Chapter 3 - Functional Components of Azure RTOS ThreadX-Azure RTOS ThreadX的功能组件
[译]:Chapter 3 - Functional Components of Azure RTOS ThreadX | Microsoft Docs
This chapter contains a description of the high-performance Azure RTOS ThreadX kernel from a functional perspective. Each functional component is presented in an easy-to-understand manner.
本章从功能的角度对高性能azurertos ThreadX内核进行了描述。每个功能组件都以易于理解的方式呈现。
Execution Overview
There are four types of program execution within a ThreadX application: Initialization, Thread Execution, Interrupt Service Routines (ISRs), and Application Timers.
Figure 2 shows each different type of program execution. More detailed information about each of these types is found in subsequent sections of this chapter.
执行概述
ThreadX应用程序中有四种类型的程序执行:初始化、线程执行、中断服务例程(isr)和应用程序计时器。
图2显示了每种不同类型的程序执行。有关每种类型的详细信息,请参阅本章后续章节。
Initialization
As the name implies, this is the first type of program execution in a ThreadX application. Initialization includes all program execution between processor reset and the entry point of the thread scheduling loop.
初始化
顾名思义,这是ThreadX应用程序中的第一种程序执行类型。初始化包括处理器重置和线程调度循环入口点之间的所有程序执行。
Thread Execution
After initialization is complete, ThreadX enters its thread scheduling loop. The scheduling loop looks for an application thread ready for execution. When a ready thread is found, ThreadX transfers control to it. After the thread is finished (or another higher-priority thread becomes ready), execution transfers back to the thread scheduling loop to find the next highest priority ready thread.
This process of continually executing and scheduling threads is the most common type of program execution in ThreadX applications.
线程执行
初始化完成后,ThreadX进入其线程调度循环。调度循环查找准备执行的应用程序线程。当找到一个就绪线程时,ThreadX将控制权转移给它。线程完成后(或者另一个优先级更高的线程准备就绪),执行转移回线程调度循环,以找到下一个优先级最高的就绪线程。
这种连续执行和调度线程的过程是ThreadX应用程序中最常见的程序执行类型。
Interrupt Service Routines (ISR)
Interrupts are the cornerstone of real-time systems. Without interrupts it would be extremely difficult to respond to changes in the external world in a timely manner. On detection of an interrupt, the processor saves key information about the current program execution (usually on the stack), then transfers control to a predefined program area. This predefined program area is commonly called an Interrupt Service Routine. In most cases, interrupts occur during thread execution (or in the thread scheduling loop).
However, interrupts may also occur inside of an executing ISR or an Application Timer.
中断服务程序(ISR)
中断是实时系统的基石。如果没有中断,就很难及时应对外部世界的变化。在检测到中断时,处理器保存有关当前程序执行的关键信息(通常在堆栈上),然后将控制转移到预定义的程序区域。这个预定义的程序区域通常称为中断服务例程。在大多数情况下,中断发生在线程执行期间(或在线程调度循环中)。但是,中断也可能发生在正在执行的ISR或应用程序计时器内部。
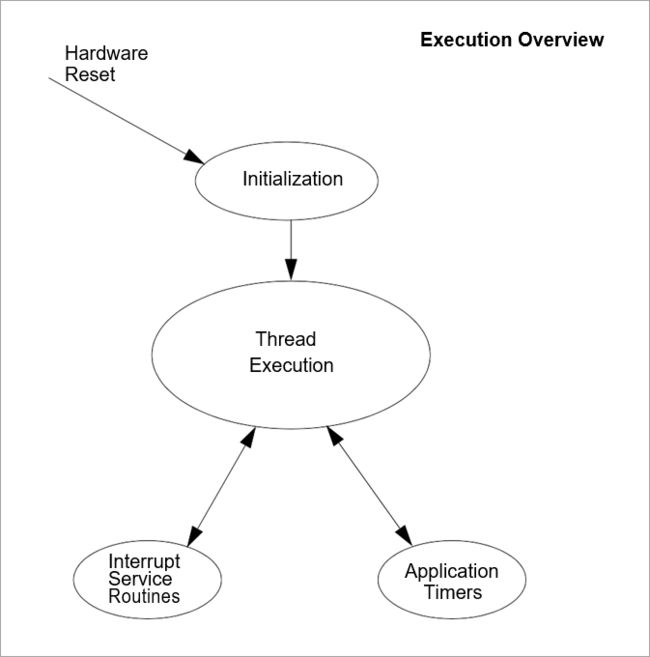
FIGURE 2. Types of Program Execution
Application Timers
Application Timers are similar to ISRs, except the hardware implementation (usually a single periodic hardware interrupt is used) is hidden from the application. Such timers are used by applications to perform time-outs, periodics, and/or watchdog services. Just like ISRs, Application Timers most often interrupt thread execution. Unlike ISRs, however, Application Timers cannot interrupt each other.
应用程序计时器
应用程序计时器与isr类似,只是对应用程序隐藏了硬件实现(通常使用单个周期性硬件中断)。这些计时器被应用程序用来执行超时、周期和/或看门狗服务。就像isr一样,应用程序计时器经常中断线程执行。但是,与isr不同的是,应用程序计时器不能相互中断。
Memory Usage
ThreadX resides along with the application program. As a result, the static memory (or fixed memory) usage of ThreadX is determined by the development tools; e.g., the compiler, linker, and locator. Dynamic memory (or run-time memory) usage is under direct control of the application.
内存使用
ThreadX与应用程序一起驻留。因此,ThreadX的静态内存(或固定内存)使用由开发工具决定,例如编译器、链接器和定位器。动态内存(或运行时内存)的使用由应用程序直接控制。
Static Memory Usage
Most of the development tools divide the application program image into five basic areas: instruction, constant, initialized data, uninitialized data, and system stack. Figure 3 shows an example of these memory areas.
It is important to understand that this is only an example. The actual static memory layout is specific to the processor, development tools, and the underlying hardware.
The instruction area contains all of the program's processor instructions. This area is typically the largest and is often located in ROM.
The constant area contains various compiled constants, including strings defined or referenced within the program. In addition, this area contains the "initial copy" of the initialized data area. During the Memory Usage compiler's initialization process, this portion of the constant area is used to set up the initialized data area in RAM. The constant area usually follows the instruction area and is often located in ROM.
The initialized data and uninitialized data areas contain all of the global and static variables. These areas are always located in RAM.
The system stack is generally set up immediately following the initialized and uninitialized data areas.
The system stack is used by the compiler during initialization, then by ThreadX during initialization and, subsequently, in ISR processing.
静态内存使用
大多数开发工具将应用程序映像划分为五个基本区域:指令、常量、初始化数据、未初始化数据和系统堆栈。图3显示了这些内存区域的一个示例。
重要的是要明白这只是一个例子。实际的静态内存布局是特定于处理器、开发工具和底层硬件的。
指令区包含程序的所有处理器指令。这个区域通常是最大的,通常位于ROM中。
常量区域包含各种编译的常量,包括在程序中定义或引用的字符串。此外,此区域包含初始化数据区域的“初始副本”。在内存使用编译器的初始化过程中,这部分常量区域用于在RAM中设置初始化的数据区域。常量区域通常位于指令区域之后,并且通常位于ROM中。
初始化数据和未初始化数据区域包含所有全局变量和静态变量。这些区域始终位于RAM中。
系统堆栈通常紧跟在初始化和未初始化的数据区域之后设置。
系统堆栈在初始化期间由编译器使用,然后在初始化期间由ThreadX使用,随后在ISR处理中使用。

FIGURE 3. Memory Area Example
Dynamic Memory Usage
As mentioned before, dynamic memory usage is under direct control of the application. Control blocks and memory areas associated with stacks, queues, and memory pools can be placed anywhere in the target's memory space. This is an important feature because it facilitates easy utilization of different types of physical memory.
For example, suppose a target hardware environment has both fast memory and slow memory. If the application needs extra performance for a high-priority thread, its control block (TX_THREAD) and stack can be placed in the fast memory area, which may greatly enhance its performance.
动态内存使用
如前所述,动态内存使用由应用程序直接控制。与堆栈、队列和内存池相关联的控制块和内存区域可以放置在目标内存空间的任何位置。这是一个重要的特性,因为它有助于轻松利用不同类型的物理内存。
例如,假设目标硬件环境既有快内存又有慢内存。如果应用程序需要高优先级线程的额外性能,则可以将其控制块(TX\u线程)和堆栈放置在快速内存区中,这可以极大地提高其性能。
Initialization
Understanding the initialization process is important. The initial hardware environment is set up here. In addition, this is where the application is given its initial personality.
备注
ThreadX attempts to utilize (whenever possible) the complete development tool's initialization process. This makes it easier to upgrade to new versions of the development tools in the future.
初始化
了解初始化过程很重要。初始硬件环境设置在这里。此外,这也是应用程序被赋予其初始个性化的地方。
备注
ThreadX试图利用(只要可能)整个开发工具的初始化过程。这使得将来更容易升级到新版本的开发工具。?
System Reset Vector
All microprocessors have reset logic. When a reset occurs (either hardware or software), the address of the application's entry point is retrieved from a specific memory location. After the entry point is retrieved, the processor transfers control to that location. The application entry point is quite often written in the native assembly language and is usually supplied by the development tools (at least in template form). In some cases, a special version of the entry program is supplied with ThreadX.
系统复位Vector
所有微处理器都有复位逻辑。当发生重置(硬件或软件)时,将从特定内存位置检索应用程序入口点的地址。在检索到入口点之后,处理器将控制权转移到该位置。应用程序入口点通常是用本机汇编语言编写的,并且通常由开发工具提供(至少以模板形式提供)。在某些情况下,ThreadX提供了entry程序的特殊版本。
Development Tool Initialization
After the low-level initialization is complete, control transfers to the development tool's high-level initialization. This is usually the place where initialized global and static C variables are set up. Remember their initial values are retrieved from the constant area. Exact initialization processing is development tool specific.
开发工具初始化
低级初始化完成后,控制转移到开发工具的高级初始化。这通常是设置初始化的全局和静态C变量的地方。记住,它们的初始值是从常量区域中获取的。精确的初始化处理是特定于开发工具的。
main Function
When the development tool initialization is complete, control transfers to the user-supplied main function. At this point, the application controls what happens next. For most applications, the main function simply calls tx_kernel_enter, which is the entry into ThreadX. However, applications can perform preliminary processing (usually for hardware initialization) prior to entering ThreadX.
重要
The call to tx_kernel_enter does not return, so do not place any processing after it.
主要功能
当开发工具初始化完成时,控制转移到用户提供的主功能。此时,应用程序控制接下来发生的事情。对于大多数应用程序,main函数只是调用tx_kernel_enter,这是ThreadX的入口。但是,应用程序可以在进入ThreadX之前执行初步处理(通常用于硬件初始化)。
重要
对tx_kernel_enter的调用不会返回,因此不要在它之后进行任何处理。
tx_kernel_enter
The entry function coordinates initialization of various internal ThreadX data structures and then calls the application's definition function tx_application_define.
When tx_application_define returns, control is transferred to the thread scheduling loop. This marks the end of initialization.
tx_kernel_enter
entry函数协调各种内部ThreadX数据结构的初始化,然后调用应用程序的定义函数tx_application_define。
当tx_application_define返回时,控制权被转移到线程调度循环。这标志着初始化的结束。
Application Definition Function
The tx_application_define function defines all of the initial application threads, queues, semaphores, mutexes, event flags, memory pools, and timers. It is also possible to create and delete system resources from threads during the normal operation of the application. However, all initial application resources are defined here.
The tx_application_define function has a single input parameter and it is certainly worth mentioning. The first-available RAM address is the sole input parameter to this function. It is typically used as a starting point for initial run-time memory allocations of thread stacks, queues, and memory pools.
备注
After initialization is complete, only an executing thread can create and delete system resources— including other threads. Therefore, at least one thread must be created during initialization.
应用程序定义函数
tx_application_define 函数定义所有初始应用程序线程、队列、信号量、互斥锁、事件标志、内存池和计时器。在应用程序的正常操作期间,还可以从线程中创建和删除系统资源。但是,这里定义了所有初始应用程序资源。
tx_application_define 函数只有一个输入参数,当然值得一提。第一个可用的RAM地址是这个函数的唯一输入参数。它通常用作线程堆栈、队列和内存池的初始运行时内存分配的起点。
备注
初始化完成后,只有执行线程才能创建和删除系统资源-包括其他线程。因此,在初始化期间必须至少创建一个线程。
Interrupts
Interrupts are left disabled during the entire initialization process. If the application somehow enables interrupts, unpredictable behavior may occur. Figure 4 shows the entire initialization process, from system reset through application-specific initialization.
中断
在整个初始化过程中,中断处于禁用状态。如果应用程序以某种方式启用中断,则可能会发生不可预知的行为。图4显示了整个初始化过程,从系统重置到特定于应用程序的初始化。
Thread Execution
Scheduling and executing application threads is the most important activity of ThreadX. A thread is typically defined as a semi-independent program segment with a dedicated purpose. The combined processing of all threads makes an application.
Threads are created dynamically by calling tx_thread_create during initialization or during thread execution. Threads are created in either a ready or suspended state.
线程执行
调度和执行应用程序线程是ThreadX最重要的活动。线程通常被定义为具有特定用途的半独立程序段。所有线程的联合处理构成了一个应用程序。
线程是在初始化或线程执行期间通过调用tx_thread_create动态创建的。线程是创建后工作在就绪或挂起状态下。

FIGURE 4. Initialization Process
Thread Execution States
Understanding the different processing states of threads is a key ingredient to understanding the entire multithreaded environment. In ThreadX there are five distinct thread states: ready, suspended, executing, terminated, and completed. Figure 5 shows the thread state transition diagram for ThreadX.
线程执行状态
理解线程的不同处理状态是理解整个多线程环境的关键因素。在ThreadX中有五种不同的线程状态:ready、suspended、executing、terminated和completed。图5显示了ThreadX的线程状态转换图。

FIGURE 5. Thread State Transition
A thread is in a ready state when it is ready for execution. A ready thread is not executed until it is the highest priority thread in ready state. When this happens, ThreadX executes the thread, which then changes its state to executing.
If a higher-priority thread becomes ready, the executing thread reverts back to a ready state. The newly ready high-priority thread is then executed, which changes its logical state to executing. This transition between ready and executing states occurs every time thread preemption occurs.
At any given moment, only one thread is in an executing state. This is because a thread in the executing state has control of the underlying processor.
Threads in a suspended state are not eligible for execution. Reasons for being in a suspended state include suspension for time, queue messages, semaphores, mutexes, event flags, memory, and basic thread suspension. After the cause for suspension is removed, the thread is placed back in a ready state.
A thread in a completed state is a thread that has completed its processing and returned from its entry function. The entry function is specified during thread creation. A thread in a completed state cannot execute again.
A thread is in a terminated state because another thread or the thread itself called the tx_thread_terminate service. A thread in a terminated state cannot execute again.
重要
If re-starting a completed or terminated thread is desired, the application must first delete the thread. It can then be re-created and re-started.
线程准备好执行时处于就绪状态。就绪线程只有在它是处于就绪状态的最高优先级线程时才会执行。当这种情况发生时,ThreadX执行线程,然后将其状态更改为executing。
如果更高优先级的线程准备就绪,则执行线程将恢复到就绪状态。然后执行新准备好的高优先级线程,将其逻辑状态更改为executing。每次发生线程抢占时,都会发生就绪状态和执行状态之间的转换。
在任何给定时刻,只有一个线程处于执行状态。这是因为处于执行状态的线程可以控制底层处理器。
处于挂起状态的线程不能执行。处于暂停状态的原因包括暂停时间、队列消息、信号量、互斥锁、事件标志、内存和基本线程暂停。在消除挂起原因后,线程将重新置于就绪状态。
处于完成状态的线程是一个线程,它已经完成了处理并从其入口函数返回。在线程创建期间指定了entry函数。处于完成状态的线程无法再次执行。
线程处于终止状态,可能是因为另一个线程或线程本身被tx_thread_terminate服务调用。处于终止状态的线程无法再次执行。
重要
如果需要重新启动已完成或终止的线程,应用程序必须首先删除该线程。然后,可以重新创建并重新启动它。
Thread Entry/Exit Notification
Some applications may find it advantageous to be notified when a specific thread is entered for the first time, when it completes, or is terminated. ThreadX provides this ability through the tx_thread_entry_exit_notify service. This service registers an application notification function for a specific thread, which is called by ThreadX whenever the thread starts running, completes, or is terminated. After being invoked, the application notification function can perform the application-specific processing. This typically involves informing another application thread of the event via a ThreadX synchronization primitive.
线程输入/退出通知
有些应用程序可能会发现,当特定线程第一次进入工作、完成或终止时通知它是有好处的。ThreadX通过tx_thread_entry_exit_notify 服务提供了此功能。此服务为特定线程注册应用程序通知函数,每当线程开始运行、完成或终止时,ThreadX都会调用该函数。调用后,应用程序通知函数可以执行特定于应用程序的处理。这通常发生在通过ThreadX同步原语通知另一个应用程序线程事件。
Thread Priorities
As mentioned before, a thread is a semi-independent program segment with a dedicated purpose. However, all threads are not created equal! The dedicated purpose of some threads is much more important than others. This heterogeneous type of thread importance is a hallmark of embedded realtime applications.
ThreadX determines a thread's importance when the thread is created by assigning a numerical value representing its priority. The maximum number of ThreadX priorities is configurable from 32 through 1024 in increments of 32. The actual maximum number of priorities is determined by the TX_MAX_PRIORITIES constant during compilation of the ThreadX library. Having a larger number of priorities does not significantly increase processing overhead. However, for each group of 32 priority levels an additional 128 bytes of RAM is required to manage them. For example, 32 priority levels require 128 bytes of RAM, 64 priority levels require 256 bytes of RAM, and 96 priority levels requires 384 bytes of RAM.
By default, ThreadX has 32 priority levels, ranging from priority 0 through priority 31. Numerically smaller values imply higher priority. Hence, priority 0 represents the highest priority, while priority (TX_MAX_PRIORITIES-1) represents the lowest priority.
Multiple threads can have the same priority relying on cooperative scheduling or time-slicing. In addition, thread priorities can be changed during run-time.
线程优先级
如前所述,线程是一个具有特定用途的半独立程序段。但是,并不是所有的线程都是平等的!一些线程的专用性比其他线程更重要。这种异构类型的线程重要性是嵌入式实时应用程序的一个标志。
ThreadX通过指定一个表示线程优先级的数值来确定创建线程时线程的重要性。ThreadX优先级的最大数目可配置为从32到1024,增量为32。在ThreadX库的编译过程中,实际的最大优先级数由TX_MAX_PRIORITIES 常量确定。拥有更多的优先级不会显著增加处理开销。但是,对于32个优先级的每组,需要额外的128字节RAM来管理它们。例如,32个优先级需要128字节的RAM,64个优先级需要256字节的RAM,96个优先级需要384字节的RAM。
默认情况下,ThreadX有32个优先级,从优先级0到优先级31不等。数值越小表示优先级越高。因此,优先级0表示最高优先级,而优先级(TX_MAX_PRIORITIES -1)表示最低优先级。
依赖于协作调度或时间切片,多个线程可以具有相同的优先级。此外,线程优先级可以在运行时更改。
Thread Scheduling
ThreadX schedules threads based on their priority. The ready thread with the highest priority is executed first. If multiple threads of the same priority are ready, they are executed in a first-in-first-out (FIFO) manner.
线程调度
ThreadX根据线程的优先级来调度线程。具有最高优先级的就绪线程被首先执行。如果相同优先级的多个线程就绪,它们将以先进先出(FIFO)的方式执行。
Round-robin Scheduling
ThreadX supports round-robin scheduling of multiple threads having the same priority. This is accomplished through cooperative calls to tx_thread_relinquish. This service gives all other ready threads of the same priority a chance to execute before the tx_thread_relinquish caller executes again.
循环调度
ThreadX支持具有相同优先级的多个线程的循环调度。这是通过协作调用tx_thread_relinquish来实现的。在tx_thread_relinquish调用者再次执行之前,此服务为所有其他具有相同优先级的就绪线程提供执行的机会。
Time-Slicing
Time-slicing is another form of round-robin scheduling. A time-slice specifies the maximum number of timer ticks (timer interrupts) that a thread can execute without giving up the processor. In ThreadX, time-slicing is available on a per-thread basis. The thread's time-slice is assigned during creation and can be modified during run-time. When a time-slice expires, all other ready threads of the same priority level are given a chance to execute before the time-sliced thread executes again.
A fresh thread time-slice is given to a thread after it suspends, relinquishes, makes a ThreadX service call that causes preemption, or is itself time-sliced.
When a time-sliced thread is preempted, it will resume before other ready threads of equal priority for the remainder of its time-slice.
备注
Using time-slicing results in a slight amount of system overhead. Because time-slicing is only useful in cases in which multiple threads share the same priority, threads having a unique priority should not be assigned a time-slice.
时间切片
时间切片是循环调度的另一种形式。时间片指定线程在不放弃处理器的情况下可以执行的最大计时器计时次数(计时器中断)。在ThreadX中,时间切片是基于每个线程的。线程的时间片在创建期间分配,可以在运行时修改。当时间片过期时,所有其他具有相同优先级的就绪线程都有机会在时间片线程再次执行之前执行。
在线程挂起、放弃、发出导致抢占的ThreadX服务调用或线程本身被时间切片之后,会给线程一个新的线程时间切片。
当一个时间片线程被抢占时,它将先于其他具有同等优先级的就绪线程恢复执行其剩余时间片长。
备注
使用时间切片会导致少量的系统开销。因为时间切片只在多个线程共享相同优先级的情况下才有用,所以不应该为具有唯一优先级的线程分配时间切片。
Preemption
Preemption is the process of temporarily interrupting an executing thread in favor of a higher-priority thread. This process is invisible to the executing thread. When the higher-priority thread is finished, control is transferred back to the exact place where the preemption took place. This is a very important feature in real-time systems because it facilitates fast response to important application events. Although a very important feature, preemption can also be a source of a variety of problems, including starvation, excessive overhead, and priority inversion.
抢占
抢占是暂时中断正在执行的线程以支持更高优先级线程的过程。此进程对执行线程不可见。当高优先级线程完成时,控制权被转移回发生抢占的确切位置。这在实时系统中是一个非常重要的特性,因为它有助于快速响应重要的应用程序事件。尽管抢占是一个非常重要的特性,但它也可能导致各种问题,包括饥饿、开销过大和优先级反转。
Preemption Threshold™
To ease some of the inherent problems of preemption, ThreadX provides a unique and advanced feature called preemption-threshold.
A preemption-threshold allows a thread to specify a priority ceiling for disabling preemption. Threads that have higher priorities than the ceiling are still allowed to preempt, while those less than the ceiling are not allowed to preempt.
For example, suppose a thread of priority 20 only interacts with a group of threads that have priorities between 15 and 20. During its critical sections, the thread of priority 20 can set its preemption-threshold to 15, thereby preventing preemption from all of the threads that it interacts with. This still permits really important threads (priorities between 0 and 14) to preempt this thread during its critical section processing, which results in much more responsive processing.
Of course, it is still possible for a thread to disable all preemption by setting its preemption-threshold to 0. In addition, preemption-threshold can be changed during run-time.
备注
Using preemption-threshold disables time-slicing for the specified thread.
抢占阈值™
为了缓解抢占的一些固有问题,ThreadX提供了一个独特的高级特性,称为抢占阈值。
抢占阈值允许线程为禁用抢占指定优先级上限。优先级高于上限的线程仍允许抢占,而低于上限的线程则不允许抢占。
例如,假设优先级为20的线程只与优先级在15到20之间的一组线程交互。在其关键部分期间,优先级为20的线程可以将其抢占阈值设置为15,从而防止与之交互的所有线程抢占。这仍然允许真正重要的线程(优先级介于0和14之间)在其关键部分处理期间抢占该线程,从而导致响应性更强的处理。
当然,线程仍然可以通过将其抢占阈值设置为0来禁用所有抢占。此外,抢占阈值可以在运行时更改。
备注
使用抢占阈值将禁用指定线程的时间切片。
Priority Inheritance
ThreadX also supports optional priority inheritance within its mutex services described later in this chapter. Priority inheritance allows a lower priority thread to temporarily assume the priority of a high priority thread that is waiting for a mutex owned by the lower priority thread. This capability helps the application to avoid nondeterministic priority inversion by eliminating preemption of intermediate thread priorities. Of course, preemption-threshold may be used to achieve a similar result.
优先级继承
ThreadX还支持本章后面介绍的mutex服务中的可选优先级继承。优先级继承允许低优先级线程临时提升为高优先级线程的优先级,当那个高优先线程正在等待低优先级线程拥有的互斥锁。此功能通过消除中间线程优先级的抢占,帮助应用程序避免不确定的优先级反转。当然,抢占阈值也可以用来实现类似的结果。
Thread Creation
Application threads are created during initialization or during the execution of other application threads. There is no limit on the number of threads that can be created by an application.
线程创建
应用程序线程是在初始化或其他应用程序线程执行期间创建的。应用程序可以创建的线程数没有限制。
Thread Control Block TX_THREAD
The characteristics of each thread are contained in its control block. This structure is defined in the tx_api.h file.
A thread's control block can be located anywhere in memory, but it is most common to make the control block a global structure by defining it outside the scope of any function.
Locating the control block in other areas requires a bit more care, just like all dynamically-allocated memory. If a control block is allocated within a C function, the memory associated with it is part of the calling thread's stack. In general, avoid using local storage for control blocks because after the function returns, all of its local variable stack space is released—regardless of whether another thread is using it for a control block.
In most cases, the application is oblivious to the contents of the thread's control block. However, there are some situations, especially during debug, in which looking at certain members is useful. The following are some of the more useful control block members.
tx_thread_run_count contains a counter of the number of many times the thread has been scheduled. An increasing counter indicates the thread is being scheduled and executed.
tx_thread_state contains the state of the associated thread. The following lists the possible thread states.
线程控制块Thread Control Block TX_THREAD
每个线程的特性都包含在其控制块中。这个结构是在tx_api.h文件中定义的。
线程的控制块可以位于内存中的任何位置,但最常见的做法是在任何函数的作用域之外定义控制块,使其成为全局结构。
在其他区域中定位控制块需要更多的注意,就像所有动态分配的内存一样。如果在C函数中分配了控制块,那么与之相关联的内存就是调用线程堆栈的一部分。一般情况下,避免对控制块使用本地存储,因为在函数返回后,它的所有本地变量堆栈空间都将被释放,而不管其他线程是否把它当作控制块使用。
在大多数情况下,应用程序不关心线程控制块的内容。但是,在某些情况下,特别是在调试期间,查看某些成员是有用的。下面是一些更有用的控制块成员。
tx_thread_run_count 包含线程被调度的次数的计数器。递增的计数器表示线程正在被调度和执行。
tx_thread_state 包含关联线程的状态。下面列出了可能的线程状态。
| Thread state | Value |
|---|---|
| TX_READY | (0x00) |
| TX_COMPLETED | (0x01) |
| TX_TERMINATED | (0x02) |
| TX_SUSPENDED | (0x03) |
| TX_SLEEP | (0x04) |
| TX_QUEUE_SUSP | (0x05) |
| TX_SEMAPHORE_SUSP | (0x06) |
| TX_EVENT_FLAG | (0x07) |
| TX_BLOCK_MEMORY | (0x08) |
| TX_BYTE_MEMORY | (0x09) |
| TX_MUTEX_SUSP | (0x0D) |
备注
Of course there are many other interesting fields in the thread control block, including the stack pointer, time-slice value, priorities, etc. Users are welcome to review control block members, but modifications are strictly prohibited!
重要
There is no equate for the "executing" state mentioned earlier in this section. It is not necessary because there is only one executing thread at a given time. The state of an executing thread is also TX_READY.
备注
当然,线程控制块中还有许多其他有趣的字段,包括堆栈指针、时间片值、优先级等。欢迎用户查看控制块成员,但严禁修改!
重要
这里没有本节前面提到的“正在执行”状态没有等价值。这是不必要的,因为在给定的时间只有一个执行线程。执行线程的状态也是TX_READY。
Currently Executing Thread
As mentioned before, there is only one thread executing at any given time. There are several ways to identify the executing thread, depending on which thread is making the request. A program segment can get the control block address of the executing thread by calling tx_thread_identify. This is useful in shared portions of application code that are executed from multiple threads.
In debug sessions, users can examine the internal ThreadX pointer _tx_thread_current_ptr. It contains the control block address of the currently executing thread. If this pointer is NULL, no application thread is executing; i.e., ThreadX is waiting in its scheduling loop for a thread to become ready.
当前正在执行的线程
如前所述,在任何给定的时间只有一个线程在执行。有几种方法可以识别正在执行的线程,具体取决于发出请求的线程。程序段可以通过调用tx_thread_identify来获取执行线程的控制块地址。这对于从多个线程执行的应用程序代码的共享部分非常有用。
++在调试会话中,用户可以检查内部ThreadX指针_tx_thread_current_ptr。它包含当前正在执行的线程的控制块地址。如果该指针为空,则没有应用程序线程正在执行;即,ThreadX正在其调度循环中等待线程准备就绪。
Thread Stack Area
Each thread must have its own stack for saving the context of its last execution and compiler use. Most C compilers use the stack for making function calls and for temporarily allocating local variables. Figure 6 shows a typical thread's stack.
Where a thread stack is located in memory is up to the application. The stack area is specified during thread creation and can be located anywhere in the target's address space. This is an important feature because it allows applications to improve performance of important threads by placing their stack in high-speed RAM.
线程堆栈区域
每个线程都必须有自己的堆栈,以便保存上次执行和编译器使用的上下文。大多数C编译器使用堆栈进行函数调用和临时分配局部变量。图6显示了一个典型线程的堆栈。
线程堆栈在内存中的位置由应用程序决定。堆栈区域是在线程创建期间指定的,可以位于目标地址空间中的任何位置。这是一个重要的特性,因为它允许应用程序通过将堆栈放置在高速RAM中来提高重要线程的性能。
Stack Memory Area (example)

FIGURE 6. Typical Thread Stack
How big a stack should be is one of the most frequently asked questions about threads. A thread's stack area must be large enough to accommodate worst-case function call nesting, local variable allocation, and saving its last execution context.
The minimum stack size, TX_MINIMUM_STACK, is defined by ThreadX. A stack of this size supports saving a thread's context and minimum amount of function calls and local variable allocation.
For most threads, however, the minimum stack size is too small, and the user must ascertain the worst-case size requirement by examining function-call nesting and local variable allocation. Of course, it is always better to start with a larger stack area.
After the application is debugged, it is possible to tune the thread stack sizes if memory is scarce. A favorite trick is to preset all stack areas with an easily identifiable data pattern like (0xEFEF) prior to creating the threads. After the application has been thoroughly put through its paces, the stack areas can be examined to see how much stack was actually used by finding the area of the stack where the data pattern is still intact. Figure 7 shows a stack preset to 0xEFEF after thorough thread execution.
堆栈应该有多大是关于线程的最常见问题之一。线程的堆栈区域必须足够大,以容纳最坏情况下的函数调用嵌套、局部变量分配和保存最后一次执行上下文。
最小堆栈大小TX_MINIMUM_STACK由ThreadX定义。这种大小的堆栈支持保存线程的上下文、最小数量的函数调用和局部变量分配。
但是,对于大多数线程,最小堆栈大小太小,用户必须通过检查函数调用嵌套和局部变量分配来确定最坏情况下的大小要求。当然,最好从更大的堆栈区域开始。
调试应用程序后,如果内存不足,可以调整线程堆栈的大小。最常用的技巧是在创建线程之前,用一个易于识别的数据模式(如(0xefefef))预置所有堆栈区域。在应用程序彻底完成其工作后,可以通过查找数据模式仍然完整的堆栈区域来检查堆栈区域,以查看实际使用了多少堆栈。图7显示了在彻底执行线程后将堆栈预设为0xefefef。
Stack Memory Area (another example)

FIGURE 7. Stack Preset to 0xEFEF
重要
By default, ThreadX initializes every byte of each thread stack with a value of 0xEF.
重要
默认情况下,ThreadX使用0xEF值初始化每个线程堆栈的每个字节。
Memory Pitfalls
The stack requirements for threads can be large. Therefore, it is important to design the application to have a reasonable number of threads. Furthermore, some care must be taken to avoid excessive stack usage within threads. Recursive algorithms and large local data structures should be avoided.
In most cases, an overflowed stack causes thread execution to corrupt memory adjacent (usually before) its stack area. The results are unpredictable, but most often result in an unnatural change in the program counter. This is often called "jumping into the weeds." Of course, the only way to prevent this is to ensure all thread stacks are large enough.
内存陷阱
线程的堆栈要求可能很大。因此,重要的是要设计应用程序有一个合理的线程数。此外,必须注意避免在线程中过度使用堆栈。应避免递归算法和大型局部数据结构。
在大多数情况下,溢出的堆栈会导致线程执行损坏其堆栈区域附近(通常在堆栈区域之前)的内存。结果是不可预测的,但大多数情况下会导致程序计数器发生不自然的变化。这通常被称为“跳入杂草中”。当然,防止这种情况的唯一方法是确保所有线程堆栈都足够大。
Optional Run-time Stack Checking
ThreadX provides the ability to check each thread's stack for corruption during run-time. By default, ThreadX fills every byte of thread stacks with a 0xEF data pattern during creation. If the application builds the ThreadX library with TX_ENABLE_STACK_CHECKING defined, ThreadX will examine each thread's stack for corruption as it is suspended or resumed. If stack corruption is detected, ThreadX will call the application's stack error handling routine as specified by the call to tx_thread_stack_error_notify. Otherwise, if no stack error handler was specified, ThreadX will call the internal _tx_thread_stack_error_handler routine.
可选运行时堆栈检查
ThreadX提供了在运行时检查每个线程堆栈是否损坏的功能。默认情况下,ThreadX在创建期间用0xEF数据模式填充线程堆栈的每个字节。如果应用程序在构建ThreadX库时定义了TX_ENABLE_STACK_CHECKING ,那么ThreadX将在挂起或恢复每个线程的堆栈时检查其是否损坏。如果检测到堆栈损坏,ThreadX将调用tx_thread_stack_error_notify调用指定的应用程序堆栈错误处理例程。否则,如果没有指定堆栈错误处理程序,ThreadX将调用内部的_tx_thread_stack_error_handler处理程序例程。
Reentrancy
One of the real beauties of multithreading is that the same C function can be called from multiple threads. This provides great power and also helps reduce code space. However, it does require that C functions called from multiple threads are reentrant.
Basically, a reentrant function stores the caller's return address on the current stack and does not rely on global or static C variables that it previously set up. Most compilers place the return address on the stack. Hence, application developers must only worry about the use of globals and statics.
An example of a non-reentrant function is the string token function strtok found in the standard C library. This function "remembers" the previous string pointer on subsequent calls. It does this with a static string pointer. If this function is called from multiple threads, it would most likely return an invalid pointer.
可重入
多线程处理的真正优点之一是可以从多个线程调用同一个C函数。这提供了强大的功能,也有助于减少代码空间。但是,它确实要求从多个线程调用的C函数是可重入的。
基本上,可重入函数将调用方的返回地址存储在当前堆栈上,并且不依赖于它以前设置的全局或静态C变量。大多数编译器将返回地址放在堆栈上。因此,应用程序开发人员只需担心全局变量和静态变量的使用。
不可重入函数的一个例子是标准C库中的字符串标记函数strtok。此函数在后续调用中“记住”上一个字符串指针。它通过一个静态字符串指针来实现这一点。如果从多个线程调用此函数,则很可能返回无效指针。
Thread Priority Pitfalls
Selecting thread priorities is one of the most important aspects of multithreading. It is sometimes very tempting to assign priorities based on a perceived notion of thread importance rather than determining what is exactly required during run-time. Misuse of thread priorities can starve other threads, create priority inversion, reduce processing bandwidth, and make the application's run-time behavior difficult to understand.
As mentioned before, ThreadX provides a priority-based, preemptive scheduling algorithm. Lower priority threads do not execute until there are no higher priority threads ready for execution. If a higher priority thread is always ready, the lower priority threads never execute. This condition is called thread starvation.
Most thread starvation problems are detected early in debug and can be solved by ensuring that higher priority threads don't execute continuously. Alternatively, logic can be added to the application that gradually raises the priority of starved threads until they get a chance to execute.
Another pitfall associated with thread priorities is priority inversion. Priority inversion takes place when a higher priority thread is suspended because a lower priority thread has a needed resource. Of course, in some instances it is necessary for two threads of different priority to share a common resource. If these threads are the only ones active, the priority inversion time is bounded by the time the lower priority thread holds the resource. This condition is both deterministic and quite normal. However, if threads of intermediate priority become active during this priority inversion condition, the priority inversion time is no longer deterministic and could cause an application failure.
There are principally three distinct methods of preventing nondeterministic priority inversion in ThreadX. First, the application priority selections and run-time behavior can be designed in a manner that prevents the priority inversion problem. Second, lower priority threads can utilize preemption threshold to block preemption from intermediate threads while they share resources with higher priority threads. Finally, threads using ThreadX mutex objects to protect system resources may utilize the optional mutex priority inheritance to eliminate nondeterministic priority inversion.
线程优先级陷阱
选择线程优先级是多线程处理最重要的方面之一。有时,基于对线程重要性的感知来分配优先级是非常诱人的,而不是确定运行时到底需要什么。误用线程优先级会使其他线程陷入饥饿,造成优先级反转,减少处理带宽,并使应用程序的运行时行为难以理解。
如前所述,ThreadX提供了一种基于优先级的抢占式调度算法。在没有高优先级线程可供执行之前,低优先级线程不会执行。如果高优先级线程总是就绪,则低优先级线程永远不会执行。这种情况称为线程饥饿。
大多数线程匮乏问题都是在调试的早期检测到的,可以通过确保高优先级线程不连续执行来解决。或者,可以将逻辑添加到应用程序中,逐渐提高饥饿线程的优先级,直到它们有机会执行。
与线程优先级相关的另一个陷阱是优先级反转。当高优先级线程由于低优先级线程具有所需资源而挂起时,会发生优先级反转。当然,在某些情况下,两个优先级不同的线程有必要共享一个公共资源。如果只有这些线程处于活动状态,则优先级反转时间受低优先级线程持有资源的时间限制。这种情况既有确定性,又很正常。但是,如果中间优先级的线程在此优先级反转条件期间变为活动状态,则优先级反转时间不再是确定的,并且可能导致应用程序失败。
在ThreadX中,主要有三种不同的方法来防止不确定的优先级反转。首先,应用程序优先级选择和运行时行为的设计可以防止优先级反转问题。其次,低优先级线程可以利用抢占阈值来阻止中间线程的抢占,同时它们可以与高优先级线程共享资源。最后,使用ThreadX mutex对象来保护系统资源的线程可以利用可选的mutex优先级继承来消除不确定的优先级反转。
Priority Overhead
One of the most overlooked ways to reduce overhead in multithreading is to reduce the number of context switches. As previously mentioned, a context switch occurs when execution of a higher priority thread is favored over that of the executing thread. It is worthwhile to mention that higher priority threads can become ready as a result of both external events (like interrupts) and from service calls made by the executing thread.
To illustrate the effects thread priorities have on context switch overhead, assume a three thread environment with threads named thread_1, thread_2, and thread_3. Assume further that all of the threads are in a state of suspension waiting for a message. When thread_1 receives a message, it immediately forwards it to thread_2. Thread_2 then forwards the message to thread_3. Thread_3 just discards the message. After each thread processes its message, it goes back and waits for another message.
The processing required to execute these three threads varies greatly depending on their priorities. If all of the threads have the same priority, a single context switch occurs before the execution of each thread. The context switch occurs when each thread suspends on an empty message queue.
However, if thread_2 is higher priority than thread_1 and thread_3 is higher priority than thread_2, the number of context switches doubles. This is because another context switch occurs inside of the tx_queue_send service when it detects that a higher priority thread is now ready.
The ThreadX preemption-threshold mechanism can avoid these extra context switches and still allow the previously mentioned priority selections. This is an important feature because it allows several thread priorities during scheduling, while at the same time eliminating some of the unwanted context switching between them during thread execution.
优先级开销
减少多线程开销的一个最容易被忽视的方法是减少上下文切换的数量。如前所述,当更高优先级线程的执行优于执行线程的执行时,会发生上下文切换。值得一提的是,由于外部事件(如中断)和执行线程发出的服务调用,高优先级线程可以准备就绪。
为了说明线程优先级对上下文切换开销的影响,假设一个三线程环境,其中包含名为thread_1、thread_2和thread_3的线程。进一步假设所有线程都处于暂停状态,等待消息。当thread_1收到消息时,它会立即将消息转发给thread_2。线程2然后将消息转发到thread_3。thread_3只是丢弃消息。在每个线程处理完它的消息之后,它返回并等待另一条消息。
执行这三个线程所需的处理因其优先级的不同而有很大差异。如果所有线程都具有相同的优先级,则在每个线程执行之前会发生一个上下文切换。当每个线程挂起在空消息队列上时,就会发生上下文切换。
???但是,如果线程2的优先级高于线程1,而线程3的优先级高于线程2,则上下文切换的数量将增加一倍。这是因为当tx_queue_send 服务检测到更高优先级的线程已就绪时,会在该服务内部发生另一个上下文切换。????
++ThreadX抢占阈值机制可以避免这些额外的上下文切换,并且仍然允许前面提到的优先级选择。这是一个重要的特性,因为它允许在调度期间使用多个线程优先级,同时消除了线程执行期间在它们之间进行的一些不需要的上下文切换。
Run-time Thread Performance Information
ThreadX provides optional run-time thread performance information. If the ThreadX library and application is built with TX_THREAD_ENABLE_PERFORMANCE_INFO defined, ThreadX accumulates the following information.
Total number for the overall system:
运行时线程性能信息
ThreadX提供可选的运行时线程性能信息。如果ThreadX库和应用程序是在定义了TX_THREAD_ENABLE_PERFORMANCE_INFO 的情况下构建的,ThreadX将累积以下信息。
整个系统的总数:
-
thread resumptions
-
thread suspensions
-
service call preemptions
-
interrupt preemptions
-
priority inversions
-
time-slices
-
relinquishes
-
thread timeouts
-
suspension aborts
-
idle system returns
-
non-idle system returns
- 线程恢复
- 线程挂起
- 服务呼叫抢占
- 中断抢占
- 优先级反转
- 时间切片
- 放弃
- 线程超时
- 暂停中止
- 空闲系统返回
- 非空闲系统返回
Total number for each thread:
-
resumptions
-
suspensions
-
service call preemptions
-
interrupt preemptions
-
priority inversions
-
time-slices
-
thread relinquishes
-
thread timeouts
-
suspension aborts
每个线程的总数:
- 恢复
- 暂停
- 服务呼叫抢占
- 中断抢占
- 优先级反转
- 时间切片
- 线程放弃
- 线程超时
- 暂停中止
This information is available at run-time through the services tx_thread_performance_info_get and tx_thread_performance_system_info_get. Thread performance information is useful in determining if the application is behaving properly. It is also useful in optimizing the application. For example, a relatively high number of service call preemptions might suggest the thread's priority and/or preemption-threshold is too low. Furthermore, a relatively low number of idle system returns might suggest that lower priority threads are not suspending enough.
此信息在运行时可通过服务tx_thread_performance_info_get and tx_thread_performance_system_info_get获得。线程性能信息有助于确定应用程序是否正常运行。它也有助于优化应用程序。例如,相对较高的服务调用抢占次数可能表明线程的优先级和/或抢占阈值过低。此外,相对较少的空闲系统返回数可能表明低优先级线程没有足够的挂起。
Debugging Pitfalls
Debugging multithreaded applications is a little more difficult because the same program code can be executed from multiple threads. In such cases, a break-point alone may not be enough. The debugger must also view the current thread pointer _tx_thread_current_ptr using a conditional breakpoint to see if the calling thread is the one to debug.
Much of this is being handled in multithreading support packages offered through various development tool vendors. Because of its simple design, integrating ThreadX with different development tools is relatively easy.
Stack size is always an important debug topic in multithreading. Whenever unexplained behavior is observed, it is usually a good first guess to increase stack sizes for all threads—especially the stack size of the last thread to execute!
提示
It is also a good idea to build the ThreadX library with TX_ENABLE_STACK_CHECKING defined. This will help isolate stack corruption problems as early in the processing as possible.
调试陷阱
调试多线程应用程序有点困难,因为相同的程序代码可以从多个线程执行。在这种情况下,仅仅一个断点可能是不够的。调试器还必须使用条件断点查看当前线程指针_tx_thread_current_ptr ,以查看调用线程是否是要调试的线程。
其中大部分是通过各种开发工具供应商提供的多线程支持包来处理的。由于其设计简单,将ThreadX与不同的开发工具集成起来相对容易。
堆栈大小一直是多线程调试的重要课题。每当观察到未解释的行为时,通常是一个很好的猜测,即增加所有线程的堆栈大小,特别是最后一个要执行的线程的堆栈大小!
提示
使用定义了TX_ENABLE_STACK_CHECKING来构建ThreadX库也是一个好主意。这将有助于在处理过程中尽早隔离堆栈损坏问题。
Message Queues
Message queues are the primary means of inter-thread communication in ThreadX. One or more messages can reside in a message queue. A message queue that holds a single message is commonly called a mailbox.
Messages are copied to a queue by tx_queue_send and are copied from a queue by tx_queue_receive. The only exception to this is when a thread is suspended while waiting for a message on an empty queue. In this case, the next message sent to the queue is placed directly into the thread's destination area.
Each message queue is a public resource. ThreadX places no constraints on how message queues are used.
消息队列
消息队列是ThreadX中线程间通信的主要手段。一个或多个消息可以驻留在消息队列中。一个包含一条消息的消息队列通常称为邮箱。
消息通过tx_queue_send 复制到队列,并由tx_queue_receive从队列复制。唯一的例外是当线程在空队列上等待消息时挂起。在这种情况下,发送到队列的下一条消息直接放置到线程的目标区域。
每个消息队列都是公共资源。ThreadX对消息队列的使用方式没有任何限制。
Creating Message Queues
Message queues are created either during initialization or during run-time by application threads. There is no limit on the number of message queues in an application.
创建消息队列
消息队列是在初始化期间创建的,也可以是在运行时由应用程序线程创建的。应用程序中的消息队列数量没有限制。
Message Size
Each message queue supports a number of fixed-sized messages. The available message sizes are 1 through 16 32-bit words inclusive. The message size is specified when the queue is created. Application messages greater than 16 words must be passed by pointer. This is accomplished by creating a queue with a message size of 1 word (enough to hold a pointer) and then sending and receiving message pointers instead of the entire message.
消息大小
每个消息队列支持许多固定大小的消息。可用消息大小包括1到16 的32位字。创建队列时指定消息大小。大于16个字的应用程序消息必须通过指针传递。这是通过创建一个消息大小为1个字(足以容纳指针)的队列,然后发送和接收消息指针而不是整个消息来完成的。
Message Queue Capacity
The number of messages a queue can hold is a function of its message size and the size of the memory area supplied during creation. The total message capacity of the queue is calculated by dividing the number of bytes in each message into the total number of bytes in the supplied memory area.
For example, if a message queue that supports a message size of 1 32-bit word (4 bytes) is created with a 100-byte memory area, its capacity is 25 messages.
消息队列容量
队列可以保存的消息数是其消息大小和创建期间提供的内存区域大小的函数。队列的总消息容量是通过将每个消息中的字节数除以提供的内存区域中的字节总数来计算的。
例如,如果使用100字节内存区域创建支持消息大小为1 32位字(4字节)的消息队列,则其容量为25条消息。
Queue Memory Area
As mentioned previously, the memory area for buffering messages is specified during queue creation. Like other memory areas in ThreadX, it can be located anywhere in the target's address space.
This is an important feature because it gives the application considerable flexibility. For example, an application might locate the memory area of an important queue in high-speed RAM to improve performance.
队列内存区域
如前所述,在创建队列时指定用于缓冲消息的内存区域。与ThreadX中的其他内存区域一样,它可以位于目标地址空间的任何位置。
这是一个重要的特性,因为它给应用程序带来了相当大的灵活性。例如,应用程序可以在高速RAM中找到重要队列的内存区域,以提高性能。
Thread Suspension
Application threads can suspend while attempting to send or receive a message from a queue. Typically, thread suspension involves waiting for a message from an empty queue. However, it is also possible for a thread to suspend trying to send a message to a full queue.
After the condition for suspension is resolved, the service requested is completed and the waiting thread is resumed. If multiple threads are suspended on the same queue, they are resumed in the order they were suspended (FIFO).
However, priority resumption is also possible if the application calls tx_queue_prioritize prior to the queue service that lifts thread suspension. The queue prioritize service places the highest priority thread at the front of the suspension list, while leaving all other suspended threads in the same FIFO order.
Time-outs are also available for all queue suspensions. Basically, a time-out specifies the maximum number of timer ticks the thread will stay suspended. If a time-out occurs, the thread is resumed and the service returns with the appropriate error code.
线程挂起
应用程序线程在尝试从队列发送或接收消息时可以挂起。通常,线程挂起因为等待空队列中的消息。但是,线程也可能因尝试向完整队列发送消息而挂起。
解决挂起条件后,请求的服务已完成,等待线程将恢复。如果多个线程挂起在同一队列上,则它们将按照暂停的顺序恢复(FIFO)。
尽管如此,如果应用程序在队列服务挂起线程之前调用tx_queue_prioritize ,那么优先级恢复也是可能的。队列优先级服务将最高优先级线程放在挂起列表的前面,同时将所有其他挂起的线程保持相同的FIFO顺序。
超时也适用于所有队列挂起。基本上,超时指定了线程将保持挂起的最大计时器计时次数。如果超时发生,则恢复线程,并返回服务,并返回相应的错误代码。
Queue Send Notification
Some applications may find it advantageous to be notified whenever a message is placed on a queue. ThreadX provides this ability through the tx_queue_send_notify service. This service registers the supplied application notification function with the specified queue. ThreadX will subsequently invoke this application notification function whenever a message is sent to the queue. The exact processing within the application notification function is determined by the application; however, it typically consists of resuming the appropriate thread for processing the new message.
队列发送通知
有些应用程序可能会发现,每当消息被放置在队列上时被通知,是有好处的。ThreadX通过tx_queue_send_notify服务提供了这种功能。此服务将提供的应用程序通知函数注册到指定队列。每当消息发送到队列时,ThreadX将随后调用此应用程序通知函数。应用程序通知函数中的精确处理由应用程序确定;但是,它通常包括恢复处理新消息的适当线程。
Queue Event chaining™
The notification capabilities in ThreadX can be used to chain various synchronization events together. This is typically useful when a single thread must process multiple synchronization events.
For example, suppose a single thread is responsible for processing messages from five different queues and must also suspend when no messages are available. This is easily accomplished by registering an application notification function for each queue and introducing an additional counting semaphore. Specifically, the application notification function performs a tx_semaphore_put whenever it is called (the semaphore count represents the total number of messages in all five queues). The processing thread suspends on this semaphore via the tx_semaphore_get service. When the semaphore is available (in this case, when a message is available!), the processing thread is resumed. It then interrogates each queue for a message, processes the found message, and performs another tx_semaphore_get to wait for the next message. Accomplishing this without event-chaining is quite difficult and likely would require more threads and/or additional application code.
In general, event-chaining results in fewer threads, less overhead, and smaller RAM requirements. It also provides a highly flexible mechanism to handle synchronization requirements of more complex systems.
队列事件链™
ThreadX中的通知功能可用于将各种同步事件链接在一起。当单个线程必须处理多个同步事件时,这通常很有用。
例如,假设一个线程负责处理来自五个不同队列的消息,并且在没有消息可用时也必须挂起。通过为每个队列注册一个应用程序通知函数并引入一个额外的计数信号量,可以很容易地实现这一点。具体地说,应用程序通知函数在每次被调用时都执行tx_semaphore_put(信号量计数表示所有五个队列中的消息总数)。处理线程通过tx_semaphore_get服务挂起这个信号量。当信号量可用时(在本例中,当消息可用时!),则继续处理线程。然后,它询问每个队列中的一条消息,处理找到的消息,并执行另一个tx_semaphore_get来等待下一条消息。在没有事件链接的情况下实现这一点非常困难,可能需要更多的线程和/或额外的应用程序代码。
一般来说,事件链接导致更少的线程、更少的开销和更小的RAM需求。它还提供了一种高度灵活的机制来处理更复杂系统的同步需求。
Run-time Queue Performance Information
ThreadX provides optional run-time queue performance information. If the ThreadX library and application is built with TX_QUEUE_ENABLE_PERFORMANCE_INFO defined, ThreadX accumulates the following information.
运行时队列性能信息
ThreadX提供可选的运行时队列性能信息。如果ThreadX库和应用程序是在定义了TX_QUEUE_ENABLE_PERFORMANCE_INFO的情况下构建的,ThreadX将累积以下信息。
Total number for the overall system:
-
messages sent
-
messages received
-
queue empty suspensions
-
queue full suspensions
-
queue full error returns (suspension not specified)
-
queue timeouts
整个系统的总数:
- 发送的消息
- 收到的消息
- 队列空挂起
- 队列完全暂停
- 队列已满错误返回(未指定暂停)
- 队列超时
Total number for each queue:
-
messages sent
-
messages received
-
queue empty suspensions
-
queue full suspensions
-
queue full error returns (suspension not specified)
-
queue timeouts
每个队列的总数:
- 发送的消息
- 收到的消息
- 队列空挂起
- 队列完全暂停
- 队列已满错误返回(未指定暂停)
- 队列超时
This information is available at run-time through the services tx_queue_performance_info_get and tx_queue_performance_system_info_get. Queue performance information is useful in determining if the application is behaving properly. It is also useful in optimizing the application. For example, a relatively high number of "queue full suspensions" suggests an increase in the queue size might be beneficial.
此信息在运行时可通过服务 tx_queue_performance_info_get and tx_queue_performance_system_info_get获得。队列性能信息有助于确定应用程序是否正常运行。它也有助于优化应用程序。例如,相对较多的“队列完全暂停”表明增加队列大小可能是有益的。
Queue Control Block TX_QUEUE
The characteristics of each message queue are found in its control block. It contains interesting information such as the number of messages in the queue. This structure is defined in the tx_api.h file.
Message queue control blocks can also be located anywhere in memory, but it is most common to make the control block a global structure by defining it outside the scope of any function.
队列控制块TX_QUEUE
每个消息队列的特征都可以在其控制块中找到。它包含有趣的信息,例如队列中的消息数。这个结构是在tx_api.h文件中定义的。
消息队列控制块也可以位于内存中的任何位置,但最常见的做法是在任何函数的作用域之外定义控制块,使其成为全局结构。
Message Destination Pitfall
As mentioned previously, messages are copied between the queue area and application data areas. It is important to ensure the destination for a received message is large enough to hold the entire message. If not, the memory following the message destination will likely be corrupted.
备注
This is especially lethal when a too-small message destination is on the stack—nothing like corrupting the return address of a function!
消息目的地陷阱
如前所述,在队列区域和应用程序数据区域之间复制消息。确保接收到的消息的目的地足够大以容纳整个消息是很重要的。否则,消息目标后面的内存可能会损坏。
备注
当堆栈上的消息目的地太小时,这一点尤其致命—没有什么比破坏函数的返回地址更可怕的了!
Counting Semaphores
ThreadX provides 32-bit counting semaphores that range in value between 0 and 4,294,967,295. There are two operations for counting semaphores: . The get operation decreases the semaphore by one. If the semaphore is 0, the get operation is not successful. The inverse of the get operation is the put operation. It increases the semaphore by one.
Each counting semaphore is a public resource. ThreadX places no constraints on how counting semaphores are used.
Counting semaphores are typically used for mutual exclusion. However, counting semaphores can also be used as a method for event notification.
计数信号量
ThreadX提供的32位计数信号量的值范围在0到4294967295之间。有两种计算信号量的操作:tx_semaphore_get and tx_semaphore_put。get操作将信号量减少1。如果信号量为0,则get操作不成功。get操作的逆操作是put操作。它将信号量增加1。
每个计数信号量都是公共资源。ThreadX对如何使用计数信号量没有任何限制。
计数信号量通常用于互斥。但是,计数信号量也可以用作事件通知的方法。
Mutual Exclusion
Mutual exclusion pertains to controlling the access of threads to certain application areas (also called critical sections or application resources). When used for mutual exclusion, the "current count" of a semaphore represents the total number of threads that are allowed access. In most cases, counting semaphores used for mutual exclusion will have an initial value of 1, meaning that only one thread can access the associated resource at a time. Counting semaphores that only have values of 0 or 1 are commonly called binary semaphores.
重要
If a binary semaphore is being used, the user must prevent the same thread from performing a get operation on a semaphore it already owns. A second get would be unsuccessful and could cause indefinite suspension of the calling thread and permanent unavailability of the resource.
互斥
互斥是指控制线程对某些应用程序区域(也称为临界区或应用程序资源)的访问。当用于互斥时,信号量的“当前计数”表示允许访问的线程总数。在大多数情况下,用于互斥的计数信号量的初始值为1,这意味着一次只能有一个线程访问关联的资源。只有值为0或1的计数信号量通常称为二进制信号量。
重要
如果正在使用二进制信号量,则用户必须阻止同一线程对其已拥有的信号量执行get操作。第二次get将不成功,并可能导致调用线程无限期挂起和资源永久不可用。
Event Notification
It is also possible to use counting semaphores as event notification, in a producer-consumer fashion. The consumer attempts to get the counting semaphore while the producer increases the semaphore whenever something is available. Such semaphores usually have an initial value of 0 and will not increase until the producer has something ready for the consumer. Semaphores used for event notification may also benefit from use of the tx_semaphore_ceiling_put service call. This service ensures that the semaphore count never exceeds the value supplied in the call.
事件通知
也可以使用计数信号量作为事件通知,以生产者-消费者的方式。当有可用的时候,消费者试图获得计数信号量,而生产者会增加信号量。此类信号量通常具有0的初始值,并且在生产者准备好了消费者的东西之前不会增加。用于事件通知的信号量也可以受益于使用tx_semaphore_ceiling_put 服务调用。此服务确保信号量计数不会超过调用中提供的值。
Creating Counting Semaphores
Counting semaphores are created either during initialization or during run-time by application threads. The initial count of the semaphore is specified during creation. There is no limit on the number of counting semaphores in an application.
创建计数信号量
计数信号量是在初始化期间或在运行时由应用程序线程创建的。创建期间指定信号量的初始计数。在应用程序中计数信号量的数量没有限制。
Thread Suspension
Application threads can suspend while attempting to perform a get operation on a semaphore with a current count of 0.
After a put operation is performed, the suspended thread's get operation is performed and the thread is resumed. If multiple threads are suspended on the same counting semaphore, they are resumed in the same order they were suspended (FIFO).
However, priority resumption is also possible if the application calls tx_semaphore_prioritize prior to the semaphore put call that lifts thread suspension. The semaphore prioritize service places the highest priority thread at the front of the suspension list, while leaving all other suspended threads in the same FIFO order.
线程挂起
应用程序线程在尝试对当前计数为0的信号量执行get操作时会挂起。
执行put操作后,将执行挂起线程的get操作,并恢复线程。如果多个线程挂起在同一个计数信号量上,则它们将以相同的顺序恢复它们被挂起(FIFO)。
但是,如果应用程序在触发线程挂起的信号量put调用之前调用 tx_semaphore_prioritize,那么优先级恢复也是可能的。信号量优先级服务将最高优先级线程放在挂起列表的前面,而将所有其他挂起的线程保持相同的FIFO顺序。
Semaphore Put Notification
Some applications may find it advantageous to be notified whenever a semaphore is put. ThreadX provides this ability through the tx_semaphore_put_notify service. This service registers the supplied application notification function with the specified semaphore. ThreadX will subsequently invoke this application notification function whenever the semaphore is put. The exact processing within the application notification function is determined by the application; however, it typically consists of resuming the appropriate thread for processing the new semaphore put event.
信号量Put通知
有些应用程序可能会发现,每当信号量放置时被通知是有好处的。ThreadX通过tx_semaphore_put_notify服务提供了这种能力。此服务使用指定的信号量注册提供的应用程序通知函数。ThreadX随后将在信号量被放置时调用此应用程序通知函数。应用程序通知函数中的精确处理由应用程序确定;但是,当新信号量put事件发生时它通常包括恢复处理适当线程。
Semaphore Event chaining™
The notification capabilities in ThreadX can be used to chain various synchronization events together. This is typically useful when a single thread must process multiple synchronization events.
For example, instead of having separate threads suspend for a queue message, event flags, and a semaphore, the application can register a notification routine for each object. When invoked, the application notification routine can then resume a single thread, which can interrogate each object to find and process the new event.
In general, event-chaining results in fewer threads, less overhead, and smaller RAM requirements. It also provides a highly flexible mechanism to handle synchronization requirements of more complex systems.
信号量事件链™
ThreadX中的通知功能可用于将各种同步事件链接在一起。当单个线程必须处理多个同步事件时,这通常很有用。
例如,应用程序可以为每个对象注册通知例程,而不是为队列消息、事件标志和信号量挂起单独的线程。当调用时,应用程序通知例程可以恢复一个线程,它可以查询每个对象以查找和处理新事件。
一般来说,事件链接导致更少的线程、更少的开销和更小的RAM需求。它还提供了一种高度灵活的机制来处理更复杂系统的同步需求。
Run-time Semaphore Performance Information
ThreadX provides optional run-time semaphore performance information. If the ThreadX library and application is built with TX_SEMAPHORE_ENABLE_PERFORMANCE_INFO defined, ThreadX accumulates the following information.
运行时信号量性能信息
ThreadX提供可选的运行时信号量性能信息。如果ThreadX库和应用程序是使用定义的TX_SEMAPHORE_ENABLE_PERFORMANCE_INFO构建的,ThreadX将累积以下信息。
Total number for the overall system:
-
semaphore puts
-
semaphore gets
-
semaphore get suspensions
-
semaphore get timeouts
整个系统的总数:
- 信号量释放
- 信号量获取
- 信号量获取悬念
- 信号量获取超时
Total number for each semaphore:
-
semaphore puts
-
semaphore gets
-
semaphore get suspensions
-
semaphore get timeouts
每个信号量的总数:
- 信号量释放
- 信号量获取
- 信号量获取悬念
- 信号量获取超时
This information is available at run-time through the services tx_semaphore_performance_info_get and tx_semaphore_performance_system_info_get. Semaphore performance information is useful in determining if the application is behaving properly. It is also useful in optimizing the application. For example, a relatively high number of "semaphore get timeouts" might suggest that other threads are holding resources too long.
此信息可通过服务 tx_semaphore_performance_info_get and tx_semaphore_performance_system_info_get在运行时提供。信号量性能信息在确定应用程序是否正常运行时非常有用。它也有助于优化应用程序。例如,相对较多的“信号量获取超时”可能表明其他线程保存资源太长。
Semaphore Control Block TX_SEMAPHORE
The characteristics of each counting semaphore are found in its control block. It contains information such as the current semaphore count. This structure is defined in the tx_api.h file.
Semaphore control blocks can be located anywhere in memory, but it is most common to make the control block a global structure by defining it outside the scope of any function.
信号量控制块TX_SEMAPHORE
在控制块中发现了每个计数信号量的特点。它包含诸如当前信号量计数等信息。这个结构是在tx_api.h文件中定义的。
信号量控制块可以位于内存中的任何位置,但是最常见的做法是通过在任何函数的范围之外定义它来使控制块成为一个全局结构。
Deadly Embrace
One of the most interesting and dangerous pitfalls associated with semaphores used for mutual exclusion is the deadly embrace. A deadly embrace, or deadlock, is a condition in which two or more threads are suspended indefinitely while attempting to get semaphores already owned by each other.
This condition is best illustrated by a two thread, two semaphore example. Suppose the first thread owns the first semaphore and the second thread owns the second semaphore. If the first thread attempts to get the second semaphore and at the same time the second thread attempts to get the first semaphore, both threads enter a deadlock condition. In addition, if these threads stay suspended forever, their associated resources are locked-out forever as well. Figure 8 illustrates this example.
死亡拥抱
与用于互斥的信号量相关的最有趣和最危险的陷阱之一是死亡拥抱。一个死亡拥抱,或死锁,是两个或两个以上的线程被无限期地挂起,而试图获得已经拥有对方的信号量。
这种情况最好用一个双线程、双信号量的例子来说明。假设第一个线程拥有第一个信号量,第二个线程拥有第二个信号量。如果第一个线程尝试获取第二个信号量,同时第二个线程尝试获取第一个信号量,那么两个线程都会进入死锁状态。此外,如果这些线程永远处于挂起状态,那么它们的相关资源也将永远被锁定。图8说明了这个例子。
Deadly Embrace (example)

FIGURE 8. Example of Suspended Threads
For real-time systems, deadly embraces can be prevented by placing certain restrictions on how threads obtain semaphores. Threads can only have one semaphore at a time. Alternatively, threads can own multiple semaphores if they gather them in the same order. In the previous example, if the first and second thread obtain the first and second semaphore in order, the deadly embrace is prevented.
提示
It is also possible to use the suspension time-out associated with the get operation to recover from a deadly embrace.
对于实时系统,可以通过对线程获取信号量的方式施加某些限制来防止致命的拥抱。线程一次只能有一个信号量。或者,线程可以拥有多个信号量,如果它们以相同的顺序收集它们的话。在前面的示例中,如果第一个和第二个线程按顺序获得第一个和第二个信号量,则可以防止致命的拥抱。
提示
也可以使用与get操作相关联的暂停超时来从致命的拥抱中恢复。
Priority Inversion
Another pitfall associated with mutual exclusion semaphores is priority inversion. This topic is discussed more fully in "Thread Priority Pitfalls".
The basic problem results from a situation in which a lower-priority thread has a semaphore that a higher priority thread needs. This in itself is normal. However, threads with priorities in between them may cause the priority inversion to last a nondeterministic amount of time. This can be handled through careful selection of thread priorities, using preemption-threshold, and temporarily raising the priority of the thread that owns the resource to that of the high priority thread.
优先级反转
与互斥信号量相关的另一个陷阱是优先级反转。这个主题在“线程优先级陷阱”中有更详细的讨论。
基本问题产生于这样一种情况:低优先级线程具有高优先级线程所需的信号量。这本身就是正常的。但是,优先级介于两者之间的线程可能会导致优先级反转持续不确定的时间。这可以通过仔细选择线程优先级、使用抢占阈值以及暂时将拥有资源的线程的优先级提高到高优先级线程的优先级来处理。
Mutexes
In addition to semaphores, ThreadX also provides a mutex object. A mutex is basically a binary semaphore, which means that only one thread can own a mutex at a time. In addition, the same thread may perform a successful mutex get operation on an owned mutex multiple times, 4,294,967,295 to be exact. There are two operations on the mutex object: tx_mutex_get and tx_mutex_put. The get operation obtains a mutex not owned by another thread, while the put operation releases a previously obtained mutex. For a thread to release a mutex, the number of put operations must equal the number of prior get operations.
Each mutex is a public resource. ThreadX places no constraints on how mutexes are used.
ThreadX mutexes are used solely for mutual exclusion. Unlike counting semaphores, mutexes have no use as a method for event notification.
互斥量
除了信号量,ThreadX还提供了一个mutex对象。互斥锁基本上是一个二进制信号量,这意味着一次只能有一个线程拥有互斥锁。此外,同一线程可能会多次对所拥有的互斥执行成功的互斥get操作,确切地说是4294967295。mutex对象上有两个操作:tx_mutex_get and tx_mutex_put。get操作获得一个不属于另一个线程的mutex,而put操作释放一个先前获得的mutex。对于要释放互斥锁的线程,put操作的数量必须等于先前get操作的数量。
每个互斥锁都是公共资源。ThreadX对互斥锁的使用方式没有任何限制。
ThreadX互斥仅用于互斥。与统计信号量不同,互斥锁没有用作事件通知的方法。+++++通知没有,优先级有
Mutex Mutual Exclusion
Similar to the discussion in the counting semaphore section, mutual exclusion pertains to controlling the access of threads to certain application areas (also called critical sections or application resources). When available, a ThreadX mutex will have an ownership count of 0. After the mutex is obtained by a thread, the ownership count is incremented once for every successful get operation performed on the mutex and decremented for every successful put operation.
互斥锁互斥
与计数信号量部分中的讨论类似,互斥涉及控制线程对特定应用程序区域(也称为临界区或应用程序资源)的访问。如果可用,ThreadX mutex的所有权计数将为0。线程获取互斥体后,对于在互斥体上执行的每个成功的get操作,所有权计数都会增加一次,对于每个成功的put操作,所有权计数都会减少一次。
Creating Mutexes
ThreadX mutexes are created either during initialization or during run-time by application threads. The initial condition of a mutex is always "available." A mutex may also be created with priority inheritance selected.
创建互斥
ThreadX互斥锁是由应用程序线程在初始化或运行时创建的。互斥锁的初始条件总是“可用”。也可以在选择优先级继承的情况下创建互斥锁。
Thread Suspension
Application threads can suspend while attempting to perform a get operation on a mutex already owned by another thread.
After the same number of put operations are performed by the owning thread, the suspended thread's get operation is performed, giving it ownership of the mutex, and the thread is resumed. If multiple threads are suspended on the same mutex, they are resumed in the same order they were suspended (FIFO).
However, priority resumption is done automatically if the mutex priority inheritance was selected during creation. Priority resumption is also possible if the application calls tx_mutex_prioritize prior to the mutex put call that lifts thread suspension. The mutex prioritize service places the highest priority thread at the front of the suspension list, while leaving all other suspended threads in the same FIFO order.
线程挂起
应用程序线程会在尝试对另一个线程已经拥有的互斥执行get操作时挂起。
在拥有线程执行相同数量的put操作之后,将执行挂起线程的get操作,赋予它mutex的所有权,然后线程继续。如果多个线程挂起在同一个互斥体上,那么它们将按照挂起的顺序(FIFO)恢复。
但是,如果在创建过程中选择了mutex优先级继承,则会自动恢复优先级。如果应用程序在解除线程挂起的mutex put调用之前调用tx_mutex_prioritize,那么也可以恢复优先级。mutex prioritize服务将最高优先级的线程放在挂起列表的前面,而将所有其他挂起的线程保持相同的FIFO顺序。
Run-time Mutex Performance Information
ThreadX provides optional run-time mutex performance information. If the ThreadX library and application is built with TX_MUTEX_ENABLE_PERFORMANCE_INFO defined, ThreadX accumulates the following information.
运行时互斥体性能信息
ThreadX提供可选的运行时mutex性能信息。如果ThreadX库和应用程序是在定义了TX_MUTEX_ENABLE_PERFORMANCE_INFO的情况下构建的,ThreadX将累积以下信息。
Total number for the overall system:
-
mutex puts
-
mutex gets
-
mutex get suspensions
-
mutex get timeouts
-
mutex priority inversions
-
mutex priority inheritances
整个系统的总数:
- 互斥输入
- 互斥得到
- 互斥得到暂停
- 互斥获取超时
- 互斥优先级反转
- 互斥优先级继承
Total number for each mutex:
-
mutex puts
-
mutex gets
-
mutex get suspensions
-
mutex get timeouts
-
mutex priority inversions
-
mutex priority inheritances
每个互斥体的总数:
- 互斥输入
- 互斥得到
- 互斥得到暂停
- 互斥获取超时
- 互斥优先级反转
- 互斥优先级继承
This information is available at run-time through the services tx_mutex_performance_info_get and tx_mutex_performance_system_info_get. Mutex performance information is useful in determining if the application is behaving properly. It is also useful in optimizing the application. For example, a relatively high number of "mutex get timeouts" might suggest that other threads are holding resources too long.
此信息可通过服务tx互斥锁性能\u info_uget和tx互斥锁性能_system_info_uget在运行时获得。互斥体性能信息在确定应用程序是否正常运行时非常有用。它也有助于优化应用程序。例如,相对较多的“互斥锁获取超时”可能表明其他线程占用资源太长。
Mutex Control Block TX_MUTEX
The characteristics of each mutex are found in its control block. It contains information such as the current mutex ownership count along with the pointer of the thread that owns the mutex. This structure is defined in the tx_api.h file. Mutex control blocks can be located anywhere in memory, but it is most common to make the control block a global structure by defining it outside the scope of any function.
互斥控制块TX_MUTEX
每个互斥体的特性都在其控制块中找到。它包含诸如当前互斥锁所有权计数以及拥有互斥锁的线程指针等信息。该结构在tx炣api.h文件中定义。互斥锁控制块可以位于内存中的任何位置,但是最常见的做法是通过在任何函数的范围之外定义它来使控制块成为全局结构。
Deadly Embrace
One of the most interesting and dangerous pitfalls associated with mutex ownership is the deadly embrace. A deadly embrace, or deadlock, is a condition where two or more threads are suspended indefinitely while attempting to get a mutex already owned by the other threads. The discussion of deadly embrace and its remedies are completely valid for the mutex object as well.
死亡拥抱
与互斥拥有相关的最有趣和最危险的陷阱之一是死亡拥抱。致命的拥抱或死锁是一种情况,在试图获得其他线程已经拥有的互斥锁时,两个或多个线程无限期地被挂起。死亡拥抱及其补救方法的讨论对于互斥对象也是完全有效的。
Priority Inversion
As mentioned previously, a major pitfall associated with mutual exclusion is priority inversion. This topic is discussed more fully in "Thread Priority Pitfalls".
The basic problem results from a situation in which a lower priority thread has a semaphore that a higher priority thread needs. This in itself is normal. However, threads with priorities in between them may cause the priority inversion to last a nondeterministic amount of time. Unlike semaphores discussed previously, the ThreadX mutex object has optional priority inheritance. The basic idea behind priority inheritance is that a lower priority thread has its priority raised temporarily to the priority of a high priority thread that wants the same mutex owned by the lower priority thread. When the lower priority thread releases the mutex, its original priority is then restored and the higher priority thread is given ownership of the mutex. This feature eliminates nondeterministic priority inversion by bounding the amount of inversion to the time the lower priority thread holds the mutex. Of course, the techniques discussed earlier in this chapter to handle nondeterministic priority inversion are also valid with mutexes as well.
优先级反转
如前所述,相互排斥相关的一个主要陷阱是优先倒置。这个主题在“线程优先级陷阱”中有更详细的讨论。
基本问题是由于优先级较低的线程具有高优先级线程所需的信号量。这本身就是正常的。但是,优先级介于两者之间的线程可能会导致优先级反转持续不确定的时间。与前面讨论的信号量不同,ThreadX互斥对象具有可选的优先级继承。优先级继承背后的基本思想是,低优先级线程的优先级临时提高到高优先级线程的优先级,该线程希望低优先级线程拥有相同的互斥锁。当低优先级线程释放互斥锁时,它的原始优先级将被恢复,并且更高优先级的线程被赋予互斥锁的所有权。该特性通过将反转量与低优先级线程保持互斥体的时间相结合,消除了不确定的优先级反转。当然,本章前面讨论的处理非确定性优先级反转的技术对于互斥量也是有效的。
Event Flags
Event flags provide a powerful tool for thread synchronization. Each event flag is represented by a single bit. Event flags are arranged in groups of 32. Threads can operate on all 32 event flags in a group at the same time. Events are set by tx_event_flags_set and are retrieved by tx_event_flags_get.
Setting event flags is done with a logical AND/OR operation between the current event flags and the new event flags. The type of logical operation (either an AND or OR) is specified in the tx_event_flags_set call.
There are similar logical options for retrieval of event flags. A get request can specify that all specified event flags are required (a logical AND).
Alternatively, a get request can specify that any of the specified event flags will satisfy the request (a logical OR). The type of logical operation associated with event flags retrieval is specified in the tx_event_flags_get call.
重要
Event flags that satisfy a get request are consumed, i.e., set to zero, if TX_OR_CLEAR or TX_AND_CLEAR are specified by the request.
Each event flags group is a public resource. ThreadX places no constraints on how event flags groups are used.
事件标志
事件标志提供了一个强大的线程同步工具。每个事件标志都由一个位表示。事件标志以32组排列。线程可以同时对组中的所有32个事件标志进行操作。事件由tx_event_flags_set 设置,并由tx_event_flags_get 获取。
设置事件标志是通过当前事件标志和新事件标志之间的逻辑和/或操作来完成的。逻辑操作的类型(A和或)在tx_event_flags_set 调用中指定。
检索事件标志有类似的逻辑选项。get请求可以指定所有指定的事件标志都是必需的(逻辑和)。
或者,get请求可以指定指定的任何事件标志都将满足请求(逻辑或)。与事件标志检索关联的逻辑操作类型在tx_event_flags_get call中指定。
重要
如果请求指定了TX_OR_CLEAR or TX_AND_CLEAR ,则满足get请求的事件标志将被消耗,即设置为零。
每个事件标志组都是公共资源。ThreadX对如何使用事件标志组没有任何限制。
Creating Event Flags Groups
Event flags groups are created either during initialization or during run-time by application threads. At the time of their creation, all event flags in the group are set to zero. There is no limit on the number of event flags groups in an application.
创建事件标志组
事件标志组是在初始化期间或在运行时由应用程序线程创建的。在创建这些标志时,组中的所有事件标志都设置为零。应用程序中事件标志组的数量没有限制。
Thread Suspension
Application threads can suspend while attempting to get any logical combination of event flags from a group. After an event flag is set, the get requests of all suspended threads are reviewed. All the threads that now have the required event flags are resumed.
备注
All suspended threads on an event flag group are reviewed when its event flags are set. This, of course, introduces additional overhead. Therefore, it is good practice to limit the number of threads using the same event flag group to a reasonable number.
线程挂起
应用程序线程会在尝试从组中获取事件标志的任何逻辑组合时挂起。设置事件标志后,将检查所有挂起线程的get请求。现在具有所需事件标志的所有线程都将恢复。
备注
设置事件标志组的事件标志时,将检查事件标志组上的所有挂起线程。当然,这会带来额外的开销。因此,将使用相同事件标志组的线程数限制为合理的数目是一个好的做法。
Event Flags Set Notification
Some applications may find it advantageous to be notified whenever an event flag is set. ThreadX provides this ability through the tx_event_flags_set_notify service. This service registers the supplied application notification function with the specified event flags group. ThreadX will subsequently invoke this application notification function whenever an event flag in the group is set. The exact processing within the application notification function is determined by the application, but it typically consists of resuming the appropriate thread for processing the new event flag.
事件标志集通知
有些应用程序可能会发现,每当设置事件标志时通知它是有利的。ThreadX通过tx事件_flags\u set_notify service提供了此功能。此服务将提供的应用程序通知函数注册到指定的事件标志组。每当设置组中的事件标志时,ThreadX将随后调用此应用程序通知函数。应用程序通知函数中的精确处理由应用程序确定,但通常包括恢复处理新事件标志的适当线程。
Event Flags Event chaining™
The notification capabilities in ThreadX can be used to "chain" various synchronization events together. This is typically useful when a single thread must process multiple synchronization events.
For example, instead of having separate threads suspend for a queue message, event flags, and a semaphore, the application can register a notification routine for each object. When invoked, the application notification routine can then resume a single thread, which can interrogate each object to find and process the new event.
In general, event-chaining results in fewer threads, less overhead, and smaller RAM requirements. It also provides a highly flexible mechanism to handle synchronization requirements of more complex systems.
事件标志事件链接™
ThreadX中的通知功能可以用于将各种同步事件“链”在一起。当单个线程必须处理多个同步事件时,这通常很有用。
例如,应用程序可以为每个对象注册通知例程,而不是为队列消息、事件标志和信号量挂起单独的线程。当调用时,应用程序通知例程可以恢复一个线程,它可以查询每个对象以查找和处理新事件。
一般来说,事件链接导致更少的线程、更少的开销和更小的RAM需求。它还提供了一种高度灵活的机制来处理更复杂系统的同步需求。
Run-time Event Flags Performance Information
ThreadX provides optional run-time event flags performance information. If the ThreadX library and application is built with TX_EVENT_FLAGS_ENABLE_PERFORMANCE_INFO defined, ThreadX accumulates the following information.
运行时事件标志性能信息
ThreadX提供可选的运行时事件标志性能信息。如果ThreadX库和应用程序是使用定义的TX_EVENT_FLAGS_ENABLE_PERFORMANCE_INFO构建的,ThreadX将累积以下信息。
Total number for the overall system:
-
event flags sets
-
event flags gets
-
event flags get suspensions
-
event flags get timeouts
整个系统的总数:
- 事件标志集
- 事件标志获取
- 事件标志获取暂停
- 事件标志获取超时
otal number for each event flags group:
-
event flags sets
-
event flags gets
-
event flags get suspensions
-
event flags get timeouts
每个事件标志组的总数:
- 事件标志集
- 事件标志获取
- 事件标志获取暂停
- 事件标志获取超时
This information is available at run-time through the services tx_event_flags_performance_info_get and tx_event_flags_performance_system_info_get. The performance information of event flags is useful in determining if the application is behaving properly. It is also useful in optimizing the application. For example, a relatively high number of timeouts on the tx_event_flags_get service might suggest that the event flags suspension timeout is too short.
此信息可通过服务tx事件\u标志\u performance_uinfo_uget和tx_event_flags_performance_system_uinfo_uget获得。事件标志的性能信息在确定应用程序是否正常运行时非常有用。它也有助于优化应用程序。例如,tx_UEvent_uFlags_uGet服务上的超时数相对较高可能表明事件标志暂停超时太短。
Event Flags Group Control Block TX_EVENT_FLAGS_GROUP
The characteristics of each event flags group are found in its control block. It contains information such as the current event flags settings and the number of threads suspended for events. This structure is defined in the tx_api.h file.
Event group control blocks can be located anywhere in memory, but it is most common to make the control block a global structure by defining it outside the scope of any function.
事件标志组控制块TX_EVENT_FLAGS_GROUP
每个事件标志组的特性都在其控制块中找到。它包含诸如当前事件标志设置和事件挂起的线程数等信息。这个结构是在tx_api.h文件中定义的。
事件组控制块可以位于内存中的任何位置,但是最常见的做法是通过在任何函数的范围之外定义它来使控制块成为全局结构。
Memory Block Pools
Allocating memory in a fast and deterministic manner is always a challenge in real-time applications. With this in mind, ThreadX provides the ability to create and manage multiple pools of fixed-size memory blocks.
Because memory block pools consist of fixed-size blocks, there are never any fragmentation problems. Of course, fragmentation causes behavior that is inherently nondeterministic. In addition, the time required to allocate and free a fixed-size memory block is comparable to that of simple linked-list manipulation. Furthermore, memory block allocation and de-allocation is done at the head of the available list. This provides the fastest possible linked list processing and might help keep the actual memory block in cache.
Lack of flexibility is the main drawback of fixed-size memory pools. The block size of a pool must be large enough to handle the worst case memory requirements of its users. Of course, memory may be wasted if many different size memory requests are made to the same pool. A possible solution is to make several different memory block pools that contain different sized memory blocks.
Each memory block pool is a public resource. ThreadX places no constraints on how pools are used.
内存块池
在实时应用程序中,以快速和确定的方式分配内存一直是一个挑战。考虑到这一点,ThreadX提供了创建和管理多个固定大小内存块池的能力。
因为内存块池由固定大小的块组成,因此从来没有任何碎片问题。当然,碎片化会导致本质上不确定的行为。此外,分配和释放固定大小内存块所需的时间与简单链接列表操作所需的时间相当。此外,内存块分配和取消分配在可用列表的头部完成。这提供了可能最快的链接列表处理,并可能有助于将实际内存块保留在缓存中。
固定大小内存池的主要缺点是灵活性不足。池的块大小必须足够大,以处理用户最差的情况内存需求。当然,如果对同一池发出许多不同大小的内存请求,内存可能会被浪费。一个可能的解决方案是制作几个不同的内存块池,这些池包含不同大小的内存块。
每个内存块池都是公共资源。ThreadX对池的使用方式没有任何限制。
Creating Memory Block Pools
Memory block pools are created either during initialization or during run-time by application threads. There is no limit on the number of memory block pools in an application.
创建内存块池
内存块池是在初始化期间或在运行时由应用程序线程创建的。应用程序中内存块池的数量没有限制。
Memory Block Size
As mentioned earlier, memory block pools contain a number of fixed-size blocks. The block size, in bytes, is specified during creation of the pool.
备注
ThreadX adds a small amount of overhead—the size of a C pointer—to each memory block in the pool. In addition, ThreadX might have to pad the block size to keep the beginning of each memory block on proper alignment.
内存块大小
如前所述,内存块池包含许多固定大小的块。块大小(以字节为单位)是在创建池期间指定的。
备注
ThreadX向池中的每个内存块添加一个C指针大小的少量开销。此外,ThreadX可能需要填充块大小,以保持每个内存块的开头处于正确的对齐状态。
Pool Capacity
The number of memory blocks in a pool is a function of the block size and the total number of bytes in the memory area supplied during creation. The capacity of a pool is calculated by dividing the block size (including padding and the pointer overhead bytes) into the total number of bytes in the supplied memory area.
池容量
池中的内存块数是块大小和创建期间提供的内存区域中的字节总数的函数。池的容量是通过将块大小(包括填充和指针开销字节)除以提供的内存区域中的总字节数来计算的。
Pool's Memory Area
As mentioned before, the memory area for the block pool is specified during creation. Like other memory areas in ThreadX, it can be located anywhere in the target's address space.
This is an important feature because of the considerable flexibility it provides. For example, suppose that a communication product has a highspeed memory area for I/O. This memory area is easily managed by making it into a ThreadX memory block pool.
池的内存区域
如前所述,块池的内存区域在创建过程中指定。与ThreadX中的其他内存区域一样,它可以位于目标地址空间的任何位置。
这是一个重要的特性,因为它提供了相当大的灵活性。例如,假设通信产品具有用于I/O的高速内存区域。通过将其放入ThreadX内存块池,可以轻松管理此内存区域。
Thread Suspension
Application threads can suspend while waiting for a memory block from an empty pool. When a block is returned to the pool, the suspended thread is given this block and the thread is resumed.
If multiple threads are suspended on the same memory block pool, they are resumed in the order they were suspended (FIFO).
However, priority resumption is also possible if the application calls tx_block_pool_prioritize prior to the block release call that lifts thread suspension. The block pool prioritize service places the highest priority thread at the front of the suspension list, while leaving all other suspended threads in the same FIFO order.
线程挂起
应用程序线程可以在等待空池中的内存块时挂起。当一个块返回池时,将给挂起的线程这个块,线程将被恢复。
如果多个线程挂起在同一内存块池上,则按照暂停的顺序恢复它们(FIFO)。
但是,如果应用程序在解除线程暂停的块释放调用之前调用tx_block_pool_prioritize,那么优先级恢复也是可能的。块池优先级服务将最高优先级线程放在挂起列表的前面,同时将所有其他挂起的线程保持相同的FIFO顺序。
Run-time Block Pool Performance Information
ThreadX provides optional run-time block pool performance information. If the ThreadX library and application is built with TX_BLOCK_POOL_ENABLE_PERFORMANCE_INFO defined, ThreadX accumulates the following information.
运行时块池性能信息
ThreadX提供可选的运行时块池性能信息。如果ThreadX库和应用程序是使用定义的TX_BLOCK_POOL_ENABLE_PERFORMANCE_INFO 构建的,ThreadX将累积以下信息。
Total number for the overall system:
-
blocks allocated
-
blocks released
-
allocation suspensions
-
allocation timeouts
整个系统的总数:
- 分配的块
- 释放的块
- 分配暂停
- 分配超时
Total number for each block pool:
-
blocks allocated
-
blocks released
-
allocation suspensions
-
allocation timeouts
每个块池的总数:
- 分配的块
- 释放的块
- 分配暂停
- 分配超时
This information is available at run-time through the services tx_block_pool_performance_info_get and tx_block_pool_performance_system_info_get. Block pool performance information is useful in determining if the application is behaving properly. It is also useful in optimizing the application. For example, a relatively high number of "allocation suspensions" might suggest that the block pool is too small.
此信息可通过服务tx_block_pool_performance_info_get and tx_block_pool_performance_system_info_get在运行时提供。块池性能信息在确定应用程序是否正常运行时非常有用。它也有助于优化应用程序。例如,相对较多的“分配暂停”可能表明块池太小。
Memory Block Pool Control Block TX_BLOCK_POOL
The characteristics of each memory block pool are found in its control block. It contains information such as the number of memory blocks available and the memory pool block size. This structure is defined in the tx_api.h file.
Pool control blocks can also be located anywhere in memory, but it is most common to make the control block a global structure by defining it outside the scope of any function.
内存块池控制块TX_BLOCK_POOL
每个内存块池的特性都在其控制块中找到。它包含诸如可用内存块的数量和内存池块大小等信息。这个结构是在tx\u api.h文件中定义的。
池控制块也可以位于内存中的任何位置,但是最常见的做法是通过在任何函数的范围之外定义控制块作为全局结构。
Overwriting Memory Blocks
It is important to ensure that the user of an allocated memory block does not write outside its boundaries. If this happens, corruption occurs in an adjacent (usually subsequent) memory area. The results are unpredictable and often fatal to the application.
覆盖内存块
确保分配内存块的用户不会在其边界之外写入,这一点很重要。如果发生这种情况,则在相邻(通常是后续)内存区域中发生损坏。结果是不可预测的,并且对应用程序来说往往是致命的。
Memory Byte Pools
ThreadX memory byte pools are similar to a standard C heap. Unlike the standard C heap, it is possible to have multiple memory byte pools. In addition, threads can suspend on a pool until the requested memory is available.
Allocations from memory byte pools are similar to traditional malloc calls, which include the amount of memory desired (in bytes). Memory is allocated from the pool in a first-fit manner; i.e., the first free memory block that satisfies the request is used. Excess memory from this block is converted into a new block and placed back in the free memory list. This process is called fragmentation.
Adjacent free memory blocks are merged together during a subsequent allocation search for a large enough free memory block. This process is called defragmentation.
Each memory byte pool is a public resource. ThreadX places no constraints on how pools are used, except that memory byte services cannot be called from ISRs.
内存字节池
ThreadX内存字节池类似于标准C堆。与标准C堆不同,可以有多个内存字节池。此外,线程可以挂起池,直到请求的内存可用为止。
来自内存字节池的分配类似于传统的malloc调用,其中包括所需的内存量(以字节为单位)。内存以第一适合的方式从池分配;即使用满足请求的第一个空闲内存块。此块中的多余内存将转换为新块,并放回空闲内存列表中。这个过程称为碎片。
在随后的分配搜索中,相邻的空闲内存块合并在一起,以查找足够大的可用内存块。此过程称为碎片整理。
每个内存字节池都是公共资源。ThreadX对池的使用方式没有任何限制,除非无法从ISRs调用内存字节服务。
Creating Memory Byte Pools
Memory byte pools are created either during initialization or during run-time by application threads. There is no limit on the number of memory byte pools in an application.
创建内存字节池
内存字节池是在初始化期间或在运行时由应用程序线程创建的。应用程序中的内存字节池数量没有限制。
Pool Capacity
The number of allocatable bytes in a memory byte pool is slightly less than what was specified during creation. This is because management of the free memory area introduces some overhead. Each free memory block in the pool requires the equivalent of two C pointers of overhead. In addition, the pool is created with two blocks, a large free block and a small permanently allocated block at the end of the memory area. This allocated block is used to improve performance of the allocation algorithm. It eliminates the need to continuously check for the end of the pool area during merging.
During run-time, the amount of overhead in the pool typically increases. Allocations of an odd number of bytes are padded to ensure proper alignment of the next memory block. In addition, overhead increases as the pool becomes more fragmented.
池容量
内存字节池中可分配字节的数量略小于创建期间指定的字节数。这是因为对空闲内存区域的管理引入了一些开销。池中的每个空闲内存块都需要相当于两个C指针的开销。此外,池是由两个块创建的,一个大的空闲块和一个在内存区域的末尾有一个小的永久分配块。该分配块用于提高分配算法的性能。它消除了在合并期间连续检查池区域末端的需要。
在运行时,池中的开销通常会增加。填充奇数字节的分配,以确保下一个内存块的正确对齐。此外,随着池变得更分散,开销也会增加。
Pool's Memory Area
The memory area for a memory byte pool is specified during creation. Like other memory areas in ThreadX, it can be located anywhere in the target's address space. This is an important feature because of the considerable flexibility it provides. For example, if the target hardware has a high-speed memory area and a low-speed memory area, the user can manage memory allocation for both areas by creating a pool in each of them.
池的内存区域
创建过程中指定内存字节池的内存区域。与ThreadX中的其他内存区域一样,它可以位于目标地址空间的任何位置。这是一个重要的特性,因为它提供了相当大的灵活性。例如,如果目标硬件具有高速内存区域和低速内存区域,则用户可以通过在两个区域中创建池来管理两个区域的内存分配。
Thread Suspension
Application threads can suspend while waiting for memory bytes from a pool. When sufficient contiguous memory becomes available, the suspended threads are given their requested memory and the threads are resumed.
If multiple threads are suspended on the same memory byte pool, they are given memory (resumed) in the order they were suspended (FIFO).
However, priority resumption is also possible if the application calls tx_byte_pool_prioritize prior to the byte release call that lifts thread suspension. The byte pool prioritize service places the highest priority thread at the front of the suspension list, while leaving all other suspended threads in the same FIFO order.
线程挂起
应用程序线程可以在等待池中的内存字节时挂起。当足够的连续内存可用时,将为挂起的线程提供其请求的内存,并恢复线程。
如果多个线程挂起在同一内存字节池上,则它们将按照暂停的顺序(FIFO)被赋予内存(恢复)。
但是,如果应用程序在提升线程暂停的字节释放调用之前调用tx_byte_pool_prioritize,则优先级恢复也是可能的。字节池优先级服务将最高优先级线程放在挂起列表的前面,同时将所有其他挂起的线程保持相同的FIFO顺序。
Run-time Byte Pool Performance Information
ThreadX provides optional run-time byte pool performance information. If the ThreadX library and application is built with TX_BYTE_POOL_ENABLE_PERFORMANCE_INFO defined, ThreadX accumulates the following information.
运行时字节池性能信息
ThreadX提供可选的运行时字节池性能信息。如果ThreadX库和应用程序是使用定义的TX_BYTE_POOL_ENABLE_PERFORMANCE_INFO 构建的,ThreadX将累积以下信息。
Total number for the overall system:
-
allocations
-
releases
-
fragments searched
-
fragments merged
-
fragments created
-
allocation suspensions
-
allocation timeouts
整个系统的总数:
- 分配
- 释放
- 搜索到的碎片
- 合并的碎片
- 创建的碎片
- 分配暂停
- 分配超时
Total number for each byte pool:
-
allocations
-
releases
-
fragments searched
-
fragments merged
-
fragments created
-
allocation suspensions
-
allocation timeouts
每个字节池的总数:
- 分配
- 释放
- 搜索到的碎片
- 合并的碎片
- 创建的碎片
- 分配暂停
- 分配超时
This information is available at run-time through the services tx_byte_pool_performance_info_get and tx_byte_pool_performance_system_info_get. Byte pool performance information is useful in determining if the application is behaving properly. It is also useful in optimizing the application. For example, a relatively high number of "allocation suspensions" might suggest that the byte pool is too small.
此信息可通过服务tx_byte_pool_performance_info_get and tx_byte_pool_performance_system_info_get获取。字节池性能信息在确定应用程序是否正常运行时非常有用。它也有助于优化应用程序。例如,相对较多的“分配暂停”可能表明字节池太小。
Memory Byte Pool Control Block TX_BYTE_POOL
The characteristics of each memory byte pool are found in its control block. It contains useful information such as the number of available bytes in the pool. This structure is defined in the tx_api.h file.
Pool control blocks can also be located anywhere in memory, but it is most common to make the control block a global structure by defining it outside the scope of any function.
内存字节池控制块TX_BYTE_POOL
每个内存字节池的特性都在其控制块中找到。它包含有用的信息,例如池中可用字节的数量。这个结构是在tx_api.h文件中定义的。
池控制块也可以位于内存中的任何位置,但是最常见的做法是通过在任何函数的范围之外定义控制块作为全局结构。
Nondeterministic Behavior
Although memory byte pools provide the most flexible memory allocation, they also suffer from somewhat nondeterministic behavior. For example, a memory byte pool may have 2,000 bytes of memory available but may not be able to satisfy an allocation request of 1,000 bytes. This is because there are no guarantees on how many of the free bytes are contiguous. Even if a 1,000 byte free block exists, there are no guarantees on how long it might take to find the block. It is completely possible that the entire memory pool would need to be searched to find the 1,000 byte block.
提示
As a result of the nondeterministic behavior of memory byte pools, it is generally good practice to avoid using memory byte services in areas where deterministic, real-time behavior is required. Many applications pre-allocate their required memory during initialization or run-time configuration.
不确定性行为
虽然内存字节池提供了最灵活的内存分配,但它们也会受到一些不确定的行为的影响。例如,内存字节池可能具有2000字节可用内存,但可能无法满足1000字节的分配请求。这是因为没有保证多少空闲字节是连续的。即使存在1000字节的空闲块,也无法保证找到该块可能需要多长时间。完全有可能需要搜索整个内存池才能找到1000字节块。
提示
由于内存字节池的不确定性行为,通常是在需要确定性、实时行为的区域避免使用内存字节服务的良好做法。许多应用程序在初始化或运行时配置期间预先分配所需的内存。
Overwriting Memory Blocks
It is important to ensure that the user of allocated memory does not write outside its boundaries. If this happens, corruption occurs in an adjacent (usually subsequent) memory area. The results are unpredictable and often catastrophic for program execution.
覆盖内存块
确保分配内存的用户不会超出其边界写入,这一点很重要。如果发生这种情况,则在相邻(通常是后续)内存区域中发生损坏。结果是不可预测的,而且对程序执行来说往往是灾难性的。
Application Timers
Fast response to asynchronous external events is the most important function of real-time, embedded applications. However, many of these applications must also perform certain activities at predetermined intervals of time.
ThreadX application timers provide applications with the ability to execute application C functions at specific intervals of time. It is also possible for an application timer to expire only once. This type of timer is called a one-shot timer, while repeating interval timers are called periodic timers.
Each application timer is a public resource. ThreadX places no constraints on how application timers are used.
应用程序计时器
对异步外部事件的快速响应是实时嵌入式应用程序最重要的功能。然而,其中许多应用程序还必须以预定的时间间隔执行某些活动。
ThreadX应用程序计时器为应用程序提供了以特定时间间隔执行应用程序C函数的能力。应用程序计时器也可能只过期一次。这种类型的计时器称为一次性计时器,而重复间隔计时器称为周期计时器。
每个应用程序计时器都是公共资源。ThreadX对如何使用应用程序计时器没有任何限制。
Timer Intervals
In ThreadX time intervals are measured by periodic timer interrupts. Each timer interrupt is called a timer tick. The actual time between timer ticks is specified by the application, but 10ms is the norm for most implementations. The periodic timer setup is typically found in the tx_initialize_low_level assembly file.
It is worth mentioning that the underlying hardware must have the ability to generate periodic interrupts for application timers to function. In some cases, the processor has a built-in periodic interrupt capability. If the processor doesn't have this ability, the user's board must have a peripheral device that can generate periodic interrupts.
重要
ThreadX can still function even without a periodic interrupt source. However, all timer-related processing is then disabled. This includes timeslicing, suspension time-outs, and timer services.
计时器间隔
在ThreadX中,时间间隔是通过定时中断来测量的。每个定时器中断都称为一个定时器滴答声。计时器滴答声之间的实际间隔时间由应用程序指定,但对于大多数实现,10ms是标准值。定期计时器设置通常位于tx_initialize_low_level 程序集文件中。
值得一提的是,底层硬件必须能够生成周期性中断,以便应用程序计时器正常工作。在某些情况下,处理器具有内置的周期性中断功能。如果处理器没有这种能力,用户板必须有一个能产生周期性中断的外围设备。
重要
即使没有周期性中断源,ThreadX仍然可以正常工作。但是,所有与计时器相关的处理都将被禁用。这包括时间限制、暂停超时和计时器服务。
Timer Accuracy
Timer expirations are specified in terms of ticks. The specified expiration value is decreased by one on each timer tick. Because an application timer could be enabled just prior to a timer interrupt (or timer tick), the actual expiration time could be up to one tick early.
If the timer tick rate is 10ms, application timers may expire up to 10ms early. This is more significant for 10ms timers than 1 second timers. Of course, increasing the timer interrupt frequency decreases this margin of error.
定时器精度
计时器的过期时间是以记号的形式指定的。每当始终滴答到来,每个计时器刻度上就减少一个。因为应用程序计时器可以在计时器中断(或计时器滴答声)之前启用,所以实际的过期时间可能会提前一个滴答声。
如果计时器计时频率为10ms,应用程序计时器可能会提前10ms过期。这对于10ms计时器比1秒计时器更重要。当然,增加定时器中断频率会减小这种误差幅度。
Timer Execution
Application timers execute in the order they become active. For example, if three timers are created with the same expiration value and activated, their corresponding expiration functions are guaranteed to execute in the order they were activated.
计时器执行
应用程序计时器按其激活的顺序执行。例如,如果创建了三个具有相同过期值的计时器并将其激活,则它们相应的过期函数将保证按其激活的顺序执行。
Creating Application Timers
Application timers are created either during initialization or during run-time by application threads. There is no limit on the number of application timers in an application.
创建应用程序计时器
应用程序计时器由应用程序线程在初始化或运行时创建。应用程序中的应用程序计时器数量没有限制。
Run-time Application Timer Performance Information
ThreadX provides optional run-time application timer performance information. If the ThreadX library and application are built with TX_TIMER_ENABLE_PERFORMANCE_INFO defined, ThreadX accumulates the following information.
运行时应用程序计时器性能信息
ThreadX提供可选的运行时应用程序计时器性能信息。如果ThreadX库和应用程序是在定义了TX_TIMER_ENABLE_PERFORMANCE_INFO的情况下构建的,ThreadX将累积以下信息。
Total number for the overall system:
-
activations
-
deactivations
-
reactivations (periodic timers)
-
expirations
-
expiration adjustments
整个系统的总数:
- 激活
- 停用
- 重新激活(周期计时器)
- 过期
- 到期调整
Total number for each application timer:
-
activations
-
deactivations
-
reactivations (periodic timers)
-
expirations
-
expiration adjustments
每个应用程序计时器的总数:
- 激活
- 停用
- 重新激活(周期计时器)
- 过期
- 到期调整
This information is available at run-time through the services tx_timer_performance_info_get and tx_timer_performance_system_info_get. Application Timer performance information is useful in determining if the application is behaving properly. It is also useful in optimizing the application.
此信息在运行时可通过服务tx\u timer\u performance\u info\u get和tx\u timer\u performance\u system\u info\u get获得。应用程序计时器性能信息有助于确定应用程序是否正常运行。它也有助于优化应用程序。
Application Timer Control Block TX_TIMER
The characteristics of each application timer are found in its control block. It contains useful information such as the 32-bit expiration identification value. This structure is defined in the tx_api.h file.
Application timer control blocks can be located anywhere in memory, but it is most common to make the control block a global structure by defining it outside the scope of any function.
应用程序定时器控制块TX_TIMER
每个应用程序计时器的特性都可以在其控制块中找到。它包含有用的信息,例如32位过期标识值。这个结构是在 tx_api.h文件中定义的。
应用程序计时器控制块可以位于内存中的任何位置,但最常见的做法是将控制块定义在任何函数的范围之外,从而使其成为全局结构。
Excessive Timers
By default, application timers execute from within a hidden system thread that runs at priority zero, which is typically higher than any application thread. Because of this, processing inside application timers should be kept to a minimum.
It is also important to avoid, whenever possible, timers that expire every timer tick. Such a situation might induce excessive overhead in the application.
重要
As mentioned previously, application timers are executed from a hidden system thread. It is, therefore, important not to select suspension on any ThreadX service calls made from within the application timer's expiration function.
定时器过多
默认情况下,应用程序计时器从以零优先级运行的隐藏系统线程中执行,该优先级通常高于任何应用程序线程。因此,应用程序计时器内部的处理应保持在最低限度。类似中断处理,要快速
同样重要的是,尽可能避免计时器在每次计时器滴答响时都过期。这种情况可能会导致应用程序中的开销过大。
重要
如前所述,应用程序计时器是从隐藏的系统线程执行的。因此,在应用程序计时器的过期函数中进行的任何ThreadX服务调用上,不要选择suspension挂起是很重要的。
Relative Time
In addition to the application timers mentioned previously, ThreadX provides a single continuously incrementing 32-bit tick counter. The tick counter or time is increased by one on each timer interrupt.
The application can read or set this 32-bit counter through calls to tx_time_get and tx_time_set, respectively. The use of this tick counter is determined completely by the application. It is not used internally by ThreadX.
相对时间
除了前面提到的应用程序计时器之外,ThreadX还提供了一个连续递增的32位计时计数器。每次定时器中断时,滴答计数器或时间增加一个。
应用程序可以通过分别调用 tx_time_get and tx_time_set来读取或设置这个32位计数器。此滴答计数器的使用完全由应用程序决定。ThreadX没有在内部使用它。
Interrupts
Fast response to asynchronous events is the principal function of real-time, embedded applications. The application knows such an event is present through hardware interrupts.
An interrupt is an asynchronous change in processor execution. Typically, when an interrupt occurs, the Interrupts processor saves a small portion of the current execution on the stack and transfers control to the appropriate interrupt vector. The interrupt vector is basically just the address of the routine responsible for handling the specific type interrupt. The exact interrupt handling procedure is processor specific.
中断
对异步事件的快速响应是实时嵌入式应用程序的主要功能。应用程序知道这样的事件是通过硬件中断出现的。
中断是处理器执行过程中的一种异步变化。通常,当中断发生时,中断处理器将当前执行的一小部分保存在堆栈上,并将控制转移到适当的中断向量。中断向量基本上只是负责处理特定类型中断的例程的地址。确切的中断处理过程是特定于处理器的。
Interrupt Control
The tx_interrupt_control service allows applications to enable and disable interrupts. The previous interrupt enable/disable posture is returned by this service. It is important to mention that interrupt control only affects the currently executing program segment. For example, if a thread disables interrupts, they only remain disabled during execution of that thread.
备注
A Non-Maskable Interrupt (NMI) is an interrupt that cannot be disabled by the hardware. Such an interrupt may be used by ThreadX applications. However, the application's NMI handling routine is not allowed to use ThreadX context management or any API services.
中断控制
tx_interrupt_control 服务允许应用程序启用和禁用中断。此服务返回上一个中断启用/禁用姿势。必须指出的是,中断控制只影响当前正在执行的程序段。例如,如果一个线程禁用中断,那么它们只在该线程执行期间保持禁用状态。
备注
不可屏蔽中断(NMI)是硬件不能禁用的中断。ThreadX应用程序可以使用这种中断。但是,应用程序的NMI处理例程不允许使用ThreadX上下文管理或任何API服务。???
ThreadX Managed Interrupts
ThreadX provides applications with complete interrupt management. This management includes saving and restoring the context of the interrupted execution. In addition, ThreadX allows certain services to be called from within Interrupt Service Routines (ISRs). The following is a list of ThreadX services allowed from application ISRs.
ThreadX管理的中断
ThreadX为应用程序提供了完整的中断管理。这种管理包括保存和恢复中断执行的上下文。此外,ThreadX允许从中断服务例程(isr)中调用某些服务。以下是应用程序ISR允许的ThreadX服务列表。
tx_block_allocate
tx_block_pool_info_get tx_block_pool_prioritize
tx_block_pool_performance_info_get
tx_block_pool_performance_system_info_get tx_block_release
tx_byte_pool_info_get tx_byte_pool_performance_info_get
tx_byte_pool_performance_system_info_get
tx_byte_pool_prioritize tx_event_flags_info_get
tx_event_flags_get tx_event_flags_set
tx_event_flags_performance_info_get
tx_event_flags_performance_system_info_get
tx_event_flags_set_notify tx_interrupt_control
tx_mutex_performance_info_get
tx_mutex_performance_system_info_get tx_queue_front_send
tx_queue_info_get tx_queue_performance_info_get
tx_queue_performance_system_info_get tx_queue_prioritize
tx_queue_receive tx_queue_send tx_semaphore_get
tx_queue_send_notify tx_semaphore_ceiling_put
tx_semaphore_info_get tx_semaphore_performance_info_get
tx_semaphore_performance_system_info_get
tx_semaphore_prioritize tx_semaphore_put tx_thread_identify
tx_semaphore_put_notify tx_thread_entry_exit_notify
tx_thread_info_get tx_thread_resume
tx_thread_performance_info_get
tx_thread_performance_system_info_get
tx_thread_stack_error_notify tx_thread_wait_abort tx_time_get
tx_time_set tx_timer_activate tx_timer_change
tx_timer_deactivate tx_timer_info_get
tx_timer_performance_info_get
tx_timer_performance_system_info_get
重要
Suspension is not allowed from ISRs. Therefore, the wait_option parameter for all ThreadX service calls made from an ISR must be set to TX_NO_WAIT.
重要
ISRs不允许挂起。因此,从ISR发出的所有ThreadX服务调用的wait_option 参数必须设置为TX_NO_WAIT。
ISR Template
To manage application interrupts, several ThreadX utilities must be called in the beginning and end of application ISRs. The exact format for interrupt handling varies between ports.
The following small code segment is typical of most ThreadX managed ISRs. In most cases, this processing is in assembly language.
ISR模板
要管理应用程序中断,必须在应用程序isr的开头和结尾调用几个ThreadX实用程序。中断处理的确切格式因端口而异。
下面的小代码段是大多数ThreadX管理的isr的典型代码段。在大多数情况下,这种处理是在汇编语言中进行的。
_application_ISR_vector_entry:
; Save context and prepare for
; ThreadX use by calling the ISR
; entry function.
CALL _tx_thread_context_save
; The ISR can now call ThreadX
; services and its own C functions
; When the ISR is finished, context
; is restored (or thread preemption)
; by calling the context restore ; function. Control does not return!
JUMP _tx_thread_context_restore
High-frequency Interrupts
Some interrupts occur at such a high frequency that saving and restoring full context upon each interrupt would consume excessive processing bandwidth. In such cases, it is common for the application to have a small assembly language ISR that does a limited amount of processing for a majority of these high-frequency interrupts.
After a certain point in time, the small ISR may need to interact with ThreadX. This is accomplished by calling the entry and exit functions described in the above template.
高频中断
有些中断发生的频率很高,在每次中断时保存和恢复完整的上下文会消耗过多的处理带宽。在这种情况下,应用程序通常有一个小的汇编语言ISR,它对大多数高频中断进行有限的处理。
在某个时间点之后,小型ISR可能需要与ThreadX交互。这是通过调用上述模板中描述的入口和出口函数来实现的。
Interrupt Latency
ThreadX locks out interrupts over brief periods of time. The maximum amount of time interrupts are disabled is on the order of the time required to save or restore a thread's context.
中断延迟
ThreadX在短时间内锁定中断。中断被禁用的最大时间量取决于保存或恢复线程上下文所需的时间顺序。