差分隐私随笔
隐私保护手段包括:抑制(suppression)、泛化(generalization)、置换(permutation)、扰动(perturbation)、裁剪(anatomy)等。
1.抑制:最常见的数据匿名措施,通过将数据置空的方式限制数据发布。
2.泛化:通过降低数据精度来提供匿名方法。属性泛化即通过制定泛化规则,使得多个元组的在规则下近似的取值相同。最深的属性泛化效果通常等同于抑制。社交关系数据的泛化则是将某些节点以及这些节点间的连接进行泛化。位置轨迹数据可进行时间、空间泛化。
3.置换:不对数据内容作更改,但是改变数据的属主。
4.扰动:在数据发布时添加一定的噪音,包括数据增删、变换等。
5.裁剪:将数据分开发布。
显示标识符(Explicit Identifier):能唯一标识单一个体的属性,如身份证号,姓名等。
准标识符(QID,Quasi-Identifier):联合起来就能唯一标识一个人的多个属性,如邮编,生日,性别等联合起来则可能是准标识符。
敏感属性(Sensitive Attribute):包含隐私数据的属性,如疾病,薪资等。
k-匿名:
背景:即便去除了表中的身份ID等标志性信息,攻击者仍可凭借背景知识,如地域、性别等准标识符信息,迅速确定攻击目标对应的记录。此类攻击称为记录链接(record linkage)攻击。
定义:令T(![]() )为一张具有有限行的表,属性集合为{
)为一张具有有限行的表,属性集合为{![]() }。Q
}。Q![]() 为表中的准标识符Q
为表中的准标识符Q![]() ={
={![]() }。表T满足K-匿名,当且仅当每一组准标识符的取值序列在T[QI]中出现至少k次。
}。表T满足K-匿名,当且仅当每一组准标识符的取值序列在T[QI]中出现至少k次。
L-多样化、T-贴近,M-不变性等。
社交图谱的隐私保护:节点匿名、边匿名、属性匿名。
位置轨迹隐私保护:
面向 基于位置的服务(Location Based Service,LBS)应用的隐私保护:Mix-zone在路网中的应用、隐私信息检索(PIR)在近邻查询中的应用。
隐私信息检索(private information retrieval,PIR)是指用户在不向远端服务器暴露查询意图的前提下通过特殊索引结构对服务器的数据进行查询并取得指定数据。
针对空间位置的索引构建主要基于:
1、希尔伯特曲线(Hilbert curves)
2、泰森多边形(Voronoi diagram
面向数据发布的隐私保护:针对敏感位置的隐私保护技术、(k,δ)-匿名及相关模型、LKC-匿名及相关模型、可逆位置泛化。
基于用户活动规律的攻击:马尔科夫模型及攻击、隐马尔科夫模型及攻击、混合高斯模型及攻击、贝叶斯模型及攻击、推荐系统(基于内容、基于协同过滤的推荐)模型及攻击等。
以上讨论的隐私保护机制从各个角度分别对用户隐私保护需求和攻击者的能力进行了分析,并在一定程度上解决了用户隐私保护问题。这些匿名方案对用户隐私保护需求和攻击者的能力进行了假设,其使用范围大大受限。而差分隐私保护技术作为一种不限攻击者能力,且能严格证明其安全性的隐私保护框架。对于差分隐私模型的目标,首先,攻击者无法确认攻击目标在数据集中。其次,即使攻击者确认攻击目标在数据集中,攻击目标的单条数据纪录对输出结果的影响并不显著,攻击者无法通过观察输出结果获得关于攻击目标的确切信息。
基本差分隐私:
差分隐私的核心在于其随机算法的设计,设计者首先要证明算法输出的带噪中间件满足定义,然后在满足上述标准的情况下尽量少的加入噪声。
最早用于交互式数据发布的差分隐私保护机制是Dwork等人提出的Laplace机制。
拉普拉斯机制的核心思想是通过向中间件加入拉普拉斯噪声来满足定义中的约束条件。
拉普拉斯机制对数值型查询能提供相应的保护,但无法对输出为实体结果的查询进行扰动。
拉普拉斯适用于数据查询的返回值为实数值的场合,指数机制适用于数据查询的范围值域为离散值域的场合。
指数机制中的打分函数q(D,r)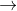 R又被称为可用性函数,用来评价查询q的输出结果r的可用性,
R又被称为可用性函数,用来评价查询q的输出结果r的可用性, q为打分函数的敏感性。如果该查询函数以正比于exp(εq(D,r)/2q)的概率从值域范围内选择输出,那么该查询函数能够提供ε-差分隐私保护。
q为打分函数的敏感性。如果该查询函数以正比于exp(εq(D,r)/2q)的概率从值域范围内选择输出,那么该查询函数能够提供ε-差分隐私保护。
本地差分隐私(Local Differential Privacy,LDP):一个随机化算法Α满足ε-LDP的条件是,在一个空间域中,对于任意的一对数据 l,l'∈Z 和任意输出O∈Range(A),都存在下列关系:Pr[ A(l)∈0]≤exp( ε). Pr[ A(I')∈0]。其中Α的概率空间是基于硬币翻转的。概率Pr[·]由算法犃的随机性控制,也表示隐私被披露的风险;隐私预算参数ε表示隐私保护程度,ε越小隐私保护程度越高
特点:本地差分隐私与差分隐私的最重要区别在于,本地差分隐私没有一个可信任的数据管理员(服务端不可信任),所以用户的真实敏感数据只会保存在自身的客户端上。
核心思想:用户先在本地将数据进行随机化处理,使其满足差分隐私条件,然后将其再上传给数据采集者(服务端),数据采集者得到添加扰动后的用户数据,经过无偏估计算法得到此所有用户的此类数据的估计值。
主要目的:是使数据保护的过程直接在用户本地进行,服务器无法获得真实隐藏数据。
本地差分隐私算法的核心是随机化算法。
本地差分隐私算法分本地算法(randomized response,input perturbation,Post Randomization Method(PRAM))和已有的统计查询(statistical query)算法等价。
RR协议提供了强隐私保护机制,用户的结果并不能作为对他们的意见或属性的推断。(例:用户对选型N选一,用户对每一个选项分别应用RR协议进行随机化,将最终的答案作为二进制发送给采集者。问题是,采用这种做法是,如果候选集很大,每个用户所需要返回的数据量巨大,且存在较大统计误差)。所以为了解决该问题并提高分析结果的准确度,提出了一系列协议。比价经典的包括Rappor协议和SH协议。
Pappor协议是一种基于RR协议的用户选项采集统计方法,提供强隐私保护机制。基本协议包括两部分:一部分发生在用户终端的本地数据随机化操作,另一部分是数据采集者对采集到的噪声数据的分析处理。
该协议的客户端部分在第一步中通过引入Bloom Filter数据结构,将海量的候选项转化为长度固定的二进制数组。
用户终端的本地随机化操作应用了两轮RR协议,第二次随机化可以防止反复查询导致的用户隐私泄露。基本内容如下:
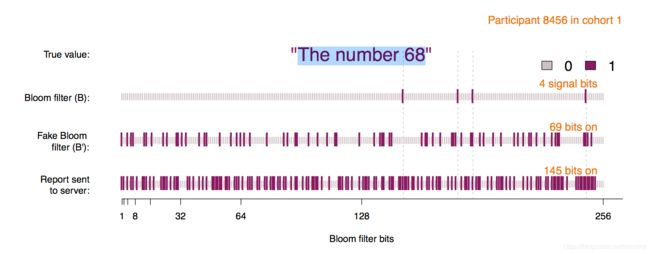
图-1 Rappor协议两次随机化过程示例
Rappor协议客户端步骤:
1.假设要求用户上传一个网站的具体网址的字符串s,用户将s存放到一个公共的布隆过滤器bloom filter中(bloom filter 的长度为k,hash函数的个数为h),得到定长序列B。
2.使用RR协议对B中的每一位进行随机化,定义一个概率f(0
3.为了防止恶意攻击者反复查询的行为,可以对B'在使用一次RR协议进行随机化,设置概率p、q。当![]() =1时,以q的概率随机化产生
=1时,以q的概率随机化产生![]() =1,当
=1,当![]() =0时,以p的概率随机化产生
=0时,以p的概率随机化产生![]() =1,。最终得到一串二进制数组S=
=1,。最终得到一串二进制数组S=![]() ,将S上传给服务器。
,将S上传给服务器。
Rappor协议服务端步骤:
1.数据采集者收集所有用户上交的S序列后,对其进行统计分析。假设服务器收集到N个用户提交的数据,数据累计后,第i位的计数为![]() ,通过最大似然将
,通过最大似然将![]() 修正为
修正为![]() 。
。
2.修正后的各个![]() 组成结果M维向量Y,设计单位矩阵X(k * M),M是类别候选项的数目,单位矩阵的每一行都是一个候选项的bloom filter 正确结果。可以看出X是一个稀疏矩阵,每一行都只有h个位的结果为1。利用Lasso回归可以拟合Y~X这个模型得到相应的系数,此系数就是候选项的频数。
组成结果M维向量Y,设计单位矩阵X(k * M),M是类别候选项的数目,单位矩阵的每一行都是一个候选项的bloom filter 正确结果。可以看出X是一个稀疏矩阵,每一行都只有h个位的结果为1。利用Lasso回归可以拟合Y~X这个模型得到相应的系数,此系数就是候选项的频数。
SH协议是一个典型的热门选项挖掘和频率估计的协议。与Rappor协议中的随机化处理算法有所不同,SH协议中的随机化处理采用了一种非对称的方式。
SH协议能够达到和Rappor协议相同的频率估计的目的,其基本步骤如下:
1. 服务端基于Johnson-Lindenstrauss引理生成一个m位的 {−1,1}{(-1)/√m,1/√m }^m,用X表示公开向量。
2. 客户端中随机在m位中均匀概率选取一位 Xj(索引为j),若用户包含这个候选项,以e^ε∕〖(1+〗 e^ε)的概率则返回Xj,以1∕(1+ e^ε)的概率返回 -Xj。若用户不包含这个候选项,则以1/2的概率返回 Xj。同时用户还要加上索引j返回给服务器。
3.服务端计算所有用户的返回结果得到一个平均m位向量Z,用Z和原始的X相似度比较,这个相似度可以转换为该候选项的频率,误差在可控范围内。
SH协议和Rappor协议的3个区别:
1. SH协议客户端部分,仅要求用户对自己拥有的候选项做RR处理,而其他的候选项以均匀50%概率返回给服务器;
2. 服务器端不需要对收集到的信息的数目进行概率修正,而可以利用一种纠错码机制,让其自动修正;
3. SH 可以应用于用户数量小于heavy hitters 取值空间的情形,同时用户终端向服务器传输的信息量可以优化为1-bit,大大减少数据传输量。
基于差分隐私的轨迹隐私保护:
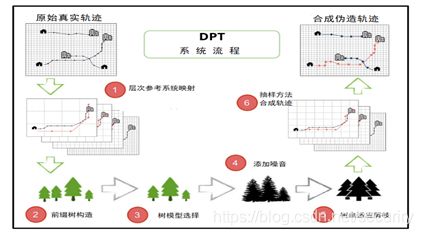
集中式差分隐私轨迹保护方法:DPT(Differential Private Trajectory)将所有用户轨迹汇集成轨迹数据集,在保持数据集总体统计特征稳定的基础上,产生新的轨迹来替代原始轨迹,且新数据集满足差分隐私安全定义。系统采用前缀树(Prefix Tree)结构来描述所有轨迹集合,对该树上的节点进行加噪处理与剪枝处理后,抽样合成新轨迹。
本地差分隐私轨迹保护方法:
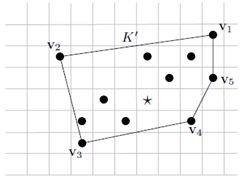
满足差分隐私的K-Norm轨迹分享方法:用户只在本地保存真实轨迹数据,在提交轨迹信息之前,依次按照时序顺序对每一个地理位置点随机化处理,以满足差分隐私的K-Norm方法添加干扰。处理后的地理位置点重新连接成一条轨迹,用户只将这生成的轨迹上传给服务器。
图中五角星是一个真实的地理位置,所有的黑点是随机化可能发布的地理位置,K-Norm就是将这些可能的随机化位置用一个凸形包括起来,然后依照规则以一定概率选取待发布的地理位置替代真实的地理位置(五角星)。
ps:本文来自冯国登老师大数据与隐私保护一书,请自行参考。