Sym-NCO: Leveraging Symmetricity for Neural Combinatorial Optimization 学习笔记
文章目录
- 摘要
- 零、一些基础
-
- 1.Invariant Representation
- 一、介绍
-
-
-
- 高性能
- 问题不可知论
- 架构不可知论
-
-
- 二、组合优化马尔可夫决策过程中的对称性
-
- 0.基础
- 1.组合优化马尔可夫决策过程
-
-
- 状态
- 动作
- 奖励
-
- 2.CO-MDP的对称性
-
- (0)基础
- (1)问题对称性(定义2.1)
- (2)解对称性(定义2.2)
- (3)旋转对称性(定理2.1)
- 三、对称神经组合优化
-
- 1.通过 L i n v \mathcal{L}_{\mathrm{inv}} Linv进行不变问题表示
- 2.通过 L p s \mathcal{L}_{\mathrm{ps}} Lps和 L s s \mathcal{L}_{\mathrm{ss}} Lss强加问题和解的对称性
-
- (0)基础
- (1)施加解决方案对称性
- (2)施加问题和解决方案对称性
- 四、相关工作
-
- 1.深度构造启发式
- 2.等变深度学习
- 五、实验
-
- 0.基础
- 1.任务和基线选择
- 2.实验设置
-
-
- 问题尺寸
- 超参数
- 数据集和计算资源
-
- 3.性能标准
-
-
- 平均成本
- 评估速度
- 贪婪/多启动性能
-
- 4.实验结果
-
- (1)TSP和CVRP的结果
- (2)PCTSP和OP的结果
- (3)real-world TSP的结果
- (4)应用于各种DRL-NCO方法
- (5)多起点的时间性能分析
- 六、讨论
-
- 1.软不变学习vs.硬约束不变学习
-
- (0)基础
- (1) L i n v \mathcal{L}_{inv} Linv的消融研究
- (2)与EGNN的比较
- 2.限制和未来的方向
-
- (1)扩展问题对称性
- (2)大尺度适应
- (3)对图形COP的扩展
- 七、附录
-
- A 定理2.1的证明
- B 基线的实施
-
- B.1 指针网络
- B.2 AM
- B.3 POMO
- C 有能力的车辆路径规划问题
-
- C.1 训练超参数
- C.2 多起点 后处理
- C.3 投影头的细节
- C.4 计算资源和计算时间
- 八、主要参考文献
- 九、代码解析
- 相关领域
摘要
基于深度强化学习(DRL)的组合优化(CO)方法(如DRL-NCO)已经展现了超过传统CO解决器的显著优点,因为DRL-NCO能够在没有验证求解器得到监督的情况下学习CO求解器标签。本文展示了一个新的训练方案,Sym-NCO,与现有DRL-NCO方法的性能显著提高。Sym-NCO是一种基于正则化器的训练方案,它在各种CO问题和解决方案中利用了通用的对称性。施加旋转不变性和反射不变性等对称性可以大大提高DRL-NCO的泛化能力,因为对称性是某些CO任务所共享的不变性特征。我们的实验结果验证了我们的Sym-NCO大大提高了DRL-NCO方法在四种CO任务中的性能,包括旅行推销员问题(TSP)、能力有限的车辆路径问题(CVRP)、奖品收集TSP(PCTSP)、定向问题(OP),没有使用特定问题的技术。值得注意的是,Sym-NCO不仅优于现有的DRL-NCO方法,而且优于具有竞争力的传统求解器迭代局部搜索(ILS),在PCTSP中有240倍的更快速度。
零、一些基础
1.Invariant Representation
不变表示(invariant representation)是一种计算机编程中的概念,指的是一组不受对象状态影响的恒定属性。不变表示可以用于域自适应(domain adaptation)或强化学习(reinforcement learning)等领域,以提高学习效率和泛化能力。不变表示也可以通过相对于一个基准帧(basis frame)来描述所有帧的配置来实现结构的全局位置和方向的不变性。
一、介绍
组合优化问题(COPs)是离散输入空间上的数学优化问题,具有许多有价值的应用价值,包括车辆路由问题(VRPs)、药物发现和半导体芯片设计。然而,由于COP的NP-hard,很难找到一个最优的解决方案。因此,从实际的角度来看,快速计算接近最优的解是必要的。
传统上,COPs是通过整数程序(IP)求解器或手工制作的(meta)启发式方法来解决的。计算基础设施和深度学习的最新进展构思了神经组合优化(NCO)领域,这是一种基于深度学习的COP解决策略。根据训练方案的不同,NCO方法通常分为监督学习和强化学习(RL)。根据解生成方案的不同,NCO方法也被分为改进式和构造启发式。在NCO方法中,基于深度RL(DRL)的建设性启发式(即DRL-NCO)优于传统方法,因为RL的训练能力不依赖于现有的COP解决方案,以及易处理的构造过程,该过程防止违反规则的特定任务,并保证合格的解决方案。
尽管DRL-NCO很强大,但最先进的常规启发式与DRL-NCO之间存在性能差距。为了缩小差距,已经有人尝试对现有的DRL-NCO方法采用特定问题的启发式。然而,设计一个通用的训练方案来提高DRL-NCO的性能仍然具有挑战性。

在本研究中,我们提出了对称神经组合优化(Sym-NCO),这是一种适用于通用CO问题的通用训练方案。Sym-NCO是一种基于正则化的训练方案,它利用COPs中常见的对称性来提高现有的DRL-NCO方法的性能。为此,我们首先确定了各种COPs中存在的对称性。Sym-NCO利用了在欧几里得图上定义的COP中固有的两种对称性。首先,由解的旋转不变性推导出的问题的对称性;旋转图必须表现出与原始图相同的最优解,如图1a所示。其次是解的对称性,即具有相同最优值的解之间的共享特征。例如,旅行推销员问题(TSP)中的解对称性包括了第一城市的排列不变性(见图1b)。然而,在训练过程中必须自动识别一般COPs的解对称性。这是因为在没有高度研究的领域知识的情况下,多个最优解之间的共享特征通常是难以处理的。
Sym-NCO由两种新的利用对称性的正则化方法组成。首先,我们提出了一种新的优势REINFORCE算法函数,它可以自动识别和利用对称性,而不施加误导性偏差。其次,我们设计了一种新的表示学习方案,通过利用预先识别的对称性来施加对称性。
我们在各种现有的DRL-NCO方法上实验验证了Sym-NCO,通过解决它们的原始目标问题,而没有使用任何特定于问题的技术。通过利用COPs的对称性,Sym-NCO实现了以下目标:
高性能
Sym-NCO在各种COP任务中以极高的速度(解决10,000个实例的几秒钟)实现了接近最佳的性能(不到2%)。此外,SymNCO以更快240×的速度超过了竞争激烈的PCTSP求解器ILS 。
问题不可知论
Sym-NCO不使用特定于问题的启发式方法来解决各种COPs。Sym-NCO一般适用于TSP、CVRP PCTSP和OP的解决方案。
架构不可知论
Sym-NCO可以很容易地实现到任何编码器-解码器模型上,并施加COPs的对称性。Sym-NCO成功地提高了现有的基于编码器-解码器的DRL-NCO方法的性能,如指针网络、AM和POMO。
二、组合优化马尔可夫决策过程中的对称性
0.基础
本节介绍了在组合优化中发现的几个对称特征,并在马尔可夫决策过程中加以表述。NCO的目标是通过解决以下问题来训练 θ θ θ参数化求解器 F θ F_θ Fθ,如式(1):
θ ∗ = arg max θ E P ∼ ρ [ E π ( P ) ∼ F θ ( P ) [ R ( π ( P ) ) ] ] \theta^*=\underset{\theta}{\arg \max } \mathbb{E}_{\boldsymbol{P} \sim \rho}\left[\mathbb{E}_{\boldsymbol{\pi}(\boldsymbol{P}) \sim F_\theta(\boldsymbol{P})}[R(\boldsymbol{\pi}(\boldsymbol{P}))]\right] θ∗=θargmaxEP∼ρ[Eπ(P)∼Fθ(P)[R(π(P))]]
其中 P = ( x , f ) \boldsymbol{P}=(\boldsymbol{x}, \boldsymbol{f}) P=(x,f)是有 N N N个节点的问题实例,由节点坐标 x = { x i } i = 1 N \boldsymbol{x}=\left\{x_i\right\}_{i=1}^N x={xi}i=1N和相关 N N N个特征 f = { x i } i = 1 N \boldsymbol{f}=\left\{x_i\right\}_{i=1}^N f={xi}i=1N组成。
ρ \rho ρ是问题生成分布,
π ( P ) \boldsymbol{\pi}(\boldsymbol{P}) π(P)是 P \boldsymbol{P} P的解决方案,
R ( π ( P ) ) R(\boldsymbol{\pi}(\boldsymbol{P})) R(π(P))是 π ( P ) \boldsymbol{\pi}(\boldsymbol{P}) π(P)的目标价值。
1.组合优化马尔可夫决策过程
我们将组合优化马尔可夫决策过程(CO-MDP)定义为COP解的顺序构造。对于一个给定的 P \boldsymbol{P} P,相应的CO-MDP的分量定义如下:
状态
状态 s t = ( a 1 : t , x , f ) \boldsymbol{s}_t=\left(\boldsymbol{a}_{1: t}, \boldsymbol{x}, \boldsymbol{f}\right) st=(a1:t,x,f)是第 t t t(部分完成)解决方案,其中 a 1 : t \boldsymbol{a}_{1: t} a1:t表示之前选择的节点。初始状态和终端状态 s 0 s_0 s0和 s T s_T sT分别等价于空解和完成解。在本文中,我们将解 π ( P ) \boldsymbol{\pi}(\boldsymbol{P}) π(P)表示为完全解。
动作
动作 a t a_t at是从未访问节点中选择一个节点(即 a t ∈ A t = { { 1 , … , N } \ { a 1 : t − 1 } } a_t \in \mathbb{A}_t=\left\{\{1, \ldots, N\} \backslash\left\{\boldsymbol{a}_{1: t-1}\right\}\right\} at∈At={{1,…,N}\{a1:t−1}})
奖励
奖励 R ( π ( P ) ) R(\boldsymbol{\pi}(\boldsymbol{P})) R(π(P))是COP的目标。我们假定奖励是 a 1 : T \boldsymbol{a}_{1: T} a1:T(解序列)的函数, ∥ x i − x j ∥ i , j ∈ { 1 , … N } \left\|x_i-x_j\right\|_{i, j \in\{1, \ldots N\}} ∥xi−xj∥i,j∈{1,…N}(相对距离)和 f \boldsymbol{f} f(节点特征)。在TSP,能力受限的VRP(CVRP)和奖励收集TSPs(PCTSP),奖励是旅途长度的负数。在定向运动问题(OP)奖励是价值的总和。
当定义CO-MDP时,我们可以定义解地图为式(2):
π ( P ) ∼ F θ ( P ) = ∏ t = 1 T p θ ( a t ∣ s t ( P ) ) \pi(P) \sim F_\theta(P)=\prod_{t=1}^T p_\theta\left(a_t \mid s_t(P)\right) π(P)∼Fθ(P)=t=1∏Tpθ(at∣st(P))
其中 p θ ( a t ∣ s t ( P ) ) p_\theta\left(a_t \mid \boldsymbol{s}_t(\boldsymbol{P})\right) pθ(at∣st(P))是策略,用于在状态 s t s_t st产生 a t a_t at,
T T T是求解构造过程中的最大状态数。
2.CO-MDP的对称性
(0)基础
在各种COPs中都存在对称性。我们推测,将这些对称性施加于 F θ F_θ Fθ上可以提高 F θ F_θ Fθ的泛化性和采样效率。我们定义了在不同的COPs中常见的两种已确定的对称性:
(1)问题对称性(定义2.1)
问题 P i \boldsymbol{P}^i Pi和问题 P j \boldsymbol{P}^j Pj为对称的 P i ⟷ s y m P j \boldsymbol{P}^i \stackrel{\mathrm{sym}}{\longleftrightarrow} \boldsymbol{P}^j Pi⟷symPj,如果它们的最优解集是相同的。
(2)解对称性(定义2.2)
两个问题的解 P P P( π i ( P ) \boldsymbol{\pi}^i(\boldsymbol{P}) πi(P) 和 π j ( P ) \boldsymbol{\pi}^j(\boldsymbol{P}) πj(P))为解对称的 ( π i ⟶ s y m π j ) \left(\boldsymbol{\pi}^i \stackrel{\mathrm{sym}}{\longrightarrow} \boldsymbol{\pi}^j\right) (πi⟶symπj) 如果 R ( π i ) = R ( π j ) R\left(\boldsymbol{\pi}^i\right)=R\left(\boldsymbol{\pi}^j\right) R(πi)=R(πj)。
(3)旋转对称性(定理2.1)
对于任何正交矩阵 Q Q Q,问题 P \boldsymbol{P} P和 Q ( P ) ≜ { { Q x i } i = 1 N , f } Q(\boldsymbol{P}) \triangleq \left\{\left\{Q x_i\right\}_{i=1}^N, \boldsymbol{f}\right\} Q(P)≜{{Qxi}i=1N,f}为问题对称的:即 P ⟷ sym Q ( P ) \boldsymbol{P} \stackrel{\text { sym }}{\longleftrightarrow} Q(\boldsymbol{P}) P⟷ sym Q(P)。证明见附录A。
旋转问题的对称性在每个欧氏COPs中都被识别出来。另一方面,解的对称性不能很容易地识别,因为每个COP的解的性质都是不同的。
三、对称神经组合优化
本节介绍了Sym-NCO,一种利用代码代码对称性的有效训练方案。Sym-NCO通过最小化对称损失函数来对 F θ F_θ Fθ施加对称性,其定义如下式(3):
L s y m = α L i n v + β L s s + L p s \mathcal{L}_{\mathrm{sym}}=\alpha \mathcal{L}_{\mathrm{inv}}+\beta \mathcal{L}_{\mathrm{ss}}+\mathcal{L}_{\mathrm{ps}} Lsym=αLinv+βLss+Lps
其中, L s y m \mathcal{L}_{\mathrm{sym}} Lsym、 L i n v \mathcal{L}_{\mathrm{inv}} Linv和 L s s \mathcal{L}_{\mathrm{ss}} Lss分别是施加不变表示、问题-解联合对称性和解对称性的损失函数。 α , β ∈ [ 0 , 1 ] \alpha,\beta \in [0,1] α,β∈[0,1]为权重系数。在接下来的章节,我们将详细介绍每一个损失。

1.通过 L i n v \mathcal{L}_{\mathrm{inv}} Linv进行不变问题表示
根据定理2.1,原问题 x x x及其旋转问题 Q ( x ) Q (x) Q(x)具有相同的解。我们利用旋转不变表示法,将这个解的对称性施加到 F θ F_θ Fθ的编码器上。
我们将 h ( x ) h (x) h(x)和 h ( Q ( x ) ) h(Q (x)) h(Q(x))分别表示为 x x x和 P ( x ) P (x) P(x)的隐藏表示。为了将旋转不变性施加到 h ( x ) h (x) h(x)上,我们将 L i n v \mathcal{L}_{\mathrm{inv}} Linv定义如下:
L i n v = − S cos ( g ( h ( x ) ) , g ( h ( Q ( x ) ) ) ) \mathcal{L}_{\mathrm{inv}}=-S_{\cos }(g(h(x)), g(h(Q(x)))) Linv=−Scos(g(h(x)),g(h(Q(x))))
其中, S c o s ( a , b ) S_{\mathrm{cos}}(a,b) Scos(a,b)是 a a a和 b b b之间的余弦相似度。 g ( ⋅ ) g(·) g(⋅)是MLP参数化的投影头。
为了施加旋转不变性,我们惩罚投影表示 g ( h ( x ) ) g(h(x)) g(h(x))和 g ( h ( Q ( x ) ) g(h(Q(x)) g(h(Q(x))之间的差异,而不是直接惩罚 h ( x ) h(x) h(x)和 ( h ( Q ( x ) ) (h(Q(x)) (h(Q(x))之间的差异。这种惩罚方案允许使用任意的编码器网络架构,同时保持 h h h的多样性。我们通过经验验证,这种方法获得了更强的求解器,在6.1节有详细介绍。
注意, h h h的旋转不变性也可以通过EGNN,一个不变编码器架构。然而,这种方法不可避免地限制了编码器体系结构的灵活性,从而阻止了使用灵活的体系结构,如Transformer。我们已经通过经验验证了我们的方法比EGNN更有效。
2.通过 L p s \mathcal{L}_{\mathrm{ps}} Lps和 L s s \mathcal{L}_{\mathrm{ss}} Lss强加问题和解的对称性
(0)基础
如第2.2节所述,COPs存在问题和解对称性。我们解释了如何在训练 F θ F_θ Fθ时通过最小化 L p s \mathcal{L}_{\mathrm{ps}} Lps和 L s s \mathcal{L}_{\mathrm{ss}} Lss来施加对称性。我们在REINFORCE算法的背景下提供了 L s s ( π ( P ) ) \mathcal{L}_{\mathrm{ss}}(\boldsymbol{\pi}(\boldsymbol{P})) Lss(π(P))和 L p s ( π ( P ) ) \mathcal{L}_{\mathrm{ps}}(\boldsymbol{\pi}(\boldsymbol{P})) Lps(π(P))的策略梯度。
(1)施加解决方案对称性
一般来说,对称解通常是难以解决的。如定义2.2中的定义,对称解必须具有相同的目标值。因此,我们用 L s s ( π ( P ) ) \mathcal{L}_{\mathrm{ss}}(\boldsymbol{\pi}(\boldsymbol{P})) Lss(π(P))的梯度对 F θ ( π ∣ P ) F_\theta(\boldsymbol{\pi} \mid \boldsymbol{P}) Fθ(π∣P)进行正则化,使其实现的解具有相同的目标值。 L p s ( π ( P ) ) \mathcal{L}_{\mathrm{ps}}(\boldsymbol{\pi}(\boldsymbol{P})) Lps(π(P))的梯度如下:
∇ θ L s s ( π ( P ) ) = − E π k ∼ F θ ( ⋅ ∣ P ) [ [ R ( π ( P ) ) − 1 K ∑ k = 1 K R ( π k ) ⏞ Baseline ⏟ Advantage ] ∇ θ log F θ ( π ( P ) ) ] \left.\nabla_\theta \mathcal{L}_{\mathrm{ss}}(\pi(P))=-\mathbb{E}_{\pi^k \sim F_\theta(\cdot \mid P)}[\underbrace{[R(\pi(P))-\overbrace{\frac{1}{K} \sum_{k=1}^K R\left(\pi^k\right)}^{\text {Baseline }}}_{\text {Advantage }}] \nabla_\theta \log F_\theta(\pi(P))\right] ∇θLss(π(P))=−Eπk∼Fθ(⋅∣P)[Advantage [R(π(P))−K1k=1∑KR(πk) Baseline ]∇θlogFθ(π(P))
式中, { π k } k = 1 K \left\{\pi^k\right\}_{k=1}^K {πk}k=1K为从 F θ ( π ∣ P ) F_\theta(\boldsymbol{\pi} \mid \boldsymbol{P}) Fθ(π∣P)中采样的 P P P的解, log F θ ( π ( P ) ) \log F_\theta(\pi(\boldsymbol{P})) logFθ(π(P))为 F θ F_θ Fθ生成 π ( P ) \boldsymbol{\pi}(\boldsymbol{P}) π(P)的对数似然。 K K K是采样解的个数。
REINFORCE训练通过最大化预期奖励来训练求解者,如果训练得当,预期奖励最终会饱和(即可以找到次优解)。奖励值的饱和度表明采样解 π 1 , . . . , π K π^1,...,π^K π1,...,πK之间的奖励有较小的偏差,即定义2.2中定义的(接近)解的对称性。尽管naive REINFORCE具有本质上施加解对称性的能力,但它不能保证所识别的对称解是最优的。我们提出的基线引导求解器通过诱导对称解群内的竞争来找到改进的对称解。如果对称解群中的任何一个比该群中的其他解具有更高的最优性,则其余解的建议优势将变为负值。负的优势,然后鼓励求解器找到更好的解决方案,从而防止落入一个糟糕的局部最优。总的来说,所提出的 L s s \mathcal{L}_{\mathrm{ss}} Lss不仅施加了解的对称性,而且指导了找到接近最优的解。
POMO采用了一种类似的训练技术,在解决TSP和CVRP时,通过强迫 F θ F_θ Fθ访问所有可能的初始城市来找到对称的解决方案。对于TSP,训练技术是合理的,因为初始城市的排列保留了奖励。然而,COPs的奖励,包括CVRP、PCTSP和OP,通常对第一个城市的选择很敏感。为此,我们不限制第一个城市的选择(TSP除外),而是把它留给 L s s \mathcal{L}_{\mathrm{ss}} Lss的训练过程。因此,解决方案的对称性必须通过训练过程来确定,而不使用潜在的误导性偏差。虽然解对称性是提高泛化能力的一个重要特征,但它并不总是存在或在所有的COPs中发现。这样的观察结果突出了在推导 F θ F_θ Fθ时仅利用解对称性的局限性。这促使我们设计出一种更通用的方法来利用COPs中的对称性。
(2)施加问题和解决方案对称性
如第2.2节所述,旋转问题的对称性在各种COPs中都是常见的。因此,我们根据旋转问题的对称性来正则化 F θ F_θ Fθ,而 L p s ( π ( P ) ) \mathcal{L}_{\mathrm{ps}}(\boldsymbol{\pi}(\boldsymbol{P})) Lps(π(P))的梯度定义如下式(6):
∇ θ L p s ( π ( P ) ) = − E Q l ∼ Q [ E π l , k ∼ F θ ( ⋅ ∣ Q l ( P ) ) [ [ R ( π ( P ) ) − 1 L K ∑ l = 1 L ∑ k = 1 K R ( π l , k ) ⏞ Baseline ⏟ Advantage ∇ θ log F θ ( π ( P ) ) ] ] \nabla_\theta \mathcal{L}_{\mathrm{ps}}(\pi(\boldsymbol{P}))=-\mathbb{E}_{Q^l \sim \mathbf{Q}}\left[\mathbb{E}_{\pi^{l, k} \sim F_\theta\left(\cdot \mid Q^l(\boldsymbol{P})\right)}[\underbrace{[R(\pi(\boldsymbol{P}))-\overbrace{\frac{1}{L K} \sum_{l=1}^L \sum_{k=1}^K R\left(\pi^{l, k}\right)}^{\text {Baseline }}}_{\text {Advantage }} \nabla_\theta \log F_\theta(\pi(\boldsymbol{P}))]\right] ∇θLps(π(P))=−EQl∼Q Eπl,k∼Fθ(⋅∣Ql(P))[Advantage [R(π(P))−LK1l=1∑Lk=1∑KR(πl,k) Baseline ∇θlogFθ(π(P))]
其中 Q \mathbf{Q} Q为随机正交矩阵的分布, Q l Q^l Ql为第 l l l个采样旋转矩阵, π l , k π^{l,k} πl,k为第 l l l个旋转问题的第 k k k个样本解。 L L L和 K K K分别为采样的旋转矩阵和解对称解的个数。
与 L s s \mathcal{L}_{\mathrm{ss}} Lss的正则化方案类似, L p s \mathcal{L}_{\mathrm{ps}} Lps的优势项也引起了从旋转对称问题中采样的解之间的竞争。由于旋转对称性被定义为 x x x和 Q l ( x ) Q_l (x) Ql(x)具有相同的解,负优势值迫使求解器找到更好的解。如第2.2节所述,COPs中的问题对称性通常是预先识别的; L p s \mathcal{L}_{\mathrm{ps}} Lps适用于一般的COPs。此外,对每个对称问题采样多个解,使 L p s \mathcal{L}_{\mathrm{ps}} Lps可以通过与 L s s \mathcal{L}_{\mathrm{ss}} Lss采用类似的方法来施加解的对称性。
四、相关工作
1.深度构造启发式
Bello等人提出了最早的DRL-NCO方法之一,基于指针网络,并使用actor-critic方法对其进行训练。注意模型(AM)通过与Transformer替代指针网络成功地扩展了,它是目前NCO事实上的de-facto标准方法。值得注意的是,AM通过解决几个经典的路由问题及其实际扩展来验证其问题的不可知性。POMO通过利用TSP和CVRP中的解对称性来扩展了AM。尽管POMO显示出了来自AM的显著改进,但它依赖于特定于问题的解决方案的对称性(即,不是问题不可知的)。MDAM通过使用解码器的集成来扩展AM。然而,这种扩展不适用于随机路由问题(即,不是问题不可知的)。在这些很有前途的DRL-NCO方法中,Sym-NCO实现了具有问题不可知特性的SOTA性能。
2.等变深度学习
在深度学习中,对称性通常是通过使用特定的网络架构来实现的。EDP-GNN提出了一种排列等变图神经网络(GNN),它可以产生对输入顺序排列的等变输出。SE(3)-Transformer对Transformer进行限制,使其与SE(3)组输入变换等变。类似地,EGNN提出了一种能产生O(n)群等变输出的GNN体系结构。这些网络架构可以显著减少模型参数的搜索空间。一些研究将等变神经网络应用于RL任务来提高样本效率。然而,通过专门的网络架构(即不限制对称性以满足对称性)来施加对称性会限制模型的表示能力,从而限制DRL-NCO的解质量。我们将在第6.1节中进一步讨论这个问题。
五、实验
0.基础
本节提供了Sym-NCO对TSP、CVRP、PCTSP和OP的实验结果。针对Sym-NCO可以应用于任何基于编解码器的NCO方法,我们在POMO上实现Sym-NCO求解TSP和CVRP,AM求解PCTSP和OP。此外,我们还验证了Sym-NCO对指针网的有效性。
1.任务和基线选择
TSP的目标是找到具有最小行程长度的哈密顿循环。我们使用Concorde和LKH-3作为不可学习的基线,指针网络,S2V-DQN ,RL AM,POMO和MDAM作为神经构建基线。
CVRP是TSP的扩展,旨在找到一组最小的总行程长度,同时满足车辆的容量限制。我们使用LKH-3作为不可学习的基线,而RL,AM,POMO和MDAM作为构建的神经基线。
PCTSP是TSP的一种变体,旨在找到一个最小的旅游长度,同时满足price限制。我们使用迭代局部搜索(ILS)作为不可学习的基线,而AM和MDAM作为构造的神经基线。
OP是TSP的一种变体,旨在在满足旅游长度约束的同时找到最大的总奖金。我们使用指南针作为不可学习的基线,而AM和MDAM作为构建的神经基线。
2.实验设置
问题尺寸
我们提供了四个问题类的 N = 100 N = 100 N=100问题的结果,以及来自TSPLIB的 50 < N < 250 50 < N < 250 50<N<250的real-world TSP问题
超参数
我们将Sym-NCO应用于POMO、AM和指针网络。为了进行公平的比较,我们使用相同的网络架构和训练相关的超参数来训练他们的sym-nco增强模型。详情请参见附录、附录C.1。
数据集和计算资源
我们使用基准数据集来评估求解器的性能。为了训练神经求解器,我们使用了Nvidia A100 GPU。为了评估推理速度,我们使用Intel Xeon E5-2630 CPU和Nvidia RTX2080Ti GPU,与中提出的现有方法进行公平的比较。
3.性能标准
平均成本
我们报告了由Kool提出的10,000个基准实例的平均成本。
评估速度
我们报告的评估速度,因为他们在实践中使用。在这方面,非神经方法和神经方法分别在CPU和GPU上测量了执行时间。
贪婪/多启动性能
对于神经求解器,将衡量多启动性能作为其最终性能是一种常见的做法。然而,当这些在实践中使用时,这种消耗资源的multi-start可能是不可能的。因此,我们分别讨论了贪婪启动问题和多启动问题。
4.实验结果
(1)TSP和CVRP的结果

如表1所示,Sym-NCO在贪婪推出和多启动设置中都优于具有最快推理速度的NCO基线。值得注意的是,Sym-NCO在使用贪婪推理的TSP中实现了0.95%的差距。在TSP贪婪设置中,它在几秒钟内解决了TSP 10,000个实例。
(2)PCTSP和OP的结果

如表2所示,Sym-NCO在贪婪卷展栏和多启动设置中都优于NCO基线。在多启动设置中,Sym-NCO以优于经典的PCTSP基线(即240×)。
(3)real-world TSP的结果

我们在TSPLib上评估了POMO和SymNCO。表3显示,Sym-NCO的性能优于POMO。有关完整的基准测试结果,请参阅附录D.2。
(4)应用于各种DRL-NCO方法

如在第3节中所讨论的,Sym-NCO可以应用于各种DRL-NCO方法。我们验证了Sym-NCO显著改进了现有的DRL-NCO方法,如图3所示。
(5)多起点的时间性能分析
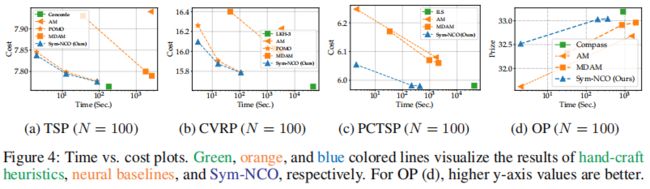
多启动是一种常见的方法,它可以提高解决方案的质量,同时需要更长的时间预算。我们使用旋转增强来产生多个输入(即开始)。如图4所示,Sym-NCO对所有基准数据集都实现了帕累托边界。换句话说,Sym-NCO在给定的时间消耗内的基线中表现出最好的解决方案质量。
六、讨论
1.软不变学习vs.硬约束不变学习
(0)基础
本文提出了一种新的不变学习方案,通过正则化(即soft invariant learning)将问题的对称性施加到NCO上。此外,我们设计了 L i n v \mathcal{L}_{inv} Linv来施加隐表示的对称性。在本节中,我们将提供对这些设计选择的讨论和注释。
(1) L i n v \mathcal{L}_{inv} Linv的消融研究

如图5b所示, L i n v \mathcal{L}_{inv} Linv增加了投影表示法的余弦相似度(即 g ( h ) g (h) g(h))。我们可以得出结论, L i n v \mathcal{L}_{inv} Linv有助于性能的改进(见图5a)。我们进一步验证了在 h h h上施加相似性会降低性能,如图5c所示。这再次证明了保持编码器的表示能力的重要性。
(2)与EGNN的比较
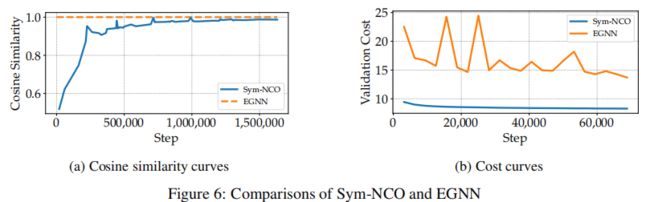
Sym-NCO的一个独特方面是通过soft invariant learning来施加对称性。然而,通过修改网络架构,通过high constraint invariant learning来施加对称性也是一个可行的选择。为了进一步理解对称施加机制的影响,我们还训练了高约束内变量学习模型EGNN作为编码器。如图6a所示,硬方法(即EGNN)严格地加强了对称性。然而,我们观察到EGNN的性能明显低于Sym-NCO,并且不能收敛,如图6b所示。我们认为性能差异主要源于EGNN的网络结构。
2.限制和未来的方向
(1)扩展问题对称性
在这项工作中,我们使用旋转对称性(定理2.1)作为问题的对称性。然而,对于一些COPs,也可以考虑不同的问题对称性,如缩放和平移 P P P。采用这些额外的对称性可以进一步提高Sym-nco的性能。我们把这个问题留给未来的研究吧。
(2)大尺度适应
大规模的适用性对NCO至关重要(这项工作解决了N < 250)。因此,我们期望transfer- , curriculum-和元学习方法可以提高NCO对更大规模问题的通用性。
(3)对图形COP的扩展
本文发现了普遍适用于欧几里得代码的问题对称性。然而,一些COPs被定义在非欧几里得空间中,如非对称TSP。我们也将寻找非欧几里得COPs的普遍对称性留给了未来的研究。
七、附录
A 定理2.1的证明


B 基线的实施
我们直接复制了竞争性的DRL-NCO方法: POMO和AM和指针Net。
B.1 指针网络
指针网是DRL-NCO的早期工作,使用基于LSTM的编码器-解码器架构,以演员-评论家的方式进行训练。我们遵循的开放源代码的指令。

B.2 AM
AM是一种通用的DRL-NCO,一种基于变压器的编码器-解码器模型,可以解决各种路由问题,如TSP、CVRP、PCTSP和OP。我们遵循开放源代码的指令,与带有以下超参数的指针网相同。

B.3 POMO
POMO是一种用于TSP和CVRP的高性能DRL-NCO,在AM的顶部实现。我们按照开放源代码2的说明使用以下超参数。
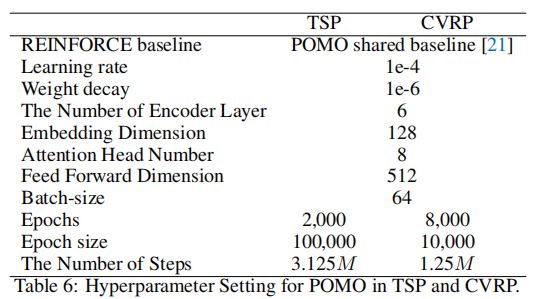
C 有能力的车辆路径规划问题
C.1 训练超参数
Sym-NCO是一种附加在现有DRL-NCO模型顶部的训练方案。我们使用PointerNet、AM和POMO附录B设置了相同的超参数,除了加强基线(我们设置了第3节中介绍的Sym-NCO基线)。Sym-NCO有额外的超参数。首先,我们为所有任务的指针网和AM设置了相同的超参数:
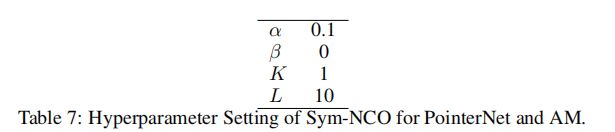
请注意, β = 0 β = 0 β=0的设计选择是为了显示 L p s \mathcal{L}_{\mathrm{ps}} Lps的高适用性,并且因为使用 L s s \mathcal{L}_{\mathrm{ss}} Lss的AM与POMO非常相似。对于POMO,我们设置 β = 1 β = 1 β=1来在POMO基线的顶部强制解的对称性。请注意,我们只在TSP中遵循POMO的第一个节点限制,这是我们在第3节中提到的一个合理的偏差。超参数设置如下:

请注意, β = 1 β = 1 β=1和 K = 100 K = 100 K=100的设计选择是基于POMO的基线设置。我们只是设置了 L = 2 L = 2 L=2,因为训练效率。如果培训资源和时间预算足够,我们建议设置 L > 4 L > 4 L>4;它可能会进一步提高绩效。
C.2 多起点 后处理
为了从一个求解器 F θ F_θ Fθ中取样多个解,我们建议采用之后的实例增强方法。如中所建议的,我们可以生成多个样本来消除对解码步骤的第一节点选择,而且我们可以生成8个样本来以0、90、180、270度旋转,反射:4×2=8。为了与图4(三个标记)中的Sym-NCO和POMO进行比较,我们进行了多态后处理,采样宽度为:1,100,100×8。
另一方面,我们提出了的实例扩展方法,使用随机正交矩阵 Q Q Q。通过将输入问题 P P P与 Q 1 , . . . , Q M Q1,...,QM Q1,...,QM转换为正交矩阵,我们可以从 M M M对称问题中采样多个样本解。我们在PCTSP和OP中通过设置 M = 200 M = 200 M=200来使用这些策略。
C.3 投影头的细节
在第3.1节中介绍的投影头是一个简单的具有ReLU激活函数的两层感知,其中输入/输出/隐藏维数等于编码器的嵌入维数(即128)。
C.4 计算资源和计算时间
为了训练Sym-NCO,我们使用NVIDIA A100 GPU。因为POMO实现不支持GPU并行化,所以我们为POMO + Sym-NCO使用单个GPU。大约需要2周的时间来完成POMO + Sym-NCO的训练。对于训练AM + Sym-NCO,我们使用4×的GPU,它大约需要3天的时间来完成训练。如第5.2节所述,我们在测试时使用NVIDIA RTX2080Ti单GPU。
八、主要参考文献
九、代码解析
【待补充】
相关领域
【待补充】