MyBatis 源码阅读 -- 配置解析篇
配置解析包用来实现MyBatis配置文件、映射文件的解析等工作,并最终为MyBatis准备好进行数据库操作的运行环境。
1. 配置解析概述
许多应用需要在进行一定的配置之后才能使用,MyBatis也不例外。MyBatis的配置依靠两个文件来完成:
- 一是配置文件,里面包含 MyBatis的基本配置信息。该文件只有一个。
- 二是映射文件,里面设置了 Java对象和数据库属性之间的映射关系、数据库操作语句等。该文件可以有多个。
在进行真正的数据库操作之前,MyBatis 首先要完成以上两类文件的解析,并根据解析出的信息设置好 MyBatis的运行环境以备使用。在这个过程中,需要 MyBatis的多个包配合完成。配置解析的过程就是将配置信息提取、转化,最终在 Java对象中保存的过程。
从类的角度分析,可以将与配置解析相关的类(含接口)分为以下两种:
- 解析器类(含接口):提供配置的解析功能,负责完成配置信息的提取、转化。MyBatis中这样的类有 XMLConfigBuilder类、XMLMapperBuilder类、CacheRefResolver类和XMLStatementBuilder类等。
- 解析实体类(含接口):提供配置的保存功能。该类在结构上与配置信息有对应关系。配置信息最终会保存到解析实体类的属性中。MyBatis 中这样的类有Configuration类、ReflectorFactory类、Environment类、DataSource类、ParameterMap类、ParameterMapping类、Discriminator类和 SqlNode类等。
这种划分不是绝对的,例如有一些类既是解析实体类,又是解析器类。它们既能在属性中保存信息,又能解析自身或者下层配置。从配置文件的角度看,我们可以将配置文件中各个节点对应的解析器类和解析实体类找出来。以 MyBatis 配置文件为例,可以将其中各个节点对应的解析器类和解析实体类标注出来:


同样,也可以将映射文件节点对应的解析器类和解析实体类标注出来:

这会让阅读配置解析类源码的过程更为清晰,大家在阅读其他开源项目的配置解析类源码时,可以参照以下方法。
- 从类的角度分析,将源码中的解析器类和解析实体类划分出来;
- 从配置文件的角度分析,将各个配置信息对应的解析器类和解析实体类找出来。
2. binding
binding 包是主要用来处理Java方法与SQL语句之间绑定关系的包。例如,调用Java程序中的抽象方法,然后映射文件中SQL语句被触发。正是因为binding包维护了映射接口中方法和数据库操作节点之间的关联关系,MyBatis才能在调用某个映射接口中的方法时找到对应的数据库操作节点。binding 包具有以下两个功能:
- 维护映射接口中抽象方法与数据库操作节点之间的关联关系;
- 为映射接口中的抽象方法接入对应的数据库操作。
2.1 数据库操作的接入
为映射接口中的抽象方法接入对应的数据库操作是相对底层的操作。说起为抽象方法接入实现方法,最先想到的就是动态代理。binding 包也是基于反射的动态代理的原理实现功能的。为映射接口中的抽象方法接入对应的数据库操作相关类的类图。
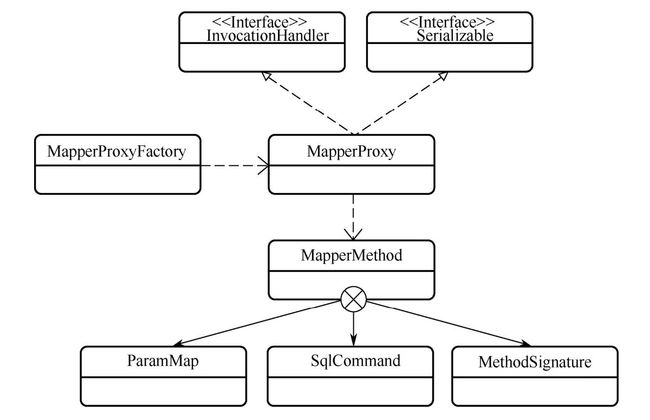
2.1.1 数据库操作的方法化
要想将一个数据库操作接入一个抽象方法中,首先要做的就是将数据库操作节点转化为一个方法。MapperMethod对象就表示数据库操作转化后的方法。每个 MapperMethod对象都对应了一个数据库操作节点,调用 MapperMethod实例中的 execute方法就可以触发节点中的 SQL语句。
MapperMethod 类有两个属性,这两个属性分别对应了其两个重要的内部类:
- MethodSignature类:MethodSignature 内部类指代一个具体方法的签名。 MethodSignature 内部类的属性详细描述了一个方法的细节。
- SqlCommand类:SqlCommand内部类指代一条SQL语句。SqlCommand的构造方法主要就是根据传入的参数完成对 name和 type字段的赋值。
public static class MethodSignature {
// 返回类型是否为集合类型
private final boolean returnsMany;
// 返回类型是否是map
private final boolean returnsMap;
// 返回类型是否是空
private final boolean returnsVoid;
// 返回类型是否是cursor类型
private final boolean returnsCursor;
// 返回类型是否是optional类型
private final boolean returnsOptional;
// 返回类型
private final Class returnType;
// 如果返回为map,这里记录所有的map的key
private final String mapKey;
// resultHandler参数的位置
private final Integer resultHandlerIndex;
// rowBounds参数的位置
private final Integer rowBoundsIndex;
// 引用参数名称解析器
private final ParamNameResolver paramNameResolver;
...
}
public static class SqlCommand {
// SQL语句的名称
private final String name;
// SQL语句的种类,一共分为以下六种:增、删、改、查、清缓存、未知
private final SqlCommandType type;
...
} public SqlCommand(Configuration configuration, Class mapperInterface, Method method) {
// 方法名称
final String methodName = method.getName();
// 方法所在的类。可能是mapperInterface,也可能是mapperInterface的子类
final Class declaringClass = method.getDeclaringClass();
MappedStatement ms = resolveMappedStatement(mapperInterface, methodName, declaringClass,
configuration);
if (ms == null) {
if (method.getAnnotation(Flush.class) != null) {
name = null;
type = SqlCommandType.FLUSH;
} else {
throw new BindingException("Invalid bound statement (not found): "
+ mapperInterface.getName() + "." + methodName);
}
} else {
name = ms.getId();
type = ms.getSqlCommandType();
if (type == SqlCommandType.UNKNOWN) {
throw new BindingException("Unknown execution method for: " + name);
}
}
}
/**
* 找出指定接口指定方法对应的MappedStatement对象
* @param mapperInterface 映射接口
* @param methodName 映射接口中具体操作方法名
* @param declaringClass 操作方法所在的类。一般是映射接口本身,也可能是映射接口的子类
* @param configuration 配置信息
* @return MappedStatement对象
*/
private MappedStatement resolveMappedStatement(Class mapperInterface, String methodName,
Class declaringClass, Configuration configuration) {
// 数据库操作语句的编号是:接口名.方法名
String statementId = mapperInterface.getName() + "." + methodName;
// configuration保存了解析后的所有操作语句,去查找该语句
if (configuration.hasStatement(statementId)) {
// 从configuration中找到了对应的语句,返回
return configuration.getMappedStatement(statementId);
} else if (mapperInterface.equals(declaringClass)) {
// 说明递归调用已经到终点,但是仍然没有找到匹配的结果
return null;
}
// 从方法的定义类开始,沿着父类向上寻找。找到接口类时停止
for (Class superInterface : mapperInterface.getInterfaces()) {
if (declaringClass.isAssignableFrom(superInterface)) {
MappedStatement ms = resolveMappedStatement(superInterface, methodName,
declaringClass, configuration);
if (ms != null) {
return ms;
}
}
}
return null;
}而 resolveMappedStatement子方法是一切的关键。因为 resolveMappedStatement子方法查询出一个 MappedStatement 对象,我们将在后续【TODO】了解 MappedStatement 完整对应了一条数据库操作语句。
因此说 MapperMethod类将一个数据库操作语句和一个 Java方法绑定在了一起:它的MethodSignature属性保存了这个方法的详细信息;它的 SqlCommand属性持有这个方法对应的 SQL语句。MapperMethod类的功能:
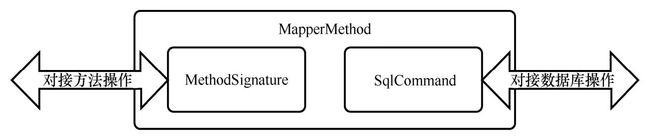
只要调用 MapperMethod 对象的 execute方法,就可以触发具体的数据库操作,于是数据库操作就被转化为了方法。可以看出 execute方法根据自身 SQL 语句类型的不同触发不同的数据库操作。 在 MapperMethod类的帮助下,只要我们能将 Java映射接口的调用转为对 MapperMethod对象 execute方法的调用,就能在调用某个 Java映射接口时完成指定的数据库操作。
/**
* 执行映射接口中的方法
* @param sqlSession sqlSession接口的实例,通过它可以进行数据库的操作
* @param args 执行接口方法时传入的参数
* @return 数据库操作结果
*/
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) { // 根据SQL语句类型,执行不同操作
case INSERT: { // 如果是插入语句
// 将参数顺序与实参对应好
Object param = method.convertArgsToSqlCommandParam(args);
// 执行操作并返回结果
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: { // 如果是更新语句
// 将参数顺序与实参对应好
Object param = method.convertArgsToSqlCommandParam(args);
// 执行操作并返回结果
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: { // 如果是删除语句MappedStatement
// 将参数顺序与实参对应好
Object param = method.convertArgsToSqlCommandParam(args);
// 执行操作并返回结果
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT: // 如果是查询语句
if (method.returnsVoid() && method.hasResultHandler()) { // 方法返回值为void,且有结果处理器
// 使用结果处理器执行查询
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) { // 多条结果查询
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) { // Map结果查询
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) { // 游标类型结果查询
result = executeForCursor(sqlSession, args);
} else { // 单条结果查询
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH: // 清空缓存语句
result = sqlSession.flushStatements();
break;
default: // 未知语句类型,抛出异常
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
// 查询结果为null,但返回类型为基本类型。因此返回变量无法接收查询结果,抛出异常。
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}MapperMethod类中还有一个内部类 ParamMap,ParamMap内部类用来存储参数,是 HashMap的子类,但是比 HashMap更为严格:如果试图获取其不存在的键值,它会直接抛出异常。这是因为当我们在数据库操作中引用了一个不存在的输入参数时,这样的错误是无法消解的。
public static class ParamMap extends HashMap {
private static final long serialVersionUID = -2212268410512043556L;
@Override
public V get(Object key) {
if (!super.containsKey(key)) {
throw new BindingException("Parameter '" + key + "' not found. Available parameters are " + keySet());
}
return super.get(key);
}
} 2.1.2 数据库操作方法的接入
上一节已经把一个数据库操作转化为了一个方法(这里指MapperMethod对象的execute方法),可这个方法怎么才能被调用呢?当调用映射接口中的方法,
如“List<User> queryUserBySchoolName(User user)”时,Java 会去该接口的实现类中寻找并执行该方法。而我们的映射接口是没有实现类的,那么调用映射接口中的方法应该会报错才对,又怎么会转而调用 MapperMethod 类中的 execute方法呢?
上述工作需要 MapperProxy 类,它基于动态代理将针对映射接口的方法调用转接成了对 MapperMethod对象 execute方法的调用,进而实现了数据库操作。
MapperProxy 继承了 InvocationHandler 接口,是一个动态代理类。这意味着当使用它的实例替代被代理对象后,对被代理对象的方法调用会被转接到 MapperProxy中 invoke方法上。
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) { // 继承自Object的方法
// 直接执行原有方法
return method.invoke(this, args);
} else if (method.isDefault()) { // 默认方法
// 执行默认方法
return invokeDefaultMethod(proxy, method, args);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
// 找对对应的MapperMethod对象
final MapperMethod mapperMethod = cachedMapperMethod(method);
// 调用MapperMethod中的execute方法
return mapperMethod.execute(sqlSession, args);
}而 MapperProxyFactory则是 MapperProxy的生产工厂,newInstance核心方法会生成一个 MapperProxy对象。
@SuppressWarnings("unchecked")
protected T newInstance(MapperProxy mapperProxy) {
// 三个参数分别是:
// 创建代理对象的类加载器、要代理的接口、代理类的处理器(即具体的实现)。
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
} 至此,我们知道,只要用对应的 MapperProxy 对象作为映射接口的实现,便可以完整地实现为映射接口接入数据库操作的功能。
2.2 抽象方法与数据库操作节点的关联
映射接口文件(UserMapper.class等存有接口的文件)那么多,其中的抽象方法又很多;另一方面,映射文件(UserMapper.xml等存有 SQL操作语句的文件)那么多,映射文件中的数据库操作节点又很多,那么这一切的对应关系怎么维护呢?也就是说,一个映射接口中的抽象方法如何确定自身要接入的 MapperMethod对象是哪一个?MyBatis分两步解决了这一问题。
第一步,MyBatis 将映射接口与 MapperProxyFactory 关联起来。这种关联关系是在MapperRegistry类的 knownMappers属性中维护的:
// 已知的所有映射
// key:mapperInterface,即dao的数据库接口,不是方法
// value:MapperProxyFactory,即映射器代理工厂
private final Map, MapperProxyFactory> knownMappers = new HashMap<>(); knownMappers 是一个 HashMap,其键为映射接口,值为对应的 MapperProxyFactory对象。
MapperProxyFactory 的构造方法如代码所示,只有一个参数便是映射接口。而MapperProxyFactory 的其他属性也不允许修改,因此它生产出的 MapperProxy 对象是唯一的。所以,只要 MapperProxyFactory 对象确定了,MapperProxy 对象也便确定了。于是,MapperRegistry中的 knownMappers属性间接地将映射接口和 MapperProxy对象关联起来。
/**
* MapperProxyFactory构造方法
* @param mapperInterface 映射接口
*/
public MapperProxyFactory(Class mapperInterface) {
this.mapperInterface = mapperInterface;
} 正因为 MapperRegistry中存储了映射接口和 MapperProxy 的对应关系,它的 getMapper方法便可直接为映射接口找出对应的代理对象。MapperProxy 对应的是映射文件。通过 MapperRegistry,映射接口和映射文件的对应关系便建立起来。该方法的源码:
/**
* 找到指定映射接口的映射文件,并根据映射文件信息为该映射接口生成一个代理实现
* @param type 映射接口
* @param sqlSession sqlSession
* @param 映射接口类型
* @return 代理实现对象
*/
@SuppressWarnings("unchecked")
public T getMapper(Class type, SqlSession sqlSession) {
// 找出指定映射接口的代理工厂
final MapperProxyFactory mapperProxyFactory = (MapperProxyFactory) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
// 通过mapperProxyFactory给出对应代理器的实例
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
} 第二步,此时的范围已经缩小到一个映射接口或者说是 MapperProxy 对象内。由MapperProxy 中的 methodCache 属性维护接口方法和 MapperMethod 对象的对应关系。methodCache属性及注释如代码:
// 该Map的键为方法,值为MapperMethod对象。通过该属性,完成了MapperProxy内(即映射接口内)方法和MapperMethod的绑定
private final Map methodCache; 这样一来,任意一个映射接口中的抽象方法都和一个 MapperProxy 对象关联的MapperMethod对象相对应,抽象方法与数据库操作节点的对应关系:
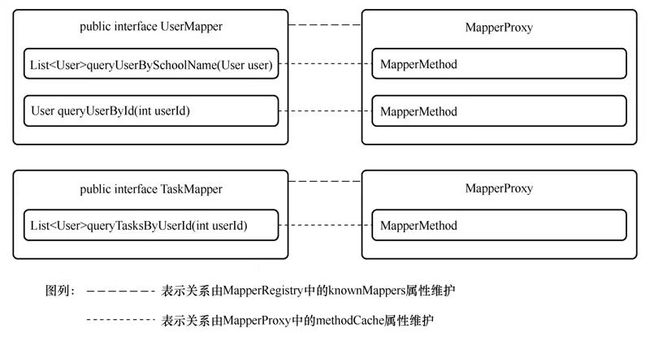
MapperProxy类就是映射接口的一个代理类。代理关系建立完成后,只要调用映射接口中的方法,都会被对应的 MapperProxy 截获,而 MapperProxy 会创建或选取合适的 MapperMethod 对象,并触发其 execute方法。于是,针对映射接口中抽象方法的调用就转变为了具体的数据库操作。
2.3 数据库操作接入总结
2.3.1 初始化阶段
MyBatis 在初始化阶段会进行各个映射文件的解析,然后将各个数据库操作节点的信息记录到 Configuration对象的 mappedStatements 属性中。Configuration 对象的 mappedStatements 属性,其结构是一个StrictMap(一个不允许覆盖键值的 HashMap),该 StrictMap的键为 SQL语句的“namespace值.语句 id 值”(如果语句 id 值没有歧义的话,还会单独再以语句 id 值为键放入一份数据),值为数据库操作节点的详细信息。
MyBatis 还会在初始化阶段扫描所有的映射接口,并根据映射接口创建与之关联的MapperProxyFactory,两者的关联关系由 MapperRegistry 维护。当调用 MapperRegistry 的getMapper方法(SqlSession的getMapper方法最终也会调用到这里)时,MapperProxyFactory会生产出一个 MapperProxy对象作为映射接口的代理。
2.3.2 数据读写阶段
当映射接口中有方法被调用时,会被代理对象 MapperProxy 拦截,转而触发了MapperProxy对象中的 invoke方法。MapperProxy对象中的 invoke方法会创建或取出该映射接口方法对应的 MapperMethod对象,在创建 MapperMethod对象的过程中,MapperMethod中 SqlCommand子类的构造方法会去 Configuration对象的 mappedStatements属性中根据当前映射接口名、方法名索引前期已经存好的 SQL语句信息。然后,MapperMethod对象的 execute方法被触发,在 execute方法内会根据不同的 SQL语句类型进行不同的数据库操作。这样,一个针对映射接口中的方法调用,终于被转化为了对应的数据库操作。
2.4 MyBatis与Spring、SpringBoot的整合
在 Spring 或 Spring Boot 中,MyBatis不需要调用 getMapper方法获取映射接口的具体实现类,甚至连配置文件都可以省略。可这是怎么做到的呢?这些问题的答案不属于 MyBatis源码的范围,但是简要了解它们能帮助我们更好地了解 MyBatis的工作原理。
MyBatis与 Spring的整合功能由 mybatis-spring项目提供,该项目是由 MyBatis团队开发的用于将 MyBatis接入 Spring的工具。基于它,能够简化 MyBatis在 Spring中的应用。
以 Spring为例,我们可以在 Spring的配置文件 applicationContext.xml 中配置指明了 MyBatis映射接口文件所在的包。Spring在启动阶段会使用 MapperScannerConfigurer 类对指定包进行扫描。对于扫描到的映射接口,mybatis-spring 会将其当作MapperFactoryBean对象注册到 Spring的 Bean列表中。而 MapperFactoryBean可以给出映射接口的代理类。
这样,我们可以在代码中直接使用@Autowired 注解来注入映射接口。然后在调用该接口时,MapperFactoryBean给出的代理类会将操作转接给 MyBatis。
Spring Boot项目诞生的目的是简化 Spring项目中的配置工作。在 Spring Boot中使用MyBatis更为简单,两者的整合主要也是靠 mybatis-spring 项目的支持。但在此基础上,增加了负责完成自动配置工作的mybatis-spring-boot-autoconfigure 项目,并将相关项目一同合并封装到了 mybatis-spring-boot-starter项目中。于是只需引用 mybatis-spring-boot-starter项目,即可将 MyBatis整合到Spring Boot中。
3. builder
builder包是一个按照类型划分出来的包,包中存在许多的建造者类。该包中也完成了两个比较重要的功能:
- 一是解析XML文件和映射文件,这部分功能在XML子包中;
- 二是解析注解形式的Mapper声明,这部分功能在annotation子包中。
3.1 建造者模式
先建造空对象,然后再不断调用set方法为对象属性赋值是一种常见的建造对象的方式,但这种方式需要了解对象的所有属性细节,是与对象的属性耦合的,建造过程中可能会遗忘某些属性。
使用具有多个输入参数的构造方法直接建造对象也是一种常见的建造对象的方式,这种情况下,为了能适应多种输入参数组合,通常需要重载大量的构造方法。
建造者模式给我们提供了另一种建造对象的思路。使用建造者模式,对象的建造细节均交给建造者来完成,调用者只需要掌控总体流程即可,而不需要了解被建造对象的细节。基于建造者创建对象时,有以下几个有点:
- 使用建造者时十分灵活,可以一次也可以分多次设置被建造对象的属性;
- 调用者只需要调用建造者的主要流程而不需要关心建造对象的细节;
- 可以很方便地修改建造者的行为,从而建造出不同的对象。
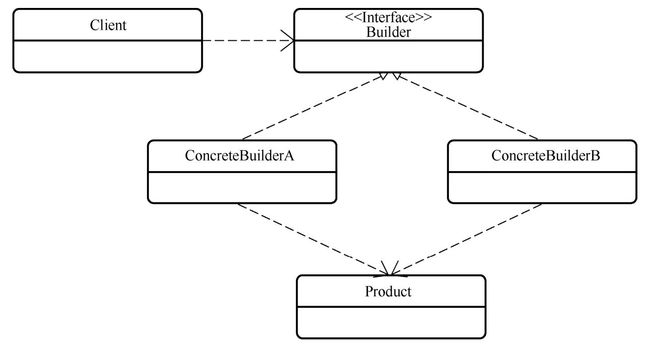
在学习了建造者模式后,可以为属性较多的类创建建造者类。建造者类一般包含两类方法:
- 一类是属性设置方法。这类方法一般有多个,可以接受不同类型的参数来设置建造者的属性。
- 一类是目标对象生产方法。该类方法一般只有一个,即根据目前建造者中的属性创建出一个目标对象。
/**
* @author Shawn
* @date 2022/3/24 23:28
* @title 建造者模式
*/
public interface UserBuilder {
UserBuilder setEmail(String email);
UserBuilder setAge(Integer age);
UserBuilder setSex(Integer sex);
User build();
}
/**
* @author Shawn
* @date 2022/3/24 23:32
* @title Function
*/
public class SunnySchoolUserBuilder implements UserBuilder{
private String name;
private String email;
private Integer age;
private Integer sex;
private String schoolName;
public SunnySchoolUserBuilder(String name) {
this.name = name;
}
@Override
public UserBuilder setEmail(String email) {
this.email = email;
return this;
}
@Override
public UserBuilder setAge(Integer age) {
this.age = age;
return this;
}
@Override
public UserBuilder setSex(Integer sex) {
this.sex = sex;
return this;
}
@Override
public User build() {
if (this.name != null && this.email == null) {
this.email = this.name.toLowerCase(Locale.ROOT).replace(" ", "").concat("@sunnyschool.com");
}
if (this.age == null) this.age = 7;
if (this.sex == null) this.sex = 0;
this.schoolName = "Sunny School";
return new User(name,email,age,sex,schoolName);
}
}
/**
* @author Shawn
* @date 2022/3/24 23:30
* @title Function
*/
public class User {
private String name;
private String email;
private Integer age;
private Integer sex;
private String schoolName;
public User() {
}
public User(String name, String email, Integer age, Integer sex, String schoolName) {
this.name = name;
this.email = email;
this.age = age;
this.sex = sex;
this.schoolName = schoolName;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Integer getSex() {
return sex;
}
public void setSex(Integer sex) {
this.sex = sex;
}
public String getSchoolName() {
return schoolName;
}
public void setSchoolName(String schoolName) {
this.schoolName = schoolName;
}
}
3.2 建造者基类和工具类
builder包中的 BaseBuilder 类是所有建造者的基类,BaseBuilder类及其子类的类图:
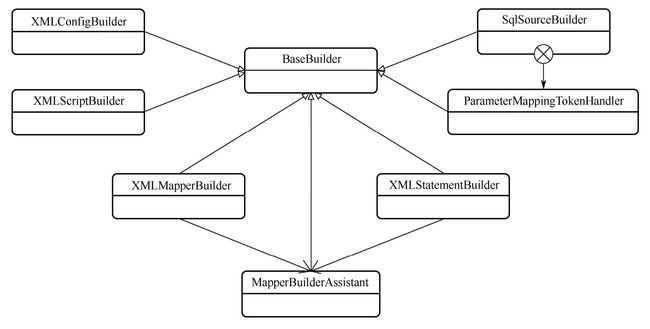
BaseBuilder类虽然被声明成一个抽象类,但是本身不含有任何的抽象方法,因此它的子类无须实现它的任何方法。BaseBuilder类更像一个工具类,为继承它的建造者类提供了众多实用的工具方法。当然,有很多建造者类不需要 BaseBuilder提供的工具方法,因此没有继承 BaseBuilder,这些类有 MapperAnnotationBuilder、SelectBuilder等。BaseBuilder类提供的工具方法大致分为以下几类:
- *ValueOf:类型转化函数,负责将输入参数转换为指定的类型,并支持默认值设置;
- resolve*:字符串转枚举类型函数,根据字符串找出指定的枚举类型并返回;
- createInstance:根据类型别名创建类型实例;
- resolveTypeHandler:根据类型处理器别名返回类型处理器实例。
在BaseBuilder类的子类中,MapperBuilderAssistant类最为特殊,因为它本身不是建造者类而是一个建造者辅助类。它继承 BaseBuilder 类的原因仅仅是因为要使用 BaseBuilder类中的方法。
MyBatis 映射文件中的设置项非常多,包括命名空间、缓存共享、结果映射等。最终这些设置将解析生成不同的类,而 MapperBuilderAssistant类是这些解析映射文件配置项类的辅助类。
MapperBuilderAssistant 类提供了许多辅助方法,如 Mapper 命名空间的设置、缓存的创建、鉴别器的创建等。例如,缓存创建方法:
/**
* 创建一个新的缓存
* @param typeClass 缓存的实现类
* @param evictionClass 缓存的清理类,即使用哪种包装类来清理缓存
* @param flushInterval 缓存清理时间间隔
* @param size 缓存大小
* @param readWrite 缓存是否支持读写
* @param blocking 缓存是否支持阻塞
* @param props 缓存配置属性
* @return 缓存
*/
public Cache useNewCache(Class typeClass,
Class evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
Cache cache = new CacheBuilder(currentNamespace)
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();
configuration.addCache(cache);
currentCache = cache;
return cache;
}通过 BaseBuilder 类和 MapperBuilderAssistant 类我们知道,建造者类不一定继承了BaseBuilder,而继承了 BaseBuilder的类也不一定是建造者类。
3.3 SqlSourceBuilder 类和 StaticSqlSource 类
SqlSourceBuilder 是一个建造者类,但它被解析或转化,它不能用来创建所有的 SqlSource 对象(SqlSource 是一个接口,有四种实现),而是只能通过 parse 方法生产出 StaticSqlSource 这一种对象。确切地说,SqlSourceBuilder 类能够将 DynamicSqlSource 和 RawSqlSource 中的“#{}”符号替换掉,从而将它们转化为 StaticSqlSource。
/**
* 将DynamicSqlSource和RawSqlSource中的“#{}”符号替换掉,从而将他们转化为StaticSqlSource
* @param originalSql sqlNode.apply()拼接之后的sql语句。已经不包含 等节点,也不含有${}符号
* @param parameterType 实参类型
* @param additionalParameters 附加参数
* @return 解析结束的StaticSqlSource
*/
public SqlSource parse(String originalSql, Class parameterType, Map additionalParameters) {
// 用来完成#{}处理的处理器
ParameterMappingTokenHandler handler = new ParameterMappingTokenHandler(configuration, parameterType, additionalParameters);
// 通用的占位符解析器,用来进行占位符替换
GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);
// 将#{}替换为?的SQL语句
String sql = parser.parse(originalSql);
// 生成新的StaticSqlSource对象
return new StaticSqlSource(configuration, sql, handler.getParameterMappings());
} 因此,把 SqlSourceBuilder类称作一个解析器或者转化器更合适。而事实上,许多引用 SqlSourceBuilder对象的地方都将对象的变量名定为“sqlSourceParser”(在 DynamicSqlSource和 RawSqlSource类中都能找到这个变量)。
StaticSqlSource是 SqlSource的四个子类之一,它内部包含的 SQL语句中已经不存在“${}”和“#{}”这两种符号,而只有“?”,其属性的注释如代码所示:
// 经过解析后,不存在${}和#{}这两种符号,只剩下?符号的SQL语句
private final String sql;
// SQL语句对应的参数列表
private final List parameterMappings;
// 配置信息
private final Configuration configuration; StaticSqlSource 有一个非常重要的功能,那就是给出一个 BoundSql 对象。StaticSqlSource内 getBoundSql 方法负责完成这项功能:
/**
* 组建一个BoundSql对象
* @param parameterObject 参数对象
* @return 组件的BoundSql对象
*/
@Override
public BoundSql getBoundSql(Object parameterObject) {
return new BoundSql(configuration, sql, parameterMappings, parameterObject);
}3.4 CacheRefResolver 类和 ResultMapResolver 类
CacheRefResolver类和 ResultMapResolver类有几分相似之处,不仅类名上相似,在结构和功能上也相似。它们都是某些类的解析器类,属性中包含被解析类的相关属性,同时还包含一个解析器。这些整合后的具有解析功能的类在 MyBatis中有着规范的命名:假如被解析对象名称为 A,则整合后的自解析类叫作 AResolver。这样,在之后的分析中遇到这样命名的类,就可以直接分析它的组成和作用。这种命名方式和功能是相对通用的,但不是绝对的。例如,annotation子包中的 MethodResolver就符合这种模式,包含被解析对象的属性和解析器;而ParamNameResolver 就不符合这种模式,因为它的解析功能是自身通过方法实现的,不需要依赖其他的解析器。
3.4.1 CacheRefResolver 类
MyBatis支持多个 namespace之间共享缓存。如代码14-10所示,在“com.company.app.dao.UserDao”的命名空间内我们通过<cache-ref>标签声明了另外一个命名空间“com.company.app.dao.TaskDao”,那么前者会使用后者的缓存。
CacheRefResolver 类用来处理多个命名空间共享缓存的问题。它自身有两个属性,这两个属性中,assistant是解析器,cacheRefNamespace是被解析对象。
/**
* @author Clinton Begin
*
* 缓存引用解析器
*
* 包含了被解析的对象cacheRefNamespace 和对应的解析器MapperBuilderAssistant 因此具有自解析功能。
*/
public class CacheRefResolver {
// Mapper建造者辅助类
private final MapperBuilderAssistant assistant;
// 被应用的namespace,即使用cacheRefNamespace的缓存空间
private final String cacheRefNamespace;
public CacheRefResolver(MapperBuilderAssistant assistant, String cacheRefNamespace) {
this.assistant = assistant;
this.cacheRefNamespace = cacheRefNamespace;
}
public Cache resolveCacheRef() {
return assistant.useCacheRef(cacheRefNamespace);
}
}
/**
* 使用其他namespace的缓存
* @param namespace 其他的namespace
* @return 其他namespace的缓存
*/
public Cache useCacheRef(String namespace) {
if (namespace == null) {
throw new BuilderException("cache-ref element requires a namespace attribute.");
}
try {
unresolvedCacheRef = true;
// 获取其他namespace的缓存
Cache cache = configuration.getCache(namespace);
if (cache == null) {
throw new IncompleteElementException("No cache for namespace '" + namespace + "' could be found.");
}
// 修改当前缓存为其他namespace的缓存,从而实现缓存共享
currentCache = cache;
unresolvedCacheRef = false;
return cache;
} catch (IllegalArgumentException e) {
throw new IncompleteElementException("No cache for namespace '" + namespace + "' could be found.", e);
}
}借助于 MapperBuilderAssistant的 useCacheRef方法,CacheRefResolver类可以解析缓存共享的问题。
3.4.2 ResultMapResolver 类
MyBatis的 resultMap 标签支持继承。如下图所示,girlUserMap通过设置extends="userMap"继承"userMap"中设置的属性映射。
 resultMap 继承关系的解析由 ResultMapResolver 类来完成。ResultMapResolver类的属性中, assistant属性是解析器,其他属性则是被解析的属性。
resultMap 继承关系的解析由 ResultMapResolver 类来完成。ResultMapResolver类的属性中, assistant属性是解析器,其他属性则是被解析的属性。
// Mapper建造者辅助类
private final MapperBuilderAssistant assistant;
// ResultMap的id
private final String id;
// ResultMap的type属性,即目标对象类型
private final Class type;
// ResultMap的extends属性,即继承属性
private final String extend;
// ResultMap中的Discriminator节点,即鉴别器
private final Discriminator discriminator;
// ResultMap中的属性映射列表
private final List resultMappings;
// ResultMap的autoMapping属性,即是否开启自动映射
private final Boolean autoMapping; 借助于 MapperBuilderAssistant 的 addResultMap 方法,ResultMapResolver 完成了ResultMap 的继承关系解析,最终给出一个解析完继承关系之后的 ResultMap 对象。MapperBuilderAssistant的 addResultMap方法如代码所示:
/**
* 创建结果映射对象
* 入参参照ResultMap属性
* @return ResultMap对象
*/
public ResultMap addResultMap(
String id,
Class type,
String extend,
Discriminator discriminator,
List resultMappings,
Boolean autoMapping) {
id = applyCurrentNamespace(id, false);
extend = applyCurrentNamespace(extend, true);
// 解析ResultMap的继承关系
if (extend != null) { // 如果存在ResultMap的继承
if (!configuration.hasResultMap(extend)) {
throw new IncompleteElementException("Could not find a parent resultmap with id '" + extend + "'");
}
// 获取父级的ResultMap
ResultMap resultMap = configuration.getResultMap(extend);
// 获取父级的属性映射
List extendedResultMappings = new ArrayList<>(resultMap.getResultMappings());
// 删除当前ResultMap中已有的父级属性映射,为当前属性映射覆盖父级属性属性创造条件
extendedResultMappings.removeAll(resultMappings);
// 如果当前ResultMap设置有构建器,则移除父级构建器
boolean declaresConstructor = false;
for (ResultMapping resultMapping : resultMappings) {
if (resultMapping.getFlags().contains(ResultFlag.CONSTRUCTOR)) {
declaresConstructor = true;
break;
}
}
if (declaresConstructor) {
extendedResultMappings.removeIf(resultMapping -> resultMapping.getFlags().contains(ResultFlag.CONSTRUCTOR));
}
// 最终从父级继承而来的所有属性映射
resultMappings.addAll(extendedResultMappings);
}
// 创建当前的ResultMap
ResultMap resultMap = new ResultMap.Builder(configuration, id, type, resultMappings, autoMapping)
.discriminator(discriminator)
.build();
// 将当期的ResultMap加入到Configuration
configuration.addResultMap(resultMap);
return resultMap;
} 3.5 ParameterExpression 类
ParameterExpression 是一个属性解析器,用来将描述属性的字符串解析为键值对的形式。
ParameterExpression 的构造方法是属性解析的总入口,也是整个类中唯一的 public 方法。ParameterExpression 类继承了 HashMap,内部能以键值对的形式保存最后的解析结果。
public ParameterExpression(String expression) {
parse(expression);
}
// content = id, javaType= int, jdbcType=NUMERIC, typeHandler=DemoTypeHandler ;
private void parse(String expression) {
// 跳过空格
int p = skipWS(expression, 0);
// 跳过左括号
if (expression.charAt(p) == '(') {
expression(expression, p + 1);
} else {
// 处理参数
property(expression, p);
}
}对于这种以字符串处理为主的类,最合适的源码阅读方法是断点调试法。对于没有声明属性名称的属性值,ParameterExpression会为其赋予默认的属性名称“expression”。
3.6 XML文件解析
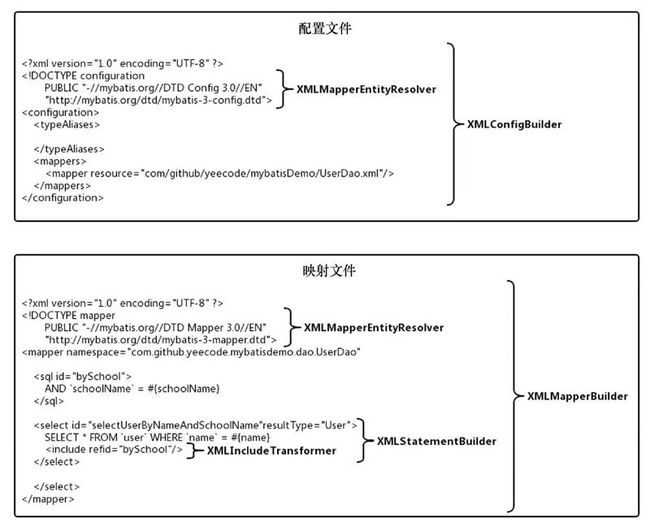
MyBatis的配置文件和映射文件都是 XML文件,最终这些 XML文件需要被解析成为对应的类。builder包的 xml子包用来完成 XML文件的解析工作。MyBatis 的配置文件和映射文件中包含的节点很多。这些节点的解析是由 xml 子包中的五个解析器类逐层配合完成的,解析器类的解析范围示意图:
3.6.1 XML文件的声明解析
XML文件可以引用外部的 DTD文件来对 XML文件进行校验。如下代码所示的 DOCTYPE声明中,表明当前 XML文件引用的 DTD文件的地址是“http://mybatis.org/dtd/mybatis-3-config.dtd”。
 然而,MyBatis可能会运行在无网络的环境中,无法通过互联网下载 DTD文件。这时该怎么办?XMLMapperEntityResolver就是用来解决这个问题的。在“org.xml.sax.EntityResolver”接口中存在一个 resolveEntity 方法,可以通过实现该方法自定义给出 DTD文档流的方式,而不是只能从互联网下载 DTD文档。XMLMapperEntityResolver 继承了“org.xml.sax.EntityResolver”接口,并实现了resolveEntity方法,如代码所示:
然而,MyBatis可能会运行在无网络的环境中,无法通过互联网下载 DTD文件。这时该怎么办?XMLMapperEntityResolver就是用来解决这个问题的。在“org.xml.sax.EntityResolver”接口中存在一个 resolveEntity 方法,可以通过实现该方法自定义给出 DTD文档流的方式,而不是只能从互联网下载 DTD文档。XMLMapperEntityResolver 继承了“org.xml.sax.EntityResolver”接口,并实现了resolveEntity方法,如代码所示:
/**
* 在一个XML文件的头部是这样的:
*
* 那么上述例子中,
* @param publicId 为-//mybatis.org//DTD Config 3.0//EN
* @param systemId 为http://mybatis.org/dtd/mybatis-3-config.dtd
* @return 对应DTD文档的输入流
* @throws SAXException
*/
@Override
public InputSource resolveEntity(String publicId, String systemId) throws SAXException {
try {
if (systemId != null) {
// 将systemId转为全小写
String lowerCaseSystemId = systemId.toLowerCase(Locale.ENGLISH);
if (lowerCaseSystemId.contains(MYBATIS_CONFIG_SYSTEM) || lowerCaseSystemId.contains(IBATIS_CONFIG_SYSTEM)) {
// 说明这个是配置文档
// 直接把本地配置文档的dtd文件返回
return getInputSource(MYBATIS_CONFIG_DTD, publicId, systemId);
} else if (lowerCaseSystemId.contains(MYBATIS_MAPPER_SYSTEM) || lowerCaseSystemId.contains(IBATIS_MAPPER_SYSTEM)) {
// 说明这个是映射文档
// 直接把本地映射文档的dtd文件返回
return getInputSource(MYBATIS_MAPPER_DTD, publicId, systemId);
}
}
return null;
} catch (Exception e) {
throw new SAXException(e.toString());
}
}XMLMapperEntityResolver的 resolveEntity方法通过字符串匹配找出了本地的 DTD文档并返回,因此 MyBatis可以在无网络的环境下正常地校验 XML文件。
3.6.2 配置文件解析
配置文件的解析工作是由 XMLConfigBuilder 类负责的,同时该类会用解析的结果建造出一个 Configuration对象。XMLConfigBuilder类的入口方法是 parse方法,它调用 parseConfiguration方法后正式展开配置文件的逐层解析工作。
/**
* 解析配置文件的入口方法
* @return Configuration对象
*/
public Configuration parse() {
// 不允许重复解析
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
// 从根节点开展解析
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
/**
* 从根节点configuration开始解析下层节点
* @param root 根节点configuration节点
*/
private void parseConfiguration(XNode root) {
try {
// 解析信息放入Configuration
// 首先解析properties,以保证在解析其他节点时便可以生效
propertiesElement(root.evalNode("properties"));
Properties settings = settingsAsProperties(root.evalNode("settings"));
loadCustomVfs(settings);
loadCustomLogImpl(settings);
typeAliasesElement(root.evalNode("typeAliases"));
pluginElement(root.evalNode("plugins"));
objectFactoryElement(root.evalNode("objectFactory"));
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
reflectorFactoryElement(root.evalNode("reflectorFactory"));
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
environmentsElement(root.evalNode("environments"));
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
typeHandlerElement(root.evalNode("typeHandlers"));
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}parseConfiguration 方法会调用不同的子方法解析下级节点,这些方法大同小异。我们以解析“/configuration/mappers”节点的 mapperElement方法为例进行介绍。
/**
* 解析mappers节点,例如:
*
*
* @param parent mappers节点
* @throws Exception
*/
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
// 处理mappers的子节点,即mapper节点或者package节点
if ("package".equals(child.getName())) { // package节点
// 取出包的路径
String mapperPackage = child.getStringAttribute("name");
// 全部加入Mappers中
configuration.addMappers(mapperPackage);
} else {
// resource、url、class这三个属性只有一个生效
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
if (resource != null && url == null && mapperClass == null) {
ErrorContext.instance().resource(resource);
// 获取文件的输入流
InputStream inputStream = Resources.getResourceAsStream(resource);
// 使用XMLMapperBuilder解析Mapper文件
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url != null && mapperClass == null) {
ErrorContext.instance().resource(url);
// 从网络获得输入流
InputStream inputStream = Resources.getUrlAsStream(url);
// 使用XMLMapperBuilder解析Mapper文件
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
// 配置的不是Mapper文件,而是Mapper接口
Class mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}
XMLConfigBuilder在 MyBatis的配置解析中起到了引导的作用,正是从它的 parse方法开始,引发了配置文件和映射文件的解析。当解析到映射文件时,会调用 XMLMapperBuilder 类继续展开映射文件的解析。
3.6.3 数据库操作语句解析
映射文件的解析由 XMLMapperBuilder类负责,该类的结构与 XMLConfigBuilder 类十分类似。parse 方法为解析的入口方法,然后调用 configurationElement 方法逐层完成解析。
/**
* 解析Mapper文件
*/
public void parse() {
// 该节点是否被解析过
if (!configuration.isResourceLoaded(resource)) {
// 处理mapper节点
configurationElement(parser.evalNode("/mapper"));
// 加入到已经解析的列表,防止重复解析
configuration.addLoadedResource(resource);
// 将mapper注册给Configuration
bindMapperForNamespace();
}
// 下面分别用来处理失败的、、SQL语句
parsePendingResultMaps();
parsePendingCacheRefs();
parsePendingStatements();
}
/**
* 解析Mapper文件的下层节点
* @param context Mapper文件的根节点
*/
private void configurationElement(XNode context) {
try {
// 读取当前Mapper文件的命名空间
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
// mapper文件中其他配置节点的解析
cacheRefElement(context.evalNode("cache-ref"));
cacheElement(context.evalNode("cache"));
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
resultMapElements(context.evalNodes("/mapper/resultMap"));
sqlElement(context.evalNodes("/mapper/sql"));
// 处理各个数据库操作语句
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
} 与 XMLConfigBuilder类中的 parse方法不同,XMLMapperBuilder的 parse方法结尾处有三个 parsePending*方法。它们用来处理解析过程中的暂时性错误。由 configurationElement(parser.evalNode("/mapper"))语句触发后,系统会依次解析映射文件的各个节点。解析时是从上到下读取文件解析的,可能会解析到一个节点,但它引用的节点还没有被定义。例如在解析“id="girlUserMap"”的 resultMap时,它通过“extends="userMap"”引用的“id="userMap"”的 resultMap 还未被读入。此时就会出现暂时性的错误。出现暂时性错误后,“id="girlUserMap"”的 resultMap就会被写入 incompleteResultMaps列表中。Configuration中有几个属性,都是用来存储暂时性错误的节点的。
// 暂存未处理完成的一些节点
protected final Collection incompleteStatements = new LinkedList<>();
protected final Collection incompleteCacheRefs = new LinkedList<>();
protected final Collection incompleteResultMaps = new LinkedList<>();
protected final Collection incompleteMethods = new LinkedList<>(); 上述的这种依赖无法确认的情况是暂时的,只要在第一次解析完成后,再处理一遍这些错误节点即可。这是解决无序依赖的一种常见办法,即先尝试第一轮解析,并在解析时将所有节点读入。之后进行第二轮解析,处理第一轮解析时依赖寻找失败的节点。由于已经在第一遍解析时读入了所有节点,因此第二遍解析的依赖总是可以找到的。还有另外一种方法,更为直接和简单,即在第一轮解析时只读入所有节点,但不处理依赖关系,然后在第二轮解析时只处理依赖关系。Spring初始化时对 Bean之间的依赖处理采用的就是这种方式。
3.6.4 Statement解析
在映射文件的解析中,一个重点就是解析数据库操作节点,即 select、insert、update、delete这四类节点。数据库操作节点的解析由 XMLStatementBuilder完成。XMLStatementBuilder 类中的 parseStatementNode方法完成主要的解析过程,该方法源码如代码所示:
/**
* 解析select、insert、update、delete这四类节点
*/
public void parseStatementNode() {
// 读取当前节点的id与databaseId
String id = context.getStringAttribute("id");
String databaseId = context.getStringAttribute("databaseId");
// 验证id与databaseId是否匹配。MyBatis允许多数据库配置,因此有些语句只对特定数据库生效
if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) {
return;
}
// 读取节点名
String nodeName = context.getNode().getNodeName();
// 读取和判断语句类型
SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
boolean useCache = context.getBooleanAttribute("useCache", isSelect);
boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);
// 处理语句中的Include节点
XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant);
includeParser.applyIncludes(context.getNode());
// 参数类型
String parameterType = context.getStringAttribute("parameterType");
Class parameterTypeClass = resolveClass(parameterType);
// 语句类型
String lang = context.getStringAttribute("lang");
LanguageDriver langDriver = getLanguageDriver(lang);
// 处理SelectKey节点,在这里会将KeyGenerator加入到Configuration.keyGenerators中
processSelectKeyNodes(id, parameterTypeClass, langDriver);
// 此时, 和 节点均已被解析完毕并被删除,开始进行SQL解析
KeyGenerator keyGenerator;
String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;
keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true);
// 判断是否已经有解析好的KeyGenerator
if (configuration.hasKeyGenerator(keyStatementId)) {
keyGenerator = configuration.getKeyGenerator(keyStatementId);
} else {
// 全局或者本语句只要启用自动key生成,则使用key生成
keyGenerator = context.getBooleanAttribute("useGeneratedKeys",
configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType))
? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
}
// 读取各个配置属性
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString()));
Integer fetchSize = context.getIntAttribute("fetchSize");
Integer timeout = context.getIntAttribute("timeout");
String parameterMap = context.getStringAttribute("parameterMap");
String resultType = context.getStringAttribute("resultType");
Class resultTypeClass = resolveClass(resultType);
String resultMap = context.getStringAttribute("resultMap");
String resultSetType = context.getStringAttribute("resultSetType");
ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType);
if (resultSetTypeEnum == null) {
resultSetTypeEnum = configuration.getDefaultResultSetType();
}
String keyProperty = context.getStringAttribute("keyProperty");
String keyColumn = context.getStringAttribute("keyColumn");
String resultSets = context.getStringAttribute("resultSets");
// 在MapperBuilderAssistant的帮助下创建MappedStatement对象,并写入到Configuration中
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
} 我们看到 parseStatementNode方法引用了 XMLIncludeTransformer对象处理数据库操作节点中的 include节点。
3.6.5 引用解析
MyBatis支持在数据库操作语句的编写中引用语句片段。这让代码片段的复用成为可能,提高了 MyBatis中数据库操作语句的编写效率。
代码中 include节点的解析是由 XMLIncludeTransformer负责的,它能将 SQL语句中的 include节点替换为被引用的 SQL片段。XMLIncludeTransformer 类中的 applyIncludes(Node)方法是解析 include 节点的入口方法,而 applyIncludes(Node,Properties,boolean)方法则是核心方法。
/**
* 解析数据库操作节点中的include节点
* @param source 数据库操作节点,即select、insert、update、delete这四类节点
*/
public void applyIncludes(Node source) {
Properties variablesContext = new Properties();
// 读取全局属性信息
Properties configurationVariables = configuration.getVariables();
Optional.ofNullable(configurationVariables).ifPresent(variablesContext::putAll);
applyIncludes(source, variablesContext, false);
}
/**
* Recursively apply includes through all SQL fragments.
* @param source Include node in DOM tree
* @param variablesContext Current context for static variables with values
*/
/**
* 解析数据库操作节点中的include节点
* @param source 数据库操作节点或其子节点
* @param variablesContext 全局属性信息
* @param included 是否嵌套
*/
private void applyIncludes(Node source, final Properties variablesContext, boolean included) {
if (source.getNodeName().equals("include")) { // 当前节点是include节点
// 找出被应用的节点
Node toInclude = findSqlFragment(getStringAttribute(source, "refid"), variablesContext);
Properties toIncludeContext = getVariablesContext(source, variablesContext);
// 递归处理被引用节点中的include节点
applyIncludes(toInclude, toIncludeContext, true);
if (toInclude.getOwnerDocument() != source.getOwnerDocument()) {
toInclude = source.getOwnerDocument().importNode(toInclude, true);
}
// 完成include节点的替换
source.getParentNode().replaceChild(toInclude, source);
while (toInclude.hasChildNodes()) {
toInclude.getParentNode().insertBefore(toInclude.getFirstChild(), toInclude);
}
toInclude.getParentNode().removeChild(toInclude);
} else if (source.getNodeType() == Node.ELEMENT_NODE) { // 元素节点
if (included && !variablesContext.isEmpty()) {
// 用属性值替代变量
NamedNodeMap attributes = source.getAttributes();
for (int i = 0; i < attributes.getLength(); i++) {
Node attr = attributes.item(i);
attr.setNodeValue(PropertyParser.parse(attr.getNodeValue(), variablesContext));
}
}
// 循环到下层节点递归处理下层的include节点
NodeList children = source.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
applyIncludes(children.item(i), variablesContext, included);
}
} else if (included && source.getNodeType() == Node.TEXT_NODE
&& !variablesContext.isEmpty()) { // 文本节点
// 用属性值替代变量
source.setNodeValue(PropertyParser.parse(source.getNodeValue(), variablesContext));
}
}include节点的解析过程示意图:

3.7 注解映射的解析
通常我们使用 XML形式的映射文件来完成 MyBatis的映射配置。同时,MyBatis也支持使用注解来配置映射,builder 包中的 annotation 子包就可以用来完成这种形式的映射解析工作。使用注解来配置映射的方式可能使用得比较少,我们在本节将先介绍这种配置方式,然后阅读 annotation子包的源码来了解 MyBatis如何对注解映射进行解析。
 同理,除了@Select 注解外,@Insert、@Update、@Delete 注解也可以实现类似的功能。MyBatis还支持一种更为灵活的注解方式:
同理,除了@Select 注解外,@Insert、@Update、@Delete 注解也可以实现类似的功能。MyBatis还支持一种更为灵活的注解方式:
![]()
在这种方式中,可以为抽象方法增加@SelectProvider注解,该注解中的 type字段指向一个类,method 指向了该类中的一个方法。最终,type 类中的 method 方法返回的字符串将作为 queryUserBySchoolName方法所绑定的 SQL语句,如代码所示:

同样,除@SelectProvider 注解外,还有@InsertProvider、@UpdateProvider、@DeleteProvider这三种注解。我们将@Select、@Insert、@Update、@Delete这四种注解方式称 为 直 接 注 解 映 射,将@SelectProvider、@InsertProvider、@UpdateProvider、@DeleteProvider这四种注解方式称为间接注解映射。
显然,采用间接注解时可以在生成 SQL语句的方法中添加复杂的逻辑,因此更为灵活一些。
3.7.2 注解映射解析的触发
注解映射解析是从 MapperAnnotationBuilder 类中的 parse方法开始的。在该方法被触发之前,MapperAnnotationBuilder 类已经在静态代码块中完成了一些初始化工作:将直接注解映射的四种注解放入了 SQL_ANNOTATION_TYPES常量中;将间接注解映射的四种注解放入了 SQL_PROVIDER_ANNOTATION_TYPES常量中。
static {
SQL_ANNOTATION_TYPES.add(Select.class);
SQL_ANNOTATION_TYPES.add(Insert.class);
SQL_ANNOTATION_TYPES.add(Update.class);
SQL_ANNOTATION_TYPES.add(Delete.class);
SQL_PROVIDER_ANNOTATION_TYPES.add(SelectProvider.class);
SQL_PROVIDER_ANNOTATION_TYPES.add(InsertProvider.class);
SQL_PROVIDER_ANNOTATION_TYPES.add(UpdateProvider.class);
SQL_PROVIDER_ANNOTATION_TYPES.add(DeleteProvider.class);
}当配置文件中存在如代码14-32所示的配置时,就会触发 MapperAnnotationBuilder类中的 parse方法,开始映射接口文件的解析工作。
parse方法比较简短,其源码如代码所示:
/**
* 解析包含注解的接口文档
*/
public void parse() {
String resource = type.toString();
// 防止重复分析
if (!configuration.isResourceLoaded(resource)) {
// 寻找类名对应的resource路径下是否有xml配置,如果有则解析掉。这样就支持注解和xml混合使用
loadXmlResource();
// 记录资源路径
configuration.addLoadedResource(resource);
// 设置命名空间
assistant.setCurrentNamespace(type.getName());
// 处理缓存
parseCache();
parseCacheRef();
Method[] methods = type.getMethods();
for (Method method : methods) {
try {
// 排除桥接方法
// JDK 1.5 引入泛型后,为了使Java的泛型方法生成的字节码和 1.5 版本前的字节码相兼容,由编译器自动生成的方法,这个就是桥接方法。
// 就是说一个子类在继承(或实现)一个父类(或接口)的泛型方法时,在子类中明确指定了泛型类型,那么在编译时编译器会自动生成桥接方法
if (!method.isBridge()) {
// 解析该方法
parseStatement(method);
}
} catch (IncompleteElementException e) {
// 解析异常的方法暂存起来
configuration.addIncompleteMethod(new MethodResolver(this, method));
}
}
}
// 处理解析异常的方法
parsePendingMethods();
}
在阅读 parse方法的源码时,有两点需要注意:
- 第一点是“!method.isBridge()”语句,该操作是为了排除桥接方法。桥接方法是为了匹配泛型的类型擦除而由编译器自动引入的,并非用户编写的方法,因此要排除掉。
- 第二点是 parsePendingMethods方法,在解析接口方法时,可能会遇到一些尚未读取的其他信息,如未解析的 ResultMap 信息、尚未解析的命名空间等,这时就会将该方法放入 Configuration 类中的 incompleteMethods 属性中,在最后再次处理。在再次处理时,用到了 MethodResolver 对象,该对象通过调用 parseStatement方法对解析失败的接口方法进行再一次的解析。
/**
* 解析该方法。主要是解析该方法上的注解信息
* @param method 要解析的方法
*/
void parseStatement(Method method) {
// 通过子方法获取参数类型
Class parameterTypeClass = getParameterType(method);
// 获取方法的脚本语言驱动
LanguageDriver languageDriver = getLanguageDriver(method);
// 通过注解获取SqlSource
SqlSource sqlSource = getSqlSourceFromAnnotations(method, parameterTypeClass, languageDriver);
if (sqlSource != null) {
// 获取方法上可能存在的配置信息,配置信息由@Options注解指定
Options options = method.getAnnotation(Options.class);
final String mappedStatementId = type.getName() + "." + method.getName();
// 用默认值初始化各项设置
Integer fetchSize = null;
Integer timeout = null;
StatementType statementType = StatementType.PREPARED;
ResultSetType resultSetType = configuration.getDefaultResultSetType();
SqlCommandType sqlCommandType = getSqlCommandType(method);
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
boolean flushCache = !isSelect;
boolean useCache = isSelect;
// 主键自动生成的处理
KeyGenerator keyGenerator;
String keyProperty = null;
String keyColumn = null;
if (SqlCommandType.INSERT.equals(sqlCommandType) || SqlCommandType.UPDATE.equals(sqlCommandType)) {
// first check for SelectKey annotation - that overrides everything else
SelectKey selectKey = method.getAnnotation(SelectKey.class);
if (selectKey != null) {
keyGenerator = handleSelectKeyAnnotation(selectKey, mappedStatementId, getParameterType(method), languageDriver);
keyProperty = selectKey.keyProperty();
} else if (options == null) {
// 这里不能单独配置,因此查看全局配置
keyGenerator = configuration.isUseGeneratedKeys() ? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
} else {
keyGenerator = options.useGeneratedKeys() ? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
keyProperty = options.keyProperty();
keyColumn = options.keyColumn();
}
} else {
keyGenerator = NoKeyGenerator.INSTANCE;
}
if (options != null) {
// 根据@Options中的配置信息重新设置配置
if (FlushCachePolicy.TRUE.equals(options.flushCache())) {
flushCache = true;
} else if (FlushCachePolicy.FALSE.equals(options.flushCache())) {
flushCache = false;
}
useCache = options.useCache();
fetchSize = options.fetchSize() > -1 || options.fetchSize() == Integer.MIN_VALUE ? options.fetchSize() : null; //issue #348
timeout = options.timeout() > -1 ? options.timeout() : null;
statementType = options.statementType();
if (options.resultSetType() != ResultSetType.DEFAULT) {
resultSetType = options.resultSetType();
}
}
// 返回结果ResultMap处理
String resultMapId = null;
ResultMap resultMapAnnotation = method.getAnnotation(ResultMap.class);
if (resultMapAnnotation != null) {
resultMapId = String.join(",", resultMapAnnotation.value());
} else if (isSelect) {
resultMapId = parseResultMap(method);
}
// 将获取的映射信息存入Configuration
assistant.addMappedStatement(
mappedStatementId,
sqlSource,
statementType,
sqlCommandType,
fetchSize,
timeout,
// ParameterMapID
null,
parameterTypeClass,
resultMapId,
getReturnType(method),
resultSetType,
flushCache,
useCache,
// TODO gcode issue #577
false,
keyGenerator,
keyProperty,
keyColumn,
// DatabaseID
null,
languageDriver,
// ResultSets
options != null ? nullOrEmpty(options.resultSets()) : null);
}
}上述 parse方法中,调用了 parseStatement逐步完成对方法上注解的 SQL语句的解析,并存储到 configuration对象中。parseStatement 方法中处理了参数、配置信息等额外的信息,其中最关键的是调用getSqlSourceFromAnnotations方法获取了 SqlSource对象。在这个方法中,分析了注解中的内容。该方法的源码如代码所示:
/**
* 通过注解获取SqlSource对象
* @param method 含有注解的方法
* @param parameterType 参数类型
* @param languageDriver 语言驱动
* @return SqlSource对象
*/
private SqlSource getSqlSourceFromAnnotations(Method method, Class parameterType, LanguageDriver languageDriver) {
try {
// 遍历寻找是否有Select、Insert、Update、Delete 四个注解之一
Class sqlAnnotationType = getSqlAnnotationType(method);
// 遍历寻找是否有SelectProvider、insertProvider、UpdateProvider、DeleteProvider四个注解之一
Class sqlProviderAnnotationType = getSqlProviderAnnotationType(method);
if (sqlAnnotationType != null) {
if (sqlProviderAnnotationType != null) {
// 两类注解不可同时使用
throw new BindingException("You cannot supply both a static SQL and SqlProvider to method named " + method.getName());
}
// 含有Select、Insert、Update、Delete 四个注解之一
Annotation sqlAnnotation = method.getAnnotation(sqlAnnotationType);
// 取出value值
final String[] strings = (String[]) sqlAnnotation.getClass().getMethod("value").invoke(sqlAnnotation);
// 基于字符串构建SqlSource
return buildSqlSourceFromStrings(strings, parameterType, languageDriver);
} else if (sqlProviderAnnotationType != null) {
// 含有SelectProvider、insertProvider、UpdateProvider、DeleteProvider四个注解之一
Annotation sqlProviderAnnotation = method.getAnnotation(sqlProviderAnnotationType);
// 根据对应的方法获取SqlSource
return new ProviderSqlSource(assistant.getConfiguration(), sqlProviderAnnotation, type, method);
}
return null;
} catch (Exception e) {
throw new BuilderException("Could not find value method on SQL annotation. Cause: " + e, e);
}
}3.7.3 直接注解映射的解析
直接注解映射由 MapperAnnotationBuilder 对象的 buildSqlSourceFromStrings 方法完成。
/**
* 基于字符串创建SqlSource对象
* @param strings 字符串,即直接映射注解中的字符串
* @param parameterTypeClass 参数类型
* @param languageDriver 语言驱动
* @return 创建出来的SqlSource对象
*/
private SqlSource buildSqlSourceFromStrings(String[] strings, Class parameterTypeClass, LanguageDriver languageDriver) {
final StringBuilder sql = new StringBuilder();
for (String fragment : strings) {
sql.append(fragment);
sql.append(" ");
}
return languageDriver.createSqlSource(configuration, sql.toString().trim(), parameterTypeClass);
}buildSqlSourceFromStrings 方法的处理非常简单,直接将描述 SQL 语句的字符串拼接起来交给 LanguageDriver进行处理。
3.7.4 间接注解映射的解析
间接注解映射的解析由 ProviderSqlSource 完成,在介绍它之前,先介绍两个辅助类:ProviderContext类和 ProviderMethodResolver类。
1. ProviderContext类
ProviderContext 类非常简单,它内部整合了三个属性。该类的功能就是将内部的三个属性整合为一个整体,以便于传递和使用。
// 提供映射信息的类
private final Class mapperType;
// 提供映射信息的方法,该方法属于mapperType类
private final Method mapperMethod;
// 数据库编号
private final String databaseId;2.ProviderMethodResolver类
ProviderMethodResolver 是一个附带有默认方法 resolveMethod 的接口。该方法的作用是从@*Provider 注解的 type 属性所指向的类中找出 method属性中所指定的方法。
/**
* 从@*Provider注解的type属性所指向的类中找出method属性中所指的方法
* @param context 包含@*Provider注解中的type值和method值
* @return 找出的指定方法
*/
default Method resolveMethod(ProviderContext context) {
// 找出同名方法
List sameNameMethods = Arrays.stream(getClass().getMethods())
.filter(m -> m.getName().equals(context.getMapperMethod().getName()))
.collect(Collectors.toList());
// 如果没有找到指定的方法,则@*Provider注解中的type属性所指向的类中不含有method属性中所指的方法。
if (sameNameMethods.isEmpty()) {
throw new BuilderException("Cannot resolve the provider method because '"
+ context.getMapperMethod().getName() + "' not found in SqlProvider '" + getClass().getName() + "'.");
}
// 根据返回类型再次判断,返回类型必须是CharSequence类或其子类
List targetMethods = sameNameMethods.stream()
.filter(m -> CharSequence.class.isAssignableFrom(m.getReturnType()))
.collect(Collectors.toList());
if (targetMethods.size() == 1) {
// 方法唯一,返回该方法
return targetMethods.get(0);
}
if (targetMethods.isEmpty()) {
throw new BuilderException("Cannot resolve the provider method because '"
+ context.getMapperMethod().getName() + "' does not return the CharSequence or its subclass in SqlProvider '"
+ getClass().getName() + "'.");
} else {
throw new BuilderException("Cannot resolve the provider method because '"
+ context.getMapperMethod().getName() + "' is found multiple in SqlProvider '" + getClass().getName() + "'.");
}
} resolveMethod寻找指定方法的过程主要分为两步:
- 第一步先找出符合方法名的所有方法;
- 第二步根据方法的返回值进行进一步校验。
在阅读和分析接口的源码时,一定要注意接口默认方法中 this 的指代。在resolveMethod 方法中,this 是指调用该方法的实体对象,而非 ProviderMethodResolver 接口。

这句话中所涉及的“getClass().getMethods()”语句可以写为“this.getClass().getMethods()”。而调用 resolveMethod方法的语句为 ProviderSqlSource类的构造方法,如下所示。
因此,resolveMethod方法中的 this指的是“this.providerType.getDeclaredConstructor().newInstance()”,即指代 providerType对象。而进一步分析 providerType的赋值语句可以得出结论,providerType是指@*Provider注解的 type属性所指的类的实例。
3.ProviderSqlSource类
介绍完 ProviderContext 类和 ProviderMethodResolver 类之后,我们来阅读ProviderSqlSource类的源码。
// SqlSource的子类,能够根据*Provider的信息初始化得到
// 调用入口唯一,在MapperAnnotationBuilder:getSqlSourceFromAnnotations中
public class ProviderSqlSource implements SqlSource {
// Configuration对象
private final Configuration configuration;
// *Provider注解上type属性所指的类
private final Class providerType;
// 语言驱动
private final LanguageDriver languageDriver;
// 含有注解的接口方法
private final Method mapperMethod;
// *Provider注解上method属性所指的方法
private Method providerMethod;
// 给定SQL语句的方法对应的参数
private String[] providerMethodArgumentNames;
// 给定SQL语句的方法对应的参数类型
private Class[] providerMethodParameterTypes;
// ProviderContext对象
private ProviderContext providerContext;
// ProviderContext编号
private Integer providerContextIndex;
...
}ProviderSqlSource类作为 SqlSource接口的子类,实现了 getBoundSql方法(SqlSource接口中的抽象方法)。其实现过程包含在 getBoundSql 和 createSqlSource 两个方法中:
/**
* 获取一个BoundSql对象
* @param parameterObject 参数对象
* @return BoundSql对象
*/
public BoundSql getBoundSql(Object parameterObject) {
// 获取SqlSource对象
SqlSource sqlSource = createSqlSource(parameterObject);
// 从SqlSource中获取BoundSql对象
return sqlSource.getBoundSql(parameterObject);
}
/**
* 获取一个BoundSql对象
* @param parameterObject 参数对象
* @return SqlSource对象
*/
private SqlSource createSqlSource(Object parameterObject) {
try {
// SQL字符串信息
String sql;
if (parameterObject instanceof Map) { // 参数是Map
int bindParameterCount = providerMethodParameterTypes.length - (providerContext == null ? 0 : 1);
if (bindParameterCount == 1 &&
(providerMethodParameterTypes[Integer.valueOf(0).equals(providerContextIndex) ? 1 : 0].isAssignableFrom(parameterObject.getClass()))) {
// 调用*Provider注解的type类中的method方法,从而获得SQL字符串
sql = invokeProviderMethod(extractProviderMethodArguments(parameterObject));
} else {
@SuppressWarnings("unchecked")
Map params = (Map) parameterObject;
// 调用*Provider注解的type类中的method方法,从而获得SQL字符串
sql = invokeProviderMethod(extractProviderMethodArguments(params, providerMethodArgumentNames));
}
} else if (providerMethodParameterTypes.length == 0) {
// *Provider注解的type类中的method方法无需入参
sql = invokeProviderMethod();
} else if (providerMethodParameterTypes.length == 1) {
if (providerContext == null) {
// *Provider注解的type类中的method方法有一个入参
sql = invokeProviderMethod(parameterObject);
} else {
// *Provider注解的type类中的method方法入参为providerContext对象
sql = invokeProviderMethod(providerContext);
}
} else if (providerMethodParameterTypes.length == 2) {
sql = invokeProviderMethod(extractProviderMethodArguments(parameterObject));
} else {
throw new BuilderException("Cannot invoke SqlProvider method '" + providerMethod
+ "' with specify parameter '" + (parameterObject == null ? null : parameterObject.getClass())
+ "' because SqlProvider method arguments for '" + mapperMethod + "' is an invalid combination.");
}
Class parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
// 调用languageDriver生成SqlSource对象
return languageDriver.createSqlSource(configuration, sql, parameterType);
} catch (BuilderException e) {
throw e;
} catch (Exception e) {
throw new BuilderException("Error invoking SqlProvider method '" + providerMethod
+ "' with specify parameter '" + (parameterObject == null ? null : parameterObject.getClass()) + "'. Cause: " + extractRootCause(e), e);
}
} 整个实现过程可以概括为以下三步。
- 调用*Provider注解的 type类中的 method方法,从而获得 SQL字符串。
- 向 languageDriver 的 createSqlSource 方法传入 SQL 字符串等参数,新生成一个SqlSource对象。
- 调用新生成的 SqlSource对象的 getBoundSql方法,获得 BoundSql对象。
4. mapping
mapping 包是一个非常重要的包,它定义了 MyBatis 中众多的解析实体类。这些实体类有一些与 SQL语句相关,有一些与 SQL的输入/输出参数有关,有一些与配置信息有关。mapping包主要完成以下功能:
- SQL语句处理功能;
- 输出结果处理功能;
- 输入参数处理功能;
- 多数据库种类处理功能;
- 其他功能。
4.1 SQL语句处理功能
在 mapping 包中,与 SQL 语句处理功能相关的类主要有三个,它们是MappedStatement类、SqlSource类和 BoundSql类。其中 MappedStatement 类表示的是数据库操作节点(select、insert、update、delete四类节点)内的所有内容;SqlSource类是数据库操作标签中包含的 SQL语句;BoundSql类则是 SqlSource类进一步处理的产物。SQL 语句相关解析实体类示意图如下,展示了 MappedStatement 类、SqlSource类、BoundSql类这三个解析实体类与数据库操作节点之间的关系。
4.1.1 MappedStatement类
MappedStatement是一个典型的解析实体类,它就是映射文件中数据库操作节点对应的实体。

MappedStatement类的属性和数据库操作标签的属性十分相近:
// Mapper文件的磁盘路径
private String resource;
// Configuration对象
private Configuration configuration;
// 查询语句的完整包名加方法名,例如:com.github.yeecode.mybatisdemo.dao.UserMapper.addUser
private String id;
private Integer fetchSize;
private Integer timeout;
private StatementType statementType;
private ResultSetType resultSetType;
//SQL源码,对应于我们所写在配置文件中的SQL语句。包含占位符,无法直接执行。可以展开分析就是分行的sql语句text。
private SqlSource sqlSource;
private Cache cache;
// 参数们
private ParameterMap parameterMap;
// 输出的resultMap放在这里,我们在设置resultMap="UserBean" 时可以设置多个,即resultMap="UserBean,RoleBean"。
// 因此这里是一个list
private List resultMaps;
// 执行该语句前是否清除一二级缓存
private boolean flushCacheRequired;
private boolean useCache;
private boolean resultOrdered;
// 类型,增删改查
private SqlCommandType sqlCommandType;
private KeyGenerator keyGenerator;
// 存储了主键的属性名
private String[] keyProperties;
private String[] keyColumns;
private boolean hasNestedResultMaps;
private String databaseId;
private Log statementLog;
private LanguageDriver lang;
private String[] resultSets; 4.1.2 SqlSource类
SqlSource是一个解析实体接口,它对应了 MappedStatement中的 SQL语句。例如,如下 SQL语句就可以表述为一个 SqlSource。
SqlSource 本身是一个接口,接口中只定义了一个返回 BoundSql 对象的方法。SqlSource 接口的源码如代码:
/**
* 一共有四个实现
*/
public interface SqlSource {
/**
* 获取一个BoundSql对象
* @param parameterObject 参数对象
* @return BoundSql对象
*/
BoundSql getBoundSql(Object parameterObject);
}SqlSource接口有四种实现类,SqlSource接口与子类的类图:
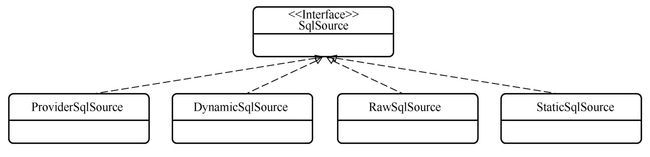
SqlSource接口的四种实现类的区别如下。
- DynamicSqlSource:动态 SQL语句。所谓动态 SQL是指含有动态 SQL节点(如“if”节点)或者含有“${}”占位符的语句。
- RawSqlSource:原生 SQL语句。指非动态语句,语句中可能含“#{}”占位符,但不含有动态 SQL节点,也不含有“${}”占位符。
- StaticSqlSource:静态语句。语句中可能含有“?”,可以直接提交给数据库执行。
- ProviderSqlSource:上面的几种都是通过 XML 文件获取的 SQL 语句,而ProviderSqlSource是通过注解映射的形式获取的 SQL语句。
而 DynamicSqlSource 和 RawSqlSource 都会被处理成 StaticSqlSource,再通过StaticSqlSource的 getBoundSql方法得到 SqlSource对象。DynamicSqlSource和 RawSqlSource都在 scripting包中,因此我们将在下一章详细介绍 SqlSource接口的四个实现类之间的转化过程。
4.1.3 BoundSql
BoundSql是参数绑定完成后的 SQL语句,它的属性:
// 可能含有“?”占位符的sql语句
private final String sql;
// 参数映射列表
private final List parameterMappings;
// 实参对象本身
private final Object parameterObject;
// 实参
private final Map additionalParameters;
// additionalParameters的包装对象
private final MetaObject metaParameters; BoundSql是 SQL语句中一个重要的中间产物,它既存储了转化结束的 SQL信息,又包含了实参信息和一些附加的环境信息。接下来,它会在 SQL的执行中继续发挥作用。
4.2 输出结果处理功能
在映射文件的数据库操作节点中,可以直接使用 resultType 设置将输出结果映射为 Java对象。不过,还有一种更为灵活和强大的方式,那就是使用 resultMap来定义输出结果的映射方式。
resultMap的功能十分强大,它支持输出结果的组装、判断、懒加载等。在输出结果的处理中主要涉及 ResultMap类、ResultMapping类、Discriminator类,它们也都是解析实体类。下图给出了 resultMap标签与相关解析实体类的对应关系。
4.2.1 ResultMap类
ResultMap类就是 resultMap节点对应的解析实体类,其属性和 resultMap节点的信息高度一致。
// 全局配置信息
private Configuration configuration;
// resultMap的编号
private String id;
// 最终输出结果对应的Java类
private Class type;
// XML中的的列表,即ResultMapping列表
private List resultMappings;
// XML中的的列表
private List idResultMappings;
// XML中的中各个属性的列表
private List constructorResultMappings;
// XML中非相关的属性列表
private List propertyResultMappings;
// 所有参与映射的数据库中字段的集合
private Set mappedColumns;
// 所有参与映射的Java对象属性集合
private Set mappedProperties;
// 鉴别器
private Discriminator discriminator;
// 是否存在嵌套映射
private boolean hasNestedResultMaps;
// 是否存在嵌套查询
private boolean hasNestedQueries;
// 是否启动自动映射
private Boolean autoMapping; 对照 XML配置后,所有的属性都比较好理解。稍显繁复的就是有四个*ResultMappings列表。我们以如下的映射文件片段为例,对这四个*ResultMappings列表进行单独分析。
- 在“id="userMap"”的 resultMap中 MyBatis会调用类的无参构造方法创建一个对象,然后再给各个属性赋值。而“id="userMapByConstructor"”的 resultMap中 MyBatis会调用对应的构造方法创建对象。于是,对象的属性被分为了两类:构造方法中的属性和非构造方法中的属性。
- constructor标签下可以设置一个 idArg标签。普通的 resultMap标签下也可以设置一个id 标签。与其他标签对应的属性不同,这两个标签对应的属性可以作为区别对象是否为同一个对象的标识属性。于是,对象的属性被分为了两类:id属性和非 id属性。
根据以上两种分类方式就产生了下面的四种属性。
- resultMappings:所有的属性;
- idResultMappings:所有的 id属性;
- constructorResultMappings:所有构造方法中的属性;
- propertyResultMappings:所有非构造方法中的属性。
4.2.2 ResultMapping类
上节中涉及的 idArg、arg、id、result等标签都对应一个 ResultMapping对象。ResultMapping类的属性比较简单,下面主要讨论 ResultMapping 类使用建造者模式的方式:内部类建造者。该方式在其他类中也常有应用,但在这里最为明显。
ResultMapping中存在大量的属性,因此创建 ResultMapping对象非常复杂。为了改善这个过程,ResultMapping使用了建造者模式。并且,它的建造者直接放在了类的内部,作为内部静态类出现。内部静态类中方法的调用不需要创建类的对象,而它们却可以生成类的对象。因此,通过如下代码方法可以方便地创建一个 ResultMapping对象,并设置各种属性。
基于内部类的建造者模式提升了类的内聚性,值得我们在软件设计时借鉴。
4.2.3 Discriminator
Discriminator是 resultMap内部的鉴别器,就像程序中的选择语句一样,它使得数据查询结果能够根据某些条件的不同而进行不同的映射。
例如,如下所示的配置使得“id="userMap"”的 resultMap能够根据 sex字段的值进行不同的映射:如果 sex值为 0,则最终输出结果为 Girl对象,并且根据查询结果设置email属性;如果 sex值为 1,则最终输出结果为 Boy对象,并且根据查询结果设置 age属性。
上述鉴别功能非常强大,但 Discriminator类的属性却非常简单:
// 存储条件判断行的信息,如中的信息
private ResultMapping resultMapping;
// 存储选择项的信息,键为value值,值为resultMap值。如 discriminatorMap; 相比于 Discriminator类的属性,我们更关心它的生效逻辑。在 DefaultResultSetHandler类的 resolveDiscriminatedResultMap方法中可以看到这部分逻辑:
/**
* 应用鉴别器
* @param rs 数据库查询出的结果集
* @param resultMap 当前的ResultMap对象
* @param columnPrefix 属性的父级前缀
* @return 已经不包含鉴别器的新的ResultMap对象
* @throws SQLException
*/
public ResultMap resolveDiscriminatedResultMap(ResultSet rs, ResultMap resultMap, String columnPrefix) throws SQLException {
// 已经处理过的鉴别器
Set pastDiscriminators = new HashSet<>();
Discriminator discriminator = resultMap.getDiscriminator();
while (discriminator != null) {
// 求解条件判断的结果,这个结果值就是鉴别器鉴别的依据
final Object value = getDiscriminatorValue(rs, discriminator, columnPrefix);
// 根据真实值判断属于哪个分支
final String discriminatedMapId = discriminator.getMapIdFor(String.valueOf(value));
// 从接下来的case里面找到这个分支
if (configuration.hasResultMap(discriminatedMapId)) {
// 找出指定的resultMap
resultMap = configuration.getResultMap(discriminatedMapId);
// 继续分析下一层
Discriminator lastDiscriminator = discriminator;
// 查看本resultMap内是否还有鉴别器
discriminator = resultMap.getDiscriminator();
// 辨别器出现了环
if (discriminator == lastDiscriminator || !pastDiscriminators.add(discriminatedMapId)) {
break;
}
} else {
break;
}
}
return resultMap;
}
/**
* 求解鉴别器条件判断的结果
* @param rs 数据库查询出的结果集
* @param discriminator 鉴别器
* @param columnPrefix
* @return 计算出鉴别器的value对应的真实结果
* @throws SQLException
*/
private Object getDiscriminatorValue(ResultSet rs, Discriminator discriminator, String columnPrefix) throws SQLException {
final ResultMapping resultMapping = discriminator.getResultMapping();
// 要鉴别的字段的typeHandler
final TypeHandler typeHandler = resultMapping.getTypeHandler();
// prependPrefix(resultMapping.getColumn(), columnPrefix) 得到列名,然后取出列的值
return typeHandler.getResult(rs, prependPrefix(resultMapping.getColumn(), columnPrefix));
} 我们查看判断条件的求解过程,该过程在 DefaultResultSetHandler 类的getDiscriminatorValue方法中,其操作就是从结果集中取出指定列的值。
4.3 输入参数处理功能
MyBatis不仅可以将数据库结果映射为对象,还能够将对象映射成 SQL语句需要的输入参数。这种映射关系由如下所示的 parameterMap标签来表示。这样,只要输入 User对象,parameterMap就可以将其拆解为 name、schoolName参数。
在输入参数的处理过程中,主要涉及 ParameterMap、ParameterMapping这两个类,它们也都是解析实体类。下图给出了 parameterMap标签与相关解析实体类的对应关系。
作为解析实体类,ParameterMap类和 ParameterMapping类与标签中的属性相对应,整体架构比较简单。并且这两个类和 ResultMap类、ResultMapping类十分类似,这里不再单独介绍。
注意:parameterMap标签是老式风格的参数映射,未来可能会废弃。更好的办法是使用内联参数。
4.4 多数据库种类处理功能
作为一个出色的 ORM 框架,MyBatis 支持多种数据库,如 SQL Server、DB2、Oracle、MySQL、PostgreSQL 等。然而,不同类型的数据库之间支持的 SQL 规范略有不同。例如,同样是限制查询结果的条数,在 SQL Server中要使用 TOP关键字,而在 MySQL中要使用 LIMIT关键字。为了能够兼容不同数据库的 SQL规范,MyBatis支持多种数据库。在使用多种数据库前,需要先在配置文件中列举要使用的数据库类型,然后在 SQL语句上标识其对应的数据库类型。
多数据支持的实现由 DatabaseIdProvider接口负责。它有一个 VendorDatabaseIdProvider子类,还有一个即将废弃的 DefaultDatabaseIdProvider 子类。接下来我们通过VendorDatabaseIdProvider类分析多数据库支持的实现原理。
VendorDatabaseIdProvider 有两个重要的方法均继承自 DatabaseIdProvider 接口,它们是 setProperties方法和 getDatabaseId方法。setProperties方法用来将MyBatis配置文件中设置在databaseIdProvider节点中的信息写入VendorDatabaseIdProvider对象中。这些信息实际是数据库的别名信息。getDatabaseId 方法用来给出当前传入的 DataSource 对象对应的 databaseId。主要的逻辑存在于 getDatabaseName方法中:
/**
* 获取当前的数据源类型的别名
* @param dataSource 数据源
* @return 数据源类型别名
* @throws SQLException
*/
private String getDatabaseName(DataSource dataSource) throws SQLException {
// 获取当前连接的数据库名
String productName = getDatabaseProductName(dataSource);
// 如果设置有properties值,则根据将获取的数据库名称作为模糊的key,映射为对应的value
if (this.properties != null) {
for (Map.Entry property : properties.entrySet()) {
if (productName.contains((String) property.getKey())) {
return (String) property.getValue();
}
}
// 没有找到对应映射
return null;
}
return productName;
} getDatabaseName方法做了两个工作,首先是获取当前数据源的类型,然后是将数据源类型映射为我们在 databaseIdProvider节点中设置的别名。这样,在需要执行 SQL语句时,就可以根据数据库操作节点中的 databaseId设置对 SQL语句进行筛选。
4.5 其他功能
mapping包中还有两个重要的类:Environment类和 CacheBuilder类。
Environment类也是一个解析实体类,它对应了配置文件中的environments节点,该类的属性如代码所示。
// 编号
private final String id;
// 事务工厂
private final TransactionFactory transactionFactory;
// 数据源信息
private final DataSource dataSource;CacheBuilder 类是缓存建造者,它负责完成缓存对象的创建。具体的创建过程将在后续【TODO】进行分析。此外,mapping包中还存在一些枚举类,其作用如下。
- FetchType:延迟加载设置;
- ParameterMode:参数类型,指输入参数、输出参数等;
- ResultFlag:返回结果中属性的特殊标志,表示是否为 id属性、是否为构造器属性;
- ResultSetType:结果集支持的访问方式;
- SqlCommandType:SQL命令类型,指增、删、改、查等;
- StatementType:SQL语句种类,指是否为预编译的语句、是否为存储过程等。
5. scripting
MyBatis支持灵活的SQL语句组件方式,可以在组建SQL时使用 foreach、where、if等标签完成复杂的语句组装工作。

上图所示的语句最终还是会被解析成为最基本的SQL语句才能被数据库接收,这个解析过程主要由scripting包完成。
5.1 OGNL
OGNL(Object Graph Navigation Language,对象图导航语言)是一种功能强大的表达式语言(Expression Language,EL)。通过它,能够完成从集合中选取对象、读写对象的属性、调用对象和类的方法、表达式求值与判断等操作。
OGNL应用十分广泛,例如,同样是获取 Map中某个对象的属性,用 Java语言表示出来如下:userMap.get("user2").getName();
而使用OGNL表达式则为:#user2.name
除了简单、清晰以外,OGNL有着更高的环境适应性。我们可以将 OGNL表达式应用在配置文件、XML文件等处,而只在解析这些文件时使用 OGNL即可。例如,下图所示的一段 XML配置中,test条件的判断就使用了 OGNL表达式。

OGNL有 Java工具包,只要引入它即可以在 Java中使用 OGNL的功能。这样我们就可以使用 Java来解析引入了 OGNL的各种文档。在介绍 OGNL用法之前,先介绍 OGNL解析时要接触的三个重要概念:
- 表达式(expression):是一个带有语法含义的字符串,是整个 OGNL的核心内容。通过表达式来确定需要进行的 OGNL操作。
- 根对象(root):可以理解为 OGNL 的被操作对象。表达式中表示的操作就是针对这个对象展开的。
- 上下文(context):整个 OGNL处理时的上下文环境,该环境是一个 Map对象。在进行 OGNL处理之前,我们可以传入一个初始化过的上下文环境。
OGNL支持表达式的预编译,对表达式进行预编译后,避免了每次执行表达式前的编译工作,能够明显地提高 OGNL的执行效率。可见,如果要多次运行一个表达式,则先将其编译后再运行的执行效率更高。我们在 JSP、XML中常常见到 OGNL表达式,可见,OGNL 是一种广泛、便捷、强大的语言。
5.2 语言驱动接口及语言驱动注册表
LanguageDriver为语言驱动类的接口,通过其源码可以看出,它一共定义了三个方法。其中包含两个 createSqlSource方法,前面章节的SqlSource对象都是由这两个方法创建的:
// 脚本语言解释器
// 在接口上注解的SQL语句,就是由它进行解析的
// @Select("select * from `user` where id = #{id}")
//User queryUserById(Integer id);
public interface LanguageDriver {
/**
* Creates a {@link ParameterHandler} that passes the actual parameters to the the JDBC statement.
*
* @param mappedStatement The mapped statement that is being executed
* @param parameterObject The input parameter object (can be null)
* @param boundSql The resulting SQL once the dynamic language has been executed.
* @return
* @author Frank D. Martinez [mnesarco]
* @see DefaultParameterHandler
*/
/**
* 创建参数处理器。参数处理器能将实参传递给JDBC statement。
* @param mappedStatement 完整的数据库操作节点
* @param parameterObject 参数对象
* @param boundSql 数据库操作语句转化的BoundSql对象
* @return 参数处理器
*/
ParameterHandler createParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql);
/**
* Creates an {@link SqlSource} that will hold the statement read from a mapper xml file.
* It is called during startup, when the mapped statement is read from a class or an xml file.
*
* @param configuration The MyBatis configuration
* @param script XNode parsed from a XML file
* @param parameterType input parameter type got from a mapper method or specified in the parameterType xml attribute. Can be null.
* @return
*/
/**
* 创建SqlSource对象(基于映射文件的方式)。该方法在MyBatis启动阶段,读取映射接口或映射文件时被调用
* @param configuration 配置信息
* @param script 映射文件中的数据库操作节点
* @param parameterType 参数类型
* @return SqlSource对象
*/
SqlSource createSqlSource(Configuration configuration, XNode script, Class parameterType);
/**
* Creates an {@link SqlSource} that will hold the statement read from an annotation.
* It is called during startup, when the mapped statement is read from a class or an xml file.
*
* @param configuration The MyBatis configuration
* @param script The content of the annotation
* @param parameterType input parameter type got from a mapper method or specified in the parameterType xml attribute. Can be null.
* @return
*/
/**
* 创建SqlSource对象(基于注解的方式)。该方法在MyBatis启动阶段,读取映射接口或映射文件时被调用
* @param configuration 配置信息
* @param script 注解中的SQL字符串
* @param parameterType 参数类型
* @return SqlSource对象,具体来说是DynamicSqlSource和RawSqlSource中的一种
*/
SqlSource createSqlSource(Configuration configuration, String script, Class parameterType);
}
LanguageDriver接口默认有两个实现,分别是XMLLanguageDriver和RawLanguageDriver,而其中的RawLanguageDriver又是 XMLLanguageDriver的子类。LanguageDriver及其子类的类图如下图所示:
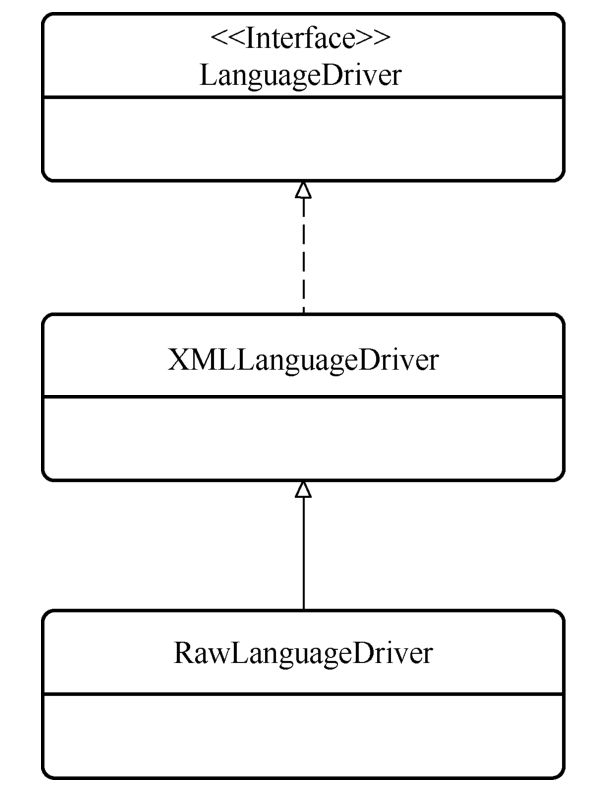
从RawLanguageDriver类的源码可以看出,RawLanguageDriver类的所有操作都是调用父类XMLLanguageDriver完成的。并且在XMLLanguageDriver类完成操作后通过 checkIsNotDynamic 方法校验获得的SqlSource 必须为 RawSqlSource。因此说,RawLanguageDriver 类实际上是通过checkIsNotDynamic方法对XMLLanguageDriver类的功能进行了裁剪,使得自身仅仅支持 RawSqlSource类型的 SqlSource。
/**
* As of 3.2.4 the default XML language is able to identify static statements
* and create a {@link RawSqlSource}. So there is no need to use RAW unless you
* want to make sure that there is not any dynamic tag for any reason.
*
* @since 3.2.0
* @author Eduardo Macarron
*/
public class RawLanguageDriver extends XMLLanguageDriver {
@Override
public SqlSource createSqlSource(Configuration configuration, XNode script, Class parameterType) {
// 调用父类方法完成操作
SqlSource source = super.createSqlSource(configuration, script, parameterType);
// 校验得到的SqlSource是RawSqlSource
checkIsNotDynamic(source);
return source;
}
@Override
public SqlSource createSqlSource(Configuration configuration, String script, Class parameterType) {
// 调用父类方法完成操作
SqlSource source = super.createSqlSource(configuration, script, parameterType);
// 校验得到的SqlSource是RawSqlSource
checkIsNotDynamic(source);
return source;
}
/**
* 校验输入的SqlSource是RawSqlSource,否则便抛出异常
* @param source 输入的SqlSource对象
*/
private void checkIsNotDynamic(SqlSource source) {
if (!RawSqlSource.class.equals(source.getClass())) {
throw new BuilderException("Dynamic content is not allowed when using RAW language");
}
}
}在面向对象的设计中子类通常会在继承父类方法的基础上扩充更多的方法,因此子类功能是父类功能的超集。而RawLanguageDriver类却对其父类 XMLLanguageDriver的功能进行了裁剪,使得自身的功能是父类功能的子集,这是一种先繁再简的设计方式。当我们在开发中遇到类似的需求时,可以参考这种设计方式。
MyBatis 还允许用户给出 LanguageDriver 的实现类,通过配置文件中的defaultScriptingLanguage 属性将其指定为默认的脚本驱动。该功能的支持由XMLConfigBuilder 类实现,从调用的 setDefaultScriptingLanguage方法可以看出,系统的默认语言驱动类是XMLLanguageDriver类,而用户自定义的语言驱动可以覆盖它。
configuration.setDefaultScriptingLanguage(resolveClass(props.getProperty("defaultScriptingLanguage")));
public void setDefaultScriptingLanguage(Class driver) {
if (driver == null) {
driver = XMLLanguageDriver.class;
}
getLanguageRegistry().setDefaultDriverClass(driver);
}scripting包中还存在一个 LanguageDriverRegistry类,它作为语言驱动的注册表管理所有的语言驱动。LanguageDriverRegistry类内主要包括向其中注册驱动、从中选取驱动的方法,实现都比较简单。其属性如代码:
// 所有的语言驱动类
private final Map, LanguageDriver> LANGUAGE_DRIVER_MAP = new HashMap<>();
// 默认的语言驱动类
private Class defaultDriverClass; 5.3 SQL节点树的组建

映射文件中的数据库操作语句,它实际上是由众多 SQL节点组成的一棵树。要想解析这棵树,首先要做的是将 XML中的信息读取进来,然后在内存中将 XML树组建为 SQL 节点树。SQL 节点树的组建由 XMLScriptBuilder 类负责,该类的属性如代码所示:
// 当前要处理的XML节点
private final XNode context;
// 当前节点是否为动态节点
private boolean isDynamic;
// 输入参数的类型
private final Class parameterType;
// 节点类型和对应的处理器组成的Map
private final Map nodeHandlerMap = new HashMap<>(); 在 XMLScriptBuilder 类中,定义有一个接口 NodeHandler。NodeHandler 接口有一个 handleNode方法负责将节点拼装到节点树中。
private interface NodeHandler {
/**
* 该方法将当前节点拼装到节点树中
* @param nodeToHandle 要被拼接的节点
* @param targetContents 节点树
*/
void handleNode(XNode nodeToHandle, List targetContents);
} 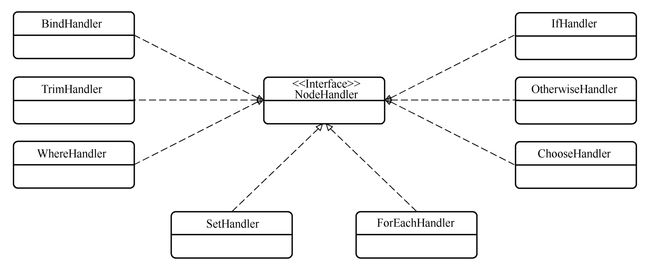
每一种 SQL节点都有一个 NodeHandler实现类,NodeHandler接口与其实现类的类图上图所示。SQL节点和NodeHandler实现类的对应关系由nodeHandlerMap负责存储。以 IfHandler为例,我们查看如何基于 XML信息组建 SQL节点树。IfHandler源码如下所示:
private class IfHandler implements NodeHandler {
public IfHandler() {
// Prevent Synthetic Access
}
/**
* 该方法将当前节点拼装到节点树中
* @param nodeToHandle 要被拼接的节点
* @param targetContents 节点树
*/
@Override
public void handleNode(XNode nodeToHandle, List targetContents) {
// 解析该节点的下级节点
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
// 获取该节点的test属性
String test = nodeToHandle.getStringAttribute("test");
// 创建一个IfSqlNode
IfSqlNode ifSqlNode = new IfSqlNode(mixedSqlNode, test);
// 将创建的IfSqlNode放入到SQL节点树中
targetContents.add(ifSqlNode);
}
} 可以看到,在 IfHandler的 handleNode方法中先对当前 if节点的下级节点进行了拼接,因此组建 SQL节点树的过程是一个深度优先遍历的过程。在下级节点处理完毕后,提取了XML中的信息组建成 IfSqlNode对象,然后将 IfSqlNode对象加入 SQL节点树中。
在了解了 NodeHandler 接口及其实现类之后,我们看一下如何从根节点开始组建一棵SQL节点树。入口方法是parseScriptNode方法,而主要操作在 parseDynamicTags方法中展开,这两个方法的源码如下所示:
/**
* 解析节点生成SqlSource对象
* @return SqlSource对象
*/
public SqlSource parseScriptNode() {
// 解析XML节点节点,得到节点树MixedSqlNode
MixedSqlNode rootSqlNode = parseDynamicTags(context);
SqlSource sqlSource;
// 根据节点树是否为动态,创建对应的SqlSource对象
if (isDynamic) {
sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
} else {
sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
}
return sqlSource;
}
/**
* 将XNode对象解析为节点树
* @param node XNode对象,即数据库操作节点
* @return 解析后得到的节点树
*/
protected MixedSqlNode parseDynamicTags(XNode node) {
// XNode拆分出的SqlNode列表
List contents = new ArrayList<>();
// 输入XNode的子XNode
NodeList children = node.getNode().getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
// 循环遍历每一个子XNode
XNode child = node.newXNode(children.item(i));
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) { // CDATASection类型或者Text类型的XNode节点
// 获取XNode内的信息
String data = child.getStringBody("");
TextSqlNode textSqlNode = new TextSqlNode(data);
// 只要有一个TextSqlNode对象是动态的,则整个MixedSqlNode是动态的
if (textSqlNode.isDynamic()) {
contents.add(textSqlNode);
isDynamic = true;
} else {
contents.add(new StaticTextSqlNode(data));
}
} else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // 子XNode仍然是Node类型
String nodeName = child.getNode().getNodeName();
// 找到对应的处理器
NodeHandler handler = nodeHandlerMap.get(nodeName);
if (handler == null) {
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
// 用处理器处理节点
handler.handleNode(child, contents);
isDynamic = true;
}
}
// 返回一个混合节点,其实就是一个SQL节点树
return new MixedSqlNode(contents);
} 通过源码可以得知,parseDynamicTags 会逐级分析 XML 文件中的节点并使用对应的NodeHandler 实现来处理该节点,最终将所有的节点整合到一个 MixedSqlNode 对象中。MixedSqlNode对象就是 SQL节点树。在整合节点树的过程中,只要存在一个动态节点,则 SQL节点树就是动态的。动态的SQL节点树将用来创建DynamicSqlSource对象,否则就创建 RawSqlSource对象。
5.4 SQL节点树的解析
对组建好的 SQL 节点树进行解析,这部分工作主要在scripting包的 xmltags子包中展开,下面我们对解析过程中涉及的源码进行阅读和分析。
5.4.1 OGNL辅助类
SQL 节点树中存在许多 OGNL 表达式,例如下面的代码片段中就展示了一段 OGNL表达式。
这些 OGNL表达式的解析就是基于 OGNL包来完成的。我们在 MyBatis的 pom文件中可以看到对 OGNL包的引用:

为了更好地完成 OGNL 的解析工作,xmltags 子包中还设置了三个相关的类,它们分别是 OgnlClassResolver类、OgnlMemberAccess类、OgnlCache类:
1.OgnlClassResolver类
DefaultClassResolver 类是 OGNL 中定义的一个类,OGNL 可以通过该类进行类的读取,即将类名转化为一个类。而 OgnlClassResolver 则继承了 DefaultClassResolver 类,并覆盖了其中的toClassForName,如代码所示:
public class OgnlClassResolver extends DefaultClassResolver {
@Override
protected Class toClassForName(String className) throws ClassNotFoundException {
return Resources.classForName(className);
}
}2.OgnlMemberAccess类
MemberAccess 接口是 OGNL提供的一个钩子接口。OGNL借助这个接口为访问对象的属性做好准备。OgnlMemberAccess 类就实现了 MemberAccess接口,并基于反射提供了修改对象属性可访问性的功能。这样,OGNL便可以基于这些功能为访问对象的属性做好准备。
class OgnlMemberAccess implements MemberAccess {
// 当前环境下,通过反射是否能够修改对象属性的可访问性
private final boolean canControlMemberAccessible;
OgnlMemberAccess() {
this.canControlMemberAccessible = Reflector.canControlMemberAccessible();
}
/**
* 设置属性的可访问性
* @param context 环境上下文
* @param target 目标对象
* @param member 目标对象的目标成员
* @param propertyName 属性名称
* @return 属性的可访问性
*/
@Override
public Object setup(Map context, Object target, Member member, String propertyName) {
Object result = null;
if (isAccessible(context, target, member, propertyName)) { // 如果允许修改属性的可访问性
AccessibleObject accessible = (AccessibleObject) member;
if (!accessible.isAccessible()) { // 如果属性原本不可访问
result = Boolean.FALSE;
// 将属性修改为可访问
accessible.setAccessible(true);
}
}
return result;
}
/**
* 将属性的可访问性恢复到指定状态
* @param context 环境上下文
* @param target 目标对象
* @param member 目标对象的目标成员
* @param propertyName 属性名称
* @param state 指定的状态
*/
@Override
public void restore(Map context, Object target, Member member, String propertyName,
Object state) {
if (state != null) {
((AccessibleObject) member).setAccessible((Boolean) state);
}
}
/**
* 判断对象属性是否可访问
* @param context 环境上下文
* @param target 目标对象
* @param member 目标对象的目标成员
* @param propertyName 属性名称
* @return 判断结果
*/
@Override
public boolean isAccessible(Map context, Object target, Member member, String propertyName) {
return canControlMemberAccessible;
}
}3.OgnlCache类
为了提升 OGNL 的运行效率,MyBatis 还为 OGNL 提供了一个缓存,即OgnlCache类。
public final class OgnlCache {
// MyBatis提供的OgnlMemberAccess对象
private static final OgnlMemberAccess MEMBER_ACCESS = new OgnlMemberAccess();
// MyBatis提供的OgnlClassResolver对象
private static final OgnlClassResolver CLASS_RESOLVER = new OgnlClassResolver();
// 缓存解析后的OGNL表达式,用以提高效率
private static final Map expressionCache = new ConcurrentHashMap<>();
private OgnlCache() {
// Prevent Instantiation of Static Class
}
/**
* 读取表达式的结果
* @param expression 表达式
* @param root 根环境
* @return 表达式结果
*/
public static Object getValue(String expression, Object root) {
try {
// 创建默认的上下文环境
Map context = Ognl.createDefaultContext(root, MEMBER_ACCESS, CLASS_RESOLVER, null);
// 依次传入表达式树、上下文、根,从而获得表达式的结果
return Ognl.getValue(parseExpression(expression), context, root);
} catch (OgnlException e) {
throw new BuilderException("Error evaluating expression '" + expression + "'. Cause: " + e, e);
}
}
/**
* 解析表达式,得到解析后的表达式树
* @param expression 表达式
* @return 表达式树
* @throws OgnlException
*/
private static Object parseExpression(String expression) throws OgnlException {
// 先从缓存中获取
Object node = expressionCache.get(expression);
if (node == null) {
// 缓存没有则直接解析,并放入缓存
node = Ognl.parseExpression(expression);
expressionCache.put(expression, node);
}
return node;
}
} 我们知道,如果一个表达式需要运行多次,则先对表达式进行预先解析可以提高整体的运行效率。在 OgnlCache 类中,即使用 parseExpression方法对表达式进行了预先解析,并且将表达式解析的结果放入 expressionCache 属性中缓存了起来。这样,在每次进行表达式解析时,会先从 expressionCache属性中查询已经解析好的结果。这样一来避免了重复解析,提高了 OGNL操作的效率。
5.4.2 表达式求值器
MyBatis 并没有将 OGNL 工具直接暴露给各个 SQL 节点使用,而是对 OGNL 工具进行了进一步的易用性封装,得到了 ExpressionEvaluator类,即表达式求值器。
ExpressionEvaluator 类提供了两个方法,一个是 evaluateBoolean 方法。该方法能够对结果为 true、false形式的表达式进行求值。例如,“<if test="name!=null">”节点中的 true、false判断便可以直接调用该方法完成。
/**
* 对结果为true/false形式的表达式进行求值
* @param expression 表达式
* @param parameterObject 参数对象
* @return 求值结果
*/
public boolean evaluateBoolean(String expression, Object parameterObject) {
// 获取表达式的值
Object value = OgnlCache.getValue(expression, parameterObject);
if (value instanceof Boolean) { // 如果确实是Boolean形式的结果
return (Boolean) value;
}
if (value instanceof Number) { // 如果是数值形式的结果
return new BigDecimal(String.valueOf(value)).compareTo(BigDecimal.ZERO) != 0;
}
return value != null;
}另外一个是 evaluateIterable 方法,该方法能对结果为迭代形式的表达式进行求值。这样,“<foreach item="id" collection="array"open="(" separator=","close=")">#{id} </foreach>”节点中的迭代判断便可以直接调用该方法完成。
/**
* 对结果为迭代形式的表达式进行求值
* @param expression 表达式
* @param parameterObject 参数对象
* @return 求值结果
*/
public Iterable evaluateIterable(String expression, Object parameterObject) {
// 获取表达式的结果
Object value = OgnlCache.getValue(expression, parameterObject);
if (value == null) {
throw new BuilderException("The expression '" + expression + "' evaluated to a null value.");
}
if (value instanceof Iterable) { // 如果结果是Iterable
return (Iterable) value;
}
if (value.getClass().isArray()) { // 结果是Array
// 原注释:得到的Array可能是原始的,因此调用Arrays.asList()可能会抛出ClassCastException。因此要手工转为ArrayList
int size = Array.getLength(value);
List基于 OGNL 封装的表达式求值器是 SQL 节点树解析的利器,它能够根据上下文环境对表达式的值做出正确的判断,这是将复杂的数据库操作语句解析为纯粹SQL语句的十分重要的一步。
5.4.3 动态上下文
一方面,在进行 SQL 节点树的解析时,需要不断保存已经解析完成的 SQL片段;另一方面,在进行SQL节点树的解析时也需要一些参数和环境信息作为解析的依据。以上这两个功能是由动态上下文 DynamicContext提供的。DynamicContext类的属性中的 StringJoiner用来存储解析结束的SQL片段,bindings则保存了 SQL节点树解析时的上下文环境。
// 上下文环境
private final ContextMap bindings;
// 用于拼装SQL语句片段
private final StringJoiner sqlBuilder = new StringJoiner(" ");
// 解析时的唯一编号,防止解析混乱
private int uniqueNumber = 0;DynamicContext类的构造方法中清晰地展示了上下文环境是如何被初始化出来的,如下图所示:
/**
* DynamicContext的构造方法
* @param configuration 配置信息
* @param parameterObject 用户传入的查询参数对象
*/
public DynamicContext(Configuration configuration, Object parameterObject) {
if (parameterObject != null && !(parameterObject instanceof Map)) {
// 获得参数对象的元对象
MetaObject metaObject = configuration.newMetaObject(parameterObject);
// 判断参数对象本身是否有对应的类型处理器
boolean existsTypeHandler = configuration.getTypeHandlerRegistry().hasTypeHandler(parameterObject.getClass());
// 放入上下文信息
bindings = new ContextMap(metaObject, existsTypeHandler);
} else {
// 上下文信息为空
bindings = new ContextMap(null, false);
}
// 把参数对象放入上下文信息
bindings.put(PARAMETER_OBJECT_KEY, parameterObject);
// 把数据库id放入上下文信息
bindings.put(DATABASE_ID_KEY, configuration.getDatabaseId());
}通过上述代码可以看出,上下文环境 bindings属性中存储了以下信息。
- 数据库 id。因此在编写 SQL语句时,我们可以直接使用 DATABASE_ID_KEY变量引用数据库 id的值。
- 参数对象。在编写 SQL 语句时,我们可以直接使用PARAMETER_OBJECT_KEY变量来引用整个参数对象。
- 参数对象的元数据。基于参数对象的元数据可以方便地引用参数对象的属性值,因此在编写 SQL语句时可以直接引用参数对象的属性。
DynamicContext中还有一个 ContextMap,它是 HashMap 的子类。在进行数据查询时,DynamicContext会先从 HashMap中查询,如果查询失败则会从参数对象的属性中查询。正是基于这一点,我们可以在编写 SQL 语句时直接引用参数对象的属性。DynamicContext类的数据查询操作的源码如下所示。
/**
* 它继承了HashMap的put方法
* public void bind(String name, Object value) {
* bindings.put(name, value);
* }等方法会将一些信息放进来
*/
/**
* 根据键索引值。会尝试从HashMap中寻找,失败后会再尝试从parameterMetaObject中寻找
* @param key 键
* @return 值
*/
@Override
public Object get(Object key) {
String strKey = (String) key;
// 如果HashMap中包含对应的键,直接返回
if (super.containsKey(strKey)) {
return super.get(strKey);
}
// 如果Map中不含有对应的键,尝试从参数对象的原对象中获取
if (parameterMetaObject == null) {
return null;
}
if (fallbackParameterObject && !parameterMetaObject.hasGetter(strKey)) {
return parameterMetaObject.getOriginalObject();
} else {
return parameterMetaObject.getValue(strKey);
}
}
}
阅读了动态上下文环境的源码,我们就知道为什么在书写映射文件时既能够直接引用实参,又能直接引用实参的属性。
5.4.4 SQL节点及其解析
MyBatis 有一个重要的优点是支持动态节点。可数据库本身并不认识这些节点,因此MyBatis 会先对这些节点进行处理后再交给数据库执行。这些节点在 MyBatis中被定义为SqlNode。SqlNode是一个接口,接口中只定义了一个 apply方法。该方法负责完成节点自身的解析,并将解析结果合并到输入参数提供的上下文环境中。SqlNode接口源码如下代码所示。
/**
* @author Clinton Begin
* 在我们写动态的SQL语句时,MyBatis 的 SQL 语句中支持许多种类的节点,如 if、where、foreach 等,它们都是SqlNode的子类。SqlNode及其子类的类图:
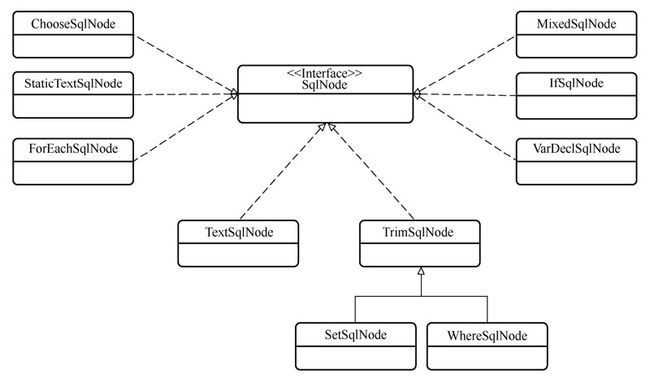
接下来我们将以常见并且典型的 IfSqlNode、ForEachSqlNode、TextSqlNode 为例,对SqlNode接口的实现类进行介绍。
1.IfSqlNodeIfSqlNode
对应着数据库操作节点中的 if节点。通过 if节点可以让 MyBatis根据参数等信息决定是否写入一段 SQL片段。如下便展示了包含 if节点的数据库操作节点。

IfSqlNode类的属性如下所示。 IfSqlNode的 apply方法非常简单:直接调用表达式求值器计算 if节点中表达式的值,如果表达式的值为真,则将 if 节点中的内容添加到环境上下文的末尾。源码如代码16-28所示。
/*** IfSqlNode类的属性 ***/
// 表达式评估器
private final ExpressionEvaluator evaluator;
// if判断时的测试条件
private final String test;
// if成立时,要被拼接的SQL片段信息
private final SqlNode contents;
/*** apply方法源码 ***/
/**
* 完成该节点自身的解析
* @param context 上下文环境,节点自身的解析结果将合并到该上下文环境中
* @return 解析是否成功
*/
@Override
public boolean apply(DynamicContext context) {
// 判断if条件是否成立
if (evaluator.evaluateBoolean(test, context.getBindings())) {
// 将contents拼接到context
contents.apply(context);
return true;
}
return false;
}2.ForEachSqlNode
ForEachSqlNode 节点对应了数据库操作节点中的 foreach 节点。该节点能够对集合中的各个元素进行遍历,并将各个元素组装成一个新的 SQL 片段。如下代码展示了包含foreach节点的数据库操作节点。

ForEachSqlNode类的属性基本和 foreach标签中的内容相对应。ForEachSqlNode类的 apply方法主要流程是解析被迭代元素获得迭代对象,然后将迭代对象的信息添加到上下文中,之后再根据上下文信息拼接字符串。最后,在字符串拼接完成后,会对此次操作产生的临时变量进行清理,以避免对上下文环境造成的影响。
/*** ForEachSqlNode类的属性 ***/
// 表达式求值器
private final ExpressionEvaluator evaluator;
// collection属性的值
private final String collectionExpression;
// 节点内的内容
private final SqlNode contents;
// open属性的值,即元素左侧插入的字符串
private final String open;
// close属性的值,即元素右侧插入的字符串
private final String close;
// separator属性的值,即元素分隔符
private final String separator;
// item属性的值,即元素
private final String item;
// index属性的值,即元素的编号
private final String index;
// 配置信息
private final Configuration configuration;
/*** apply方法源码 ***/
/**
* 完成该节点自身的解析
* @param context 上下文环境,节点自身的解析结果将合并到该上下文环境中
* @return 解析是否成功
*/
@Override
public boolean apply(DynamicContext context) {
// 获取环境上下文信息
Map bindings = context.getBindings();
// 交给表达式求值器解析表达式,从而获得迭代器
final Iterable iterable = evaluator.evaluateIterable(collectionExpression, bindings);
if (!iterable.iterator().hasNext()) { // 没有可以迭代的元素
// 不需要拼接信息,直接返回
return true;
}
boolean first = true;
// 添加open字符串
applyOpen(context);
int i = 0;
for (Object o : iterable) {
DynamicContext oldContext = context;
if (first || separator == null) { // 第一个元素
// 添加元素
context = new PrefixedContext(context, "");
} else {
// 添加间隔符
context = new PrefixedContext(context, separator);
}
int uniqueNumber = context.getUniqueNumber();
// Issue #709
if (o instanceof Map.Entry) { // 被迭代对象是Map.Entry
// 将被迭代对象放入上下文环境中
Map.Entry mapEntry = (Map.Entry) o;
applyIndex(context, mapEntry.getKey(), uniqueNumber);
applyItem(context, mapEntry.getValue(), uniqueNumber);
} else {
// 将被迭代对象放入上下文环境中
applyIndex(context, i, uniqueNumber);
applyItem(context, o, uniqueNumber);
}
// 根据上下文环境等信息构建内容
contents.apply(new FilteredDynamicContext(configuration, context, index, item, uniqueNumber));
if (first) {
first = !((PrefixedContext) context).isPrefixApplied();
}
context = oldContext;
i++;
}
// 添加close字符串
applyClose(context);
// 清理此次操作对环境的影响
context.getBindings().remove(item);
context.getBindings().remove(index);
return true;
}
3.TextSqlNode
TextSqlNode 类对应了字符串节点,字符串节点的应用非常广泛,在 if 节点、foreach节点中也包含了字符串节点。例如,如下代码中的 SQL片段就包含了字符串节点。
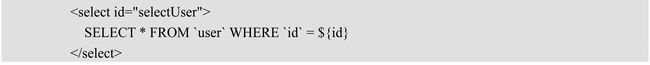
似乎 TextSqlNode对象本身就很纯粹不需要解析,其实并不是。TextSqlNode对象的解析是必要的,因为它能够替换掉其中的“${}”占位符。在介绍 TextSqlNode 对象的解析之前,我们先介绍它的两个内部类:BindingTokenParser类和 DynamicCheckerTokenParser类。BindingTokenParser 类和 DynamicCheckerTokenParser 类都是 TokenHandler接口的子类。TextSqlNode相关类的类图如下图所示。
TokenHandler 接口会和通用占位符解析器 GenericTokenParser 配合使用,当GenericTokenParser 解析到匹配的占位符时,会将占位符中的内容交给TokenHandler 对象的 handleToken 方法处理。在 TextSqlNode 对象中,占位符就是“${}”符号。那么遇到“${}”符号时,BindingTokenParser对象和DynamicCheckerTokenParser对象分别会怎么处理呢?
- BindingTokenParser:该对象的 handleToken方法会取出占位符中的变量,然后使用该变量作为键去上下文环境中寻找对应的值。之后,会用找到的值替换占位符。因此,该对象可以完成占位符的替换工作。
- DynamicCheckerTokenParser:该对象的 handleToken 方法会置位成员属性isDynamic。因此该对象可以记录自身是否遇到过占位符。了解了 BindingTokenParser类和 DynamicCheckerTokenParser类的作用后,我们继续进行 TextSqlNode类的分析。
了解了 BindingTokenParser类和 DynamicCheckerTokenParser类的作用后,我们继续进行 TextSqlNode类的分析。TextSqlNode类的 apply方法如代码所示。
/**
* 完成该节点自身的解析
* @param context 上下文环境,节点自身的解析结果将合并到该上下文环境中
* @return 解析是否成功
*/
@Override
public boolean apply(DynamicContext context) {
// 创建通用的占位符解析器
GenericTokenParser parser = createParser(new BindingTokenParser(context, injectionFilter));
// 替换掉其中的${}占位符
context.appendSql(parser.parse(text));
return true;
}
/**
* 创建一个通用的占位符解析器,用来解析${}占位符
* @param handler 用来处理${}占位符的专用处理器
* @return 占位符解析器
*/
private GenericTokenParser createParser(TokenHandler handler) {
return new GenericTokenParser("${", "}", handler);
}
在对“${}”占位符进行替换时,用到了 BindingTokenParser内部类,它能够从上下文中取出“${}”占位符中的变量名对应的变量值。而 TextSqlNode类中还有一个 isDynamic方法,该方法用来判断当前的TextSqlNode是不是动态的。对于 TextSqlNode对象而言,如果内部含有“${}”占位符,那它就是动态的,否则就不是动态的。isDynamic方法源码如下所示。
/**
* 判断当前节点是不是动态的
* @return 节点是否为动态
*/
public boolean isDynamic() {
// 占位符处理器,该处理器并不会处理占位符,而是判断是不是含有占位符
DynamicCheckerTokenParser checker = new DynamicCheckerTokenParser();
GenericTokenParser parser = createParser(checker);
// 使用占位符处理器。如果节点内容中含有占位符,则DynamicCheckerTokenParser对象的isDynamic属性将会被置为true
parser.parse(text);
return checker.isDynamic();
}因此 BindingTokenParser内部类具有替换字符串的能力,会在 TextSqlNode类的解析方法 apply中发挥作用;DynamicCheckerTokenParser内部类具有记录能力,会在 TextSqlNode类的判断是否为动态方法 isDynamic中发挥作用。
5.5 再论 SqlSource
语言驱动类完成的主要工作就是生成SqlSource,在语言驱动接口LanguageDriver的三个方法中,有两个方法是用来生成 SqlSource 的。而 SqlSource 子类的转化工作也主要在scripting包中完成,因此我们在这里再一次讨论 SqlSource接口及其子类。SqlSource接口的四种实现类及它们的区别:
- DynamicSqlSource:动态 SQL语句。所谓动态 SQL语句是指含有动态 SQL节点(如if节点)或者含有“${}”占位符的语句。
- RawSqlSource:原生 SQL语句。指非动态语句,语句中可能含有“#{}”占位符,但不含有动态 SQL节点,也不含有“${}”占位符。
- StaticSqlSource:静态语句。语句中可能含有“?”,可以直接提交给数据库执行。
- ProviderSqlSource:上面的几种都是通过 XML 文件获取的 SQL 语句,而ProviderSqlSource是通过注解映射的形式获取的 SQL语句。
5.5.1 SqlSource 的生成
1.解析映射文件生成 SqlSource
LanguageDriver 中的接口用来解析映射文件中的节点信息,从中获得SqlSource对象。
/**
* 创建SqlSource对象(基于映射文件的方式)。该方法在MyBatis启动阶段,读取映射接口或映射文件时被调用
* @param configuration 配置信息
* @param script 映射文件中的数据库操作节点
* @param parameterType 参数类型
* @return SqlSource对象
*/
SqlSource createSqlSource(Configuration configuration, XNode script, Class parameterType);
/**
* 创建SqlSource对象(基于映射文件的方式)。该方法在MyBatis启动阶段,读取映射接口或映射文件时被调用
* @param configuration 配置信息
* @param script 映射文件中的数据库操作节点
* @param parameterType 参数类型
* @return SqlSource对象
*/
@Override
public SqlSource createSqlSource(Configuration configuration, XNode script, Class parameterType) {
XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType);
return builder.parseScriptNode();
}
/**
* 解析节点生成SqlSource对象
* @return SqlSource对象
*/
public SqlSource parseScriptNode() {
// 解析XML节点节点,得到节点树MixedSqlNode
MixedSqlNode rootSqlNode = parseDynamicTags(context);
SqlSource sqlSource;
// 根据节点树是否为动态,创建对应的SqlSource对象
if (isDynamic) {
sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
} else {
sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
}
return sqlSource;
}上述代码所示接口的实现在 XMLLanguageDriver类中,可以看出,SqlSource对象主要由XMLScriptBuilder的parseScriptNode方法生成,而该方法生成的 SqlSource 对象是 DynamicSqlSource 对象或者RawSqlSource 对象。
2.解析注解信息生成 SqlSource
ProviderSqlSource类是SqlSource接口的子类。并且,ProviderSqlSource类通过调用 LanguageDriver接口中的 createSqlSource(Configuration,String,Class<?>)方法给出了另一个 SqlSource子类。
/**
* 创建SqlSource对象(基于注解的方式)。该方法在MyBatis启动阶段,读取映射接口或映射文件时被调用
* @param configuration 配置信息
* @param script 注解中的SQL字符串
* @param parameterType 参数类型
* @return SqlSource对象,具体来说是DynamicSqlSource和RawSqlSource中的一种
*/
SqlSource createSqlSource(Configuration configuration, String script, Class parameterType);
// 创建SQL源码(注解方式)
@Override
public SqlSource createSqlSource(Configuration configuration, String script, Class parameterType) {
if (script.startsWith("