学习周报3.19
文章目录
- 前言
- 文献阅读
-
- 摘要
- 简介
- 问题定义
- 方法
- 结论
- 克里金插值法(Kriging法)
- 总结
前言
本周阅读文献《A novel model for water quality prediction caused by non-point sources pollution based on deep learning and feature extraction methods》,文献主要开发了一种新的深度学习模型SOD-VGG-LSTM来提高NPS污染下水质预测的准确性。利用SOD模块计算误差序列,利用VGG模块提取空间特征,以污染物浓度误差序列作为LSTM的输出,用于误差和水质预测。实验结果表明,所建的模型能够很好地预测NPS污染引起的水质变化,并且可以提高水质极值的预测精度。其次,学习了克里金插值法,对克里金插值法有了初步的了解,了解到克里金法公式它主要是对周围的测量值进行加权平均得出未测量位置的预测值。
This week,I read an article which proposes a novel deep learning model named SOD-VGG-LSTM to improve the accuracy of the water quality prediction with NPS pollution. The error sequence was calculated by the SOD modular, and the spatial feature was extracted by the VGG modular. The error sequence of pollutant concentration was used as output of LSTM for error and water quality prediction.The results showed that the established SOD-VGG-LSTM model could predict the water quality change caused by NPS pollution well and improve the prediction accuracy of the extreme value for water quality.Then, I learn the Kriging interpolation method and have a preliminary understanding of Kriging interpolation method. I learn that the formula of Kriging method mainly obtained the predicted value of the unmeasured position by weighted average of the surrounding measurement values.
文献阅读
题目:A novel model for water quality prediction caused by non-point sources pollution based on deep learning and feature extraction methods
作者:Hang Wan , Rui Xu , Meng Zhang , Yanpeng Cai , Jian Li , Xia Shen
摘要
非点源(NPS)污染是影响水环境质量的重要因素。近年来,大量利用在线水质监测站获取连续时间序列水质监测数据。这些数据为深度学习方法在水质预测中的应用提供了必要的基础。然而,传统深度学习方法的预测精度较低,特别是在预测NPS污染的水质方面。针对这一局限性,该文基于物理过程的模拟-观测差分(SOD)模块、反映空间特征的视觉几何(VGG)模块和基于深度学习方法的长短期记忆(LSTM)模块,开发了一种新型深度学习模型SOD-VGG-LSTM,以提高NPS污染下水质预测的准确性。所建立的模型可以克服机制模型无法预测小时或分钟时间尺度上水质变化的问题。该模型应用于漓江流域。实验结果表明,所建立的SOD-VGG-LSTM模型具有优异的计算性能。评估结果表明,SOD-VGG-LSTM 的 R 2提高了 3.2–39.3%相比于ARIMA,SVR和RNN。该模型可为NPS污染水质预测提供新方法。
简介
非点源(NPS)污染是导致水质恶化的重要因素之一。准确预测NPS污染引起的水质变化,对区域水环境保护具有重要意义。然而,NPS污染的特点是随机性和不确定性,具有复杂的传输过程和机制,导致模拟和预测NPS污染引起的水质变化的不便。多年来,已经开发了基于物理过程的机制模型,并用于预测NPS污染引起的水质变化,例如SWAT(土壤和水评估工具),HSPF(水文模拟程序 - FORTRAN)和MIKE SHE(MIKE SYSTEM HYDROLOGICAL EUROPE)模型。水质预测的机理模型通常是在了解物理过程和因素的基础上构建的。机理模型的优点在于这些模型的参数具有严格的物理解释,但参数标定困难、建模结构复杂、模型参数不确定和计算成本高等问题也限制了其在流域水质预测中的应用。与机制模型相比,深度学习模型可能是克服这些限制的有效工具。深度学习模型可以通过动态自适应校正模型元素来处理非线性和高随机性预测,可以有效减少建模者的工作量。而且,与机制模型不同,深度学习模型只关注输入输出关系,而不考虑参数之间的因果关系,可以为环境管理者的建模过程带来便利。因此,深度学习模型可能在一定程度上取代机制模型,成为未来水质预测的有效工具。以前的研究表明,与传统神经网络模型相比,LSTM模型更准确,适用于时间序列数据预测, 然而,LSTM模型无法反映空间特征对研究区NPS污染的影响。好的是,卷积神经网络(CNN)由于其强大的图像识别性能而被开发并应用于提取空间特征,可以反映空间特征对 NPS 预测的影响。作为CNN模型的代表,VGG模型性能稳定,结构简洁,可以成为利用深度学习方法反映空间特征对NPS污染影响的有效方法。这些研究表明,耦合机制模型、VGG模型和LSTM模型的混合模型在NPS污染引起的水质预测中具有潜在的应用前景。
本文建立了模拟-观测差分(SOD)模块化、VGG模块和LSTM模块的混合深度学习模型,用于预测流域NPS污染引起的水质变化。所建立的模型具有以下创新:a)建立了结合深度学习和特征提取方法的智能模型,以反映空间特征对研究区水质的影响;(b)提出了一种结合机制模型和智能模型获得的小时水质估算方法,并与漓江流域观测结果进行了对比验证, (c)所建立的方法利用耦合机制法和深度学习方法提高了水质极值的预测精度,(d)将所建立的模型应用于漓江流域,在水质预测中表现良好。
问题定义
流域水质的变化是空间因子和气象因子等多种因素综合作用的结果。传统的LSTM模型无法反映空间因子对流域水质的影响。因为 LSTM 模型无法识别和提取流域的空间要素。将空间特征耦合到深度学习模型中以预测NPS污染引起的水质变化的研究尚未开展,并且面临一些挑战,然而,VGG方法可以通过卷积过程提取空间特征并降低数据维度,这为通过将空间特征耦合到深度学习方法中来预测NPS污染引起的水质变化提供了机会。因此,建立了一种基于LSTM和VGG方法的新型模型,以克服NPS污染对水质预测的局限性。
方法
文中建立了SOD模块化、VGG模块化和LSTM模块化耦合的混合深度学习模型。模型框架如图所示,包括数据采集部分、VGG特征提取部分、污染物输运扩散模拟部分、纠错部分、结果分析部分。首先,对空间信息、水文气象参数和污染物参数等研究数据进行收集和预处理;其次,采用VGG模型提取流域空间特征,生成具有空间特征的多维时间序列数据;第三,研究水质监测站的空间相关性,建立多源水扩散模型。利用仿真结果和观测结果之间的差异来构建误差序列。第四,开发混合深度学习模型预测NPS污染引起的水质变化。最后,以均方根误差(RMSE)、平均绝对误差(MAE)和对称平均绝对百分比误差(SMAPE)为评价参数,通过实验对模型参数进行优化。通过与现有预测模型的对比,验证了所提模型的准确性。

Feature extraction through VGG
水质变化受地形、植被、坡度等空间因素影响,呈非线性趋势。在这项研究中,采用VGG模型通过卷积过程确定空间特征对水质的影响。该模型包括 13 个卷积层、3 个全连接层和 5 个池化层。采用3*3卷积核通过扫描图像矩阵提取图像特征。原始矩阵数据(图像)可以通过固定矩阵(卷积核)扫描以获得图像特征。结果表明,卷积过程可以提取原始图像的特征,并缩小图像的维数。一般规律可以概括为卷积处理后的矩阵维数等于图像的矩阵维数与卷积核的矩阵维数之差加1。卷积层具有连续3X3卷积内核和最大池化大小2X2。在卷积层中,每层的输入表示前一层输出的一小部分,这小部分的大小与卷积核的大小相同。利用卷积层对上层各小部分进行分析,得到更抽象的空间特征。 ReLU函数作为该层的激活函数,因为它可以有效避免梯度消失的问题,加速训练过程。
空间遥感影像可以提供丰富的土地属性信息,如图4所示。首先,从网络上收集土地利用、植被和坡度等遥感数据;其次,将空间特征图像转换为224x224X3,然后通过VGG模型提取特征。最后,得到了空间图像的时间序列高维特征。为了消除高维冗余特征带来的噪声影响,采用主成分分析对高维特征降维,得到多维空间特征时间序列数据。将这些数据与水文气象数据、污染物数据和目标污染物误差相结合,构建混合深度学习模型的输入输出数据集。

Simulation-observation difference for pollutant
本文采用基于物理过程的机理模型模拟流域污染物的传输扩散过程。基于物理的模型是一个模块化结构模型,由水文过程子模块、土壤侵蚀子模块和污染负荷子模块组成。该模型主要由水平衡方程驱动,可以表示为
![]()
SWt代表土壤含水量;SW0表示初始土壤含水量;T 是时间;Rd,Qsurf,Ea,Wseep和Qgw分别表示降水、地表径流、蒸发、渗透和地下水含量。
根据DEM和实测河网将研究区划分为8个子流域。模型的校准和验证遵循先径流后养分的原则。利用阳朔水文监测站流量数据对径流进行标定验证,利用阳朔河流日实测水质数据进行趋势验证。模型的一些关键参数和过程没有标定和校正,只能保证模型预测趋势的准确性。模型标定的目的只需要保证模型预测趋势的准确性。基于预测结果,利用模拟-观测差值稳定水质时间序列,降低极值预测误差。
![]()
其中,N 是数据系列的长度;St和Vt分别是时间t处模拟结果和观测结果的数据记录;XDiff是基于一阶差St和Vt并将用作已建立模型的输出。目标站污染物的误差时间序列通过下式获得XDiff。
Error correlation through LSTM
利用长短期记忆模型,根据近一刻的水文气象指标、污染物指数、空间特征指标和目标污染物误差,预测下一刻污染物误差。该方案采用了滚动预测方案。预测窗口中的所有指标都用于预测下一刻的污染物误差。重复此过程,直到目标污染物的误差预测完成。

以基于机制模型的模拟值与监测值之间的水质误差序列、VGG模型提取的空间特征时间序列、上游监测站水文水质数据作为LSTM模型的输出或输入,预测河流污染物浓度误差。最后,通过LSTM模型预测污染物浓度的误差序列和机制模型模拟的估计值的误差序列来反演河流的实际水质。最终的模型结构如图所示。
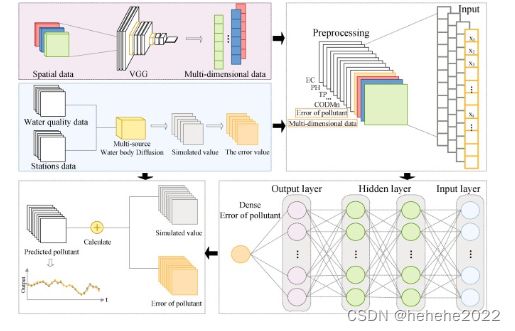
模型性能评估
通过一系列数值试验对所建立的SOD-VGG-LSTM模型的准确性和性能进行了评价。首先,研究了所提出的SOD-VGG-LSTM模型能否有效克服数据偏差的极值问题。然后,在不考虑空间流域特征的情况下,将所提出的模型与LSTM模型进行比较。最后,将所提方法与基于统计理论的自回归移动平均模型(ARIMA)、基于传统机器学习的支持向量回归模型(SVR)和基于深度学习的传统神经网络模型(RNN)模型进行了对比。
评价指标包括RMSE、MAE和SMAPE。
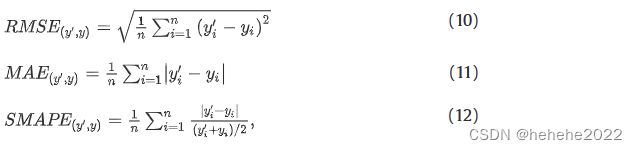
极值预测
当NPS污染物在极端气象条件下急剧变化时,传统的深度学习方法受历史数据限制,无法有效预测极值,而物理模型可以确保预测在可控范围内。为了评估所提出的模型对极值的预测性能,对未出现在训练数据集中的数据进行了SOD-VGG-LSTM。预测结果表明,预测值与观测值的最大相对误差分别为6.07%、11.6%、22.1%和23.9%。显然,所建立的SOD-VGG-LSTM模型在耦合机制模型预测日尺度极值后获得了较好的预测精度。

结论
本文开发了一种与SOD、VGG和LSTM模块耦合的混合深度学习模型。训练数据集由一组时间序列数据构建,包括水文气象参数、污染物参数、误差序列和空间特征序列。利用SOD模块计算误差序列,利用VGG模块提取空间特征。以污染物浓度误差序列作为LSTM的输出,用于误差和水质预测。所建立的模型不仅可以克服极值预测的问题,而且可以反映不同时间或区域的空间特征对水质的影响。
克里金插值法(Kriging法)
反距离插值(IDW)
空间插值问题,就是在已知空间上若干离散点(xi,yi)的某一属性(如气温,PM2.5浓度)的观测值Zi=z(xi,yi)的条件下,估计空间上任意一点(x,y)的属性值的问题。地理属性有空间相关性,相近的事物会更相似。由此人们发明了反距离插值,对于空间上任意一点(x,y)的属性z=z(x,y),定义反距离插值公式估计量:

其中α通常取1或者2。用空间上所有已知点的数据加权求和来估计未知点的值,权重取决于距离的倒数(或者倒数的平方)。那么,距离近的点,权重就大;距离远的点,权重就小。
但存在的问题是:
1.通常 α的值通常不确定
2.用倒数来描述空间的关联程度不够准确
所以提出了克里金插值法。
克里金插值法
定义:根据样品空间位置不同、样品间相关程度的不同,对每个样品品位赋予不同的权,进行滑动加权平均,以估计中心块段平均品位。
克里金斯插值的优势:
1.在数据网格化的过程中考虑了描述对象的空间相关性质,使插值结果更科学、更接近于实际情况;
2.能给出插值的误差(克里金方差),使插值的可靠程度一目了然
克里金插值公式:

其中Z0^ 是点(x0,y0)处的估计值。λi是权重系数。它同样是用空间上所有已知点的数据加权求和来估计未知点的值。但权重系数并非距离的倒数,而是能够满足点(x0,y0)处的估计值Z0^ 与真实值Z0的差最小的一套最优系数。
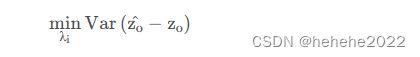 假设条件:
假设条件:
普通克里金插值的假设条件为,空间属性z是均一的。对于空间任意一点(x0,y0),都有同样的期望c与方差 。
无偏估计条件:
 又因为上述假设条件,对任意点(x,y)都有
又因为上述假设条件,对任意点(x,y)都有
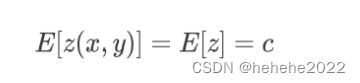
所以推出
得出了系数λi的约束条件之一。
总结
本周学习了克里金插值法,有了初步的了解,下周继续学习克里金插值法,了解具体的推断过程。