计算机网络复习总结(超详细加思维导图)
目录
一、计算机层次结构概略
计算机网络层次结构
1、OSI七层参考模型、五层模型、TCP/IP模型他们到底有何关联?
2、为什么要分层呢?
3、那这些01比特流在传递的过程中都经过了传输媒体?
二、计算机网络各层次功能
应用层
传输层
网络层
功能:
网络层提供了什么服务?
网络层主体是什么,它又是如何提供上述服务呢?
IP协议
路由协议和路由算法有什么联系?。
路由协议(略讲,不在此处讲):
路由算法(细说):
数据链路层
以太网帧格式:
物理层
三、计算机网络各层次设备
各层次设备详解及注意点
1.物理层
2.数据链路层
3.网络层
4.高层
五、计算机网络协议、等基础概念理解
计算机网络各层次协议详解
物理层
数据链路层
网络层
IP协议
传输层
TCP协议(记住:不是不会丢包,丢了可以重传)
UDP协议
应用层
ftp协议
协议传输数据上限
- 前言
学习计算机网络必须得自己搭建出自己的一套知识体系。不然那可就太乱了,不管看了多少书,做了多少题,永远都有懵逼的
如果有联系,自己没见过的也可以排除、分析。没有形成知识脉络整个大脑就是乱的,碎片知识而已。
本文对于课本上重复的重点(也就是学过的人都知道的)不再累赘,更注重疑问、难理解、不好记忆的东西总结成体系
另:在总结传输介质时,一路刨根刨到物理上的波立二相性了(其实我就想知道啥是电磁波,他怎么传播的,怎么什么都是电磁波。。。)
我觉得计算机网络就是讲通信,我好像连信号最终怎么传递的都不知道。。。有必要学习一下(以下来自网上查阅,自觉有理)
- 什么是电磁波?
随时间变化的电场产生磁场,而随时间变化的磁场又产生电场,两者互为因果。这种不断转化的场我们统称为电磁场。这种相互的转化成为电磁振荡
在高频率的电振荡中,磁电互相转化速度极快快,能量不可能全部反回,于是电,磁能随着电场与磁场的周期变化以波的形式向空间传播出去。这就是电磁波了
电磁波的产生从本质上来讲是因为带电荷的基本粒子的运动,而物质温度的高低本质上又是取决于其内部基本粒子的运动剧烈程度,只有在绝对零度下基本粒子才会静止,所以任何高于绝对零度的物质都会向外界辐射电磁波,而绝对零度的物质是不存在的。因此宇宙间的一切都在产生电磁波
作者:必云
链接:https://www.zhihu.com/question/19999211/answer/21193760
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- 电磁辐射对我们身体有影响吗?(过量才有危害,这个量不用去关心,咱普通老百姓也没那个机会暴露在强辐射里,参与特殊工作的也会有防护)
而且,光就是电磁波,怎么多晒太阳还好呢!!!所以别天天提心掉胆害怕被辐射。




- 为啥要讲到电磁波呢?
因为如今网络通信就是利用的电磁波。
电磁波频率高于100khz时,电磁波才可以在空气中传播,并经大气层外缘的电离层反射,形成远距离传输能力。
当频率很高,比如可见光,就不能通过金属导体传播,会被反射、吸收
- 双绞线、同轴电缆、光缆都是通过电磁波传递信号的吗?
yes:本质都是通过电磁波为载体来传播数字信号
其实可以理解为传输同样的信息,通过有线和无线两种方式所发射出来的电磁波,其特征是完全不一样的。
- 又有人会疑问双绞线里通电后里明显是电流信号,也有说电压信号的?
我理解为电流电压只是一种表现形式,你都通电了,里面肯定有电流,那说电流电压信号有什么意义呢?
对电流的基本模型理解有错误。
电流并不是电子不断的从负极运动到正极,虽然中学做题时总是怎么想的。可是实际上电子的运动速度相当之慢,如果电子从负极运动到正极才产生电流,那你打开电灯开关,估计要几年才能等到灯亮。
所以要纠正这个想法。当网线回路接通后,首先电磁场会以光速在导线内传播,然后才是导线内的电子在电磁场的影响下开始运动。
所以导线中既存在电磁场的运动,也存在电流的运动。
所以说,我们利用导线传播的信号,实际上是不断变化的电磁场。变化的电磁场在空间传播的形式,叫电磁波
作者:shawn
链接:https://www.zhihu.com/question/39706853/answer/82985186
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
注意:学习网络之前:我们需提前明白这些名词:
- HZ: 赫兹是电,磁,声波和机械振动周期循环时频率的单位。即每秒的周期次数(周期/秒)
- 网速:就是传输速率
- 网速=传输速率=比特率:计算机每秒可以向所连媒体能发送多少个bit (单位是bit/s)
注意:单位
一般,宽带速率的单位用bps(或b/s)表示;bps表示比特每秒即表示每秒钟传输多少位信息,是bit per second的缩写。在实际所说的1M带宽的意思是1Mbps(是兆比特每秒Mbps不是兆字节每秒MBps)
1Gbps = 1000Mbps = 1000 000 kbps = 1000 000 000 bps
- 传播速率:bit在传输媒体上的传播速率,即一个bit在单位时间内能跑多远。(即就是电磁波单位时间内在传输媒体上走的距离)(单位是:米/s). 这里电磁传播速率(理论=光速 :3*10^8m/s)
注意:传输速率 和 传播速率 概念完全不同
传播速率:讲的是bit能跑多快,传输速率:讲一秒能有多少bit出发!根本不是一回事
现在已知电磁波传播速率为3*10^8m/s
拿人吹泡泡举例,传输速率的提高相当于:从一秒吹出一个泡泡 到 一秒吹出10个泡泡(这个能力的增加是发送者(吹泡泡的人)),并不是吹出的泡泡跑的有多快。
- 码元速率=波特率:
通俗点说,可以把一个码元看做一个存放一定信息量的包,如果只存放1bit,那么波特率等于比特率,但是一般不止存放1bit 如一串二进制信息为101010101 当一个码元携带的信息量为1bit时,那么就有9个码元,其波特率相当于比特率,如果每三个一组101,010,101,这时就可以使用8种振幅来表示某个码元,这里相当于一个码元就包含了3bit,这里码元的离散取值数目就是8。
由此可得波特率和比特率的关系
若一个码元用L个bit表示,波特率是B,数据率(比特率)为C,则
C = B*L
- 带宽是量词,指的是网速的大小,比如1Mbps的意思是一兆比特每秒,这个数值就是指带宽。
- 宽带是名词,说明网络的传输速率速很高 。宽带的标准各不相同,最初认为128kbps以上带宽的就是宽带,而以下的就是窄带。
- 协议数据单元:PDU
-
一、计算机层次结构概略
-
计算机网络层次结构
-
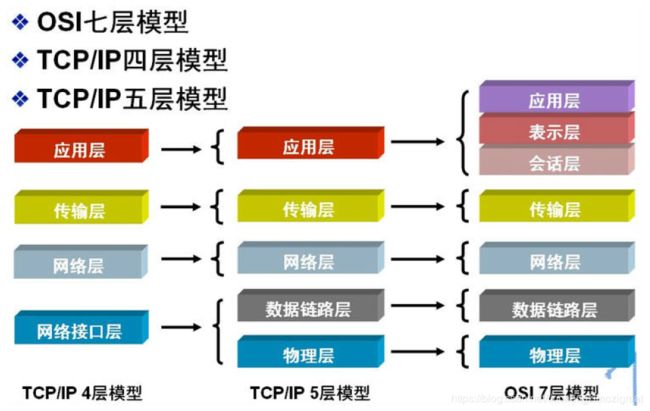
1、OSI七层参考模型、五层模型、TCP/IP模型他们到底有何关联?
为什么标红参考:因为他没能实际的被广泛应用,被TCP/IP模型抢先广泛应用市场。又因为他的分层思路很好,所以经常拿出来讲一下。要知道他就是一堆概念。现实中用的还是TCP/IP模型。
TCP/IP模型原为4层、至于五层模型:是TCP/IP与OSI七层模型的混合后的产物。五层更方便统一通信规则和知识统一
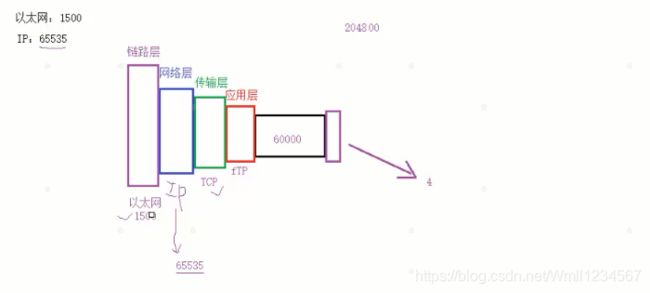
(TCP/IP体系最核心的是靠上的三层:应用层、运输层、网络层。至于下面的网络接口层(也可以分为数据链路层和物理层)不重要,因为TCP/IP本来也没有为网络层以下的层次制定标准。TCP/IP的思路是:形成IP数据包后,只要交付给下面的网络去发就行了)(下图扣别人的)
-
2、为什么要分层呢?
这个模型最终目的是为了什么:对,通信。可以理解为A给B写信,他俩就连接上了,这就是为他俩通信了。
可是A不可能直接把信就寄走,他总得打包吧、总得贴邮票吧、总得有载体吧,为了是这一过程更加清晰,各个流程功能不会相互干扰,可以把这个寄的过程分为好几个步骤,这些步骤是依次进行的。
以上是实际物品来传递文字信息,那么如何利用电子设备交互信息呢?无非就是换了载体,将文字信息编码为电气信号(0101比特),用电线电缆来传递。流程内容不一样,但分步骤的思想还是一样的。
-
3、那这些01比特流在传递的过程中都经过了传输媒体?
注意:这里01是物理层的规定,在传输媒体里,他们的表现形式可能不同,由物理层规定他们的特性来识别是0还是1
- 为什么会有这么多种类传输媒体?
各有特点,最终的目的就是数据传输速率变快。才不断出现各种提高通信速率的技术和材料
1.电缆通信中的电信号也是以光速进行传播的。光纤通信速率高于电缆通信的真正原因是光的频率更高,因此能够加载的信息量更大,也就是我们常说的带宽更大。
举个不那么恰当的例子,这就像是一边是小汽车,一边是大货车,即便车速相等,但单位时间内运送的货物量却不可同日而语。这个例子中,车的速度类比的是光的传播速度,而车的载货量类比的则是带宽。
虽然理论上通信使用的光频率越高、波长越短,信息加载的容量就会越高,但是现实中光纤通信使用的却是近红外光波(如波长1.55μm左右),而不是频率更高的可见光。这是科学家综合考虑光波长、光纤损耗、光源稳定性、综合成本等诸多因素后做出的选择。
2.在通信速率增加上,除了选择物理特性,还有一些技术方法来提高!
比如频分复用,波分复用、时分复用等等(这在后续章节详解)
注意:无论光通信的带宽如何增加、信道如何拓展,信号的延迟依然会存在。
-
二、计算机网络各层次功能
之前已经讲述了为何要分层,其实就是把数据经过一层层的打包然后传递出去。
- 而我们发送的东西如何到达我们想要的目的地呢? 也就是怎么找到目的地呢?
就像我们人类如何识别谁是谁,会用一个ID(身份证)来作为一个唯一的独有的凭证。网络设备也一样,也需要一个凭证。这个凭证就是 MAC地址。
MAC地址被写死在网卡上。每一块网卡是拥有全世界唯一的MAC地址。
近距离:局域网的以太网技术就够了。以太网:通过广播的方式把信息发给每一个在此局域网上的设备。收到此消息的设备比对自己的MAC地址,就OK.
但是全球这么多设备发个消息就广播,那简直难以想象。因此又出现路由器也隔绝这种广播风暴,因此又会多了一个识别网络节点的东西:IP地址。(于是我们把带有MAC地址的消息打包给他加一个IP头)
以上只是两个设备找到了彼此,那么两个设备上的进程又如何识别呢。我们又出现了端口来标识,【于是我们把之前的输据又打包加上传输层协议】
最终同学A的qq发的hello, 经过电脑操作系统层层打包 到达了同学B电脑,操作系统又层层解包,最终到达qq进程。
以上的会在后续详细解释,此处是大概描述
宏观上看看信息如何解封装和传递的 (用一个包含较多层的设备网络拓扑图)
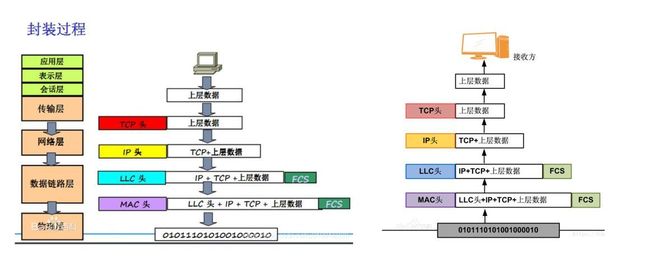
这里从最上层往下层讲,符合一个消息从产生到传递到接收的过程。
-
应用层
-
传输层
网络层为主机间提供逻辑通信,而运输层为应用进程之间提供端到端的逻辑通信。
运输层还要对收到的报文进行差错检测(网络层,ip数据报首部中的检验和字段,只检验首部是否出现差错而不检查数据部分)
根据应用程序的不同需求:传输层两种不同的协议:TCP 、UDP
- 当采用面向连接的TCP协议时:尽管下面的网络是不可靠的(只提供尽最大努力服务),但这种逻辑通信(端到端)相当于一条全双工的可靠信道。
- 当采用无连接的TCP协议时:这种逻辑通信信道仍然是一条不可靠信道
-
网络层
在物理层和数据链路层使用传输媒体和中继器、网桥等设备将主机连接这只是扩大了网络,在网络层面看来,他们仍是同一个网络,并不是达到了网络互联。
网络层的网络也可称为虚拟互联网(也就是逻辑互联网,并非必须物理上连接)。网络互联通常指用路由器进行网络互联。
我们可以想想在物理层上数据只能通过广播转发实现通信,经过数据链路层,我们还是会广播,但是通过网桥和二层交换机隔离了冲突域(不在本网段的才会转发),这一定减少了帧的大范围广播,但他不能阻隔广播。如果全世界计算机就这样连结起来,大量频繁广播可能会造成广播风暴,事实ye而且,不在同一子网也无法通信,因为全世界在一个子网下真的很难想象,我们要想通过广播实现所有网络节点相互通信,听起来就有点二。那么就必须网络节点必须自己学会找到通信目的地,就不需要通过广播来找到目的节点。
于是还需要将数据再封装一层,进行有目的的转发,于是就来到了网络层,出现了路由器,路由器怎么找到目的呢?我们知道链路层通过广播以MAC地址来确定接收节点。我们必须重新定义一套唯一标识网络节点的东西。于是重新找了叫做IP地址的家伙来标识。有了标识,还需要一套找寻目的地的协议和算法。
- 爱思考的人可能还会疑问:为什么不用现成的MAC地址来标识啊
其实,上面已经说到,网络层设备要学会自己找到目的地,但是仅仅通过MAC地址(它只与厂商有关,与所处网络无关。)无法知道是不是在同一个子网,而我们就是为了识别是否在一个子网下,才能决定是否需要转发。

- 打洞机制:
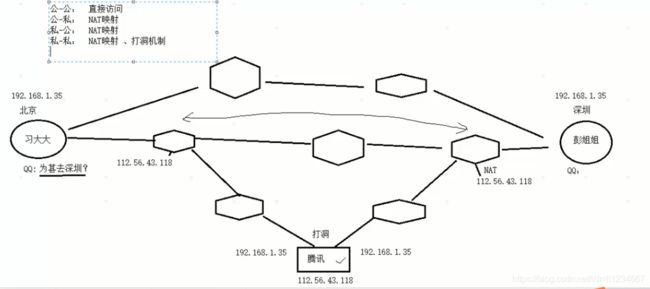
-
功能:
互联网使用的网络层是无连接的网际协议IP和多种路由选择协议,因此网络层也叫网际层或IP层
总的来说就是:网络层的主要作用是“实现终端节点之间的通信”,也就是点对点的通信。
如何点对点?就要进行逻辑地址寻址,实现不同网络之间的路径选择。 协议有:ICMP IGMP IP(IPV4 IPV6) ARP RARP等。
1.异构网络互联(怎么连,规定IP地址)
2.路由和转发(根据路由协议确定路由表,根据路由表得到转发表,根据路由算法选择路由通过转发表转发)
3.拥塞控制(注意:与流量控制不同)
注意:网络层负责在源机器和目标机器之间建立它们所使用的路由。这一层本身没有任何错误检测和修正机制,因此,网络层必须依赖于端端之间的由D L L提供的可靠传输服务。
-
网络层提供了什么服务?
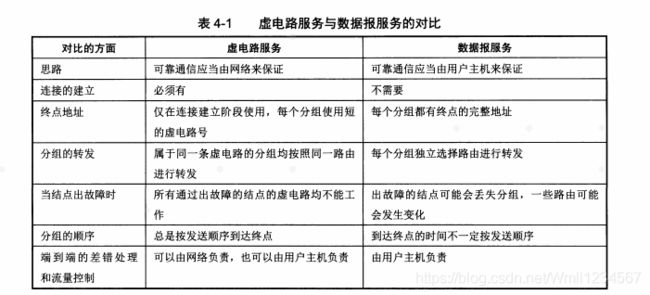
-
网络层主体是什么,它又是如何提供上述服务呢?
-
IP协议
-
路由协议和路由算法有什么联系?。
路由协议:他是规定用ip数据包来转发,怎么转发。路由器之间运行路由协议交换路由信息,路由协议交换的路由信息最终 会形成路由表保持在路由器中,而路由器就是根据路由表(通过某种算法来选择最佳路由)来决定分组的转发
总的来说,就是指导IP数据包发送过程中事先约定好的规定和标准。他是包括路由选择算法的。
路由算法:路由器根据多种路由测度(比如长度)来选择路由,确定路由表的方法。
-
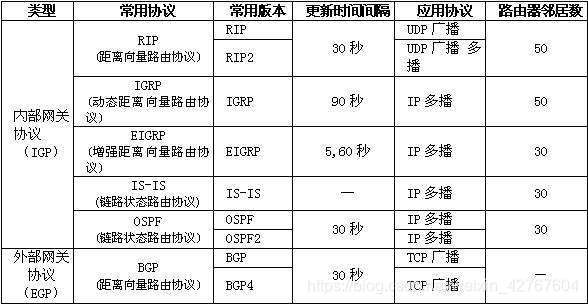
路由协议(略讲,不在此处讲):
按应用范围的不同,路由协议可分为两类:
在一个AS(Autonomous System,自制系统)内的路由协议称为内部网关协议(Interior gateway protocol),AS之间的路由协议称为外部网关协议(Exterior gateway protocol)。
正在使用的内部网关协议:
- RIP(Routing Information Protocol):基于距离矢量(DV)的路由协议,以路由跳数作为计数单位的路由协议,适用于比较小的网络环境。
- IGRP(Interior Gateway Routing Protocol):一种基于距离向量型的内部网关协议。
- EIGRP(Enhanced Interior Gateway Routing Protocol):增强内部网关路由协议,结合了链路状态(LS)和距离矢量(DV)型路由选择协议的Cisco专用协议
- IS-IS(Intermediate System-to-Intermediate System):中间系统到中间系统路由协议,最初是ISO为CLNP(Connection Less Network Protocol,无连接网络协议)设计的一种动态路由协议。
- OSPF(Open Shortest Path First):开放式最短路径优先。是对链路状态路由(LS)协议的一种实现,隶属内部网关协议(IGP),故运作于自治系统内部。著名的迪克斯加算法(Dijkstra)被用来计算最短路径树。
外部网关协议:
- EGP (Exterior Gateway Protocol):是AS之间使用的路由协议,由于EGP存在很多的局限性,IETF边界网关协议工作组制定了标准的边界网关协议(BGP),当前被广泛使用。
- BGP 边界网关协议
-
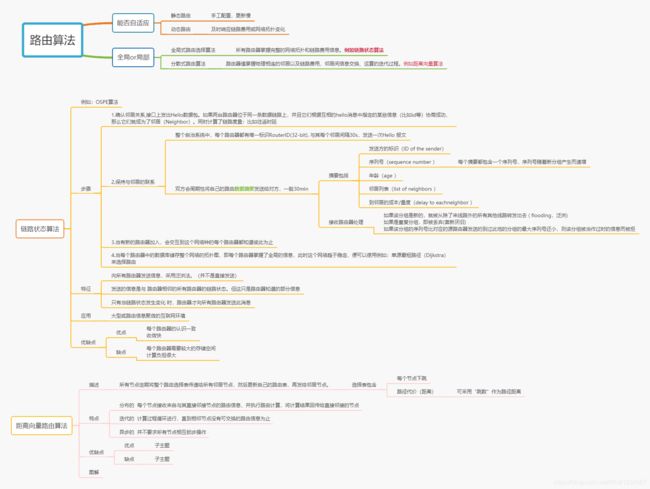
路由算法(细说):
https://blog.csdn.net/qq_18738333/article/details/66205394
-
数据链路层
定义了如何让格式化数据以帧为单位进行传输,以及如何让控制对物理介质的访问。这一层通常还提供错误检测和纠正,以确保数据的可靠传输。如:串口通信中使用到的115200、8、N、1
在网络通讯时,源主机的应用程序知道目的主机的IP地址和端口号,却不知道目的主机的硬件地址,而数据包首先是被网卡接收到再去处理上层协议的,如果接收到的数据包的硬件地址与本机不符,则直接丢弃。因此在通讯前必须获得目的主机的硬件地址。ARP协议就起到这个作用。源主机发出ARP请求,询问“IP地址是192.168.0.1的主机的硬件地址是多少”,并将这个请求广播到本地网段(以太网帧首部的硬件地址填FF:FF:FF:FF:FF:FF表示广播),目的主机接收到广播的ARP请求,发现其中的IP地址与本机相符,则发送一个ARP应答数据包给源主机,将自己的硬件地址填写在应答包中。
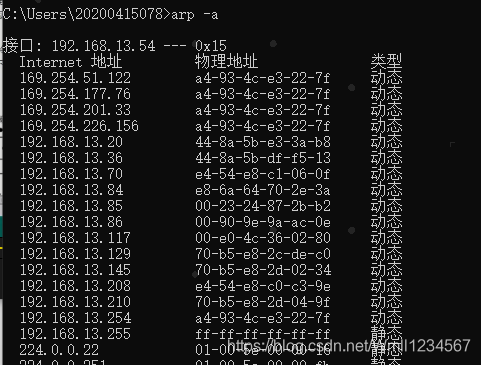
每台主机都维护一个ARP缓存表,可以用arp -a命令查看。缓存表中的表项有过期时间(一般为20分钟),如果20分钟内没有再次使用某个表项,则该表项失效,下次还要发
ARP请求来获得目的主机的硬件地址。想一想,为什么表项要有过期时间而不是一直有效?
MAC地址:
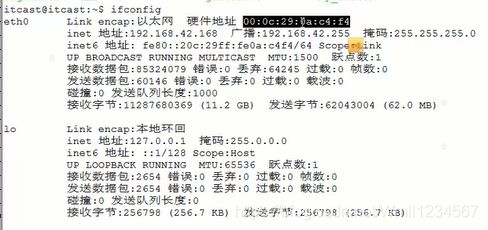
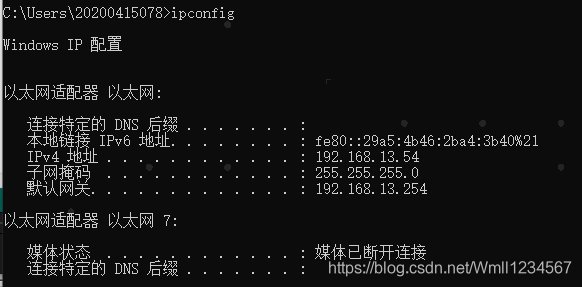
电脑端如何查看:linux: ifconfig
window : ipconfig
-
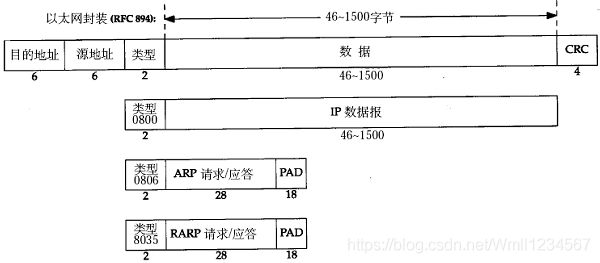
以太网帧格式:
其中的源地址和目的地址是指网卡的硬件地址(也叫MAC地址),长度是48位,是在网卡出厂时固化的。可在shell中使用ifconfig命令查看,“HWaddr 00:15:F2:14:9E:3F”部分就是硬件地址。
协议字段有三种值,分别对应IP、ARP、RARP。帧尾是CRC校验码。
ARP: 字段是 0806 ;用来请求下一跳的MAC地址
RAPP:
以太网帧中的数据长度规定最小46字节,最大1500字节,ARP和RARP数据包的长度不够46字节,要在后面补填充位。最大值1500称为以太网的最大传输单元(MTU),不同的网络类型有不同的MTU,如果一个数据包从以太网路由到拨号链路上,数据包长度大于拨号链路的MTU,则需要对数据包进行分片(fragmentation)。ifconfig命令输出中也有“MTU:1500”。注意,MTU这个概念指数据帧中有效载荷的最大长度,不包括帧头长度
ARP数据报格式:
源MAC地址、目的MAC地址在以太网首部和ARP请求中各出现一次,对于链路层为以太网的情况是多余的,但如果链路层是其它类型的网络则有可能是必要的。硬件类型指链路层网络类型,1为以太网,协议类型指要转换的地址类型,0x0800为IP地址,后面两个地址长度对于以太网地址和IP地址分别为6和4(字节),op字段为1表示ARP请求,op字段为2表示ARP应答。

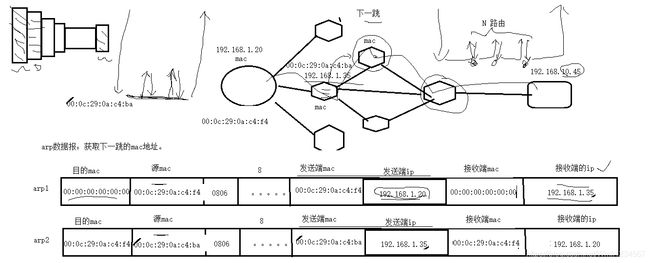
-
物理层
主要定义物理设备标准,如网线的接口类型、光纤的接口类型、各种传输介质的传输速率等。它的主要作用是传输比特流(就是由1、0转化为电流强弱来进行传输,到达目的地后再转化为1、0,也就是我们常说的数模转换与模数转换)。这一层的数据叫做比特。
-
三、计算机网络各层次设备
学完计算机网络后,看到这些东西我脑袋真的要爆炸... ...
(本来在这里打算放一个词云......)
调制解调器、集线器、集成器、中继器、放大器、交换机、第三层交换机、网桥、透明网桥、源路由网桥,多端口网桥、网卡、网关、网络适配器、猫、路由器。貌似知道,一具体,一做题,实际就不会了。
生活当中,我们会听过或接触到哪些设备呢?无线AP,路由器,猫,wifi放大器、网卡是听过接触最多的吧。
我自己也产生了很多的疑问,一一来解答吧!
为什么家里上网要用猫?不用不可以吗?有了网卡还需要猫吗?无线网卡又是怎么的?电话线上网能快吗?拉宽带什么意思?光纤上网就一定快吗?拨号上网的过程是怎样的?家里的路由器覆盖范围不到位应怎么办?家里有很多设备需要用网怎么办? 如果你跟我一样疑问,可以探索一下家里网络拓扑结构图!!!
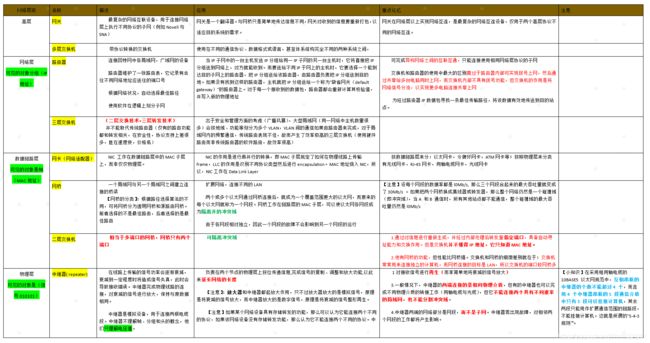
- 先来看看这些设备在实际网络拓扑图的哪些位置吧(从简单网络再到复杂网络)
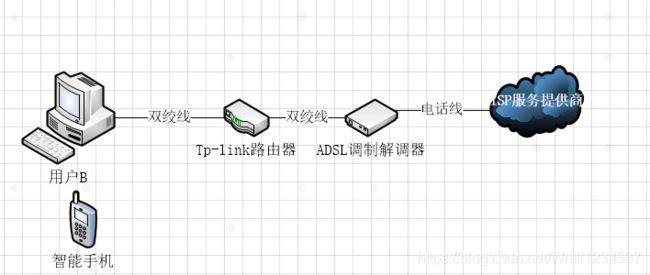
这是我家多年前的一个网络拓扑图,那时候是连电话线上网的,所以必须要有一个猫(调制解调器)
这是我家最新的一个网络拓扑图,拉了移动服务商的光纤,就不需要猫了。路由器还是那个路由器,同时为了覆盖面积更广,添加了一个AP(我把他叫做wifi放大器)
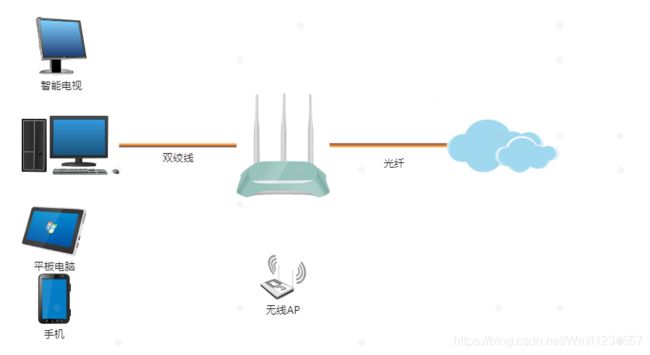
如果说我们要添加5台pc联网呢,在以上的基础上我们有什么方案呢?
1.路由器LAN口不够用,我能想到的方案就是买五个无线网卡(内置/usb外置)
2.用网线连接,那么我能想到的是连接集线器、或者交换机
- 为什么有时候还要在路由器的后面先接1台交换机再接计算机?
路由器是可以直接接电脑等终端设备,为什么标准都是路由器接交换机然后再接电脑等终端,是因为路由器本来就是一个路由设备,用来选路的,不适合大量的数据交换,
交换机是用来大量数据交换的,终端在内网的性质就是需要使用交换机,所以标准就是路由器地下接交换机的形式。
一般是情况就是在路由器下面接交换机,路由器主要起数据转发,也就是寻址、路由的功能,交换机起到用户接入的目的。
但是家用的路由器的话直接就接计算机就可以了,而不必考虑再接交换机。
-
各层次设备详解及注意点
1.物理层
- 中继器
- 集线器
2.数据链路层
- 网桥
- 二层交换机
- 网卡
- 网卡的分类
1、按照网卡支持的计算机种类分类 主要分为标准以太网卡和PCMCIA网卡。标准以太网卡用于台式计算机联网,而PCMCIA网卡用于笔记本电脑。
2、按照网卡支持的传输速率分类 主要分为10Mbps网卡、100Mbps网卡、10/100Mbps自适应网卡和1000Mbps网卡四类。 根据传输速率的要求,10Mbps和100Mbps网卡仅支持10Mbps和100Mbps的传输速率,在使用非屏蔽双绞线UTP作为传输介质时,通常10Mbps网卡与3类UTP配合使用,而100Mbps网卡与5类UTP相连接。10/100Mbps自适应网卡是由网卡自动检测网络的传输速率,保证网络中两种不同传输速率的兼容性。随着局域网传输速率的不断提高,1000Mbps网卡大多被应用于高速的服务器中。
3、按网卡所支持的总线类型分类 主要可以分为ISA、EISA、PCI等。 由于计算机技术的飞速发展,ISA总线接口的网卡的使用越来越少。EISA总线接口的网卡能够并行传输32位数据,数据传输速度快,但价格较贵。PCI总线接口网卡的CPU占用率较低,常用的32位PCI网卡的理论传输速率为133Mbps,因此支持的数据传输速率可达100Mbps。
3种类型的网卡端口
网络接口卡(Network Interface Card,NIC),通常简称为网卡
RJ-45端口:通常用于双绞线的接口。
BNC端口:通常用作细同轴电缆的接口。
AUI端口:通常用作粗同轴电缆的接口
3.网络层
- 路由器
- 三层交换机
4.高层
- 网关
- 多层交换机
-
五、计算机网络协议、等基础概念理解
- 网络到底怎么理解?网络的网络呢?
网络:{计算机,节点,链路} 三要素(结点:计算机,集线器、交换机或路由器等)
网络的网络是把许多网络连接起来
网络的网络:{网络,路由器,链路}
将通信的过程分层,那每一层的数据格式等的规定,就一套协议来规定了
- 互联网两大组成部分是什么?他们的工作方式有何特点?
边缘部分:主机组成。用户直接使用,用来进行通信和资源共享。
工作方式:C/S方式和P2P(对等)
核心部分:大量网络和连接这些网络的路由器组成。为边缘部分提供服务
就是路由器的工作方式:1.转发分组,2.交换路由信息
- 计算机网络有哪些常用的性能指标?
1)速率:指的是连接在计算机网络上的主机在数字信道上传输数据的速率。也称为数据率或比特率
2)带宽:用来表示网络的通信链路传送数据的能力
3)吞吐量:单位时间内通过某个网络(或信道、接口)的数据量
4)时延:指数据从网络的一端传送到另一端所需要的时间(包括:发送时延、传播时延、处理时延和排队时延等)
5)时延带宽积:传播时延和带宽的乘积
6)往返时间:从发送方发数据开始,到发送方收到来自接收方的确认,总经历的时间
2)利用率:
信道利用率:某信道有百分之几的时间有数据通过
网络利用率:全网络的信道利用率的加权平均值
- 网络协议的三个要素是什么?
语法:数据和控制信息的结构或格式
语义:需要发出何种控制信息,完成何种动作、和做出何种响应
同步:事件顺序的详细解释
- 网络吞吐量是什么?如何计算?
- 网络时延是什么?如何计算?
- 网络吞吐量和网络时延有何关系?
- 如何理解可靠传输和不可靠传输?
- 如何理解面向连接和无连接?

-
计算机网络各层次协议详解
-
物理层
-
数据链路层
-
网络层
-
IP协议
IP数据报格式:
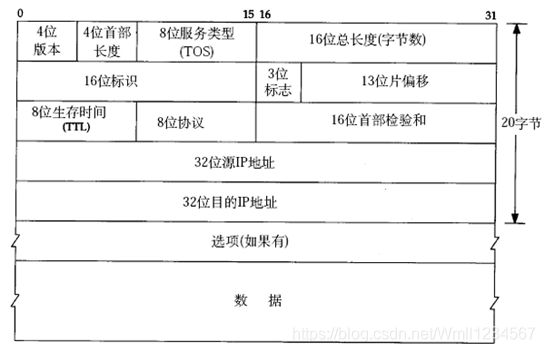
IP数据报的首部长度和数据长度都是可变长的,但总是4字节的整数倍。对于IPv4,4位版本字段是4。4位首部长度的数值是以4字节为单位的,最小值为5,也就是说首部长度最小是4x5=20字节,也就是不带任何选项的IP首部,4位能表示的最大值是15,也就是说首部长度最大是60字节。
8位TOS字段有3个位用来指定IP数据报的优先级(目前已经废弃不用),还有4个位表示可选的服务类型(最小延迟、最大?吐量、最大可靠性、最小成本),还有一个位总是0。总长度是整个数据报(包括IP首部和IP层payload)的字节数。每传一个IP数据报,16位的标识加1,可用于分片和重新组装数据报。3位标志和13位片偏移用于分片。TTL(Time to live)是这样用的:源主机为数据包设定一个生存时间,比如64,每过一个路由器就把该值减1,如果减到0就表示路由已经太长了仍然找不到目的主机的网络,就丢弃该包,因此这个生存时间的单位不是秒,而是跳(hop)。协议字段指示上层协议是TCP、UDP、ICMP还是IGMP。然后是校验和,只校验IP首部,数据的校验由更高层协议负责。IPv4的IP地址长度为32位。
想一想,前面讲了以太网帧中的最小数据长度为46字节,不足46字节的要用填充字节补上,那么如何界定这46字节里前多少个字节是IP、ARP或RARP数据报而后面是填充字节?

-
传输层
-
TCP协议(记住:不是不会丢包,丢了可以重传)
-
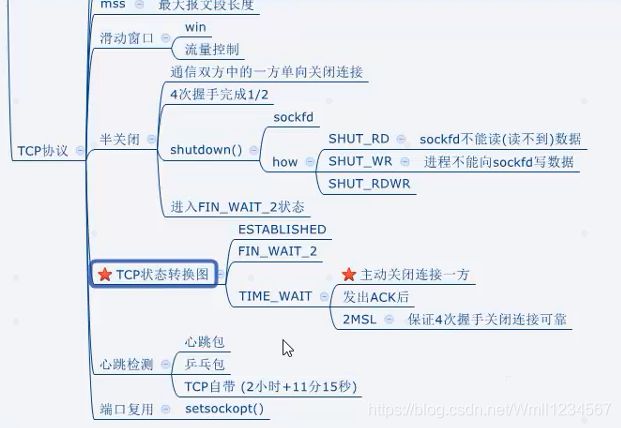
tcp通信时序
在这个例子中,首先客户端主动发起连接、发送请求,然后服务器端响应请求,然后客户端主动关闭连接。两条竖线表示通讯的两端,从上到下表示时间的先后顺序,注意,数据从一端传到网络的另一端也需要时间,所以图中的箭头都是斜的。双方发送的段按时间顺序编号为1-10,各段中的主要信息在箭头上标出,例如段2的箭头上标着SYN, 8000(0), ACK1001, ,表示该段中的SYN位置1,32位序号是8000,该段不携带有效载荷(数据字节数为0),ACK位置1,32位确认序号是1001,带有一个mss(Maximum Segment Size,最大报文长度)选项值为1024。
- 建立连接(三次握手)的过程:
- 客户端发送一个带SYN标志的TCP报文到服务器。这是三次握手过程中的段1。
客户端发出段1,SYN位表示连接请求。序号是1000,这个序号在网络通讯中用作临时的地址,每发一个数据字节,这个序号要加1,这样在接收端可以根据序号排出数据包的正确顺序,也可以发现丢包的情况,另外,规定SYN位和FIN位也要占一个序号,这次虽然没发数据,但是由于发了SYN位,因此下次再发送应该用序号1001。mss表示最大段尺寸,如果一个段太大,封装成帧后超过了链路层的最大帧长度,就必须在IP层分片,为了避免这种情况,客户端声明自己的最大段尺寸,建议服务器端发来的段不要超过这个长度。
- 服务器端回应客户端,是三次握手中的第2个报文段,同时带ACK标志和SYN标志。它表示对刚才客户端SYN的回应;同时又发送SYN给客户端,询问客户端是否准备好进行数据通讯。
服务器发出段2,也带有SYN位,同时置ACK位表示确认,确认序号是1001,表示“我接收到序号1000及其以前所有的段,请你下次发送序号为1001的段”,也就是应答了客户端的连接请求,同时也给客户端发出一个连接请求,同时声明最大尺寸为1024。
- 客户必须再次回应服务器端一个ACK报文,这是报文段3。
客户端发出段3,对服务器的连接请求进行应答,确认序号是8001。在这个过程中,客户端和服务器分别给对方发了连接请求,也应答了对方的连接请求,其中服务器的请求和应答在一个段中发出,因此一共有三个段用于建立连接,称为“三方握手(three-way-handshake)”。在建立连接的同时,双方协商了一些信息,例如双方发送序号的初始值、最大段尺寸等。
在TCP通讯中,如果一方收到另一方发来的段,读出其中的目的端口号,发现本机并没有任何进程使用这个端口,就会应答一个包含RST位的段给另一方。例如,服务器并没有任何进程使用8080端口,我们却用telnet客户端去连接它,服务器收到客户端发来的SYN段就会应答一个RST段,客户端的telnet程序收到RST段后报告错误Connection refused:
$ telnet 192.168.0.200 8080
Trying 192.168.0.200...
telnet: Unable to connect to remote host: Connection refused
- 数据传输的过程:
- 客户端发出段4,包含从序号1001开始的20个字节数据。
- 服务器发出段5,确认序号为1021,对序号为1001-1020的数据表示确认收到,同时请求发送序号1021开始的数据,服务器在应答的同时也向客户端发送从序号8001开始的10个字节数据,这称为piggyback。
- 客户端发出段6,对服务器发来的序号为8001-8010的数据表示确认收到,请求发送序号8011开始的数据。
在数据传输过程中,ACK和确认序号是非常重要的,应用程序交给TCP协议发送的数据会暂存在TCP层的发送缓冲区中,发出数据包给对方之后,只有收到对方应答的ACK段才知道该数据包确实发到了对方,可以从发送缓冲区中释放掉了,如果因为网络故障丢失了数据包或者丢失了对方发回的ACK段,经过等待超时后TCP协议自动将发送缓冲区中的数据包重发。
- 关闭连接(四次握手)的过程:
由于TCP连接是全双工的,因此每个方向都必须单独进行关闭。这原则是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向的连接。收到一个 FIN只意味着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
- 客户端发出段7,FIN位表示关闭连接的请求。
- 服务器发出段8,应答客户端的关闭连接请求。
- 服务器发出段9,其中也包含FIN位,向客户端发送关闭连接请求。
- 客户端发出段10,应答服务器的关闭连接请求。
建立连接的过程是三方握手,而关闭连接通常需要4个段,服务器的应答和关闭连接请求通常不合并在一个段中,因为有连接半关闭的情况,这种情况下客户端关闭连接之后就不能再发送数据给服务器了,但是服务器还可以发送数据给客户端,直到服务器也关闭连接为止。
- 注意:什么是半关闭?
一方关闭连接,另一方未关闭。
当TCP链接中A发送FIN请求关闭,B端回应ACK后(A端进入FIN_WAIT_2状态),B没有立即发送FIN给A时,A方处在半链接状态,此时A可以接收B发送的数据,但是A已不能再向B发送数据。
从程序的角度,可以使用API来控制实现半连接状态。
#includeint shutdown(int sockfd, int how); sockfd: 需要关闭的socket的描述符 how: 允许为shutdown操作选择以下几种方式: SHUT_RD(0): 关闭sockfd上的读功能,此选项将不允许sockfd进行读操作。 该套接字不再接受数据,任何当前在套接字接受缓冲区的数据将被无声的丢弃掉。 SHUT_WR(1): 关闭sockfd的写功能,此选项将不允许sockfd进行写操作。进程不能在对此套接字发出写操作。 SHUT_RDWR(2): 关闭sockfd的读写功能。相当于调用shutdown两次:首先是以SHUT_RD,然后以SHUT_WR。 使用close中止一个连接,但它只是减少描述符的引用计数,并不直接关闭连接,只有当描述符的引用计数为0时才关闭连接。
shutdown不考虑描述符的引用计数,直接关闭描述符。也可选择中止一个方向的连接,只中止读或只中止写。
注意:
- 如果有多个进程共享一个套接字,close每被调用一次,计数减1,直到计数为0时,也就是所用进程都调用了close,套接字将被释放。
- 在多进程中如果一个进程调用了shutdown(sfd, SHUT_RDWR)后,其它的进程将无法进行通信。但,如果一个进程close(sfd)将不会影响到其它进程。
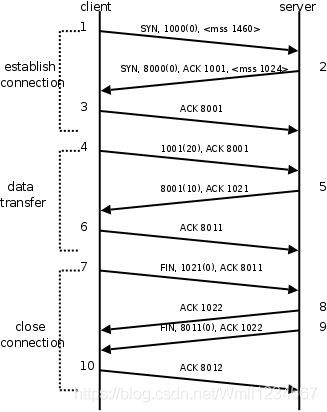
- 滑动窗口(流量控制)
介绍UDP时我们描述了这样的问题:如果发送端发送的速度较快,接收端接收到数据后处理的速度较慢,而接收缓冲区的大小是固定的,就会丢失数据。TCP协议通过“滑动窗口(Sliding Window)”机制解决这一问题。看下图的通讯过程
- 发送端发起连接,声明最大段尺寸是1460,初始序号是0,窗口大小是4K,表示“我的接收缓冲区还有4K字节空闲,你发的数据不要超过4K”。接收端应答连接请求,声明最大段尺寸是1024,初始序号是8000,窗口大小是6K。发送端应答,三方握手结束。
- 发送端发出段4-9,每个段带1K的数据,发送端根据窗口大小知道接收端的缓冲区满了,因此停止发送数据。
- 接收端的应用程序提走2K数据,接收缓冲区又有了2K空闲,接收端发出段10,在应答已收到6K数据的同时声明窗口大小为2K。
- 接收端的应用程序又提走2K数据,接收缓冲区有4K空闲,接收端发出段11,重新声明窗口大小为4K。
- 发送端发出段12-13,每个段带2K数据,段13同时还包含FIN位。
- 接收端应答接收到的2K数据(6145-8192),再加上FIN位占一个序号8193,因此应答序号是8194,连接处于半关闭状态,接收端同时声明窗口大小为2K。
- 接收端的应用程序提走2K数据,接收端重新声明窗口大小为4K。
- 接收端的应用程序提走剩下的2K数据,接收缓冲区全空,接收端重新声明窗口大小为6K。
- 接收端的应用程序在提走全部数据后,决定关闭连接,发出段17包含FIN位,发送端应答,连接完全关闭。
上图在接收端用小方块表示1K数据,实心的小方块表示已接收到的数据,虚线框表示接收缓冲区,因此套在虚线框中的空心小方块表示窗口大小,从图中可以看出,随着应用程序提走数据,虚线框是向右滑动的,因此称为滑动窗口。
从这个例子还可以看出,发送端是一K一K地发送数据,而接收端的应用程序可以两K两K地提走数据,当然也有可能一次提走3K或6K数据,或者一次只提走几个字节的数据。也就是说,应用程序所看到的数据是一个整体,或说是一个流(stream),在底层通讯中这些数据可能被拆成很多数据包来发送,但是一个数据包有多少字节对应用程序是不可见的,因此TCP协议是面向流的协议。而UDP是面向消息的协议,每个UDP段都是一条消息,应用程序必须以消息为单位提取数据,不能一次提取任意字节的数据,这一点和TCP是很不同的。
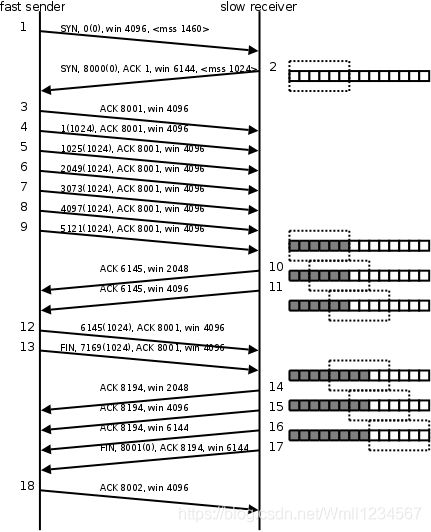
- TCP状态转换
这个图N多人都知道,它排除和定位网络或系统故障时大有帮助,但是怎样牢牢地将这张图刻在脑中呢?那么你就一定要对这张图的每一个状态,及转换的过程有深刻的认识,不能只停留在一知半解之中。下面对这张图的11种状态详细解析一下,以便加强记忆!不过在这之前,需要十分清楚TCP建立连接的三次握手过程,以及 关闭连接的四次握手过程。
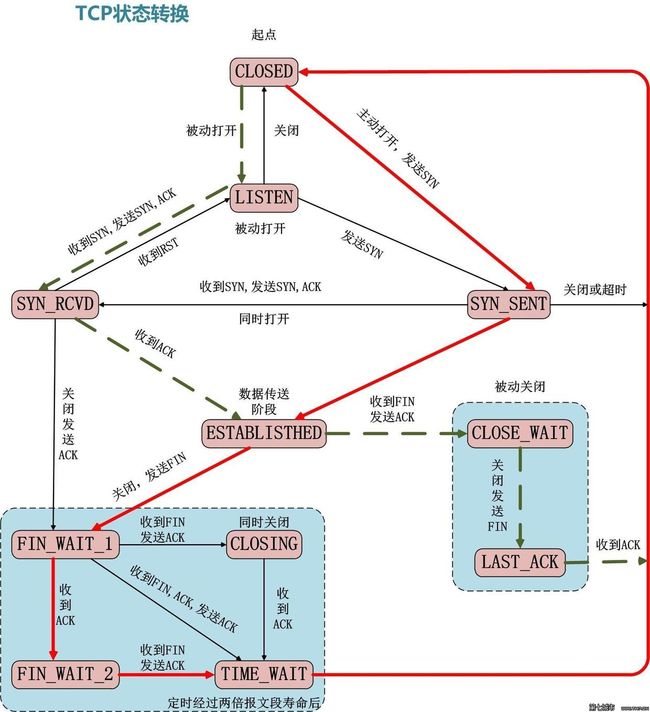
上图可分为三部分:粗实线(指的是主动发起连接和主动关闭连接)、细实线(指两端同时操作部分)、虚线(被动发起连接、被动关闭连接)
CLOSED:表示初始状态。
LISTEN:该状态表示服务器端的某个SOCKET处于监听状态,可以接受连接。
SYN_SENT:这个状态与SYN_RCVD遥相呼应,当客户端SOCKET执行CONNECT连接时,它首先发送SYN报文,随即进入到了SYN_SENT状态,并等待服务端的发送三次握手中的第2个报文。SYN_SENT状态表示客户端已发送SYN报文。(转瞬即逝的状态)
SYN_RCVD: 该状态表示接收到SYN报文,在正常情况下,这个状态是服务器端的SOCKET在建立TCP连接时的三次握手会话过程中的一个中间状态,很短暂。此种状态时,当收到客户端的ACK报文后,会进入到ESTABLISHED状态。
ESTABLISHED:表示连接已经建立。
FIN_WAIT_1: FIN_WAIT_1和FIN_WAIT_2状态的真正含义都是表示等待对方的FIN报文。区别是:
FIN_WAIT_1状态是当socket在ESTABLISHED状态时,想主动关闭连接,向对方发送了FIN报文,此时该socket进入到FIN_WAIT_1状态。
FIN_WAIT_2状态是当对方回应ACK后,该socket进入到FIN_WAIT_2状态,正常情况下,对方应马上回应ACK报文,所以FIN_WAIT_1状态一般较难见到,而FIN_WAIT_2状态可用netstat看到。
FIN_WAIT_2:主动关闭链接的一方,发出FIN收到ACK以后进入该状态。称之为半连接或半关闭状态(主动发起一方进入的状态,被动一方不会出现此状态)。该状态下的socket只能接收数据,不能发。
TIME_WAIT(主动一方才会有次状态): 表示收到了对方的FIN报文,并发送出了ACK报文,等2MSL后即可回到CLOSED可用状态。如果FIN_WAIT_1状态下,收到对方同时带 FIN标志和ACK标志的报文时,可以直接进入到TIME_WAIT状态,而无须经过FIN_WAIT_2状态。
为什么要等2msl(linux操作系统大概一分钟左右)之后才回到closed的状态,是因为不确定对方是否收到发出的ack报文(此报文时应答对方发来的FIN报文),所以等就是确保对方能收到ACK。如果在着2ml还是收不到,那就没办法了。这个时间过后,就会进入closed状态
CLOSING: 这种状态较特殊,属于一种较罕见的状态。正常情况下,当你发送FIN报文后,按理来说是应该先收到(或同时收到)对方的 ACK报文,再收到对方的FIN报文。但是CLOSING状态表示你发送FIN报文后,并没有收到对方的ACK报文,反而却也收到了对方的FIN报文。什么情况下会出现此种情况呢?如果双方几乎在同时close一个SOCKET的话,那么就出现了双方同时发送FIN报文的情况,也即会出现CLOSING状态,表示双方都正在关闭SOCKET连接。
CLOSE_WAIT: 此种状态表示在等待关闭。当对方关闭一个SOCKET后发送FIN报文给自己,系统会回应一个ACK报文给对方,此时则进入到CLOSE_WAIT状态。接下来呢,察看是否还有数据发送给对方,如果没有可以 close这个SOCKET,发送FIN报文给对方,即关闭连接。所以在CLOSE_WAIT状态下,需要关闭连接。
LAST_ACK: 该状态是被动关闭一方在发送FIN报文后,最后等待对方的ACK报文。当收到ACK报文后,即可以进入到CLOSED可用状态。
- 关于半关闭
当TCP链接中A发送FIN请求关闭,B端回应ACK后(A端进入FIN_WAIT_2状态),B没有立即发送FIN给A时,A方处在半链接状态,此时A可以接收B发送的数据,但是A已不能再向B发送数据。
从程序的角度,可以使用API来控制实现半连接状态。
#includeint shutdown(int sockfd, int how); sockfd: 需要关闭的socket的描述符 how: 允许为shutdown操作选择以下几种方式: SHUT_RD(0): 关闭sockfd上的读功能,此选项将不允许sockfd进行读操作。 该套接字不再接受数据,任何当前在套接字接受缓冲区的数据将被无声的丢弃掉。 SHUT_WR(1): 关闭sockfd的写功能,此选项将不允许sockfd进行写操作。进程不能在对此套接字发出写操作。 SHUT_RDWR(2): 关闭sockfd的读写功能。相当于调用shutdown两次:首先是以SHUT_RD,然后以SHUT_WR。 使用close中止一个连接,但它只是减少描述符的引用计数,并不直接关闭连接,只有当描述符的引用计数为0时才关闭连接。
shutdown不考虑描述符的引用计数,直接关闭描述符。也可选择中止一个方向的连接,只中止读或只中止写。
注意:
- 如果有多个进程共享一个套接字,close每被调用一次,计数减1,直到计数为0时,也就是所用进程都调用了close,套接字将被释放。
- 在多进程中如果一个进程调用了shutdown(sfd, SHUT_RDWR)后,其它的进程将无法进行通信。但,如果一个进程close(sfd)将不会影响到其它进程。
- 关于标志位RST
三次握手,中途一些意外导致握手失败,操作系统会替有问题一端发送一个重置报文。
比如:服务器监听中,收到客户端连接请求,此时服务端回复syn,ack,等待客户端回复ack才能进入establish状态。但如果此时客户端挂了,出问题了,如果网络还能通的话,客户端的操作系统会主动发送一个带有RST标志的报文。意思是此次握手失败,重新再来。服务器由syn_recv状态恢复到 LISTEN状态。
再比如:尝试连接一个没有在侦听的端口,对端操作系统也会发送一个RST标志的报文。
- 关于2MSL
2MSL (Maximum Segment Lifetime) TIME_WAIT状态的存在有两个理由:
(1)让4次握手关闭流程更加可靠;4次握手的最后一个ACK是是由主动关闭方发送出去的,若这个ACK丢失,被动关闭方会再次发一个FIN过来。若主动关闭方能够保持一个2MSL的TIME_WAIT状态,则有更大的机会让丢失的ACK被再次发送出去。
(2)防止lost duplicate对后续新建正常链接的传输造成破坏。lost uplicate在实际的网络中非常常见,经常是由于路由器产生故障,路径无法收敛,导致一个packet在路由器A,B,C之间做类似死循环的跳转。IP头部有个TTL,限制了一个包在网络中的最大跳数,因此这个包有两种命运,要么最后TTL变为0,在网络中消失;要么TTL在变为0之前路由器路径收敛,它凭借剩余的TTL跳数终于到达目的地。但非常可惜的是TCP通过超时重传机制在早些时候发送了一个跟它一模一样的包,并先于它达到了目的地,因此它的命运也就注定被TCP协议栈抛弃。
另外一个概念叫做incarnation connection,指跟上次的socket pair一摸一样的新连接,叫做incarnation of previous connection。lost uplicate加上incarnation connection,则会对我们的传输造成致命的错误。
TCP是流式的,所有包到达的顺序是不一致的,依靠序列号由TCP协议栈做顺序的拼接;假设一个incarnation connection这时收到的seq=1000, 来了一个lost duplicate为seq=1000,len=1000, 则TCP认为这个lost duplicate合法,并存放入了receive buffer,导致传输出现错误。通过一个2MSL TIME_WAIT状态,确保所有的lost duplicate都会消失掉,避免对新连接造成错误。
该状态为什么设计在主动关闭这一方:
(1)发最后ACK的是主动关闭一方。
(2)只要有一方保持TIME_WAIT状态,就能起到避免incarnation connection在2MSL内的重新建立,不需要两方都有。
如何正确对待2MSL TIME_WAIT?
RFC要求socket pair在处于TIME_WAIT时,不能再起一个incarnation connection。但绝大部分TCP实现,强加了更为严格的限制。在2MSL等待期间,socket中使用的本地端口在默认情况下不能再被使用。
若A 10.234.5.5 : 1234和B 10.55.55.60 : 6666建立了连接,A主动关闭,那么在A端只要port为1234,无论对方的port和ip是什么,都不允许再起服务。这甚至比RFC限制更为严格,RFC仅仅是要求socket pair不一致,而实现当中只要这个port处于TIME_WAIT,就不允许起连接。这个限制对主动打开方来说是无所谓的,因为一般用的是临时端口;但对于被动打开方,一般是server,就悲剧了,因为server一般是熟知端口。比如http,一般端口是80,不可能允许这个服务在2MSL内不能起来。
解决方案是给服务器的socket设置SO_REUSEADDR选项,这样的话就算熟知端口处于TIME_WAIT状态,在这个端口上依旧可以将服务启动。当然,虽然有了SO_REUSEADDR选项,但sockt pair这个限制依旧存在。比如上面的例子,A通过SO_REUSEADDR选项依旧在1234端口上起了监听,但这时我们若是从B通过6666端口去连它,TCP协议会告诉我们连接失败,原因为Address already in use.
RFC 793中规定MSL为2分钟,实际应用中常用的是30秒,1分钟和2分钟等。
RFC (Request For Comments),是一系列以编号排定的文件。收集了有关因特网相关资讯,以及UNIX和因特网社群的软件文件。
- 程序设计中的问题
做一个测试,首先启动server,然后启动client,用Ctrl-C终止server,马上再运行server,运行结果:
itcast$ ./server bind error: Address already in use这是因为,虽然server的应用程序终止了,但TCP协议层的连接并没有完全断开,因此不能再次监听同样的server端口。我们用netstat命令查看一下:
itcast$ netstat -apn |grep 6666 tcp 1 0 192.168.1.11:38103 192.168.1.11:6666 CLOSE_WAIT 3525/client tcp 0 0 192.168.1.11:6666 192.168.1.11:38103 FIN_WAIT2 -server终止时,socket描述符会自动关闭并发FIN段给client,client收到FIN后处于CLOSE_WAIT状态,但是client并没有终止,也没有关闭socket描述符,因此不会发FIN给server,因此server的TCP连接处于FIN_WAIT2状态。
现在用Ctrl-C把client也终止掉,再观察现象:
itcast$ netstat -apn |grep 6666 tcp 0 0 192.168.1.11:6666 192.168.1.11:38104 TIME_WAIT - itcast$ ./server bind error: Address already in useclient终止时自动关闭socket描述符,server的TCP连接收到client发的FIN段后处于TIME_WAIT状态。TCP协议规定,主动关闭连接的一方要处于TIME_WAIT状态,等待两个MSL(maximum segment lifetime)的时间后才能回到CLOSED状态,因为我们先Ctrl-C终止了server,所以server是主动关闭连接的一方,在TIME_WAIT期间仍然不能再次监听同样的server端口。
MSL在RFC 1122中规定为两分钟,但是各操作系统的实现不同,在Linux上一般经过半分钟后就可以再次启动server了。至于为什么要规定TIME_WAIT的时间,可参考UNP 2.7节。
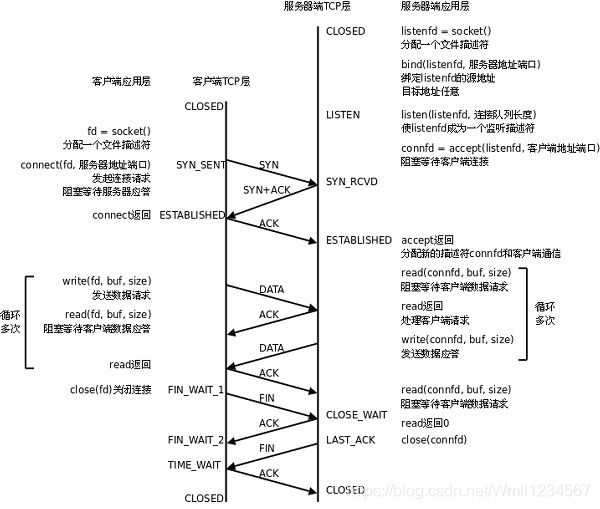
- C/S模型-TCP
下图是基于TCP协议的客户端/服务器程序的一般流程:
TCP协议通讯流程
服务器调用socket()、bind()、listen()完成初始化后,调用accept()阻塞等待,处于监听端口的状态,客户端调用socket()初始化后,调用connect()发出SYN段并阻塞等待服务器应答,服务器应答一个SYN-ACK段,客户端收到后从connect()返回,同时应答一个ACK段,服务器收到后从accept()返回。
数据传输的过程:
建立连接后,TCP协议提供全双工的通信服务,但是一般的客户端/服务器程序的流程是由客户端主动发起请求,服务器被动处理请求,一问一答的方式。因此,服务器从accept()返回后立刻调用read(),读socket就像读管道一样,如果没有数据到达就阻塞等待,这时客户端调用write()发送请求给服务器,服务器收到后从read()返回,对客户端的请求进行处理,在此期间客户端调用read()阻塞等待服务器的应答,服务器调用write()将处理结果发回给客户端,再次调用read()阻塞等待下一条请求,客户端收到后从read()返回,发送下一条请求,如此循环下去。
如果客户端没有更多的请求了,就调用close()关闭连接,就像写端关闭的管道一样,服务器的read()返回0,这样服务器就知道客户端关闭了连接,也调用close()关闭连接。注意,任何一方调用close()后,连接的两个传输方向都关闭,不能再发送数据了。如果一方调用shutdown()则连接处于半关闭状态,仍可接收对方发来的数据。
在学习socket API时要注意应用程序和TCP协议层是如何交互的: 应用程序调用某个socket函数时TCP协议层完成什么动作,比如调用connect()会发出SYN段 应用程序如何知道TCP协议层的状态变化,比如从某个阻塞的socket函数返回就表明TCP协议收到了某些段,再比如read()返回0就表明收到了FIN段
- 问题?
【问题1】为什么连接的时候是三次握手,关闭的时候却是四次握手?
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,"你发的FIN报文我收到了"。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
【问题2】为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
答:虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。在Client发送出最后的ACK回复,但该ACK可能丢失。Server如果没有收到ACK,将不断重复发送FIN片段。所以Client不能立即关闭,它必须确认Server接收到了该ACK。Client会在发送出ACK之后进入到TIME_WAIT状态。Client会设置一个计时器,等待2MSL的时间。如果在该时间内再次收到FIN,那么Client会重发ACK并再次等待2MSL。所谓的2MSL是两倍的MSL(Maximum Segment Lifetime)。MSL指一个片段在网络中最大的存活时间,2MSL就是一个发送和一个回复所需的最大时间。如果直到2MSL,Client都没有再次收到FIN,那么Client推断ACK已经被成功接收,则结束TCP连接。
【问题3】为什么不能用两次握手进行连接?
答:3次握手完成两个重要的功能,既要双方做好发送数据的准备工作(双方都知道彼此已准备好),也要允许双方就初始序列号进行协商,这个序列号在握手过程中被发送和确认。
现在把三次握手改成仅需要两次握手,死锁是可能发生的。作为例子,考虑计算机S和C之间的通信,假定C给S发送一个连接请求分组,S收到了这个分组,并发 送了确认应答分组。按照两次握手的协定,S认为连接已经成功地建立了,可以开始发送数据分组。可是,C在S的应答分组在传输中被丢失的情况下,将不知道S 是否已准备好,不知道S建立什么样的序列号,C甚至怀疑S是否收到自己的连接请求分组。在这种情况下,C认为连接还未建立成功,将忽略S发来的任何数据分 组,只等待连接确认应答分组。而S在发出的分组超时后,重复发送同样的分组。这样就形成了死锁。
【问题4】如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
【问题5】CP协议规定,主动关闭连接的一方要处于TIME_WAIT状态,等待两个MSL(maximum segment lifetime)的时间后才能回到CLOSED状态,因为我们先Ctrl-C终止了server,所以server是主动关闭连接的一方,在TIME_WAIT期间仍然不能再次监听同样的server端口,如何解决?
前文已经讲过,再说一遍,端口复用:在server的TCP连接没有完全断开之前不允许重新监听是不合理的。因为,TCP连接没有完全断开指的是connfd(127.0.0.1:6666)没有完全断开,而我们重新监听的是lis-tenfd(0.0.0.0:6666),虽然是占用同一个端口,但IP地址不同,connfd对应的是与某个客户端通讯的一个具体的IP地址,而listenfd对应的是wildcard address。解决这个问题的方法是使用setsockopt()设置socket描述符的选项SO_REUSEADDR为1,表示允许创建端口号相同但IP地址不同的多个socket描述符。
在server代码的socket()和bind()调用之间插入如下代码
int opt = 1; setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
-
UDP协议
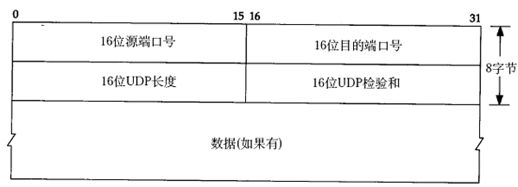
UDP报文格式:
下面分析一帧基于UDP的TFTP协议帧。
以太网首部
0000: 00 05 5d 67 d0 b1 00 05 5d 61 58 a8 08 00
IP首部
0000: 45 00
0010: 00 53 93 25 00 00 80 11 25 ec c0 a8 00 37 c0 a8
0020: 00 01
UDP首部
0020: 05 d4 00 45 00 3f ac 40
TFTP协议
0020: 00 01 'c'':''\''q'
0030: 'w''e''r''q''.''q''w''e'00 'n''e''t''a''s''c''i'
0040: 'i'00 'b''l''k''s''i''z''e'00 '5''1''2'00 't''i'
0050: 'm''e''o''u''t'00 '1''0'00 't''s''i''z''e'00 '0'
0060: 00以太网首部:源MAC地址是00:05:5d:61:58:a8,目的MAC地址是00:05:5d:67:d0:b1,上层协议类型0x0800表示IP。
IP首部:每一个字节0x45包含4位版本号和4位首部长度,版本号为4,即IPv4,首部长度为5,说明IP首部不带有选项字段。服务类型为0,没有使用服务。16位总长度字段(包括IP首部和IP层payload的长度)为0x0053,即83字节,加上以太网首部14字节可知整个帧长度是97字节。IP报标识是0x9325,标志字段和片偏移字段设置为0x0000,就是DF=0允许分片,MF=0此数据报没有更多分片,没有分片偏移。TTL是0x80,也就是128。上层协议0x11表示UDP协议。IP首部校验和为0x25ec,源主机IP是c0 a8 00 37(192.168.0.55),目的主机IP是c0 a8 00 01(192.168.0.1)。
UDP首部:源端口号0x05d4(1492)是客户端的端口号,目的端口号0x0045(69)是TFTP服务的well-known端口号。UDP报长度为0x003f,即63字节,包括UDP首部和UDP层pay-load的长度。UDP首部和UDP层payload的校验和为0xac40。
TFTP是基于文本的协议,各字段之间用字节0分隔,开头的00 01表示请求读取一个文件,接下来的各字段是:
c:\qwerq.qwe
netascii
blksize 512
timeout 10
tsize 0
一般的网络通信都是像TFTP协议这样,通信的双方分别是客户端和服务器,客户端主动发起请求(上面的例子就是客户端发起的请求帧),而服务器被动地等待、接收和应答请求。客户端的IP地址和端口号唯一标识了该主机上的TFTP客户端进程,服务器的IP地址和端口号唯一标识了该主机上的TFTP服务进程,由于客户端是主动发起请求的一方,它必须知道服务器的IP地址和TFTP服务进程的端口号,所以,一些常见的网络协议有默认的服务器端口,例如HTTP服务默认TCP协议的80端口,FTP服务默认TCP协议的21端口,TFTP服务默认UDP协议的69端口(如上例所示)。在使用客户端程序时,必须指定服务器的主机名或IP地址,如果不明确指定端口号则采用默认端口,请读者查阅ftp、tftp等程序的man page了解如何指定端口号。/etc/services中列出了所有well-known的服务端口和对应的传输层协议,这是由IANA(Internet Assigned Numbers Authority)规定的,其中有些服务既可以用TCP也可以用UDP,为了清晰,IANA规定这样的服务采用相同的TCP或UDP默认端口号,而另外一些TCP和UDP的相同端口号却对应不同的服务。
很多服务有well-known的端口号,然而客户端程序的端口号却不必是well-known的,往往是每次运行客户端程序时由系统自动分配一个空闲的端口号,用完就释放掉,称为ephemeral的端口号,想想这是为什么?
前面提过,UDP协议不面向连接,也不保证传输的可靠性,例如:
发送端的UDP协议层只管把应用层传来的数据封装成段交给IP协议层就算完成任务了,如果因为网络故障该段无法发到对方,UDP协议层也不会给应用层返回任何错误信息。
接收端的UDP协议层只管把收到的数据根据端口号交给相应的应用程序就算完成任务了,如果发送端发来多个数据包并且在网络上经过不同的路由,到达接收端时顺序已经错乱了,UDP协议层也不保证按发送时的顺序交给应用层。
通常接收端的UDP协议层将收到的数据放在一个固定大小的缓冲区中等待应用程序来提取和处理,如果应用程序提取和处理的速度很慢,而发送端发送的速度很快,就会丢失数据包,UDP协议层并不报告这种错误。
因此,使用UDP协议的应用程序必须考虑到这些可能的问题并实现适当的解决方案,例如等待应答、超时重发、为数据包编号、流量控制等。一般使用UDP协议的应用程序实现都比较简单,只是发送一些对可靠性要求不高的消息,而不发送大量的数据。例如,基于UDP的TFTP协议一般只用于传送小文件(所以才叫trivial的ftp),而基于TCP的FTP协议适用于 各种文件的传输。TCP协议又是如何用面向连接的服务来代替应用程序解决传输的可靠性问题呢。
-
应用层
ftp协议
- 工作过程
-
协议传输数据上限