深度学习之DCN-v2
这篇文章发表在2019的CVPR上,是Deformable Convolution Network的进阶版本——DCN-v2,通过对DCN的两处改进来增加卷积神经网络的适应性与灵活性。具体来说,通过堆叠多个DCN来增强感知的范围;通过引入调制机制来为DCN增加更多选择采样区域的自由度,这种调制通过门机制来实现对采样区域的注意力。
Deformable ConvNets v2: More Deformable, Better Results
- Abstract
- 1 Introduction
- 2 Focus point
-
- 2.1 Stacking More Deformable Conv Layers
- 2.2 Modulated Deformable Modules
- 3 Experiments
- 4 Conclusion
Abstract
发现问题:
DCN由于其适应于图像几何变化而保持网络性能不变的特点(即空间不变性)在近几年可作为取代普通CNN层的一种趋势。但是DCN暴露出来的一大缺陷在于,其采样点经过offset之后的新位置会超出我们理想中的采样位置,导致部分可变形卷积的卷积点可能是一些和物体内容不相关的部分,如下图所示:

解决问题
- 通过引入一个调制模块来控制好offset的变化幅度(或者说变化范围),减缓上述2种情况要么偏移幅度过小,要么过大的窘境。这种调制模块和超分算法Robust-LTD中时间自适应网络中的调制分支很类似,都是去训练一个注意力权重来控制新采样点为我们感兴趣的区域。
- 此外,为了增强模型的表现力,作者在DCN-v2中又引入了多个DCN堆积的机制,并通过实验证明了其对于模型表现力的提升作用。
- DCN-v2在视频超分领域的对齐中起着至关重要的作用,从19年DCN-v2提出后,诸如EDVR、BasicVSR++等都使用了DCN-v2来取代DCN(初代版本)。
DCN-v2的功效
- 在表现力上,通过堆积调制过的DCN块来使得模型的表现力要强于DCN的堆积,当然比普通的CNN的堆积也要好得多,这得益于DCN本身空间不变性的增强以及采样范围的扩大。
- 有了调制模块,可变形卷积在控制采样范围上也更加精确。
1 Introduction
作者通过在DCN的基础上,增加了2个创新点,分别是调制模块和使用多个调制后的DCN模块,从形成了DCN的升级版本——DCN-v2!
①调制模块:
除了学习偏移参数 Δ p \Delta p Δp(offset)之外,还要通过调制学习一个变化幅度 Δ m \Delta m Δm。通过这个幅度来进一步合理控制新采样点的偏移范围。经过调制后的单个DCN我们记为mDCN(modulated-DCN)。
②多个调制DCN的堆积:
通过堆积多个调制mDCN来增加offset的偏移范围,同时显然多个块的堆积对偏移的精确性也是有一定校正细化的作用的,即进一步增强其对抗空间变化的能力(coarse-to-fine)。
2 Focus point
2.1 Stacking More Deformable Conv Layers
这里的思想也很简单,不仅用DCN取代普通的CNN,还同时使用多个DCN堆积来提升模型对空间变换的对抗能力。
这种级联产生对模型表现力的提升可以直接从实验结果中得到验证,具体看第3节实验结果部分。
2.2 Modulated Deformable Modules
这部分的理解需要现有DCN的基础,在介绍调制机制之前,不了解DCN的请参考深度学习之DCN,避免对一些符号和原理的不理解。
为了方便介绍,我们还是假设可变形卷积核为 3 × 3 3\times 3 3×3, p k , w k p_k,w_k pk,wk分别为一个卷积核内第 k ∈ { 1 , ⋯ , K } k\in \{1, \cdots, K\} k∈{1,⋯,K}个位置和相应卷积参数,其中 p k ∈ { ( − 1 , − 1 ) , ⋯ , ( 0 , 0 ) , ⋯ , ( 1 , 1 ) } p_k\in \{(-1, -1), \cdots, (0,0), \cdots , (1,1)\} pk∈{(−1,−1),⋯,(0,0),⋯,(1,1)}, K = 9 K=9 K=9表示一个卷积核内的卷积点个数。
设 p 0 p_0 p0为输出feature map上的位置,则DCN-v1的可变形卷积为:
Y ( p 0 ) = ∑ k = 1 K w k X ( p 0 + p k + Δ p k ⏟ p ) . Y(p_0) = \sum^K_{k=1} w_k X(\underbrace{p_0+p_k+\Delta p_k}_p). Y(p0)=k=1∑KwkX(p p0+pk+Δpk).其中 p = p 0 + p k + Δ p k p=p_0+p_k+\Delta p_k p=p0+pk+Δpk表示待卷积的新采样位置,一般为浮点数; X 、 Y X、Y X、Y分别为输入和输出feature map,当然 Y Y Y也可以是Image; Δ p \Delta p Δp是我们学习到的offset。
Note:
- 这里我们忽略卷积中的bias参数。
接下来我们在DCN-v1的基础上引出调制过的DCN——DCN-v2:
Y ( p 0 ) = ∑ k = 1 K w k X ( p 0 + p k + Δ p k ⏟ p ) ⋅ Δ m k . Y(p_0) = \sum^K_{k=1} w_k X(\underbrace{p_0+p_k+\Delta p_k}_p) \cdot {\color{mediumorchid}\Delta m_k}. Y(p0)=k=1∑KwkX(p p0+pk+Δpk)⋅Δmk.
- 这个 Δ m k \Delta m_k Δmk和offset一样,都需要一个额外的CNN去学习它,和offset的学习过程一样,输入都是 X X X,输出都是一个feature map;唯一不同的是,offset对输入的每一个通道输出的offset参数通道是 2 K 2K 2K,因为包括垂直和横向2个方向,而modulation scalars的输出通道数为 K K K。
- 它是一个常数,且 Δ m ∈ [ 0 , 1 ] \Delta m\in[0,1] Δm∈[0,1],因此调制网络的输出末端一定有限定函数,比如sigmoid,由于 Δ m \Delta m Δm以以相乘的方式和前面部分相结合,且其使用了sigmoid等阈值函数,故调制机制本质上是们机制的变形。
- 通过 Δ m \Delta m Δm来控制偏移的幅度,使得我们采样的新位置会更好地移动到我们感兴趣的区域,故调制也是注意力机制的一种。
- Δ m \Delta m Δm的出现也正是因为 Δ p \Delta p Δp是一个无限制的变量。
Note:
- 可变形卷积中变形的是基于输入feature map上采样点的变化,卷积核是不变的!
- 输入 X X X和offset、modulation scalars都是高和宽一样的feature map。
- w k w_k wk是可变形卷积参数,而学习
offset和modulation scalars的卷积是普通的CNN。 - 和DCN-v1一样,之后还需要通过双线性插值来进一步获取最终的 X ( p ) X(p) X(p)从而完成整个warp。
3 Experiments
为了验证DCN-v2相对DCN-v1、常规CNN对表现力的提升作用,作者在COCO 2017数据集上,用可变形卷积替换网络模型中的第3~5
层中的卷积层,实验结果如下:
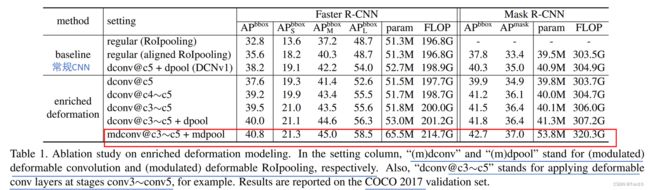
实验结论如下:
- 不管是哪个版本的DCN,相比常规CNN,都可以增加一定的表现力。
- 在不使用mDCN下,堆叠DCN可以提升性能,证明了使用多个DCN能有效增强模型的表现力。
- 增加了mDCN之后的堆叠比DCN-v1的堆叠更能提升模型的表现力,证明了调制机制的有效性。
可视化结果如下:
一共3个场景,其中绿色点是我们要卷积的对象:第一个场景我们的目标是一个很小的物体;第二场景是一个较大的物体;第三个场景是背景。每一种卷积类型下,从上到下表征的分别是卷积位置、感受野、error-bounded saliency regions。
Note:
- error-bounded saliency regions在视觉显著性(视觉显著性(Visual Attention Mechanism,VA,即视觉注意机制)是指面对一个场景时,人类自动地对感兴趣区域进行处理而选择性地忽略不感兴趣区域,这些人们感兴趣区域被称之为显著性区域)方面用的比较多,关于该指标的解释原文种有介绍:
 意思就是不影响网络输出的最小范围,比如说某一块区域,其实影响网络输出的只是其中一块,那么删去多余的那部分,剩下的就是error-bounded saliency regions,类似化繁为简,更注意我们需要的那一部分。
意思就是不影响网络输出的最小范围,比如说某一块区域,其实影响网络输出的只是其中一块,那么删去多余的那部分,剩下的就是error-bounded saliency regions,类似化繁为简,更注意我们需要的那一部分。
实验结论:
- 相比常规卷积,可变形卷积可以增加采样范围,DCN-v2的采样范围和DCN-v1类似。
- 尤其是在小物体的感受野上,DCN-v2的采样范围过大,使得除了我们关注的小物体外,还有其它和小物体不相关的部分,而我们卷积的目的是利用空间冗余,根据局部空间的相关性来实现分类等任务,故DCN-v1这种过大的偏移会影响到最后的性能;而DCN-v2显然就控制好了偏移的幅度。
- 从error-bounded saliency regions看出,DCN-v2更加关注于对网络性能真正有用的区域,这得益于调制机制本质是一种注意力机制的原因。
4 Conclusion
- 文章通过在DCN基础上引入2个点:多个DCN堆叠、调制机制来提出DCN的进阶版本——
DCN-v2。 - DCN-v2的功能:①提升模型对空间变换的抗性②控制好偏移的范围,避免提取不相关的特征信息③增大卷积的范围等来提升模型的表现力。