id函数 / 可变类型变量 / 不可变类型变量 / +=操作
前言
再说正文之前,需要大家先了解一下对象,指针和引用的含义,不懂得同学可以参考我上一篇博客“(12条消息) 引用是否有地址的讨论的_xx_xjm的博客-CSDN博客”
正文
一:python中一切皆对象
“python中一切皆对象”这句话我相信凡是接触过python得同学应该都听过,但我想应该很少有人真正理解这句话,对此,本文在这里进行一个简单得阐述!
在C++里面,我们说int a = 1; a就是一个对象,什么意思呢?在这里a代表了一个内存空间,我们假定这个内存空间的地址是x0001,那么a表示的是存放有1的x0001这个内存空间!所以,与其说a是一个对象,不如说是这个x0001是个对象。a和x0001的关系就是一个人和身份证上名字之间的关系,x0001就表示真实的人,a表示这个人身份证上的名字,比如“小明”。所以,我们简单理解一下,对象,就是一个真实存在的内存空间。
那么python中一切皆对象什么意思呢?还是拿上面的例子来说, int a = 1, 在这里,a代表了一个对象,一个真实的内存地址,那么1是什么呢? 1是一个立即数,是一个稍纵即逝的电流。但是在python里面对于a = 1这个式子,1其实是一个对象,也就是说,python里面,1表示的是一块存放值为1的内存空间!!!python一切皆为对象,就是说在python中,所有东西都是一个具体的内存空间!!,不管是数字,还是字符字符串,他们都是一个实际存在的内存空间。
二:可变类型变量和不可变类型变量
首先,我们先明确,python的数据类型有6中:数字number/ 字符串string / 元组 Tuple / 列表 list / 字典 dictionary / 集合 sets;(bool、int,float,complex(复数)等都属于number数字类型)
可变类型变量:字典/列表/集合
不可变类型变量:数字/字符串/元组
关于可变类型和不可变类型变量的定义参考自:python中可变类型和不可变类型 - 百度文库 (baidu.com)
1:可变类型变量,定义如下: 
也就是说可变类型变量实际上是对象的引用,也就是对象的别名,其实指代的还是对象本身,所以对象本身当然可以对自己的数据进行变换啦。(再次强调,关于引用和指针的关系参考“(12条消息) 引用是否有地址的讨论的_xx_xjm的博客-CSDN博客“)
2:不可变类型变量,定义如下:

所以,不可变类型变量实际上相当于对象的指针,它存储的只是对象的地址,比如a = 1,a这个变量存储的实际上是1这个对象的地址,当然我们也可以把a当作是一个对象,在c++里面,a这种存放地址的变量叫做指针变量,实际上也是一个对象,因为它也是一个实际存在的内存空间。
三:id函数的作用(个人理解,欢迎讨论,指正)
id函数对于可变类型变量和不可变类型变量来说,其实作用是不同的,对于可变类型变量来说,比如a = 1,a是对象1得引用,也就相当于a就是1这个对象(这句话还不理解,再看看引用得含义),id(a)取得是对象1的地址; 而对于不可变类型变量,比如a = [1,2,3],a其实是一个指针变量,也就是说a本身也是一个对象,a有自己的地址,但id(a)取得是[1,2,3]这个对象得地址。
四: +=操作得真实含义
关于 += 的代码层面的区别在于:参考:(12条消息) python的+=和=的区别_Liquor6的博客-CSDN博客

先说结论:对于不可变类型对象:i += 1和 i = i+1是一样的,都会改变 i 的地址(真实的含义是,都会改变i这个指针指向的地址),逻辑上理解为,因为不可变类型变量是指针,i指向的是一个具体的数值对象,不同的数值对象对应的内存地址不同,所以当 i 指向的数值改变了以后,i指向的地址也就变了;
举例: 比如本来i = 1,i是一个指针变量,它指向了1这个对象的内存地址,现在 i += 1和 i = i + 1,表示的都是说 i 这个指针要指向2这个对象的地址,所以,i 指向的地址肯定会从1变成2,这就是为什么不可变对象 += 和 =+是一样的操作。
实验如下

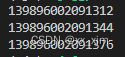
---------------------------------------------------------------------------------------------------------------------
同理,对于可变类型对象,比如a = [1,2,3], [1,2,3]是一个具体的对象,a是这个对象的引用,所以a += 1表示的是[ 1, 2, 3]这个对象自己加1,所以a还是这个对象的引用,但是a = a + 1则不同了,因为是引用,所以a = a + 1则表示a现在引用的应该是a + 1表示的[2,3,4]这个对象的地址,所以a = a + 1导致内存地址改变了。
实验如下:

结果:
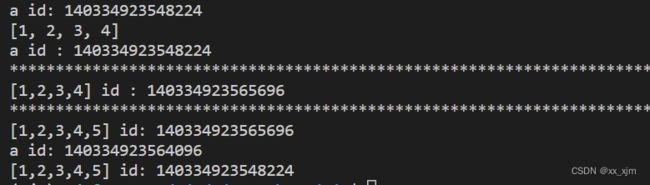
可以看见,虽然a = [1,2,3,4],但是a这个[1,2,3,4]对象,实际上是[1,2,3]这个对象变来的,和本来的[1,2,3,4]对象是两个东西,也就是说,这里a和[1,2,3,4]对象表示的是两块内存空间,只不过两块内存空间保存的值是相同的。
再看a = a + [5]以后,这个时候a的地址是改变了的,它变成了[1,2,3,4,5]的地址,这里有一点小意思,因为我们是在a = a +[5]之前打印的[1,2,3,4,5]的id,所以,这时候[1,2,3,4,5]应该是已经被内存建立起来了,因此此时的a直接指向了[1,2,3,4,5]的内存地址,那么为什么此时[1,2,3,4,5]的地址和[1,2,3,4]的地址相同呢?因为这个时候,python其实是值记住了这个列表中1这个元素的地址,id([1,2,3,4])和id([1,2,3,4,5])返回的其实都是这个列表首元素1的地址。我们意义做如下实验,表明[1,2,3,4])和id([1,2,3,4,5]其实是一块地址空间:
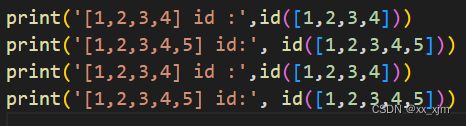

所以,我们来解释为什么这个时候a的地址就是[1,2,3,4,5]的地址,因为这时候内存中已经有一块连续的[1,2,3,4,5]了,并且这个值没有给任何变量(也就是没有引用),所以直接分配给了a。
那么为什么在a之后的[1,2,3,4,5]的地址又变成了最开始a=[1,2,3]的地址了呢?因为这时候a指向了新的[1,2,3,45]的地址,本来的[1,2,3]就被释放了,那么这时候的[1,2,3]就是没人管的了,那么python直接在这个基础上分发[1,2,3,4,5]的地址。由此可以看出python的内存管理机制确实很出色。更多的实验可以参照以下代码自己跑一遍:

补充:另外python中numpy数组是可变类型的, pytorch的张量和numpy数组共享底层内存,所以是可变类型,这就是为什么网络运行过程中,不能有原地+=操作。tensorflow的张量是不可变的。pytorch和tensorflow的张量确实是不同的。
参考:TensorFlow vs PyTorch 2: 张量(Tensor) - 简书 (jianshu.com)
五:由可变不可变类型对象引出的深浅拷贝