SparkSQL概述、6种不同数据格式创建DataFream方式、3种函数
SparkSQL概述、6种不同数据格式创建DataFream方式、3种函数
一、SparkSQL简述
1 SparkSQL产生
Hive->Shark->SparkSQL
Shark Hive on Spark Hive即作为存储又负责sql的解析优化,Spark负责执行
SparkSQL Spark on Hive Hive只作为储存角色,Spark负责sql解析优化,执行
SparkSQL产生的根本原因是为了完全脱离Hive限制(解耦)
2 SparkSQL特点
SparkSQL兼容所有的Hive和Shark语法
SparkSQL支持查询原生的RDD。 RDD是Spark平台的核心概念,是Spark能够高效的处理大数据的各种场景的基础
能够在Scala中写SQL语句。支持简单的SQL语法检查,能够在Scala中写Hive语句访问Hive数据,并将结果取回作为RDD使用--------> df.rdd + val age: Long = row.getAs[Long] (“age”)
使用DataFrame分布式容器
3-1 DataFrame分布式数据容器
DataSet = DataFream
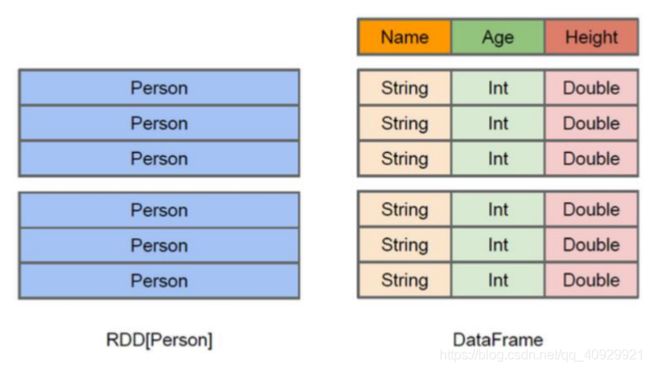
DataFrame也是一个分布式数据容器,与RDD类似
DataFrame更像一张二维表格,有数据也有列的Schema信息–数据的结构信息
DataFrame与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)
DataFrame的底层封装的是RDD,只不过RDD的泛型是Row类型
想要使用SQL查询分布式数据,必须创建DataFream,而后可以注册视图,使用SQL查询
DataFrame转化成RDD df.rdd
3-2 DateSet-区别RDD与创建
1 SparkCore底层操作的是RDD,SparkSQL底层操作的是DataSet
2 序列化机制与RDD不同,可以不用反序列化成对象再去调用该对象中的方法
3 在RDD的基础上增加了一些方法
4 强类型,类似于DataFream,默认列名是“value”
5 三种创建方法
a 由集合 创建DataSet
1 Person对象
//直接映射成Person类型的DataSet
val list = List[Person](
Person(1,"zhangsan",18,100),
Person(2,"lisi",19,200),
Person(3,"wangwu",20,300)
)
val personDs: Dataset[Person] = list.toDS()
personDs.show(100)
2 集合
val value: Dataset[Int] = List[Int](1, 2, 3, 4, 5).toDS()
value.show()
b 由json文件和类 直接映射成DataSet
val lines: Dataset[Student] = spark.read.json("./Test_spark/data/json").as[Student]
c 读取外部文件 直接加载DataSet
val dataSet: Dataset[String] = spark.read.textFile("./Test_spark/data//people.txt")
val result: Dataset[Person] = dataSet.map(line => {
val arr: Array[String] = line.split(",")
Person(arr(0).toInt, arr(1).toString, arr(2).toInt, arr(3).toDouble)
})
result.show()
4 SparkSQL数据源
JSON类型的字符串,JDBC,Parquent,Hive,HDFS等
5 SparkSQL底层架构
首先拿到sql后解析一批未被解决的逻辑计划,再经过分析得到分析后的逻辑计划,再经过一批优化规则转换成一批最佳优化的逻辑计划,再经过SparkPlanner的策略转化成一批物理计划,随后经过消费模型转换成一个个的Spark任务执行
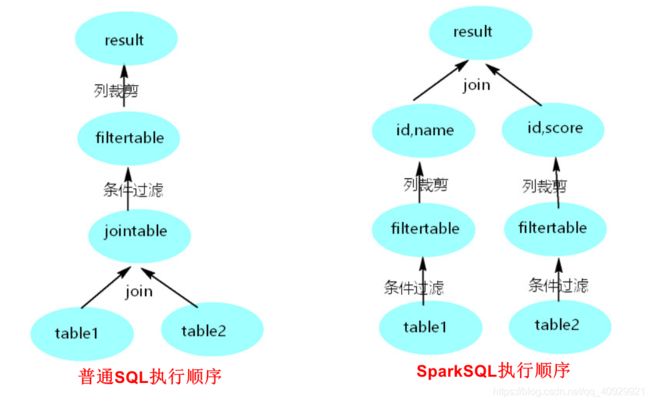
6 谓词下推-优化job
以下列语句为例:
SELECT table1.name,table2.score FROM table1
Join table2 ON(table1.id=table2.id)
WHERE table1.age>50 AND table2.score>90
二、创建DataFrame的方式
1 读取json格式文件
注意事项
Ø json中的属性名自动成为列,列的类型会自动推断
Ø 注册成临时表时,表中的列默认按ASCII顺序显示列
Ø 创建临时表的2种方式
createOrReplaceTempView /createGlobalTempView
createGlobalTempView可以跨session
Ø json文件中的json数据可以嵌套json格式数据(2.0+)
Ø DataFrame是一个一个Row类型的RDD,df.rdd()/df.javaRdd()
Ø 读取json格式文件的2种方式
DataFream df = sqlContext.read().json("/xx/xx"); sparkSession.read().json(“路径”)
DataFream df = sqlContext.read().format("/xx/xx"); sparkSession.read().format(“json”).load(“路径”)
Ø df.show()默认显示前20行数据
Ø DataFrame原生API可以操作DataFrame(不方便)
1.6版本
//1.6版本
object Sql1_6Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("sql1_6Test")
val sc = new SparkContext(conf)
sc.setLogLevel("Error")
val sqlContext = new SQLContext(sc = sc)
//给定读取格式化的类型和路径
val df: DataFrame = sqlContext.read.format("json").load("./Test_spark/data/json")
//查看数据,可能有行数的显示限制,若全显示,要添加参数df.show(1000)
df.show()
//拿取前10行
df.take(10).foreach(println)
//打印列名和列中存储数据的类型
df.printSchema()
//查看固定的数据(数组形式)
//1在getAs[列数据类型]("列名")
//2在getAs(下标索引) 注意这时的下标索引是ASCII码排序的,不是表中列存放的位置 所以不常使用
// val name: String = row.getAs(1)
// val age: Long = row.getAs(0)
//3直接get(下标索引)
//将DataFream格式转换成RDD格式 [xxx,xxxx]
val rdd3: RDD[Row] = df.rdd
//拿取转换后的RDD数据
rdd3.foreach(row=>{
val name: String = row.getAs[String]("name")
val age: Long = row.getAs[Long]("age")
println(s"name= $name,age=$age")
})
}
}
2.0版本
//2.0版本
object Sql2_3Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("sql2_3Test").master("local").getOrCreate()
val df: DataFrame = spark.read.format("json").load("./Test_spark/data/json")
df.show(100)
df.printSchema()
}
}
2 读取嵌套json
explode(“嵌套的属性名”)
导入隐式转换
$–自动转换
json格式1
{“name”:“wangwu”,“score”:80,“infos”:{“age”:23,“gender”:‘man’}}
frame.createOrReplaceTempView("infosView")
spark.sql("select name,infos.age,score,infos.gender from infosView").show(100)
json格式2
{“name”:“zhangsan”,“age”:18,“scores”:[{“yuwen”:98,“shuxue”:90,“yingyu”:100},{“yuwen”:90,“shuxue”:78,“yingyu”:100}]}
//不折叠显示
frame.show(false)
frame.printSchema()
//必须导入隐式
import org.apache.spark.sql.functions._
import spark.implicits._
val transDF: DataFrame = frame.select($"name", $"age", explode($"scores")).toDF("name", "age","allScores")
transDF.show(100,false)
transDF.printSchema()
val result: DataFrame = transDF.select($"name",$"age",
$"allScores.yuwen" as "yuwen",
$"allScores.shuxue" as "shuxue",
$"allScores.yingyu" as "yingyu",
)
result.show(100)
3 读取RDD格式—2种
1反射的方式
注意
记得导入隐式包 import spark.implicits._
将对象中的属性自动映射成DataFrame中的列
将对象中属性的类型自动映射成DataFrame中列的Schema
people.txt数据格式:
1,zhangsan,18,100
2,lisi,19,200
3,wangwu,20,300
4,zhaoliu,30,300
val spark = SparkSession.builder().master("local").appName("createDataFrameFromRDDWithReflection").getOrCreate()
import spark.implicits._
/**
* 直接读取文件为RDD
*/
val rdd: RDD[String] = spark.sparkContext.textFile("./Test_spark/data/people.txt")
val personDs: RDD[Person] = rdd.map(one => {
val arr = one.split(",")
Person(arr(0).toInt, arr(1).toString, arr(2).toInt, arr(3).toDouble)
})
val frame: DataFrame = personDs.toDF()
frame.show()
2动态创建Schema
注意
自动将Row类型RDD中的每个位置数据,映射成每列的数据
Row中数据的顺序要和构建StructField中列的顺序保持一致
val spark = SparkSession.builder().master("local").appName("createdataframefromrddwithschema").getOrCreate()
val peopleRDD: RDD[String] = spark.sparkContext.textFile("./Test_spark/data/people.txt")
/**
* 将peopleRDD转换成RDD[Row]
*/
val rowRDD: RDD[Row] = peopleRDD.map(one => {
val arr: Array[String] = one.split(",")
Row(arr(0).toInt, arr(1), arr(2).toInt, arr(3).toLong)
})
val structType: StructType = StructType(List[StructField](
StructField("id", IntegerType, nullable = true),
StructField("name", StringType, nullable = true),
StructField("age", IntegerType, nullable = true),
StructField("score", LongType, nullable = true)
))
val frame: DataFrame = spark.createDataFrame(rowRDD,structType)
frame.show()
frame.printSchema()
4 读取parquest格式
parquest格式的数据内部是经过压缩的,直接查看可能会是乱码
val spark = SparkSession.builder().master("local").appName("createdataframefromparquet").getOrCreate()
val df1: DataFrame = spark.read.json("./Test_spark/data/json")
df1.show()
/**
* 将 DataFream数据 保存成 parquet文件(有自己的压缩格式,是乱码的)
*/
df1.write.mode(SaveMode.Append).format("parquet").save("./Test_spark/data/parquet")
/**
* 读取parquet文件
*/
val df2: DataFrame = spark.read.parquet("./Test_spark/data/parquet")
df2.show()
5 读取MySQL数据—4种
val spark = SparkSession.builder().master("local").appName("createdataframefrommysql")
//设置执行join等操作运行的task数量,默认是200
.config("spark.sql.shuffle.partitions",1)
.getOrCreate()
1 读取mysql表第一种方式
直接连接
/**
* 读取mysql表第一种方式
*/
val properties = new Properties()
properties.setProperty("user", "root")
properties.setProperty("password", "123")
val person: DataFrame = spark.read.jdbc("jdbc:mysql://sxt001:3306/spark","person",properties)
person.show()
2 读取mysql表第二种方式
将连接的参数封装map,再option(map).load()连接
/**
* 读取mysql表第二种方式
*/
val map = Map[String,String](
//"K" -> "V"
"url"->"jdbc:mysql://sxt001:3306/spark",
//要在pom.xml文件中指定连接的驱动包
"driver"->"com.mysql.jdbc.Driver",
"user"->"root",
"password"->"123",
"dbtable"->"score"//表名
)
val score: DataFrame = spark.read.format("jdbc").options(map).load()
score.show()
3 读取mysql表第三种方式
将连接参数option给连接对象,再.load()连接
/**
* 读取mysql数据第三种方式
*/
val reader: DataFrameReader = spark.read.format("jdbc")
.option("url", "jdbc:mysql://sxt001:3306/spark")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "123")
.option("dbtable", "score")
val score2: DataFrame = reader.load()
score2.show()
4 读取mysql关联表第四种方式
数据库的关联表
/**
* 读取mysql中数据的第四种方式
*/
val properties = new Properties()
properties.setProperty("user", "root")
properties.setProperty("password", "123")
spark.read.jdbc("jdbc:mysql://sxt001:3306/spark","(select person.id,person.name,person.age,score.score from person ,score where person.id = score.id) T",properties).show()
执行操作
//将以上两张表注册临时表,关联查询
person.createOrReplaceTempView("person")
score.createOrReplaceTempView("score")
spark.sql("select person.id,person.name,person.age,score.score from person ,score where person.id = score.id").show()
//将结果保存在Mysql表中,String 格式的数据在MySQL中默认保存成text格式,如果不想使用这个格式 ,可以自己建表创建各个列的格式再保存。
val result: DataFrame = spark.sql("select person.id,person.name,person.age,score.score from person ,score where person.id = score.id")
result.write.mode(SaveMode.Append).jdbc("jdbc:mysql://sxt001:3306/spark", "result", properties)
6 读取Hive数据
SparkSession.enableHiveSupport
一般情况不推荐本地运行
student_infos文件数据:
zhangsan 18
lisi 19
wangwu 20
student_scores文件数据:
zhangsan 100
lisi 200
wangwu 300
val spark = SparkSession.builder().appName("CreateDataFrameFromHive").enableHiveSupport().getOrCreate()
spark.sql("use spark")
spark.sql("drop table if exists student_infos")
spark.sql("create table if not exists student_infos (name string,age int) row format delimited fields terminated by '\t'")
spark.sql("load data local inpath '/root/data/student_infos' into table student_infos")
spark.sql("drop table if exists student_scores")
spark.sql("create table if not exists student_scores (name string,score int) row format delimited fields terminated by '\t'")
spark.sql("load data local inpath '/root/data/student_scores' into table student_scores")
val df = spark.sql("select si.name,si.age,ss.score from student_infos si,student_scores ss where si.name = ss.name")
spark.sql("drop table if exists good_student_infos")
//将结果写入到hive表中
df.write.mode(SaveMode.Overwrite).saveAsTable("good_student_infos")
三、函数
UDF
用户自定义函数 1:1
val spark = SparkSession.builder().master("local").appName("UDF").getOrCreate()
val nameList: List[String] = List[String]("zhangsan", "lisi", "wangwu", "zhaoliu", "tianqi")
import spark.implicits._
val nameDF: DataFrame = nameList.toDF("name")
nameDF.createOrReplaceTempView("students")
spark.udf.register("STRLEN",(n:String)=>{
n.length
})
spark.sql("select name ,STRLEN(name) as length from students sort by length desc").show(100)
UDAF
用户自定义聚合函数 n:1
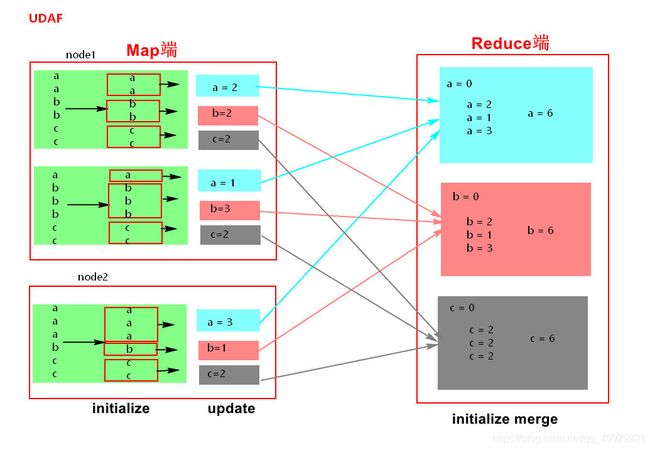
聚合函数,要继承UserDefinedAggregateFunction(),实现8个方法,最重要的三个方法
initialize update merge
lass MyUDAF extends UserDefinedAggregateFunction {
//输入数据的类型
def inputSchema: StructType = {
DataTypes.createStructType(Array(DataTypes.createStructField("uuuu", StringType, true)))
}
// 为每个分组的数据执行初始化值 2次
// 1 在map端每个EDD分区内按照group by的字段分组,每个分组都有一个初始化的值 新数据没加入前是0
// 2 在reduce端的每个group by的分组做初识值
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0
}
// 每个组,有新的值进来的时候,进行分组对应的聚合值的计算
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer(0) = buffer.getAs[Int](0)+1
}
// 最后merger的时候,在各个节点上的聚合值,要进行merge,也就是合并
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getAs[Int](0)+buffer2.getAs[Int](0)
}
// 聚合操作时,所处理的数据的类型
def bufferSchema: StructType = {
DataTypes.createStructType(Array(DataTypes.createStructField("xxxs", IntegerType, true)))
}
// 最后返回一个最终的聚合值要和dataType的类型一一对应
def evaluate(buffer: Row): Any = {
buffer.getAs[Int](0)
}
// 最终函数返回值的类型
def dataType: DataType = {
DataTypes.IntegerType
}
//多次运行 相同的输入总是相同的输出,确保一致性
def deterministic: Boolean = {
true
}
}
object UDAF {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local").appName("UDAF").getOrCreate()
val nameList: List[String] = List[String]("zhangsan", "lisi", "wangwu", "zhangsan", "lisi", "zhangsan", "wangwu")
import spark.implicits._
val frame: DataFrame = nameList.toDF("name")
frame.createOrReplaceTempView("students")
/**
* 注册UDAF函数
*/
spark.udf.register("NAMECOUNT",new MyUDAF())
spark.sql("select name,NAMECOUNT(name) as count from students group by name").show(100)
开窗函数–over
按照某一列的参数,排序其他的一列,使用开窗函数比较简单
依照类型排价格
日期、类型、价格
1 B 6
1 C 7
1 A 8
1 D 9
1 F 10
2 B 11
2 D 12
2 A 13
2 E 14
val spark = SparkSession.builder().appName("over").enableHiveSupport().getOrCreate()
spark.sql("use spark")
spark.sql("create table if not exists sales (riqi string,leibie string,jine Int) " + "row format delimited fields terminated by '\t'")
spark.sql("load data local inpath '/root/data/sales' into table sales")
//rank 在每个分组内从1开始
val result = spark.sql(
"select"
+" riqi,leibie,jine "
+ "from ("
+ "select "
+"riqi,leibie,jine," + "row_number() over (partition by leibie order by jine desc) rank "
+ "from sales) t "
+ "where t.rank<=3")
result.write.mode(SaveMode.Append).saveAsTable("salesResult")
result.show(100)
附:Scala版本区别–1.6和2.0+
a 创建对象的调用不一样
1.6 在创建连接对象不一样SparkContext,SQLContext等都需要单独创建
2.0+ 都封装在SparkSession中,使用的是SparkSession
b 得到DateFrame后注册临时表不一样
1.6 df.registerTempTable
2.0+ df.createOrReplaceTempView 或 df.createGlobalTempView