SENSORO 处理智慧城市海量感知数据的数据库应用
作为城市级数据服务提供商,SENSORO(北京升哲科技有限公司)是一家领先的物联网与人工智能独角兽企业。
要建造城市级的物联感知网络,涉及到的物联网设备种类不胜枚举。例如,街头巷尾的路灯、路面的智能井盖、社区的门禁、楼道里的智慧空气开关、房间屋顶上的烟雾报警器、商店的门磁与红外人体探测器、仓库里的温湿度传感器、地下室角落管道旁的跑冒滴漏、后厨中的可燃气体报警器、水管上的智能水表等等……这些终端时时刻刻都在产生着各式各样的感知数据,基于业务需求,这些数据需要正确地存储起来。

第一阶段:强大但昂贵的 Elasticsearch
如果有非常大量的数据要存储,还要实现各种各样的统计分析需求,首先想到的就是,把数据塞进 ES 里。
这在业务初期是没有什么问题的,ES 优秀的写入性能、水平扩展能力、成熟的生态,再加上强大的搜索查询 API,让我们开发人员能轻易的应付产品经理各种各样的数据统计分析需求。
我们初期使用方式相对简单粗暴,各种感知数据写入到 Kafka 集群中,通过 Logstash 消费 Kafka 将数据写入到 ES。同时按月来拆分索引,来方便清理数据。
1.1 数据无法写入 —— Mapping Explosion

几个月后我们就遇到了第一个问题,某天数据突然无法写入。我们数据的字段数很快便达到了 ES 默认的 index.mapping.total_fields.limit: 1000。尽管通过临时扩大该设置解决了数据写入问题,但终究是权宜之计,接下来还需要去根据设备类型分拆 index 来彻底避免这种问题的再次发生,幸运的是使用 ES 仍然不需要我们自己去维护每种设备的 Schema。
1.2 ES 数据膨胀与存储成本
ES 作为一个分布式系统,为了保证可靠性,数据一般都会保存副本。副本有利于增加数据的可靠性,但同时会增加存储成本。除原始数据外,ES 还需要存储索引、列存数据等,在应用编码压缩等技术后,一般膨胀 10%。同时 ES 还需要一定空间用于 segment 合并、ES Translog、日志等。大体而言 ES 集群使用空间约为源数据 × (1 + 副本数量) × 1.45。
哦别忘记可不能让集群节点磁盘跑满,我们一般在节点磁盘 80~85% 时就会考虑增加节点进行集群扩容。因而空间占用大概会变成源数据 × (1 + 副本数量) × 1.6。以默认副本数 1 而言,存储使用已经会变成原始数据的 3.2 倍。
所以简单来说,ES 功能强大且相对容易使用,并且大部分云服务提供商都提供对应服务。但缺点显而易见的,在长期存储海量数据时——它太昂贵了。
第二阶段:运维复杂的 Apache Druid
出于成本考量,我们决定选择一款时序数据库来存储系统的感知数据。依赖时序数据库针对性的优化,理论上应该可以凭借更高的压缩比极大的降低存储成本。
打开 DB-Engines 的 Ranking 页面,分类选到 Time Series DBMS,接下来就是做选择的时候。
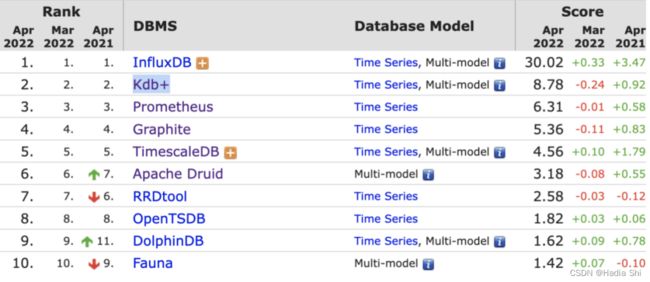
db-engines 2022年4月时序数据库排名
完全开源,InfluxDB、Kdb+ pass;Prometheu 与 Graphite 都是为监控而生,数据必须是“Numeric data only”(RRDtool 同样是 Numberic data only)。综合下来我们考虑的基本上在 TimescaleDB、Apache Druid 与 OpenTSDB 中选择。
原本 OpenTSDB Schema-free 的特点非常加分,但依赖于 HBase 这点带来的部署复杂度又是一个问题。TimescaleDB 基于 PG 扩展而来,同样的带来问题就是数据压缩率其实并不是非常理想,我们查阅资料,学习了解对应系统的存储结构与对应空间使用情况,以及系统架构设计各个方面,我们还是选择了 Druid。

2.1 Schema 问题
选定 Druid 之后,接下来就遇到了问题。我们的传感器种类实在太多,每一类都有少则三五种,多则十几种细分型号,而且种类与数据随着时间与业务发展还在不停增加。这么多的型号为每种设备单独建模创建对应的表结构去存储,基本是不现实的。那么为每类设备设计共用的大表行得通吗?至少以我们目前划分出的 18 个子系统而言,也需要创建至少 18 张表(至少是因为每个子系统实际仍然会包含不同类型设备)。
对应到 Druid 的 Datasource,仅创建 18 个 indexing 任务,便是一份不小的资源开销了。
因此我们需要设计一种通用的存储方案,简单来说就是额外提供类似 ES 的 Auto Mapping 的机制,由程序来实现业务数据与存储数据结构的映射。有大概两种不同的思路我们称呼为横向与纵向映射。
2.1.1 纵向
这种相对简单,就是将一条数据拆分成多条,每一条变成对应的 Key-Value 结构去存储。就 Druid 而言 Datasource 的 Schema 如下:

这样如下一条数据:

存储到 Druid 中需要拆分成 4 条:

比如我们需要查询传感器 “01020304” 过去一天中的最大温度,就可以使用如下语句:

这样存储解决了 Schema 问题,但同样也会带来新的问题。首先显而易见的数据量会数十倍的增长,不过对于本身设计应对这种场景的时序数据库来说尚可接受,同时这种结构 Druid 也能够实现较高的数据压缩比,以我们的使用情况来看,一百亿条数据大约使用 110GB 左右的存储空间。
另外一个问题就比较麻烦,同一设备的数据被拆分,存储到不同的行中,但很多时候,尤其是对于一些复杂类型的传感器如电气类的,通常会有几十种感知数据上报上来,数据被拆开很简单,再重新合并起来就不太容易了,就以最简单的数据日志为例,如何用一条 SQL 查询出来 “01020304” 过去 1 天上报的数据呢?
2.1.2 横向
那换一种思路,我们可以提前创建一个大的宽表,将原始数据字段名称映射成统一的列名,存储到同一表的对应列中。就物联网感知数据而言大部分是 Number 类型的数据,我们就提前创建 50 列出来并编号。

对于之前提到的温湿度数据而言,写入到 Druid 集群中的数据会变成:
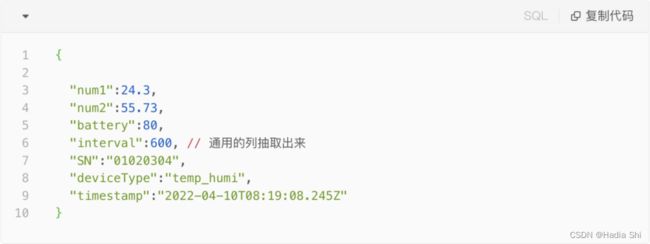
这样处理数据就可以解决纵向拆分数据带来的问题,但也会带来额外的数据映射的管理复杂度。我们需要开发对应的程序,把原始数据转化成对应的格式,同时还要维护列与原始字段名的映射关系。每次查询时都要获取对应的映射信息,来决定去查询聚合哪些列。同时数据库中还会存在着大量的空列,要求数据库能够高效的应对这种情形。
维护的映射信息还要考虑字段增加的情形,假设我们的温湿度传感器包含气压传感器,后续通过固件升级增加了对应大气压的数据上报字段。

映射数据最好包含对应的时间关系,体现出什么时间段内不存在 atmosphere 这个字段。
我们最终选择了横向方式存储数据,截止目前基本上能够满足各种需求。但仍然有不好处理的问题存在,比如两种设备比如电气火灾和空气开关,均存在电压这种感知数据,想要统计某个区域的电压,并不关心哪种设备的时候,不太容易去实现对应的查询。
2.2 部署运维的复杂度
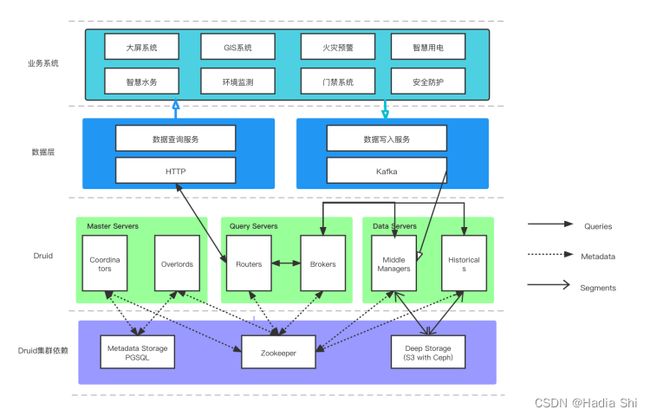
使用 Druid 集群的另外一个问题就是部署与运维的复杂度问题。
Druid 划分了 Coordinator、Overlord、Broker、Router、Historical、MiddleManager 六个进程。要实现完整的集群功能,Druid 还需要一个 Deep storage (支持 S3 和 HDFS),Metadata storage (典型如 mysql / pgsql),以及为实现服务发现与选主功能而需要的 ZooKeeper。
从工程师的角度来看,Druid 的架构设计可以说是清晰明了,每个服务都只承担单一的职责,同时也可以充分复用现有基础设施,同时支持了灵活的 retention rules,能够轻易的实现多级存储,降低硬件成本,优化热数据查询性能。但对于运维同事来说,这套系统太复杂了,需要组件太多,外部依赖太多,集群单纯启动需要的最小资源也太多(针对开发测试环境来说)。

上图配置了最近两周数据在 Druid 集群中 hot 分组中(配置高性能 SSD 的节点)保存 3 个副本,最近 1 月双副本,保留最近一年的在 default_tier 中,清理超过一年的数据。
第三阶段:平衡成本和性能的 TDengine
Druid 的系统复杂度问题一直困扰着我们,同时随着数据量的增长,查询聚合的响应时间也不太理想(大部分情况仍然能够实现亚秒级响应,但响应时间波动极大)。然后我们想起来之前调研过的国产时序数据库 TDengine。
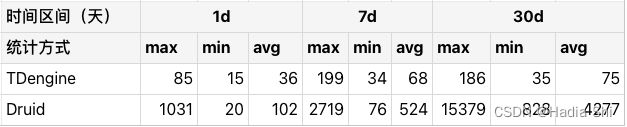
我们部署了一套 TDengine 集群,并构造了一些测试数据进行测试,结果非常不错:
我们导入了相同的两份数据到 Druid 和 TDengine 中,以下为三节点(8c16g),100 万传感设备,40 列(6 个字符串数据列,30 个 double 数据列,以及 4 个字符串 tag 列),总计 5.5 亿条记录的结果(由于数据很多为随机生成,数据压缩率一般会比真实情况要差)。
3.1 资源对比

3.2 响应时间对比
1. 随机单设备原始数据查询
a. 查询结果集 100 条
b. 重复 1000 次查询,每次查询设备随机指定
c. 查询时间区间分别为:1 天、7 天、1 月,
d. 统计查询耗时的最大值、最小值、平均值
e. SELECT * FROM device_${random} LIMIT 100
2. 随机单设备聚合查询
a. 聚合计算某列的时间间隔的平均值
b. 重复 1000 次查询,每次查询设备随机指定
c. 查询时间区间分别为:1 天、7 天、7 天、1 月,对应聚合时间为 1 小时、1 小时、7 天,7 天。
d. 统计查询耗时的最大值、最小值、平均值
e. SELECT AVG(col_1) FROM device_${random} WHERE ts >= ${tStart} and ts < ${tEnd} INTERVAL(${timeslot})
3. 随机多设备聚合查询
a. 聚合计算某列的时间间隔的总和
b. 重复 1000 次查询,每次查询设备约 10000 个
c. 查询时间区间分别为:1 天、7 天、7 天、1 月,对应聚合时间为 1 小时、1 小时、7 天,7 天。
d. 统计查询耗时的最大值、最小值、平均值
e. SELECT SUM(col_1) FROM stable WHERE ts >= ${tStart} and ts < ${tEnd} AND device_id in (${deviceId_array}) INTERVAL(${timeslot})

TDengine 的空间占用只有 Druid 的 60%(没有计算 Druid 使用的 Deep storage)。针对单一设备的查询与聚和的响应时间比 Druid 有倍数的提升,尤其时间跨度较久时差距十倍以上,Druid 的响应时间方差也较大。然而针对多子表的聚合操作,TDengine 与 Druid 的表现没有明显区别,可以说是各有优劣。
总之,对比 Druid 在物联网感知数据方面,TDengine 的性能、资源使用方面均有较大领先。再加上 TDengine 安装部署配置上的简单方便(尤其是私有化应用的部署场景),以及相较于 Apache 社区支持来说更可靠与及时的商业服务,当前阶段我们的传感数据存储使用的便是 TDengine。
新型智慧城市建设过程中的挑战很多,城市级传感网络的数据存储只是其中重要的一部分。升哲科技基于技术的创新融合能力和场景落地的长效服务能力,已取得丰硕成果。延续数字化应用标杆的共建、共享,升哲科技希望将一些经验心得分享出来,以期让数字化建设成果惠及更多城市。接下来,我们还将对「支撑百万级传感器的延时队列」进行分享,敬请期待。