蜂鸟E203学习笔记(四)——取指
1.1 取值概述
1.1.1 如何快速取指
首先要保证存储器的读延时足够小,通常使用指令紧耦合存储器(ITCM)和指令缓存器(ICache)。
- ITCM通常使用离处理核很近的SRAM因此实现极短的延时。但是没有过大的存储空间,只能存放大小有限的关键指令。
- 指令缓存是指利用软件程序的时间局部性和空间局部性,将容量巨大的外部指令存储器空间动态映射到容量有限的指令缓冲中,将访问指令存储器的平均延迟降低到最低。但是指令缓存的容量有限,存在着不确定性有可能会缓存不命中(cache miss)此时需要从外部存储器中存取数据造成较大延迟。
1.1.2 如何处理地址不对齐的指令
如果处理器在每一个时钟周期都能够取一个指令,就可以源源不断地为处理器提供后续指令流,而不会出现空闲的时钟。但是不论是从ITCM还是从指令cache中都是使用的SRAM,端口往往是固定长度的。
- 普通指令的地址不对齐
对于普通指令按顺序取指(地址连续增长)的情形,使用剩余缓冲区保存上次取指令后没有用完的位,供下次使用。假设从ITCM中取出一个32位的指令但是只用了低16位,有可能是和上一次取出的高16位组成一个真正的指令,也有可能指令就是16位的。此次没有使用到的高16位可以暂存在剩余缓冲区内待下一个时钟周期直接拼接。 - 分支跳转指令的地址不对齐
如果跳转的地址与32位不对齐,且需要取值32位的指令,那么使用两个SRAM,指令字存在两个SRAM中,然后通过拼接获得指令。
1.1.3 如何处理分支指令
首先介绍一下RISC架构处理器的分支指令架构
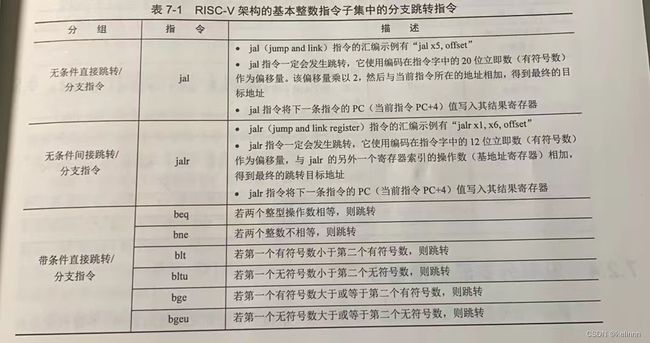
(1)无条件跳转/分支(unconditional jump/branch)指令
不需要判断条件一定会发生的跳转指令,按照跳转的目标地址计算方式,可以分为以下两种。
- 无条件直接跳转,如jal,'jal x5, offset’20位有符号立即数乘2作为偏移量。
- 无条件间接跳转,如jalr 'jalr x1, x6, offset’12位有符号立即数与基地址相加
(2)有条件跳转/分支指令
- 带条件直接跳转,“直接”是指跳转的目标地址可以从指令编码中的立即数直接计算,以RISC-V为例它有6条,这种指令和普通的运算指令一样直接使用两个整型操作数,然后对其比较。条件满足则发生跳转。
- 带条件间接跳转,跳转的目标地址需要根据寄存器索引的操作数中计算得到,RISC-V没有相关的指令。
需要注意的是,带条件的跳转指令只有等到执行阶段之后才能够解析出最终的跳转结果。这样的话会造成大量的流水线空泡周期,从而影响性能。为了提高性能一般会采用分支预测(branch prediction),需要解决两个方面的问题
- 预测分支指令是否真的需要跳转?即预测的“方向”
- 跳转的目标地址是什么?即预测的“地址”
使用预测的方向和地址及逆行取值称为预测取值。
根据指令进行执行叫做预测执行。
1.1.3 预测方向
主要分为静态预测和动态预测
静态预测方法
最简单的静态预测方法是总预测分支指令不会发生跳转。因此,取指指令总是顺序取分支指令的下一条指令。在执行阶段之后如果发现要进行跳转则会冲刷流水线,重新进行取指。为了弥补冲刷流水线造成的性能损失,很多早期的RISC架构采用了分支延迟槽。
- BTFN预测:向后的预测为跳,向前的预测为不跳。
动态预测方法:依赖已经执行过的指令的历史信息和分支指令本身的信息综合进行“方向”预测。
- 最简单的动态预测为一位饱和计数器,机制是每次分支指令执行之后纪录方向,下一次预测的方向就是这个方向。
- 两位饱和计数器是最常见的分支方向动态预测器。每次预测错会改变状态,有一定的切换缓冲。
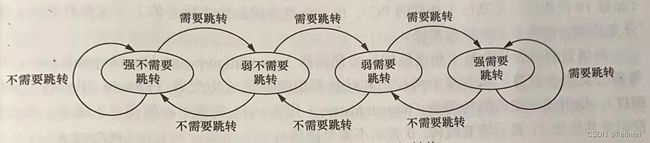
最理想的情况是为每一条分支指令都分配专有的2位饱和计数器,但是硬件开销巨大,所以会使用把有限个计数器组织成表格。不可避免会出现别名重合,不同的分支指令指向相同的饱和计数器。
最简单的索引就是把PC后10位进行,形成1维表格。
两级预测器也成为**基于相关性的分支预测器**。
两级预测器对每条分支指令而言,将有限个两位饱和计数器组织成模式历史表,使用该分支的跳转历史作为PHT的索引。分支历史又可以分为局部分支历史和全局分支历史。
- 局部分支预测器会使用分立的局部历史缓冲器,同时有自己的PHT
- 全局分支预测器的弊端在于无法区分不同指令的跳转历史,在PHT容量大的时候效果比较好。最具代表性的全局分支预测器算法是Gshare和Gselect
1.1.4 预测地址
1、分支目标缓存区(Branch Target Buffer0,BTB)技术是指使用容量有限的缓冲区保存最近执行过的分支指令的PC之,以及他们的跳转坐标。比较PC指判断是否跳转,并且直接跳转这个地址。
缺点:
- BTB的容量不能太大
- 对于间接跳转指令不太理想,因为地址是计算得到的。
2、返回地址栈(Return Address Stack, RAS)技术是指使用容量有限的硬件栈(先入后出)来存储函数调用的返回地址。
3、间接BTB技术是专门为间接跳转指令设计的,通过高级的索引方法进行匹配,结合了BTB和两级预测器,但是缺点是硬件开销较大,适用于高级处理器。
1.2 RISC-V架构特点对于取指的简化
- 规整的指令编码格式
- 指令长度指示码放于低位
- 简单的分支跳转指令
- 没有 分支延迟槽指令
- 提供明确的静态分支预测依据
- 提供明确的RAS依据
1.2.1 规整的指令编码格式
RISC-V的指令集十分规整,可以非常便捷地译码
1.2.2 指令长度指示码放于低位
相对于E压缩指令集混合使用而说的,假如使用RV32I的话最低两位为11可以忽略。
1.1.3 简单的分支跳转指令
jal和jalr配合可以实现函数的调用和返回。
1.1.4 没有分支延迟槽
由于现代的高性能处理器的分支预测算法的精度很高所以放弃了delay slot,得大于失
1.1.5 提供明确的静态分支预测依据
RISC-V架构文档明确规定,编译器生成的代码应该尽量优化使得,向后跳转的概率大于向前跳转指令的概率
1.1.6 提供明确的RAS依据
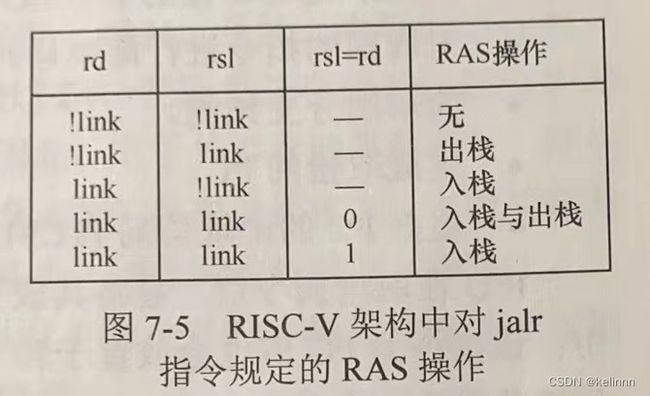
架构规定,如果使用jal指令且目标寄存器索引值rd等于x1寄存器的值或者x5寄存器的值则需要入栈,jalr通过rd和rs1的不同规定了入栈出栈
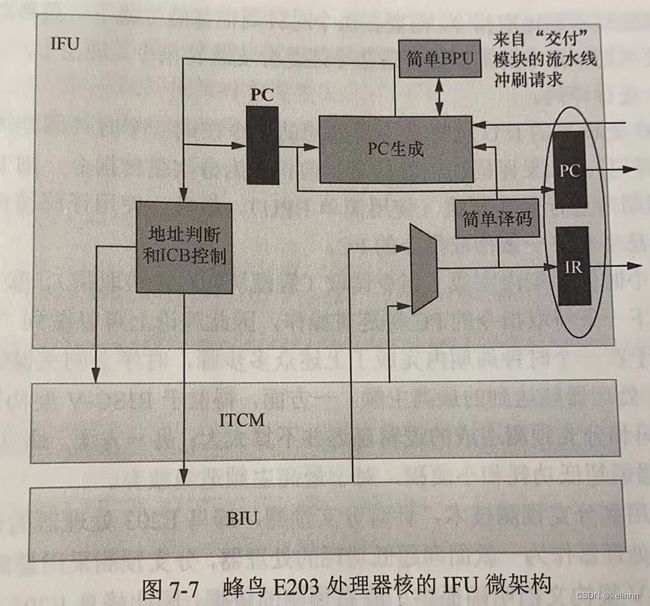
1.3 蜂鸟E203处理器的取指实现
画圈为取指子系统,主要包括取指令单元IFU和ITCM。

1.3.1 IFU总体设计思路
主要包括以下功能
- 对取回的指令进行简单译码
- 简单的分支预测
- 生成取指的PC
- 根据PC的地址访问ITCM或BIUU(地址判断和ICB控制)
IFU取出指令后放到和EX相连的指令寄存器(Insteuction Register, IR)中,同时PC也会放到PC寄存器中。
取指令要“快”和“连续不断”
针对快:
- 取指绝大部分发生在ITCM中以满足实时性的要求。
- ITCM使用单周期SRAM,一个周期就可以取一条指令
- 对于某些必须从外部存储器读取的指令(如系统上电后的引导程序可能从外部闪存中),此时IFU通过BIU使用系统存储接口访问外部的存储器
针对连续不断:
- 每个时钟周期都能生成下一条PC,这就要求需要判断是普通指令还是分支跳转指令,理论上需要对指令进行译码。如果是分支跳转指令则IFU直接在同一周期内进行分支预测,然后结合以上信息生成下一条待取指令的PC
- 在一个周期完成这么多会有一些逻辑延时,稍微影响最高主频。
1.3.2 简单译码
此处只需要译出IFU所需的部分指令信息,这些信息包括此指令是属于普通指令还是分支跳转指令,分支跳转指令的类型和细节。
调用了完成的译码模块,只不过把不需要的输入指令,不需要的输出悬空。综合工具会优化掉。
/*
Copyright 2018-2020 Nuclei System Technology, Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
//=====================================================================
// Designer : Bob Hu
//
// Description:
// The mini-decode module to decode the instruction in IFU
//
// ====================================================================
`include "e203_defines.v"
module e203_ifu_minidec(
//
// The IR stage to Decoder
input [`E203_INSTR_SIZE-1:0] instr,//取指逻辑取回的指令,作为输入等待译码[31:0]
//
// The Decoded Info-Bus
output dec_rs1en,//解码判断reg-source1是否有效,一条指令的源操作数1和2
output dec_rs2en,
output [`E203_RFIDX_WIDTH-1:0] dec_rs1idx,//也就是说cpu中的寄存器单独编址(即cpu内部总线,独立于系统总线)成一个文件
output [`E203_RFIDX_WIDTH-1:0] dec_rs2idx,//这里的index就是原操作数寄存器在cpu内部总线上的地址
output dec_mulhsu,// mul-high-signed-unsigned rs1有符号,rs2无符号,相乘结果(64bit)的高32bit放入rd
output dec_mul ,// mul rs1无符号,rs2无符号,(有符号无符号其实是一样的)相乘结果(64bit)的低32bit放入rd
output dec_div ,// div rs1有符号,rs2有符号
output dec_rem ,// 取 rs1有符号与rs2有符号数,取余数送到rd;
output dec_divu ,// 无符号取商送rd
output dec_remu ,// 无符号取余送d
output dec_rv32,//表示当前指令是rsic-v32位指令,还是16位指令
output dec_bjp,//表示当前指令是普通指令还是分支跳转指令
output dec_jal,//属于jal指令
output dec_jalr,//数据jalr指令
output dec_bxx,//属于BXX指令,(BEQ,BNE等带条件分支指令)
output [`E203_RFIDX_WIDTH-1:0] dec_jalr_rs1idx,//针对jalr指令,其首先要取出rs1操作数,然后与立即数相加才能得到值+4作为新的pc,为了取rs1,指令里带了rs1的地址(cpu内部index)
output [`E203_XLEN-1:0] dec_bjp_imm //针对bxx指令,如果条件满足的话,会把12bit立即数(有符号)×2然后与pc相加,作为新的pc;这里是译码出的指令的立即数
);
e203_exu_decode u_e203_exu_decode(
.i_instr(instr),
.i_pc(`E203_PC_SIZE'b0),
.i_prdt_taken(1'b0),
.i_muldiv_b2b(1'b0),
.i_misalgn (1'b0),
.i_buserr (1'b0),
.dbg_mode (1'b0),
.dec_misalgn(),
.dec_buserr(),
.dec_ilegl(),
.dec_rs1x0(),
.dec_rs2x0(),
.dec_rs1en(dec_rs1en),
.dec_rs2en(dec_rs2en),
.dec_rdwen(),
.dec_rs1idx(dec_rs1idx),
.dec_rs2idx(dec_rs2idx),
.dec_rdidx(),
.dec_info(),
.dec_imm(),
.dec_pc(),
`ifdef E203_HAS_NICE//{
.dec_nice (),
.nice_xs_off(1'b0),
.nice_cmt_off_ilgl_o(),
`endif//}
.dec_mulhsu(dec_mulhsu),
.dec_mul (dec_mul ),
.dec_div (dec_div ),
.dec_rem (dec_rem ),
.dec_divu (dec_divu ),
.dec_remu (dec_remu ),
.dec_rv32(dec_rv32),
.dec_bjp (dec_bjp ),
.dec_jal (dec_jal ),
.dec_jalr(dec_jalr),
.dec_bxx (dec_bxx ),
.dec_jalr_rs1idx(dec_jalr_rs1idx),
.dec_bjp_imm (dec_bjp_imm )
);
endmodule
1.3.3 简单BPU
主要对取回的指令进行简单译码后发现的分支跳转指令进行简单的静态分支预测。
/*
Copyright 2018-2020 Nuclei System Technology, Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
//=====================================================================
// Designer : Bob Hu
//
// Description:
// The Lite-BPU module to handle very simple branch predication at IFU
//
// ====================================================================
`include "e203_defines.v"
module e203_ifu_litebpu(
// Current PC
input [`E203_PC_SIZE-1:0] pc,//被译码的指令(也就是当前EXU正在执行的指令)对应的pc指针值
// The mini-decoded info
input dec_jal,//从mini-decode模块送过来的,具体的指令译码结果信息,这个信号指示是直接跳转
input dec_jalr,
input dec_bxx,
input [`E203_XLEN-1:0] dec_bjp_imm,//跳转指令的立即数
input [`E203_RFIDX_WIDTH-1:0] dec_jalr_rs1idx,//跳转指令的rs1源操作数的cpu内部地址
// The IR index and OITF status to be used for checking dependency
input oitf_empty,//oitf模块为空的标志,不为空表明有长指令正在运行,用于判断跳转指令跟之前的指令的相关性
input ir_empty,//当前IR寄存器为空
input ir_rs1en,//这个信号源自指令预取模块入口的dec2ifu_rs1en模块,表示的是当前正在执行的指令,其rs1操作数是否有效
input jalr_rs1idx_cam_irrdidx,//jalr指令的rs1的index 和 IR寄存器中rd的index比较,如果相等则为1,//这里是针对jalr指令如果其源操作数rs1和目的操作数rd是同一个寄存器,这样会导致分支预测这里,这条指令本身具有相关性??
// The add op to next-pc adder
output bpu_wait,
output prdt_taken, // 表示分支预测单元的预测结果是否进行跳转
output [`E203_PC_SIZE-1:0] prdt_pc_add_op1, //用于计算PC值的操作数
output [`E203_PC_SIZE-1:0] prdt_pc_add_op2,
input dec_i_valid,// 当前正在执行的指令经解码后发现指令是有效的
// The RS1 to read regfile
output bpu2rf_rs1_ena,// 生成用第一个读端口的使能信号,该信号将加载和IR寄存器位于同一级的rs1索引(index)寄存器,从而读取REGFile
input ir_valid_clr,// 表示当前ir中的内容被clear(// The ir valid is cleared when it is accepted by EXU stage *or* the flush happening )
input [`E203_XLEN-1:0] rf2bpu_x1,// 从regfile直接拉过来的同IR处于同一级的x1的内容
input [`E203_XLEN-1:0] rf2bpu_rs1, // 从regfile的读端口取出来的rs1的内容
input clk,
input rst_n
);
// BPU of E201 utilize very simple static branch prediction logics
// * JAL: The target address of JAL is calculated based on current PC value
// and offset, and JAL is unconditionally always jump
// * JALR with rs1 == x0: The target address of JALR is calculated based on
// x0+offset, and JALR is unconditionally always jump
// * JALR with rs1 = x1: The x1 register value is directly wired from regfile
// when the x1 have no dependency with ongoing instructions by checking
// two conditions:
// ** (1) The OTIF in EXU must be empty
// ** (2) The instruction in IR have no x1 as destination register
// * If there is dependency, then hold up IFU until the dependency is cleared
// * JALR with rs1 != x0 or x1: The target address of JALR need to be resolved
// at EXU stage, hence have to be forced halted, wait the EXU to be
// empty and then read the regfile to grab the value of xN.
// This will exert 1 cycle performance lost for JALR instruction
// * Bxxx: Conditional branch is always predicted as taken if it is backward
// jump, and not-taken if it is forward jump. The target address of JAL
// is calculated based on current PC value and offset
// //解码出来的指令是jal、jalr一定要跳,当为bxx类指令时若最高位符号位为1则说明是负数向后跳转。
assign prdt_taken = (dec_jal | dec_jalr | (dec_bxx & dec_bjp_imm[`E203_XLEN-1]));
// The JALR with rs1 == x1 have dependency or xN have dependency
wire dec_jalr_rs1x0 = (dec_jalr_rs1idx == `E203_RFIDX_WIDTH'd0);//判断rs1的索引是否为x0寄存器的值
wire dec_jalr_rs1x1 = (dec_jalr_rs1idx == `E203_RFIDX_WIDTH'd1);
wire dec_jalr_rs1xn = (~dec_jalr_rs1x0) & (~dec_jalr_rs1x1);
wire jalr_rs1x1_dep = dec_i_valid & dec_jalr & dec_jalr_rs1x1 & ((~oitf_empty) | (jalr_rs1idx_cam_irrdidx));
wire jalr_rs1xn_dep = dec_i_valid & dec_jalr & dec_jalr_rs1xn & ((~oitf_empty) | (~ir_empty));//既要保证没有长指令运行也要保证指令寄存器为空
// If only depend to IR stage (OITF is empty), then if IR is under clearing, or
// it does not use RS1 index, then we can also treat it as non-dependency
wire jalr_rs1xn_dep_ir_clr = (jalr_rs1xn_dep & oitf_empty & (~ir_empty)) & (ir_valid_clr | (~ir_rs1en));//xn相关性、没有长指令运行、指令寄存器非空。。。需要清零
wire rs1xn_rdrf_r;
wire rs1xn_rdrf_set = (~rs1xn_rdrf_r) & dec_i_valid & dec_jalr & dec_jalr_rs1xn & ((~jalr_rs1xn_dep) | jalr_rs1xn_dep_ir_clr);
wire rs1xn_rdrf_clr = rs1xn_rdrf_r;//使得set一个周期高电平
wire rs1xn_rdrf_ena = rs1xn_rdrf_set | rs1xn_rdrf_clr;
wire rs1xn_rdrf_nxt = rs1xn_rdrf_set | (~rs1xn_rdrf_clr);
sirv_gnrl_dfflr #(1) rs1xn_rdrf_dfflrs(rs1xn_rdrf_ena, rs1xn_rdrf_nxt, rs1xn_rdrf_r, clk, rst_n);
assign bpu2rf_rs1_ena = rs1xn_rdrf_set;
assign bpu_wait = jalr_rs1x1_dep | jalr_rs1xn_dep | rs1xn_rdrf_set;//如果存在RAW相关性,则将bpu_wait拉高,将阻止IFU生成写一个PC等待相关性解除,
assign prdt_pc_add_op1 = (dec_bxx | dec_jal) ? pc[`E203_PC_SIZE-1:0]//如果指令是带条件直接跳转指令bxx,便使用它本身的pc当作加法器操作数1
: (dec_jalr & dec_jalr_rs1x0) ? `E203_PC_SIZE'b0//如果是jalr,jalr的rs1是x0的时候op1为0
: (dec_jalr & dec_jalr_rs1x1) ? rf2bpu_x1[`E203_PC_SIZE-1:0]//直接读出来防止EXU写会x1形成RAW相关性
: rf2bpu_rs1[`E203_PC_SIZE-1:0];
assign prdt_pc_add_op2 = dec_bjp_imm[`E203_PC_SIZE-1:0]; //使用立即数表示的偏移量
endmodule
1.3.4 PC生成
复位后的第一次取指采用CPU-TOP输入的pc_rtvec的值确定,如果32位指令顺序取值则自加4,对于分支指令则使用简单的BPU预测的目标地址,如果来自EXU的流水线冲刷,则使用EXU送过来的新PC。
两种指令生成:
wire jalr_rs1xn_dep_ir_clr = (jalr_rs1xn_dep & oitf_empty & (~ir_empty)) & (ir_valid_clr | (~ir_rs1en));//xn相关性、没有长指令运行、指令寄存器非空。。。需要清零
wire rs1xn_rdrf_r;
wire rs1xn_rdrf_set = (~rs1xn_rdrf_r) & dec_i_valid & dec_jalr & dec_jalr_rs1xn & ((~jalr_rs1xn_dep) | jalr_rs1xn_dep_ir_clr);
wire rs1xn_rdrf_clr = rs1xn_rdrf_r;//使得set一个周期高电平
wire rs1xn_rdrf_ena = rs1xn_rdrf_set | rs1xn_rdrf_clr;
wire rs1xn_rdrf_nxt = rs1xn_rdrf_set | (~rs1xn_rdrf_clr);
sirv_gnrl_dfflr #(1) rs1xn_rdrf_dfflrs(rs1xn_rdrf_ena, rs1xn_rdrf_nxt, rs1xn_rdrf_r, clk, rst_n);
这种只是拿set去做了一个判断,所以set带上了输出信号这样可以直接拉低set。
还有一种由两种req控制的命令生成
assign pipe_flush_ack = 1'b1;
wire dly_flush_set;
wire dly_flush_clr;
wire dly_flush_ena;
wire dly_flush_nxt;
// The dly_flush will be set when There is a flush requst is coming, but the ifu is not ready to accept new fetch request
// * There is a flush requst is coming, but the ifu
// is not ready to accept new fetch request
wire dly_flush_r;
assign dly_flush_set = pipe_flush_req & (~ifu_req_hsked);
// The dly_flush_r valid is cleared when The delayed flush is issued
// * The delayed flush is issued
assign dly_flush_clr = dly_flush_r & ifu_req_hsked;
assign dly_flush_ena = dly_flush_set | dly_flush_clr;
assign dly_flush_nxt = dly_flush_set | (~dly_flush_clr);
sirv_gnrl_dfflr #(1) dly_flush_dfflr (dly_flush_ena, dly_flush_nxt, dly_flush_r, clk, rst_n);
wire dly_pipe_flush_req = dly_flush_r;
wire pipe_flush_req_real = pipe_flush_req | dly_pipe_flush_req;
这种最后生成了一种真正的请求信号,set不能直接拉低,这样的话会带来毛刺,所以没有带上输出信号取反,set置高后的时钟上升沿r跟随nxt也置高,当clr置高时,ena置高,上升沿r随nxt置低。之后其他信号都回归。保持住了req信号,等待IFU的请求信号。