Java 高级/资深/架构 面试题
第1题:什么是内存溢出,什么是内存泄漏?请举例发生场景与解决方案
文案如下 视频讲解链接
内存溢出:
这个一般发生频率较低
内存容量就是个桶 内存就是 水 溢出 就是水满了 你再倒水装不下了
不正常情况:由于你对数据的不熟,或者预见性不足 或者编码经验的不足
while(true)
递归
但是没有很好的终止他们
正常情况:比如说你的对象 太多了 内存不够
比如说我要处理当前方法 要处理十个文件对象的读写 每一个 同时会占用 200M
那么如果你设置给当前应用的内存不够 比如 只有1G
那么就需要调大jvm中 内存设置 或者 减少 同一批次处理大对象 数量
内存泄漏:这个经常发生
就是桶坏了 有洞 水漏出去了
对象的生命周期
一个是方法中 ,成员变量,静态成员变量
比如方法的生命周期
就比 你的成员变量(也就是这个类的对象)的声明周期 短
成员变量 的生命周期又会比你的静态变量 也就是你的应用的生命周期短
class StaticTest
{
private static Vector v = new Vector(10);
private Vector v2 = new Vector(10);
public void init()
{
Vector v3;
for (int i = 1; i < 100; i++)
{
Object object = new Object();
v.add(object);
object = null;
}
}
}第2题:对象被创建出来时被放在JVM的什么地方?对象什么时候进入老年代?
对象被创建出来时被放在JVM的什么地方?:
对象创建后被放到堆区,大部分情况下是新生代 Eden区,还有种特殊情况会被放到老年代
这种情况需要满足
1.大对象
2.大对象的大小超出通过以下JVM参数进行设置的大小:(注意此参数仅适用于Serial和ParNew两款新生代收集器。)
-XX:PretenureSizeThreshold=5242880 默认值为0对象什么时候进入老年代?
1.除了上面那种情况外,还有两种情况对象会进入老年代
默认情况下,对象在新生代经历了15次GC后,便会达到进入老年代的条件,将对象转移进入老年代。当然,年龄的阈值可以通过JVM参数进行设置:
-XX:MaxTenuringThreshold=10 默认值为152.动态对象年龄判断
XX:TargetSurvivorRatio=<字节大小>目的:为了防止对象在达到晋升老年代年龄前 s区域的内存就已经不够用了,所以需要整个这个 动态对象年龄判断
详情:假如说当前放对象的Survivor区域里一批对象的 总大小大于了这块Survivor区域的内存大小的50% ,
那么此时大于等于这批对象年龄的对象,就可以直接进入老年代了
第三题:kafka 千万消息积压解决方案
生产者 ——》broker(数据-》磁盘 -》数据)——》消费者
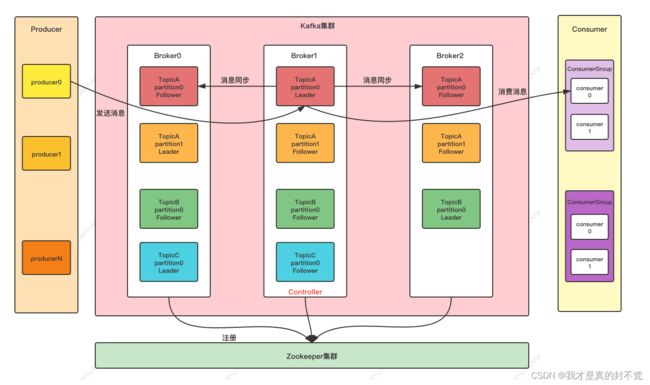
方法:
1 增大分区数量
2.使Kafka分区之间的数据均匀分布 不均匀的话 一般kafka key 后面拼个随机值然后hash后对分区数取模
3.适当缩小数据体积 比如减少不必要的字段 比如某个字段的值可以gzip压缩 然后是序列化方式的选择 推荐avro
4. 在适当的时候进行批量生产 不那么需要立即处理的消息 以及对数据的激增有预期
5..消费者代码优化
比如连接池用hikari,是否需要引入redis
然后是我前面说过的例如变量作用域的不注意 导致内存泄露 垃圾回收更频繁 甚至最终内存溢出 还有比如如果要频繁操作数据库那么也可以先缓存然后批量插入或者更新 这样避免连接数不够而等待
然后可以异步提交 异步提交不仅可以提高消费端性能,同时__consumer_offsets的压力也会降低,其实按照批次异步提交方案是最佳选择,只要我们做好消费端幂等性即可 还有jvm参数调优 比如直接增大堆区内存 比如 调整新生代与老年代的比例
6. 消费者加了并发,服务, 扩大消费线程
7. 增加消费组服务数量 也不要过多 多余消费者会闲置
8. kafka单机升级成集群 负载均衡以及 容错
9.删__consumer_offset 设置 offsets.topic.replication.factor 为3
10.监测消费者消费情况,如有必要超时时间适当增大 避免 消费者消费消息时间过长,导致超时
11.硬件方面 这里说个重要点的 磁盘吞吐量 机械升固态 一般不升成本太高 或者 一个服务器使用多个机械硬盘 设置多个数据目录或者设置成磁盘阵列 还有磁盘控制器的质量
第四题:常见线程池有哪些他们分别适合什么场景使用
6 种常见的线程池:
FixedThreadPool;
CachedThreadPool;
ScheduledThreadPool;
SingleThreadExecutor;
SingleThreadScheduledExecutor;
Executors的工厂方法
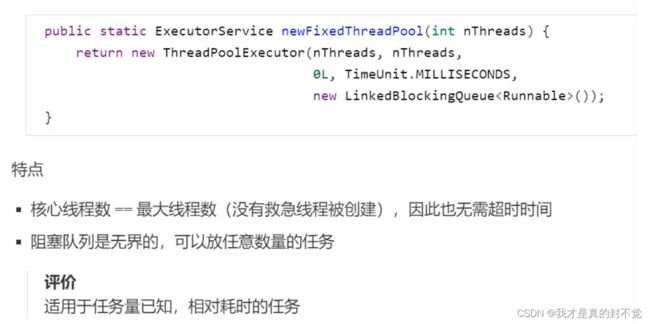
newFixedThreadPool
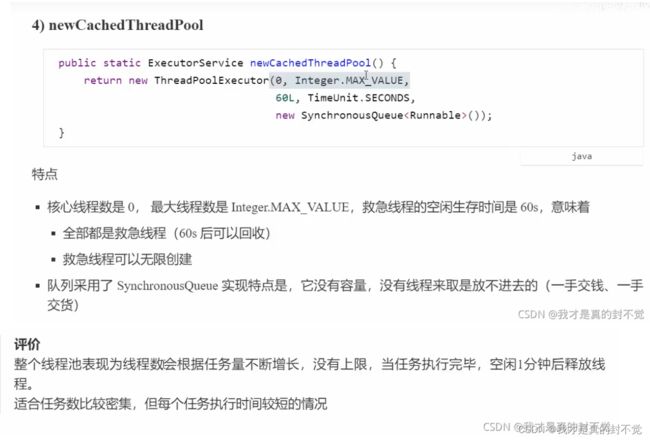
newCachedThreadPool
newSingledThreadPool

ScheduledThreadPool
