C语言基础
文章目录
-
-
-
- 二. 前言
-
- 1.vscode 搭建C语言开发环境
- 2.编程语言的演变
-
- 2-1.计算机语言
- 2-2 解释型vs编译型
- 2-2 面向过程vs面向对象
- 三. C语言基础
-
- 0.数据存储范围
- 1.变量与常量
- 2.数据类型
-
- 2-1 整型数据
- 2-2 浮点型数据
- 2-3 字符型数据
- 2-4 格式化输出
- 2-5 输入框语句
- 2-5 字符输入函数
- 2-6 字符输出函数
- 2-7 取值范围的计算
- 3.运算符
-
- 3-1 算数运算符
- 3-2 关系运算符
- 3-3 逻辑运算符
- 3-4 三目运算符
- 3-5 逗号运算符
- 3-6 自增自减运算符
- 3-7 运算符的优先级
- 3-8 混合运算
- 4. 分支结构
-
- 4-1 if分支结构
- 4-2 SWITCH 条件分支结构
- 5. 循环结构
-
- 5-1 WHILE 循环
- 5-2 DO WHILE 循环
- 5-3 FOR 循环
- 5-4 BREAK 终止循环
- 5-5 CONTINUE 结束本次循环
- 6. 函数
-
- 6-1 函数的概念
- 6-2 函数的参数
- 6-3 函数的return!!
- 6-4 函数的声明
- 6-5 内存的分区
- 6-6 普通的全局变量
- 6-7 静态全局变量 static
- 6-8 普通的局部变量
- 6-9 静态的局部变量
- 6-10 静态函数
- 6-11 作用域
- 6-12 定义与声明
- 6-13 链接属性
- 6-14 生存期
- 6-15 存储类型
- 6-16 内联函数
- 6-17 可变参数
- 7.数组
-
- 7.1数组的概念
- 7.2 数组的分类
- 7.3 二维数组
- 7-4 数组的排序
- 8.指针
-
- 8-0 内存与地址与变量名
- 8-1 指针的概念
- 8-2 指针变量的定义
- 8-3 指针的用处
- 8-4 指针和数组
- 8-5 指针的分类
- 8-6 字符串和指针
- 8-7 指针数组
- 8-8 指针的指针
- 8-9 数组指针
- 8-10 数组名字取地址
- 8-11 数组名字和指针变量的异同
- 8-12 给函数传指针参数
- 8-13 函数返回值是指针
- 8-14 初识函数指针
- 8-15 函数指针的定义和调用
- 8-16 函数指针的用处
- 8-17 易混淆指针
- 8-18 特殊指针
- 四. 动态内存申请
-
- 1.初识动态内存
- 2. malloc 函数
- 3. free 函数(释放内存函数)
- 4. calloc 函数
- 5. realloc 函数
- 6. 初始化内存空间
- 7. 内存泄露
- 五. 字符串处理函数
-
- 1. 字符串拷贝函数strcpy_s和strcpy和strncpy
- 2. 测字符串长度函数strlen
- 3. 字符串追加函数strcat_s和strcat和strncat
- 4.字符串比较函数strcmp
- 5.字符查找函数strchr
- 6. 字符串匹配函数strstr
- 7.字符串转换数值atoi
- 8.字符串切割函数strtok
- 9.空间设定函数memset
- 六. 结构体
-
- 1.初识结构体
- 2.结构体初始化与访问
- 3. 结构体数组
- 4. 结构体指针
- 5. 结构体与函数
- 6. 结构体内存分配
-
- 规则 1
- 规则 2
- 字节对齐的好处
- 7.链表
- 8.位域
- 七. 共用体
- 八. 枚举
- 九.位运算
-
- 1.原码反码补码
- 2.位运算
- 3.位运算符的应用
- 十.预处理
-
- 1.宏定义define
- 2.选择性编译
- 3.文件包含
- 十一.文件
-
- 1.初识文件
- 2.标准 io 库函数对磁盘文件的读取
- 3.磁盘文件的分类
- 4.标准流
- 4.指示器
- 4.文件指针
- 5.fopen
- 6.fclose
- 7. fgetc 与 fputc
- 8. fgets 与 fputs
- 9.fread
- 10.fwrite
- 11.rewind
- 12. fseek
- 13.feof
- 14.ftell
- 15.fscanf、fprintf
- 十二. 第三方库
-
-
二. 前言
1.vscode 搭建C语言开发环境
vscode搭建c语言开发环境
MinGW,是Minimalist GNU on Windows 的缩写。它实际上是将经典的开源 C语言 编译器GCC 移植到了 Windows 下,并且包含了 Win32API ,因此可以将源代码编译生成 Windows 下的可执行程序
2.编程语言的演变
2-1.计算机语言
计算机语言(Computer Language)指用于人与计算机之间通讯的语言。计算机语言是人与计算机之间传递信息的媒介。计算机系统最大特征是指令通过一种语言传达给机器。为了使电子计算机进行各种工作,就需要有一套用以编写计算机程序的数字、字符和语法规划,由这些字符和语法规则组成计算机各种指令(或各种语句)。这些就是计算机能接受的语言。
2-2 解释型vs编译型
解释型语言:解释性语言编写的程序不进行预先编译,以文本方式存储程序代码。执行时才翻译执行。程序每执行一次就要翻译一遍。
优缺点:跨平台能力强,易于调,执行速度慢。
编译型语言:编译型语言在执行之前要先经过编译过程,编译成为一个可执行的机器语言的文件,比如exe。因为翻译只做一遍,以后都不需要翻译,所以执行效率高。
编译型语言的优缺点:执行效率高,缺点是跨平台能力弱,不便调试。
汇编语言:由汇编编译器将助记符转化为机器码==》编译
机器语言:cpu通过查找指令表将0和1与具体指令相挂钩【ASCII字符表】
-
编译型语言执行流程:计算机会将编译型语言编译成汇编然后再编译成机器语言
-
解释型语言执行流程:解释型语言不直接编译成机器码,而是转化为中间代码,例如java转化为字节码,然后交给解释器逐句翻译给cpu执行,好处是可以实现跨平台特性,缺点是执行效率低,因为CPU无法读懂字节码,每次执行都需要解释器去翻译【 Java解释器是JVM的一部分。Java解释器用来解释执行Java编译器编译后的程序。java.exe可以简单看成是Java解释器】
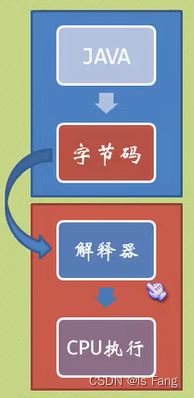
2-2 面向过程vs面向对象
面向过程是一种以事件为中心的编程思想,分解为多个步骤然后依次调用
三. C语言基础
0.数据存储范围
cpu能读懂的最小单位–比特位
但是人类习惯使用字节去表示数据大小,所以,引申出了字节,内存机构最小寻址单位-字节
1字节=8比特位
进制
-
二进制转十进制中最大数的规律:2的n次方减1
-
十进制整型常数没有前缀,其他的有八进制0开头,十六进制0x或0X开头,
1.变量与常量
变量:
- 变量的意义就是确定目标并提供存储空间
- 用小写来命名变量
常量:
-
用大写来表示符号常量名
-
常量的分类
- 整型常量
- 实型常量(实数或浮点数)
- 实数只采用十进制,有两种方式:十进制小数,指数(加阶码标志e或者E)
- 例如2.9E-2 表示2.9*10-2次方
- 标准c允许浮点数使用后缀,后缀为f或F,表示该数为浮点数,250.等价于250F
- 占4个字节,以指数形式存储,
- 字符常量
- 普通字符
- 转义字符
- 字符串常量
- 可以用把一个字符常量赋值给字符变量,但是不能把字符串常量赋值给字符变量
- 一个字节一个字节存放
- 编译器会为字符串添加特殊的转义字符’\0’表示该字符串读取结束
- 所以不要遗忘空格和结束所占据的字节
- 字符常量a和字符串常量a占用的内存是不同的
- 符号常量:在使用前需要定义
- 格式:#define 标识符 常量
- 宏定义,预处理命令都带#
- 实现替换功能,将标识符替换成常量
- 符号常量与变量不一样,他的值在作用域内不能被修改,也不能再被赋值
- 在文件开头定义
- 不用分号结尾
- 使用const关键字修饰
- const int price = 520
- 将变量变为只读常量
2.数据类型
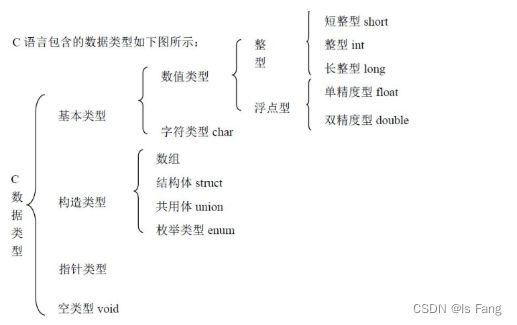
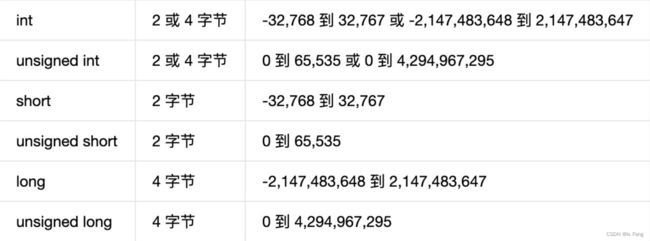
2-1 整型数据
对于不同的操作系统,8/16位的操作系统,int是2字节,64位操作系统,int是4字节
类型限定符:
- signed:带符号位,可以存放负数
- unsigned:不带符号位,释放一个字节存放数据
- 占位符用%u
- 限定符unsigned和signed就是用于限定字符类型和任何整型变量的取值范围
- 对于整型,默认使用signed
- 对于字符型,默认由编译系统决定
- 作用:
- 用于限定char类型和任何整型变量的取值范围
符号位:
- 存放signed类型的存储单元中,左边第一位表示符号位,如果该位为0,表示该整数是一个正数,如果该位为1表示该整数是一个负数。
- 因为符号位的缘故,第一位占用了一个字节,会导致常量转化时候溢出,所以要设置为unsigned限定符,释放一个字节存放数据。在默认情况下int是signed类型,第一位会占用一个字节去存放符号位。
2-2 浮点型数据
| 关键字 | 字节 | 数值范围 |
|---|---|---|
| float单精度 | 4字节 | 3.4E-38 到 3.4E+38 |
| double双精度 | 8字节 | 1.7E-308 到 1.7E+308 |
2-3 字符型数据
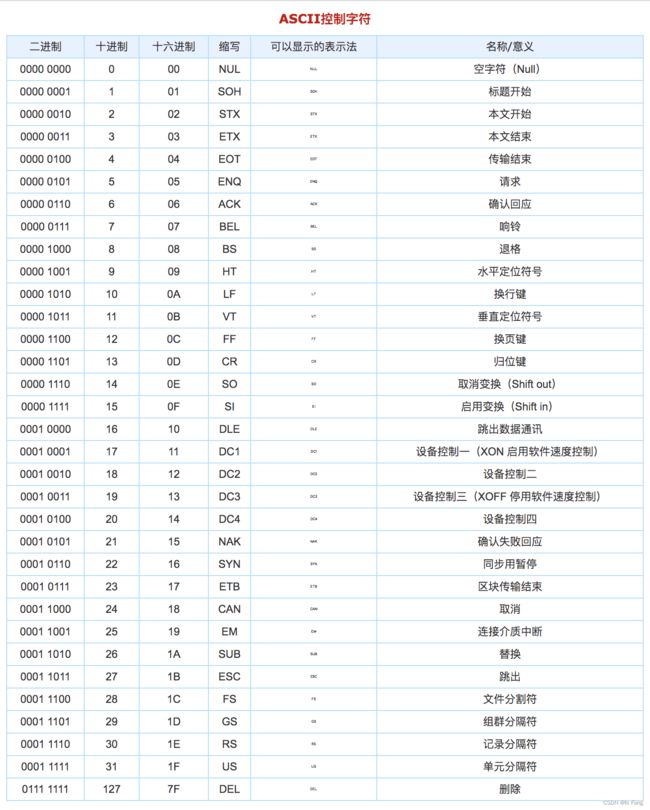
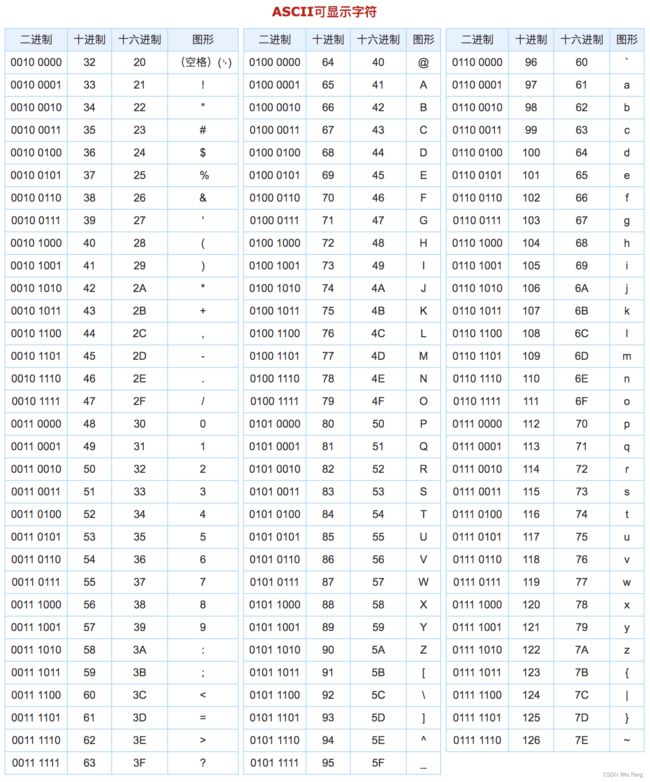

- 一字节为8位,对于没有符号位的数据类型,最大值是2的8次方减1
2-4 格式化输出
输入输出函数需要引入头文件#include
printf
- f是format格式,格式化输出函数
- 将不同的数据类型转化为字符串的形式打印
- 将携带的变量或数值,按照指定的格式打印
指定格式
- %d是整型数据的占位符
- %c是字符型数据的占位符
- %.2f表示精确到小数点后两位的浮点数
- %11.9表示总占11位,而小数点后占用9位
- %u表示不带符号位的占位符
- %s表示字符串的占位符
- %lld表示long long格式的整型
- %p表示打印地址类型的数据
- %x表示以十六进制的形式打印
ASCll:是字符与数字的对应关系
- 如果用%c,为数字占位则会查表转化为字符
- 如果用%d,为字符占位则会查表转化为数字
2-5 输入框语句
从标准输入流读取一个数据存储在指定的变量中
如果存储的位置是指针变量而不是普通变量,就不需要使用取址操作符
int a;
int *p = &a;//使用指针
printf("请输入一个整数:");
scanf("%d",&a);
printf("a = %d\n",a);//通过普通变量打印
printf("请重新输入一个整数:");
scanf("%d",p);//p = &a
printf("a = %d\n",a);
return 0;
2-5 字符输入函数
getchar函数:
- 没有参数,从输入缓冲区中读取一个字符(一次只能读取一个)
- 从标准输入流中获取下一个字符,相当于调用getc(stdin)函数
- 调用该函数有返回值,如果调用成功返回的是字符的ASCII码值(整数),如果调用失败则返回值为EOF
- 回车表示Y,如果需要屏蔽掉,则采用getchar()吸收,获取输入流是否为\n,然后过滤掉
- 当多次使用scanf收集用户输入数据时,会收集到回车换行符,可以使用getchar();将获取到的换行符替换为空
例子:
int main()
{
int count = 0;
printf("请输入一行英文字符");
while (getchar() != '\n')
{
count = count + 1;
}
printf("你总共输入了%d个字符i\n",count);
return 0;
}
2-6 字符输出函数
#include- 参数是个字符,若是数字则通过ASCLL码字符集找到对应的字符
- 返回值是参数的ASCLL码值
- putchar(‘\n’)直接打印换行符
2-7 取值范围的计算
sizeof运算符
- 获取数据类型或表达式长度
sizeof(object);//输入变量的名字
sizeof(type_name);//输入类型
sizeof object;//输入变量的名字
3.运算符
运算符
用算术运算符将运算对象(也称操作数)连接起来的、符合C语法规则的式子,称为C算术表达式运算对象包括常量、变量、函数等
a * b / c + 5
运算符的分类:【运算符作用的运算对象称为操作数】
1、双目运算符:即参加运算的操作数有两个
a + b
2、单目运算符:参加运算的操作数只有一个 **++**自增运算符 , 给变量值+1
a++
3、三目运算符:即参加运算的操作数有 3 个 ()?() : ()
int x = a>b?10:20
3-1 算数运算符
+, -, *, /, % ,+= ,-=, *=, /=, %=
int time = 1000;
int hours = 1000 / 60;
int minutes = 1000 % 60;
复合运算符:
a += 1 相当于 a=a+1
3-2 关系运算符
>、<、= =、>=、<=、!=

3-3 逻辑运算符
1、&& 逻辑与
两个条件都为真,则结果为真
(b>a) && (b<c)
2、|| 逻辑或
两个条件至少有一个为真,则结果为真
(b>a) || (b<c)
3、! 逻辑非
!(a>b)
短路求值
-
又称为最小化求值,是逻辑运算符的求值策略,只有当第一个运算符的值无法确定逻辑运算的结果时,才对第二个运算数进行求值
-
c语言对逻辑与和逻辑或采用的就是短路求值,也就是与看false,或看true,后面的不需要看
3-4 三目运算符
- 语法:
条件 ? 条件为 true 的时候执行 : 条件为 false 的时候执行 - if else的简写形式
#include3-5 逗号运算符
运算过程为从左到右逐个计算
注意区分逗号运算符与分隔符
int a = (1,2) 逗号表达式作为一个整体,运算符的结果是后边表达式的结果
int a = 1;
int x = (a+=2, a*a);
printf("%d", x);
3-6 自增自减运算符
-
++-
进行自增运算
-
分成两种,前置++ 和 后置++
-
前置++,会先把值自动 +1,再返回
-
后置++,会先把值返回,自动+1
-
-
--- 进行自减运算
- 分成两种,前置– 和 后置–
- 和
++运算符道理一样
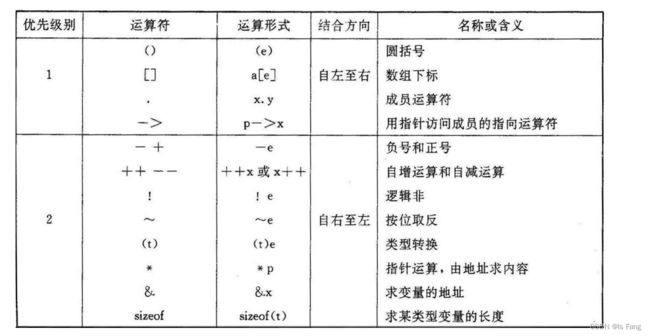
3-7 运算符的优先级
运算符优先级
- 在表达式中按照优先级先后进行运算,优先级高的先于优先级低的先运算。
- 优先级一样的按结合性来运算
- 单目运算符的优先级一定高于双目运算符
- 关系运算符的优先级要高于逻辑与和或的优先级
- 逻辑运算符的非要高于关系运算符
运算符结合性
左结合性:从左向右运算
sum = x + y + z;
右结合性:从右向左运算
int a,b,c;
int d = 100;
a = b = c = d += 100;

3-8 混合运算

4. 分支结构
- 我们的 C 代码都是顺序执行的(从上到下)
- 逻辑分支就是根据我们设定好的条件来决定要不要执行某些代码
4-1 if分支结构
if 语句
-
通过一个
if语句来决定代码是否执行 -
语法:
if (条件) { 要执行的代码 } -
通过
()里面的条件是否成立来决定{}里面的代码是否执行
if else 语句
-
通过
if条件来决定,执行哪一个{}里面的代码 -
语法:
if (条件) { 条件为 true 的时候执行 } else { 条件为 false 的时候执行 } -
两个
{}内的代码一定有一个会执行
if else if … 语句
-
可以通过
if和else if来设置多个条件进行判断 -
语法:
if (条件1) { 条件1为 true 的时候执行 } else if (条件2) { 条件2为 true 的时候执行 } -
会从头开始依次判断条件
- 如果第一个条件为
true了,那么就会执行后面的{}里面的内容 - 如果第一个条件为
false,那么就会判断第二个条件,依次类推
- 如果第一个条件为
-
多个
{},只会有一个被执行,一旦有一个条件为true了,后面的就不在判断了
if else if … else 语句
- 和之前的
if else if ...基本一致,只不过是在所有条件都不满足的时候,执行最后else后面的{}
4-2 SWITCH 条件分支结构
-
也是条件判断语句的一种
-
是对于某一个变量的判断
-
语法:
switch (要判断的变量) { case 情况1: 情况1要执行的代码 break case 情况2: 情况2要执行的代码 break case 情况3: 情况3要执行的代码 break default: 上述情况都不满足的时候执行的代码 }- 要判断某一个变量 等于 某一个值得时候使用,比如说用在状态变量,模式变量等
-
default不是必须写的,可选,如果没有符合switch的结果则不执行任何代码
-
需要使用break跳出分支语句
5. 循环结构
- 循环结构,就是根据某些给出的条件,重复的执行同一段代码
- 循环必须要有某些固定的内容组成
- 初始化计数器
- 循环条件
- 更新计数器
5-1 WHILE 循环
-
while,中文叫 当…时,其实就是当条件满足时就执行代码,一旦不满足了就不执行了 -
语法
while (条件) { 满足条件就执行 } -
因为满足条件就执行,所以我们写的时候一定要注意,就是设定一个边界值,不然就一直循环下去了
// 1. 初始化条件 int n = 0; // 2. 条件判断 while (n<3) { // 3. 要执行的代码 printf("%d\n",n); // 4. 自身改变 n++; }- 如果没有自身改变,那么就会一直循环不停了
5-2 DO WHILE 循环
-
是一个和
while循环类似的循环 -
while会先进行条件判断,满足就执行,不满足直接就不执行了 -
但是
do while循环是,先不管条件,先执行一回,然后在开始进行条件判断 -
语法:
do { 要执行的代码 } while (条件)// 下面这个代码,条件一开始就不满足,但是依旧会执行一次 do 后面 {} 内部的代码 int num = 10; do { num += 1; } while (num < 10); printf("%d", num); -
do while用于校验用户输入的密码
-
do while的区别是while语句后面要加分号
-
while是入口条件循环,do while是出口条件循环
5-3 FOR 循环
-
和
while和do while循环都不太一样的一种循环结构 -
道理是和其他两种一样的,都是循环执行代码的
-
语法:
for (int i = 0; i < 10; i++) { 要执行的代码 }// 把初始化,条件判断,自身改变,写在了一起 for (int i = 0; i < 10; i++) { // 这里写的是要执行的代码 } // 控制台会依次输出 1 ~ 10 -
for循环是优化while循环,将初始化计数器,循环条件,更新计数器写在一起
-
允许在for语句的表达式1中定义变量,而不用在外面定义,这样变量就是
局部变量
5-4 BREAK 终止循环
-
在循环没有进行完毕的时候,因为我设置的条件满足,提前终止循环
-
作用:提升效率,例如判断一个数是不是素数,如果已经满足无余数,则不用继续循环,使用break跳出for循环
-
要终止循环,就可以直接使用
break关键字for (int i = 1; i <= 5; i++) { // 每循环一次,吃一个包子 // 循环就不会继续向下执行了,也就没有 4 和 5 了 if (i == 3) { break; } printf("%d", i); }
5-5 CONTINUE 结束本次循环
-
在循环中,把循环的本次跳过去,跳出本轮循环剩余的语句,继续执行后续的循环
-
跳过本次循环,就可以使用
continue关键字for (int i = 1; i <= 5; i++) { // 当 i 的值为 3 的时候,执行 {} 里面的代码 // {} 里面有 continue,那么本次循环后面的代码就都不执行了 // 自动算作 i 为 3 的这一次结束了,去继续执行 i = 4 的那次循环了 if (i == 3) { continue; } printf("%d", i); }
注意:
- for语句与while语句不是随意转换的,在遇到continue时,如果使用while语句,更新计数器语句可能不会执行,导致程序进入死循环,而for语句的更新计数器表达式写在for表达式中,不会收到continue的影响
6. 函数
6-1 函数的概念
-
函数就是把任意一段代码放在一个 盒子 里面
-
在我想要让这段代码执行的时候,直接执行这个 盒子 里面的代码就行
6-2 函数的参数
-
我们在定义函数和调用函数的时候都出现过
() -
现在我们就来说一下这个
()的作用 -
就是用来放参数的位置
-
参数分为两种 形参 和 实参
void fn(行参写在这里) { // 一段代码 } fn(实参写在这里)
形参和实参的作用
-
形参
-
就是在函数内部可以使用的变量,在函数外部不能使用
-
每写一个单词,就相当于在函数内部定义了一个可以使用的变量(遵循变量名的命名规则和命名规范)
-
多个单词之间以
,分隔// 书写一个参数 void fn(num) { // 在函数内部就可以使用 num 这个变量 } // 书写两个参数 void fun(num1, num2) { // 在函数内部就可以使用 num1 和 num2 这两个变量 } -
行参的值是在函数调用的时候由实参决定的
-
-
实参
-
在函数调用的时候给形参赋值的
-
也就是说,在调用的时候是给一个实际的内容的
void fn(num) { // 函数内部可以使用 num } // 这个函数的本次调用,书写的实参是 100 // 那么本次调用的时候函数内部的 num 就是 100 fn(100) // 这个函数的本次调用,书写的实参是 200 // 那么本次调用的时候函数内部的 num 就是 200 fn(200) -
函数内部的形参的值,由函数调用的时候传递的实参决定
-
多个参数的时候,是按照顺序一一对应的
void fn(num1, num2) { // 函数内部可以使用 num1 和 num2 } // 函数本次调用的时候,书写的参数是 100 和 200 // 那么本次调用的时候,函数内部的 num1 就是 100,num2 就是 200 fn(100, 200)
-
6-3 函数的return!!
return返回的意思,其实就是给函数一个 返回值 和 终断函数
返回值
-
函数调用本身也是一个表达式,表达式就应该有一个值出现
-
return关键字就是可以给函数执行完毕一个结果int fn() { // 执行代码 return 100 } // 此时,fn() 这个表达式执行完毕之后就有结果出现了- 我们可以在函数内部使用
return关键字把任何内容当作这个函数运行后的结果
- 我们可以在函数内部使用
终断函数
-
当我开始执行函数以后,函数内部的代码就会从上到下的依次执行
-
必须要等到函数内的代码执行完毕
-
而
return关键字就是可以在函数中间的位置停掉,让后面的代码不在继续执行void fn() { printf("11"); printf("22"); return; //后面不会执行了 printf("33"); printf("44"); } // 函数调用 fn()
6-4 函数的声明
为什么要声明?
有些情况下,如果不对函数进行声明,编译器在编译的时候,可能不认识这个函数,因为编译器在编译 c 程序的时候,从上往下编译的。
(1) 直接声明法
void func(void);
int main()
{
func();
}
void func(void)
{
printf("hello kerwin\n");
}
(2) 间接声明法
将函数的声明放在头文件中,.c 程序包含头文件即可
main.c文件
#include”k.h”
k.h文件
extern void func(void);
使用函数的好处?
1、定义一次,可以多次调用,减少代码的冗余度。
2、使咱们代码,模块化更好,方便调试程序,而且阅读方便。
6-5 内存的分区
1、内存:物理内存、虚拟内存
-
物理内存:实实在在存在的存储设备
-
虚拟内存:操作系统虚拟出来的内存。
-
操作系统会在物理内存和虚拟内存之间做映射。
-
在写应用程序的,咱们看到的都是虚拟地址。
-
系统会给虚拟内存的每个存储单元【1字节】分配一个编号,这个编号就是虚拟地址
2、在运行程序的时候,操作系统会将虚拟内存进行分区。
根据内存地址从高到低分别划分为:
1).文字常量区
存放常量的。
2).栈(heap)
主要存放局部变量,函数的参数,函数的返回值。
栈内存会自动释放【可以联想到和函数有关的参数与返回值】
栈是函数执行的内存区域,通常和堆共享同一片区域。
3).堆(stack)
堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩展或缩小。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上;当利用free等函数释放内存时,被释放的内存从堆中被剔除。
4).bss段(Uninitialized data segment)
未初始化的全局变量、未初始化的静态局部变量
初始化为0的全局变量、初始化为0的静态局部变量
这个区段中的数据在程序运行前将被自动初始化为数字0
5).数据段(Initialized data segment)
初始化不为0的全局变量、初始化不为0的静态局部变量、const常量
6).代码区(Text segment)
存放咱们的程序代码
这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
图片

堆和栈的区别
-
申请方式:
- 堆由程序员手动申请
- 栈由系统自动分配
-
释放方式:
- 堆由程序员手动释放
- 栈由系统自动释放
-
生存周期:
- 堆的生存周期由动态申请到程序员主动释放为止,不同函数之间均可自由访问
- 栈的生存周期由函数调用开始到函数返回时结束,函数之间的局部变量不能互相访问
-
申请之后排序方向:
- 堆和其它区段一样,都是从低地址向高地址发展
栈则相反,是由高地址向低地址发展 【栈在最顶部】
注意:
- linux中命令(size 文件名)可以查看所有地址划分情况
6-6 普通的全局变量
在函数外部定义的变量.
int number=100;//number 就是一个全局变量
int main()
{
return 0;
}
作用范围:
- 普通全局变量的作用范围,是程序的所有地方。
- 只不过在其他文件用之前需要声明。声明方法 extern int number;
- 注意声明的时候,不要赋值。
生命周期:
- 程序运行的整个过程,一直存在,直到程序结束。
注意:
- 定义普通的全局变量的时候,如果不赋初值,它的值默认为 0
6-7 静态全局变量 static
定义全局变量的时候,前面用 static 修饰。
static int number=100;//number 就是一个静态全局变量
int main()
{
return 0;
}
作用范围:
- 只能在它定义的.c(源文件)中有效(普通全局变量可以在其他.c文件中使用,只需要extern关键字)
生命周期:
- 在程序的整个运行过程中,一直存在。
注意:
- 定义静态全局变量的时候,如果不赋初值,它的值默认为 0。
6-8 普通的局部变量
在函数内部定义的,或者复合语句中定义的变量
int main()
{
int num;//普通局部变量
if(1){
int a;//普通局部变量
}
}
作用范围:
- 在函数中定义的变量,在它的函数中有效
- 在复合语句中定义的,在它的复合语句中有效。
6-9 静态的局部变量
定义局部变量的时候,前面加 static 修饰
作用范围:
- 在它定义的函数或复合语句中有效。
生命周期:
- 第一次调用函数的时候,开辟空间赋值,函数结束后,不释放,以后再调用函数的时候,就不再为其开辟空间,也不赋初值,用的是以前的那个变量。
- 局部静态变量的生命期是到程序执行结束才消失和全局变量一样,但是作用范围不一样
6-10 静态函数
在定义函数的时候,返回值类型前面加 static 修饰。这样的函数 被称为静态函数。
static 限定了函数的作用范围,在定义的.c 中有效。
6-11 作用域
标识符声明的位置决定它的作用域
分类:
- 代码块作用域
- 函数的形参不在大括号内定义,但是具有代码块作用域,隶属于包含函数体的代码块
- 声明在代码块的开始位置的标识符和函数定义的形式参数(注意是函数定义)都具有代码块作用域。
- 文件作用域
- 函数名和全局变量
- 任何在代码块之外声明的标识符都具有文件作用域,作用范围是从他们的声明位置开始,到文件的结尾处都是可以访问的
- 它表示这些标识符从它们的声明之外直到它所在的源文件结尾处都是可以访问的 。所以我们一般会在文件开始处先定义或者使用extren关键字
- 函数名也具有文件作用域,因为函数名在代码块之外, 函数名本身并不属于任何代码块
- 在头文件中编写并 通过#include指令包含到其他文件中的声明就好像它们是直接写在那些文件中一样。它们的作用域并不局限于头文件的文件尾。
- 原型作用域【少用】
- 原型作用域(prototype scope)只适用于在函数原型中声明的参数名(注意是函数声明)。在原型中(与函数定义不同),参数的名字(参数类型必需)并非必需。但是,如果出现参数名,可以随意取个名字,不必与函数定义的形参名匹配,也不必与函数实际调用时所传递的实参匹配。原型作用域防止这些参数名与程序其他部分的名字冲突。事实上,唯一可能出现的冲突就是在同一个原型中不止一次地使用同一个名字。
- 函数作用域【少用】
- 它只适用于语句标签,语句标签用于goto语句。基本上,函数作用域可以简化为一条规则——一个函数中的所有语句标签必须唯一。
6-12 定义与声明
- 当一个变量被定义的时候,编译器为变量申请内存空间并填充一些值
- 当一个变量被声明的时候,编译器就知道该变量被定义在其他地方
声明就是通知编译器该变量名及相关类型已经存在,不需要再申请内存空间,例如extern关键字声明- 局部变量既是定义也是声明
- 声明可以多次,但是定义只有一次
6-13 链接属性
可执行程序要通过编译和链接两步
编译是将源代码编程机器码,链接是将相关的库文件拉取代码合并
链接属性的作用:处理不同源文件里面的同名标志符
- external外部的
- 多个文件中声明的同名标识符表示同一个实体
- internal内部的
- 单个文件中声明的同名标识符表示同一个实体
- none无(空链接属性)
- 声明的同名标识符被当做独立不同的实体
只有具备文件作用域的标识符(函数名和全局变量)才能拥有external或internal的链接属性,其他作用域的标识符都是none属性
默认情况下,具备文件作用域的标识符拥有external属性,也就是说该标识符允许跨文件访问,对于external属性的标识符,无论在不同的文件中声明几次,表示的都是同一个实体
使用static关键字可以使得原先拥有external属性的标识符变为internal属性
- 使用static关键字修改的链接属性,只对具有文件作用域的标识符生效(对于拥有其他作用域的标识符是另外一种功能【静态局部变量】)
- 链接属性只能修改一次,不能变回external
在main函数文件中对于全局变量和函数名使用,此时该变量(函数)只能在main函数的文件中使用,避免污染
6-14 生存期
从时间维度分析变量,c语言的变量有两种生存期
- 静态存储器
- 自动存储器
具有文件作用域的变量属于静态存储期,函数名也属于静态存储期,属于静态存储期的变量在程序执行期间将一直占据存储空间,直到程序关闭才释放
- 全局变量
- 函数名
具有代码块作用域的变量一般情况下属于自动存储期,属于自动存储期的变量在代码块结束的时候自动释放存储空间
- 函数的形式参数
- 代码块内局部变量
6-15 存储类型
存储类型其实是指存储变量值的内存类型
分类:
- auto
- register
- static
- extern
- typedef
auto自动变量
- 在代码块中声明的变量默认的存储类型就是自动变量
- 函数中的形式参数,局部变量,拥有:代码块作用域,自动存储期,空链接属性
int i ;
int main(){
auto int i;
return 0;
}
register
-
存在cpu内部
-
将一个变量声明为存储期变量,那么该变量就有可能被存放在CPU的寄存器中
-
register变量拥有:代码块作用域,自动存储期,空链接属性
-
当变量声明为寄存器变量时,那么无法通过取址运算符获取该变量地址
static
- 将全局变量的作用范围从多文件共享到单文件独享
- 使用static声明局部变量时,该局部变量指定为静态局部变量
- 使得局部变量由自动存储期变为静态存储期,生存期变得和全局变量一样,直到程序结束才释放
- 但是并不是将该变量声明为全局变量,其他函数内也无法使用,也就是说改变了的存储位置,生存期发生了改变,但是作用域并没有改变,任然是局部变量作用域
extern
typedef
- 为数据类型定义别名
typedef unsigned int t_int;
//由于unsigned int 这个类型定义太长了,避免数据冗余,我将其定义为 t_int 。
总结:
-
使用auto和register声明的变量具有自动存储期
-
使用static和entern声明的变量具有静态存储期
6-16 内联函数
内联函数解决程序中函数调用的效率问题。(但会增加编译时间)
定义函数前加上inline关键字
内联函数执行过程是在主函数中展开,而不是主函数-子函数-返回主函数。
现在的编译器很聪明,不写inline,也会自动将一些函数优化成内连函数
#include6-17 可变参数
#include #include 7.数组
7.1数组的概念
数组是若干个相同类型的变量在内存中有序存储的集合。
循环与数组的关系
- 一般初始化计数器设置为0,循环条件是小于号,避免数组越界
数组的初始化:
- 如果只写了部分元素,则剩余元素都自动赋值为0
- 用逗号隔开
7.2 数组的分类
1)字符数组
char s[10]; s[0],s[1]....s[9];
2)短整型的数组
short a[10];
3)整型的数组
int a[10];
4) 长整型的数组
lont a[5];
5)浮点型的数组(单、双)
float a[6]; a[4]=3.14f;
double a[8]; a[7]=3.115926;
6)指针数组
char *a[10]
7)结构体数组
struct student a[10];
7.3 二维数组
二维数组又称为矩阵
数组名【行下标】【列下标】
int a [3] [3]
| arr[0,0] | arr[0,1] | arr[0,2] |
|---|---|---|
| arr[1,0] | arr[1,1] | arr[1,2] |
| arr[2,0] | arr[2,1] | arr[2,2] |
在c语言中数组的存放是线性的,也就是堆结构,而二维数组也是线性的
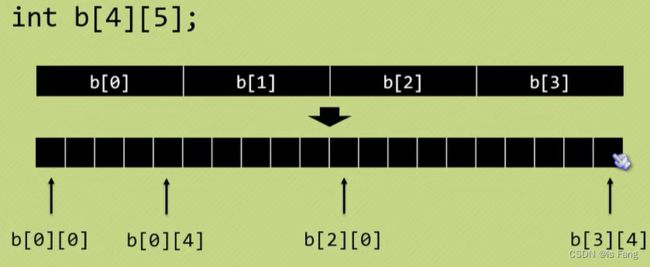
二维数组的初始化
- 可以将所有数据写在一个花括号内
- 可以使用多个花括号分隔每一行
- 可以只对部分元素赋值
- 可以指定初始化元素,例如
int a[3][4] = {[0][0]= 1 , [1][1]=2}
- 第一维元素个数可以不写,但是其他维度的必须写上
int a[][4] = {{1,2,3,4},{5,6,7,8},{9,10,11,12}}
矩阵的转置
- 将for循环的变量交换即可
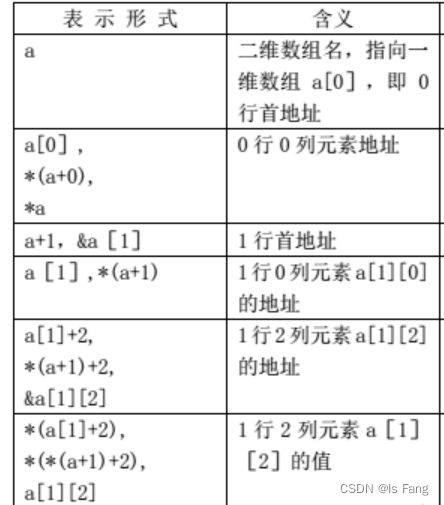
#include 二维数组名的含义
在一维数组中,数组名相当于数组的第一个元素的地址值,
在二维数组中,数组名相当于包含第一行元素的地址值(数组指针的应用)
- 数组名+1表示跳过一行数组到下一行数组,也就是说array+1表示取出第二行数组的地址,所以此时的
*(array+1) = 数组第二行第一个元素的地址值,若要取出该元素,需要再使用解引用,也就是**(array+1)
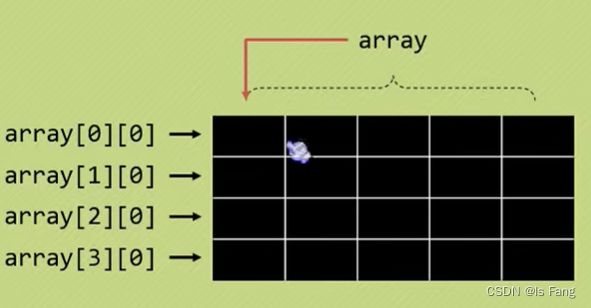
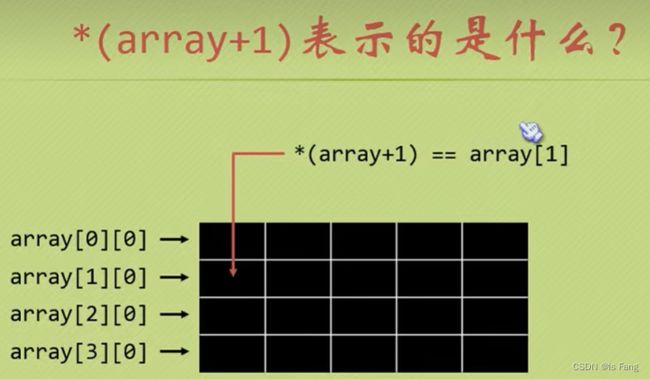 结论:
结论:

| array | 首行元素的地址值 |
|---|---|
| array[1] = *(array+1) | 第二行首元素地址值 |
| **(array+1) | 第二行首元素的值 |
数组指针与二维数组
int array[2][3] = {
{1,2,3}
{2,3,4}
}
int (*p)[3] = array;
//此时p就是数组指针,该指针指向array数组的第一行,一次解引用获得第一行第一个元素的地址,二次解引用获得该元素的内容。
// p = array可以相互替换
// 每一行的内存为int * [3] ===>> 4*3 = 12字节
7-4 数组的排序
冒泡排序
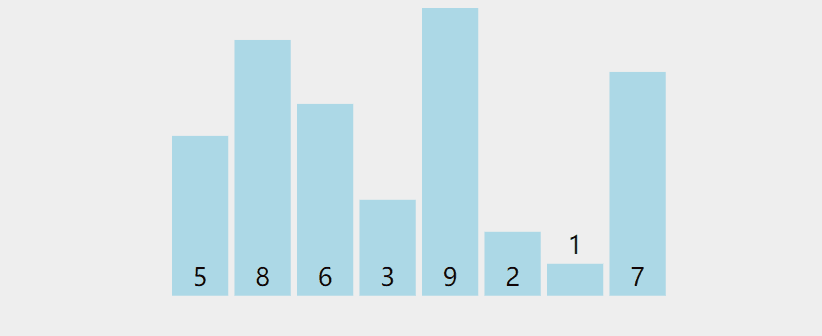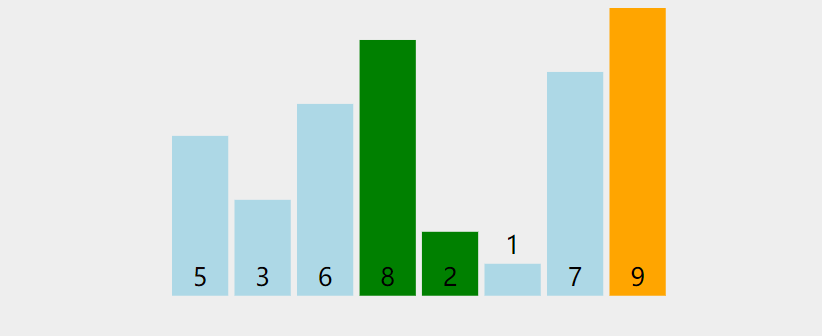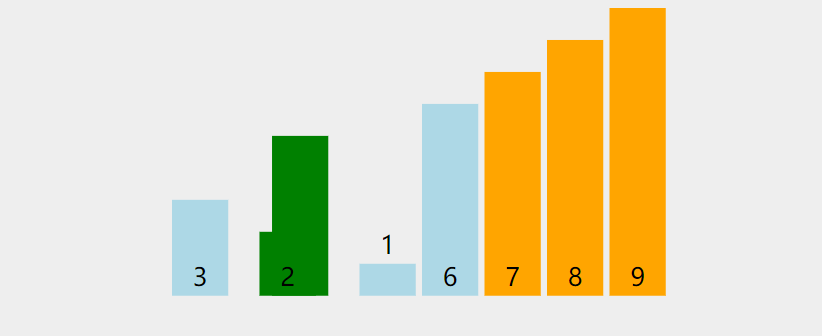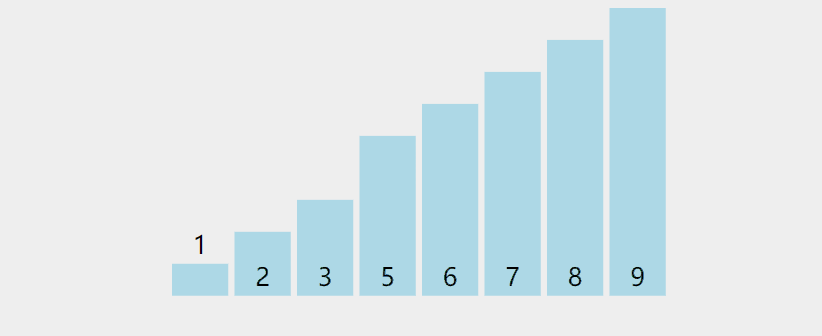
-
先遍历数组,让挨着的两个进行比较,如果前一个比后一个大,那么就把两个换个位置
-
数组遍历一遍以后,那么最后一个数字就是最大的那个了
-
然后进行第二遍的遍历,还是按照之前的规则,第二大的数字就会跑到倒数第二的位置
-
以此类推,最后就会按照顺序把数组排好了
选择排序
- 先假定数组中的第 0 个就是最小的数字的索引
- 然后遍历数组,只要有一个数字比我小,那么就替换之前记录的索引
- 知道数组遍历结束后,就能找到最小的那个索引,然后让最小的索引换到第 0 个的位置
- 再来第二趟遍历,假定第 1 个是最小的数字的索引
- 在遍历一次数组,找到比我小的那个数字的索引
- 遍历结束后换个位置
- 依次类推,也可以把数组排序好
快速排序
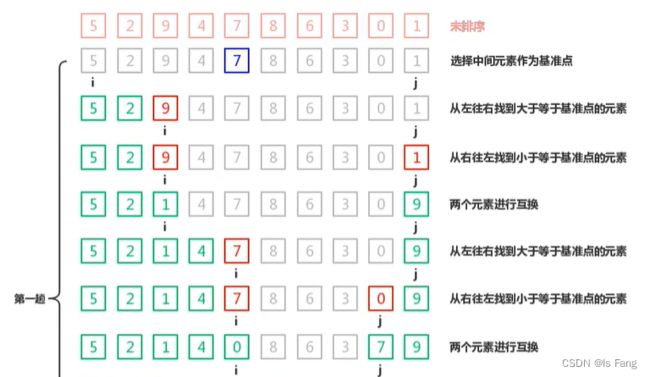
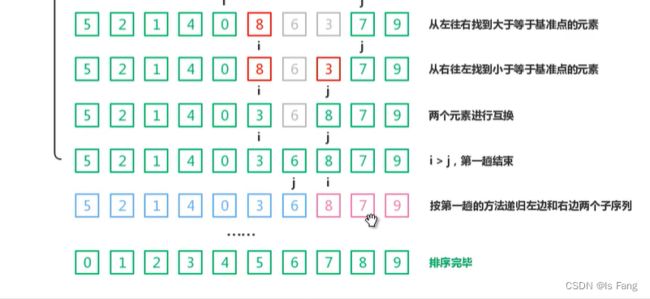
递归解法
- 一般在递归函数里面要定义static变量来作为遍历次数,将其生存期变为静态生存期然后进行统计
#define _CRT_SECURE_NO_WARNINGS 1
//快速排序算法,递归求解
#include 8.指针
8-0 内存与地址与变量名
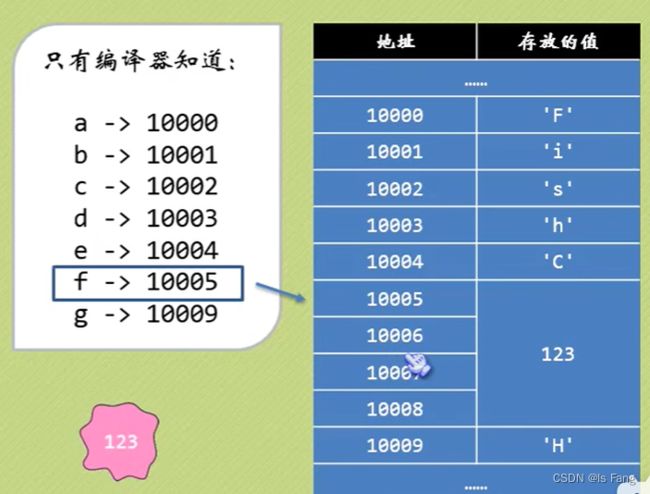
数据在内存中如何存储和读取?
- 通过变量名进行获取数据和定义数据存储空间
- 内存并没有存放变量名!!!编译器会有一张变量名与地址的映射关系表
内存是如何存储数据?
- 内存的最小索引单元是一个字节
- 整型占用四个字节,占用四个存储单元
数据是以小端存储的,靠后面的数据存放在上面
而在内存中数组是顺序存储的,在前面的存放在上
- 人类习惯使用变量名
- 只有编译器知道变量名对应的地址值
- 读取变量时,通过访问变量名映射的地址值,并根据变量的类型取得相应范围的数据
8-1 指针的概念

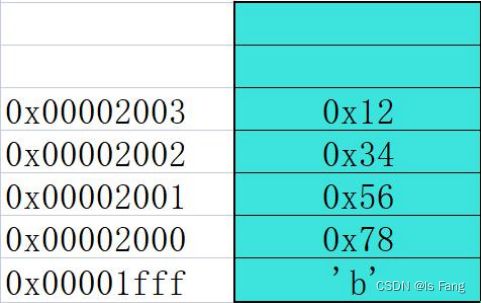
字符变量 char ch=‘b’; ch 占 1 个字节,它有一个地址编号,这个地址编号就是ch 的地址整型变量 int a=0x12 34 56 78; a 占 4 个字节,它占有 4 个字节的存储单元,有4 个地址编号。
操作系统是32位,地址是32位编号,那么0x的十六进制表示符中,一个字符就是4位
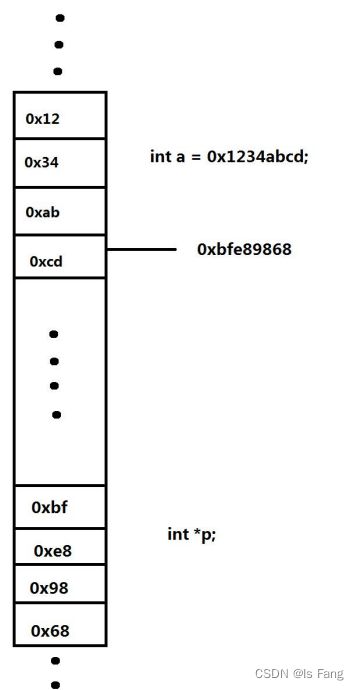
指针变量存放的是地址值,通过该地址值访问到的是变量名的地址值

8-2 指针变量的定义
1.简单的指针变量
数据类型 * 指针变量名;
int * p;//定义了一个指针变量 p
在 定义指针变量的时候 * 是用来修饰变量的,说明变量 p 是个指针变量。
2.关于指针的运算符
& 取地址运算符 、 *取值运算符
- 获取某个变量的首地址,使用取地址运算符&
- 访问指针变量指向的那个变量的值,可以使用取值运算符*【间接访问】
- 通过指针变量修改其存储地址指向的变量的值是间接访问,通过变量访问变量值是直接访问
int a=0x1234abcd;
int *p;//在定义指针变量的时候*代表修饰的意思,修饰 p 是个指针变量。
p=&a;//把 a 的地址给 p 赋值 ,&是取地址符,
8-3 指针的用处
8-3-1传递参数
1、 使用指针传递大量参数,主函数和子函数使用的是同一套数据,避免传递参数过程中的数据复制,提高运行效率,减少内存使用
2、 使用指针传递输出参数,利用主函数和子函数使用同一套数据的特性,实现数据的返回,可实现多返回值函数的设计
-
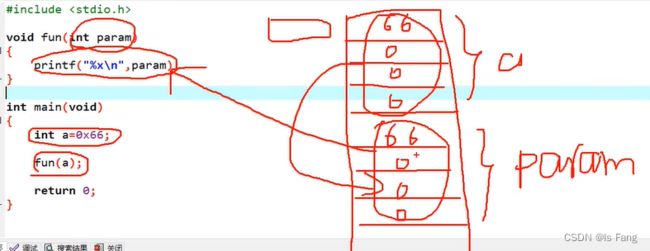
例子:使用值传递的时候,会在内存里面开辟两个一样内容的空间,造成内存浪费,好处是两个隔绝变量的修改,此时修改param的值a的值不会被修改
-
-
例子:当实参是数组名的时候,其实传递的是数组首元素地址值,此时fun函数要用指针接收,指针的解引用可以得到首元素值。此时额外的开销只是地址所占用的空间

-
#include//传递地址会导致函数共用一块内存数据,但是可以使用const关键字修饰指针时,此时是指向常量的指针,不可以通过解引用来修改指针指向的数据 int FindMax(cosnt int *array,int count){ int i; // int max = array[0]; int max = *array; for (i = 0; i < count; i++) { if (*(array+i)>max) { max= *(array+i); } } return max; } int main(void) { int a[]={1,2,3,4,15}; int Max; Max = FindMax(a,5); printf("%d",Max); return 0; } -
总结:
-
如果是传递值,此时由于函数的作用域,其他函数内部的该变量名不会被修改到
-
而如果是传递地址,此时修改该变量的值,在任何函数内,访问该变量都是修改之后的值
-
-
例子:利用指针实现多返回值
-
#includevoid FindMaxAndCount(int *max, int *count, const int *array, int length) { int i; *max = array[0]; *count = 1; for (i = 0; i < length; i++) { if (array[i] > *max) { *max = array[i]; *count = 1; } else if (array[i] > *max) { (*count)++; } } } int main(void) { int a[] = {10, 20, 20, 4, 15}; int Max; int Count; //将多个返回值作为函数的参数 FindMaxAndCount(&Max, &Count, a, 5); printf("%d\n", Max); printf("%d\n", Count); return 0; } - 类似的函数有strcpy(char *,const char *),右边的字符串复制到左边,左边不是指向常量的指针,字符串可以被修改,
8-3-2传递返回值
-
将模块内的公有部分返回,让主函数持有模块的“句柄”,便于程序对指定对象的操作
-
指针很多时候应用于封装,封装的模块里面会定义全局变量,然后通过函数暴露出去,此时在别的函数体内可以使用该全局变量,不同模块里面相同 的变量使用的不是同一个地址
-
#include`````````````````````定时器模块 int Time[]={12,32,45}; int* GetTime(void){ return Time; } ``````````````````````` int main(void) { int *p; //获取其他模块的句柄 p = GetTime(); printf("%d\n", p[0]); printf("%d\n", p[1]); printf("%d\n", p[2]); return 0; } -
不能将局部变量返回,可以返回模块内的全局变量
-
例如调用fopen函数,参数是指针,返回值也是指针,参数传递字符串(字符指针指向首元素地址值),返回值是结构体指针,此时该结构体指针就是“句柄”,通过该句柄我们可以写入、读取和关闭文件等
8-3-3直接访问物理地址下的数据
-
访问硬件指定内存下的数据,如设备ID号等
-
#include#include"LCD1602.h" void main(){ unsigned char *p; LCD_Init(); P = (unsigned char)0xF1; LCD_ShowHexNum(2,1,*p,2); LCD_ShowHexNum(2,1,*(p+1),2); ..... }
-
-
将复杂格式的数据转化为字节,方便通信与存储
-
串口与无限模块只能一个字节发送,精度无法保证
-
#include/**********无线模块*************/ // 无线模块接收到的内容 unsigned char AirData[20]; void SendData(const unsigned char *data,unsigned char count){ unsigned char i; for ( i = 0; i < count; i++) { AirData[i]=data[i]; } } // 接收参数 void ReceiveData(unsigned char *data,unsigned char count){ unsigned char i; for ( i = 0; i < count; i++) { data[i]=AirData[i]; } } /***********************/ /************PC展示数据*******************/ int main(void) { unsigned char data[]={0x12,0x45,0x65,0x85}; float num = 123.456; unsigned char *p; p = (unsigned char *)# SendData(p,4); /************打印***********/ unsigned char i; for ( i = 0; i < 4; i++) { printf("AirData里面的数据"); printf("%x\n",AirData[i]); } //接收变量 unsigned char DataReceive[4]; float *fp; ReceiveData(DataReceive,4); fp=(float *)DataReceive; printf("%f",*fp); return 0; } -
复杂格式的数据有float,double,结构体等,需要将其强制转化为unsigned char*类型的数据(指针变量)以数组的形式进行传递,接收的时候使用原复杂格式类型的指针变量。
-
float是四个字节的数据,但是编码形式不一样,当我们用unsigned char *指针指向首地址时,此时数据传递以数组的形式发送过去,解码的时候使用float *等于数组首地址,解码得到的就是float类型的数据
-
8-4 指针和数组
数组名是数组首元素的地址值
int a[5];
int *p;
p = a; //数组名是首元素地址值
p=&a[0];//首元素地址值
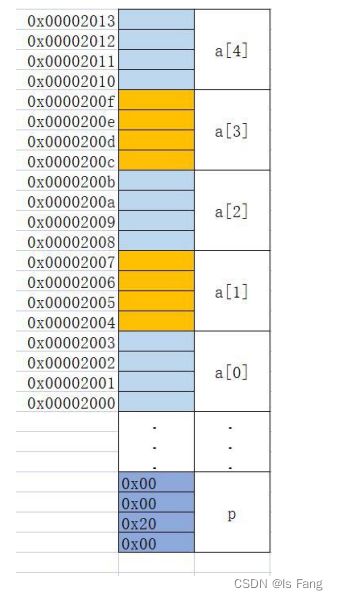
指针变量 p 保存了数组 a 中第 0 个元素的地址,即 a[0]的地址
通过指针变量运算加取值的方法来引用数组的元素
int a[5];
int *p;
p=a; *(p+2)=100;//也是可以的,相当于 a[2]=100
解释:
p 是第 0 个元素的地址,p+2 是 a[2]这个元素的地址。对第二个元素的地址取值,即 a[2]
p+1不是将地址加1,而是地址+字符存储空间大小 ,也就是指向下一个元素
在指针的定义的时候就告诉指针移动的距离,例如int移动的是4个字节,char移动的是1个字节
所以:利用下标引用数组数据等效于指针取内容。对比标准的下标访问数组的元素,这种使用指针进行间接访问数组元素的方法叫做指针法
注意:数组名的指针访问形式也可以读取到元素
char a[] = "FishC";
char *p = a;
printf("*a = %c,*(a+1) = %c,*(a+2) = %c\n",*a,*(a+1),*(a+2));
注意:定义的指针也可以使用数组的下标法进行访问,指针的下标访问形式
char *str = "i love";//字符串常量就是字符数组,数组名就是首元素地址值
int i ,length;
length = strlen(str);//获取元素个数
for(i=0 ;i<length;i++)
{
printf("%c",str[i]);
}
printf("\n");
虽然数组和指针之间可以交替使用但是还是有区别:
指针和数组的区别
-
数组名只是一个地址,而指针是一个左值【左值指用于识别或定位一个存储位置的标识符,左值同时还必须是可以改变的】
-
例如:计算一个字符串里面字符的个数时利用自值运算符进行遍历,而自增运算符的操作数必须是个左值,应该采用指针去访问,将数组首元素地址赋值给指针
char str[] = "FISH";
int count = 0;
//数组名的指针访问形式会报错,因为数组名不是左值,想要用于定位一个存储位置的标识符,需要是可以改变的
while (*str++ != '\0')
//单目运算符,从右到左
{
count++;
}
printf("字符串长度:%d",count);
return 0;
//lvalue required as increment operand
修改为
char str[] = "FISH";
char *p = str;//指针变量p指向字符串首字符的地址值
int count = 0;
//数组名的指针访问形式
while (*p++ != '\0')
//单目运算符,从右到左
{
count++;
}
printf("字符串长度:%d",count);
return 0;
//lvalue required as increment operand
8-5 指针的分类
按指针指向的数据的类型来分
1:字符指针
字符型数据的地址
字符串其实就是指向首字符的指针所以一般采用字符指针接收char *str = "i love";
char *p;//定义了一个字符指针变量,只能存放字符型数据的地址编号
char *str = "FISHTC";//str是字符指针,指向该字符串首字符的地址
printf("*str = %s\n",str)//FISHC
字符串的特殊点就是只要给首地址值,用%s打印则会依次打印出所有的字符
2:短整型指针
short *p;//定义了一个短整型的指针变量 p,只能存放短整型变量的地址
3:整型指针
int *p;//定义了一个整型的指针变量 p,只能存放整型变量的地址
4:长整型指针
long *p;//定义了一个长整型的指针变量 p,只能存放长整型变量的地址
5:float 型的指针
float *p;//定义了一个 float 型的指针变量 p,只能存放 float 型变量的地址
6:double 型的指针
double *p;//定义了一个 double 型的指针变量 p,只能存放 double 型变量的地址
7:函数指针
8、结构体指针
9、指针的指针
10、数组指针
11、通用指针 void *p;
无论什么类型的指针变量,在 32 位系统下,都是 4 个字节
指针只能存放对应类型的变量的地址编号。
8-6 字符串和指针
字符串就是以’\0’结尾的若干的字符的集合:比如“hello world”。
字符串的地址,是第一个字符的地址。如:字符串“hello world”的地址,其实是字符串中字符’h’的地址。
我们可以定义一个字符指针变量保存字符串的地址,比如:char *s =”hello world”;
字符串的可修改性
字符串内容是否可以修改,取决于字符串存放在哪里
-
存放在数组中的字符串的内容是可修改的
char str[100]=”kerwin”; str[0]=‘y’;//正确可以修改的 -
文字常量区里的内容是不可修改的
char *str=”kerwin”; *str =’y’;//错误,存放在文字常量区,不可修改
字符指针str与字符数组str的区别是:str是一个变量,可以改变str使它指向不同的字符串,但不能改变str所指的字符串常量。string是一个数组,可以改变数组中保存的内容。
8-7 指针数组
定义一个数组,数组中有若干个相同类型指针变量,这个数组被称为指针数组int *p[5]
指针数组本身是个数组,是个指针数组,是若干个相同类型的指针变量构成的集合

解决二维数组的问题,指针数组里面的指针变量指向某个数组首元素的地址值,也就是说指针数组里面的元素又可以通过指针进行访问,所以我们可以用指向指针的指针来访问每个元素,便于循环遍历
// 需求:前四个字符串一起打印,后一个字符串另外打印
#include 8-8 指针的指针
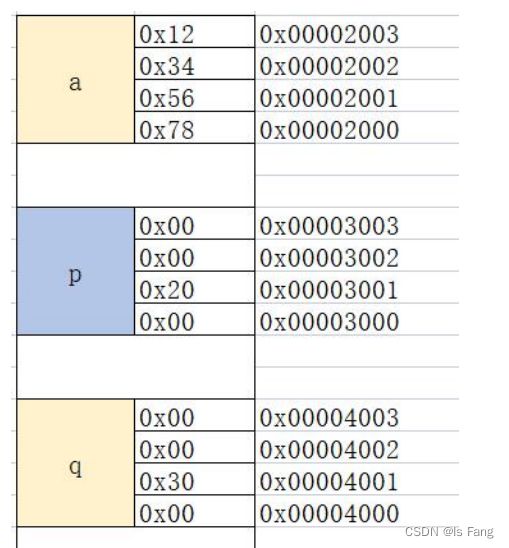
指针的指针,即指针的地址,
int a=0x12345678;
假如:a 的地址是 0x00002000
int *p;
p =&a;
则 p 中存放的是 a 的地址编号即 0x00002000
假如:指针变量 p 的地址编号是 0x00003000,这个地址编号就是指针的地址
int **q;
q=&p;//q 保存了 p 的地址,也可以说 q 指向了 p
则 q 里存放的就是 0x00003000
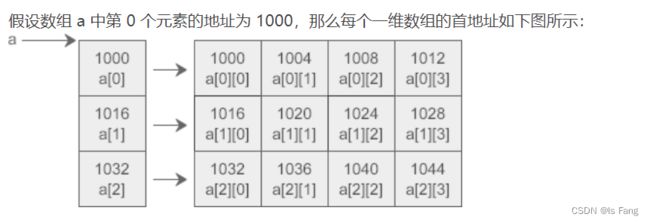
8-9 数组指针
本身是个指针,指向一个数组,加 1 跳一个数组,即指向下个数组。
指向的数组的类型(*指针变量名)[指向的数组的元素个数]
int (*p)[5];//定义了一个数组指针变量 p,p 指向的是整型的有 5 个元素的数组,p+1 往下指 5 个整型,跳过一个有 5 个整型元素的数组。

重点
注意数组指针的解引用
int temp[5] = {1,2,3,4,5};
int (*p2)[5]= &temp;
int i;
for ( i = 0; i < 5; i++)
{
printf("%d\n",*(*p2+i);//&temp其实是二级指针,解引用一次得到一级指针,也就是*p2解引用得到数组名,数组名表示首元素地址值,+i获取下一个元素的地址值,再解引用得到元素内容
}
return 0;
8-10 数组名字取地址
变成 数组指针
#include重点:
a 和&a 所代表的地址编号是一样的,即他们指向同一个存储单元,但是a和&a 的指针类型不同。
a 是个 int *类型的指针,是 a[0]的地址。 &a 变成了数组指针,加 1 跳一个 10 个元素的整型一维数组
8-11 数组名字和指针变量的异同
int a[5]= {1,2,3,4,5}
int *p = a;
此时p=a;
相同点:
a 是数组的名字,是 a[0]的地址,p=a 即 p 保存了 a[0]的地址,即 a 和 p 都指向a[0],所以在引用数组元素的时候,a 和 p 等价 引用数组元素回顾: a[1]、**(a+1)、p[1]、* *(p+1) 都是对数组 a 中 a[1]元素的引用。
不同点:
-
a 是常量、p 是变量
-
对 a 取地址,和对 p 取地址结果不同
因为 a 是数组的名字,所以对 a 取地址结果为数组指针。
p 是个指针变量,所以对 p 取地址(&p)结果为指针的指针。即二级指针
8-12 给函数传指针参数
要想改变主调函数中变量的值,必须传变量的地址,而且还得通过*+地址去赋值。无论这个变量是什么类型的。
void fun(char **barr) {
printf("%d\n", barr[0][0]);
barr[0][0] = 2;//修改为2
}
int main() {
int arr1[] = { 1,2,3 };
int arr2[] = { 4,5,6 };
int* arr[] = { arr1,arr2 };//指针数组
fun(arr);
printf("%d\n", arr[0][0]);
}
8-13 函数返回值是指针
指针函数:函数的类型由函数的返回值决定
不要返回局部变量的指针【见指针的用处章节】
int* swap( int a,int b) {
int temp = a; //临时变量先存其中一个值
a = b;
b = temp;
static int arr[2]; //静态
arr[0] = a;
arr[1] = b;
return arr;
}
......
int *x = swap(myarr[j], myarr[j + 1]);
myarr[j] = x[0];
myarr[j + 1] = x[1];
......
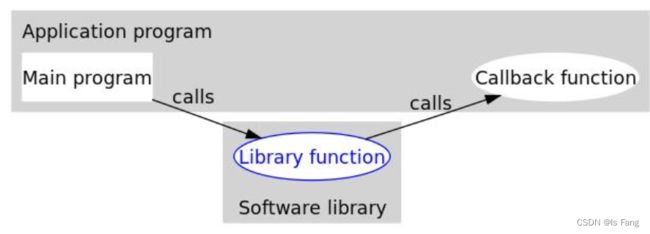
8-14 初识函数指针
咱们定义的函数,在运行程序的时候,会将函数的指令加载到内存的代码段。所以函数也有起始地址。
c 语言规定:函数的名字就是函数的首地址,即函数的入口地址, 咱们就可以定义一个指针变量,来存放函数的地址。 这个指针变量就是函数指针变量。
8-15 函数指针的定义和调用
定义:
int max(int x,int y)
{
...
}
int(*p)(int,int);//定义了一个函数指针变量 p,
p=max; //p 指向的函数
调用:
(*p)(30,50);//解引用得到函数
p(30,50);
8-16 函数指针的用处
-
函数指针作为参数
- 在main函数中只需要写一个函数,该函数的参数之一就是函数指针,该指针接收的地址就是准备使用到的函数,这样就可以减少代码冗余。
-
将函数指针作为返回值
void call_back(int current , int total){
printf("压缩进度是:%d------%d" , current , total); // 22------100
}
void compress(char* file_name ,void(call_back)(int , int)){
call_back(22 , 100);
}
void main(){
compress("kerwin.jpg" , call_back);
}
int add(int,int);
int sub(int,int);
int add(int num1,int num2){
return num1 + num2;
}
int sub(int num1,int num2){
return num1 - num2;
}
//定义一个函数,参数为函数指针,该指针指向需要调用函数的地址
int cal(int (*fp)(int ,int),int num1,int num2){
//解引用得到函数
return (*fp)(num1,num2);
}
//定义一个函数,返回值是函数指针,将函数名和括号去掉就是返回的数据类型
int (*select(char op))(int ,int){
switch(op){
case: '+':return add;
case:'-':return sub;
}
}
int main()
{
int num1, num2;
char op;
int (*fp)(int,int);
printf("请输入一个式子");
scanf("%d %c %d",&num1,&op,&num2);
fp = select(op);
printf("%d %c %d = %d\n",num1,op,num2,cal(fp,num1,num2))
return 0 ;
}
8-17 易混淆指针
1、 int *a[5];
这是个指针数组,数组 a 中有 5 个整型的指针变量
a[0]~a[4] ,每个元素都是 int *类型的指针变量
2、int (*a)[5];
数组指针变量,它是个指针变量。它占 8 个字节,存地址编号。
它指向一个数组,它加 1 的话,指向下一行。
3、 int **p;
这个是个指针的指针,保存指针变量的地址。
它经常用在保存指针的地址:
4、int *f(void);
注意:*f 没有用括号括起来
它是个函数的声明,声明的这个函数返回值为 int *类型的。
5、int (*f)(void);
注意*f 用括号括起来了,*修饰 f 说明,f 是个指针变量。
f 是个函数指针变量,存放函数的地址,它指向的函数,
必须有一个 int 型的返回值,没有参数。
8-18 特殊指针
- 空类型的指针(void *)
void* 通用指针,任何类型的地址都可以给 void*类型的指针变量赋值。
好处是可以让不同类型的指针相互转化,不要直接对void类型的指针进行解引用,要先转化
任何类型的指针都可以赋值给无类型指针
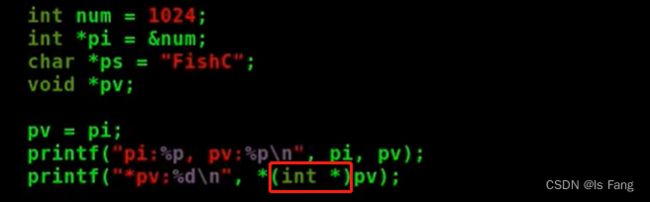
因为对于这种通用型接口,你不知道用户的数据类型是什么,但是你必须能够处理用户的各种类型数据,因而会使用void*。void*能包容地接受各种类型的指针。也就是说,如果你期望接口能够接受任何类型的参数,你可以使用void*类型。但是在具体使用的时候,你必须转换为具体的指针类型。例如,你传入接口的是int*,那么你在使用的时候就应该按照int*使用。
- 空指针 NULL
char *p=NULL;
p 哪里都不指向,也可以认为 p 指向内存编号为 0 的存储单位。
在对指针进行解引用的时候,先检查该指针是否为NULL,可以节省调试时间
四. 动态内存申请
1.初识动态内存
C语言提供了一些内存管理函数,这些内存管理函数可以按需要动态的分配内存空间,也可把不再使用的空间回收再次利用。
静态分配
1、 在程序编译或运行过程中,按事先规定大小分配内存空间的分配方式。int a [10]
2、 必须事先知道所需空间的大小。
3、分配在栈区或全局变量区,一般以数组的形式。
4、 按计划分配。
动态分配
1、在程序运行过程中,根据需要大小自由分配所需空间。
2、按需分配。
3、分配在堆区,一般使用特定的函数进行分配。
2. malloc 函数
void * malloc(size_t size )
在内存的动态存储区(堆区)中分配一块长度为 size 字节的连续区域,用来存放类型说明符指定的类型。函数原型返回 void*指针,使用时必须做相应的强制类型转换.
返回值:
-
分配空间的起始地址 ( 分配成功 )
-
NULL ( 分配失败 )
注意:
- 在调用 malloc 之后,一定要判断一下,是否申请内存成功。
#include - 如果多次 malloc 申请的内存,第 1 次和第 2 次申请的内存不一定是连续的
内存池
-
malloc内存分配会造成内存碎片
-
malloc向操作系统申请内存在时间上消耗 应用层——内核层——应用层
解决方法:
-
内存池 —》让程序额外维护的一个缓存区域
-
当申请内存时检查内存池有没有适合的垃圾内存块,重新使用
-
想申请内存时
- 如果内存池非空,则直接从里面获取空间
- 如果内存池为空,则重新申请内存空间
-
想释放内存时
- 如果内存池有空位(小于内存池容量),那么将即将废弃的内存块插入内存池
- 如果内存池没有空位,那么就用free等释放掉
实现:
- 使用单链表来维护内存池
- 将没有用的空间地址依次用一个单链表记录下
内存池介绍
3. free 函数(释放内存函数)
void free(void *ptr)
free 函数释放 p 指向的内存。该内存空间必须是由malloc、calloc或realloc函数申请的。否则,该函数将导致未定义行为。如果p指向NULL,则不执行任何操作。注意:该函数并不会修改p的值,所以调用后仍然指向原来的地方(变为非法空间)。
char *p=(char *)malloc(100);
free(p);
4. calloc 函数
函数原型
void *calloc(size_t nmemb,size_t size);
在内存中动态地申请nmemb个长度为size的连续内存空间(即申请的总空间尺寸为nmemb *size),这些内存空间全部被初始化为0。
函数的返回值:
- 返回申请的内存的首地址(申请成功)
- 返回 NULL(申请失败)
注意:malloc 和 calloc 函数都是用来申请内存的。
区别:
1) 函数的名字不一样
2) 参数的个数不一样
3) malloc 申请的内存,内存中存放的内容是随机的,不确定的,而calloc 函数申请的内存中的内容为 0,进行了初始化操作
所以下面两种写法是等价的:
int *ptr=(int *)calloc(8,sizeof(int));
//calloc()分配内存空间并初始化等价于malloc()分配内存空间并用memset()初始化
int *ptr=(int *)malloc(8 *sizeof()int);
memset(ptr,0,8*sizeof(int)); //使用功能memset方法初始化
5. realloc 函数
函数原型
void *realloc(void *ptr,size_t size);
- realloc函数修改ptr指向的内存空间大小为size字节
重新分配内存空间
在原先 s 指向的内存基础上重新申请内存,新的内存的大小为 new_size 个字节,如果原先内存后面有足够大的空间,就追加,如果后边的内存不够用,则relloc 函数会在堆区找一个 newsize 个字节大小的内存申请,将原先内存中的内容拷贝过来,然后释放原先的内存,最后返回新内存的地址。
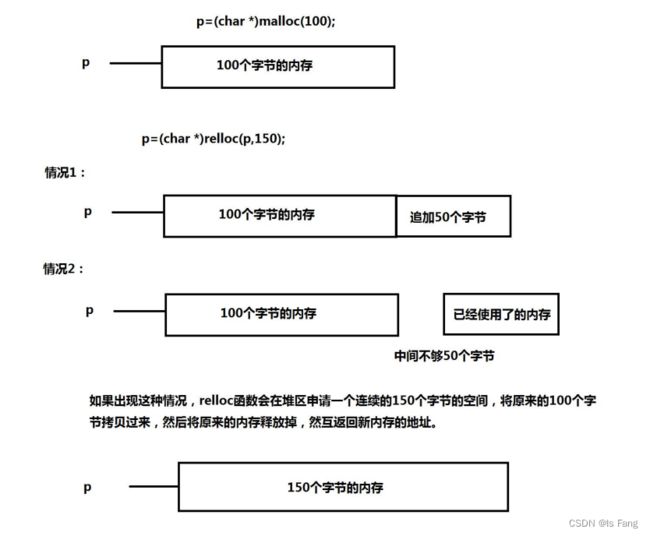
注意:
-
如果新分配的内存空间比原来的大,则旧内存块的数据不会发生改变;如果新的内存空间大小小于旧的内存空间,可能会导致数据丢失,慎用!
-
如果ptr参数为NULL,那么调用该函数就相当于调用malloc(size)
-
如果size参数为0,并且ptr参数不为NULL,那么调用该函数就相当于调用free(ptr)
-
除非ptr参数为NULL,否则ptr的值必须由先前调用malloc、calloc或realloc函数返回
6. 初始化内存空间
以mem开头的函数被编入字符串标准库,函数的声明包含在
-
memset 使用一个常量填充内存空间 //配合malloc函数初始化内存空间
-
memcpy 拷贝内存空间 //参数:目标,源,拷贝数据大小,应用在为变量申请更大的空间。等效于realloc函数
-
memmove 拷贝内存空间
-
memcmp比较内存空间
-
memchar在内存空间中搜索一个字符
mem开头的函数返回值是无类型指针
7. 内存泄露
申请的内存,首地址丢了,找不了,再也没法使用了,也没法释放了,这块内存就被泄露了。
int main()
{
char *p;
p=(char *)malloc(100);
//接下来,可以用 p 指向的内存了,原来malloc申请的内存块丢失,free不能释放原来的动态内存。
p="kerwin";//p 指向别的地方了
//从此以后,再也找不到你申请的 100 个字节了。则动态申请的 100 个字节就被泄露了
}
void func()
{
char *p;
p=(char *)malloc(100);
}
int main()
{
func();//函数调用结束后局部变量会x
func();
}
//每调用一次 fun 泄露 100 个字节
为了防止函数调用结束后内存空间泄漏,应该将指针返回,修改void func为char * func
五. 字符串处理函数
1. 字符串拷贝函数strcpy_s和strcpy和strncpy
拷贝 src 指向的字符串到 dest 指针指向的内存中,’\0’也会拷贝
#include- 拷贝的时候也会携带结束符,所有结束符后面的内容时看不到的
- 拷贝的时候要确保左边的字符串空间要大于右边字符串的空间,否则会报错
- strncpy()是受限的拷贝字符串,在第三个参数写拷贝的字符的个数【不包含自结束符,需要自己手动添加】
- 所以需要自己追加自结束符,否则打印拷贝对象时会一直读下去
2. 测字符串长度函数strlen
测字符指针 s 指向的字符串中字符的个数,不包括’\0’【注意使用sizeof得到的是尺寸包含结束符】
#include 3. 字符串追加函数strcat_s和strcat和strncat
strcat 函数追加 src 字符串到 dest 指向的字符串的后面。追加的时候会追加’\0’
char* str = (char*)malloc(100);
if (str == NULL) return;
scanf_s("%s", str, 100);
char *str2 = "先生/女士";
strcat_s(str, 100,str2);
printf("%s\n", str);
strncat()可以限定连接的字符个数,但是需要自己追加自结束符
4.字符串比较函数strcmp
比较 s1 和 s2 指向的字符串的大小, 比较的方法:逐个字符去比较 ascII 码,一旦比较出大小返回。 如果所有字符都一样,则返回 0
char* a = (char *)malloc(100);
char* b = (char *)malloc(100);
scanf_s("%s", a,100);
scanf_s("%s", b,100);
if (a == NULL || b == NULL) return;
if (strcmp(a, b) == 0) {
printf("输入正确");
}
else {
printf("输入错误");
}
- strncmp()限定只对某几个字符进行比较
5.字符查找函数strchr
在字符指针 s 指向的字符串中,找 ascii 码为 c 的字符 注意,是首次匹配,如果过说 s 指向的字符串中有多个 ASCII 为 c 的字符,则找的是第1 个字符
char* str[] = { "teichui","xiaoming","kerwin" };
char x;
scanf_s("%c", &x,1);
for (int i= 0; i < sizeof(str) / sizeof(char*); i++) {
if (strchr(str[i], x) != NULL) {
printf("%s\n", str[i]);
}
}
6. 字符串匹配函数strstr
char *strstr(const char *haystack, const char *needle);
在 haystack 指向的字符串中查找 needle 指向的字符串,也是首次匹配
char* str[] = { "teichui","xiaoming","kerwin"};
char x[100];
scanf_s("%s", x,100);
for (int i= 0; i < sizeof(str) / sizeof(char*); i++) {
if (strstr(str[i], x) != NULL) {
printf("%s\n", str[i]);
}
}
7.字符串转换数值atoi
atoi/atol/atof 字符串转换功能
函数的声明:int atoi(const char *nptr);
int num;
num=atoi(“12岁”);
则 num 的值为 12
8.字符串切割函数strtok
函数声明:char *strtok(char *str, const char *delim);
字符串切割,按照 delim 指向的字符串中的字符,切割 str 指向的字符串。其实就是在 str 指向的字符串中发现了 delim 字符串中的字符,就将其变成’\0’, 调用一次 strtok 只切割一次,切割一次之后,再去切割的时候 strtok 的第一个参数传 NULL,意思是接着上次切割的位置继续切
void split(char *p,char **myp) {
char* buf = NULL;
myp[0] = strtok_s(p,"|", &buf);
int i = 0;
while (myp[i]) {
i++;
myp[i] = strtok_s(NULL, "|", &buf);
}
}
9.空间设定函数memset
函数声明:void* memset(void *ptr,int value,size_t num);
memset 函数是将 ptr 指向的内存空间的 num 个字节全部赋值为 value
int* str = (int*)malloc(100);
if (!str)return;
//memset(str, -1, 100);
memset(str, 0, 100);
for (int i = 0; i < 25; i++)
{
printf("%d\n",str[i]);
}
六. 结构体
1.初识结构体
在程序开发的时候,有些时候我们需要将不同类型的数据组合成一个有机的整体
struct stu{
char name[100];
int score;
int age;
};
结构体是一种构造类型的数据结构, 是一种或多种基本类型或构造类型的数据的集合。
结构体声明不会分配内存空间
定义结构体类型变量才会分配空间
2.结构体初始化与访问
结构体变量,是个变量,这个变量是若干个相同或不同数据构成的集合注:
- 在定义结构体变量之前首先得有结构体类型,然后再定义变量
- 在定义结构体变量的时候,可以顺便给结构体变量赋初值,被称为结构体的初始化
- 结构体变量初始化的时候,各个成员顺序初始化
struct 结构体名称 结构体变量名;
或者在声明结构体时定义
struct 结构体名 {
。。。
} 变量名;//不过这时是全局变量
定义结构体的简称
typedef struct 结构体名称{
。。。
}简称;//简称可以有多个
或typedef struct 结构体名 简称;
使用typedef给结构体定义了一个简称,并不是变量
初始化结构体变量
struct stu {
char name[100];
int score;
int age;
};
struct stu student1= {"tiechui",100,18};
struct stu student0;
struct stu student2={.age=21};//只初始化stu的age成员;
strcpy_s(student0.name, 100, "kerwin");
student0.score = 100;
student0.age = 100;
3. 结构体数组
结构体数组是个数组,由若干个相同类型的结构体变量构成的集合,即数组成员是结构体
struct 结构体类型名 数组名[元素个数];
struct 结构名称
{
结构体成员;
} 数组名[长度];
方法二:先声明一个结构体类型,再此类型定义一个结构体数组
struct 结构体名称
{
结构体成员;
}
struct 结构体名称 数组名[长度];
结构体数组初始化
struct Book book[3]=
{
{。。。},
{。。。},
{。。。}
}
4. 结构体指针
即结构体的地址,结构体变量存放内存中,也有起始地址 咱们定义一个变量来存放这个地址,那这个变量就是结构体指针变量。 结构体指针变量也是个指针,既然是指针在 64 位环境下,指针变量的占 8 个字节,存放一个地址编号。
struct 结构体类型名 * 结构体指针变量名;
struct student *p;
struct student student1;
p = &student1;//结构体的变量名不是指向地址的,需要用取址运算符
//通过结构体指针访问成员的两种方法:
(*p).name//(*结构体指针).成员名
p->name//结构体指针->成员名
区别:
- 成员选择运算符,应用于指针
- 点号运算符,应用于对象
5. 结构体与函数
给函数传结构体变量的地址,该方法和传递数组地址一样,有利于节省内存
void input(struct stu *student) {
printf("请录入姓名,年龄, 成绩\n");
scanf_s("%s%d%d", student->name, &student->age, &student->score);
//字符数组名指向首元素地址 不用&,其他类型取其变量需要用取址操作符
}
6. 结构体内存分配
结构体变量大小是它所有成员的大小之和。
规则 1
以多少个字节为单位开辟内存, 给结构体变量分配内存的时候,会去结构体变量中找基本类型的成员,哪个基本类型的成员占字节数多,就以它大大小为单位开辟内存
(1):成员中只有 char 型数据 ,以 1 字节为单位开辟内存。
(2):成员中出现了 short ,int 类型数据,没有更大字节数的基本类型数据。以 2 字节为单位开辟内存
(3):出现了 int, float 没有更大字节的基本类型数据的时候以 4 字节为单位开辟内存。
(4):出现了 double 类型的数据, 以 8 字节为单位开辟内存。
规则 2
字节对其方式
(1):char 1 字节对齐 ,即存放 char 型的变量,内存单元的编号是1 的倍数即可。
(2):short, int 2 字节对齐 ,即存放 short int 型的变量,起始内存单元的编号是2 的倍数即可。
(3):int 4 字节对齐 ,即存放 int 型的变量,起始内存单元的编号是4 的倍数即可
(4):long int 在 32 位平台下,4 字节对齐 ,即存放 long int 型的变量,起始内存单元的编号是4的倍数即可
(5):float 4 字节对齐 ,即存放 float 型的变量,起始内存单元的编号是4 的倍数即可
(6):double 8 字节对齐,即存放 double 型变量的起始地址,必须是 8 的倍数,double 变量占8字节
字节对齐的好处
用空间来换时间,提高 cpu 读取数据的效率
堆内存地址从低到高

7.链表
概念:链表是一种物理存储结构上非连续 、非顺序的存储结构,数据元素的逻辑顺序。是通过链表中的指针链接次序实现的 。
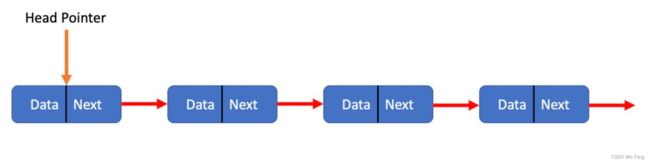
单链表
链表弥补数组的不足,不需要紧密存放,元素通过指针进行排序存放
包含信息域和指针域
- 信息域存储链表节点的内容,指针域指向下一个地址
- 直到最后一个节点指向的指针域为NULL
- head头指针指向第一个节点
定义一个结构体
//创建一个单链表的节点
struct Book {
char title[128];
char author[40];
float price;
struct Book *next;
//结构体指针,该指针指向结构体自身
};
这里我们可以看到数据存储在结构体内,结构体一部分用来存储数据,一部分用指针来存储需要链接的地址。通过这些地址,我们能灵活地查找到其数据位置,从而完成增删查改等功能。
单链表插入元素(头插法)
-
定义结构体头指针指向NULL,判断用户是否要输入新的元素
-
如果需要添加新元素则在堆内存中申请内存空间。将head指针存放的地址赋值给新的链表节点指针域。将head指针指向新的链表节点
如果需要修改头指针的指向,就需要传递头指针的地址,也就是二级指针
如果只是读取链表的内容,只需要传递头指针
#include单链表插入元素(尾插法)
只需修改addBook函数的有书情况下的插法
struct Book *temp;
。。。
if(*library!=NULL){//有书的情况
temp=*library;
while(temp->next!=NULL){//定位 单链表尾部位置
temp=temp->next;
}
//插入数据
temp->next=book;
book->next=NULL;
}
优化 :定义一个指针始终指向尾部,提高效率
//静态变量,生命周期延长到程序停止才结束
static struct Book *tail;
。。。
if(*library!=NULL){//有书的情况
tail->next=book;
book->next=NULL;
}
else{//开始没有书的情况 *library=NULL的情况下添加书
*library=book;//第一个节点指针不是 NULL了是book节点的
book->next=NULL; //next指向下一个节点地址,即NULL
}
//book设置为新的尾部
tail=book;
搜索单链表(遍历)
struct Book *searchBook(struct Book *library,char *target){
struct Book *book;
book=library;
while(book!=NULL){
if(!strcmp(book->title,target)||!strcmp(book->author,target)){//strcmp相等返回0 。需要string.h
break;
}
book=book->next;
}
return book;
}
void printBook(struct Book *book){
printf("书名:%s",book->title);
printf("作者:%s",book->author);
}
int main(){
。。。
char input[128];
struct Book *book;
。。。
printf("请输入查找的书名或作者") ;
scanf("%s",input);
book=searchBook(library,input);
if(book==NULL)
{
printf("很抱歉,未找到");
}
else{
do{
printf("已找到符合条件的图书...");
printBook(book);
}while((book =searchBook(book->next,input))!=NULL);//多本图书都匹配的话可以重复找
}
。。。
}
单链表插入节点(中间插入)
#include单链表删除节点
void deleteNode(struct Node **head,int value){
struct Node *previous;
struct Node *current;
current = *head;
previous=NULL;
while(current!=NULL&¤t->value!=value){
previous=current;
current=current->next;
}
if(current==NULL){
printf("找不到匹配的节点");
return;
}
else{
if(previous==NULL){
*head=current->next;
}
else{
previous->next=current->next;
}
free(current);
}
//main函数修改
printf("开始测试删除整数。。。\n");
while(1){
printf("请输入一个整数(输入-1表示结束):");
scanf("%d",&input);
if(input==-1){
break;
}
deleteNode(&head,input);
printNode(head);
}
8.位域
单片机 集成电路芯片,把CPU、RAM、ROM、I/O等集成到一块硅片上构成小而完善的微型计算机系统。
位域,位段,位字段的提出是为了节约空间
对一个字节划分为几个部分并命名,这几部分就是位域
使用位域的做法是 在结构体定义时,在结构体或成员后面使用冒号和数字来表示该成员所占的位byte数。
位域设置的坑位要大于能够存储的数字所需要的坑位,例如存储数字2,需要定义两个比特位去存储。
#include无名位域
位域成员可以没有名称,只要给出数据类型和宽度即可。 为了填充和调整成员位置
struct Test{
unsigned int x:100;
unsigned int :100//位域成员可以没有名称,只要给出数据类型和宽度即可。
}
七. 共用体
联合类型或联合体
共用体常用来节省内存,特别是一些嵌入式编程
共用体也常用于操作系统数据结构或硬件数据结构!
union 在操作系统底层的代码中用的比较多,因为它在内存共享布局上方便且直观。所以网络编程,协议分析,内核代码上有一些用到 union 都比较好懂,简化了设计。
共用体(union)是一种数据格式,它能够存储不同类型的数据,但是只能同时存储其中的一种类型。
几个不同的变量共同占用一段内存的结构,在C语言中,被称作“共用体”类型结构共用体所有成员占有同一段地址空间 ,共用体的大小是其占内存长度最大的成员的大小,也会受内存对齐影响
共用体和结构体类似,也是一种构造类型的数据结构。把 struct 改成 union 就可以了。
typedef struct {
char name[100];
int score;
}stu;
typedef struct {
char name[100];
int salary;
}tea;
typedef union
{
stu student;
tea teacher;
} any;
共用体的特点:
1、同一内存段可以用来存放几种不同类型的成员,但每一瞬时只有一种起作用
2、共用体变量中起作用的成员是最后一次存放的成员,在存入一个新的成员后原有的成员的值会被覆盖
3、共用体变量的地址和它的各成员的地址都是同一地址
代码实例:
#include初始化共用体
-
union data a={520};//初始化第一个成员
-
union data b=a;//使用一个共用体初始化另一个
-
union data c={.ch=‘c’};//C99新特性,指定初始化成员
八. 枚举
用途:定义一个取值受限制的整型变量,用于限制变量取值范围;
如果一个变量只有几种可能的值,那么就可以将其定义为枚举(enumeration)类型
枚举类型类似于宏定义的集合
将变量的值一一列举出来,变量的值只限于列举出来的值的范围内
enum 枚举类型名 { 枚举值列表; };
在枚举值表中应列出所有可用值,也称为枚举元素
枚举元素是常量,默认是从 0 开始编号的,也可以指定值,后面的会依次自动加1。
枚举常量的值定义后不能再修改
enum TYPE { STU = 1, TEA };
enum TYPE type;
//条件判断语句
if (type == STU) {
//......
}
例如在stm32中
typedef enum {
DISABLE = 0,
ENABLE = !DISABLE
} FunctionalState;
FunctionalState a;
a = ENABLE;
注意:
-
宏定义是一个值/表达式,不是一种类型
-
枚举是一种类型,可以定义枚举类型的一个变量
九.位运算
c语言并没有规定一个字节有几位(一般是8位),只是规定“可寻址的数据存储单位,其尺寸必须可以容纳运行环境的基本字符集的任何成员”。一般是由编译器规定在limits.h中
1.原码反码补码
正数在内存中以原码形式存放,负数在内存中以补码形式存放
正数的 原码=反码=补码
原码:将一个整数,转换成二进制,就是其原码。 如单字节的 5 的原码为:0000 0101;-5 的原码为 1000 0101。
反码:正数的反码就是其原码;负数的反码是将原码中,除符号位以外,每一位取反。如单字节的 5 的反码为:0000 0101;-5 的反码为 1111 1010。
补码:正数的补码就是其原码;负数的反码+1 就是补码。 如单字节的 5 的补码为:0000 0101;-5 的补码为 1111 1011。
- 计算机通过补码的形式存放整数的值,不论正数还是负数
- 补码例子:
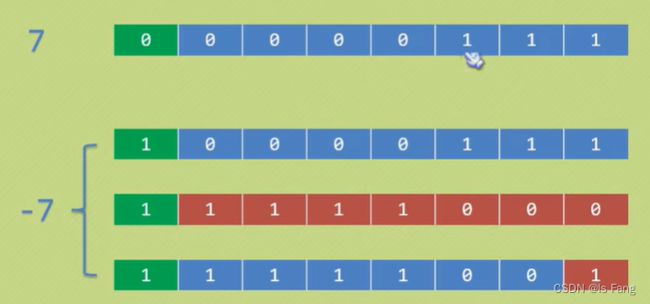
-
对于正数,补码是该数的二进制形式
-
对于负数,补码需要通过以下几个步骤活动
-
- 首先获取该数的绝对值的二进制【除符号位以外,每一位取反】
-
- 将第一步的值按位取反
-
- 最后是将第二步的值加一
-
-
规律:
-
当符号位为0的时候,后面的1越多则越大
-
当符号位为1的时候,后面的0越多越大
-
-
2.位运算
无论是正数还是负数【只作用于整型数据】,编译系统都是按照内存中存储的内容进行位运算。
-
&按位 与
任何值与 0 得 0,与 1 保持不变
-
|按位 或
任何值或 1 得 1,或 0 保持不变
-
~ 按位取反
1 变 0,0 变 1
-
^ 按位异或
相异得 1,相同得 0
-
位移
>>右移 << 左移
左移位运算符和右移位运算符:移出的数据扔掉,移动后空位用0填充
可以和赋值号结合,简写
将一个无符号的整数按位左移n位表示乘以2的n次幂
将一个无符号的整数按位右移n位表示除以2的n次幂
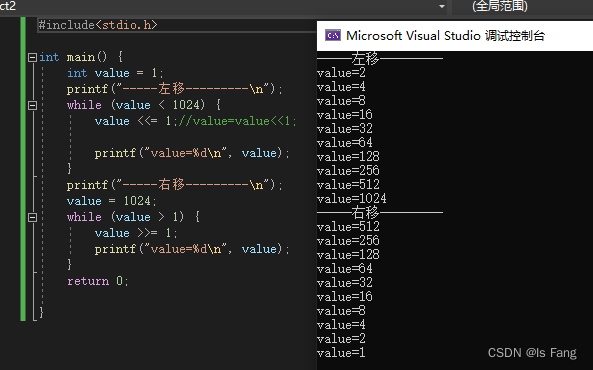
注意:
-
和赋值号=结合,除了按位取反都可以和赋值号结合,便于简写
-
用二进制的形式打印用x%
-
移位运算符右操作数如果是负数,或右操作数大于左操作数支持的最大宽度,那么表达式结果均属于“未定义行为”。不同编译器结果不同。
-
有符号和无符号也对移位运算符有不同的影响。有符号数移动后是否覆盖符号位决定权还是在编译器。
3.位运算符的应用
-
掩码
- 子网掩码:与TCP、IP协议的设置有关
-
linux驱动编写
十.预处理
- 预编译
将.c 中的头文件展开、宏展开 生成的文件是.i 文件
- 编译
将预处理之后的.i 文件生成 .s 汇编文件
- 汇编
将.s 汇编文件生成.o 目标文件
- 链接
将.o 文件链接成目标文件
- 执行
预处理包含三种:宏定义,文件包含和条件编译。
1.宏定义define
定义宏用 define 去定义, 宏是在预编译的时候进行替换,编译器不会对宏定义进行语法检查。
为了和普通的变量进行区分,宏的名字通常我们约定是全部由大写字母组成
宏定义不是说明或语句,在末尾不必加分号
宏定义的作用域是从定义的位置开始到整个程序结束,可以用#undef来终止宏定义的作用域
(1) 不带参宏
#define PI 3.1415
在预编译的时候如果代码中出现了 PI 就用 3.1415 去替换。
宏定义允许嵌套
#define PI 3.14
#define R 6371
#define V PI*R*R*R*4/3
(2) 带参宏
#define MAX(a,b) (a>b?a:b)
将来在预处理的时候替换成 实参替代字符串的形参,其他字符保留
作用类似于函数,但是不需要像函数一样定义类型,在预定义阶段操作,而不是在编译阶段(函数处理的位置)
代码实例:
#include带参宏和带参函数的区别
-
带参宏,被调用多少次就会展开多少次,执行代码的时候没有函数调用的过程,不需要压栈弹栈。所以带参宏,是浪费了空间,因为被展开多次,节省时间。
-
带参函数,代码只有一份,存在代码段,调用的时候去代码段取指令,调用的时候要,压栈弹栈。有个调用的过程。 所以说,带参函数是浪费了时间,节省了空间。
-
带参函数的形参是有类型的,带参宏的形参没有类型名。
#和##两个预处理运算符
在带参数的宏定义中,#运算符后面应该跟一个参数,预处理会把这个参数转化为一个字符串。
#include会把多个空格转化为一个空格
#include##运算符被称为记号连接运算符,比如我们可以使用##运算符连接两个参数
#include可变参数
带参数的宏定义也可以使用可变参数
#define SHOWLIST(…) printf(#VA_ARGS)
其中…表示使用可变参数 ,#表示将后面的参数变为字符串,__VA_ARGS__在预处理中被实际的参数集所替换(就像参数列表)(两边是两个下划线哦)。
#include可变参数允许空参数
#includetypedef
typedef基本功能
- 给数据类型起别名,可以取多个别名,简化一些比较复杂的类型声明。
与#define语法相反,
- typedef 被替换 替换
- #define 替换 被替换
本质是不一样
- 宏定义是直接替换,加类型限定符可以
- typedef是对类型的封装,给原来的数据类型起别名,可以对指针类型起别名
typedef int INTEGER;
typedef int *PTRINT;//别名,带指针
# define PTRINT int*
//相当于int* b,c,此时c不是指针变量
int main(void){
INTEGER a = 520;
PTRINT b,c;
b = &a;
c = b;
printf(%p,c);
}
2.选择性编译
(1)
#ifdef KERWIN
代码段一
#else
代码段二
#endif
(2)
#ifndef KERWIN
代码段一
#else
代码段二
#endif
(3)
#if KERWIN==1
代码段一
#elif KERWIN==2
代码段二
#else
代码段三
#endif
在较大程序调试中常用。防止重复定义某些常量。如果某个常量没有被定义则定义,已经定义的话就忽略。这样不会产生错误。
注意和 if else 语句的区别
-
if else 语句都会被编译,通过条件选择性执行代码
-
选择性编译,只有一块代码被编译
3.文件包含
由来:文件包含处理在程序开发中会给我们的模块化程序设计带来很大的好处,通过文件包含的方法把程序中的各个功能模块联系起来是模块化程序设计中的一种非常有利的手段。
定义:文件包含处理是指在一个源文件中,通过文件包含命令将另一个源文件的内容全部包含在此文件中。在源文件编译时,连同被包含进来的文件一同编译,生成目标目标文件。
文件包含的处理方法:
- (1) 处理时间:文件包含也是以"#"开头来写的(#include ), 那么它就是写给预处理器来看了, 也就是说文件包含是会在编译预处理阶段进行处理的。
- (2) 处理方法:在预处理阶段,系统自动对#include命令进行处理,具体做法是:将包含文件的内容复制到包含语句(#include )处,得到新的文件,然后再对这个新的文件进行编译。
其一般形式为:
- #include " 文件名" 或 #include <文件名>
- 使用尖括号< >和双引号" "的区别在于头文件的搜索路径不同:
- 使用尖括号< >,编译器会到系统路径下查找头文件;
- 而使用双引号" ",编译器首先在当前目录下查找头文件,如果没有找到,再到系统路径下查找。
- 我们自己编写的文件头文件,只能使用双引号引入,而不能使用尖括号引入。而系统自带的头文件则两者都可以使用。
十一.文件
1.初识文件
文件用来存放程序、文档、音频、视频数据、图片等数据的。
文件就是存放在磁盘上的,一些数据的集合。
磁盘文件: 指一组相关数据的有序集合,通常存储在外部介质(如磁盘)上,使用时才调入内存。
设备文件:在操作系统中把每一个与主机相连的输入、输出设备看作是一个文件,把它们的输入、输出等同于对磁盘文件的读和写。
键盘:标准输入文件
屏幕:标准输出文件
其它设备:打印机、触摸屏、摄像头、音箱等
2.标准 io 库函数对磁盘文件的读取
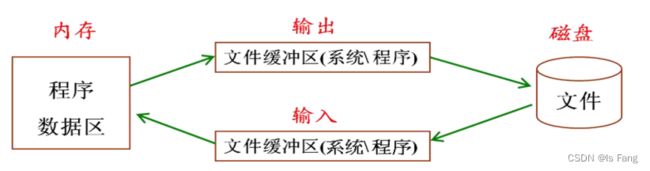
文件缓冲区是库函数申请的一段内存,由库函数对其进行操作,程序员没有必要知道存放在哪里,只需要知道对文件操作的时候的一些缓冲特点即可。
往文件里面写入数据需要fclose,因为还在缓冲区,还没写入文件。关闭文件才将数据写入文件,释放缓冲区 。【fflush函数刷新缓冲区】
和内存池原理类似
标准IO提供三种类型的缓冲模式
-
按块缓存 也称为全缓存,在填满缓冲区后才进行实际的设备读写操作;
-
按行缓存 是指在接收到换行符\n之前,数据都是先缓存在缓冲区的;
-
不缓存 允许直接读写设备上的数据
setvbuf函数
用于设定文件流的缓冲区
int setvbuf(FILE *stream, char *buffer, int mode, size_t size)
-
参数
-
stream – 这是指向 FILE 对象的指针,该 FILE 对象标识了一个打开的流。
-
buf 这是分配给用户的缓冲。如果设置为 NULL,该函数会自动分配一个指定大小的缓冲。
-
mode 三种模式
- _IOFBF(满缓冲):当缓冲区为空时,从流读入数据。或者当缓冲区满时,向流写入数 据。
- _IOLBF(行缓冲):每次从流中读入一行数据或向流中写入一行数据。
- _IONBF(无缓冲):直接从流中读入数据或直接向流中写入数据,而没有缓冲区。
-
size 这是缓冲的大小,以字节为单位
-
-
返回值
如果成功,则该函数返回 0,否则返回非零值。
#include3.磁盘文件的分类
一个文件通常是磁盘上一段命名的存储区 ,计算机的存储在物理上是二进制的,所以物理上所有的磁盘文件本质上都是一样的:以字节为单位进行顺序存储.
从用户或者操作系统使用的角度把文件分为:
-
文本文件:基于字符编码的文件
-
二进制文件:基于值编码的文件【通常指除了文本文件以外的】
- 严格来说,文本文件也属于二进制文件,只不过他存放的是相应的字符编码值。
注意:
- 打开方式要区分开主要是因为换行符。C语言换行符\n,unix系统\n,windows用\r\n,mac用\r。如果在windows系统以文本文件打开,读会将\r\n自动转换为\n,写会\n转换为\r\n,但是以二进制模式打开则不会做转换。如果在unix系统二者是一样的。
译码:
文本文件编码基于字符定长,译码容易些;
二进制文件编码是变长的,译码难一些(不同的二进制文件格式,有不同的译码方式,一般需要特定软件进行译码)。
空间利用率
二进制文件用一个比特来代表一个意思(位操作);
而文本文件任何一个意思至少是一个字符。
所以二进制文件,空间利用率高。
可读性:
文本文件用通用的记事本工具就几乎可以浏览所有文本文件
二进制文件需要一个具体的文件解码器
4.标准流
文件流包含:(文件指针)
-
标准输入stdin
-
标准输出stdout
-
标准错误输出stderr
如何区分标准流和标准错误输出
- 使用重定向区分标准输出流和标准错误输出
4.指示器
每个流里面都有两个指示器
- 文件结束指示器,
- 错误指示器
错误指示器ferror
ferror(结构体指针);返回布尔值 0或1
使用clearerr函数可以人为的清除文件末尾指示器和错误指示器状态
clearerr(结构体指针);
ferror函数只能检测是否出错,但无法获取错误原因。
不过,大多数系统函数在出现错误时会将错误原因就在errno中。引入error.h头文件
da
#include perror函数可以直观的打印出错误原因。会自己加"冒号空格错误原因"。例如perror(“错误原因是”);输出为"错误原因是: Bad file descriptor"
if ((fp = fopen("score.txt", "r")) == NULL)
{
perror("错误原因是");
//只需要一个参数,就是字符串,打印需要说的内容
}
strerror函数直接返回错误码对应的错误消息。
#include 4.文件指针
文件指针在程序中用来标识(代表)一个文件的,在打开文件的时候得到文件指针,文件指针就用来代表咱们打开的文件。
FILE * 指针变量标识符;
typedef struct _iobuf {
int cnt; // 剩余的字符,如果是输入缓冲区,那么就表示缓冲区中还有多少个字符未被读取
char *ptr; // 下一个要被读取的字符的地址
char *base; // 缓冲区基地址
int flag; // 读写状态标志位
int fd; // 文件描述符
// 其他成员
} FILE;
在缓冲文件系统中,每个被使用的文件都要在内存中开辟一块 FILE 类型的区域,存放与操作文件相关的信息
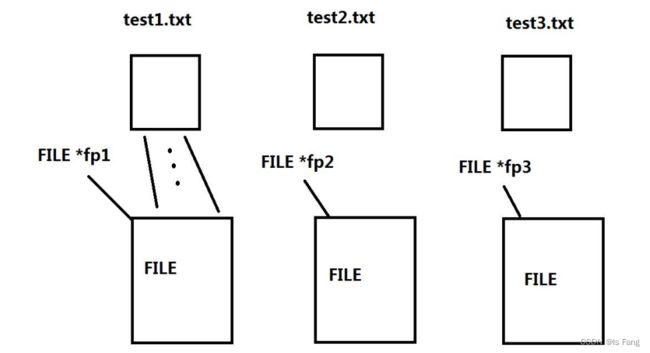
对文件操作的步骤:
1、对文件进行读写等操作之前要打开文件得到文件指针
2、可以通过文件指针对文件进行读写等操作
3、读写等操作完毕后,要关闭文件,关闭文件后,就不能再通过此文件指针操作文件了
5.fopen
FILE *fopen(const char *path, const char *mode);
函数的参数:
- 参数 1:打开的文件的路径【路径参数可以是相对路径(./a.txt),也可以是绝对路径(/home/user1/a.txt)。如果只给出文件名(a.txt)则表示该文件在当前文件夹。 】
- 参数 2:文件打开的方式,即以什么样的方式 r w a +
模式参数 :
“r”
- 以只读的模式打开一个文本文件,从文件头开始读取
- 该文本文件必须存在
“w”
- 以只写的模式打开一个文本文件,从文件头开始写入
- 如果文件不存在则创建一个新的文件
- 如果文件已存在则将文件的长度截断为 0(重新写入的内容将覆盖原有的所有内容)
“a”
- 以追加的模式打开一个文本文件,从文件末尾追加内容
- 如果文件不存在则创建一个新的文件
“r+”
- 以读和写的模式打开一个文本文件,从文件头开始读取和写入
- 该文件必须存在
- 该模式不会将文件的长度截断为 0(只覆盖重新写入的内容,原有的内容保留)
“w+”
- 以读和写的模式打开一个文本文件,从文件头开始读取和写入
- 如果文件不存在则创建一个新的文件
- 如果文件已存在则将文件的长度截断为 0(重新写入的内容将覆盖原有的所有内容)
“a+”
- 以读和追加的模式打开一个文本文件
- 如果文件不存在则创建一个新的文件
- 读取是从文件头开始,而写入则是在文件末尾追加
“b”
- 与上面 6 中模式均可结合(“rb”, “wb”, “ab”, “r+b”, “w+b”, “a+b”)
- 其描述的含义一样,只不过操作的对象是二进制文件 【主要是换行符的问题】
返回值:
- 成功:打开的文件对应的文件指针
- 失败:返回 NULL
6.fclose
int fclose(FILE *fp);
关闭 fp 所代表的文件
返回值:
- 成功返回 0
- 失败返回非 0
7. fgetc 与 fputc
int fgetc(FILE *stream);
stream参数是FILE对象的指针,指定一个待读取的文件流
fgetc 从 stream 所标识的文件中读取一个字节,将字节值返回,并推进文件的位置指示器,用于指向下一个字符的位置
返回值: 如果到达文件尾或者发生错误时返回EOF.
EOF 是在 stdio.h 文件中定义的符号常量,值为-1
关于fgetc 函数和 getc 函数:两个的功能和描述基本上是一模一样的,它们的区别主要在于实现上:fgetc 是一个函数;而 getc 则是一个宏的实现。一般来说宏产生较大的代码,但是避免了函数调用的堆栈操作,所以速度会比较快。【类似于宏定义带参数和函数的区别】
int fputc(int c, FILE *stream)
fputc 将一个字符写入指定的文件中并推进文件的位置指示器
参数:
- c 指定待写入的字符
- stream 该参数是一个 FILE 对象的指针,指定一个待写入的文件流
返回值:
- 如果输出成功,则返回输出的字节值;
- 如果输出失败,则返回一个 EOF。
fputc 是一个函数;而 putc 则是一个宏的实现
#include8. fgets 与 fputs
char *fgets(char *s, int size, FILE *stream);
- s 字符型指针,指向用于存放读取字符串的位置
- size 指定读取的字符数(包括最后自动添加的 '\0')
- stream 该参数是一个 FILE 对象的指针,指定一个待操作的数据流
-
用于从指定文件中读取字符串。
-
fgets 函数最多可以读取 size - 1 个字符,因为结尾处会自动添加一个字符串结束符 ‘\0’。当读取到换行符(‘\n’)或文件结束符(EOF)时,表示结束读取(‘\n’ 会被作为一个合法的字符读取,EOF不会)。
返回值:
-
如果函数调用成功,返回 s 参数指向的地址。
-
如果在读取字符的过程中遇到 EOF,则 eof 指示器被设置;如果还没读入任何字符就遇到这种 EOF,则 s 参数指向的位置保持原来的内容(s不变),函数返回 NULL。
-
如果在读取的过程中发生错误,则 error 指示器被设置,函数返回 NULL,但 s 参数指向的内容可能被改变。
int fputs(const char *s, FILE *stream);
- s 字符型指针,指向用于存放待写入字符串的位置
- stream 该参数是一个 FILE 对象的指针,指定一个待操作的数据流
- 用于将一个字符串写入到指定的文件中,表示字符串结尾的 ‘\0’ 不会被一并写入。
返回值:
-
如果函数调用成功,返回一个非 0 值;(此处错误。API文档里是成功时返回非负值, 失败时返回EOF)
-
如果函数调用失败,返回EOF
#include9.fread
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
- ptr 指向存放数据的内存块指针,该内存块的尺寸最小应该是 size * nmemb 个字节
- size 指定要读取的每个元素的尺寸,最终尺寸等于 size * nmemb
- nmemb 指定要读取的元素个数,最终尺寸等于 size * nmemb
- stream 该参数是一个 FILE 对象的指针,指定一个待读取的文件流
fread 函数从 stream 所标识的文件中读取数据,每块是 size 个字节,共nmemb 块,存放到ptr 指向的内存里
返回值:
-
返回值是实际读取到的元素个数(nmemb);
-
如果返回值比 nmemb 参数的值小,表示可能读取到文件末尾或者有错误发生(可以使用 feof 函数或 ferror 函数进一步判断)。
10.fwrite
size_t fwrite(void *ptr, size_t size, size_t nmemb, FILE *stream);
- ptr 指向存放数据的内存块指针,该内存块的尺寸最小应该是 size * nmemb 个字节
- size 指定要写入的每个元素的尺寸,最终尺寸等于 size * nmemb
- nmemb 指定要写入的元素个数,最终尺寸等于 size * nmemb
- stream 该参数是一个 FILE 对象的指针,指定一个待写入的文件流
fwrite 函数将 ptr 指向的内存里的数据,向 stream 所标识的文件中写入数据,每块是size 个字节,共nmemb 块。
返回值:
-
返回值是实际写入到文件中的元素个数(nmemb);
-
如果返回值与 nmemb 参数的值不同,则有错误发生。
11.rewind
rewind 复位读写位置
void rewind(文件指针);
把文件内部的位置指针移到文件首
在rewind函数后面执行插入数据的函数,会把原来的内容覆盖掉
12. fseek
fseek用于设置文件流的位置指示器
int fseek(FILE *stream, long offset, int whence);
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
- offset -- 这是相对 whence 的偏移量,以字节为单位。
- whence -- 这是表示开始添加偏移 offset 的位置。
移动文件流的读写位置.
whence 起始位置
-
文件开头 SEEK_SET 0
-
文件当前位置 SEEK_CUR 1
-
文件末尾 SEEK_END 2
返回值:如果成功,则该函数返回零,否则返回非零值。
位移量: 以起始点为基点,向前、后移动的字节数,正数往文件末尾方向偏移,负数往文件开头方向偏移。
#include 可移植性问题
-
对于以二进制模式打开的文件,fseek在某些操作系统中可能不支持SEEK_END位置。
-
对于以文本模式打开的文件,feek函数的whence参数只能取SEEK_SET才是有意义的,并且传递给offset参数的值要么是0,要么是上一次对同一个文件调用ftell函数获取的返回值。
13.feof
用于检测文件的末尾指示器(end-of-file indicator)是否被设置。
int feof(FILE *stream);
- stream 该参数是一个 FILE 对象的指针,指定一个待检测的文件流
返回值:
-
如果检测到末尾指示器(end-of-file indicator)被设置,返回一个非 0 值;
-
如果检测不到末尾指示器(end-of-file indicator)被设置,返回值为 0。
-
feof 函数仅检测末尾指示器的值,它们并不会修改文件的位置指示器。
-
文件末尾指示器只能使用 clearerr 函数清除。
代码实例:
#include 14.ftell
测文件读写位置距文件开始有多少个字节
位置指示器用于指定读取和写入的位置
long ftell(文件指针);
返回值: 返回当前读写位置(距离文件起始的字节数),出错时返回-1.
long int length;
length = ftell(fp)
printf("%ld\n",length)
15.fscanf、fprintf
格式化读写文件
和scanf、printf相似【但是是从终端读写文件】,只不过是从文件读取、输出到文件,并且多了一个参数,该参数是指针
拓展 为什么scanf中用&取地址符,而printf不用。因为scanf本来就是一个函数,用取地址后就能将接受的数据存在这个地址里,在scanf函数外也能用。指针在函数内就是通过访问所指向地址的值来进行改写,并且能延续到函数外。
#include 十二. 第三方库
C语言的Math库
c语言标准库详解(十四):时间函数time.h
#include