Mysql 你还在一个字段一个索引吗
今天看到某系统的mysql在某时段存在thread_running线程数飙高触发告警,挤时间分析了该异常时间段的慢日志记录,并进行了sql优化
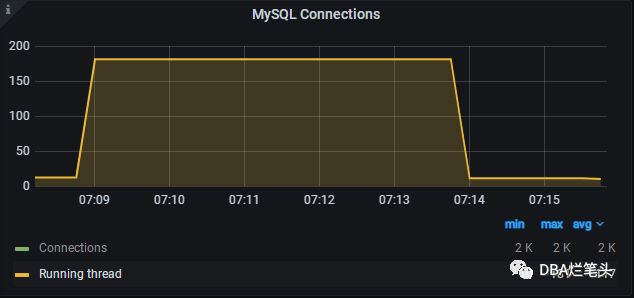
慢日志记录主要归为3个慢sql (编号1,2,3)
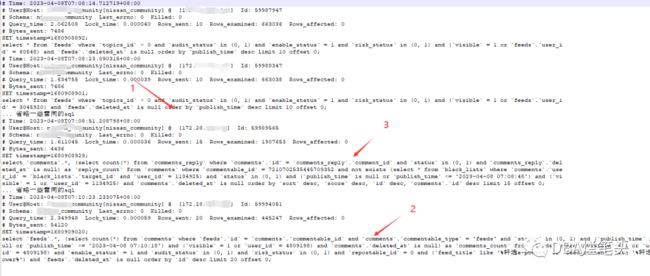
一、 1号sql原文
select * from `feeds` where `topics_id` > 0 and `audit_status` in (0, 1) and `enable_status` = 1 and `risk_status` in (0, 1) and (`visible` = 1 or `feeds`.`user_id` = 60548) and `feeds`.`deleted_at` is null order by `publish_time` desc limit 10 offset 0;
有limit 10 offset 0 限定最终结果的数据量,虽然走了索引,但是扫描近40万数据量,单并发执行耗时1.5秒~2秒,这能优化吗?


查看格式化后的sql,where的条件有点复杂,存在多个条件,可抽象出来抓可利用的组合索引,feeds(deleted_at,risk_status,enable_status,topics_id)

创建索引 idx2 feeds(deleted_at,risk_status,enable_status,topics_id),查看执行计划发现并没有按照预期选择新的索引,被deleted_at_idx 单列索引干扰,优化器傻傻地认为代价更低!

删掉deleted_at_idx 单列索引,再次查看执行计划

执行效率对比,原sql执行耗时1.5秒,创建新索引后执行耗时0.3秒,效率提升4倍!

二、2号sql原本
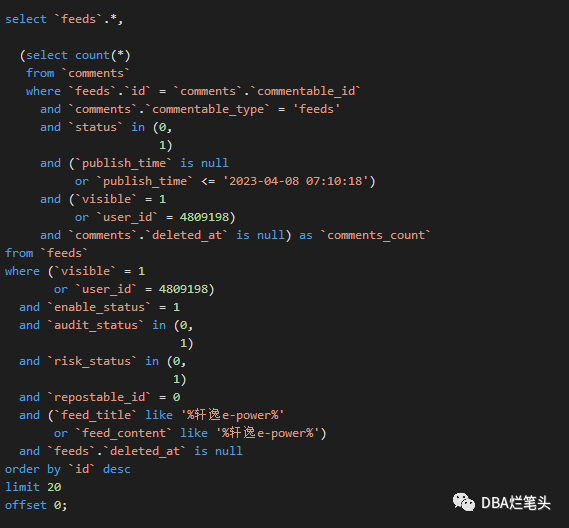
select `feeds`.*, (select count(*) from `comments` where `feeds`.`id` = `comments`.`commentable_id` and `comments`.`commentable_type` = 'feeds' and `status` in (0, 1) and (`publish_time` is null or `publish_time` <= '2023-04-08 07:10:18') and (`visible` = 1 or `user_id` = 4809198) and `comments`.`deleted_at` is null) as `comments_count` from `feeds` where (`visible` = 1 or `user_id` = 4809198) and `enable_status` = 1 and `audit_status` in (0, 1) and `risk_status` in (0, 1) and `repostable_id` = 0 and (`feed_title` like '%轩逸e-power%' or `feed_content` like '%轩逸e-power%') and `feeds`.`deleted_at` is null order by `id` desc limit 20 offset 0;
sql执行耗时1秒,执行计划选择repostable_id_idx,表feeds与表comments存在 `feeds`.`id` = `comments`.`commentable_id`,是不是选择 feeds 的主机id作为被驱动表扫描更好呢? 干掉干扰单列索引
![]()

查看格式化后的sql
sql执行耗时1秒,执行计划选择repostable_id_idx,表feeds与表comments存在 `feeds`.`id` = `comments`.`commentable_id`,是不是选择 feeds 的主机id作为被驱动表扫描更好呢? 干掉干扰单列索引repostable_id_idx。再次查看执行计划,果然去掉干扰索引后选择主键id扫描数据。

feeds由repostable_id_idx扫描数据量40万条数据&主键回表,变成了根据主键id PRIMARY 只需扫描20条数据,优化后执行耗时0.74秒,感觉还是不够快,大家看到这里有其他想法了吗?
![]()
继续回头分析sql, order by `id` desc,mysql索引是b+树且是递增组织的,desc 这是要递减呈现结果集啊!能否用mysql 8.x 的降序索引优化呢?

继续深挖,我们来把sql的desc改为asc 看一波!再次执行sql,执行耗时0.02秒!就是这个条件desc的锅!

三、3号sql原本
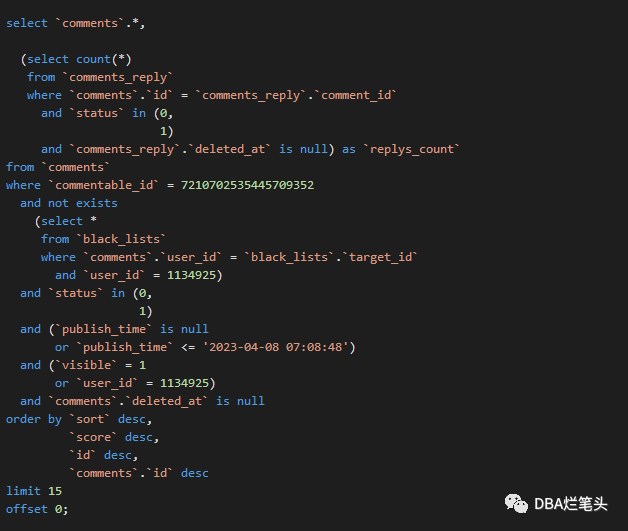
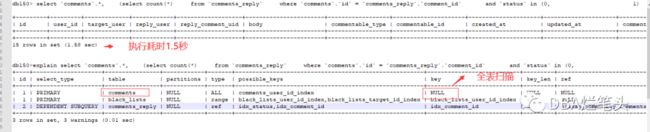
select `comments`.*, (select count(*) from `comments_reply` where `comments`.`id` = `comments_reply`.`comment_id` and `status` in (0, 1) and `comments_reply`.`deleted_at` is null) as `replys_count` from `comments` where `commentable_id` = 7210702535445709352 and not exists (select * from `black_lists` where `comments`.`user_id` = `black_lists`.`target_id` and `user_id` = 1134925) and `status` in (0, 1) and (`publish_time` is null or `publish_time` <= '2023-04-08 07:08:48') and (`visible` = 1 or `user_id` = 1134925) and `comments`.`deleted_at` is null order by `sort` desc, `score` desc, `id` desc, `comments`.`id` desc limit 15 offset 0;
格式化sql
执行耗时1.5秒+,comments表扫描走全表扫描
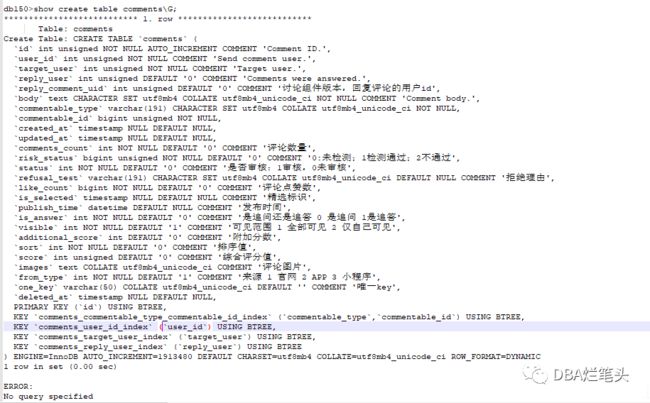
comments表的表结构
解读执行计划,表comments_reply使用idx_comment_id 索引后与comments 进行关联,但表comments 缺少可利用索引,走全表扫描200万数据,注意from `comments`where `commentable_id` = 7210702535445709352条件,虽然有KEY `comments_commentable_type_commentable_id_index` (`commentable_type`,`commentable_id`) ,但不是索引的最左前缀原则,无法有效利用,明显缺少 commentable_id字段的索引,咱现在创建一个!

原执行耗时1.5秒,优化后,执行耗时0.00秒。comments表由全表扫描200万数据,改变成索引扫描446条数据,666

总结
1、绝大部分情况不要一个字段一个索引
2、索引不是越多越好,无效索引对优化器的最佳执行计划存在干扰与误导
3、mysql 索引是由小到大组织数据的,字段 慎用 desc,可考虑8.x新特性降序索引
4、mysql索引可利用的条件之一为最左前缀原则,创建索引要考虑字段排列顺序