同济大学等提出EQL v2:用于长尾目标检测的新梯度平衡方法
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达
本文转载自:AI人工智能初学者
 论文:https://arxiv.org/abs/2012.08548代码:https://github.com/tztztztztz/eqlv2
论文:https://arxiv.org/abs/2012.08548代码:https://github.com/tztztztztz/eqlv2
均衡损失(equalization loss)v2 表现SOTA!性能优于BAGS、Forest R-CNN等网络,代码即将开源!
作者单位:同济大学, 商汤科技, 清华大学
1.简介
最近提出的解耦训练方法成为长尾目标检测的主要范式。但是它们需要一个额外的微调阶段,并且表示和分类器的脱节优化可能导致次优结果。但是,端到端的训练方法,例如均衡损失(EQL),仍然比解耦的训练方法更差。

上图观察结果梯度的幅度相近;尾部类别的梯度接近于0,说明正梯度被负梯度所淹没。因此梯度比可以指示分类器是否经过平衡训练。与基线(蓝色线)相比,EQL(橙色线)的梯度比率只是略有增加。
本文揭示了长尾目标检测中的主要问题是正负之间的梯度不平衡,并且发现EQL不能很好地解决它。为了解决梯度不平衡的问题,本文引入了一种新版本的均衡损失,称为Equalization Loss v2(EQL v2),这是一种新颖的梯度引导Re-Weighing机制,可以独立且均等地重新平衡每个类别的训练过程。
在具有挑战性的LVIS基准上进行了广泛的实验。EQL v2在整体AP方面比原始EQL高出约4个百分点,在稀有类别上提高了14-18个百分点。更重要的是,它还超越了分离训练方法。EQL v2无需进一步调整Open Images数据集,便将EQL提高了6.3个点的AP,显示了其强大的泛化能力。
2.相关工作
2.1 通用目标检测
当前性能比较好的目标检测框架主要依赖于卷积神经网络(CNN)的支持。它们可以分为基于区域的检测器和基于Anchor的检测器。然而,这些框架都是在数据平衡的条件下发展起来的。在数据的长尾分布时,由于类别间的不平衡,性能会严重下降。
2.2 Long-tailed图像分类
我们都知道,传统针对Long-tailed图像分类使用的要么是数据Re-Sample、要么是损失Re-Weighted的方法;但是,数据重采样必须预先计算的数据分布统计,可能存在尾类过拟合和头类欠拟合的风险。同时损失Re-Weighted受到敏感超参数的影响,不同数据集的最佳设置可能差异很大,需要花费很大的精力才能找到相对合适的权重。
也有一些工作试图把Knowledge从头类转移到尾类。OLTR设计了一个内存模块来增加tail类的功能。有研究者通过在特征迁移head类中学习到的知识,然后在特征空间中扩充未充分表示的类。最近,解耦训练模式也引起了人们的广泛关注。他们认为,不需要重新采样就可以学习通用表示,分类器应该在冻结表示的第2微调阶段重新平衡。尽管有很好的结果,额外的微调阶段似乎略显冗余,为什么表示和分类器必须分开学习呢???
2.3 Long-tailed目标检测
相较于前面所说的Long-tailed图像分类,Long-tailed目标检测是一个更具挑战性的任务,它必须在每个可能的位置找到所有不同尺度的目标对象。
Li等人通过实验和实践的经验发现,针对长尾图像分类的方法在目标检测中并不能取得良好的效果。Tan等人也证明了尾部类受到头部类的严重抑制,并提出了一种均衡损失的方法来解决这一问题,忽略尾部类的抑制部分。然而,他们认为负面抑制来自于前景类目的竞争,忽略了背景提案的影响。
而EQL方法必须访问类别的频率,并使用阈值函数显式地分割头部和尾部类别。LST方法则是将长尾分布的学习模型作为一种增量式学习,学习在几个级联阶段从头类切换到尾类。
SimCal方法和Balanced GroupSoftmax方法则遵循解耦训练的思想。BAGS则是根据实例数将所有类别划分为几个组,并在每个组中单独执行softmax操作,以避免head类占据主导地位。
相比之下,本文的方法不需要将类别划分为不同的组,并平等对待所有类别。此外,也不需要微调阶段,可以端到端训练。同时保持了训练与推理之间的一致性。
3.Equalization Loss v2
3.1 实例和任务的纠缠
假设有一批实例 和它们的表征。为了输出 类的 ,使用权重矩阵 作为表征的线性变换。 中的每个权重向量称之为类别分类器,它负责一个特定的类别,即一个任务Task。然后利用sigmoid函数将输出日志转换为估计的概率分布P。期望对于每个实例只有相应的分类器给出高分,而其他分类器给出低分。也就是说,一个带有正号标签的任务和一个带有负号标签的c1任务由一个实例引入。因此,可以计算分类器 的实际正样本 和负样本 的个数

其中 是第 个实例Groud Truth的One-Hot编码,通常有 。则数据集上正样本与负样本的期望之比为:

其中, 是类别 的实例数, 是数据集上的总实例数。上式表明,如果单独考虑每个分类器,对于不同的分类器阳性样本与阴性样本的比例可能会有很大的差异。
3.2 梯度引导Reweighing
显然,当 时, 类便是一个罕见的类。但是,公式2中的比率可能并不能很好地指示训练的平衡程度。这背后的原因是每个样本的影响是不同的。
例如,大量负面影响所积累的负梯度可能比一些正面影响所产生的正梯度要小。因此,可以直接选择梯度统计量作为衡量一个任务是否处于均衡训练状态的指标。每个分类器的输出 相对于损失 的正梯度和负梯度表达式为:

其中, 是第 个情况下第 类的估计概率。
梯度引导Reweighing的基本思想是:根据分类器正梯度与负梯度的累积梯度比,分别对每个分类器的正梯度和负梯度进行加权。为此,先定义 为任务 的累计正梯度与负梯度的比值,直到迭代 。然后在此迭代中,正梯度 和负梯度 的权重可计算如下:
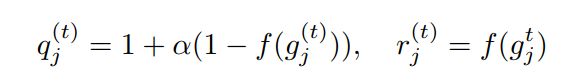
其中, 是映射函数:

得到正梯度 和负梯度 ,然后将它们分别应用于当前批次的正梯度和负梯度,重新加权后的梯度为:

最后为下一个迭代 更新累积的正梯度与负梯度的比率:

3.3 Category-Agnostic任务
本文还增加了一个检测客观性的分支,不是具体的类别,以减少虚假,称之为类别不可知论任务。在训练阶段,本任务将所有其他任务的正样本视为自己的正样本。在推理阶段,其他子任务的估计概率为:

其中 是建议为目标对象的概率。
4. 实验

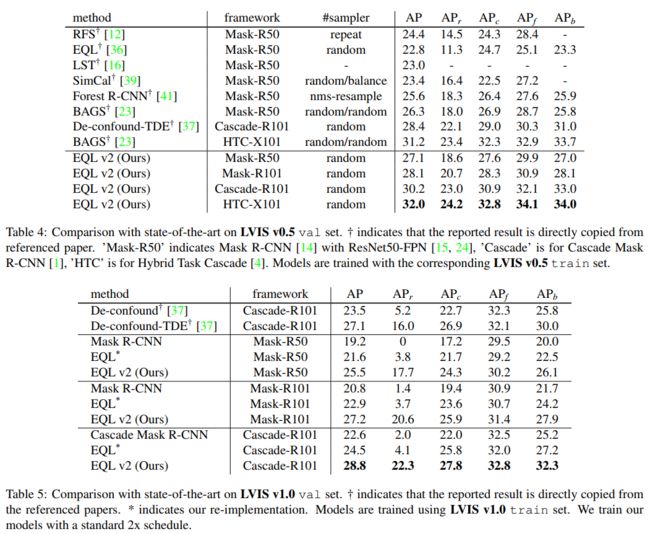
总之,在这项工作中提出了提高长尾目标检测性能的关键是保持正负梯度之间的平衡。然后提出EQL的改进版本EQL v2,以动态平衡训练阶段的正负梯度比率。它带来了巨大的改进,显著增强了跨各种框架的尾部类别。作为一种端到端的训练方法,它在具有挑战性的LVIS基准上击败了所有现有的方法,包括占主导地位的解耦训练模式。
5. 参考
[1].Equalization Loss v2:A New Gradient Balance Approach for Long-tailed Object Detection
目标检测综述下载
后台回复:目标检测二十年,即可下载39页的目标检测最全综述,共计411篇参考文献。
下载2
后台回复:CVPR2020,即可下载代码开源的论文合集
后台回复:ECCV2020,即可下载代码开源的论文合集
后台回复:YOLO,即可下载YOLOv4论文和代码
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2400+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!