不平衡数据分类方法
仅个人学习时,阅读相关资料总结。(可能有部分不准确)
概述
定义
数据不平衡分类是对各类别间样本的数目相差较大的数据集进行分类。例如:二分类问题中,一个样本总数为100,80个样本被标为类别1,剩下的20个样本被标为类别2。类别1比类别2的样本总数为4:1。这是一个不平衡的数据集。实际生活中,故障检测,癌症检测,石油勘探都是不平衡数据。
传统分类器对于不平衡数据的不适用性
传统分类方法有:决策树法,朴素贝叶斯分类器,支持向量机,K近邻法,多层感知器等。其中,决策树法又称判定树,基于实例的基本分类与回归方法,从一组无次序、无规则的事例中推理出以树为表示形式的分类规则,形成分类器和预测模型。主流算法有ID3算法(选择增益最大的特征与阈值进行分裂)、C4.5算法(使用基尼指数作为分割标准,目的是最小化不纯度)、CART算法。朴素贝叶斯分类器基于贝叶斯定理构建了概率模型来估计样本属于每个类别的后验概率,选择最大后验概率的类作为分类结果。适用于邮件分类、疾病诊断。支持向量机将线性样本映射到高维的非线性空间中,有效地对原始数据集进行非线性分类。适用于文本分类、手写数字识别、信号处理通讯。
传统分类问题基于两种假设:
1)各类别间数目大致均等
2)各种类别错分的代价相同
但不平衡数据中的少数样本发生的概率低于多数类样本。且代价明显高于多数类样本,若采用传统分类器的以提高总体分类精度为目标,容易造成少数类的分类错误。例如,对于邮件分类,假使100封邮件中有3封垃圾邮件,其余正常邮件,若均判别为正常邮件,分类器将全部邮件判别为正常邮件,就有97%准确率。但高准确率并没有完成识别出垃圾邮件的任务。
可应用领域
对于网络入侵检测问题,把入侵行为误判为正常行为,可能出现一定区域的网络问题,更严重的情况是整个网络系统瘫痪。在癌症检测上,如果把癌症病人误诊为正常病人,很有可能会错过最佳治疗时期。
在实际应用领域中,矿物质的勘探,信用卡非法交易,卫星雷达检测海面油污,它们的关注重点都是少数类,不平衡数据分类的研究更有意义。
分类方法总框架
对于数据不平衡问题,已有多种技术用于解决此类问题。
分类技术总体框图:

分类层面总体框图:
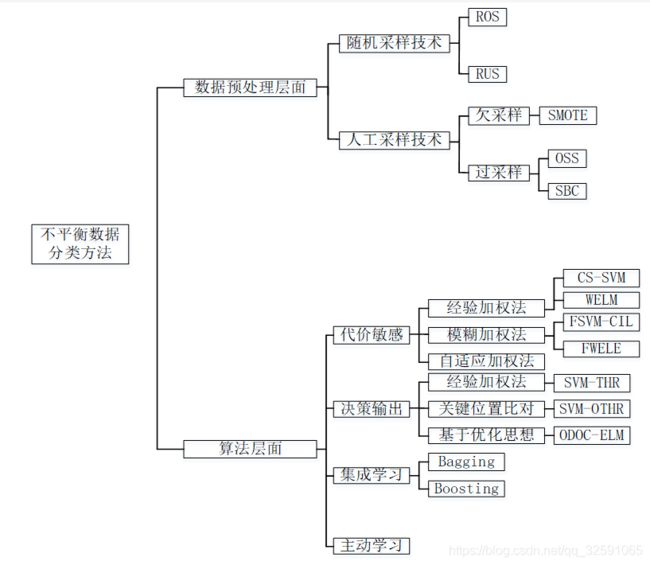
数据层面
样本采样技术
基本思想:通过增或减某类样本的数目,获得相对平衡的数据集。
优点:不需要考虑后期使用何种算法。
缺点:易产生信息冗余或缺失,分类性能下降。
样本采样技术大致分为三类:欠采样技术,过采样技术,混合采样技术。
随机采样技术
随机欠采样:随机删除一定数量或比例的多数类,少数类样本不处理。会导致分类信息缺失,分类性能下降。
随机过采样:通过简单复制少数类样本,多数类不处理。仅增加了数量,没有增加样本信息,易发生过拟合,并且数量增加引入了一定的额外数据,构建分类器耗时增加。
以上两种实现困难程度较小,分类性能有一定的提升空间。
人工采样技术
经典过采样方法
SMOTE:利用了样本集在属性空间的特点:某类样本趋于出现在同类的样本的邻域区间。采用简单的K邻近法,选取主样本及k个邻近样本,随机从k个临近样本选取一个主邻近样本,在主样本与邻近样本的连接线上,随机生成新样本。
优点:保证了样本的原始分布,解决了随机过采样法过适应的问题。
缺点:涉及大量近邻关系运算;少数类样本含有较多噪声信息时,会影响分类性能;由于每轮主样本的选取随机,当少数类样本数较少时,可能造成各原始少数类样本被选作主样本的频次差较大,从而偏离原始的样本分布。每个样本生成新样本的个数随机。
改进:Borderline-SMOTE采样法(选取起决定作用的处于分类边界上的样本),有效规避原始噪声在新样本集上的传播。
ADA-SYN采样法(利用样本密度分布信息来确定个少数样本用作主样本的频次)。边界区域样本作为主样本的频次较高,自适应每个少数类样本的频次。
经典欠采样方法
单边选择OSS:根据多数类样本所含信息量大小选择移除。满足Tomek links(两个不同的样本且互为最近邻)的样本处于边界或噪声,进行剔除。使数据集达到平衡。
优点:保留多数类中的绝大多数信息,进而保证后期分类器的训练质量。
缺点:RUS 采样率可控,OSS不可控。
SBC采样法:基于聚类的采样法,在多数类样本的聚集区域,保留尽可能多的多数类样本,在少数类样本的聚集区域,移除尽可能多的多数类样本。对选择性保留每个类簇中的多数类样本。需要注意聚类算法及K值确定。
其他方法:
KNN-NearMiss:通过对多数类样本与三个少数类样本的距离比对,选取合适的多数类样本为新的多数类子集。
压缩最近邻:所有少数类及随机选取的一个多数类样本为初始子集,通过分类产生的错分样本叠加到初始子集中。
特征层面
Filter过滤式
使用发散性或相关性指标对各个特征进行评分,选择分数大于阈值的特征或者选择前K个分数最大的特征。特征选择过程与与分类器无关。相当于先对初始特征进行过滤,再用过滤后的特征训练分类器。过滤式特征选择法简单、易于运行、易于理解,通常对于理解数据有较好的效果,但对特征优化、提高模型泛化能力来说效果一般。
Wrapped封装式
与分类器独立。根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
Embedded嵌入式
与分类器结合。先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
算法层面
代价敏感学习技术
基本思想:不在以样本的整体误差最小化为目标,追求整体误分代价的最小化。无须对样本分布做预处理,通过修改后的准则在原始样本上直接训练得出无偏的分类面。通过赋予多数类和少数类不同的误分类代价。
优点:分类器在分类时更加关注少数类,提高分类准确率。
缺点:仅当考虑误分代价时适用。
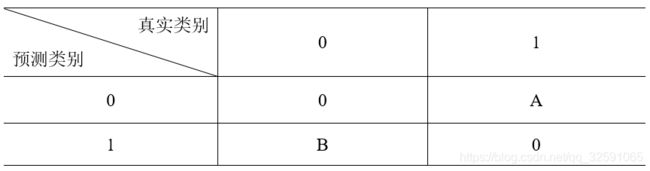
以二分类任务为例,可设定一个“矩阵代价”,通常情况下的二分类代价矩阵如下,其0、A、B表示分类代价。并且根据误判造成的损失程度,确定A与B的大小。若真实类别中0为多数类,而1为少数类,解决这个二类问题,应选择A>B。
经验加权法
利用类别不平衡比率IR,设计代价矩阵。
缺点:忽略了每个样本自身“重要度”。(可通过先验分布信息量化计算得出)
CS-SVM算法:
将代价敏感学习思想与支持向量机分类器结合,直接对支持向量机的优化式进行修改。少数类与多数类惩罚系数之比始终等于IR。
WELM算法:
加权极限学习机算法
模糊加权法
引入IR值且考虑样本分布。通过模糊隶属函数确定个性化的惩罚代价。
FSVM-CIL算法
权重或隶属值的分配,考虑问题:抑制类别不平衡分布影响,体现每个样本的重要度。
FWELE算法
模糊加权极限学习机算法
自适应加权法
利用Boosting
决策输出补偿技术
基本思想:对分类面决策输出值进行调整,修正偏倚分类面。传统学习算法产生的分类面往往会出现在少数类稠密区域,将分类面向多数类区域移动,回归到交叠中心。
优点:此过程与训练过程相互独立。
缺点:能够使分类性能最大化的参数难以确定。
手段:乘法补偿(针对决策输出表示为概率的分类算法),加法补偿(在少数类的决策输出加一个正数)。
基于经验
通过人为设定或通过IR计算得出。
SVM-THR:
基于经验的加法决策输出补偿算法
缺点:对于调整后的分类面结果难以控制,调整不足或调整过大。
基于关键位置比对
SVM-OTHR
考虑了样本在特征空间中的分布信息,训练样本中被误分的少数类样本在特征空间中标定了少量的关键位置,比对G-mean测度,确定最优调整位置,进一步根据原始分类面与最优调整分类面之间的距离确定输出补偿值。
基于优化思想
ODOC-ELM
最优决策输出补偿权限学习机的决策输出补偿算法
集成学习技术
经典方法
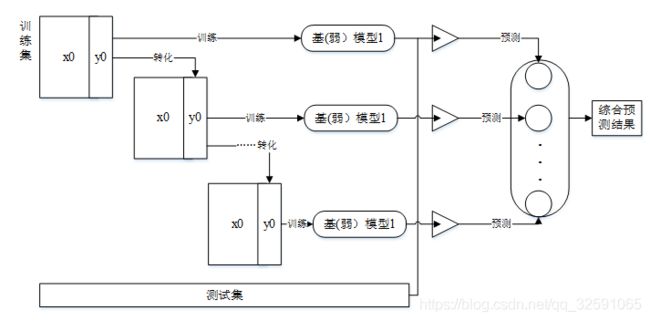
基本思想:基学习器为采用单一机器学习算法所训练的模型,这些模型通过组合模块结合到一起,进而根据某种预设的结合策咯而给出最终的决策输出。是将多个相同或不同的个体学习器组合起来去完成同一个学习任务的分类算法,这些个体学习器应该是“好而不同”的,与传统的分类器相比,集成学习有更好的学习效果,并且会取得更为优越的泛化能力。
有效原因:单一学习器的训练样本数有限;单一学习器在有限时间内难以达到目标。
前提条件:基学习器要尽可能准确且各基学习器之间要有足够差异。
优点:此过程与训练过程相互独立。避免过拟合。
缺点:当训练模型没有较好的精确度或各训练模型间没有较大差异,分类性能可能低于单一训练模型。
Bagging算法
对数据集进行采样,得到新的数据集,并随机选取原数据集中的一个样本并添加至新数据集,多次操作,形成不同的训练集。多数投票法产生最终结果。
基学习器间不存在依赖关系。
自助式采样技术:放回式抽单个样本至m个,达到原始样本规模。
算法结构算法结构如图:

代表算法:随机森林算法,RS算法(决策树为基分类器)
Boosting算法
对数据集进行训练,按照训练结果更新训练集分布,对于训练失败的样本点赋予更大的权重,重新训练数据集,至达到预期效果。最终的分类预测函数采用带权重的投票产生。基学习器间具有较强的依赖关系。
优势:自动重采样,减少代价;给予样本不同权重增加多样性;
缺点:以分类准确率最大化为目标,多数类影响大,少数类提高程度有限。
代表算法:AdaBoost 算法(更改权重);梯度提升决策GBDT(Gradient Boosting Decision Tree)算法(残差减少的梯度方向)
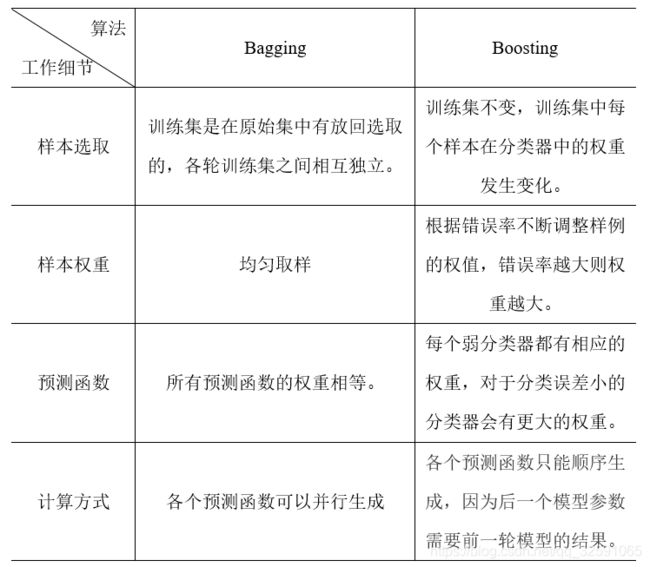
Bagging算法与Boosting算法区别
两种算法的区别如表:
基于样本采样技术
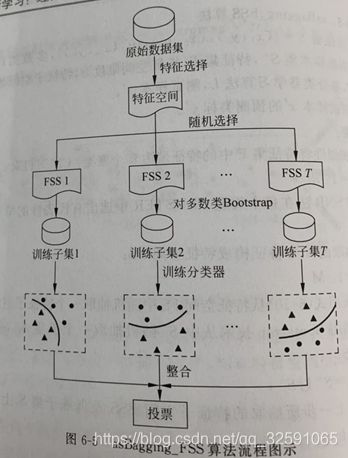
asBagging与asBagging-FSS算法
asBagging算法(Assymetric Bagging)
基本思想:随机降采样+Bagging集成基于代价敏感学习技术。划分训练子集时,全盘保留少数类样本,多数类抽取规模相同的样本,进而训练各基分类器,并做成集成决策。
优点:保留了多数类的大部分重要信息。随机降采样技术导致的分类器性能不稳定问题;有效提升了Bagging中基分类器的差异度。
缺点:应用于存在大量噪声与冗余信息的高维数据中时,性能可能大幅下降。
asBagging算法-FSS
FSS特征子空间生成策略:聚类(过滤冗余特征)+特征选择(约减噪声特征)。在不显著减少训练子集差异度的同时,大幅度提升每个子集精度。为约减冗余特征,可采用基于皮尔森相关系数(被用作特征相似度测量标准)的分层聚类法将相似的特征聚类到相同的类簇中。(平衡:个体精度与差异度)
信噪比(SNR)特征选择法:筛选与分类任务最相关的代表性特征。
对于多数类Bootstrap技术对多数类降采样,生成多个平衡训练子集。
SMOTEBoost与RUSBoost算法
SMOTEBoost算法
基本思想:先采用SMOTE算法对少数类过采样,相当于间接提升了少数类的更新权重,同时改变了样本的初始分布。
优点:改进了AdaSMOTE权重相同。提升少数类的预测精度。(平衡:不同类之间的性能差)
RUSBoost算法
EasyEnsemble及BalanceCascade算法
EasyEnsemble算法
步骤:
- RUS随机生成多个平衡的训练子集,
- 每个训练子集分别训练一个AdaBoost分类器
- Bagging中基分类器替换为AdaBoost分类器
优点:Bagging避免训练信息缺失,AdaBoost提升了分类结果的泛化能力,分类结果的方差与偏差可同步减少,令分类结果更加稳定。
BalanceCascade算法
训练一个AdaBoost分类器,移除采用该分类器可正确分类的多数类样本,串行生成基分类器。保证下一个Bagging基分类器更多关注不容易分对的多数类。
基于代价敏感学习
AdaCX系列算法
AdaBoost:在于修正样本,改变分布,聚焦于那些易被分错的“困难”样本。
代价敏感:大权重分配到“重要”样本,避免分错。
融合:借助AdaBoost算法特点来大幅度提升代价敏感学习的质量。
基于决策输出补偿
EnSVM-OTHR算法
基本思想:Bagging+SVM-OTHR
保障差异性:Bagging中Bootstrap技术;在SVM-OTHR算法建模时,引入一个相对小的随机干扰项。
EnSVM-OTHR在一个狭小范围内随机调整最优决策输出补偿值(加小的随机干扰项),不伤害基分类器性能,最大限度增大差异度。
主动学习技术
基本思想:迭代方式选取含有信息量较多的样本,并添加类别标注,更新分类模型。
优点:减少了训练样本,尽可能生成质量更高的分类模型。
对于主动学习,基于池的主动学习最为常见。基于池是指在学习开始前预先采集全部的未标注样本,并置于未标记样本池。基于池的主动学习过程示意图如图。

影响因素与性能评价测度
影响因素
数据不平衡分布对传统分类算法产生负面影响,影响程度主要有以下几个因素:
(1)类别不平衡比率IR:具体表示为多数类样本数与少数类样本数的比值。IR值越高,负面影响越大。
(2)重叠区域的大小:重叠区域越大,负面影响越大。
(3)训练样本的绝对数量:训练样本的规模小少数类样本更加稀疏,分类器的训练精度越差。
(4)类内子聚集现象的严重程度:类内子聚集也被称为类内不平衡,少数类样本出现两个或多个,会加剧分类算法的学习难度。
(5)噪声样本比率:噪声样本主要指不符合同类样本分布的样本,通常以离群点形式存在。多数类中噪声样本较多,会损害少数类分类精度。多数类中噪声样本较多,对多数类的分类性能影响不大。
性能评价测度
后续总结