【AI绘图】Stable Diffusion WebUI环境搭建
Stable Diffusion WebUI开源地址:https://github.com/AUTOMATIC1111/stable-diffusion-webui
首先根据要求做以下准备工作:
1. 安装 Python 3.10.6, 安装时记得勾选"Add Python to PATH"把Python添加到环境变量.
2. 安装Git环境,Git - Downloading Package
3. 用git命令把下载Stable Diffusion WebUI项目:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git4. 项目下载到本地后双击 webui-user.bat 运行。
webui-user.bat执行后会下载大量依赖环境,不出意外的话应该会输出各种报错,这是因为
很多依赖的库都是从github下载,国内访问github不稳定,即开了魔法上网也经常出下载报错。
这时候就需要使用github加速工具:Releases · dotnetcore/FastGithub · GitHub
5. 下载安装FastGithub, 直接双节打开,在后台挂起。

6. 再次执行步骤4,就开始下载依赖环境了。如果中途仍有报错多执行几遍步骤4即可。
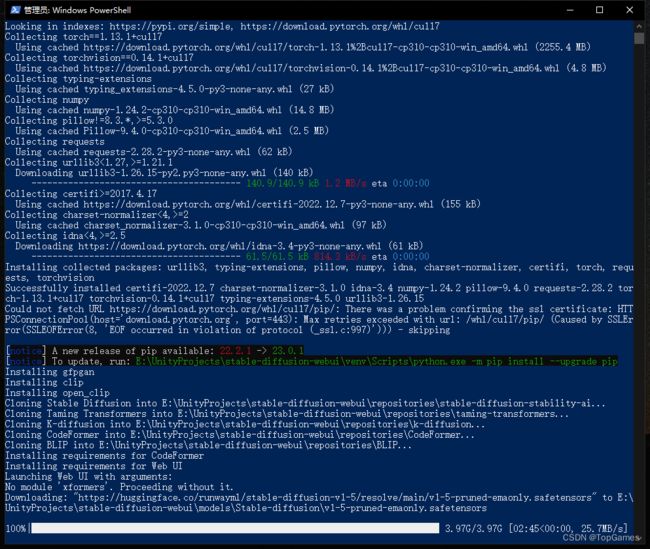
经过漫长的下载,最后命令行可能会出现:No module 'xformers'. Proceeding without it.
不必惊慌,不使用xformers模块也是没问题的。
最后看到Running on local URL: http://127.0.0.1:7860,那么恭喜,环境搭建成功。

7. 运行webui-user.bat会启动一个区域网web服务器,在浏览器输入127.0.0.1:7860打开Stable Diffusion WebUI界面:

Prompt:期望图片包含的元素;
Negative Prompt:不期望图片包含的元素;
然后点击Generate按钮生成图像。
8. 添加扩展插件,上来就用肯定是还差火候的,还需要安装各种插件加强功能才能发挥出真正的实力。添加插件方式:

9. 如果想让局域网的其它电脑也能根据ip打开Stable Diffusion WebUI界面,需要在webui-user.bat文件中,COMMANDLINE_ARGS追加参数”--listen“:
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--listen
call webui.bat
保存后重新运行webui-user.bat其它局域网中的电脑直接通过ip就能使用Stable Diffusion WebUI了。
AI是使用GPU运算,比较吃显卡,当然也可以设置只走CPU运算,那会巨慢。如果显卡比较吃力需要调低生成图像分辨率。
OK, 开始见证奇迹的时刻。
使用的时候会发现,原来提取想要画面的关键词也挺费劲的. 推荐两个关键词获取网站:
Prompt关键词分享网站:
1. https://lexica.art
2. https://arthub.ai
3. Discover and Generate AI Art | OpenArt
随便找个别人分享的Prompt测试,别人生成结果如下:
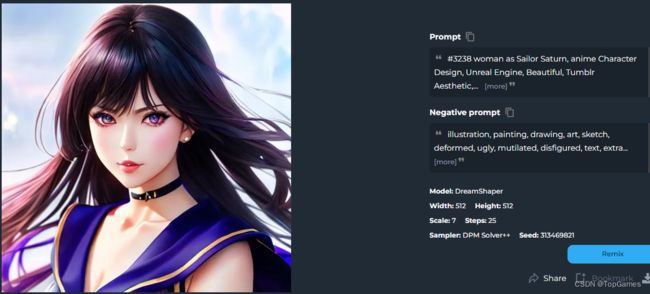
相同参数我的生成结果如下:

差点意思是不是?这是因为我们使用的AI模型不同,Stable Diffusion默认自带一个AI模型:
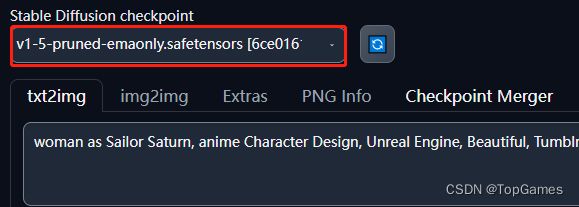
所以为了能让AI更加精确的根据描述生成高质量图像,还需要训练自己的AI模型,或者下载安装别人训练好的AI模型文件。
AI模型下载:
1.https://civitai.com
2. https://huggingface.co
2. Stable Diffusion Models
SD的AI模型有safetensors和ckpt格式,前者顾名思义,更安全。把下载好的模型文件放到stable-diffusion-webui\models\Stable-diffusion目录下,重新启动webui-user.bat,生成图片前选择对应的AI模型就可以得到差别巨大的图像:

使用新的AI模型再次生成图像,欸好像有LSP内味儿了,和原图还差挺远:

换个AI模型再生成一遍, 不能说一模一样,可以说毫无关系:

由此可见,不同AI模型根据不同的图像素材训练,基于不同模型生成的图像也会千差万别。如果AI模型覆盖面不够广泛,就很难根据给出关键词精确生成用户心中所想的画面。
需要不停的修改描述词重新生成,直到出现符合预期的元素,然后通过sd-webui-controlnet插件,把符合预期的区域涂上遮罩,以使下次生成图片时保留标记区域。重复上述步骤,直到生成整体满意的图像。
虽然就目前而言,无论是搭建Stable Diffusion环境,还是提取关键词、通过各种插件辅助生成目标图像,对于美术而言都门槛过高。但AI的更新迭代通常是指数级上升,很快就会更加完善。强烈建议美术们抓紧时间学习使用,紧跟前沿技术。与时俱进的人永远不会被AI取代。