数据仓库(跟做)
第一章 数据仓库Data Warehouse
1.1 数据仓库概念
1. 数据仓库(Data Warehouse):是为企业所有决策制定过程,提供所有系统数据支持的战略集合。为企业决策提供数据支撑
2. 通过对数据仓库中数据的分析,可以帮助企业改进业务流程,控制成本,提高产品质量等。
3. 数据仓库不是数据的最终目的地,而是为数据最终目的地做好准备:对数据进行 清晰->转义 ->分类 -> 重组 -> 合并 -> 拆分 ->统计等等。

1.2 数据仓库详细解释

1.2.1 获取数据部分

企业中获取下列三类数据:
业务数据:用户加购物车,下订单,付款等数据
用户行为数据:通过前端埋点获取用户行为数据,比如浏览时长等数据
爬虫数据:爬取别的公司的数据,别乱进行
传输这些数据到数据蚕仓库,进行存储,分析,计算,然后为企业决策提供技术支撑。
所以,java前端与大数据框架是闭环的,缺一不可
1.2.2 传输部分

把从数据来源得到的数据(文件形式)传输到数据目标地址(数据仓库,存储在hive(hive底层数据存储在hdfs中))
1. 使用flume传输用户行为数据
2. 使用sqoop传输业务数据(存储在mysql)到数据仓库(数据仓库,存储在hive(hive底层数据存储在hdfs中)),有多种传输方式,选择最适合的
1.2.3 数据仓库部分

--数据仓库不是数据的最终目的地,而是为数据最终目的地做好准备:对数据进行 清晰->转义 ->分类 -> 重组 -> 合并 -> 拆分 ->统计等等。
--数据仓库分为5层:ODS DWD DWS DWT ADS
1. ODS层:数据备份,备份元数据,假如后面层中某一层数据处理失败并且数据被损坏了,就可以从ODS层中快速拿到元数据
2. DWD层:数据清洗层,清除不合格的脏的数据(比如字段少了的数据,不完整的日志),留下合格的干净的数据,完成数据的清晰
3. DWS层DWT层:对一些小的表进行Join形成大的宽表
(1) DWS层:按天聚合数据,形成多张主题的大表
(2)DWT层:累积型聚合,比如从某用户注册网站到现在为止的数据变化,都会放到DWT进行处理
4. ADS层:数据可视化层,数据的统计,可视化展现,
(1)可以处理好的数据输出到报表系统中,可以明显的看出数据变化趋势
(2)可以做用户画像系统,给用户打标签
-----用户画像分为三个等级
->统计类标签(易)
->规则类标签(易)
->机器学习标签(难)使用算法比较强
(3)为推荐系统做准备,通常用户画像和推荐系统是绑定在一起,推荐系统也需要算法
(4)机器学习:包括推荐系统,是个大方向,涉及大量算法
1.2.4 任务调度
任务调度决定任务什么时候启动,什么时候结束
第二章 项目需求及架构设计
2.1 项目需求分析
产品经理得到的需求信息来源:
1. 老板
2. 客户
3. 设计人员设计过程发现的需求
---------------------
具体需求:
1. 用户行为数据采集平台搭建:设计flume传输参数,要不要增加卡夫卡缓存数据等问题
2. 业务数据采集平台搭建:配置设计sqoop.....
3. 数据仓库纬度建模:设计层次,每层需要做什么,那些表需要照应在一起,表样式......
4. 分析,设备,会员,商品,地区,活动等电商核心主题, 统计的报表指标近100个
5. 采用即席查询工具,随时进行指标分析
6. 对集群性能进行监控:,监控每一个框架的进程的好坏,发生异常要报警:比如hadoop某节点挂掉了,但是集群依旧在运行,在接收数据,越积越多,错误很大,就需要有报警系统,任何一个节点出错误都能及时检测到并且报警(电话,短信等)
7. 元数据管理:对hive元数据进行管理,层次执行中,某一环节某些指标被破坏,元数据管理可以把所有任务,任务的依赖关系在图形化页面上显示出,就可以知道那个指标没有出来,考虑先抢救更重要的任务
8.质量监控:数据质量监控,监控数据的异常变化,比如交易额急剧上升或者下降,可能是计算错误,当数据范围超过设计的值范围,就会报警
9. 权限管理:数仓中有很多表,给表设置权限,不是每一张表大家都能看到,比如交易额只能老板看,或者给字段设置权限
2.2 项目框架
2.2.1 技术选型
1. 技术选型需要考虑的因素?
1. 技术选型主要考虑的因素:数据量大小,业务需求,行业内经验,技术成熟度,开发维护成本,总成本预算

考虑因素:
1.数据量决定未来技术的选型:
2.业务需求:比如计算速度要求快慢就决定不同的技术框架
3.行业内经验:大厂用什么技术,说明已经调查测验过了,我们就跟着用,顺应技术潮流
4.技术成熟度:普通数仓,中台(大厂使用),数据湖(成熟)hudi
5.开发维护成本: 物理机,便宜但是考虑存放地,维护人员,风扇降温等因素,最后不一定划算;云主机,贵,但是不需要考虑其他问题
6.总成本预算:
2. 技术选型
1.数据采集传输:
使用:
(1)flume专门传输文件日志,
(2)sqoop专门传输业务数据,
(3)kafaka缓冲数据,消除风险
不选用:
----Logstash属于ELk框架,ELk框架一般小公司使用,分析的指标并不复杂
----DataX,和sqoop市场使用量不相上下
2. 数据存储:
使用:
(1)HDFS:存储海量数据
(2)MySQL:在ADS层(可视化层)存储小量数据,方便后期快速的可视化展示
(3)Hbase:存储kylin多为分析快速查询框架的数据
不选用:
---redis:实时数仓使用,这个离线数仓不使用
---MongoDB:一般存放爬虫数据
3. 数据计算:
使用:
(1)Hive:底层走MR,数据是落盘的,有suffle
(2)Tez:数据完全放在内存中进行计算,比较消耗内存,但是查询速度很快
(3)spark:部分数据放在内存,部分数据放在磁盘,计算比较可靠,速度也快,相对Hived的MR引擎速度快,因为suffle需要落盘。
不选用:
---Finhk,Strom:使用在实时数仓
4.数据查询:临时的查询某指标
使用:
(1)PreSto:
(2) Kylin:与Hbase配套使用
不选用:
---Impala:比较适合在CDH框架使用
---Druid: 快速实时查询,通常用在实时数仓场景
---ClickHouse: 快速实时查询,通常用在实时数仓场景
---Doris:通常用在实时数仓场景
5. 数据可视化:
使用:
(1)Echarts:
(2)Superset
不使用:
---QuickBI(针对离线数据),DataV(针对实时数据,大屏显示):使用更好,页面更好看,但是不开源,阿里的框架
6. 任务调度
使用
(1)Azkaban:简单实用上手快,中小型使用多
不使用:
---Oozie:功能多,框架重
---DolphinScheduler:国内开发的,可视化页面好看
---Airflow:python脚本写的
7. 集群监控
使用:
(1)Zabbix:离线使用
不使用:
Promethes:实时使用
8. 元数据管理:监控那个层次那个指标没有正常输出
Atlas:
9. 去哪先管理:
使用:Ranger
不使用Sentry
2.2.2 系统数据流程设计

1. 导入用户行为数据到Hadoop中

解释:
2. 埋点用户行为数据:用户在使用产品过程中,与客户端产品交互过程中产生的数据,比如页面浏览,点击,停留,评论,点赞,收藏等。
3. 业务交互数据采集和用户行为数据采集都会用到Nginx,起到负载均衡的作用,均匀的分配数据到几台服务器中,那么每台服务器都不会有太大的压力
4. 日志服务器中的日志文件将保存30天,如果后面数仓瘫痪了,就能找到原始数据。在大数据场景中,数据最重要,磁盘最廉价,所以用磁盘多备份好原始数据文件,用磁盘可靠性保证数仓的数据安全
5. 使用flume采集用户行为数据到Hadoop,要考虑:
(1)Flume组成,Put事务,Take事务
(2)Flume三个器:source,channel,sink的选择
(3)Flume优化
6. kafka消息缓存·,需要考虑:
(1)卡夫卡 基本信息
(2)kafka挂了
(3)kafka丢了
(4)kafka重复
(5)kafka积压
(6)kafka优化
(7)kafka高效读写原因
7. 安装kafka就得安装zookeeper:
(1)zookeeper部署多少台
(2)zookeeper选举机制,Paxos算法
8. Flume从Kafka消费到hadoop(简单配置就可以完成对应功能)
9. HDFS小文件:从Flume传输过来的数据,落盘到HDFS中,很有可能会产生小文件,就要考虑解决小文件的方法:
(1)Har归档
(2)CombineTextInputformat
(3)JVM重用
2. 导入业务数据到Hadoop中
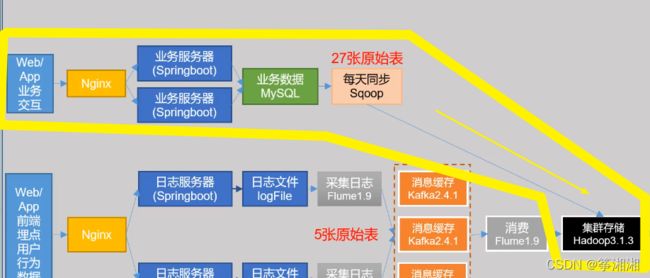
1. 业务交互数据:业务流程中产生的登录,订单,用户,商品,支付等相关的数据,通常存储在DB(database:数据库,如MySQL,Oracle)中
2. 使用sqoop从Mysql导入数据到HDFS,需要考虑
(1)输出端参数配置
(2)输入端参数配置
(3)发生空值,一致性,数据倾斜应该怎么办
(4)sqoop每天的导入数据量,执行时间如何分配
3.
3. 数仓具体分层

数仓核心·维度建模
1. 使用Hive on Spark引擎进行数据分析,需要考虑:
(1)Hive内部表,外部表的区别
(2)4个·By
(3)系统函数
(4)自定义UDF,UDTF函数
(5)窗口函数
(6)HIVE优化,数据倾斜
(7)Hive引擎
(8)数据备份
2. 分层的目标:快速统计出对应的指标,应对任何数据的变化
3.
4. 数据可视化

拿到统计分析好的数据进行可视化展示
5. 任务调度+元数据管理+权限管理+数据质量监控

6. 实时监控

监控各个节点是否正常工作
2.2.3 框架版本选型
1. Apache/CDH/HDP版本选择
1. Apache:开源麻烦运维麻烦,组件兼容性需要自己调研(一般大厂有专业的运维人员,会使用这个版本),建议使用
2. CDH:国内使用很多,但是CM免费(到3.3.2)不开源,新版本CDP7.0收费,一个节点一万美金/年
3. HDP:开源,可以进行二次开发,但是没有CDH稳定,国内使用比较少

2. 云服务选择
公司想快速搭建服务
1. 阿里云:EMR,MaxCompute,DataWorks
EMR,:在里面选择组件,会自动搭建部署框架
MaxCompute:集成多个框架的功能,省去框架间的数据传输问题
2. 亚马逊云:EMR,
3. 腾讯云:EMR
4. 华为云:EMR
3. Apache框架版本
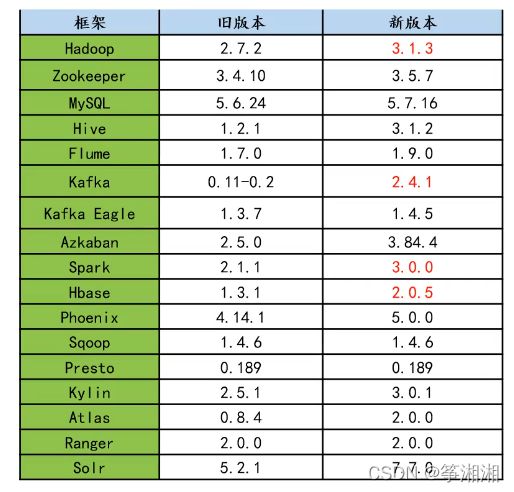
1. 为了兼容性,必须使用一整套
2. 框架选型尽量不要选择最新的框架,选择最新框架半年前左右的稳定版
2.2.4 服务器选型

1. 当购买物理机超过10台以上,就需要专业的运维人员,电费也是很大的开销,空调费,存放地,
2. 云主机缩短开发周期
3. 融资上市,先用云主机搭建效果,拉投资,拉到投资再购买物理机,为了数据安全
4.
2.2.5 集群资源规划设计
2.2.5.1 如何确定集群规模?

集群规模决定服务器的购买数量
1. 如何确认集群规模(假设一台服务器8T磁盘,128G内存)
(1)每天日活用户100万(中小型公司),没人平均一天产生100条数据:100万*100条=1亿条
注释:中小型企业在初期不一定每天每用户产生100条数据,因为统计指标可能少(比如20个)
(2)每条数据有1K左右,每天数据总量:100000000/1024/1024=约100G
一般一条用户数据在0.5k~2k
(3)如果半年内不扩容服务器:100G*180天/1024=约18T
(4)每天数据3个副本:18T*3=54T
(5)预留20%~30%Buf=54T/0.7=77T
(6)最终理论上:8T*10台服务器
2. 数据仓库会进行数仓分层,加上数据压缩,具体的量需要重新计算
数据压缩:100G-->4~5G
中小型公司(每天100G数据量),半年内不扩容的话,3~5台服务器足够,1~2年不扩容,10台左右可以。
2.2.5.2 集群资源规划设计
1. 在企业中通常会搭配一套生产集群和一套测试集群。
2. 生产集群运行生产任务
3. 测试集群用于上线前代码的编写和测试
1. 生产集群
规划原则:
(1)消耗内存的分开
(2)数据传输紧密的放在一起(kafka,zookeeper),传输速率比较快
(3)客户端尽量放在一两台服务器上,方便外部访问,避免多节点客户端带来的权限问题
(4)有依赖关系的尽量放在同一台服务器(例如:Hive和Azkaban Executor)

2. 测试集群
1. 一般企业里测试集群由3台服务器组成,三台服务器可以搭建一个集群
2. 第一台资源多一点,因为配置比较高(一般配置6G内存,从节点4G内存)
3. 规划符合生产集群规划原则

第三章 用户数据生成模块
虽然我们可以在客户端点击产生数据,但是太慢了
所以需要准备一个模块,模拟生成大量我们需要的数据,方便学习期间学习
3.1 目标数据
需要收集和分析的数据(针对前端埋点用户数据,业务数据后续再说)有:
(1)页面数据
(2)事件数据
(3)曝光数据
(4)启动数据
(5)错误数据
3.1.1 页面

1. 页面本身静态展示项的数据:
(1)页面id
(2)页面对象id(比如这个商品的id)
(3)页面对象类型(比如这个商品属于什么类型,数码产品,食物或是其他)
(4)上页id(比如手机上一页是数码产品)
页面数据主要记录一个页面的用户访问情况包括:
(1)访问时间/跳入时间(什么时间点访问的)
(2)停留时间
(3)页面来源类型(比如通过搜索来到这个页面)
(4)页面路径
等等·
3. 字段:page_id: 字段描述
home("首页"),
category("分类页"),
discovery("发现页"),
top_n("热门排行"),
favor("收藏页"),
search("搜索页"),
good_list("商品列表页"),
good_detail("商品详情"),
good_spec("商品规格"),
comment("评价"),
comment_done("评价完成"),
comment_list("评价列表"),
cart("购物车"),
trade("下单结算"),
payment("支付页面"),
payment_done("支付完成"),
orders_all("全部订单"),
orders_unpaid("订单待支付"),
orders_undelivered("订单待发货"),
orders_unreceipted("订单待收货"),
orders_wait_comment("订单待评价"),
mine("我的"),
activity("活动"),
login("登录"),
register("注册");
4. 字段:last_page_id: 上页id
5. 字段:page_item_id: 页面对象类型
sku_id("商品skuId"),
keyword("搜索关键词"),
sku_ids("多个商品skuId"),
activity_id("活动id"),
coupon_id("购物券id");
6. 字段:page_item: 页面对象id
7. 字段:sourceType: 页面来源类型
promotion("商品推广"),
recommend("算法推荐商品"),
query("查询结果商品"),
activity("促销活动");
8. 字段:during_time :停留时间
9. 字段: ts : 跳入时间
3.1.2 事件(动作日志)
1. 事件数据也叫事件日志,动作日志
2. 事件数据主要记录一个具体操作行为,包括
(1)操作行为的类型
(2)操作的对象
(3)操作对象类型
(4)操作时间

1. 字段: action_id: 动作id
favor_add("添加收藏"),
favor_canel("取消收藏"),
cart_add("添加购物车"),
cart_remove("删除购物车"),
cart_add_num("增加购物车商品数量"),
cart_minus_num("减少购物车商品数量"),
trade_add_address("增加收货地址"),
get_coupon("领取优惠券");
注:对于下单、支付等业务数据,可从业务数据库获取。
2. 字段: item_type 动作目标类型
sku_id("商品"),
coupon_id("购物券");
3. 字段 item :动作目标id
4. 字段 ts :动作时间
3.1.3 曝光
1. 曝光:只要在用户页面上显示出来了,甭管用户眼睛看到没有,都叫曝光
2. 曝光数据主要记录:
(1)曝光类型
(2)曝光对象类型
(3)曝光对象
(4)曝光顺序

displayType 曝光类型
promotion("商品推广"),
recommend("算法推荐商品"),
query("查询结果商品"),
activity("促销活动");
item_type 曝光对象类型
sku_id("商品skuId"),
activity_id("活动id");
item 曝光对象id
order 曝光顺序

3.1.4 启动
启动数据记录应用的启动信息

字段名称 字段描述
1. entry 启动入口
icon("图标"),
notification("通知"),
install("安装后启动");
2. loading_time 启动加载时间
3. open_ad_id 开屏广告id
4. open_ad_ms 广告播放时间
5. open_ad_ms 广告播放时间
6. ts 启动时间
3.1.5 错误
错误数据记录应用使用过程中的错误信息,包括错误编码和错误信息
字段名称 字段描述
1. error_code 错误码
2. msg 错误信息(错误的描述,比如404,405)
3.2 数据埋点
3.2.1 主流埋点方式
1. 埋点一般有前端程序员完成,后端开始工作是接收埋点产生的数据
2. 目前主流的埋点方式有代码埋点(前端/后端),可视化埋点,全埋点
1. 代码埋点(不推荐,太麻烦)

1. 通过调用埋点SDK函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据。
2. 简单来说就是在页面中的按钮加入JS Onclick,当点击这个按钮的时候,对应的Onclick函数调用SDK提供的数据发送接口,发送数据到日志服务器
3. SDK:软件开发工具包是一些被软件工程师用于为特定的软件包、软件框架、硬件平台、操作系统等创建应用软件的开发工具的集合,一般而言SDK即开发Windows平台下的应用程序所使用的SDK。它可以简单的为某个程序设计语言提供应用程序接口API的一些文件,但也可能包括能与某种嵌入式系统通讯的复杂的硬件。一般的工具包括用于调试和其他用途的实用工具。SDK还经常包括示例代码、支持性的技术注解或者其他的为基本参考资料澄清疑点的支持文档。
2. 可视化埋点

1. 只需要开发人员集成采集SDK,不用写入埋点代码,业务人员就可以通过访问分析平台的圈选功能,圈出需要对用户行为进行捕捉的控件并对该事件命名。圈选完毕之后,这些配置会同步到各个用户的终端上,由采集SDK按照圈选出来的配置自动进行用户行为数据的采集和发送
2. 开发人员开发一个后台Web页面,在上面进行相关配置,里面按钮都对应前端页面按钮,当用户点击前端Web页面按钮,自动选择到后端Web页面里对应的按钮
3. 开发效率高
3. 全埋点
1. 在应用里放第三方SDK,会自动埋点所有用户数据,发采集,发送用户行为数据到日志服务器上
2. 全埋点是通过在产品中嵌入SDK,前端自动采集页面上的全部用户行为事件,上报埋点数据,相当于做了一个统一的埋点。然后再通过界面配置哪些数据需要在系统里面进行分析。
3.市场主流SDK,神策,百度
3.2.2 埋点数据上报时机
1.每个事件、动作、错误等,产生后,立即发送。优点,响应及时。缺点,对服务器接收数据压力比较大。
就是 产生一条发一条:效率高但是网络IO增加
2. 在离开该页面时,上传在这个页面产生的所有数据(页面、事件、曝光、错误等)。优点,批处理,减少了服务器接收数据压力。缺点,不是特别及时。
就是页面离开后统一发送:网络IO少但是时效性差
3.2.3 埋点数据日志结构
日志结构分为两类
1. 普通页面埋点日志
2. 启动日志
1. 普通页面埋点日志
1. 普通页面埋点日志
(1)每条日志包含当前的页面信息,所有事件(动作),所有曝光信息,所有错误信息
(2)还包含一系列公共信息,包括设备信息,地理位置,应用信息等
格式如下
{
"common": { -- 公共信息
"ar": "230000", -- 地区编码
"ba": "iPhone", -- 手机品牌
"ch": "Appstore", -- 渠道
"is_new": "1",--是否首日使用,首次使用的当日,该字段值为1,过了24:00,该字段置为0。
"md": "iPhone 8", -- 手机型号
"mid": "YXfhjAYH6As2z9Iq", -- 设备id
"os": "iOS 13.2.9", -- 操作系统
"uid": "485", -- 会员id
"vc": "v2.1.134" -- app版本号
},
"actions": [ --动作(事件)
{
"action_id": "favor_add", --动作id
"item": "3", --目标id
"item_type": "sku_id", --目标类型
"ts": 1585744376605 --动作时间戳
}
],
"displays": [
{
"displayType": "query", -- 曝光类型
"item": "3", -- 曝光对象id
"item_type": "sku_id", -- 曝光对象类型
"order": 1, --出现顺序
"pos_id": 2 --曝光位置
},
{
"displayType": "promotion",
"item": "6",
"item_type": "sku_id",
"order": 2,
"pos_id": 1
},
{
"displayType": "promotion",
"item": "9",
"item_type": "sku_id",
"order": 3,
"pos_id": 3
},
{
"displayType": "recommend",
"item": "6",
"item_type": "sku_id",
"order": 4,
"pos_id": 2
},
{
"displayType": "query ",
"item": "6",
"item_type": "sku_id",
"order": 5,
"pos_id": 1
}
],
"page": { --页面信息
"during_time": 7648, -- 持续时间毫秒
"item": "3", -- 目标id
"item_type": "sku_id", -- 目标类型
"last_page_id": "login", -- 上页类型
"page_id": "good_detail", -- 页面ID
"sourceType": "promotion" -- 来源类型
},
"err":{ --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744374423 --跳入时间戳
}
2. 启动日志
启动日志主要包含公共信息,启动信息,错误信息
{
"common": {
"ar": "370000",
"ba": "Honor",
"ch": "wandoujia",
"is_new": "1",
"md": "Honor 20s",
"mid": "eQF5boERMJFOujcp",
"os": "Android 11.0",
"uid": "76",
"vc": "v2.1.134"
},
"start": {
"entry": "icon", --icon手机图标 notice 通知 install 安装后启动
"loading_time": 18803, --启动加载时间
"open_ad_id": 7, --广告页ID
"open_ad_ms": 3449, -- 广告总共播放时间
"open_ad_skip_ms": 1989 -- 用户跳过广告时点
},
"err":{ --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744304000
}
3.3 服务器和JDK准备
3.3.1 安装hadoop-3.1.3完全分布式
https://blog.csdn.net/qq_51490070/article/details/123673640
3.3.2 安装zookeeper-3.5.7集群
https://blog.csdn.net/qq_51490070/article/details/124695903
3.3.3 安装kafka2.4.1
https://blog.csdn.net/qq_51490070/article/details/124716742?spm=1001.2014.3001.5501
1. kafka机器数量计算
kafka机器数量=2*(峰值生产速度*副本数/100)+1
解释:
1. 峰值生产速度:通过kafka压力测试可以得到
2. 副本数:
(1)kafka默认副本数为1个,企业一般2~3个,2个居多
(2)副本多可以提高可靠性,但是降低网络传输效率
举例:峰值生产速度50M/s,副本数为2
kafka机器数量=2*(50M/s*2/100)+1 = 3台
2. kafka压力测试
3.3.4 安装flume1.9.0
https://blog.csdn.net/qq_51490070/article/details/124267937?spm=1001.2014.3001.5501
3.4 模拟用户行为数据生成
3.4.1 上传生成数据的jar文件
1. 上传生成数据的jar包以及配置文件:将application.yml、gmall2020-mock-log-2021-01-22.jar、path.json、logback.xml上传到hadoop102的/opt/module/applog目录下
2. 都是使用springBoot写出的
1. 创建applog文件夹
//在/opt/module/文件夹下面创建applog文件夹
mkdir applog

2. 上传生成数据文件到applog文件夹

3.4.2 配置文件
1. application.yml文件
vim application.yml
//根据需求生成对应日期的用户行为日志
# 外部配置打开
logging.config: "./logback.xml"
#业务日期:表示用户日志生成的日期
mock.date: "2020-06-14"
#模拟数据发送模式
#mock.type: "http"
#mock.type: "kafka"
mock.type: "log"
#http模式下,发送的地址
mock.url: "http://hdp1/applog"
#kafka模式下,发送的地址
mock:
kafka-server: "hdp1:9092,hdp2:9092,hdp3:9092"
kafka-topic: "ODS_BASE_LOG"
#启动次数
mock.startup.count: 200
#设备最大值:
mock.max.mid: 500000
#会员最大值:一次最多生成多少条会员数据
mock.max.uid: 100
#商品最大值
mock.max.sku-id: 35
#页面平均访问时间单位是毫秒
mock.page.during-time-ms: 20000
#错误概率 百分比
mock.error.rate: 3
#每条日志发送延迟 ms
mock.log.sleep: 10
#商品详情来源 用户查询,商品推广,智能推荐, 促销活动
mock.detail.source-type-rate: "40:25:15:20"
#领取购物券概率
mock.if_get_coupon_rate: 75
#购物券最大id
mock.max.coupon-id: 3
#搜索关键词
mock.search.keyword: "图书,小米,iphone11,电视,口红,ps5,苹果手机,小米盒子"
2. path.json配置访问路径
根据需求,配置用户点击路径,模拟多条点击路径
比如第一条:
{"path:["home","good_list","good_detail","cart","trade","pay““ment"],"rate":20 }
{"路径":[首页->商品列表->商品详情页->加入购物车->提交订单->支付],此类日志比例占20%}
[
{"path":["home","good_list","good_detail","cart","trade","payment"],"rate":20 },
{"path":["home","search","good_list","good_detail","login","good_detail","cart","trade","payment"],"rate":40 },
{"path":["home","mine","orders_unpaid","trade","payment"],"rate":10 },
{"path":["home","mine","orders_unpaid","good_detail","good_spec","comment","trade","payment"],"rate":5 },
{"path":["home","mine","orders_unpaid","good_detail","good_spec","comment","home"],"rate":5 },
{"path":["home","good_detail"],"rate":10 },
{"path":["home" ],"rate":10 }
]
3. logback.xml配置文件
配置日志生成路径
<configuration>
<property name="LOG_HOME" value="/opt/module/applog/log" />
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%npattern>
encoder>
appender>
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.logfileNamePattern>
rollingPolicy>
<encoder>
<pattern>%msg%npattern>
encoder>
appender>
<logger name="com.atgugu.gmall2020.mock.log.util.LogUtil"
level="INFO" additivity="false">
<appender-ref ref="rollingFile" />
<appender-ref ref="console" />
logger>
<root level="error" >
<appender-ref ref="console" />
root>
configuration>
3.4.3 生成日志
1. 进入applog执行
java -jar gmall2020-mock-log-2021-01-22.jar
2. 进入log,查看

3.4.4 日志生成脚本
cd bin/ //进入bin目录
vim log.sh //编辑log.sh脚本
chmod u+x log.sh //添加权限
xsync log.sh //分发脚本
log.sh start //使用脚本模拟生成用户行为数据
#!/bin/bash
for i in hadoop102 hadoop103;
do
echo "===========$i=========="
ssh $i "cd /opt/module/applog/; java -jar gmall2020-mock-log-2021-01-22.jar >/dev/null 2>&1 &"
done


3.5 采集flume配置
flume采集数据到kafka
3.5.1 编写flume拦截器
1. 背景: 对source采集到的数据在进入channel之前进行ETL清洗,允许正常json进入,不合格的json就处理掉
2. 所以需要编写拦截器,在channel之前进行数据清洗
3. 拦截器必细致的写,不然到开启flume时会出现错误,我暂时没搞懂
ERROR node.AbstractConfigurationProvider: Source r1 has been removed due to an error during configuration

1.创建maven项目flume-interceptor

2. 创建包
创建包:com.flume.interceptor
创建

3. 配置pom.xml文件
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>org.examplegroupId>
<artifactId>flume-interceptorartifactId>
<version>1.0-SNAPSHOTversion>
<dependencies>
<dependency>
<groupId>org.apache.flumegroupId>
<artifactId>flume-ng-coreartifactId>
<version>1.9.0version>
<scope>providedscope>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.62version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-pluginartifactId>
<version>2.3.2version>
<configuration>
<source>1.8source>
<target>1.8target>
configuration>
plugin>
<plugin>
<artifactId>maven-assembly-pluginartifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
project>
org.apache.flume
flume-ng-core
1.9.0
provided
解释:provided:表示在打包的时候找不到某jar包,就会去服务器上面寻找
---------------------

4. 创建类:ETLInterceptor,实现flume下的Interceptor
创建类:ETLInterceptor,实现flume下的Interceptor

5. 创建工具类:JSONUtils
package com.flume.interceptor;
import com.alibaba.fastjson.JSON;
public class JSONUtils {
/**
* 测试isValidate()方法的正确性
* @param args
*/
public static void main(String[] args) {
//1.测试一条非标准json
System.out.println(isValidate("{\"albb\":1,"));
//2.测试一条标准json
System.out.println(isValidate("{\"albb\":1}"));
//3. 说明:字符串被认为是标准json
System.out.println(isValidate("22222"));
}
/**
* 验证参数是否是标准json,是返回true,不是返回false
* @param log
* @return
*/
public static boolean isValidate(String log) {
try{
//利用阿里巴巴的json验证log是否是标准json
//没有异常说明是标准json,返回true
JSON.parse(log);
return true;
}catch(Exception e){
//c出现异常说明不是标准json,返回false
return false;
}
}
}

6. 打包


有两个jar包,一个带依赖环境,一个不带依赖环境
为了方便起见,我们使用带依赖环境的jar包
7. 上传jar包到集群
1. 上传带依赖的jar包到flume/lib目录下面
2. 分发jar包到其他主机



3.5.2 配置文件
(1)编写配置文件
1. 在flume/conf下编写采集flume文件file-flume-kafka.conf
2. flume配置文件基本五步骤
(1)定义组件
(2)配置source
(3)配置channel
(4).配置sink
(5)拼接组件
3. 采集flume不用配置sink
#为各组件命名
a1.sources = r1
a1.channels = c1
#描述source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.niit.flume.interceptor.ETLInterceptor$Builder
#描述channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
#绑定source和channel以及sink和channel的关系
a1.sources.r1.channels = c1
(2)配置文件解读
#配置解读
#flume配置文件基本五步骤
# 1.定义组件
a1.sources=r1
a1.channels=c1
# 2.配置taildirssource
//source的类型
a1.sources.r1.type=TAILDIR
//采集flume要监控的文件组
a1.sources.r1.filegroups=f1
//采集flume要监控的文件组中的文件
a1.sources.r1.filegroups.f1=/opt/module/applog/log/app.*
//断点续存的oppset存在的位置,默认在系统家目录,更改为flume目录
a1.sources.r1.positionFile=/opt/module/flume/taildir_position.json
#配置拦截器(自定义拦截器,实现ETL数据清洗,判断json是否完整)
a1.sources.r1.interceptors=i1
//配置拦截器的全类名
a1.sources.r1.interceptors.i1.type=com.flume.interceptor.ETLInterceptor$Builder
# 3.配置channel
//channel的类型
a1.channels.c1.type=org.apache.flume.channel.kafka.KafkaChannel
//要连接的kafka集群,只读kafka topic的元数据信息(文件大小,副本信息。。。。。)
a1.channels.c1.kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092
//要写入的kafkatopic
a1.channels.c1.kafka.topic=topic_log
//配置是否接收flume传输数据的原本格式(头+body格式),不保持就只有body
a1.channels.c1.parseAsFlumeEvent=false
# 4.配置sink(不用配置)
# 5.拼接组件
a1.sources.r1.channels=c1
(3)分发配置文件
1. 分发file-flume-kafka.conf文件
xsync file-flume-kafka.conf
3.5.3 测试flume-kafka通道
1.开启服务

hadoop102,hadoop103启动flume
bin/flume-ng agent --name a1 --conf-file conf/file-flume-kafka.conf &
nohup bin/flume-ng agent --name a1 --conf-file conf/file-flume-kafka.conf &
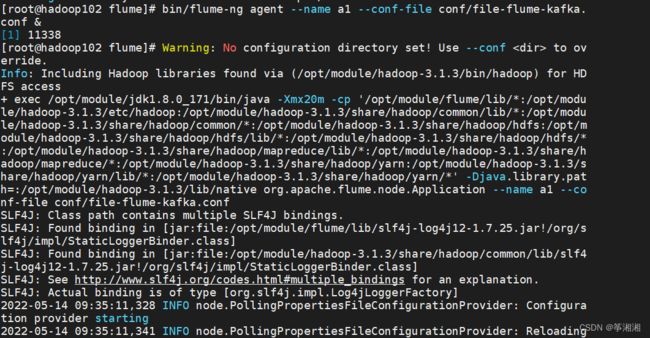
kafka消费数据
$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --from-beginning --topic topic_log

3.5.4 flume启动,停止脚本
1.问题
nohup:可以在退出账户或者关闭终端之后继续运行相应的进程,就是不间断执行
1. 命令开启的flume,不管前台开启还是后台开启,当连接断开进程就会被杀死
2. 必须保证进程持续执行,在命令前加 nohup
nohup bin/flume-ng agent --name a1 --conf-file conf/file-flume-kafka.conf &
3.flume 自身没有提供关闭application的脚本,需要自己使用kill -9 进程号杀掉进行,这里会出现问题:不知道那个进程号是需要被杀死的---此时需要先过滤出Application
ps -ef | grep Application

若不想要最下面grep行,再次进行过滤 不需要谁就 -v 名字
ps -ef | grep Application | grep -v grep

awk:默认分隔符为空格
继续过滤到对应的进程号,使用切割awk默认切割符空格号) awk '{print $n}' n:第几个元素
ps -ef | grep Application | grep -v grep | awk '{print $2}'

xargs:取出前面命令行运行的结果,作为后面命令的输入参数
一次按行获取前面的数据 xargs -n数字(获取几行)
ps -ef | grep Application | grep -v grep | awk '{print $2}' | xargs -n4
![]()
最后 加上 kill -9 ,表示把前面的数据复制到 kill -9 后面
ps -ef | grep Application | grep -v grep | awk '{print $2}' | xargs -n4 kill -9
![]()
新问题:Application只是代称,有其他程序也会叫application,就冲,重名了,可以使用配置文件名称进行过滤,这是唯一的

![]()

2.脚本
#! /bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103
do
echo " --------启动 $i 采集flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/conf/file-flume-kafka.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/log1.txt 2>&1 &"
done
};;
"stop"){
for i in hadoop102 hadoop103
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep file-flume-kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "
done
};;
esac
<--'{print \$2}',加上\转义符,避免双引号把$2解析为脚本第二个参数,造成错误-->
chmod u+x f1.sh
f1.sh start
f1.sh stop
成功
3.5 模拟业务数据生成
第四章 业务数据生成模块
4.1 业务数据解析
4.2 业务数据采集
4.2.1 安装mysql 5.7.16
1. 卸载本机已经安装的mysql
rpm -qa | grep -i -E mysql\|mariadb | xargs -n1 rpm -e --nodeps

2.安装mysql依赖
rpm -ivh 01_mysql-community-common-5.7.16-1.el7.x86_64.rpm
rpm -ivh 02_mysql-community-libs-5.7.16-1.el7.x86_64.rpm
rpm -ivh 03_mysql-community-libs-compat-5.7.16-1.el7.x86_64.rpm
3.安装mysql-client
rpm -ivh 04_mysql-community-client-5.7.16-1.el7.x86_64.rpm

4.安装mysql-server
rpm -ivh 05_mysql-community-server-5.7.16-1.el7.x86_64.rpm

5.启动mysql
systemctl start mysqld
6.查看初始密码
cat /var/log/mysqld.log | grep password

7. 配置mysql
(1)使用初始密码登录mysql
mysql -uroot -p 'dhq0BKW3eY*5'
4.2.2 安装hive3.1.2
5 普通模式下的全流程调度
数仓的每一层指代的就是每一层的执行任务,脚本
这些脚本是相互依赖的,需要一层一层执行
调度时需要考虑脚本的依赖关系
每天都有新数据产生,所以需要考虑定时执行所有脚本的问题
5.1 Azkaban安装部署
5.1.1 Azkaban基本概念

调度器原理:
1. 描述工作流程
2. 配置定时任务·
3. Azkaban:专门调度数仓中批处理定时任务的工具,调度器
4. 以一整个工作流程为单位,定时开始提交第一个工作单元,一个工作单元执行结束后会自动提交第二个工作单元,以此类推
5. 简单易用
5.1.2 Azkaban基本架构
Azkaban基本架构架构
6. web server :项目管理,用户管理,权限管理,任务的定时和触发
7. Executor Server: 负责具体任务的执行,Azkaban调度的任务最终是在 Executor Server所在的节点进行执行
8. mysql:存储工作流程的配置,定时任务的配置,任务的执行状态等等

5.1.3 Azkaban基本部署模式
1. 单机模式:只有一个进程,包含 web server ,Executor Server
2. 集群模式(生产环境下推荐使用): web server ,Executor Server是两个独立的进程,可以部署多个Executor Server,
多Executor模式可以起到负载均衡和容载的作用
1. 安装
1. hadoop02部署 web server
2. hadoop02,hadoop03,hadoop04 部署Executor Server
db里面装的是Azkanban需要在mysql中建表用的建表语句



2. 配置MySQL
1. 集群有mysql
2. 启动mysql
3. 登录mysql
4. 创建Azkaban数据库
5. 创建azkaban用户,并且赋予其增删改查Azkaban数据库的权限
6. 创建Azkaban表,source
7. 查看创建表

![]()


3. 配置Executor Server
1. 编辑azkaban.properties
vim /opt/module/azkaban/azkaban-exec/conf/azkaban.properties
2. 修改
#...
default.timezone.id=Asia/Shanghai //市区
#...
azkaban.webserver.url=http://hadoop102:8081 //指定executor
executor.port=12321 //设置executor端口号,不设置是随机值,不方便管理
#...
database.type=mysql
mysql.port=3306
mysql.host=hadoop102 //mysql所在主机
mysql.database=azkaban //指定azkaban数据库
mysql.user=azkaban //指定azkaban用户
mysql.password=000000
mysql.numconnections=100 //最大连接数
3. 分发给其他结点
xsync /opt/module/azkaban/azkaban-exec
4. 进入到/opt/module/azkaban/azkaban-exec路径,分别在三台机器上,启动executor
bin/start-exec.sh

5. 激活executor,每台结点都需要
curl -G "hadoop01:12321/executor?action=activate" && echo
curl -G "hadoop02:12321/executor?action=activate" && echo

4. 配置 Web Server
1. 编辑azkaban.properties
vim /opt/module/azkaban/azkaban-web/conf/azkaban.properties

#StaticRemainingFlowSize:正在排队的任务数;
#CpuStatus:CPU占用情况
#MinimumFreeMemory:内存占用情况。测试环境,必须将MinimumFreeMemory删除掉,否则它会认为集群资源不够,不执行。
2. 修改azkaban-users.xml文件,添加niit用户
必须进入到hadoop102的/opt/module/azkaban/azkaban-web路径,启动web server
bin/start-web.sh

访问http://hadoop102:8081,并用niit用户登陆,密码123456
有如下界面说明webserver启动成功


5.2 创建mysql数据库和表
1. 创建数据库和表
字段个数顺序类型需要与hive中表一致

2. 编写hive导出数据到mysql中的脚本,sqoop脚本
需要每张表设置主键或者唯一键,避免数据导入重复

5.3 生成功新的数据
5.3.1 用户日志数据生成
1. 启动zk
2. 启动kafka
3.启动flume采集脚本
3. 启动flume消费脚本
4. 修改生成日志日期
5. 生成用户数据
6. hdfs查看生成数据

5.3.2 新业务数据生成
1. 修改日期
2. 生成业务数据
3. mysql中查看是否生成数据



5.4 开始全流程调度
1. 创建调度项目

2. 编写azkaban.project文件,
内容如下
azkaban-flow-version: 2.0
3. 编写gmall.flow文件
编写gmall.flow文件
dt此时设置为参数,在Azkanban上面进行设置
任务之间有依赖关系
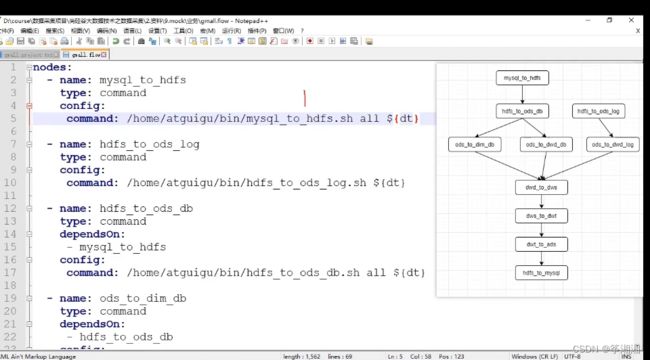
4. 将azkaban.project、gmall.flow文件压缩到一个zip文件,文件名称必须是英文。
将azkaban.project、gmall.flow文件压缩到一个zip文件,文件名称必须是英文。
gmall.zip文件上传到gmall项目

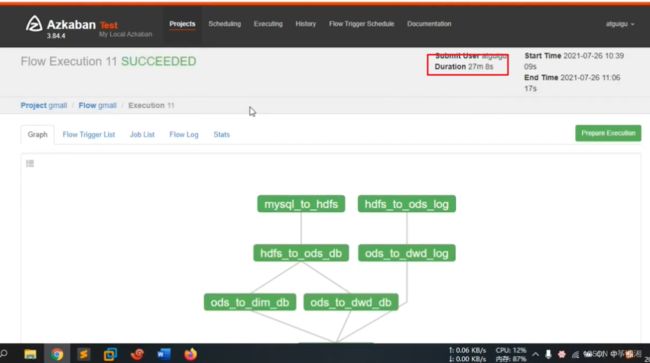
5.查看任务流

6. 配置dt时间,并且执行



全绿表示执行成功
蓝色表示正在执行
红色表示执行失败
7. mysql gmall_report中查看数据

6 安全模式下的全流程调度
6.1 为什么需要全流程调度?
1. 安全环境:启用kerberos安全认证的hadoop集群
2. 在安全环境下,前面所有可执行脚本(都是和hdfs还有hive打交道的)都需要进行认证才可以进行对数据的增删改查操作
6.2 用户准备
统一将认证用户都设置为hive用户
全部数据资源:
1. origin_data:临时存储数据资源
2. warehouse:最终存放数据资源,数据是从origin_dataload加载进来的·
故数仓的全部数据可能在两个路径下,就需要将这两个路径的所有者设置为hive,方便全流程的每一步操作进行认证,都认证为hive

6.2.1 在3个节点创建hive用户
1.在3个节点创建hive用户
useradd hive -g hadoop //创建用户
echo hive | passwd --stdin hive //设置密码为hive
6.2.2 为hive用户创建keberos主体
为hive用户创建keberos主体,这里是为hive用户创建的keberos主体:后续执行全流程每一步计算操作时需要认证的用户(客户端认证)
不同于为hive服务创建的keberos主体:是为了启动HiveServer2 和 hive Metastore 时进行认证(服务端认证)
kadmin -padmin/admin -wadmin -q"addprinc -randkey hive" //为hive用户创建keberos主体
kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/hive.keytab hive" //生成keytab文件
--因为普通用户认证需要密码认证,hive用户是给全流程中的脚本使用的,需要有可以交互的密码--

chown hive:hadoop /etc/security/keytab/hive.keytab //修改keytab文件所有者和访问权限
chmod 440 /etc/security/keytab/hive.keytab //440只读权限
xsync /etc/security/keytab/hive.keytab //分发keytab文件
--因为全流程使用Azkaban,Azkaban采用多excutor模式,执行任务有两种模式,
一种是指定excutor,若指定102为执行任务的executor,就不需要分发keytab文件
一种是把脚本分发到集群当中每台节点然后执行,这种情况下脚本被分到任意节点都是需要认证的,都需要使用keytab文件 --
6.3 数据采集通道修改
全流程中,与hdfs 和hive打交道的脚本都需要修改
6.3.1 日志,用户行为数据

flume专门为kerberos认证提供了参数
修改/opt/module/flume/conf/kafka-flume-hdfs.conf配置文件,只用修改sink增加以下参数
vim /opt/module/flume/conf/kafka-flume-hdfs.conf
[email protected] //创建的hive用户主题
a1.sinks.k1.hdfs.kerberosKeytab=/etc/security/keytab/hive.keytab //创建的用户主题的keytab文件,秘钥文件
6.3.2 业务数据
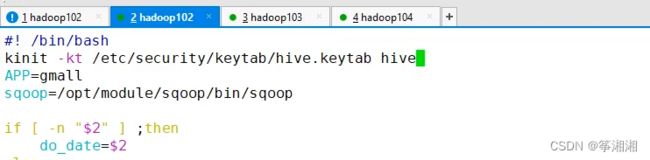
业务数据依靠sqoop上传到hdfs,
vim /home/atguigu/bin/mysql_to_hdfs.sh
在顶部增加如下认证语句
秘钥文件认证
kinit -kt /etc/security/keytab/hive.keytab hive
kinit -kt 指向秘钥文件所在路径 需要认证的用户
当我们执行相应脚本时就会先进行认证,认证完再进行操作
6.3.3 数仓各层脚本修改
除开sqoop脚本,还有10个·数据仓库的脚本需要修改
1. hdfs_to_ods_log.sh
2. hdfs_to_ods_db.sh
3. ods_to_dwd_log.sh
4. ods_to_dim_db.sh
5. ods_to_dwd_db.sh
6. dwd_to_dws.sh
7. dws_to_dwt.sh
8. dwt_to_ads.sh
9. hdfs_to_mysql.sh
均在顶部加上认证语句
kinit -kt /etc/security/keytab/hive.keytab hive
语句:sed -i '1 a kinit -kt /etc/security/keytab/hive.keytab hive' 脚本名称 //都是相对路径,需要在所在文件夹执行命令
sed -i '1 a text' file
表示将text内容加入到file文件的第1行之后
6.3.4 修改HDFS特定路径所有者
1. 先认证为hdfs用户,原本就是
kinit hdfs/hadoop
2. 修改数据采集目标路径
hadoop fs -chown -R hive:hadoop /origin_data
3.修改数仓表所在路径
hadoop fs -chown -R hive:hadoop /warehouse
4.修改hive家目录/user/hive
hadoop fs -chown -R hive:hadoop /user/hive
相当于home目录,就是家目录,里面保存所有用户,hive用户数据也在其中,需要将所有者改为hive用户

6.4 数据准备
6.4.1 用户日志数据生成
1. 启动zk
2. 启动kafka
3.启动flume采集脚本
3. 启动flume消费脚本
4. 修改生成日志日期
5. 生成用户数据
6. hdfs查看生成数据
6.4.2 业务数据生成
1. 修改日期
2. 生成业务数据
3. mysql中查看是否生成数据
6.5 启动Azkaban
帮助用户执行进程脚本
1. 各节点创建azkaban用户
useradd azkaban -g hadoop //创建用户
echo azkaban | passwd --stdin azkaban //修改密码
2. 把各个节点Azkaban安装路径所有者改为azkaban用户
chown -R azkaban:hadoop /opt/module/azkaban
-R是递归的意思,表示/opt/module/azkaban下的所东西都属于 azkaban用户,所属组都是hadoop
3. 使用azkaban用户启动Azkaban
1. 启动Executor Server:需要做两步
(1)执行启动命令:必须进入路径下执行
sudo -i -u azkaban bash -c "cd /opt/module/azkaban/azkaban-exec;bin/start-exec.sh"
sudo -i -u azkaban 以azkaban身份执行后面命令
bash -C 就是将后面的字符串当成shell命令执行
(2)激活Executor Server,任选一台节点执行以下激活命令即可
curl http://hadoop102:12321/executor?action=activate
此时mysql中查看Azkaban数据库中的表executors,active值都是1,说明3个节点都启动成功了

3. 启动Web Server
sudo -i -u azkaban bash -c "cd /opt/module/azkaban/azkaban-web;bin/start-web.sh"

访问hadoop02:8081查看web server是否开启

4. 修改数仓各层脚本访问权限,确保azkaban用户能够访问到
chown -R atguigu:hadoop /home/niit
chmod 770 /home/niit
-
指定executor:需要保证Azkaban可以访问指定节点各层脚本
chown -R atguigu:hadoop /home/niit
chmod 770 /home/niit
因为azkaban也属于hadoop组,所以可以访问/home/niit下的脚本 -
Azkaban自己分配executor
6.6 全流程调度
1. 打开azkaban进入gmall

2. 点击 Execute Flow

- 点击Flow Parameters

4.准备参数

- 执行


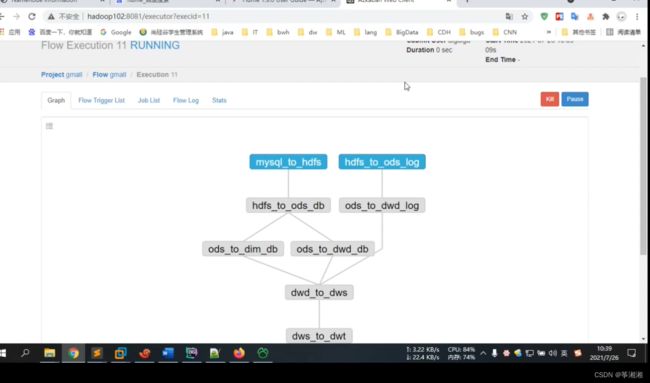
此时任务就开始执行了,大概需要20分钟左右
执行结束,任务块全部变绿