Pretrained-model-01-Transformer论文阅读笔记

论文题目:Attention Is All Y ou Need
发表会议:2017-NIPS
1、背景知识
1.1、翻译效果评价指标BLUE




参考博客:
https://blog.csdn.net/guolindonggld/article/details/56966200 主要讲解BLUE在nltk中的实现
https://blog.csdn.net/jkwwwwwwwwww/article/details/52846728
from nltk.translate.bleu_score import sentence_bleu
reference = [[1, 2, 3, 1, 5, 6,7]]
candidate = [1,1,1,1,1,1,1]
score = sentence_bleu(reference, candidate, weights=(1, 0, 0, 0))
print(score)
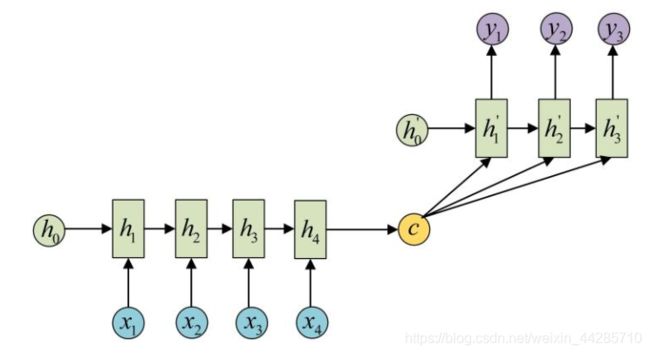
1.2、seq2seq模型与attention机制
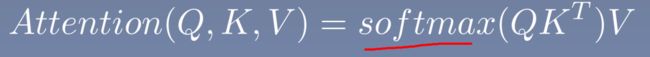
1.3、self-attention是什么?
以机器翻译任务为例,假设输入句子为:”The animal didn't cross the street because it was too tired”,当模型对每个词进行处理的时候,允许模型对输入句子中的每个词给与不同的关注程度,比如处理 it 时和 animal 或 street 之间谁更相关。以往的注意力机制通常是建模输入与输出之间的注意力关系,而没有注意输入与输入或输出与输出之间的关系,因此该方法可以形象地称为self-attention。
As the model processes each word (each position in the input sequence), self attention allows it to look at other positions in the input sequence for clues that can help lead to a better encoding for this word.

2、模型结构
参考博客:https://jalammar.github.io/illustrated-transformer/

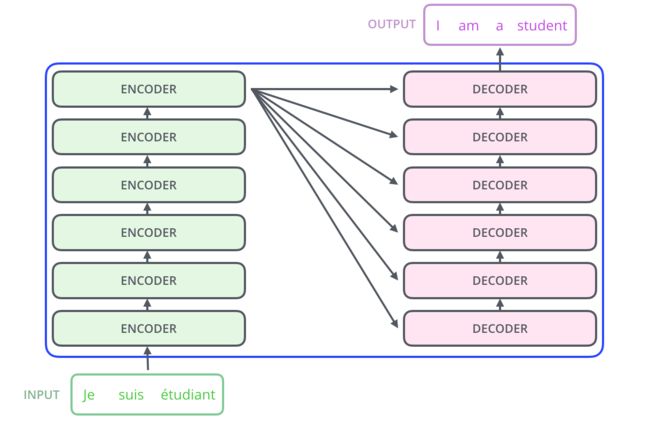
- 编码器
- 由6个相同的encoder结构堆叠而成
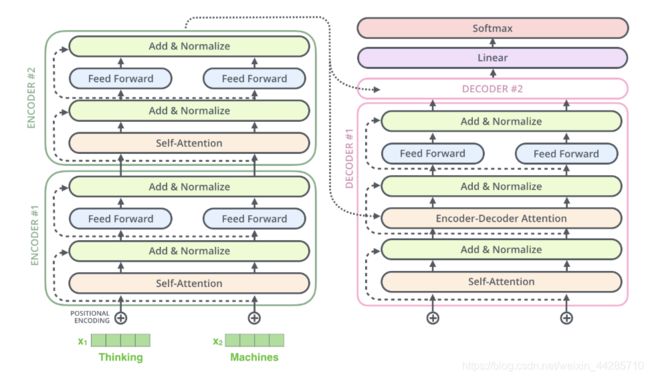
- 每个encoder结构包括两个子层,分别为multi-head attention 和全连接前馈网络
- 每个子层采用残差连接和Layer Normalization
- self-attention layer – a layer that helps the encoder look at other words in the input sentence as it encodes a specific word.
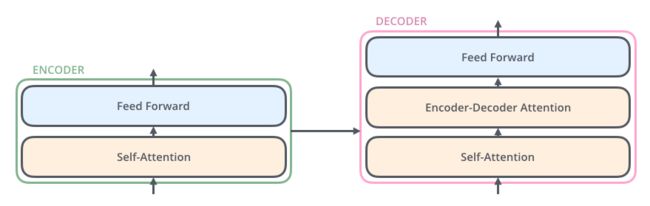
- 解码器
- 由6个相同的decoder结构堆叠而成
- 每个decoder结构包含三个子层,分别为 Self-Attention、Encoder-Decoder Attention 和全连接前馈网络
- The “Encoder-Decoder Attention” layer works just like multiheaded self-attention, except it creates its Queries matrix from the layer below Decoder, and takes the Keys and Values matrix from the output of the encoder stack.
- 每个子层采用残差连接和Layer Normalization
- 修改解码器中self-attention子层,以防止关注到未来的信息。采用mask的方式确保对位置i的预测只能依赖于小于i的信息。
- The decoder has both those layers, but between them is an attention layer that helps the decoder focus on relevant parts of the input sentence (similar what attention does in seq2seq models).
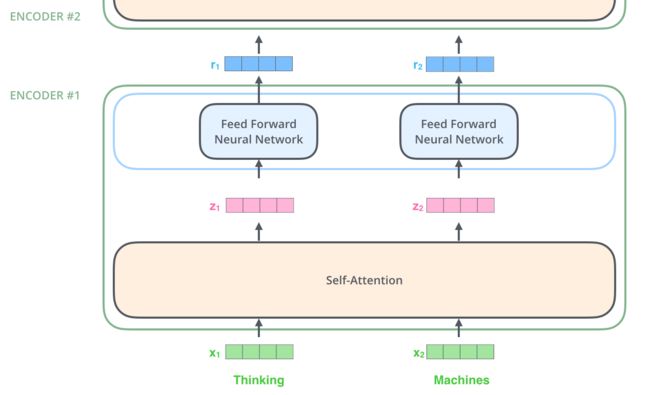
2、Encoder side
2.1、Scaled Dot-product attention
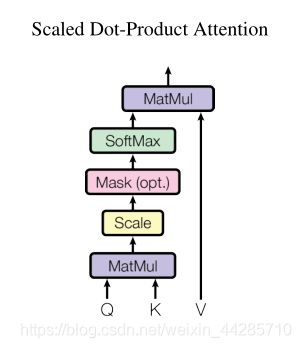
def attention(query, key, value, mask=None, dropout=None):
# "Compute 'Scaled Dot Product Attention'"
# shape: query = key = d_k ---->[batch_size, 8, max_sentence_length,64]
# shape: value = d_v
d_k = query.size(-1)
# key的纬度交换后为:[batch_size, 8, 64, max_sentence_length]
# scores的纬度为:[batch_size, 8, max_sentence_length, max_sentence_length]
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
# padding mask
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# masked_fill(mask,value) Fills elements of tensor with value where mask is True.
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn2.2、Selt Attention处理过程
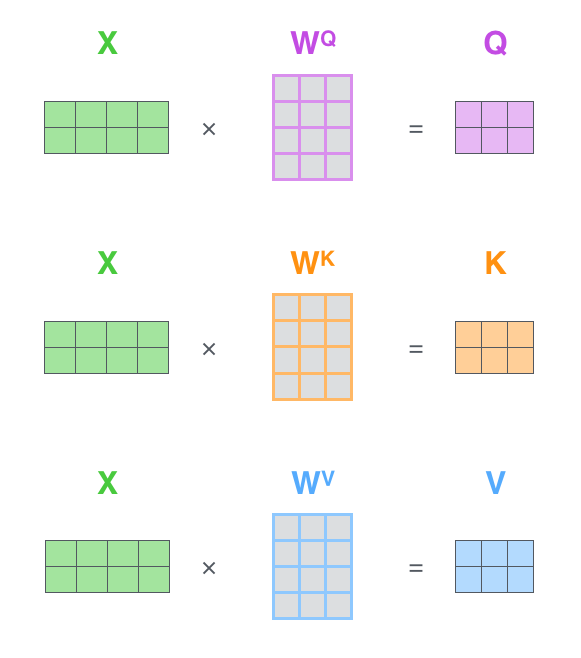
- 首先为每个词的embedding创建三个向量:分别是Query Vector, Key Vector 和Value Vector ;这些向量是通过词嵌入与三个可训练矩阵相乘得到的。即下图中的X 分别与 W_Q, W_K, W_V相乘得到
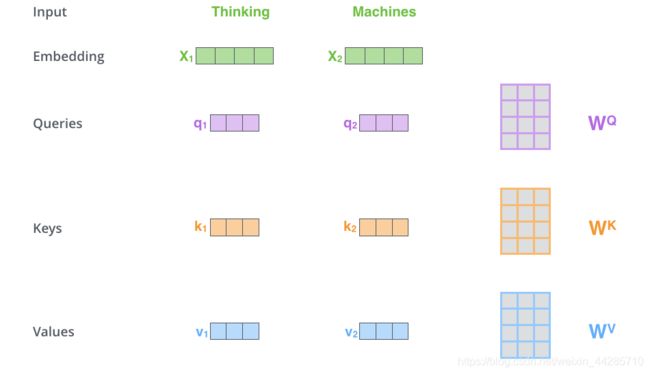
- 注意力分数的计算:通过第一步我们已经为每个词分配了Q,K,V三个向量,以下图为例,当我计算上下文各个词对Thinking这个词的贡献分别是多大时,只需要使用Thinking 这个词的 Q向量分别与其他词的K向量点乘就可以得到一串值。
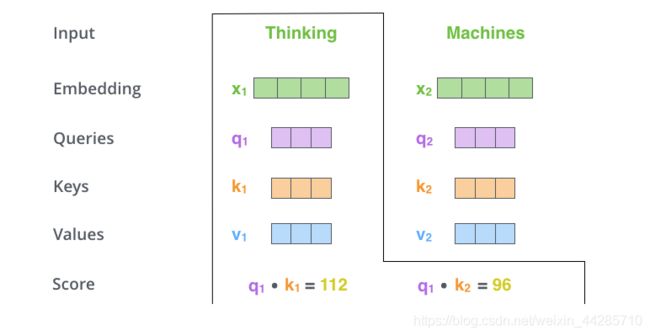
- 随后再经过一个softmax函数就可以得到上下文中各个词对Thinking这个词归一化之后的重要程度,也就是我们需要注意的程度。【除以根号d_k是为了获得稳定的梯度便于更新】
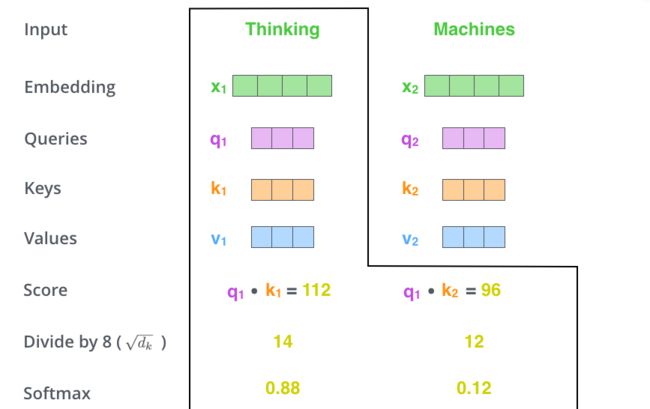
- 使用计算求得的注意力分数与每个词的 value vector相乘【或相加】得到自注意力作用后的结果Z
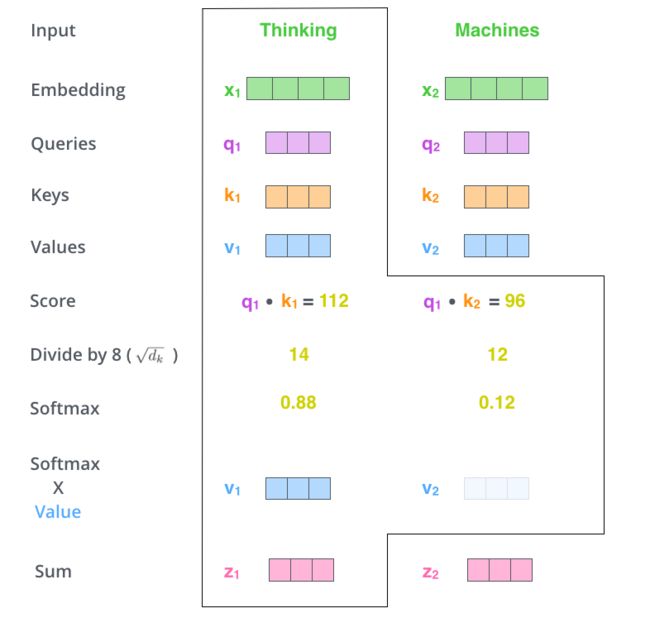
上面展示了一个词时如何进行处理的,实践中通常使用矩阵的方式加速运算。
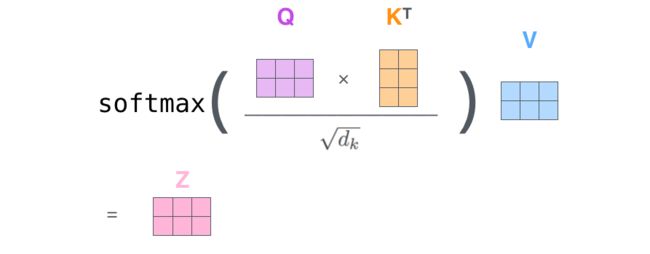
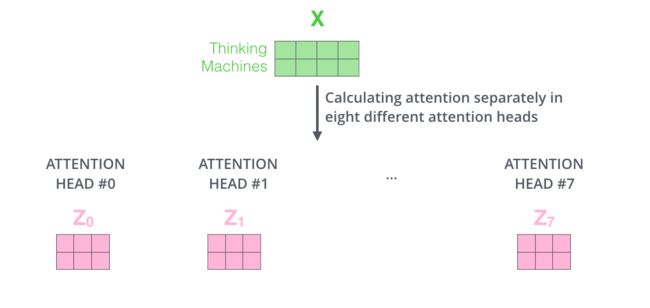
2.3、Multi-Head attention

采用Multi-Head attention机制的优点:
- 增强了模型关注不同位置的能力
- 它使得attention layer 拥有多个表征子空间:由于有多个Q,K,V,因此可以将word embedding投射到不同的表征子空间

- 由于后面的全连接前馈网络需要单个矩阵的输入,因此需要把多头得到的矩阵进行拼接
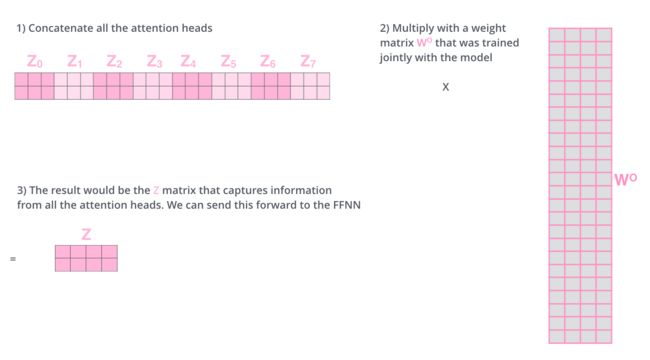

class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
# "Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0 # 用于判断一个表达式,在表达式条件为 false 的时候触发异常
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
# 为什么copy了四份全连接: query--W_Q, key--W_K, value--W_V 和 最后拼接输出的 W_O
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
# shape:query=key=value--->:[batch_size,max_legnth,embedding_dim=512]
# "Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 第一步:将q,k,v分别与Wq,Wk,Wv矩阵进行相乘
# shape:Wq=Wk=Wv----->[512,512]
# 第二步:将获得的Q、K、V在第三个纬度上进行切分
# shape:[batch_size,max_length,8,64]
# 第三步:填充到第一个纬度
# shape:[batch_size,8,max_length,64]
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 进入到attention之后纬度不变,shape:[batch_size,8,max_length,64]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 将纬度进行还原
# 交换纬度:[batch_size,max_length,8,64]
# 纬度还原:[batch_size,max_length,512]
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
# 最后与WO大矩阵相乘 shape:[512,512]
return self.linears[-1](x)2.4、Positional Encoding
从上面模型的介绍可以看出,self-attention在处理的过程中并不包含输入序列词之间的顺序信息,因此为了解决该问题,本文引入了位置编码并加入到词嵌入上送入后续的网络处理。
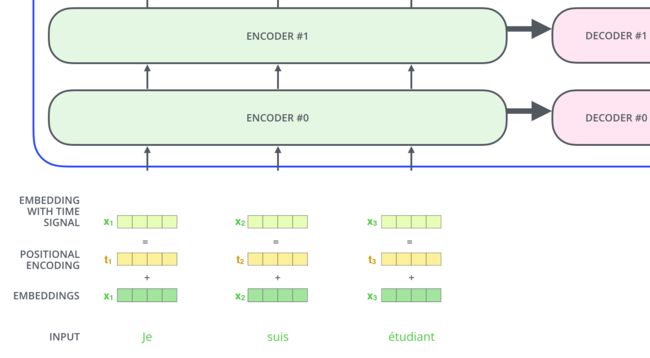

代码实现中采用的公式变形

class PositionalEncoding(nn.Module):
# "Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0., max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0., d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
2.5、 Residual Connection & Layer Normalization
每个子层具有残差连接,随后进行 layer-normalization 操作
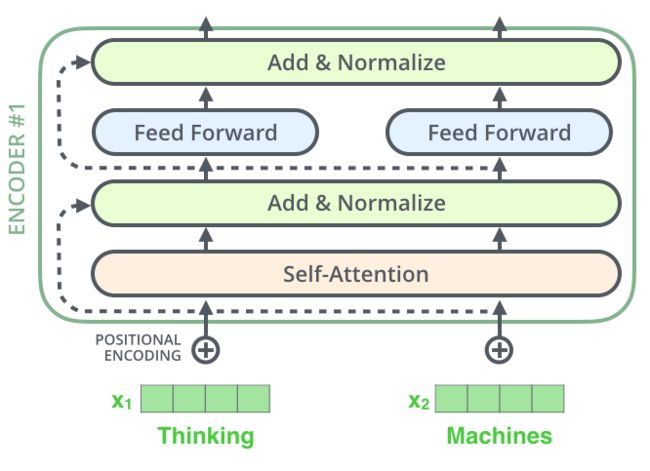
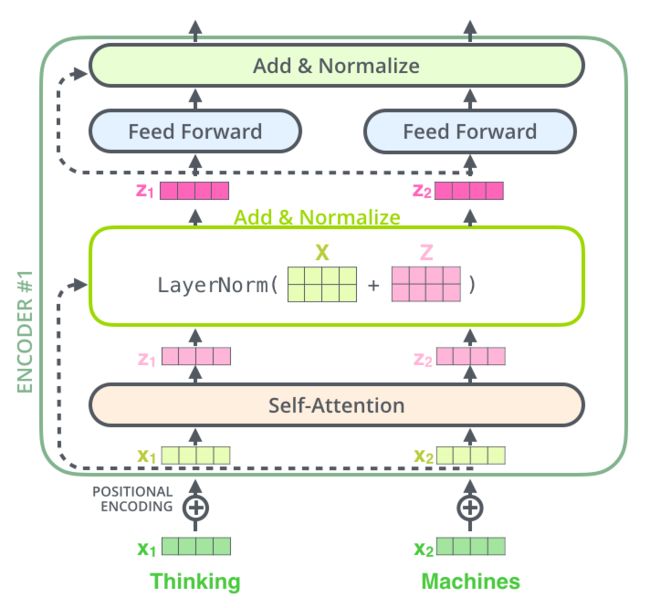
3、Decoder side
在解码器阶段,self-attention layer与在编码器阶段有一些不同,仅允许注意输出序列当前词之前的位置,这是通过mask掉未来位置来完成的【 (setting them to -inf) before the softmax step in the self-attention calculation.】
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# masked_fill(mask,value) Fills elements of tensor with value where mask is True.完整流程示意图
3.1、最终输出层
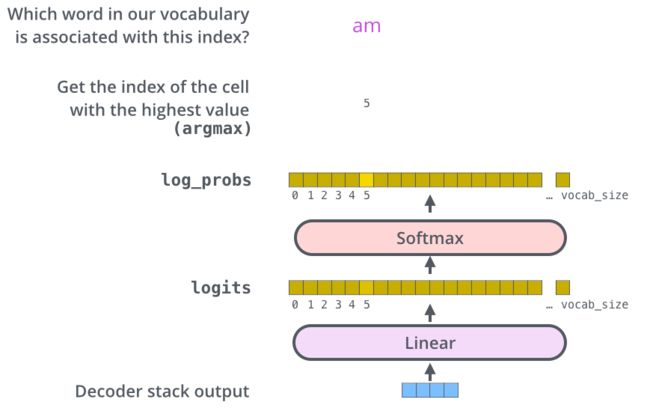
3.2、Beam search

4、代码实现
pytorch:http://nlp.seas.harvard.edu/2018/04/03/attention.html
本文为深度之眼paper论文班的学习笔记,仅供自己学习使用,如有问题欢迎讨论!关于课程可以扫描下图二维码

