存储指令可以与其他指令同时执行,实现访存与计算并行。2 分
(2)我们可以把流水线看作是一条复杂指令处理多个数据项。单指令多数据SIMD,因此它有时被认为是SIMD。2 分
(3)多发和硬件多线程实现不同的指令处理不同的数据。 多指令多数据MIMD,所以它们可以被认为是 MIMD的例子。2 分
2.3.2 Cache的特点、缺失、命中、一致性与解决办法及伪共享问题
Cache相关:
- Cache是用来对内存数据的缓存
- CPU要访问的数据在Cache中有缓存,称为“命中” (Hit),反之则称为“缺失” (Miss)
- CPU访问它的速度介于寄存器与内存之间(数量级的差别)。实现Cache的花费介于寄存器与内存之间
Cache写方式:回写和写直达
一致性问题与解决方案:
问题:
- 单核处理器系统的Cache对如下情况没有提供保证:在多核系统中,各个核的Cache存储相同变量的副本,当一个处理器更新Cache中该变量的副本时,其他处理器应该知道该变量已更新,即其他处理器中Cache的副本也应该更新。即多个CPU core有自己的Cache,需要保证多个Cache之间数据的一致性。
解决方案:
- 监听 Cache 一致性
当多个核共享总线时,总线上传递的信号都能被连接到总线的所有核“看”到。因此,当核0更新它Cache中X的副本时,如果它也将这个更新信息在总线上广播,并且假如核1正在监听总线,那么它会知道X已经更新了,并将自己Cache中的X的副本标记为非法的。 - 基于目录的Cache 一致性协议
使用一种称为目录的数据结构,该目录存储每个Cache line的状态.
当一个变量被更新时,就会查询目录,并将所有包含该变量的cache line置为非法
伪共享:
- 在多核的CPU架构中,每⼀个核⼼core都会有⾃⼰的缓存空间,因此如果⼀个变量如果同时存在不同的核⼼缓存空间时,就会出现伪共享(false sharing)的问题。
补充
在多核的CPU架构中,每⼀个核⼼core都会有⾃⼰的缓存空间,因此如果⼀个变量如果同时存在不同的核⼼缓存空间时,就会出现伪共享(false sharing)的问题。
- 表现
并发的修改在⼀个缓存⾏中的多个独⽴变量,看起来是并发执⾏的,但实际在
CPU处理的时候,是串⾏执⾏的,并发的性能⼤打折扣。 - 避免伪共享
不同线程操作的对象处于不同的缓存⾏即可。
- 伪共享不会引发错误结果,但是,它能引起过多不必要的访存,降低程序的性能。可以通过在线程或者进程中临时存储数据,再把临时存储的数据更新到共享存储来降低伪共享带来的影响
2.4 共享内存
动态线程和静态线程
- 静态线程:线程池中的常驻线程
- 动态线程:即救急线程,用完即销毁
动态线程
- 主线程等待任务,fork新线程,当新线程完成时任务后,结束新线程
- 资源的有效使用,但是线程的创建和终止非常耗时.
静态线程 - 创建线程池并分配任务,但线程不被终止直到被清理.
- 性能更好,但可能会浪费系统资源.
2.5 加速比、效率、阿姆达尔定律
加速比:
同一个任务在单处理器系统和并行处理器系统中运行消耗的时间的比率,用来衡量并行系统或程序并行化的性能和效果。

串⾏运⾏时间为T串,并行运行时间为T并,则最佳的预期为:T并 = T串 / p。此时我们称并⾏程序有线性加速比。
实际上是不可能得到线性加速比的。
并⾏程序的加速比为S = T串 / T并
⼀般都是S < p。S = p就是线性加速比。
S > p(超线性加速比)在实践中是可能出现的。比如:串行算法计算量⼤于并⾏算法、硬件问题不利于串行算法
效率E

当问题的规模变大时,加速比和效率增加;当问题的规模变小时, 加速比和效率降低

并行算法总额外开销:T开销 = p * T并 - T串。
随着问题规模的增加,T开销比T串行增长得慢。

阿姆达尔定律:
除非所有的串行程序都能够并行,否则无论可用的核的数量再多,加速将非常有限
- Amdahl 定律是计算机系统中的一个重要定律,核心思想是:我们对计算机系统的某一部分加速的时候,该加速部分对系统整体性能的影响取决于该部分的重要性和加速程度。
- 理想并行效率E = 1,实际在0到1之间,处理器数量增大而趋近于0

2.6 可扩展性
粗略地讲,如果一个技术可以处理规模不断增加的问题,那么它就是可扩展的
如果在增加进程/线程的数量时,可以维持固定的效率,缺不增加问题规模,那么程序称为强可扩展(strongly scalable).
如果在增加进程/线程数量的同时,只有以相同倍率增加问题规模才能使效率值保持不变,那么程序就称为弱可扩展的(weakly scalable)
2.7 并行程序设计
1)划分(partitioning) 。将要执行的指令和数据按照计算部分拆分成多个小任务。这一步的
关键在于识别出可以并行执行的任务。
2)通信(communication)。确定上一步所识别出来的任务之间需要执行那些通信。
3)凝聚或聚合(agglomeration or aggregation)。将第一步所确定的任务与通信结合成更大的任务。例如,如果任务A必须在任务B之前执行,那么将它们聚合成一个简单的复合任务可能更为明智。
4)分配(mapping)。将上一步聚合好的任务分配到进程/线程中。这一步还要使通信量最小化,使各个进程/线程所得到的工作量大致均衡。
第三章 用MPI进行分布式内存编程 8
重点:掌握 MPI 编程规范、进程通信与同步、进程拓扑结构。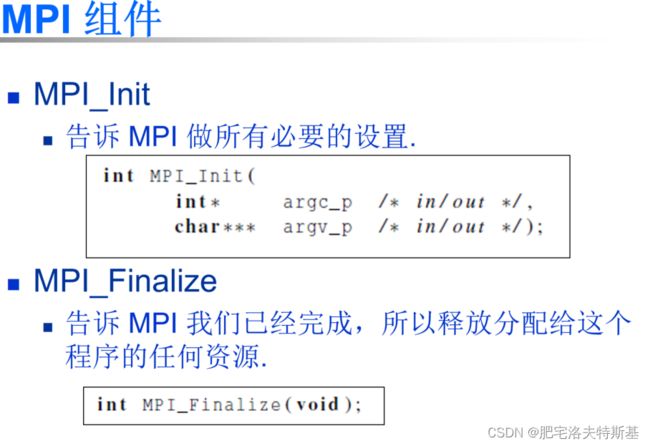
3.1 常用API及其应用
| API | 应用 |
|---|---|
| int MPI_Init() | 了告知MPI系统进行所有必要的初始化设置 |
| int MPI_Finalize() | 告诉 MPI 我们已经完成,所以释放分配给这个程序的任何资源 |
| int MPI_Comm_size() | 获取指定通信域的进程个数。其中,第一个参数是通信子,第二个参数返回进程的个数 |
| int MPI_Comm_rank() | 获得当前进程在指定通信域中的编号,将自身与其他程序区分。其中,第一个参数是通信子,第二个参数返回进程的编号 |
| int MPI_Send() | 发送缓冲区中的信息到目标进程 |
| int MPI_Recv() | 接受send的信息 |
| int MPI_Get_Count() | 会返回count参数接收到的元素数量 |
| int MPI_Reduce() | 规约函数,所有进程将待处理数据通过输入的操作子operator计算为最终结果并将它存入目标进程中。 |
| int MPI_Bcast() | 广播函数,从一个id值为source的进程将一条消息广播发送到通信子内的所有进程,包括它本身在内。 |
初始化
int MPI_Init(int *argc, char **argv)
int MPI_Finalize(void)
获取进程数量
int MPI_Comm_size(MPI_Comm comm, int *rank)
int MPI_Comm_rank(MPI_Comm comm, int *rank)
通信
假如 char message[100];
int MPI_Send(
void* msg_buf_p // 发送缓冲区的起始地址;就是message的数组名
int buf_size // 缓冲区大小; strlen(message)+1
MPI_Datatype msg_type // 发送信息的数据类型;MPI_CHAR
int dest // 目标进程的id值;0
int tag // 消息标签;
MPI_Comm communicator // 通信子;
)
假如 char message[100];
int MPI_Recv(
void* msg_buf_p // 缓冲区的起始地址;就是message的数组名
int buf_size // 缓冲区大小;message数组定义的大小 也就是100
MPI_Datatype msg_type // 发送信息的数据类型;MPI_CHAR
int dest //目标进程的id值;srouce
int tag // 消息标签;
MPI_Comm communicator // 通信子;
MPI_Status *status_p // status_p对象,包含实际接收到的消息的有关信息)

接收者可以在不知道以下信息的情况下接收消息:
- 消息中的数据量,
- 消息的发送者,
- 或消息的标签.
消息传递代码
#include 2021考题
下面代码是 mpi_output.c,该程序实现按进程号的顺序打印,即,进程 0 先输
出,然后进程 1,以此类推可以将消息发送到进程 0 进行打印,根据注释完成程序填空。
#include 3.2 用MPI实现梯形积分法
#include 3.3 集合通信
int MPI_Reduce(
void * input_data_p : 每个进程的待处理数据存放在input_data_p中;
void * output_data_p : 存放最终结果的目标进程的地址;
int count : 缓冲区中的数据个数;
MPI_Datatype datatype : 数据项的类型;
MPI_Op operator : 操作子,例如加减;
int dest_process : 目标进程的编号;
)
MPI_Reduce(&local_int, &total_int, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);