CUDA编程-05:流和事件
CUDA流
在CUDA中有两个级别的并发:内核级并发和网格级并发。前面的文章介绍的是内核级并发,这种并发方式是通过数据并行的方式用多个GPU线程去并发地完成一个内核任务,而网格级并发则是把一个任务分解为多个内核任务,通过在一个设备上并发地运行多个内核任务来实现任务的并发执行,这种方式使得设备的利用率更高。CUDA流是一系列异步操作的集合,同一个CUDA流中的操作严格按照顺序在GPU上运行,使用多个流同时启动多个内核任务就可以实现网格级并发。
首先来回顾一下一个典型的CUDA程序的执行流程:
- 将数据从
host拷贝到device上; - 在
device上执行内核任务; - 将数据从
device上拷贝到host上。
这些操作都会在一个CUDA流中运行,如果显式地创建一个流那么这个流就是显式流(非空流)否则就是隐式流(空流),前面文章介绍的CUDA例程都是在隐式流中运行的。如果显式地创建多个流分别去执行上述3个操作步骤,那么不同的CUDA操作是可以重叠进行的,参考下图:
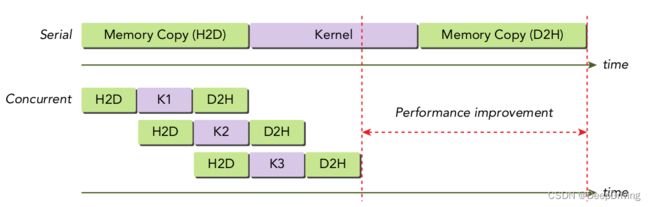
可以看到,使用多个流可以提升整个CUDA程序的运行效率。使用下面的方法可以声明和创建一个显式流:
cudaStream_t stream;
cudaStreamCreate(&stream);
要销毁一个流则可以使用下面的函数
cudaError_t cudaStreamDestroy(cudaStream_t stream);
由于显式流中的操作必须是异步的,而使用cudaMemcpy函数来拷贝数据是一种同步操作,所以必须使用它的异步版本才能在显式流中进行数据拷贝
cudaError_t cudaMemcpyAsync(void* dst, const void* src, size_t count, cudaMemcpyKind kind, cudaStream_t stream = 0);
这个函数的最后一个参数用于指定一个流标识符,默认情况下会使用空流。要执行异步的数据传输,那么就必须在host上使用固定内存,因为这样才能确保其在CPU内存中的物理地址在应用程序的整个生命周期内都不会被改变。可以使用下面的两个函数在host上分配固定内存:
cudaError_t cudaMallocHost(void **ptr, size_t size);
cudaError_t cudaHostAlloc(void **pHost, size_t size, unsigned int flags);
在非空流中启动内核的时候,必须在内核执行配置中提供一个流标识符作为第4个参数(第3个参数为共享内存的大小,如果没有分配可以设置为0):
kernel_name<<>>(...);
显式流的所有操作都是异步的,可以在host代码中调用下面两个函数去检查流中的所有操作是否完成:
cudaError_t cudaStreamSynchronize(cudaStream_t stream);
cudaError_t cudaStreamQuery(cudaStream_t stream);
cudaStreamSynchronize函数会强制阻塞host直到指定流中的所有操作都已经执行完成;cudaStreamQuery函数则不会阻塞host,如果指定流中的所有操作都已完成,它会返回cudaSuccess,否则返回cudaErrorNotReady。
CUDA事件
一个CUDA事件是CUDA流中的一个标记点,它可以用来检查正在执行的流操作是否已经到达了该点。使用事件可以用来执行以下两个基本任务:
- 同步流的执行操作
- 监控
device的进展
CUDA提供了在流中的任意点插入并查询事件完成情况的函数,只有当流中先前的所有操作都执行结束后,记录在该流中的事件才会起作用。
声明和创建一个事件的方式如下:
cudaEvent_t event;
cudaError_t cudaEventCreate(cudaEvent_t* event);
调用下面的函数可以销毁一个事件
cudaError_t cudaEventDestroy(cudaEvent_t event);
一个事件可以使用如下函数进入CUDA流的操作队列中
cudaError_t cudaEventRecord(cudaEvent_t event, cudaStream_t stream = 0);
下面的函数会在host中阻塞式地等待一个事件完成
cudaError_t cudaEventSynchronize(cudaEvent_t event);
与流类似的,也可以非阻塞式地去查询事件的完成情况
cudaError_t cudaEventQuery(cudaEvent_t event);
如果想知道两个事件之间的操作所耗费的时间,可以调用
cudaError_t cudaEventElapsedTime(float* ms, cudaEvent_t start, cudaEvent_t stop);
这个函数以毫秒为单位返回开始和停止两个事件之间的运行时间,启动和停止事件不必在同一个CUDA流中。
可以参考以下代码:
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
VectorAddGPU<<>>(da, db, dc, size);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float elapsed_time;
cudaEventElapsedTime(&elapsed_time, start, stop);
std::cout << "Elapsed time: " << elapsed_time << " ms." << std::endl;
cudaEventDestroy(start);
cudaEventDestroy(stop);
流同步
CUDA包括两种类型的host-device同步:显示同步和隐式同步。
前面文章中介绍过的很多函数都是隐式同步的,比如cudaMemcpy函数,它会使得host应用程序在数据传输完成之前都会被阻塞。许多与内存相关的操作都带有隐式同步行为,比如:
host上的固定内存分配,比如cudaMallocHostdevice上的内存分配,比如cudaMallocdevice上的内存初始化- 同一
device上两个地址之间的内存拷贝 - 一级缓存/共享内存配置的修改
CUDA提供了几种显示同步的方法:
- 使用
cudaDeviceSynchronize函数同步device - 使用
cudaStreamSynchronize函数同步流 - 使用
cudaEventSynchronize函数同步流中的事件
除此之外,CUDA还提供了下面的函数使用事件进行跨流同步:
cudaError_t cudaStreamWaitEvent(cudaStream_t stream, cudaEvent_t event);
该函数可以使指定的流等待指定的事件,该事件可能与同一个流相关,也可能与不同的流相关,如果是不同的流那么这个函数就是执行跨流同步功能。
参考资料
- 《
CUDA C 编程权威指南》 - 《
Professional CUDA C Programming》 - 《
CUDA C Programming Guide》 - 《
CUDA Programming:A Developer's Guide to Parallel Computing with GPUs》