气象数据之积温数据的获取与处理
1. 数据获取
数据从中国气象共享网站获取
注册之后记得经常登陆签到,就当自己充了个vip一样
否则的话你刚开始注册能下载的数据量就只有2.0M(虽然TXT文件比较小)
到筛选那输入3.0点击筛选。
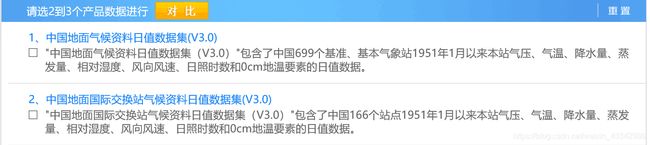
出现了2个3.0然鹅只能选择第2种,因为第一种需要科研用户才能下载,科研用户需要省级以上的项目才能成为科研用户。所以只能选第二种,只有166个站点的数据,像我要处理的山东省的站点的数据只有6个。
然后点进去之后选择时间,间隔只能为2个月,比如选择2009.03-2009.04,然后弹出来一堆数据,由于我要的是气温数据,所以选择 TEM ,具体要什么数据就可以参照网站内的 word ,选择格式说明的 doc 就ok,
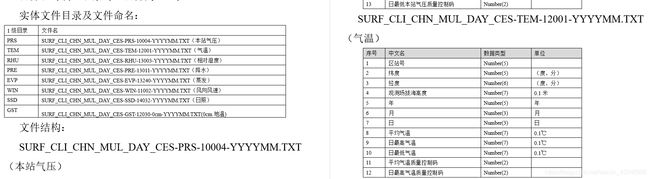
每种后缀名对应的数据以及每种数据在.TXT中的对应列的含义也在里面。
筛选完之后就出现下面的结果
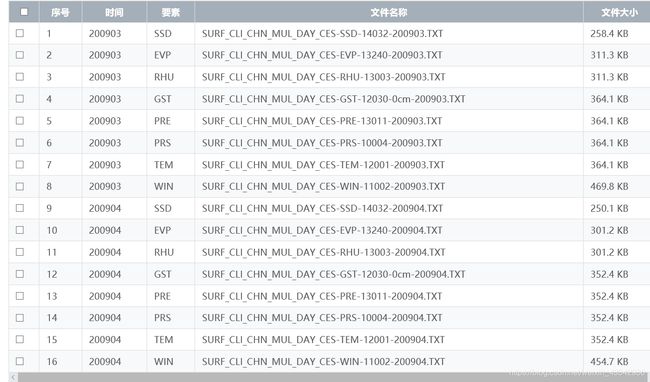
勾选 2 个TEM即可,重复操作,像 10 年跨度的数据可能需要操作一会( 我当时花了10天左右,容许数据下载量不够)。选完之后在数据框中提交,等待一会然后等数据处理成功之后就可以下载,下载给的是链接。
然后把它复制到记事本里面去,剪切一下一个一个下载就ok,下完之后把文件全部放一个文件夹里就行,为后期的处理铺垫,像我做的数据需要 10 年,每年 8 个月,一共就是 80 个 .TXT 数据。
由于 80 个文本而且是全国的气象站点,所以处理起来挺麻烦的,如果一年一年的话,就需要把数据放一起然后筛选,这样时间成本一下就上去了,于是鄙人失眠了半个晚上想出了代码处理。最后tic toc一下用了将近 5 秒就拿出了山东省 6 个站点 10 年的积温数据
生物积温:指的是每天平均气温≥10℃的数据。
由于用的是 MODIS 数据 15 景合成的数据,规定的生长期为 3 月 6 日- 10 月 6 日,所以需要找出这里面 ≥ 10 ℃ ≥10℃ ≥10℃ 的数据,由于数据都是整月的数据,需要自己剔除一部分数据,如 3.1-3.6,10.6-10.31 日。
由于数据文件的命名非常的对称,为批量处理埋下了伏笔,其实就是真正循环就是为了字符串的拼接。
SURF_CLI_CHN_MUL_DAY_CES-TEM-12001-200910.TXT
所以只需要想办法把字符串拼接起来即可。由于是10年每年 8 个月,所以外层循环套年份,内层套月份。
file1 = 'SURF_CLI_CHN_MUL_DAY_CES-TEM-12001-';
file2 = '.TXT';
year = {'2009','2010','2011','2012','2013','2014','2015','2016','2017','2018'};
month = {'03','04','05','06','07','08','09','10'}; %``
真正重要的就是这部分,因为外层年份用元胞数组{j}获取内层月份用{i}表示,

这样就阔以了,先拼出字符串好让textread能找到,我也尝试过用fid和fopen但是这样出现的数据是大元胞,又得继续重新构造数据,于是在小体量数据下还是用了textread,如果是像我之前打建模的时候 104w 条数据还是建议用fid,fopen。
整体的思路就是先找到站点,然后拿出温度所在的列,就是第 8 列,如果是 3 月份取后面的 25 天,如果是 10 月就 6 天,然后是找到大于 10 ℃ 10℃ 10℃ 的位置,由于数据是以 0.1 ℃ 0.1℃ 0.1℃ 为单位,所以这里大于等于 100 100 100 ,然后把所有的数据给并起来,最后得到一个总和就是这个年份的积温,其他 6 个站点也是同理,外层大循环就得到 10 年的数据。由于最后做总和的时候会有一个累加的过程,所以需要差分以及取出第一个数据,就需要差分拼接合成最后一个矩阵。

最后一个xlswrite把它写到excel表里去,因为实在是不想自己加搜索路径,不如让系统自动帮我把绝对路径的前面部分自己找出来了。
![]()
这是最后运行的时间,比excel繁杂的操作快多了。

这个是后来加了range部分的结果,然后自己改一改excel就ok了
这个就是最后的结果,然后和站点的坐标数据放一起然后便于导入Arcmap,导入的最后结果咯。
然而之前把属性数据忘记放进去了直接导入了,就不想管了就这样把。
感谢我2点时Mind Palace的运动让我失眠到5点,昨天差点猝死。
最后,我将在另外一个账号写博客,有兴趣的可以关注。
