Spark大数据分与实践笔记(第七章 Spark Streaming实时计算框架-02)
第七章 Spark Streaming实时计算框架
7.3.6 DStream实例——实现网站热词排序
接下来,以实现网站热词排序为例外分析出用户对网站哪些词感兴趣或者不感兴趣,以此来增加用户感兴趣词的内容,减少不感兴趣词的内容,从而提升用户访问网站的流量。在SparkStreaming中 是通过DStream编程实现热词排序,并将排名前三的热词输出到Mysql数据表中进行保存。具体实现步骤如下:
1.创建数据库和表
在MySQL数据库中创建数据库和表,用于接收处理后的数据,具体语句如下:
use spark;
create table searchKeyWord(insert_time date,keyword varchar(30),search_count integer);
上述语句中,字段insert_ time代表的是插入数据的日期;字段keyword代表的是热词;字段search_count代表的是在指定的时间内该热词出现的次数。
2.导入依赖
在pom.xm|文件中,添加Mysq|数据库的依赖,具体内容如下:
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.30version>
dependency>
3.创建Scala类,实现热词排序
在spark_ _chapter07项目的/src/main/scala/cn.itcast.dstream文件夹下,创建一个名为"HotWordBySort"的Scala类, 用于编写Spark Streaming应用程序,实现热词统计排序,具体实现代码如文件所示。
文件7-6 HotWordBySort.scala
import java.sql.{DriverManager, Statement}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object HotWordBySort {
def main(args: Array[String]): Unit = {
//1.创建SparkConf对象
val sparkConf: SparkConf = new SparkConf()
.setAppName("HotWordBySort").setMaster("local[2]")
//2.创建SparkContext对象
val sc: SparkContext = new SparkContext(sparkConf)
//3.设置日志级别
sc.setLogLevel("WARN")
//4.创建StreamingContext,需要两个参数,分别为SparkContext和批处理时间间隔
val ssc: StreamingContext = new StreamingContext(sc, Seconds(5))
//5.连接socket服务,需要socket服务地址、端口号及存储级别(默认的)
val dstream: ReceiverInputDStream[String] = ssc
.socketTextStream("192.168.121.128", 9999)
//6.通过逗号分隔第一个字段和第二个字段
val itemPairs: DStream[(String, Int)] = dstream.map(line => (line
.split(",")(0), 1))
//7.调用reduceByKeyAndWindow操作,需要三个参数
val itemCount: DStream[(String, Int)] = itemPairs.reduceByKeyAndWindow((v1: Int, v2: Int) => v1 + v2, Seconds(60), Seconds(10))
//8.Dstream没有sortByKey操作,所以排序用transform实现,false降序,take(3)取前3
val hotWord = itemCount.transform(itemRDD => {
val top3: Array[(String, Int)] = itemRDD.map(pair => (pair._2, pair._1))
.sortByKey(false).map(pair => (pair._2, pair._1)).take(3)
//9.将本地的集合(排名前三热词组成的集合)转成RDD
ssc.sparkContext.makeRDD(top3)
})
//10. 调用foreachRDD操作,将输出的数据保存到mysql数据库的表中
hotWord.foreachRDD(rdd => {
val url = "jdbc:mysql://192.168.121.128:3306/spark"
val user = "root"
val password = "123456"
Class.forName("com.mysql.jdbc.Driver")
val conn1 = DriverManager.getConnection(url, user, password)
conn1.prepareStatement("delete from searchKeyWord where 1=1")
.executeUpdate()
conn1.close()
rdd.foreachPartition(partitionOfRecords => {
val url = "jdbc:mysql://192.168.121.128:3306/spark"
val user = "root"
val password = "12345678"
Class.forName("com.mysql.jdbc.Driver")
val conn2 = DriverManager.getConnection(url, user, password)
conn2.setAutoCommit(false)
val stat: Statement = conn2.createStatement()
partitionOfRecords.foreach(record => {
stat.addBatch(
"insert into searchKeyWord(insert_time, keyword, search_count) values (now(), ' "
+record._1+"','"+record._2+"') ")
})
stat.executeBatch()
conn2.commit()
conn2.close()
})
})
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
运行文件中的代码,并在hadoop01 9999端口输入数据,具体内容如下:
[ root@hadoop01 servers]# nc -lk 9999
hadoop,111
spark, 222
hadoop,222
hadoop,222
hive,222
hive,333
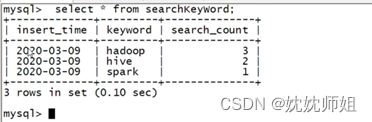
在Mysql的窗口中,执行语句“select * from searchKeyWord"查看数据表searchKeyWord中的数据,具体内容如下: