ElasticSearch——入门
ElasticSearch——入门
- 前言
- Elasticsearch介绍
- 安装Elasticsearch
- 基本操作
-
- 数据格式
- HTTP方式
-
- 1、索引操作
- 2、文档操作
- JAVA Api方式
-
- 1、索引操作
- 2、文档操作
-
- 单个文档操作
- 批量操作
- 高级查询
- ElasticSearch 环境
-
- 集群
- Windows 集群部署
- Linux单节点部署
- Linux集群部署
- end...
前言
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎,它能帮我们安全可靠地获取任何来源、任何形式的数据,然后实时地对数据进行搜索、分析和可视化,ELK分布式日志解决方案中的E就是它。当然,我们在全网站搜索内容时,也需要用到它。文章课程链接:ElasticSearch教程入门到精通
Elasticsearch介绍
谈到Elasticsearch,我们就想起了Solr,Elasticsearch和Solr都是基于Lucene开发完成的,他们俩都是不错的搜索引擎,但Elasticsearch比起Solr在许多方面表现的更好,例如
统计分析能力
良好可伸缩性以及性能分布式环境
监控和指标上,Elasticsearch暴露更多的关键指标
因此,我们肯定更多的是选择Elasticsearch,而他也被许多公司所青睐,GitHub、百度、阿里、新浪等都有使用
安装Elasticsearch
下载地址 https://www.elastic.co/cn/elasticsearch/,
下载windows版本,然后解压,解压后有几个目录,都比较常见了,简单说一下
bin 可执行的脚本文件
config 配置文件
jdk 基于java开发,因此内置有,但我们一般使用自己的环境
lib jar包 剩下还有日志、模块、插件等
在bin目录下有一个elasticsearch.bat的文件,双击它,我们就启动了elasticsearch,启动完成后,我们可以通过地址 http://localhost:9200 访问,如果有返回,则是成功了,这里注意两个端口
9300:为ElasticSearch集群间组件的通信端口,
9200:为浏览器访问的http端口
如果启动不成功可能是jdk版本和配置的问题,在操作前,我们先下载好postman
基本操作
数据格式
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,这里为了方便理解,我们贴张图,注意,在Elasticsearch7.x后,type的概念已经被删除了
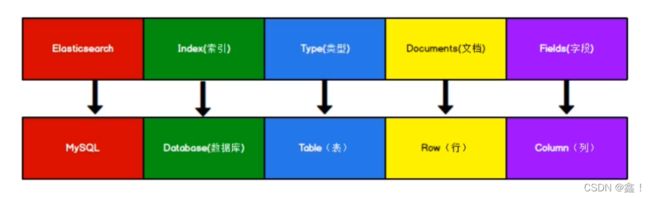
我们都知道,优化mysql查询速度最常见的就是加索引,Elasticsearch之所以这么快,也是因为有了索引,这里引入两个概念,正排索引和倒排索引,而Elasticsearch就运用了倒排索引
正排(正向)索引:比如我们的mysql存储了用户信息,我们可以通过查询主键id快速得到相应的用户信息
倒排索引:如果我们要获取用户信息名字中含有“鑫”字的,那么就需要模糊查询,效率就很低了,所以我们可以先将“鑫”字作为关键字存储,关联名字含有“鑫”的记录id,查询时,我们查询到“鑫”字对应的id,然后在拿到id去查询用户信息,这样就很快了
如表
| id | name | age | keyword | id | |
|---|---|---|---|---|---|
| 666 | 李文鑫 | 18 | 鑫 | 666 |
HTTP方式
1、索引操作
操作前,我们要知道,Restful风格的请求格式
GET 获取
POST 新增
PUT 修改
DELETE 删除
当我们的操作为幂等性操作(操作多少次返回的结果都一样),可以使用put、post,当为非幂等性时,只能使用post
索引可以理解为mysql的数据库,操作索引相当于操作我们的数据库,这样就比较简单了
首先,我们启动Elasticsearch,点击bin目录下的elasticsearch.bat,然后就启动了
- 创建索引
使用postman软件发送put请求即可,请求地址为
http://127.0.0.1:9200/索引名称
http://127.0.0.1:9200/shopping
请求后返回json字符串,“acknowledge”:true,代表成功,如果我们再次请求,返回就会提示已经存在了
- 获取索引
不难想到,我们不用改变请求地址,直接将请求方式换为get即可,返回信息包括创建时间、版本号、uuid等,我们后面进行详细的学习
当然我们也可以获取当前ES中全部的索引信息
http://127.0.0.1:9200/_cat/indices?v
- 删除索引
将 http://127.0.0.1:9200/shopping 请求的方式改为delete即可,“acknowledge”:true为成功
2、文档操作
因为高版本的ES已经移除了Type(表)的概念,我们直接操作文档(行)
- 创建文档
使用postman发送post请求,请求地址为
http://127.0.0.1:9200/索引名称/文档名称
http://127.0.0.1:9200/shopping/_doc
因为是插入数据,因此,我们还需要传输数据,数据格式为JSON,如下
{
"name":"csgo",
"age":"23"
}
postman下,传输json数据的选择为Body->raw,然后在右边选择JSON,请求返回 “result”:“created”,则为成功,返回结果还包含ES随机帮我们生成的_id(每次不一样),如果我们想自定义id,则请求时在地址后加上/id
http://127.0.0.1:9200/shopping/_doc/1001 id则为1001
注意:当我们不自定义id时,每次请求的结果都不一样(非幂等性),因此只能使用post请求,当我们定义了id时,每次请求的结果是一样的(幂等性),因此,我们可以使用put和post
- 获取文档
单个获取:get请求地址
_doc是查询文档的意思,1001为id
http://127.0.0.1:9200/shopping/_doc/1001
获取全部
http://127.0.0.1:9200/shopping/_search
- 修改文档
修改分为覆盖性和局部,覆盖性用的不多
覆盖性修改:put请求原文档地址,并写入新的JSON数据
http://127.0.0.1:9200/shopping/_doc/1001
数据
{
"name":"LOL",
"age":"23"
}
返回 “result”:“updated” 则修改成功
局部修改:post请求地址,_doc 改为了 _update,传输的JSON数据格式变化
http://127.0.0.1:9200/shopping/_update/1001
数据
{
"doc":{
"name":"CF"
}
}
这样就能完成局部更新了,且版本号会变化,因此不为幂等性操作,必须使用post
- 删除文档
delete请求
http://127.0.0.1:9200/shopping/_doc/1001
- 查询文档
条件查询:在获取中,我们讲了简单的通过id获取文档,这里我们使用条件进行查询,如,查询name为CF的文档,get请求
_search:代表查询,q:代表条件,name:文档数据的key,CF:文档数据的value
http://127.0.0.1:9200/shopping/_search?q=name:CF
然后就能查到所有name包含C或F的文档了(只查CF为 match_phrase),当然,这样操作是比较麻烦的,因此,我们可以通过JSON数据来设置条件
get请求
http://127.0.0.1:9200/shopping/_search
条件数据,match代表匹配
{
"query":{
"match":{
"name":"CF"
}
}
}
分页查询:地址不变,条件数据改变,from等同page,如下
{
"query":{
"match_all":{
}
},
"from":0,
"size":5
}
结果筛选:如果我们不想像 select * 那样获取全部的数据,我们可以这样操作,“【】”中代表需要的数据
{
"query":{
"match_all":{
}
},
"from":0,
"size":5,
"_source":["name"]
}
排序:按照年龄进行排序
{
"query":{
"match_all":{
}
},
"from":0,
"size":5,
"_source":["name"],
"sort":{
"age":{
"order":"desc"
}
}
}
多条件查询:前面的查询,我们展示的是单条件查询,多条件 must为数据,里面为查询条件
{
"query":{
"bool":{
"must":[
{
"match":{
"name":"CF"
}
},
{
"match":{
"age":"23"
}
},
// 查询年龄为23,名字为CF的
{
"match":{
"name":"CSGO"
}
}
// 查询年龄为23,名字为CF或者CSGO的
],
"filter":{
"range":{
"age":{
"gt":23
}
}
}
// 筛选年龄 > 23 的
}
}
}
当我们将查询的条件名字 CF 改为 C,是一样能查询到的,原因就是ElasticSearch使用了倒排索引,存储时就把我们的数据拆分做成了倒排索引,查询时做全文检索,match是全文匹配,当我们想要完全匹配时,需要将match换成match_phrase,例子如下
// 查询名字叫
{
"query":{
"match_phrase":{
"name":"CS"
}
},
// highlight:高亮显示查询出的指定数据
"highlight":{
"fields":{
"name":{}
}
}
}
聚合查询:将结果分组,如下为对年龄进行分组
{
"aggs":{ // 聚合操作
"price_group":{ // 名称,自定义
"terms":{ // 分组
"field":"arg" // 分组字段
}
}
},
"size":0 // 不显示原始数据
}
{
"aggs":{ // 聚合操作
"price_avg":{ // 名称,自定义
"avg":{ // 求平均值
"field":"arg" // 平均值
}
}
},
"size":0 // 不显示原始数据
}
映射关系:配置哪些可以拆分索引,哪些不能,哪些不能作为查询条件等
{
"properties":{
"name":{
"type":"text",
"index":true // 拆分索引,名字为“小周”时,查询“小”或者“周”都能查的到
},
"sex":{
"type":"keyword",
"index":true // 关键字,不可拆分,性别为“man”时,只可通过“man”才能查的到
},
"tel":{
"type":"keyword",
"index":false // false,不可以用tel进行查询,当用tel进行查询时,返回错误提示
}
}
}
JAVA Api方式
ElasticSearch是由java开发的,我们能使用postman调用,当然也可以使用java来调用,先创建一个maven工程,然后引入如下坐标,引入jar包
<dependencies>
<dependency>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
<version>7.8.0version>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
<version>7.8.0version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-apiartifactId>
<version>2.8.2version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-coreartifactId>
<version>2.8.2version>
dependency>
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-databindartifactId>
<version>2.9.9version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
dependency>
dependencies>
然后我们创建一个类,添加main方法,连接ES
// TransportClient已经被标识为过期,后面也会被移除
// 创建ES客户端
RestHighLevelClient esClient = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
// 操作索引,文档操作等在这里写
// 关闭连接ES客户端
esClient.close();
1、索引操作
- 创建索引
我们连接上ES后,就可以开始创建索引等操作了,操作完后记得关闭连接
//创建索引
CreateIndexRequest user = new CreateIndexRequest("user");
CreateIndexResponse response = esClient.indices().create(user, RequestOptions.DEFAULT);
//响应状态
boolean acknowledged = response.isAcknowledged();
创建后,可以通过postman获取一下索引,发现成功创建
- 获取索引
//查询索引
GetIndexRequest request = new GetIndexRequest("shopping");
GetIndexResponse getIndexResponse = esClient.indices().get(request, RequestOptions.DEFAULT);
// 获取相应的信息
System.out.println(getIndexResponse.getAliases());
System.out.println(getIndexResponse.getMappings());
System.out.println(getIndexResponse.getSettings());
- 删除索引
DeleteIndexRequest request = new DeleteIndexRequest("user");
AcknowledgedResponse response = esClient.indices().delete(request, RequestOptions.DEFAULT);
2、文档操作
文档操作前编写一个User类,属性有name 、sex、age等,先演示单个操作
单个文档操作
- 创建文档
// 插入数据
IndexRequest request = new IndexRequest();
request.index("user").id("1001");
User user = new User();
user.setName("zx");
user.setAge(23);
user.setSex("男");
// es插入数据需要JSON格式
ObjectMapper mapper = new ObjectMapper();
String userJson = mapper.writeValueAsString(user);
request.source(userJson, XContentType.JSON);
IndexResponse response = esClient.index(request, RequestOptions.DEFAULT);
System.out.println(response.getResult());
- 修改文档
// 修改数据
UpdateRequest request = new UpdateRequest();
request.index("user").id("1001");
request.doc(XContentType.JSON, "name", "xz");
UpdateResponse response = esClient.update(request, RequestOptions.DEFAULT);
System.out.println(response.getResult());
- 查询文档
// 查询数据,根据id查
GetRequest request = new GetRequest();
request.index("user").id("1001");
GetResponse response = esClient.get(request, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());
- 文档删除
DeleteRequest request = new DeleteRequest();
request.index("user").id("2001");
DeleteResponse response = esClient.delete(request, RequestOptions.DEFAULT);
批量操作
- 批量创建文档
// 批量插入数据
BulkRequest request = new BulkRequest();
IndexRequest source1 = new IndexRequest().index("user").id("2001").source(XContentType.JSON, "name", "LOL", "age", 16, "sex", "无");
IndexRequest source2 = new IndexRequest().index("user").id("2002").source(XContentType.JSON, "name", "CF", "age", 17, "sex", "无");
IndexRequest source3 = new IndexRequest().index("user").id("2003").source(XContentType.JSON, "name","CSGO", "age", 18, "sex", "无");
request.add(source1);
request.add(source2);
request.add(source3);
BulkResponse response = esClient.bulk(request, RequestOptions.DEFAULT);
System.out.println(response.getTook());
System.out.println(Arrays.toString(response.getItems()));
- 批量删除
BulkRequest request = new BulkRequest();
// 通过id删除
DeleteRequest source1 = new DeleteRequest().index("user").id("2001");
DeleteRequest source2 = new DeleteRequest().index("user").id("2002");
DeleteRequest source3 = new DeleteRequest().index("user").id("2003");
request.add(source1);
request.add(source2);
request.add(source3);
BulkResponse response = esClient.bulk(request, RequestOptions.DEFAULT);
高级查询
- 全查询
// 全量查询
SearchRequest request = new SearchRequest();
request.indices("user");
SearchSourceBuilder query = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());
request.source(query);
SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
System.out.println(hits.getTotalHits());
System.out.println(response.getTook());
for (SearchHit hit : hits) {
System.out.println(hit);
}
- 条件查询
// 条件查询,变换全查询的这行代码
SearchSourceBuilder query = new SearchSourceBuilder().query(QueryBuilders.termQuery("age", 18));
// 分页查询,变换全查询的这行代码
SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());
builder.from(0);
builder.size(2);
// 排序,和上面的一样
SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());
builder.sort("age", SortOrder.ASC); // 降序
// 过滤字段
SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());
String[] excludes = {}; // 排除
String[] includes = {"name"}; // 包含
builder.fetchSource(includes, excludes); // 只显示name
- 组合查询
// 替换全查询的部分代码
SearchSourceBuilder builder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(QueryBuilders.matchQuery("age", 18)); // 必须匹配
boolQueryBuilder.mustNot(QueryBuilders.matchQuery("sex", "男")); // 必须不是
boolQueryBuilder.should(QueryBuilders.matchQuery("age", "16")); // 年龄16或者18
boolQueryBuilder.should(QueryBuilders.matchQuery("age", "18"));
builder.query(boolQueryBuilder);
// 范围查询
SearchSourceBuilder builder = new SearchSourceBuilder();
RangeQueryBuilder rangeQuery = QueryBuilders.rangeQuery("age"); // boolQuery替换rangeQuery
rangeQuery.gte(18); // >=18
rangeQuery.lte(18); // <=18
builder.query(rangeQuery);
- 模糊查询
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.fuzzyQuery("name", "zx").fuzziness(Fuzziness.ONE)); // ONE:偏差几个字 符,ONE能够查到zxx,xzx,TWO:zxx1、yzxz
- 高亮查询
// 高亮查询
SearchSourceBuilder builder = new SearchSourceBuilder();
TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery("name", "zx");
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("");
highlightBuilder.preTags("");
highlightBuilder.field("name");
builder.highlighter(highlightBuilder);
builder.query(termsQueryBuilder);
- 聚合查询
SearchSourceBuilder builder = new SearchSourceBuilder();
AggregationBuilder aggregationBuilder = AggregationBuilders.max("maxAge").field("age"); // 最大年龄 .min 最小
builder.aggregation(aggregationBuilder);
// 分组
SearchSourceBuilder builder = new SearchSourceBuilder();
AggregationBuilder aggregationBuilder = AggregationBuilders.terms("ageGroup").field("age"); // 按年龄分组,显示每个年龄的个数
builder.aggregation(aggregationBuilder);
ElasticSearch 环境
前面我们学习ElasticSearch的安装和基本的操作,我们安装的ElasticSearch是单机的,而ElasticSearch的一个优点就是分布式集群,下面就来实际操作下
集群
一个集群就是由一个或多个服务器节点组织在一起,共同持有整个的数据,并一起提供索引和搜索功能,一个ElasticSearch集群有一个唯一的名字标识,增名字默认为“elasticsearch”。这个名字很重要,因为一个节点只能通过指定某个集群的名字,来加入这个集群。
Windows 集群部署
在部署前,我们需要将前面已经安装的ElasticSearch做处理,删除其data目录(数据),删除已存储的日志(进入logs,删除logs中的所有数据)
下面开始配置,打开config的elasticSearch.yml文件,打开发现全是注释掉的内容,我们需要打开以下内容
第一个节点配置
# 集群名称,节点的名称要一致,代表是这个集群的
cluster.name: my-elasticsearch
# 节点名称
node.name: node-1001
node.master: true
node.data: true
# ip地址
network.host: localhost
# 端口
http.port: 1001
# tcp监听端口
transport.tcp.port: 9301
# 跨域设置
http.cors.enabled: true
http.cors.allow-origin: "*"
配置好后保存,点击 bin/elasticsearch.bat,启动ElasticSearch,启动完成后,我们可以查看健康状态,postman GET请求,返回 “status”:“green” 为正常
http://localhost:1001/_cluster/health
第二个节点配置
我们将ElasticSearch复制一份,将其改名,第一个节点改名为 node-1001,这个改名为 node-1002,同样先删除掉数据文件data和产生的日志文件,然后配置elasticsearch.yml
# 和前面一致
cluster.name: my-elasticsearch
# 节点名称
node.name: node-1002
node.master: true
node.data: true
# ip地址
network.host: localhost
# 端口
http.port: 1002
# tcp监听端口
transport.tcp.port: 9302
# 查找master节点配置,master不用配
discovery.seed_hosts: ["localhost:9301"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
# 跨域设置
http.cors.enabled: true
http.cors.allow-origin: "*"
配置完成后启动,启动成功后,我们再次用postman访问1001节点,观察节点数,发现变成了2,说明集群成功
第三个节点配置
重复第二个节点的操作,配置文件如下
# 和前面一致
cluster.name: my-elasticsearch
# 节点名称
node.name: node-1003
node.master: true
node.data: true
# ip地址
network.host: localhost
# 端口
http.port: 1003
# tcp监听端口
transport.tcp.port: 9303
# 查找master节点配置,master不用配
discovery.seed_hosts: ["localhost:9301","localhost:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
# 跨域设置
http.cors.enabled: true
http.cors.allow-origin: "*"
启动后再次调用postman,集群节点数量已经为3,说明成功
Linux单节点部署
在linux服务器安装ElasticSearch,官网地址,linux支持多种安装方式,可自行选择,也可以使用docker方式安装,这里演示安装包的方式,下载linux,使用工具上传到服务器
- 解压缩
tar -zxvf elasticsearch-***.tar.gz -C /opt/module
# 改个名字
mv elasticsearch-*** es
- 创建用户
因为安全问题, ElasticSearch不允许root用户直接运行,所以先创建用户,在root用户中创建新用户,密码设置为 es ?
useradd es # 新增es用户
passwd es # 为es用户设置密码
userdel -r es # 删除用户,错了重新建一个
chown -R es:es /opt/module/es # 文件夹所有者
- 修改 elasticsearch.yml 配置文件
cluster.name: elasticsearch
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
# 名称要与node.name相同
cluster.initial_master_nodes: ["node-1"]
- 修改/etc/security/limits.conf
# 文件末尾添加下面内容 es 用户
# 每个进程可以打开的文件数的现状
es soft nofile 65536
es hard nofile 65536
- 修改/etc/security/limits.d/20-nproc.conf
# 文件末尾添加下面内容
# 每个进程可以打开的文件数的现状
es soft nofile 65536
es hard nofile 65536
# 操作系统级别对每个用户创建的进程数的限制 * 代表所有用户
* hard nproc 4096
- 修改/etc/sysctl.conf
# 在文件中添加下面内容
# 一个进程可以拥有的VMA(虚拟内存区域)的数量,默认值为65536
vm.max_map_count=655360
# 重新加载
sysctl -p
- 启动软件
要使用es用户来启动,root用户会报错,先切换用户
su es
启动,进入es目录
bin/elasticsearch
可能会出现错误,这时需要我们再次切换到root权限给文件授权
chown -R es:es /opt/module/es # 文件夹所有者
然后切换到es用户,再次执行启动命令,如果启动成功了可以用postman调用测试一下
Linux集群部署
先准备三台服务器(没钱就启三个虚拟机),Linux集群部署跟windows集群是大致相同的,但在配置上,相对复杂,注意:下方配置的ip改成自己的或者在host文件中配置好,就可以写linux1了
第一台配置
- 先解压缩,更改文件名称
tar -zxvf elasticsearch-***.tar.gz -C /opt/module
# 改个名字
mv elasticsearch-*** es-cluster
- 创建用户,授权文件
和前面一样 - 修改 elasticsearch.yml 配置文件
# 集群名称
cluster.name: cluster-es
# 节点名称,不能重复
node.name: node-1
# ip地址,每个节点都不一样
network.host: linux1
# 是否有资格成为主节点
node.master: true
node.data: true
http.port: 9200
# head 插件需要打开这两个配置
http.cors.enabled: true
http.cors.allow-origin: "*"
http.max_content_length: 200mb
# es7.x之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-1"]
# es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["linux1:9300","linux2:9300","linux3:9300"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
# 集群内同时启动的数据任务个数,默认为2
cluster.routing.allocation.cluster_concurrent_rebalance: 16
# 添加或者删除节点以及负载均衡时并发恢复的线程个数,默认四个
cluster.routing.allocation.node_concurrent_recoveries: 16
# 初始化数据恢复时,并发恢复线程的个数,默认四个
cluster.routing.allocation.node_initial_primaries_recoveries: 16
后面的配置和单点一致
第二台配置
重复第一台操作,然后将配置文件更改
# 节点名称,不能重复
node.name: node-2
# ip地址,每个节点都不一样
network.host: linux2
第三台配置
重复第一台操作,然后将配置文件更改
# 节点名称,不能重复
node.name: node-3
# ip地址,每个节点都不一样
network.host: linux3
最后通过地址,返回三个节点信息则是成功了
http://linux1:9200/_cat/nodes
end…
如果总结的还行,就点个赞呗 @_@ 如有错误,欢迎指点,下一篇ElasticSearch——进阶···