Spark Streaming及示例
Spark Streaming及示例
一、Spark Streaming介绍
Spark Streaming是近实时(near real time)的小批处理系统 。Spark Streaming是Spark core API的扩展,支持实时数据流的处理,并且具有可扩展,高吞吐量,容错的特点。 数据可以从许多来源获取,如Kafka,Flume,Kinesis或TCP sockets,并且可以使用复杂的算法进行处理,这些算法使用诸如map,reduce,join和window等高级函数表示。 最后,处理后的数据可以推送到文件系统,数据库等
可以从三点进行考虑:输入—–计算—–输出。正如下图所示:

从图中也能看出它将输入的数据分成多个batch进行处理,严格来说spark streaming 并不是一个真正的实时框架,因为他是分批次进行处理的。
Spark Streaming提供了一个高层抽象,称为discretized stream或DStream,它表示连续的数据流。 DStream可以通过Kafka,Flume和Kinesis等来源的输入数据流创建,也可以通过在其他DStream上应用高级操作来创建。在内部,DStream表示为一系列RDD。
Discretized Streams或DStream是Spark Streaming提供的基本抽象。 它表示连续的数据流,即从源接收的输入数据流或通过转换输入流生成的已处理数据流。 在内部,DStream由连续的RDD系列表示,这是Spark对不可变的分布式数据集的抽象。 DStream中的每个RDD都包含来自特定时间间隔的数据,如下图所示。

在DStream上应用的任何操作都会转化为对每个RDD的操作。
二、Spark Streaming示例
1、WordCount
该示例只计算5秒批次内的统计结果
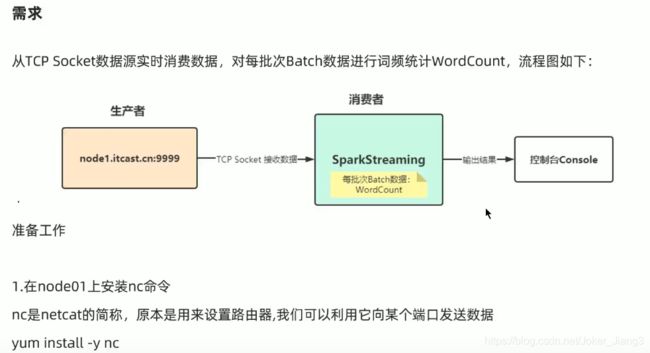
maven的pom文件:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.jianggroupId>
<artifactId>sparkartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<encoding>UTF-8encoding>
<scala.version>2.12.10scala.version>
<hadoop.version>3.2.0hadoop.version>
<spark.version>3.0.1spark.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>2.12.10version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.12artifactId>
<version>3.0.1version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.12artifactId>
<version>3.0.1version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.37version>
dependency>
<dependency>
<groupId>com.hankcsgroupId>
<artifactId>hanlpartifactId>
<version>portable-1.7.8version>
dependency>
dependencies>
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
<configuration>
<args>
<arg>-dependencyfilearg>
<arg>${project.build.directory}/.scala_dependenciesarg>
args>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.4.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
configuration>
execution>
executions>
plugin>
plugins>
build>
project>
scala代码:
package com.jiang.streaming
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCount01 {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val conf:SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc:SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5)) // 每隔5秒分一个批次
//TODO 1.加载数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.89.15",9999)
//TODO 2.处理数据
val resultDS: DStream[(String, Int)] = lines.flatMap(_.split("\\s+")).map((_,1)).reduceByKey(_+_)
//TODO 3.输出结果
resultDS.print()
//TODO 4.启动并等待结果
ssc.start()
ssc.awaitTermination() // 流式应用启动之后需要一直运行等待手动停止/等待数据到来
//TODO 5.关闭资源
ssc.stop(stopSparkContext = true,stopGracefully = true)
}
}
启动数据源:nc -lk 9999
启动程序
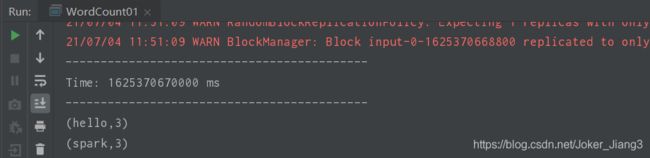
演示结果:

2、状态管理
该示例计算程序运行到结束的所有统计
scala代码:
package com.jiang.streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/*
* @param null
*
* @Description: 状态管理
*/
object WordCount02 {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val conf:SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc:SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5)) // 每隔5秒分一个批次
// The checkpoint directory has not been set. Please set it by StreamingContext.checkpoint().
// state 存在checkpoint
ssc.checkpoint("./ckp")
//TODO 1.加载数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.89.15",9999)
//TODO 2.处理数据
// 定义一个函数用来处理状态
// currentValues:表示该key(如spark)的当前批次的值,如:[1,1]
// historyValues 表示该key(如spark)的历史值,第一次是0,后面就是之前的累加值
val updateFunc = (currentValues:Seq[Int],historyValues:Option[Int]) =>{
if(currentValues.size > 0){
val currentResult = currentValues.sum + historyValues.getOrElse(0)
Some(currentResult)
}else{
historyValues
}
}
val resultDS: DStream[(String, Int)] = lines.flatMap(_.split("\\s+"))
.map((_,1))
// .reduceByKey(_+_)
.updateStateByKey(updateFunc) //updateFunc: (Seq[Int], Option[NotInferedS]) => Option[NotInferedS]
//TODO 3.输出结果
resultDS.print()
//TODO 4.启动并等待结果
ssc.start()
ssc.awaitTermination() // 流式应用启动之后需要一直运行等待手动停止/等待数据到来
//TODO 5.关闭资源
ssc.stop(stopSparkContext = true,stopGracefully = true)
}
}
3、状态恢复
启动程序接着上次停止的数据继续统计
scala代码:
package com.jiang.streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/*
* @param null
*
* @Description: 状态恢复
*/
object WordCount03 {
def creatingFun():StreamingContext = {
//TODO 0.准备环境
val conf:SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc:SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5)) // 每隔5秒分一个批次
// The checkpoint directory has not been set. Please set it by StreamingContext.checkpoint().
// state 存在checkpoint
ssc.checkpoint("./ckp")
//TODO 1.加载数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.89.15",9999)
//TODO 2.处理数据
// 定义一个函数用来处理状态
// currentValues:表示该key(如spark)的当前批次的值,如:[1,1]
// historyValues 表示该key(如spark)的历史值,第一次是0,后面就是之前的累加值
val updateFunc = (currentValues:Seq[Int],historyValues:Option[Int]) =>{
if(currentValues.size > 0){
val currentResult = currentValues.sum + historyValues.getOrElse(0)
Some(currentResult)
}else{
historyValues
}
}
val resultDS: DStream[(String, Int)] = lines.flatMap(_.split("\\s+"))
.map((_,1))
// .reduceByKey(_+_)
.updateStateByKey(updateFunc) //updateFunc: (Seq[Int], Option[NotInferedS]) => Option[NotInferedS]
//TODO 3.输出结果
resultDS.print()
ssc
}
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val ssc: StreamingContext = StreamingContext.getOrCreate("./ckp",creatingFun _)
ssc.sparkContext.setLogLevel("WARN")
//TODO 4.启动并等待结果
ssc.start()
ssc.awaitTermination() // 流式应用启动之后需要一直运行等待手动停止/等待数据到来
//TODO 5.关闭资源
ssc.stop(stopSparkContext = true,stopGracefully = true)
}
}
4、窗口计算
注意:窗口滑动长度和窗口长度一定要是SparkStreaming微批处理时间的整数倍,不然会报错.
scala代码:
package com.jiang.streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object WordCountAndWindow {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val conf:SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc:SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5)) // 每隔5秒分一个批次
//TODO 1.加载数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.89.15",9999)
//TODO 2.处理数据
val resultDS: DStream[(String, Int)] = lines.flatMap(_.split("\\s+"))
.map((_,1))
// .reduceByKey(_+_)
// windowDuration 窗口长度(大小),表示要计算最近多长时间的数据
// slideDuration 滑动间隔,表示每隔多长时间计算一次
// windowDuration和slideDuration必须是batchDuration(批次)的倍数
.reduceByKeyAndWindow((a:Int,b:Int) => a+b,Seconds(10),Seconds(5))
//TODO 3.输出结果
resultDS.print()
//TODO 4.启动并等待结果
ssc.start()
ssc.awaitTermination() // 流式应用启动之后需要一直运行等待手动停止/等待数据到来
//TODO 5.关闭资源
ssc.stop(stopSparkContext = true,stopGracefully = true)
}
}
5、 模拟排行榜每隔10s计算最近20s的top3数据
scala代码:
package com.jiang.streaming
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/*
* @param null
*
* @Description: 模拟排行榜每隔10s计算最近20s的top3数据
*/
object WordCountAndTopN {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val conf:SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc:SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5)) // 每隔5秒分一个批次
//TODO 1.加载数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.89.15",9999)
//TODO 2.处理数据
// resultDS 是20s内统计的rdd集合
val resultDS: DStream[(String, Int)] = lines.flatMap(_.split("\\s+"))
.map((_, 1))
// .reduceByKey(_+_)
// windowDuration 窗口长度(大小),表示要计算最近多长时间的数据
// slideDuration 滑动间隔,表示每隔多长时间计算一次
// windowDuration和slideDuration必须是batchDuration(批次)的倍数
.reduceByKeyAndWindow((a: Int, b: Int) => a + b, Seconds(20), Seconds(10))
val sortRDDs: DStream[(String, Int)] = resultDS.transform(rdd => { // rdd 是统计集合内的每个rdd个体
val sortRdDD: RDD[(String, Int)] = rdd.sortBy(_._2, false)
val top3: Array[(String, Int)] = rdd.sortBy(_._2, false).take(3)
println("==========top3============")
top3.foreach(println)
println("==========top3============")
sortRdDD
})
//TODO 3.输出结果
// resultDS.print()
sortRDDs.print()
//TODO 4.启动并等待结果
ssc.start()
ssc.awaitTermination() // 流式应用启动之后需要一直运行等待手动停止/等待数据到来
//TODO 5.关闭资源
ssc.stop(stopSparkContext = true,stopGracefully = true)
}
}
/*
* 测试数据
*
云南新增本土确诊病例3例热 云南新增本土确诊病例3例热 云南新增本土确诊病例3例热 云南新增本土确诊病例3例热 云南新增本土确诊病例3例热
航天员出舱七个小时怎么喝水 航天员出舱七个小时怎么喝水 航天员出舱七个小时怎么喝水 航天员出舱七个小时怎么喝水
中国成功发射风云三号05星 中国成功发射风云三号05星 中国成功发射风云三号05星
BOSS直聘等被启动网络安全审查新 BOSS直聘等被启动网络安全审查新
菲律宾军机坠毁致47死49伤
*/
6、自定义输出----foreachRDD
将结果自定义输出到控制台、本地文件、mysql等
Scala代码:
package com.jiang.streaming
import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet, Timestamp}
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/*
* @param null
*
* @Description: 模拟排行榜每隔10s计算最近20s的top3数据
* 将统计的数据自定义输出。如:mysql、hdfs等
*/
object WordCountAndTopN02 {
val url = "jdbc:mysql://localhost:3306/bigdata_test"
var username = "root"
val passwd = "123456"
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val conf:SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc:SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5)) // 每隔5秒分一个批次
//TODO 1.加载数据
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.89.15",9999)
//TODO 2.处理数据
// resultDS 是20s内统计的rdd集合
val resultDS: DStream[(String, Int)] = lines.flatMap(_.split("\\s+"))
.map((_, 1))
// .reduceByKey(_+_)
// windowDuration 窗口长度(大小),表示要计算最近多长时间的数据
// slideDuration 滑动间隔,表示每隔多长时间计算一次
// windowDuration和slideDuration必须是batchDuration(批次)的倍数
.reduceByKeyAndWindow((a: Int, b: Int) => a + b, Seconds(20), Seconds(10))
val sortRDDs: DStream[(String, Int)] = resultDS.transform(rdd => { // rdd 是统计集合内的每个rdd个体
val sortRdDD: RDD[(String, Int)] = rdd.sortBy(_._2, false)
val top3: Array[(String, Int)] = rdd.sortBy(_._2, false).take(3)
println("==========top3============")
top3.foreach(println)
println("==========top3============")
sortRdDD
})
//TODO 3.输出结果
// sortRDDs.print() // 默认输出
// 自定义输出
sortRDDs.foreachRDD((rdd,time) => {
val milliseconds: Long = time.milliseconds
println("=======自定义输出======")
println("batchtime---->"+milliseconds)
println("=======自定义输出======")
// 将结果自定义输出
// 控制台输出
rdd.foreach(println)
// 输出到hdfs/本地文件
rdd.coalesce(1).saveAsTextFile("data/output/result-"+milliseconds)
// 输出到Mysql
rdd.foreachPartition(iter => {
// 开启连接
val conn: Connection = DriverManager.getConnection(url,username,passwd)
val sql = "insert into `hotwords` (`time`,`word`,`count`) values (?,?,?)"
val ps: PreparedStatement = conn.prepareStatement(sql)
iter.foreach(t =>{
val word: String = t._1
val count: Int = t._2
ps.setTimestamp(1,new Timestamp(milliseconds))
ps.setString(2,word)
ps.setInt(3,count)
ps.addBatch()
})
ps.executeBatch()
// 关闭连接
conn.close()
ps.close()
})
})
//TODO 4.启动并等待结果
ssc.start()
ssc.awaitTermination() // 流式应用启动之后需要一直运行等待手动停止/等待数据到来
//TODO 5.关闭资源
ssc.stop(stopSparkContext = true,stopGracefully = true)
}
}
/*
* 测试数据
*
云南新增本土确诊病例3例热 云南新增本土确诊病例3例热 云南新增本土确诊病例3例热 云南新增本土确诊病例3例热 云南新增本土确诊病例3例热
航天员出舱七个小时怎么喝水 航天员出舱七个小时怎么喝水 航天员出舱七个小时怎么喝水 航天员出舱七个小时怎么喝水
中国成功发射风云三号05星 中国成功发射风云三号05星 中国成功发射风云三号05星
BOSS直聘等被启动网络安全审查新 BOSS直聘等被启动网络安全审查新
菲律宾军机坠毁致47死49伤
*/