最新Scrapy(CrawlSpider)+Selenium全站数据爬取(简书)
Scrapy(CrawlSpider)+Selenium全站数据爬取【进阶】
前言:学习了 Scrapy基于CrawlSpider进行全站数据爬取 之后,我们进阶学习Scrapy(CrawlSpider)搭载Selenium进行全站数据爬取。
为什么要搭载
Selenlium呢?在我们之前的学习中,知道网站上有些数据是通过js动态加载出来的,我们不能直接获取这部分数据 ,需要单独对ajxa数据对应的url,进行请求,但有了Selenium的加入,网页能展示给我们看的,我们就能直接去获取到,不需要单独再去处理数据了。
优点:操作简单、能看到的基本就能爬到。
缺点:费时、效率低、占用资源大…(为什么呢?因为它是模拟人操作,会加载很多无用、无价值资源)
听到这么多缺点,是不是对
selenium失望了。不过,我们在实际开发中可不是全程都用selenium进行爬取的哦,只是在应付一些,复杂操作时,会使用selenium辅助。这么解释,自己在爬取时,懒得去解析其网站的加密算法时,就可以直接使用
selenium,(我们看到的就是selenium看到的)如 破解端口加密 博客中,是去解析其加密算法,才得到真实端口号的,而现在使用selenium就可以直接去获取其显示在网页上的真实端口号了,只针对于规模较小的爬取。
好了,说了这么多,意思就是要分场景、分情况使用。
进入今天的话题,使用Scrapy(CrawlSpider)+Selenium进行全站数据爬取。
这次训练爬取的网站是【简书】,
主要是训练搭配Selenium的使用,因此本次练习,在获取数据这块,都是使用的Selenium操作的,并没考虑效率。
点击下载【完整代码】
一、了解需求
爬取简书全站的文章,字段有 [ title:标题 ,author:作者 ,time:发布时间 ,word_count:字数,read_count:阅读量,content:文章内容,topic:专题 ]。
二、分析网站
简书官网地址:https://www.jianshu.com/
我们先大致浏览下网页
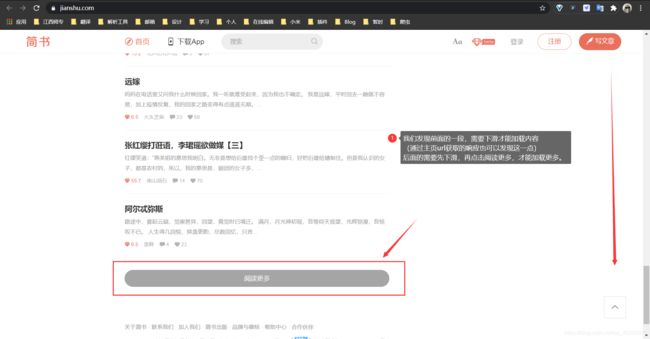
我们发现前面的一段,需要下滑才能加载内容(通过主页url获取的响应也可以发现这一点)后面的需要先下滑,再点击阅读更多,才能加载更多。
我们再看看需要爬取的字段内容。
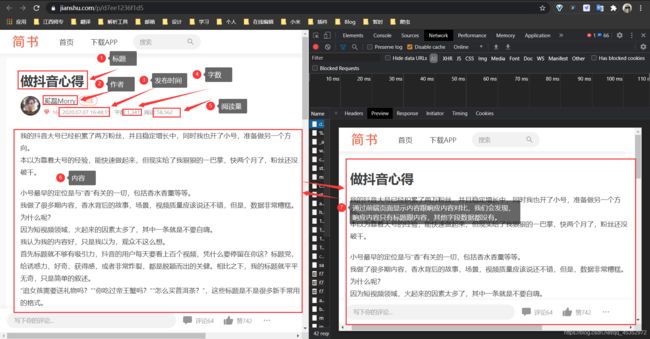
我们会发现展示在前端的内容跟响应内容不一样,响应内容只有标题跟文章内容。
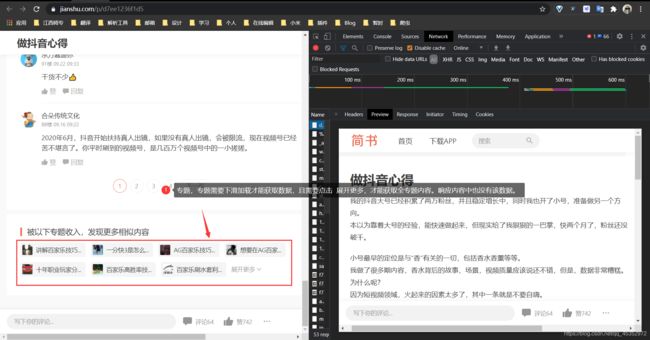
专题字段,专题需要下滑加载才能获取数据,且需要点击 展开更多,(可能不用点击,也可能需要多次点击)才能获取全专题内容。响应内容同样也没有该字段数据。
要爬取全站数据,就要多看看这些文章都出现在哪里。


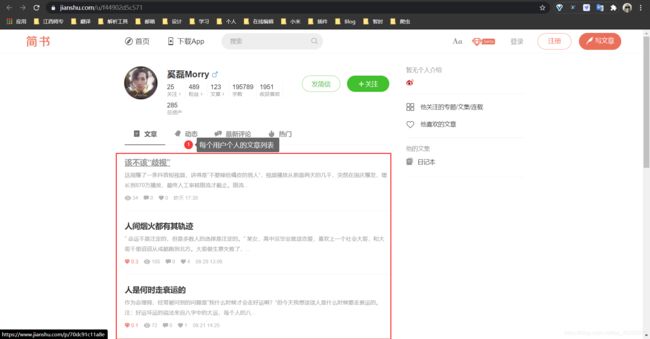
主要在首页列表、个人文章列表中。
思路:那些下滑,点击,动态加载的数据,我们用Selenium进行操作,获取内容,进而得到完整的网页数据,详情文章url,我们通过CrawlSpider中的匹配规则获取。
流程:在本站中能看到的文章主要在首页文章列表、每个用户个人文章列表以及推荐阅读列表上,爬虫CrawlSpider将start_url给Selenium,通过Selenium去加载获取这些页面的所有内容,并返回给爬虫,follow=True继续作用于匹配规则url中,直到整个网站爬取完毕,结束。
以上总结,都要自行查看网站分析并进行总结的。
三、编写代码
本次编写代码部分就不像之前文章,一步一步来讲述了,相信看这篇的小伙伴,基本的爬虫知识都掌握了,前面也进行了网站分析,需要怎么做,思路、流程也交代了,接下来,只讲代码中的一些关键部分。
首先写规则解析器
Rule(LinkExtractor(allow=r'(/u/[0-9a-z]{12}|/p/[0-9a-z]{12})'), callback='parse_item', follow=True),
我们分析可以发现,文章都是.../p/...的url格式,用户个人文章列表url都是.../u/...的格式,且后面的是一个12位数,由0-9a-z组成的字符串。
接着发起的请求,我们需要从中拦截,并交给Selenium处理,这件事,我们可以交给中间件中的下载器中间件(middlewares.py)处理,因为它有一个方法就是专门拦截请求的——process_request。
代码如下:
# 拦截请求
def process_request(self, request, spider):
# return None
driver = webdriver.Chrome(executable_path=r'E:\Python_Project\Scrapy\chromedriver.exe')
if request.url == 'https://www.jianshu.com/' or request.url.split('/')[-2] == 'u':
# 打开一个指定网址
driver.get(request.url)
time.sleep(0.5)
while True:
# 获取当前网页正文全文高度
check_height = driver.execute_script("return document.body.scrollHeight;")
try:
# 如果获取到网页上有 阅读更多 则进行点击加载
load = driver.find_element_by_class_name('load-more')
print('已点击>阅读更多')
load.click()
except:
pass
# 移动一个网页正文全文高度,也就等于下拉一次到底部
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(0.5)
# 计算最新的网页正文全文高度
check_height1 = driver.execute_script("return document.body.scrollHeight;")
# 如果滑动一次,前后两次的高度都没有变的话,说明已经滑倒底部了
if check_height == check_height1:
break
else: # else 打开的都是文章内容, .../p/...
# print(request.url)
# 打开一个指定网址
driver.get(request.url)
time.sleep(0.5)
try:
i = 1
while True:
# 定位到专题 展开更多
unfold = driver.find_element_by_class_name('H7E3vT')
if i == 1:
# 注意找到了该元素,并不等于可以进行操作,需要在屏幕可视范围内进行操作;
# 注意如果没有找到该元素,会抛出异常。
driver.execute_script("arguments[0].scrollIntoView();", unfold) # 拖动到可见的元素去
print('已将元素拖动到屏幕内')
# 以下需要注意,文章模块有两种,一种底部有推荐阅读,一种个人文章,底部没有推荐阅读。
try:
# 定位 “更多精彩内容” , 如果定位到,说明有推荐阅读;如果没有定位到,则抛出异常,并被捕捉处理。
recom = driver.find_element_by_class_name('_29KFEa')
print('查找到该篇文章有 “推荐阅读”')
# 这里有坑,因为 在简书的文章中,头部跟底部都是固定定位(fixed)的,也就是说,当你定位到指定元素时,虽说是在屏幕内,但是不在可视范围内,需要格外做处理,进行上下拖动。
driver.execute_script('window.scrollBy(0,-100)')
# scrollBy(xnum,ynum) 是从当前位置滚动到某个相对位置,从当前位置起向右和向下滚动多少像素。
# scrollTo(xpos,ypos) 是滚动到某个绝对位置,即滚动到坐标为xpos,ypos的位置。
print('向上滑动100像素')
except:
print('查找到该篇文章没有 “推荐阅读”')
# 直接滑到底部即可,即屏幕的可视范围了
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
i += 1
unfold.click()
print('已点击>展开更多')
time.sleep(0.5)
except:
print('本篇可能没有专题收入或者已经获取完了')
source = driver.page_source # 获取所有网页内容
response = HtmlResponse(url=driver.current_url, body=source, request=request, encoding='utf-8')
driver.quit() # 这里要注意的是,要先获取内容,在关闭浏览器
return response
代码上基本都有注释,这里就不多解释了。
到这,全站数据基本就全部获取到了,开启中间件(settings.py)
'Jianshu.middlewares.JianshuDownloaderMiddleware': 543,
是不是很简单。
四、数据持久化存储
设置爬取字段(items.py)
class JianshuItem(scrapy.Item):
title = scrapy.Field() # 标题
author = scrapy.Field() # 作者
time = scrapy.Field() # 发布时间
word_count = scrapy.Field() # 字数
read_count = scrapy.Field() # 阅读量
content = scrapy.Field() # 文章内容
topic = scrapy.Field() # 专题
使用xpath提取获取数据
def parse_item(self, response):
print(response)
# .../u/...格式的url是用户个人页面,并不是我们需要爬取的数据,需要剔除,我们爬取的内容在.../p/...格式的url中,也就是文章中。
if not response.url.split('/')[-2] == 'u':
# print(response)
item = JianshuItem()
item['title'] = response.xpath('//*[@id="__next"]/div[1]/div/div/section[1]/h1/text()').extract_first()
item['author'] = response.xpath('//*[@id="__next"]/div[1]/div/div/section[1]/div[1]/div/div/div[1]/span/a/text()').extract_first()
item['time'] = response.xpath('//*[@id="__next"]/div[1]/div/div/section[1]/div[1]/div/div/div[2]/time/text()').extract_first()
item['word_count'] = response.xpath('//*[@id="__next"]/div[1]/div/div/section[1]/div[1]/div/div/div[2]/span[1]/text()').extract_first().split(' ')[-1].replace(",", "") if not response.xpath('//*[@id="__next"]/div[1]/div/div/section[1]/div[1]/div/div/div[2]/span[1]/i') else response.xpath('//*[@id="__next"]/div[1]/div/div/section[1]/div[1]/div/div/div[2]/span[2]/text()').extract_first().split(' ')[-1].replace(",", "")
item['read_count'] = response.xpath('//*[@id="__next"]/div[1]/div/div/section[1]/div[1]/div/div/div[2]/span[2]/text()').extrect_first().split(' ')[-1].replace(",", "") if not response.xpath('//*[@id="__next"]/div[1]/div/div/section[1]/div[1]/div/div/div[2]/span[1]/i') else response.xpath('//*[@id="__next"]/div[1]/div/div/section[1]/div[1]/div/div/div[2]/span[3]/text()').extract_first().split(' ')[-1].replace(",", "")
item['content'] = response.xpath('//*[@id="__next"]/div[1]/div/div/section[1]/article//text()').extract()
item['topic'] = ",".join(response.xpath('//*[@id="__next"]/div[1]/div/div[1]/section[3]/div//text()').extract())
yield item
管道进行存储(pipelines.py)
我这边进行了本地存储跟MySql数据库存储,可以都学习下。
本地存储:
class JianshuPipeline:
def process_item(self, item, spider):
data = []
data.append(item['title'])
data.append(item['author'])
data.append(item['time'])
data.append(item['word_count'])
data.append(item['read_count'])
data.append(item['content'])
data.append(item['topic'])
file_name = re.sub(r'[\\/:*?"<>|]', '', item['title'])
try:
with open(f'./{file_name}.md', 'w', encoding='utf-8')as f:
for i in data:
if data.index(i) == 5:
for c in i:
if not c == '\n':
f.write(str(c) + '\n')
else:
f.write(str(i) + '\n')
print(f'文章{file_name}写入本地 ...OK')
except Exception as e:
print(f'本地写入失败:{e}')
return item
MySql数据库存储:
class MysqlPipeline(object):
conn = None
cursor = None
'''
host: 地址 本地的是127.0.0.1
port: 端口号 3306
user: 用户名
password: 密码
db: 数据库名
charset: 数据库编码(可选)
'''
def open_spider(self, spider):
# 进行异常处理,可能会因为我们的疏忽或者数据库的更改造成连接失败,所以,我们要对这部分代码块进行异常捕捉
try:
# 连接数据库
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='LJ19991215', db='jianshu',
charset='utf8')
print('连接成功<<')
except Exception as e:
print(f'连接失败!!>>{e}')
exit() # 可以直接结束运行,按需求来设定
def process_item(self, item, spider):
# 创建游标
self.cursor = self.conn.cursor()
file_name = re.sub(r'[\\/:*?"<>\'|]', '', item['title'])
content = "GN".join(item['content'])
try:
# 插入数据
self.cursor.execute(
'INSERT INTO js (id, title, author, time, word_count, read_count, content, topic) VALUES(null, "{}", "{}", "{}", "{}", "{}", "{}", "{}")'.format(item['title'], item['author'], item['time'], item['word_count'], item['read_count'], content, item['topic']))
# 数据提交到数据库
self.conn.commit()
print(f"文章<{item['title']}>已提交至数据库")
except Exception as e:
print(f">>存储失败>>文章<{item['title']}>{e}")
self.conn.rollback()
exit() # 直接关闭程序
return item
def close_spider(self, spider):
# 先关闭游标
self.cursor.close()
# 再关闭连接
self.conn.close()
开启管道(settings.py)
ITEM_PIPELINES = {
'Jianshu.pipelines.JianshuPipeline': 300,
'Jianshu.pipelines.MysqlPipeline': 301,
}
最后,我们看看爬取的数据吧

数据太多,我就没一直爬下去了,没有报错,能顺利存储下去就基本没啥大问题了。
五、优化代码
- 伪装UA
- 使用代理IP
- 无头浏览器
- 规避检测
如何伪装UA跟使用代理IP文章《Scrapy中伪装UA跟使用代理IP》有讲解。
如何设置无头浏览器跟规避检测文章《Selenium的基本使用》的第四点跟第五点有讲解。
为什么要这么做,文章中有做解释。嘻嘻,主要就是懒,就不在这唠叨了。
这里也就不展示代码了,太占位置,具体请看【完整代码】代码中未写无头浏览器跟规避检测操作,是因为在前期测试中,能更直观查看效果。
新手上路,代码写得不好,如果有理解错误的或者不理解的,欢迎在评论区中,指出来,非常感谢!
以上就是Scrapy(CrawlSpider)+Selenium全站数据爬取【进阶】练习的所有内容了,点赞收藏加评论是最大的支持哦!
编写不易,转载请注明出处,如有侵权,请联系我!