双向LSTM 对航空乘客预测
前言
1.LSTM 航空乘客预测 单步预测和多步预测。 简单运用LSTM 模型进行预测分析。
2.加入注意力机制的LSTM 对航空乘客预测采用了目前市面上比较流行的注意力机制,将两者进行结合预测。
3.多层 LSTM 对航空乘客预测 简单运用多层的LSTM 模型进行预测分析。
本文采用双向LSTM网络对其进行预测。
我喜欢直接代码+ 结果展示
先代码可以跑通,才值得深入研究每个部分之间的关系;进而改造成自己可用的数据。
1 数据集
链接: https://pan.baidu.com/s/1jv7A2JvIhA6oqvtYnYh9vQ
提取码: m5j5
2 模型
双向LSTM是传统LSTM的扩展,在输入序列的所有时间步长可用的问题中,双向LSTM在输入序列上训练两个而不是一个LSTM。
输入序列中的第一个是原样的,第二个是输入序列的反转副本。这可以为网络提供额外的上下文,并导致更快,甚至更充分的学习问题
2.1 单步预测 1—》1
- 代码
# 单变量,1---》1
import numpy
import matplotlib.pyplot as plt
from pandas import read_csv
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Bidirectional
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
#matplotlib inline
# load the dataset
dataframe = read_csv('airline-passengers.csv', usecols=[1], engine='python')
# print(dataframe)
print("数据集的长度:",len(dataframe))
dataset = dataframe.values
# 将整型变为float
dataset = dataset.astype('float32')
plt.plot(dataset)
plt.show()
# X是给定时间(t)的乘客人数,Y是下一次(t + 1)的乘客人数。
# 将值数组转换为数据集矩阵,look_back是步长。
def create_dataset(dataset, look_back=1):
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back), 0]
# X按照顺序取值
dataX.append(a)
# Y向后移动一位取值
dataY.append(dataset[i + look_back, 0])
return numpy.array(dataX), numpy.array(dataY)
# fix random seed for reproducibility
numpy.random.seed(7)
# 数据缩放
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
# 将数据拆分成训练和测试,2/3作为训练数据
train_size = int(len(dataset) * 0.67)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]
print("原始训练集的长度:",train_size)
print("原始测试集的长度:",test_size)
# 构建监督学习型数据
look_back = 1
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
print("转为监督学习,训练集数据长度:", len(trainX))
# print(trainX,trainY)
print("转为监督学习,测试集数据长度:",len(testX))
# print(testX, testY )
# 数据重构为3D [samples, time steps, features]
trainX = numpy.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = numpy.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
print('构造得到模型的输入数据(训练数据已有标签trainY): ',trainX.shape,testX.shape)
# create and fit the LSTM network
model = Sequential()
model.add(Bidirectional(LSTM(4, input_shape=(1, look_back))))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
# 打印模型
model.summary()
# 开始预测
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
# 逆缩放预测值
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY])
# 计算误差
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
# shift train predictions for plotting
trainPredictPlot = numpy.empty_like(dataset)
trainPredictPlot[:, :] = numpy.nan
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
# shift test predictions for plotting
testPredictPlot = numpy.empty_like(dataset)
testPredictPlot[:, :] = numpy.nan
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict
# plot baseline and predictions
plt.plot(scaler.inverse_transform(dataset))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()
- 结果
Train Score: 22.97 RMSE
Test Score: 48.23 RMSE
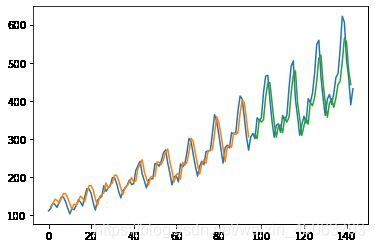
- 预测下一个月的数据
# 预测未来的数据
#测试数据的最后一个数据没有预测,这里补上
finalX = numpy.reshape(test[-1:], (1, testX.shape[1], 1))
print(finalX)
#预测得到标准化数据
featruePredict = model.predict(finalX)
#将标准化数据转换为人数
featruePredict = scaler.inverse_transform(featruePredict)
#原始数据是1949-1960年的数据,下一个月是1961年1月份
print('模型预测1961年1月份的国际航班人数是: ',featruePredict)
结果展示:
模型预测1961年1月份的国际航班人数是: [[418.70108]]
2.2 单步预测 3—》1
- 代码
# 单变量,3---》1
import numpy
import matplotlib.pyplot as plt
from pandas import read_csv
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Bidirectional
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
#matplotlib inline
# load the dataset
dataframe = read_csv('airline-passengers.csv', usecols=[1], engine='python')
# print(dataframe)
print("数据集的长度:",len(dataframe))
dataset = dataframe.values
# 将整型变为float
dataset = dataset.astype('float32')
plt.plot(dataset)
plt.show()
# X是给定时间(t)的乘客人数,Y是下一次(t + 1)的乘客人数。
# 将值数组转换为数据集矩阵,look_back是步长。
def create_dataset(dataset, look_back=1):
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back), 0]
# X按照顺序取值
dataX.append(a)
# Y向后移动一位取值
dataY.append(dataset[i + look_back, 0])
return numpy.array(dataX), numpy.array(dataY)
# fix random seed for reproducibility
numpy.random.seed(7)
# 数据缩放
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
# 将数据拆分成训练和测试,2/3作为训练数据
train_size = int(len(dataset) * 0.67)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]
print("原始训练集的长度:",train_size)
print("原始测试集的长度:",test_size)
# 构建监督学习型数据
look_back = 3
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
print("转为监督学习,训练集数据长度:", len(trainX))
# print(trainX,trainY)
print("转为监督学习,测试集数据长度:",len(testX))
# print(testX, testY )
# 数据重构为3D [samples, time steps, features]
# trainX = numpy.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
# testX = numpy.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
trainX = numpy.reshape(trainX, (trainX.shape[0], trainX.shape[1],1))
testX = numpy.reshape(testX, (testX.shape[0], testX.shape[1], 1))
print('构造得到模型的输入数据(训练数据已有标签trainY): ',trainX.shape,testX.shape)
# create and fit the LSTM network
model = Sequential()
# model.add(LSTM(4, input_shape=(1, look_back)))
model.add(Bidirectional(LSTM(4, input_shape=( look_back,1)))) # 与上面的重构格式对应,要改都改,才能跑通代码
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
# 打印模型
model.summary()
# 开始预测
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
# 逆缩放预测值
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY])
# 计算误差
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
# shift train predictions for plotting
trainPredictPlot = numpy.empty_like(dataset)
trainPredictPlot[:, :] = numpy.nan
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
# shift test predictions for plotting
testPredictPlot = numpy.empty_like(dataset)
testPredictPlot[:, :] = numpy.nan
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict
# plot baseline and predictions
plt.plot(scaler.inverse_transform(dataset))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()
- 结果展示
Train Score: 23.13 RMSE
Test Score: 88.55 RMSE

- 预测下一个月的数据
# 预测未来的数据
#测试数据的最后一个数据没有预测,这里补上
finalX = numpy.reshape(test[-3:], (1, testX.shape[1], 1))
print(finalX)
#预测得到标准化数据
featruePredict = model.predict(finalX)
#将标准化数据转换为人数
featruePredict = scaler.inverse_transform(featruePredict)
#原始数据是1949-1960年的数据,下一个月是1961年1月份
print('模型预测1961年1月份的国际航班人数是: ',featruePredict)
结果展示:
模型预测1961年1月份的国际航班人数是: [[337.3761]]
3 总结
- 双向LSTM的预测效果在一些情况下,确实比单向LSTM的好,要具体看什么数据,什么情况下
- 对LSTM网络的进一步扩充,就代码内部来看,改变了LSTM的输入格式